
结合注意力机制的生成对抗网络图像超分辨重建
2023-05-17 02:58甄昊宇林青宇
福建师范大学学报(自然科学版) 2023年3期
张 德,甄昊宇,林青宇
(北京建筑大学电气与信息工程学院,建筑大数据智能处理方法研究北京市重点实验室,北京 100044)
图像超分辨(image super-resolution,SR)重建是指采用图像处理或者信号处理的方法,通过算法将已有的细节信息较少的低分辨(low resolution,LR)图像转换为纹理细节较多的高分辨(high resolution,HR)图像的技术.相较于实现SR重建的硬件方案,软件方案的成本更加低廉且更易于推广与实现,重建出的图像质量也接近于理想图像.因此,SR重建不仅在学术上具有研究的价值,而且实际应用前景也相当广泛,在医学影像、卫星遥感成像、视频监控和刑侦分析等多个方面具有广泛的应用[1-2].
随着深度学习技术的快速发展,基于深度学习的SR重建方法得到了很多关注和研究,在超分辨的多种评价指标上取得了良好的结果.Dong等[3]提出SRCNN(super-resolution convolution neural network)模型,首次将卷积神经网络CNN应用于超分辨任务中.该模型的性能超越了大多数传统SR算法,图像重建效果得到较大提升.此后,大量基于深度学习不同网络结构的图像超分辨重建算法模型被提出.Kim等[4]将残差网络(ResNet)引入图像超分辨中,通过使用跳跃连接的方式,避免了梯度过大或者梯度消失,从而使网络结构层次可以设计得比较深.在He等[5]提出ResNet用于学习残差而不是彻底映射之前,残差学习已经被超分辨率模型广泛使用[6-8].Ledig等[9]提出了SRGAN(super-resolution generative adversarial network)模型,首次使用GAN网络进行了单幅图像超分辨重建的尝试.SRGAN由生成器G和判别器D两部分组成,将低分辨率图像输入至生成器G中进行图像重建,然后由判别器D将生成图像与真实图像对抗训练,最后输出训练后的图像.相较于之前的算法,在视觉效果、图像细节等主观方面重建效果更加理想和真实.
然而,在实际应用中SRGAN的重建效果依然不够理想.其客观评价指标比较低,虽然相较于其他网络模型而言,重建效果更为真实,但与真实图像仍然有差距.因此,基于SRGAN的很多改进算法也被提出[10-11].Xiang等[10]设计了包含2个卷积层和2个BN(batch normalization)层的深度残差块,引入SRGAN中,并提出新的多分支RFB(receptive field block)结构,增加了3×3卷积分支.Jiang等[11]则使用了密集连接残差块,并移除了BN层,简化了运算复杂度.判别器部分则使用VGG-19作为基础网络架构,并采用平均池化防止过拟合.同时,在卷积操作过程中,如果对各个通道、空间的重要程度没有进行区分,也会导致重建效果不佳.RCAN(residual channel attention network)模型[12]将通道注意力机制引入SR研究领域,可以通过通道之间的依赖关系选择包含更多重要信息的通道,增强整个网络的辨识学习能力,展现了更好的重建效果.Liu等[13]将多个残差通道注意力模块组合为编码-解码结构,应用于SRGAN的生成器网络,以得到更真实的图像.Huang等[14]使用U-Net为基础网络,结合通道注意力和空间注意力组成双重注意力模块,可以重建出高质量的HR图像.
本文借鉴以上思路,对SRGAN模型进行改进,同时引入通道注意力和空间注意力,构成双重注意力机制模块.这样,可以捕捉不同通道和空间位置特征的重要性,根据特征的重要程度自适应捕捉重要信息,并同时抑制无用特征.在生成器网络中去除BN层,以减少网络的计算复杂度,提升了网络性能.在判别器网络部分,相较于原始GAN网络,本文模型使用WGAN[15],其采用Wasserstein距离优化对抗损失,更好解决了梯度消失问题,网络训练更加稳定.
1 生成对抗网络介绍
生成对抗网络GAN采用了博弈论方法,由生成器G和判别器D两个部分组成.在图像超分辨任务中,生成器G负责生成重建图像,判别器D根据自身判定条件判别生成图像与真实图像的差距,用试图欺骗判别器的方法来进一步恢复图像(见图1).由于其特殊机制的存在,通过这种方式,往往可以生成视觉效果更好的HR图像[16-18].判别器D依据设定的目标损失函数来计算判别样本与真实数据之间一致性的概率.如果判别器认为是真实样本,则输出1,反之为0.基于博弈思想,生成器则根据判别结果不断进行更新重建图像,使得判别器无法判断输入样本是来自真实样本还是生成样本.
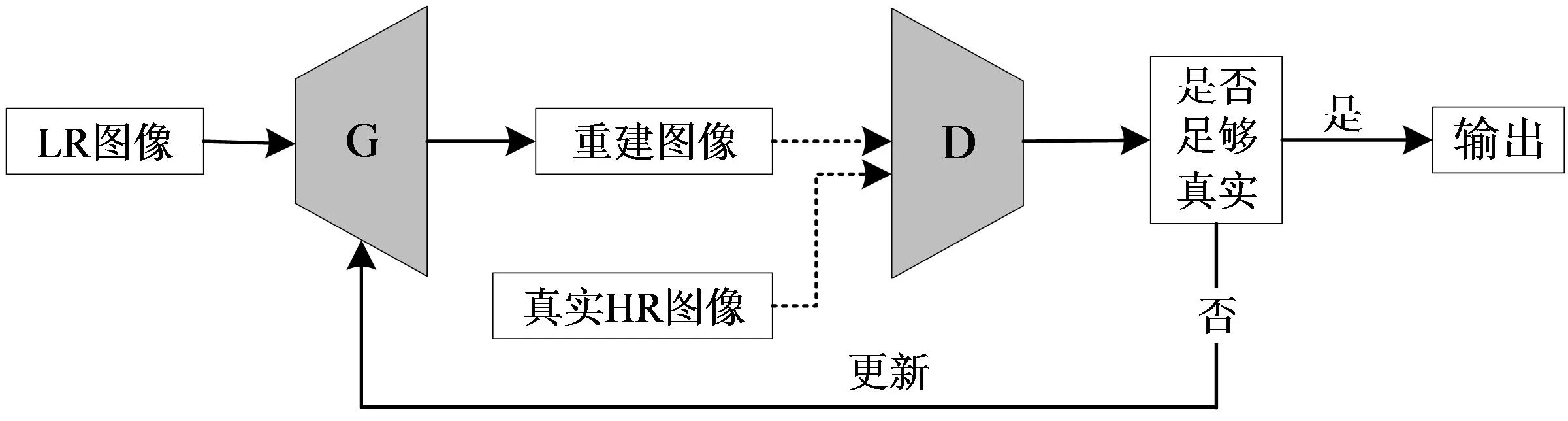
图1 SRGAN基本模型结构Fig.1 Basic structure of SRGAN
2 本文模型
2.1 基本介绍
相较于SRCNN[3]和VDSR[4]等经典SR网络模型,SRGAN在重建效果、细节纹理等方面虽然有提升,但与真实图像相比依然有很大的提升空间.在基于GAN的SR研究任务中,生成器与判别器对于图像的恢复重建均至关重要.本文首先在生成器部分引入注意力机制并去除BN层,降低模型的计算量.构建一种基于通道注意力和空间注意力的双重注意力机制模块,捕捉不同通道或空间特征的重要性来获取对应位置的权重参数,从而自适应地根据通道内特征的重要程度分配计算资源以增强有用特征抑制无用特征.同时算法模型中通过长跳跃连接构建特征监督,将每个模块的输出都自适应用于图像重建,加快网络收敛,并且各分层特征都能够得到有效利用.
在判别器部分,由于传统GAN基于JS散度进行优化,导致GAN模型的训练过程不稳定.所以,本文使用基于Wasserstein距离判别函数的WGAN网络,通过Wasserstein距离来衡量真实图片与生成图片之间的相似度,WGAN模型的训练过程更加稳定.Wasserstein距离的计算公式如下:
W(Pr,Pg)=infγ∈∏(Pr,Pg)E(x,y)~γ[‖x-y‖],
(1)
其中,Pr是真实样本分布,Pg是生成器生成样本分布,∏(Pr,Pg)是Pr和Pg所有可能的分布的集合.E(x,y)~γ[‖x-y‖]代表真实数据x与生成数据y之间距离的期望,x和y都能从分布γ中采样得到,在所有可能分布样本的集合中求出最小值即为Wasserstein距离.
2.2 双重注意力机制模块

图2 注意力块内部结构Fig.2 Inner structure of attention modules
本模型通过将通道注意力和空间注意力机制融合构建一个新的模块,进一步强化了SR重建的效果.图2为这2个注意力模块的内部结构,详细描述如下.
2.2.1 通道注意力机制块
通道注意力机制是通过通道之间的特征关系来提取通道间的重要信息.由于基本卷积块的输出不能利用局部区域之外的全局上下文信息,而通道注意力机制的全局池化层则包含了通道的全局空间信息,并且特征映射中不同通道在提取低频或高频分量上起着不同的作用,引入通道注意力机制可以自适应地调节信道的权重从而有效地提高SR重建指标.
为了有效地计算通道注意力,往往采用压缩特征图空间维数的方式,一般使用平均池化操作.另外,CBAM[19]表明最大池化可以收集不同对象的特征,进而得到更加精细的通道特征.因此,本模型把最大池化和平均池化同时应用到通道注意力模块中,如下式所示:
(2)

2.2.2 空间注意力机制块
空间注意力机制指同一通道中的不同区域,具有不同的重要性.空间注意力关注空间中哪些是重要的部分,是通道注意力很好的补充.引入空间注意力机制可以使特征提取集中在高频区域的细节部分,同时抑制低频区域的权重,有助于高频滤波器学习更多的高频特征,最终图像的高频细节被更好地重建.
本模型空间注意力的计算是通过沿着通道轴分别进行平均池化和最大池化操作,然后连接起来组成有效的特征描述符.在连接的特征描述符中使用卷积层生成空间注意力图,即标明了需要加强或者抑制的位置.空间注意力机制块可以表示为:

图3 双重注意力机制块结构Fig.3 Structure of double-attention module
(3)

图3为本模型采用的双重注意力机制方法示意图,当特征经过通道注意力机制块和空间注意力机制块后,进行局部残差操作,这样可以在利用双重注意力机制块内输入信息的同时,有效地避免梯度爆炸与梯度消失,并且提高网络训练效率.
2.3 损失函数
不同的损失函数有着各自的优势,目前在一个网络模型中往往使用多种损失函数的组合.本模型选择使用GAN网络常用的内容损失、感知损失和对抗损失的组合.
本模型采用较为稳定的L1像素损失函数,即度量2个图像之间像素值的平均绝对误差.感知损失通过预训练的VGG19网络所提取的特征图进行定义,可以使图像的生成细节更加逼真.以φi,j表示VGG19预训练网络的第i个最大池化层之前的第j个卷积的特征图,Wi,j和Hi,j分别表示特征图的宽度和高度.感知损失Lvgg则定义为重建图像ISR和高分辨率图像IHR在VGG19网络中特征图之间的欧氏距离,如下式:
(4)
对抗损失目的是使生成器生成的图像更加真实.在对抗损失计算方面,SRGAN等模型使用了交叉熵损失函数,也可以使用最小二乘法进行计算.本文为了解决梯度消失的问题,借鉴WGAN思想,基于Wasserstein距离计算对抗损失,如式(1)所示.但是由于γ~∏(Pr,Pg)无法直接求解,所以通过Lipschitz连续定理将式(1)转换为下式[15]:
(5)
其中,K为常数,使得任意的Ex~Pr[f(x)]-Ex~Pg[f(x)]≤K.函数f的Lipschitz常数‖f‖L在不超过K的条件下,对所有可能满足条件的f取到Ex~Pr[f(x)]-Ex~Pg[f(x)]的上界.用一组参数ω来表示所有满足条件的f,式(5)转换为下式:
(6)
此时,使得L=Ex~Pr[f(x)]-Ex~Pg[f(x)]尽可能取得最大值,L即近似表示真实分布与生成分布的Wasserstein距离.GAN模型中的生成器网络需要最小化L,从而得到生成器的对抗损失Ladv,如下式所示:
Ladv=Ex~Pg[D(x)]-Ex~Pr[D(x)].
(7)
最后把3种损失函数进行加权和表示,得到总的损失函数:
LG=L1+10-3Lvgg+10-3Ladv.
(8)
2.4 网络结构
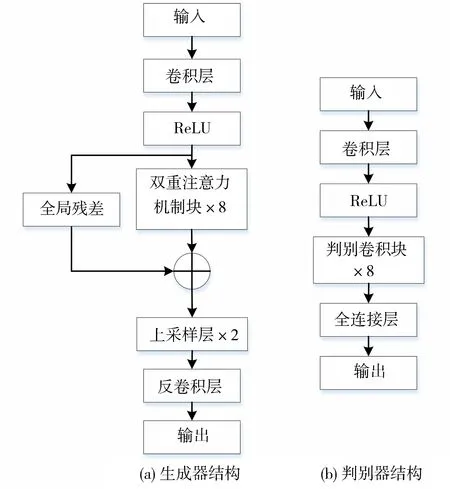
图4 本模型使用的网络模型结构Fig.4 Network structure used in this model
本模型结构设计的主要思路是把双重注意力机制应用到生成器网络部分,然后判别器网络使用WGAN进行优化,模型结构如图4所示.
在生成器端,首先使用一个3×3卷积层和一个ReLU层对输入图像进行浅层特征提取;接着将提取的特征图送入双重注意力机制模块进行进一步的特征提取和学习.双重注意力模块部分由8个基本双重注意力块(图3)组成,每一块的输出作为下一块的输入.通过双重注意力机制将所有相同大小的特征图进行特征学习,每层卷积的输入都包含前面层所学习的输出,使得网络具有连续性,同时让每层的特征可以不间断的向后传递,每层的特征信息得以不断利用.接下来进行全局残差学习,使得底层特征信息与双重注意力机制块学习后的特征进行融合,底层信息可得到充分利用.最后运用两个上采样层和反卷积层根据尺度因子逐步恢复出高分辨率图像.判别器部分以SRGAN的判别器网络为基础,引入WGAN的思想,使用Wasserstein距离来衡量真实图片与生成图片之间的距离,因此去除了判别器网络最后的Sigmoid层,模型的稳定性得到提高.
3 实验及结果分析
3.1 数据集
选择常用的DIV2K数据集[20]进行训练和验证,该数据集由1 000幅图像组成,其中800幅用作训练集,测试集和验证集各包含100张图像.然后再选择4个通用的基准数据集Set5[21]、Set14[22]、BSD100[23]和Urban100[24]进行测试.这些数据集包含了不同的图像内容,Set5中的图像来自婴儿、蝴蝶、鸟、头部和女人,Set14中图像内容主要包括斑马、花朵、喜剧演员、蔬菜和桥等,BSD100数据集图片数量多,内容也比较丰富,包括飞机、花瓶、赛车、人物和动物等,Urban100数据集主要是来自各种类型的城市建筑.因此,这些数据集既包含了自然景观,又包含了人造景物,可以综合有效地测试模型的性能.
3.2 实验设置
实验基于PyTorch深度学习平台完成,硬件环境主要由1块GTX 1080Ti显卡支持,主机内存16 GB.在模型训练过程中,使用RMSProp算法进行优化,学习率初始值设为0.000 1,迭代总次数为1 000,每次迭代的批大小为8.随着迭代训练的进行调整学习率,让学习率适当衰减以防止训练时间过长.
评价指标采用峰值信噪比PSNR(peak signal-to-noise ratio)和结构相似性SSIM (structural similarity),这是2个最常用的图像重建质量评价客观指标.其中,PSNR度量的是两幅图像对应位置的像素级差异,其值越高表明重建图像失真越少;SSIM用来衡量图像之间的结构相似度,其值越接近于1表明重建图像越接近于原HR图像.
3.3 实验结果和比较
选择一些典型的方法进行复现,并与本模型方法相互比较.典型的方法包括插值Bicubic,深度学习模型SRCNN[3]、SRGAN[9]、ESRGAN[16]和RCAN[12].在标准数据集Set5、Set14、BSD100和Urban100上进行了实验,并使用不同的尺度因子×2、×3和×4进行比较,实验结果如表1和表2所示.
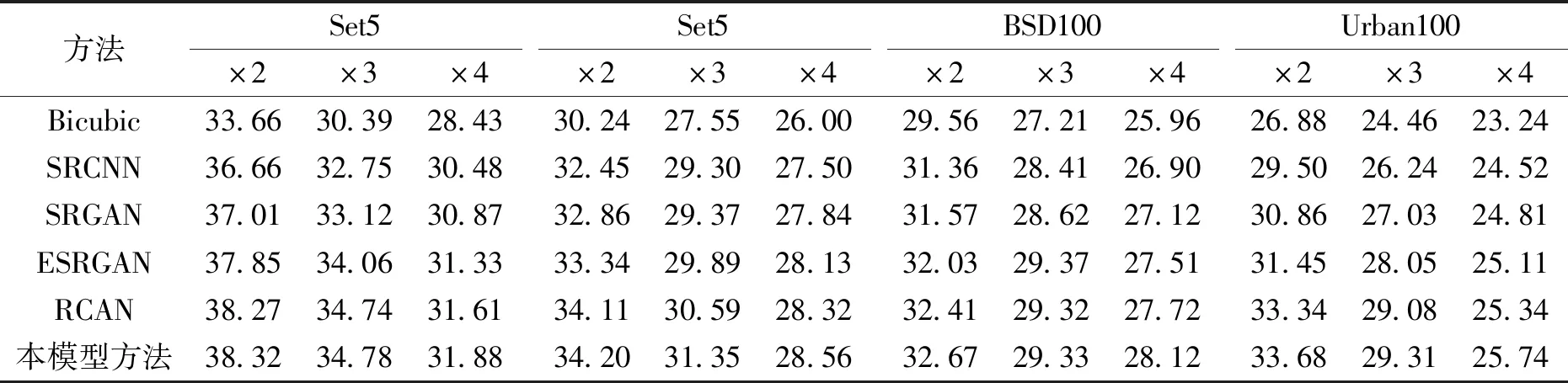
表1 本模型方法与其他算法的PSNR指标对比Tab.1 Comparison of PSNR with other methods dB
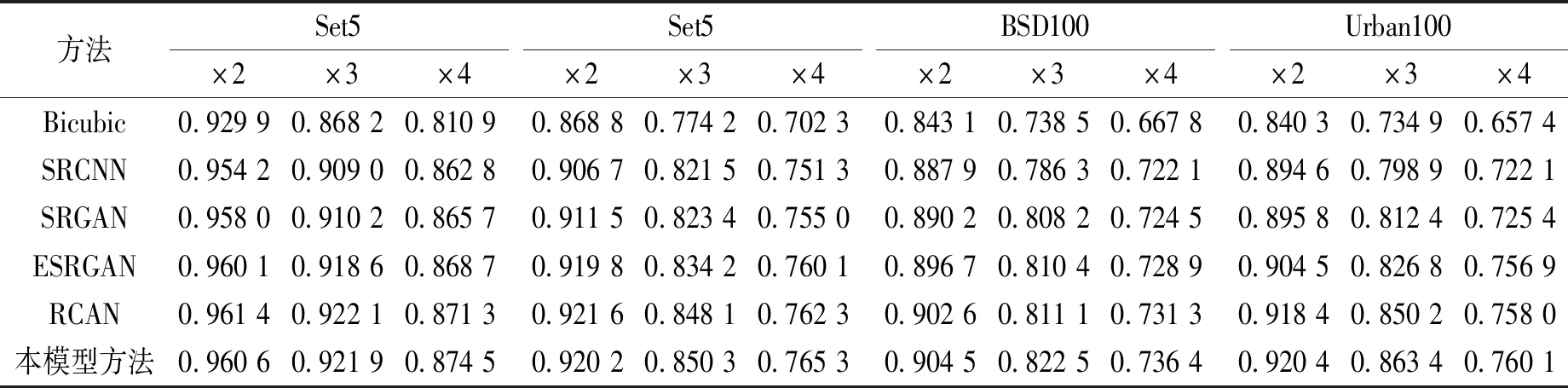
表2 本模型方法与其他算法的SSIM指标对比Tab.2 Comparison of SSIM with other methods
表1和表2分别给出了PSNR和SSIM评价指标的比较结果,可以看出,随着尺度放大因子的增加,超分辨的难度也同步增加,导致指标值呈下降趋势.在目前更多使用×4尺度因子下进行比较,本文提出的模型在PSNR和SSIM两个指标中均获得了较高的数值.与经典的SRGAN模型相比,在数据集Set5、Set14、BSD100和Urban100上PSNR分别提高了1.01、0.72、1.00、0.93 dB;SSIM分别提高了0.008 8、0.010 3、0.011 9和0.034 7.同时,在不同的数据集上本文方法的指标值都是最优,从客观评价方面说明所提出的结合双重注意力机制块的GAN模型能够生成高质量的SR图像,该模型是有效和可靠的.
为了验证本文使用的双重注意力机制对整体模型改进的有效性,进行了消融实验,实验结果如表3所示.由表3可以看出,将通道注意力和空间注意力都融入模型之后,性能比仅使用一种注意力机制得到了提升.

表3 注意力机制的有效性验证(尺度因子×4)Tab.3 Effect validation of attention mechanism (×4)
主观方面的对比效果通过在×4尺度因子下实验得到的实际重建图像进行展示,选取了来自Set14数据集的1张女孩图像、来自Urban100数据集的1张楼宇建筑图像和来自BSD100数据集的1张动物图像,分别如图5、图6和图7所示,给出了不同方法的重建结果.其中,HR表示原高分辨率图像.从图5-图7可以看出,本模型方法重建生成的SR图像主观视觉效果比较清晰,纹理细节比较丰富.Bicubic方法属于传统插值方法,重建效果最差.SRGAN和ESRGAN方法的重建效果看起来也比较模糊,细节不明显.RCAN方法的重建效果稍好一些,整体看上去比较逼真,但是和本模型方法相比,细节恢复不够完整.总体比较而言,本模型方法得到的重建图像与原图最为接近,可以说主观评价质量最优.

图5 Set14数据集示例图像重建结果比较Fig.5 Comparison of SR results from a sample image in Set14

图6 Urban100数据集示例图像重建结果比较Fig.6 Comparison of SR results from a sample image in Urban100

图7 BSD100数据集示例图像重建结果比较Fig.7 Comparison of SR results from a sample image in BSD100
4 结语
本文提出结合注意力机制的生成对抗网络模型,旨在解决图像超分辨率重建虽然客观评价指标较好,但图像主观评价较为模糊的问题.以GAN网络为基础建立图像超分辨重建模型,在生成器部分,在对输入图像的浅层特征提取之后,设计了去除BN层并将双重注意力机制块加入残差块中构成双重注意力机制块的网络结构,充分利用了图像的信息,并加深了生成网络的深度;在对抗器部分,由于原始GAN会出现训练过程不稳定的情况,因此引入Wasserstein距离来优化对抗损失,以保证算法训练的稳定性.实验结果表明,重建生成的图像在纹理细节、视觉效果等主客观评价指标上均有提升.未来的工作考虑进一步优化网络,减少网络参数量,提高网络的运行效率,使得所提出的模型能够有更大的实用价值.
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
中国外汇(2019年7期)2019-07-13
行政法论丛(2018年2期)2018-05-21
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
河南科技(2015年8期)2015-03-11
发明与创新(2015年1期)2015-02-27
