
基于草图的兼容性服装生成方法
2023-05-16 11:06:48曹晓璐卢富男朱翔翁立波卢书芳高飞
浙江大学学报(工学版) 2023年5期
曹晓璐,卢富男,朱翔,翁立波,卢书芳,高飞
(浙江工业大学 计算机科学与技术学院,浙江 杭州 310023)
近年来,越来越多的客户在寻找更加多样化的专属定制,尤其是服装定制.服装定制的关键技术是根据用户提供的草图轮廓、面料图案等设计元素合成相应的服装形象.现有的服装绘图软件通常要求使用者具备一定的专业经验,而且绘图过程也非常耗时,新手用户使用通用软件设计服装十分困难.因此,设计一个用户友好的交互工具来满足用户的需求,同时减轻他们的工作量具有重要意义.
自生成对抗网络[1]提出以来,图像生成的研究取得重大进步,不仅可以从随机噪声生成人脸、汽车、风景等高质量的逼真图像[2-4],还在图像到图像翻译的研究上取得显著的成果[5-6].目前在时尚领域已经有许多相关的应用,如虚拟试妆、虚拟试衣、时尚搭配、时装生成等.Zhao等[7]设计一个基于Pix2Pix的在线服装设计系统,在第1阶段输入服装关键点,生成一个中间态的补偿;在第2阶段结合草图生成一个粗糙的服装设计图像.该方法的缺点在于用户并不能控制设计图的风格,而且还要对生成的设计图进一步修改完善.Yu等[8]提出一种基于用户风格偏好的生成对抗网络(generative adversarial nets, GAN)模型,考虑到服装兼容性,输入用户查询上衣(下装)来生成符合用户品味的下装(上衣),但是用户不能控制生成服装的种类和细节.Han等[9]提出从设计稿到真实时尚单品的翻译网络(design draft to real fashion item translation network, R2Dnet),将具备丰富纹理与颜色信息的设计图合成为真实的服装图像,有效解决未对齐的设计图和真实服装之间的翻译问题,但是绘制精细的服装设计图需要一定的绘画基础,该方法对普通用户并不友好.
当前缺少一种既考虑服装兼容性,又考虑生成服装的风格和细节,且便于普通用户使用的方法,因此本研究提出一项新的时尚任务:兼容性服装图像生成.同时输入参考服装图和用户绘制的草图,参考服装用于控制生成服装的风格,草图用于控制生成服装的大致形状,并且便于普通用户操作.采用多级特征融合的方法,使得生成的服装图像与参考图像更兼容,细节也更丰富.这项生成任务可以辅助服装设计师的工作,具有较强的应用价值.
本研究主要内容如下:1)提出了一种新颖的服装生成方法,用户可同时输入草图与参考服装图像.模型基于草图内容生成与参考服装风格兼容的服装图像是现有研究未涉及的内容,具有较强的应用价值.2)构建了新的服装生成网络,包含草图编码器、参考服装编码器和1个解码器,在解码器与草图编码器之间采用了跳跃链接,以更好地保留草图特征,提高生成服装的质量.3)设计了真实性判别,使生成的服装图像趋于逼真.4)设计了兼容性判别器,使生成的服装图像与参考服装的风格兼容.5)将本研究方法与其他服装生成方法进行对比,本研究的定量指标和生成图像的质量均表现突出,验证了所提方法的有效性.
1 理论基础
1.1 图像翻译方法
经典的图像翻译方法将图像翻译至对称图像域中,对称指的是翻译前后的图像结构保持一致,是转换图像的表征形式.Isola等[3]首先提出有监督的基于条件GAN的图像到图像转换方法Pix2Pix,把U-Net网络和PatchGAN作为生成器和判别器,使用对抗损失和L1损失来训练网络,可以实现语义图-图像、卫星地图-平面地图等对称图像之间的翻译.Wang等[10]在Pix2Pix的基础上,进一步提出Pix2PixHD,利用多尺度生成器、多尺度判别器以及新的特征匹配损失函数来生成高清图像.常佳等[11]针对图像翻译中生成图像的轮廓、纹理等特征丢失问题,通过增加反卷积跳跃连接的次数,在一定程度上增强特征的表达能力.为了突破数据集的局限性,CycleGAN[5]、DiscoGAN[12]和StarGAN[13]等方法被相继提出,利用循环一致性损失,实现非对称图像之间的翻译.当源域和目标域之间存在显著空间变化时,上述方法会导致内容失真,因此XU等[14]提出最大空间扰动一致性(maximum spatial perturbation consistency, MSPC),强制空间扰动函数T和平移算子G,以对齐各种复杂的空间变化.这类方法的生成图像风格受限于训练数据并且不可控制,因此应用范围较为有限.
另一类研究着眼于生成图像的风格和多样性问题.Liu等[15]在基于草图的艺术风格翻译中,引入双遮罩机制,根据素描直接塑造特征图以保证草图内容,并且设计功能图转换,保证与参考图像的风格一致.为了实现生成图像的多样性以及生成对抗网络在多个域上的可扩展性.Choi等[16]在StarGAN的基础上提出StarGANv2,包含映射网络和样式编码器.映射网络学习将随机高斯噪声转换为风格代码.从给定的参考图像中,编码器则学习提取风格代码,可以把一张图像翻译为不同的风格,也可以翻译到多个域中.Richardson等[17]提出pSp图像翻译框架,把图像通过编码器映射到一个扩展的潜在空间中,不要求输入图像在StyleGAN域中进行特征表示,可以处理各种任务.Zhang等[18]提出基于示例的图像翻译方法Cocos-Net,该方法以包含风格的示例作为颜色及纹理的指导.在非对称的翻译中,利用跨域对齐网络在中间域上找到输入图像和示例的匹配关系,再利用多层卷积和扭曲的示例图像逐步生成高质量的目标域图像.Zhou等[19]提出CoCosNetv2,通过门控循环单元(gated recurrent unit, GRU)辅助的Patch Match方法生成高分辨率图像.这些方法并不适用于处理具有较大跨域结构变化的兼容性图像生成任务.
1.2 时尚兼容性研究
研究人员[20-25]探索各种方式来对时尚服装之间的兼容性建模.Vasileva等[20]提出学习类型感知嵌入以进行兼容性预测.Han等[21]将一整套服装视为一个有序序列,训练一个双向LSTM模型,以在前一件服装的基础上,顺序预测下一件服装.Lin等[25]提出一种基于类别且只依赖于项目类别的注意选择机制,该机制能够进行可伸缩的索引和搜索套装中缺失的服饰,并提出一个新的装备排名损失函数,提高兼容性预测和检索的准确性.上述的研究工作都集中于对已存在的时尚服装项目之间的兼容性关系进行建模.Yu等[8]从历史数据(如购买记录)中获取的特征向量来表示用户偏好,生成基于用户偏好的个性化服装设计,该方法是从历史数据来表示用户个性化的操作,具备高复杂性和弱时效性.Liu等[26]提出相容矩阵正则化生成对抗网络(compatibility matrix regularized gan, CMR-GAN),对于用户提供的描述条件做兼容性服装的推荐.与传统的推荐系统不同,CMRGAN进行基于多模态嵌入和兼容性学习的时尚生成研究.从给定输入的服装图像生成兼容服装,而不是在候选集合中检索兼容服装图像.在训练过程中,不仅需要输入与对应服装兼容的服装图像,还要输入与之不兼容的服装图像,训练成本较高.DONG等[27]提出兼容性穿搭框架TryonCM2,采用双向长短期记忆网络(LSTM)来捕捉试穿外观中的上下文结构,将时尚单品交互中的时尚兼容性与试穿外观相结合,作为最终的兼容性穿搭.LSTM的计算量较大,不易于训练,在本研究提出的兼容性服装生成任务中,只需要考虑与参考服装之间的兼容性而不需要考虑时尚单品序列组合.
2 研究方法
本研究提出的兼容性服装生成任务是指在给定参考服装Ir和用户绘制的草图Is的情况下,生 成与草图一致、与参考服装兼容的服装图像If.需要满足3个要求:1)真实性.生成服装在视觉效果上逼真;2)一致性.生成服装的形状和细节应当忠于草图的描述;3)兼容性.生成服装应当与输入的参考服装互相兼容.真实性保证所生成图像带给用户的参考价值;一致性则保证用户对生成图像轮廓需求的满足,应尽量的接近草图所涵盖的视觉轮廓需求; 兼容性不仅满足用户对生成服装风格的需求,也使得生成服装与参考服装形成较为和谐的视觉搭配效果,更具有应用价值.所提方法分别使用真实性判别器、条件跳跃连接 (conditional skip connection,CSC)[28]模块和兼容性判别器来满足这3个要求.
如图1所示,所提框架包括3个模块:生成器模块、真实性判别器和兼容性判别器.生成器模块 包括编码器Ec和Es、解码器D.由真实服装图像Igt得到对应的草图后,输入编码器Ec来提取草图的多尺度特征,Es则接受参考服装来提取参考图像的高级风格特征,利用解码器结合2个编码器的编码结果,合成所需的服装图像.真实性判别器Dc从全局角度判断输入服装是生成器合成的还是真实的,负责引导生成器生成逼真的服装图像.兼容性判别器Ds是在判断参考服装和生成服装之间的兼容程度,引导生成结果与参考服装兼容.训练过程由6个损失函数引导,分别为图像重建损失Lrec、感知损失Lperc、风格损失Lstyle、边缘损失Ledge以及真实性判别器损失Ladv和兼容性判别器 损失Lcom.

图1 基于草图的兼容性服装生成网络架构图Fig.1 Framework of sketch-based compatible clothing image generation network
2.1 生成器模块
如图2所示,在生成器模块中,本研究采用经典的编码器-解码器的网络体系结构来合成服装图像,具体生成细节如下.
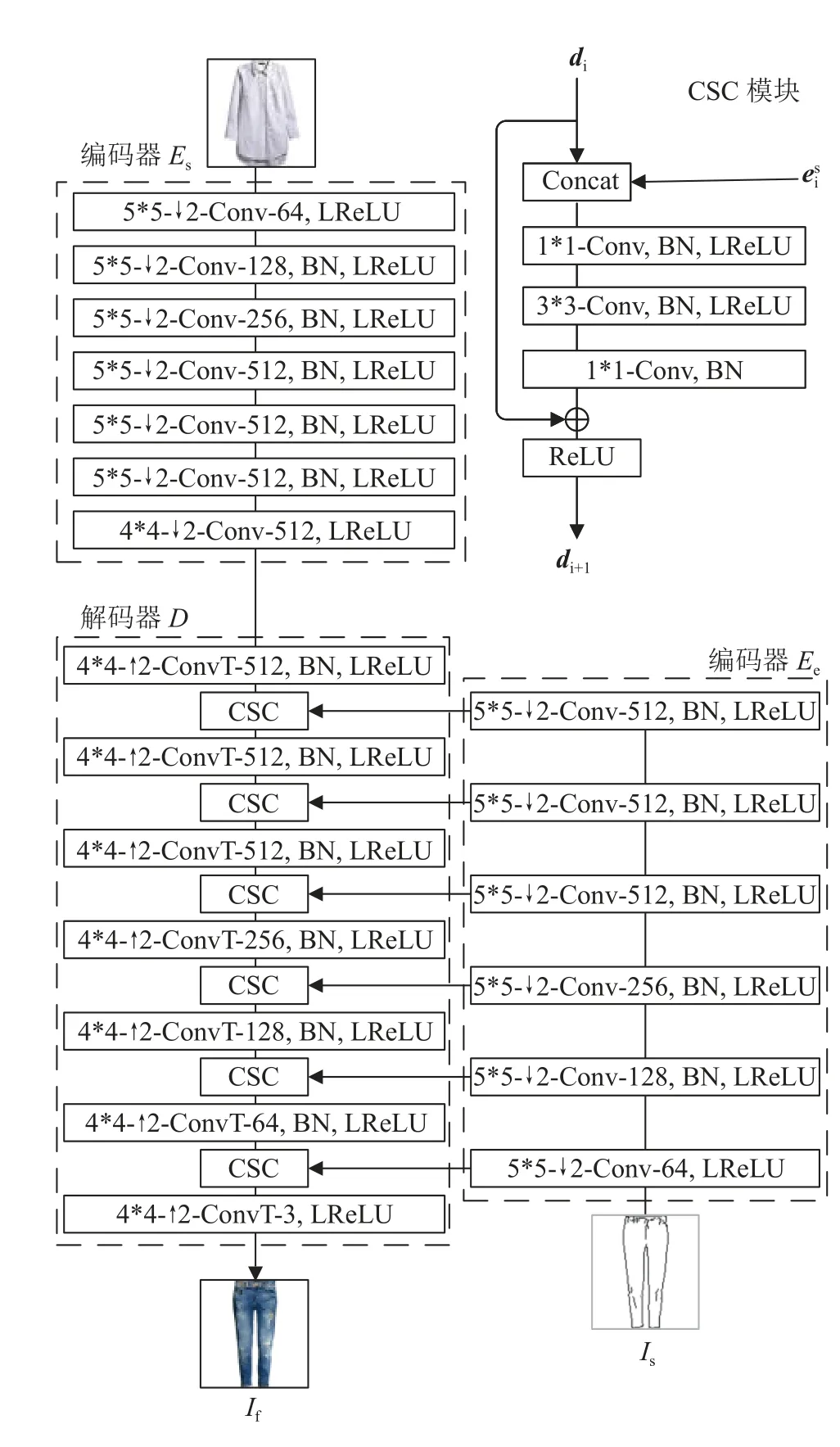
图2 生成器网络架构Fig.2 Network architecture of generator
在编码器Es中,输入参考图像经过多个卷积层进行特征下采样,直到压缩为一个高级图像特征表示特征的尺寸是通道数为512,高和宽均为1.编码器Ec也同样经过多个卷积层提取多尺度的草图特征.在解码器中,输入编码器Es提取的高级图像特征并不断结合编码器Ec提取的多尺度草图特征,通过连续的上采样来合成服装图像.
与合成随机内容相比,草图引导的服装图像合成给生成器带来额外的挑战.精细的局部形状信息会随着编码器网络深度的增加而褪化,从而导致生成器产生模糊或变形的结果.在某些极端情况下,生成的内容甚至可能会完全丢失草图中的细节信息,如服装上的图案形状,导致生成的服装与用户的草图不完全匹配.为了确保合成的服装图像与草图保持一致,强化草图特征在网络中的传播,本研究引入CSC模块.将草图作为约束条件参与每个解码过程,强化草图的边缘与细节信息,可以有效地帮助生成器“记住”预期形状的信息,达到合成服装和草图样式完全匹配的目的.CSC模块融合残差网络和U-Net的优点,包含短跳跃连接和长跳跃连接.短跳跃连接解决了梯度消失的问题,增加网络深度,提升模型性能.来自Es中的长跳跃连接加强对应的网络层间的特征传播,提高各个尺度草图特征的可重用性,有效地提高边缘与细节的一致性.
如图2所示,将编码器Ec对应的第i层特征eci跳跃连接至解码器,与解码器的第i个卷积层的输出特征di一同输入到CSC模块,获 得 第i+1层特征表示为di+1.在CSC模 块 中,先将di和eci在 通道上级联,然后依次通过3个卷积核尺寸1*1、3*3、1*1的卷积层,以获得维度与di相 同 的 新 特 征,最后残差连接把新特征和di相加,获得最终输出di+1,具体定义为
式中:f(·)为特征向量在通道维度上的级联运算,C1为 1 *1卷 积 联 合 批 量 归 一 化(batch normalization)和 ReLU激活函数,C3为 3 *3卷积.
2.2 判别器模块
此前研究[29]表明,使用多个判别器可以减轻GAN训练中的模型崩溃问题.本研究的任务需要同时满足真实性和兼容性的要求.基于以上观察,设计了2个判别器:真实性判别器(Dadv)和兼容性判别器(Dcom).
Dadv负责生成图像的视觉质量,确保每张生成的图像趋近真实的图像.具体结构如图3(a)所示,Dadv由多个卷积层组成,以真实服装或生成服装作为 输入,最后输出真实性得分Sf或Sgt.Dadv的目标函数为
Dcom负责鉴别生成的服装图像和参考图像之间是否具备高度兼容性.Dcom对用户参考图像的风格进行评估,指导生成器的训练,使得生成器所合成的服装图像与参考图像兼容.如图3(b)所示,Dcom由F和M这2个部分组成,F是一个5层卷积网络,M是一个由自适应平均池化和Sigmoid激活函数组成的度量网络.F以上下装组合为输入,经过5层卷积网络后转换为一维潜在表示:
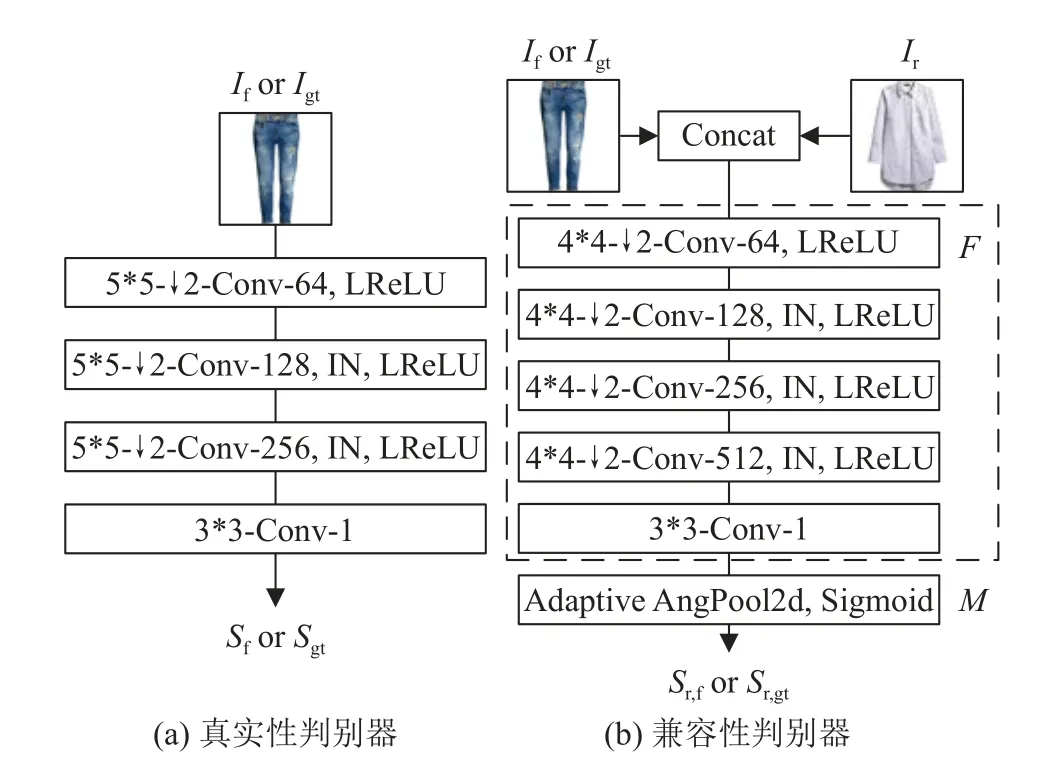
图3 判别器网络架构Fig.3 Network architecture of discriminators
式中:zo为参考服装和生成服装整体的潜在空间表示,将它输入到M中,获取最终的兼容性得分;
同理,得到参考图像和真实服装图像的兼容性得 分 为Sr,gt.通 过 优 化 生 成 网 络G和 兼 容 性 判 别 器Dcom,来实现Sr,f≈Sr,gt的目标.Dcom的目标函数为:
2.3 损失函数
优化真实性判别器的损失函数使得生成的服装看起来更加的真实,对于时尚服装合成的任务来说,还希望生成的服装和真实服装尽可能的一致.L1损失也称为最小绝对值误差,是目标值与估计值绝对差值的总和,L2损失也称为最小平方误差,是目标值与估计值差值的平方和.文献[3]表明,对于GAN的训练,比起L2损失,使用L1损失能减少模糊的生成结果,因此,本研究使用L1损失来计算生成的服装和真实服装之间的图像重建损失:
式中:‖·‖1为L1损失.
引入感知损失和风格损失[1].使用预先训练好的VGG16[30]分别计算生成服装和真实服装的激活特征图,然后计算两者之间的L1距离.感知损失表示为
式中:φi为预先训练完成的VGG16的第i层的特征图.
通过优化感知损失函数,生成服装图像和真实服装图像可以在特征空间上保持一致性.风格损失有助于生成服装在颜色、纹理等特征上与真实服装保持一致.风格损失计算激活特征图之间的统计误差为
为了保证生成图像与草图之间的一致性,引入边缘损失以最小化生成服装图像和真实服装图像的边缘信息距离:
式中:H ED(·)为与训练的边缘图提取网络[31].模型的整体损失函数如下所示:
式中:λ1、 λ2、 λ3、 λ4和 λ5分 别为损失对应的权重.
3 实验与结果
3.1 实验设置
3.1.1 数据集 FashionVC数据集是由Song等[32]在Polyvore网站上,收集时尚专家创建的成对服装构建而成,包含14871件上衣和13663件下裤,混合搭配获得20726套成对服装.其中2000套服装作为测试数据集,其余为训练数据,图像的分辨率为128×128.服装草图使用Canny边缘检测算法[33]获得,检测得到的草图内部线条有些凌乱.考虑到这个方法面向的是普通用户,而不是专业的服装设计师,因此这些在可以接受的范围内.
3.1.2 实验细节 实验的硬件配置为一块NVIDIA GTX 2080Ti显卡,软件配置为Ubuntu18.04系统、Pytorch深度学习框架.生成器和判别器均使用Adam优化器[34]进行优化,学习率设为0.0002,损失 函 数 的 权 重 参 数 λ1、λ2、λ3、λ4和λ5分 别 设 置 为1.0、100.0、0.5、1000.0和10.0,批处理大小为16,训练为200个周期.本实验所对比的其他方法在相同环境和数据集上训练,训练参数与原方法公布的参数相同.
3.1.3 评估指标 实验选择3个指标用于评估所提出的方法,分别是输入延迟(fréchet inception distance, FID)[35]、Inception指标(inception score,IS)[36]和结构相似性指标(structural similarity index,SSIM Index)[37].FID用于测量生成图像的深度特征分布与真实图像的深度特征分布之间的偏差,使用Inception-V3网络[38]提取2048 d特征,然后计算统计距离来评估生成模型.FID值越小代表2个图像分布越接近.IS是基于生成图像的分类分布和每个类的平均概率之间的KL散度来定义的,用来衡量生成图像质量和多样性.KL散度是2个分布之间距离的度量,KL散度越大,即IS值越大,生成模型的效果越好.SSIM结构相似性也是一种全参考的图像质量评价指标,它分别从亮度、对比度和结构3个方面度量2幅图像的相似性.SSIM值越大越好,最大达到1.0.
3.2 实验分析
为了验证本研究方法的有效性,与传统图像翻译方法Pix2Pix[3]、CycleGAN[5]和DiscoGAN[12],基于示例的图像翻译方法CocosNet[18]和Cocos-Net v2[19],服装图像翻译方法Anime2Clothing[39]进行定量比较.为了保证对比实验的公平,对于Pix2Pix、CycleGAN、DiscoGAN和Anime2Clothing的输入为参考服装和草稿图像级联.
定量实验:表1中加粗字体为每列最优值.从表1可以看出,在FID、IS这2项测试中,本研究方法的性能优于其他所有方法,这说明所提方法很好地确保了生成服装的真实性和多样性.在SSIM指标中,本研究方法并不是最优结果,但是与最优结果Pix2Pix非常接近.实验结果表明本研究方法图像在整体感知上,更接近实际的真实图像.
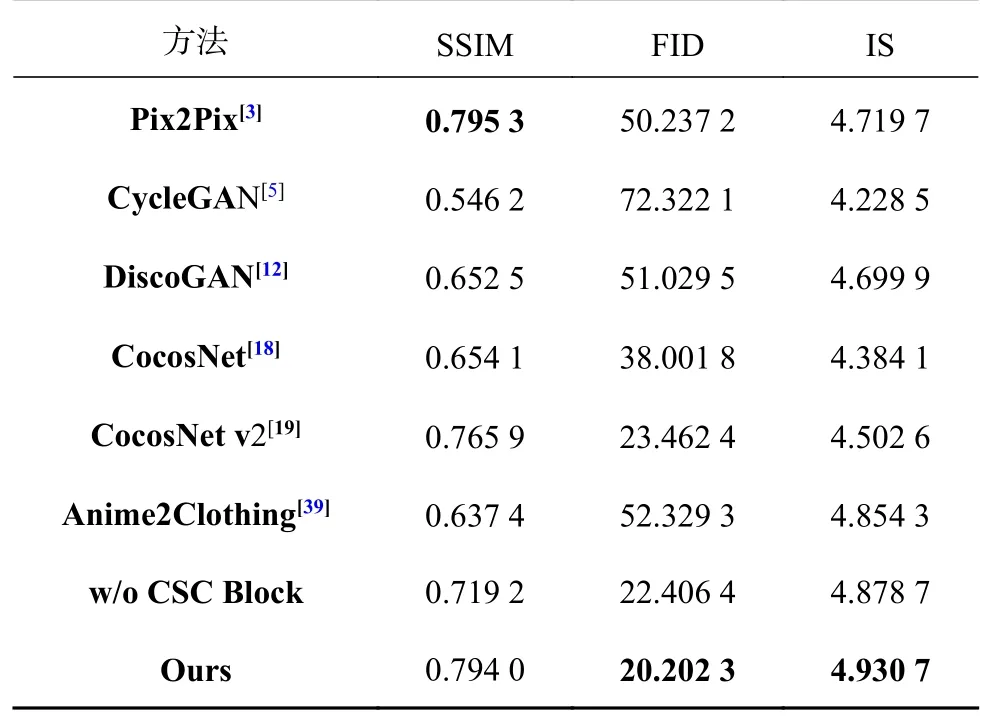
表1 不同方法生成图像的3个指标之间的对比Tab.1 Comparison of three indicators of generated images of different methods
消融实验:为了验证CSC模块的有效性,使用简单的跳跃连接来代替CSC,在相同的条件下进行实验,结果如表1中倒数第2行所示,可以看出CSC提升了网络在3个指标上的表现,尤其是SSIM,原因在于草图中的结构特征在网络传播过程中得到了强化.
主观评价:为了验证生成服装图像的真实性和兼容性,进行人工评估实验.随机选择8组结果,每组包含来自7种方法的结果.150名实验参与者被要求从中分别选择真实性和兼容性最佳的3组结果.评价结果如表2所示,使用百分比来表示用户的选择率,本研究的结果获得了最多的用户选择,表明图像真实性更高,与参考服装的兼容性效果更好.
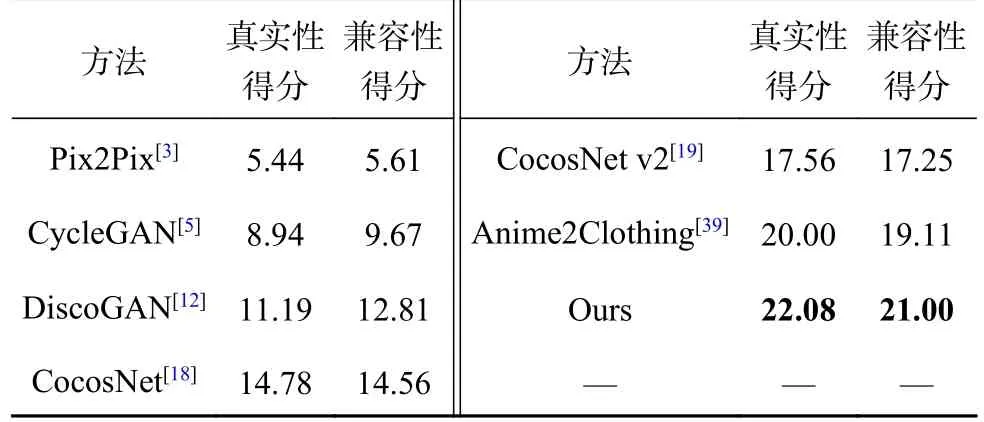
表2 图像真实性与兼容性的主观评估实验结果Tab.2 User study on authenticity and compatibility
定性实验1:图4显示各个方法的定性实验结果.从2、3、5行可以看出,对于纹理简单和颜色单一的服装,所提方法和其他方法生成的视觉结果相当.从4、7、8行可以看出,对于草图较复杂的服装而言,所提方法比其它方法的纹理和细节更真实.在服装的外形上,所提方法比CycleGAN和DiscoGAN更贴近草图.在服装细节上,所提方法比其他方法的视觉伪影更少, 原因在于草图编码特征与生成器之间的条件跳跃连接使得草图的纹理细节被较好地保留了下来.与此同时,生成图像与相应的真实服装在整体上更加的相似,与参考服装在视觉风格上也更加兼容.由于在生成器中逐步的上采样过程使得生成的图像可以平缓的增长分辨率,保证了最终图像的质量,使得与真实图像十分接近.生成器是在从参考图像提取高级特征的基础上进行生成的,很好地继承了参考图像的风格特征,而且单独应用了一个兼容性判别器,保证了更好的兼容效果.

图4 同一输入下的不同方法生成图像的对比结果Fig.4 Comparison results of images generated by different methods under same input
定性实验2:本研究可以根据用户需求合成多样化的服装,通过改变草图或参考服装,控制生成服装的外形和风格.如图5所示,每个模块中左侧是固定的草图,第1行是输入服装,第2行是对应的输出服装.如图6所示,每个模块中左侧是固定的服装,第1行是输入草图,第2行是对应的输出服装.从图5和图6的结果可以看出,本研究可以从服装中学习到兼容信息,并根据兼容信息生成多样化的逼真服装图像.

图5 输入同一张草图与不同的参考服装所生成的服装图像对比Fig.5 Generated image comparison results when inputting same sketch with different reference garments
4 结语
以草图和参考服装图像作为输入,采用双编码器分别提取风格特征和内容特征.对于特征解码在解码过程中,使用条件跳跃连接把草图作为约束,强化边缘和细节信息,以保证生成图像忠于草图.采用真实性判别器和兼容性判别器,提高生成图像的质量,使得生成图像与参考图像兼容.
定量实验结果表明,在一定程度上,所提模型提高了图像生成质量;定性实验结果表明,所提方法生成图像更符合草图描述,而且可以生成多样化的结果.本研究实现了从草图到服装图像的翻译,但是生成的服装仍然遭受缺少纹理细节的困扰,今后的研究重点是开发补偿更多纹理细节的模型.
猜你喜欢
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:56
电子设计工程(2017年20期)2017-02-10 03:39:29
福建中学数学(2016年4期)2016-10-19 05:09:02
中学生理科应试(2016年2期)2016-05-30 10:48:04
电子器件(2015年5期)2015-12-29 08:42:24
新闻传播(2015年9期)2015-07-18 11:04:13
新闻传播(2015年22期)2015-07-18 11:04:06
小学生导刊(中年级)(2014年3期)2014-05-09 11:21:27
电测与仪表(2014年13期)2014-04-04 12:04:18
