
基于卷积循环神经网络的芯片表面字符识别
2023-05-16 11:06:54熊帆陈田卞佰成刘军
浙江大学学报(工学版) 2023年5期
熊帆,陈田,卞佰成,刘军
(上海电机学院 机械学院,上海 201306)
在工业生产制造领域中,物料追踪是其中不可或缺的环节.每一块集成芯片在生产完成后,都需要进行物料流动记录,即对芯片表面上印刷的型号和序列号等信息进行提取和数据库更新.光学字符识别(optical character recognition, OCR)[1]是这项工作的技术要点.OCR可分成文本检测、文本行方向校正和文本识别3步.文本检测指的是定位到文本行字段在图片中所在的区域,即提取感兴趣区域(region of interest, ROI)[2].文本检测所提取的局部字段图像需要进行方向校正,使得转换成水平方向的图像,以便于文本识别算法的处理.文本识别是OCR的核心内容,当前文本识别算法可分为图像处理和深度学习2个分支.
通过图像处理实现字符识别主要是利用模板匹配[3],这种方法需要将字符逐个地分割出来,并事先制作各类字符固定的模板图片,分割出的单个字符图像去遍历所有的模板图像,与该单字符图像重合程度最大的模板所属字符类别被认为是该字符的种类.姚文凤等[4]通过提前建立的标准字符模板库与待识图像进行异或运算,但是无法解决形近字符的匹配问题.马欣欣等[5]在传统模板匹配的基础上,提出加权模板匹配法是对集装箱的箱号识别展开研究.采用深度学习的方法进行字符识别主要是依靠大量数据训练神经网络模型,提取图片中字符的二维形态特征和时序特征.同样是对于集装箱箱号的识别问题,白睿等[6]使用Lenet-5对行车道路场景下的字符识别进行有关实验研究.祁忠琪等[7]基于更深层次的卷积神经网络,以单个字符为单位对车牌字符设计了专门的分类模型结构.
从文本的检测问题来看,OCR按照实际应用领域可分为自然场景[8]和单一场景下的OCR.自然场景下最常见的应用实例是车牌识别[9-11].这类场景下OCR的特点是整体背景复杂和字体单一,需要相对灵活以及鲁棒性高的ROI提取方法.Naiemi等[12]使用残差网络 (residual network, ResNet)[13]完成文本行的提取,殷航[14]采用YOLOv3网络(You Only Look Once Version3)[15]与最大极值稳定区域算法来实现文本检测.
研究内容主要是面向工业生产制造场景,文本区域所处背景相对单调,理论上来说通过传统图像处理方法即可实现较好的文本区域提取效果,从而减少字符信息的整体提取时间.技术难点在于如何实现文本行字符的准确识别,在芯片表面字符印刷过程中容易出现浅蚀、油墨黑斑黏连以及生产环境污渍干扰等问题,并且各类芯片产品表面字符印刷字体多样,基于传统模板匹配进行字符识别的方法很难适应多样且不可预测的字体形式.针对芯片表面字符的识别问题,提出一种结合图像处理和深度学习技术的2阶段OCR方案,主要创新点如下:1) 基于阈值分割和仿射变换[16]实现文本行区域的提取和方向校正,提出使用积分图局部阈值分割法,大大缩短文本提取的耗时.2)基于卷积循环神经网络算法(convolutional recurrent neural network, CRNN) [17] 实现文本行图像的字符识别,在原始CRNN模型网络的基础上,分别对卷积和循环神经网络模块进行改进,同时引入中心损失函数,进一步优化模型的识别准确率和推理时间.3)针对实际的工业应用场景,提出采用多模型集成推理的方法,有效提高系统整体的识别准确率.
1 文本行检测和方向校正
1.1 积分图局部阈值分割
采用基于连通域分析的方法将字符区域以关键字段为单位从背景中分离,对工业相机采集到的原始灰度图像进行阈值分割.芯片表面的字符信息可能存在各种污渍干扰或字符印刷深浅不一,导致前景目标出现多层级灰度,给阈值分割带来困难.阈值分割按照阈值的选取方式可分为全局阈值法和局部阈值法,前者是对整幅图像选取相对固定单一的阈值,而后者是对每个像素在一定的邻域范围内求取不同的阈值,各个像素的阈值由其邻域像素的灰度值情况决定.OTSU法[18]采用前景像素与背景像素之间的类间方差最大灰度值作为该幅图像阈值,是一种常见的全局阈值分割方法,而局部阈值分割常用的邻域阈值计算方法有均值、中值和高斯加权平均等.
本研究采用基于积分图运算的局部阈值分割方法.常见的邻域阈值计算方法能够应对灰度不均情况下的阈值分割问题,不足之处是算法耗时相对较长.单通道灰度图像可看作一个由像素点构成的二维矩阵,而积分图[19]是一种对子矩阵中各元素快速求和的算法,利用积分图可以大大减少邻域阈值的计算时间.图像积分的本质其实就是求和,积分图是一种伪图像,其中每个点的值是相应原图像中该点左上角的所有像素值之和,表达式为
式中:I为积分图中某点的积分值,(x,y)为某点的位置坐标,f为灰度图像中某点的像素灰度值.
根据式(1)可反解出一定矩形区域内的灰度值之和:
式中:(x2,y2)为矩形区域右下角点的位置坐标;(x2,y1-1)为矩形区域右上角点上一格像素的位置坐标,其余位置关系类似,(x1-1,y2)为矩形区域左下角点左一格像素的位置坐标,(x1-1,y1-1)为矩形区域左上角点的左上一格像素的位置坐标.结合式(1)、(2)设定积分图的阈值分割判别规则表达式为
式中:c为所选取矩形邻域内的像素个数总和,t为可调节的常数参数.
当式(3)成立时,积分图阈值分割将二值化图像对应的像素值f(x,y)置为255,否则置为0.如图1所示,求取原图像中D区域内所有像素之和,只需利用积分图中4个伪像素值进行加减法运算.
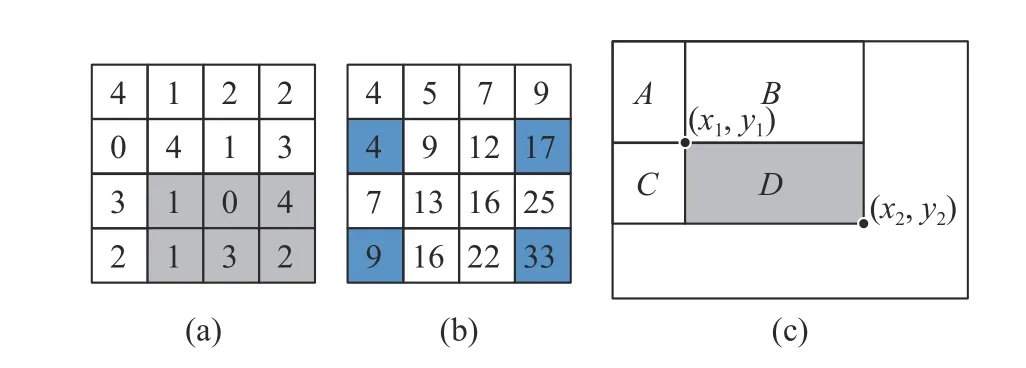
图1 积分图计算示例Fig.1 Example of integral diagram calculation
以坐标点(2,3)到(4,4)之内的区域为例,对应的实际像素之和为11=1+0+4+1+3+2,而通过式(2)计算得33-17-9+4=11.通过积分图阈值分割算法,无论选取的邻域尺寸 (x2-x1)×(y2-y1)多大,需要的运算次数都是固定的.常规计算方法需要(x2-x1)×(y2-y1)次加法,时间复杂度也会随着邻域的增大而增大.
1.2 仿射变换
采用的文本行识别算法是以仅含单行文本字段的水平图像为单位进行处理的,实际获取的芯片样品原图像中芯片放置的角度是随机的,因此需要将ROI提取出来后进行水平方向校正.仿射变换是一种二维坐标领域的线性变换,通过设置不同的仿射矩阵,可以实现图像的不同变换.通过仿射变换对各文本字段区域图像进行角度校正的表达式为
式中:u、v为经过仿射变换后的像素点坐标;a2、a1、a0、b2、b1和b0为 仿 射 矩 阵 的 各 子 元 素,各 元 素 参数值可根据需要进行设置;u′、v′为仿射变换前的坐标.
2 文本行识别
2.1 系统整体方案
在实际的应用终端,产线要求系统工作过程中的人为参与尽可能少,即需要极高的识别准确率,这就要能够保证系统的运行效能和准确性,以大幅减少系统识别出错和人工修正结果的次数,从而提升自动化程度.考虑到芯片表面字体的多样性以及产能与人力工作量的悬殊,在文本行识别阶段,提出一种基于改进 CRNN 的模型端侧训练和推理的综合方案.
文本行识别整体系统方案流程如图2所示.终端最开始部署的是预训练模型A,该模型能够应对一般情形下的字符识别,但是单一的训练模型广义的准确率难以达到实际要求,因此需要通过在线训练以得到效果更好的模型.在初始状态下,系统首先获取一张芯片样本图像,经过文本行检测后得到文本行字段图像,进而通过随机添加噪声、高斯模糊等方式实现数据增强,得到更多数量的实际样本,并加入到基础数据集中,对模型A进行微调训练得到首次训练模型B.将模型B继续投入推理工作流程,模型对每张输入的图像会输出推理结果及相应的置信度.当置信度低于一定阈值时认为该图像推理可能失误,人工进行修正后将该直接图像加入到训练模型B时使用的数据集中.当模型B推理失误的样本数据量积累到一定数量后,与上一次训练模型B时所使用的数据集共同构成新的训练数据集,用于在模型B的基础上微调训练得到2次训练模型C,从而最后可使用A、B、C这 3个模型进行综合集成推理.

图2 文本行识别整体方案流程Fig.2 Overall scheme process of text line recognition
2.2 CRNN算法基本原理
CRNN是一种将卷积神经网络(convolutional neural network, CNN)与长短期记忆神经网络(long short term memory, LSTM)[20]结合的文本行识别模型,其中CNN负责学习文本行图像的空间形态特征,LSTM负责学习上下文时间序列特征,最后LSTM的结果通过转译层输出为最后的推理结果,原始CRNN的结构如图3所示.

图3 原始CRNN结构系统Fig.3 Original CRNN structure
在原始CRNN中卷积神经网络模块的骨干网络为VGG (visual geometry group)[21]结构,在其输入将灰度图缩放到尺寸为W×32,W为宽度,即固定高为32.为了更好提取文本行图像的特征,第3个和第4个池化层采用的核尺寸为1×2,为了加速收敛引入了BatchNormalization模块.CNN的输出尺寸为 (512, 1, 40)的特征图组,每张特征图中第i个元素构成新的特征向量,即得到40个长度为512的特征向量序列,其中每个特征向量对应于原始图像中一个感受野.
循环神经网络模块采用2层各256单元的双向LSTM网络,其目标就是为了预测各个感受野对应属于的字符类别.CNN输出的特征向量序列作为LSTM的时间步输入,LSTM输出为所有字符的Softmax后验概率矩阵,该后验概率矩阵的宽度和高度分别为特征序列向量的个数和字符类别数,该后验概率矩阵将作为转译层的输入.最后转译层将各特征向量对应的预测结果转译成标签向量,每个特征向量的预测结果中筛选出置信度最高的标签向量.CRNN通过连接时序分类(connectionist temporal classification, CTC)损失函数来对CNN和LSTM进行端到端的联合训练.
2.3 改进的CRNN算法
2.3.1 CNN模块 芯片表面字符识别的应用主要在于产品型号和序列号等英文字符信息的获取,字符类别相对较少.为了进一步提高模型推理的速度,将VGG替换成MobileNet-V3[22]结构作为CNN模块的骨干网络,修改后的网络结构如表1所示.表1中卷积参数k为卷积核的尺寸,s为卷积核滑动的步长,p为特征图四边填充的宽度.与特征图的宽、高2个方向相对应,表1中卷积参数列括号中的每组值对应着卷积核横向、纵向2个参数.

表1 改进后的CNN模块结构Tab.1 Improved CNN module structure
改进后的CNN模块包括8个卷积模块组和2个卷积层,其中每个卷积模块组包含3、4个卷积层.随着神经网络层次的加深,应用非线性激活函数的成本会降低,同时减少参数量.swish类的激活函数本身具有无上界、有下界、平滑且非单调的特性,可以带来更好的效果,表达式为
式中:x为输入的网络特征张量中某一元素的值,σ(x) 为sigmoid激活函数,s wish(x)为经过swish激活函数之后的元素活性值.
h-swish激活函数是swish激活函数的一个近似拟合函数,但是去掉了sigmoid操作,计算量得以大大减少,因此MobileNet-V3结构在后半部分卷积模块中将relu激活函数替换为h-swish激活函数,表达式为
式中:x为输入的网络特征张量中某一元素的值;ReLU6 为relu激活函数的变体,当输入x>6时,导数为0;h -swish(x)为经过h-swish激活函数之后的元素活性值.
在图4中,横纵坐标分别为2种激活函数的输入值和输出值,从图中可以看出swish与h-swish激活函数的函数特性基本一致,其最大偏差值不会超过0.2,元素活性值继续经过归一化之后二者的差距几乎可以忽略.
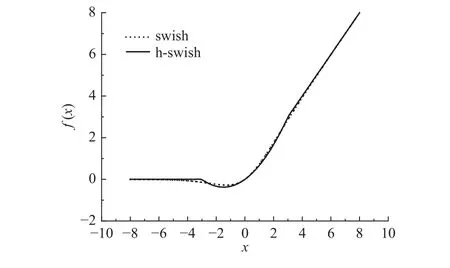
图4 swish和h-swish激活函数曲线特性Fig.4 Curve characteristics of swish and h-swish activation functions
2.3.2 LSTM模块 注意力机制(attention mechanism)[23]是对输入的权重进行分配,最开始使用注意力机制是编码器和解码器的应用, 通过对编码器所有时间步的隐藏状态做加权平均来得到下一层的输入变量.注意力机制的广义表达式为
式中:O为注意力机制的输出向量,s oftmax为归一化指数函数,Q为查询项矩阵,KT为键项的转置矩阵,V为加权平均项.
可以将注意力机制理解成一个由查询项矩阵Q和所对应的键项转置矩阵KT以及需加权平均的值 项V所构成的一层感知机.Q与KT进行相似度计算,得到权值,权值经过 s oftmax归一化之后得到可用的权重项,最后与V进行加权求和.注意力机制可以获得较长的依赖,能够使得模型对较长文本段的识别能力增强.并擅长捕捉局部与全局的关系,并且每一步的计算都是独立的,每一步的计算都不依赖于上一步的计算结果,可以实现并行加速,从而减少模型训练的收敛时间与推理时间.
在2层LSTM之间加入一层注意力机制结构,如图5所示.对于第1层LSTM的每个时间步的输出Oi,分别计算Oi其他时间步输出Oi之间的距 离di,j.从而根据时间步输出向量的距离可构成一个新的距离矩阵D,那么第2层LSTM的输入表达式为
杜思雨走进自己办公室的时候,欣竹正在屋里打扫卫生。杜思雨有个习惯,他的办公室的卫生从来都是自己打扫,而不用公司的任何一个人来打扫。欣竹发现了杜经理这两天好像不舒服,更主要的是,欣竹觉得经理好像特别喜欢她的美发。既然经理喜欢,那就让他看个够。如果是往常,杜经理会拒绝欣竹替他打扫卫生的。今天,杜经理也就没说什么。思雨坐在老板椅里,看着欣竹忙碌的身影,他又发现欣竹那天然的栗红色长发,不时耷拉到她光滑的额前,她便用手拢一拢。一注意到欣竹的长发,思雨就像条件反射似的,他下意识的摸摸装着包着那根长发丝的口袋。他的心情又沉重起来。他在心里盘算着,怎么开口向欣竹要一根长发呢?

图5 改进后的LSTM模块结构Fig.5 Improved LSTM module structure
式中:O′i为注意力机制层层的输出向量,Di为 距离矩阵D的第i行;O1至Oi分别为上一层LSTM各时间步的输出向量.
2.3.3 中心损失函数 原始CRNN中使用的CTC损失函数对于形近字可能表征不足,为了更好地扩大类间距离、缩小类内距离,提出引入中心损失函数(center loss)[24]与CTC-Loss组成新的损失函数,进行联合训练.中心损失函数的表达式为
式中:Lc为 中心损失函数计算值,cyi为第yi个类别的特征中心向量,xi为全连接层之前的特征向量,m为特征向量的个数.CTC损失函数表达式为
式中:Lctc为CTC损失函数计算值,l为目标样本类别,z为输入样本类 别,p(l|z) 为输入样本类别z属于目标样本类别l的概率值,S为所有类别标签的集合.
首先得到第2层LSTM的输出以及模型的最后预测结果,将预测结果中字符数量和标签字符数量相等的部分保留下来,并提取出相应的真实标签和对应的特征向量.将LSTM的输出特征与相应类别的特征中心计算中心损失函数值,将计算出的中心损失函数结果乘以系数 λ然后与连接时序分类损失函数求和,最终损失函数表达式为
式中:λ为可调节的比例因子.
通过引入中心损失函数,可以强化字符特征的差异,比如“0”和“O”、“6”和“G”这种形态相近的字符,使得相近字符的特征分布更加分散,从而提高分类的准确率.
2.4 集成推理
多模型集成推理的思想是即使其中某一个子模型输出错误的预测,依靠其他子模型最终也可以给出更可靠的结果.如果各子模型在不同的数据上的表达能力存在差异性,那么模型集成通过综合多个子模型的推理结果,可以实现更佳的预测.理论上来说随着系统综合子模型数量的增多,集成推理的准确率将无限接近于100%.
硬投票法假设投票最多的类别为最佳结果,即在多个模型的预测结果中出现次数最多的结果为最终结果,则将其作为模型集成的最后输出.在硬投票法的基础上,利用A、B、C这3个模型的输出结果和置信度.通过集成推理筛选出最佳结果I.多模型集成推理过程如图6所示.当3项结果的置信度均大于所设的阈值时,直接通过硬投票法选出最佳结果;当存在低于所设阈值的结果时,选出置信度值最高的结果作为最佳结果.

图6 多模型集成推理Fig.6 Multi-model integrated inference
3 实验结果分析
3.1 文本行检测
将OTSU、高斯局部阈值分割、积分图局部阈值分割3种方法进行对比测试,从图7可以看到OTSU阈值分割法在各字符印字内部灰度均匀分布的情况下分割效果较好,并且噪点最少,对于一些浅印的字符会出现前景丢失的情况.局部阈值分割能够应对图像灰度不均的情况,缺点是带来了一些噪点像素,可以通过形态学方法进行滤除.本研究采用的基于积分图运算的局部阈值分割法比高斯加权平均运算的方法噪点更少.

图7 不同算法的阈值分割效果对比Fig.7 Comparison of threshold segmentation effects of different algorithms
在效率方面,测试采集的芯片图像尺寸为762×382,3种方法的阈值分割平均时间分别为0.42、24.98和1.78 ms,可见作为全局阈值法的OTSU耗时最短,但是分割效果的鲁棒性较低.在局部阈值法中使用积分图运算的耗时比高斯加权平均运算小得多.综合来看,提出的基于积分图运算的局部阈值分割方法最佳.
3.2 方向校正
如图8所示,通过对原灰度图进行基于积分图运算的阈值分割,利用不对称的横向结构元素对得到的二值化图像进行闭操作,从而将文本行区域各字符连通起来形成整体区域块,每个区域块对应着一个字段.再从中查找轮廓,得到各文本块的位置,每个文本块对应着一个带角度的倾斜矩形,利用该矩形的中心点坐标和角度信息可以求取仿射矩阵,进而通过仿射变换将图像中的文字校正为水平方向.最后,逐个将经过方向校正的文本行图像提取出来.
3.3 文本行识别
采用ICDAR2019-LSVT数据集对改进后的CRNN进行预训练,得到预训练模型.测试数据源自实拍的20255张芯片图像,面阵相机分辨率为30万,光源采用的是同轴红光光源.实验的计算机平台环境为Windows10系统,CPU 为Intel Core i5-9500E,GPU平台为NVIDIA Quadro P1000 显卡,显存大小为4G.Python版本为3.7.4,深度学习框架为Pytorch 1.6.0.
经过文本行检测提取之后得到40510张文本字段图像,以文本字段整体为基本单位,原始的CRNN在这批实际数据上的识别准确率为67.353%.以型号信息“N002D1”为例,其中有大量的字符数字“0”被识别成字母“O”,数字“1”被识成字母“I”.改进的CRNN预训练模型在这批实际数据的识别准确率为94.831%,尚未达到产线实际要求.再使用小样本规模的芯片表面字符实拍数据集对预训练模型进行微调,通过调整小样本的数据源,最后得到3个可用的子模型进行集成推理.
模型微调使用的基础数据集为算法随机生成的62张伪文本图像,如图9所示.加入少量实际样本数据增强的图像后,共同构成实际训练模型所用的数据集.基于Adam优化器,每次训练的迭代周期为30轮,完成1次模型微调训练的时间控制在小于50 s.表2显示了6组实验测试结果,ACC为准确率,其中初次训练使用的一组文本行图像能将预训练模型微调至比较擅长该系列芯片图像及字体样本的预测,平均准确率能提高到99.872%左右,还需要二次训练再次进行微调.二次训练模型的准确率在首次训练模型的基础上略有浮动,最后将预训练模型、首次训练模型和二次训练模型进行综合集成推理,可将模型准确率提高到99.970%左右,单个文本字段的平均集成推理时间在27 ms左右,单张芯片的全阶段字符识别时间在小于60 ms以内,总体达到了产线需求.

图9 基础数据集图像Fig.9 Basic dataset images
最后一组测试的准确率比前几组有所下降,原因在于初次训练使用的样本图像中字符种类相对集中在“0”、 “1”、 “2”这几种类别,导致训练效果不佳,不过此问题可通过调整初次训练所用的样本图像数据集进行解决,使样本中所含的字符类别尽可能分散.以单模型为对象,将原始CRNN与提出的改进CRNN进行对比实验,实验结果如表3所示.

表3 CRNN各项改进的对比测试结果Tab.3 Comparative test results of CRNN improvements
在前述的40510张文本字段图像测试数据上,与原始CRNN相比,将CNN模块改进后,模型准确率提升至74.068%,单张图像平均推理时间缩短至14.58 ms.将LSTM模块改进后,相比于原始CRNN,模型准确率可提升至78.474%,平均推理时间为19.14 ms.在损失函数的改进测试中,取 λ=0.2,模型准确率A=90.751%,平均推理时间T=25.04 ms,时间基本持平于原始CRNN.
在综合3处改进后,模型准确率提升至94.831%,平均推理时间缩短至11.85 ms.可以看出引入中心损失函数对准确率带来的提升最大,提高了形近字符的分辨能力,而CNN模块的改进在提升推理效率方面产生的效果最好.
4 结语
提出的基于改进CRNN的芯片表面字符识别是一种针对工业产品物料追踪问题的OCR综合方案,具有较强的理论意义和应用价值,可以方便地部署在应用终端.作为两阶段的OCR算法,本研究利用基于积分图运算的局部阈值分割方法,有效降低了文本字段的检测时间.改进后的CRNN在效率和准确率方面都有较大的提升,引入的中心损失函数能有效解决形近字符的识别失误问题.通过在端侧的模型实时调整训练和多模型综合集成推理策略,可以保证系统的准确率和高可用性,大大节省了人工成本,同时进一步提高产能.
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
电脑爱好者(2022年15期)2022-05-30 01:29:23
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
