
基于GAN-BiLSTM的锂电池RUL预测
2023-05-16 12:15:56汪济洲张开宇
黑龙江工业学院学报(综合版) 2023年3期
孟 春,汪济洲,彭 相,张开宇
(合肥学院 1.先进制造工程学院;2.能源材料与化工学院,安徽 合肥 230601)
锂电池因其循环使用周期长、充电速率快等优越特性,被广泛应用于民用、商用、军用等能源设备中[1]。然而,随着锂电池多次的循环使用和充放电操作,电池的剩余使用寿命不可避免地缩减,最终导致系统无法正常工作甚至可能造成安全事故[2]。若能提前预测锂电池的剩余使用寿命,并预先做出对策,势必会大大降低危险事故发生的频次,因此准确的锂电池RUL预测显得尤为重要。
目前对于锂电池RUL预测任务方法的研究主要包括基于模型的方法和基于数据驱动的方法[3-5]。其中前者需要考虑锂电池内部的复杂变化,从而建立相应的物理和数学模型,而基于数据驱动的方法采用统计学理论和机器学习方法[6],主要通过神经网络对RUL进行估算。如张浩等人[7]将容量、阻抗、温度作为输入数据,提出了基于BiLSTM的RUL预测算法,赵显赫等人[8]利用attention强化输入数据中敏感性较高的特征,将长短期记忆网络(long short-term memory, LSTM)和attention相融合,提出了基于Attention-LSTM的RUL预测模型。虽然采用数据驱动的方法只需从数据出发而无需考虑复杂的电池内部变化,但是此种方法需要大量的数据作为前提,若数据量较小则其准确率无法保证,在一些获取锂电池充放电数据较为困难的场景,若采用数据驱动的方法则准确率较低。因此如何在锂电池数据量较小的情况下,研究一种具有高准确率的RUL估计方法很有必要。
本文提出基于GAN-BiLSTM的锂电池RUL预测,在学者研究的基础上,增加了GAN模型,通过生成对抗网络扩充数据集,在样本数据量较小或数据获取较为困难的场景下,大大提高了锂电池RUL预测的准确率。与其他循环神经网络进行对比,获得了较好的实验效果,并验证了具有较低的损失,因此具有一定的实际应用价值。
1 相关方法分析
1.1 GAN
生成对抗网络由两部分组成[9],包括生成器G和判别器D,如图1所示,生成器用于生成锂电池数据,而判别器用于判断数据的真假,具体步骤如下:随机噪声z经过生成器G生成虚假的锂电池数据G(z),训练判别器D判断样本数据来源于生成数据G(z)还是真实的样本数据x,用训练好的判别器训练生成器G生成接近真实锂电池数据的样本,以求达到博弈论中的“纳什平衡”,最终生成器生成接近真实的锂电池数据以欺骗判别器,而判别器判别不出真假。

图1 GAN模型结构图
GAN模型的目标函数如式(1)所示。
V(G,D)=Ex~Pdata(x)[logD(x)]+Ez~Px{log{1-D[G(z)]}}
(1)
式(1)中:高斯随机噪声z~pz;真实数据样本x~pdata(x),分为两部分进行单独训练,优化一次生成器后再优化k次训练器,从而使各自的代价函数达到最低。
1.2 LSTM
LSTM[10]在RNN的基础上提出门控的概念,该模型由输入门,输出门,遗忘门组成。通过三个门的作用进行信息的保留以及遗忘。若在训练过程中捕捉到两个信息之间的关联性,则会通过记忆单元保留其状态信息,若未捕捉到其关联性,则选择遗忘该状态信息。并通过记忆单元对数据进行更新。基本结构如图2所示,表达式如式(2)-式(7)所示。
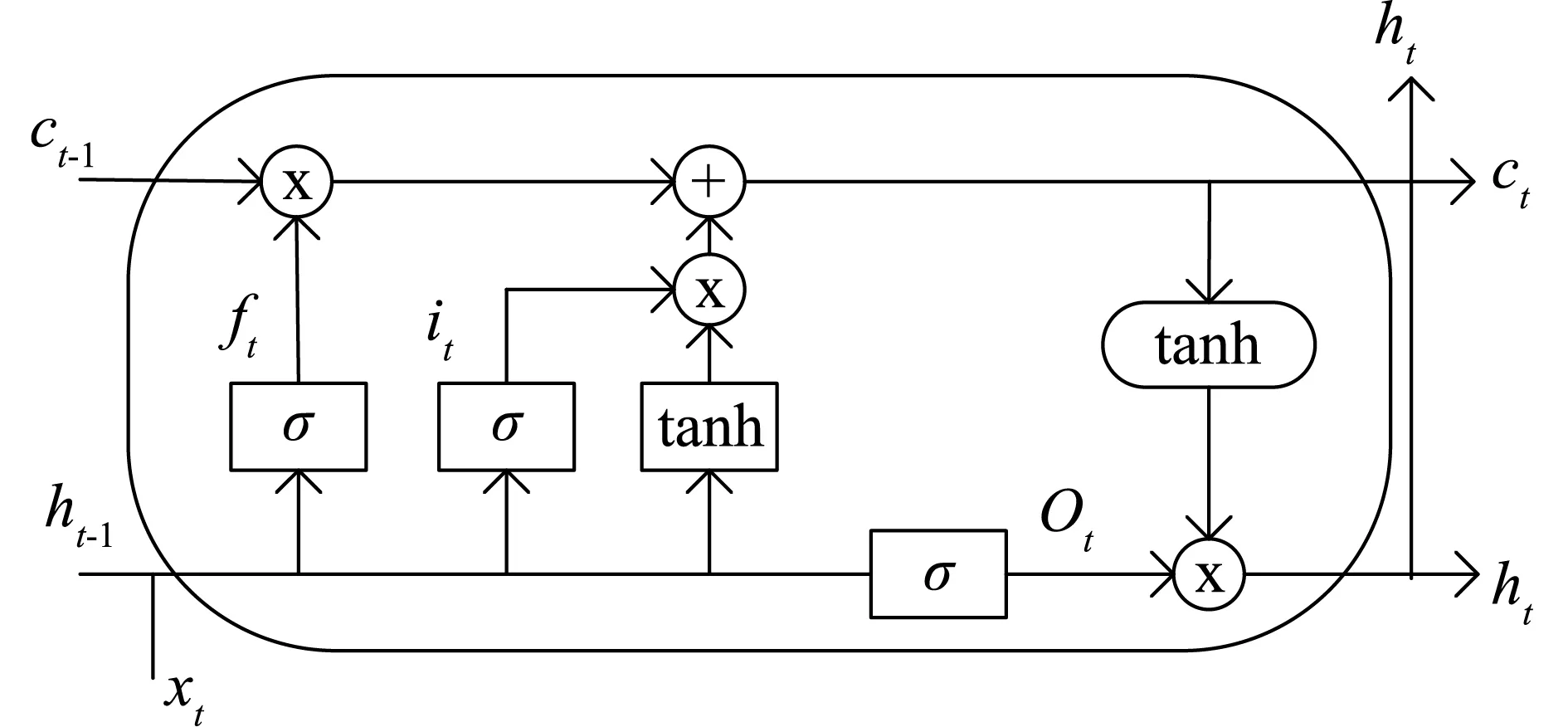
图2 LSTM结构图
(1)输入门
it=σ(Wixt+Uiht-1+bi)
(2)
式(2)中:it为输入门输出;σ为sigmoid激活函数;Wi、Ui为权重参数,ht-1为t-1时刻隐藏层输出;bi为偏重参数;xt为t时刻的输入。
(3)
(2)遗忘门
ft=σ(Wfxt+Ufht-1+bf)
(4)
式(4)中:ft为遗忘层输出;Wf、Uf为遗忘门的权重参数;bf为遗忘门的偏重参数。
(3)输出门
ot=σ(Woxt+Uoht-1+bo)
(5)
式(5)中:ot为输出门输出;Wo、Uo为输出门的权重参数;bo为输出门的偏重参数。
ht=ot·tanh(Ct)
(6)
式(6)中:ht为t时刻隐藏层的输出;Ct为t时刻内部状态。
(4)单元状态
(7)
式(7)中:Ct-1为t-1时刻内部状态,反映历史信息。
LSTM中每个神经元都通过“逐元素运算”和“激活运算”,选择和传递状态中有用的信息,但LSTM仅学习了过去状态对当前状态的影响,忽略了未来状态的作用,没有充分利用时间序列的前后依赖性关系,因此对于数据的学习能力有所欠缺。而Bi-LSTM网络能同时学习过去与未来状态对当前状态的作用,极大提高了模型对具有前后依赖关系的长序数据的学习能力,能够迅速捕捉前后数据间的细微关系。锂电池RUL预测中不仅要考虑过去数据对当前状态的影响,也需要考虑将来数据对当前状态的影响,所以必须考虑前后两个方面的状态关系。因此本文选择BiLSTM替代LSTM模型,在每一个t时刻都要进行从前往后的正向处理hL和从后往前的逆向处理hR,t时刻的BiLSTM输出为:ht=hL·hR。
2 GAN-BiLSTM模型与算法建立
锂电池的一次循环充放电数据中存在着大量的数据,由于这些数据中存在着大量的冗余信息不能直接将数据作为模型的输入,根据学者研究[11],每项数据指标中的最大值、最小值或者突变点可以更好地表征电池性能,因此本文根据锂电池的输入数据:温度、容量、电压数据,按照偏度skew,正态分布的峰度值kurtosis、最大值max、最小值min、平均值mean、标准差std进行划分数据,再加上时间t的值,得到原始数据,并划分数据集为训练集和测试集,按照SOH容量计算的方式计算每个循环次数的锂电池健康状态(state of health, SOH)值,其含义如式(8)所示,并将SOH值小于80%时的最大值作为截止SOH,而标签y即为截止SOH时对应循环次数值与当前循环次数值之差。
(8)
式(8)中:Cnow和C0分别为锂电池的当前可用容量和标称容量。
为减少异常数据的影响,加快训练过程中数据收敛,首先对数据归一化和标准化处理,标准化后的值如式(9)所示。
(9)
其中:x为样本值;x*为标准化后的值;min(·)、max(·)分别表示取最小值和取最大值。标准化操作使得所有数据位于[0,1]之间,减少了单个数据对整体的影响,并设置时间窗大小对数据进行滑动,其中窗宽度为10,时间步长为1,得到预处理后的数据。再通过GAN模型进行数据的扩充后使用BiLSTM模型进行预测,所建立的GAN-BiLSTM模型,如图3所示。
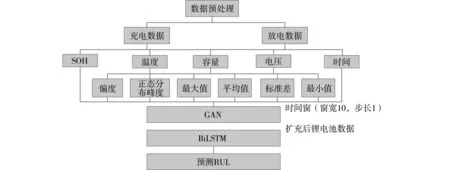
图3 基于GAN-BiLSTM的锂电池RUL预测模型图
对锂电池数据增强的GAN模型,如图4所示,为捕捉锂电池前后数据相互依赖的内部关系,生成器和判别器均采用BiLSTM模型。
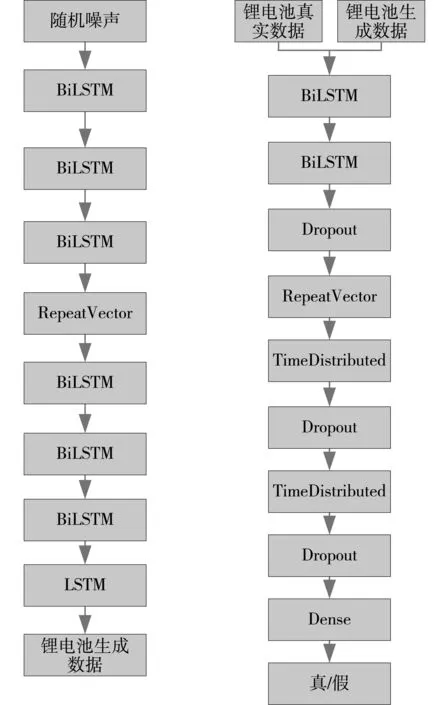
图4 生成器和判别器结构图
在生成器中,维度为(11,41)的随机噪声经过三层BiLSTM并通过RepeatVector层转换变成了(11,256)的张量,然后经过三层BiLSTM和一层LSTM后,输出(11,41)的张量,即为一组gan模型生成数据,生成器网络的BiLSTM层均采用了ReLU激活函数。
在判别器中,输入为(11,41)的张量,分为真实的锂电池数据和生成器生成的数据,经过两个BiLSTM层、一个Dropout层、一个RepeatVector层后,输出(1,256)的张量,再经过一层TimeDistributed层,一层Dropout层,输出(1,128)张量,最终输出前经过一个全连接层后得到输出值,即为判别器的判别结果,判别器的激活函数采用LeakyRelu。
实验中选择GAN模型生成的样本数量为128,原输入数据的维度为(302,11,41),经过GAN模型进行数据增强的数据维度为(128,11,41),扩充后数据量维度达到(430,11,41)。最后使用BiLSTM对锂电池此RUL进行预测。本文的模型采用了一层BiLSTM网络,前向LSTM的神经元个数是624,反向LSTM的神经元个数是416,激活函数采用Relu,损失函数采用MSE变体,优化器采用Adam,将原始数据和增强的数据一起输入到BiLSTM模型中进行训练,最后通过全连接层和relu激活函数对剩余寿命进行预测。
3 实验与结果分析
由于GAN-BiLSTM模型采用了GAN模型和基本的时间序列模型BiLSTM,为充分验证模型的先进性,通过实验与未经数据集拓展的其他时间序列模型:LSTM、GRU、BiGRU、BiLSTM进行比较,并对实验结果进行比较,验证本文提出模型的优越性。
3.1数据集介绍
本实验采用牛津大学老化实验数据集[12],电池容量740mAh的SLPB 533459H锂电池。采用恒压恒流方式进行循环充放电,共选择了cell1-cell8共8块电池进行实验,每块锂电池循环充放电次数不超过8200次,每个电池数据中包含着充电和放电的数据,每组数据中包括容量、电压、时间、温度等数据,并将其作为输入数据。
3.2 评价指标

(10)
(11)
(12)
(2)diff与0进行比较,得到是否大于0的布尔类型张量greater。
(3)将布尔类型张量greater转换为float32类型(0或者1)。
(4)将greater值加1。
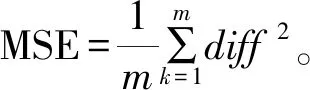
(6)计算MSE值与greater乘积:loss=MSE×greater。
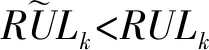

(a)MSE损失函数曲线
3.3 结果分析
五组模型在SLPB 533459H锂电池上的预测效果如图6所示,可以看出,几种模型的总体预测趋势一致,但是LSTM模型的预测曲线与实际曲线相比,始终有一定差距,这是因为使用LSTM仅考虑了单向的影响,并没有考虑到前后数据间相互依赖的关系,因此差距较大。BiLSTM、GRU、BiGRU与实际曲线较为拟合,但效果都没有加入GAN模型进行数据增强的GAN-BiLSTM模型拟合效果好。这是因为在小样本的训练中会出现过拟合或者样本数据量较小无法表征整体的情况,GAN模型的加入,解决了小样本下训练的困难,在样本量较少时,通过扩充数据集使模型泛化能力大大提高,从最初的样本个数302,扩充到430,样本数量大大提高,在样本数量充足的情况下,模型的训练效果也更好,所以曲线拟合程度也较高。
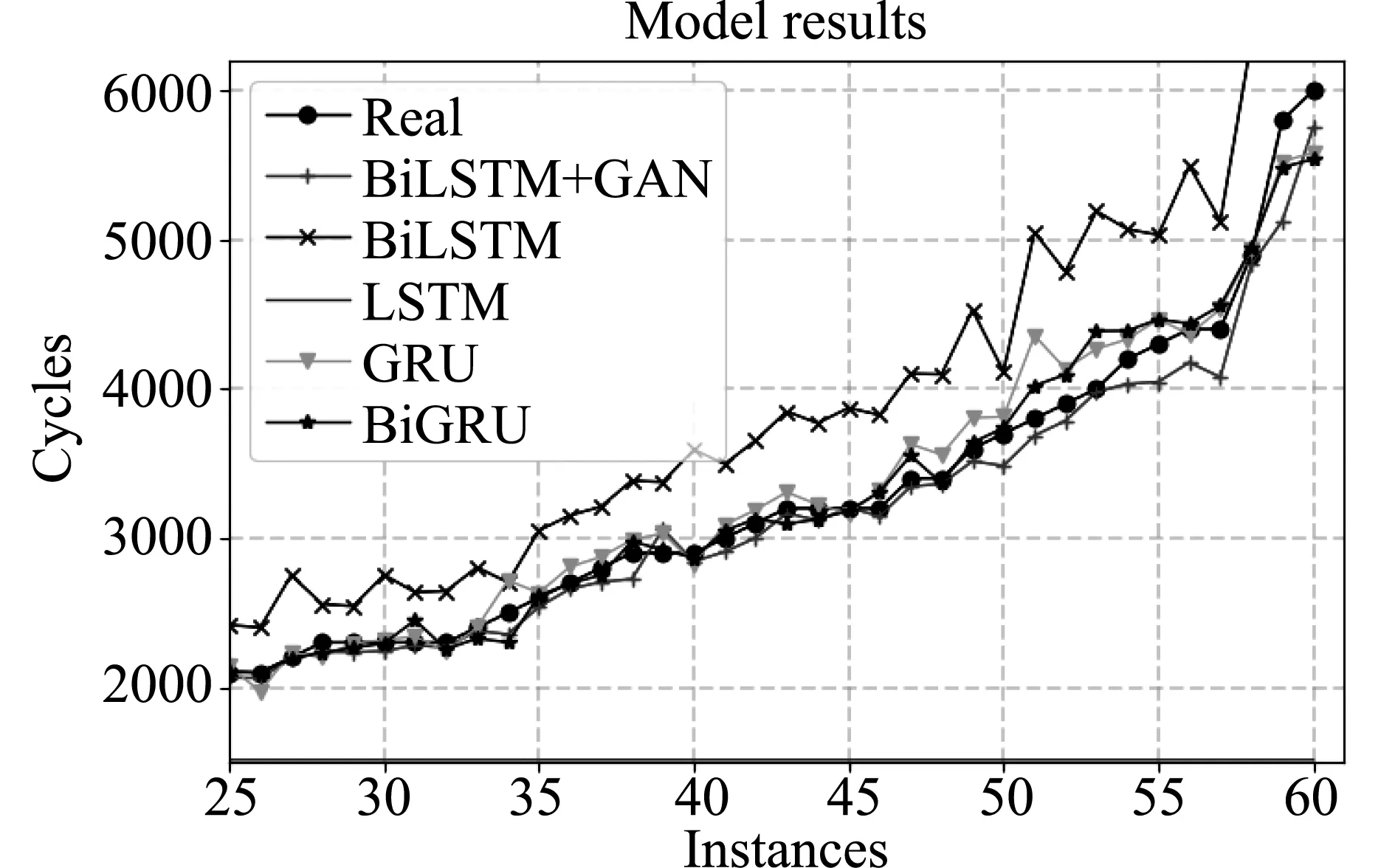
图6 模型预测比较曲线图
为了更加直观地看出各个模型的效果,根据实验结果绘制前2000个epoch的模型训练集上损失曲线图和验证集上损失曲线图,如图7所示。由图7中的结果可以直观反映出LSTM模型表现欠佳,前2000个Epoch损失未能迅速下降,而BiLSTM、GRU、BiGRU、GAN-BiLSTM曲线迅速下降,如图8所示,BiLSTM模型损失下降过程中振荡较为严重,幅度较大,一直不能达到稳定,而GAN模型的加入扩充了数据集,使得前1000个Epoch损失的振荡幅度快速下降,后趋于稳定,GAN-BiLSTM的损失值最低值达到24.1,较其他几个模型也始终最低。

图7 模型训练损失图

图8 模型训练损失图(局部放大图)
在验证集上验证时如图9所示,与在训练集上训练的趋势一致,LSTM模型的预测损失较大,且损失值较高一直不能快速下降,其验证的效果预测精度较差,局部放大后如图10所示,前500个epoch虽然BiLSTM快速震荡但后趋于稳定,并且损失值达到最低1.04,而BiLSTM模型虽然能够快速稳定但较GAN-BiLSTM而言,始终保持一定损失值。与其他模型对比表明GAN-BiLSTM在验证集上预测精度较高,即预测的RUL更接近真实值。
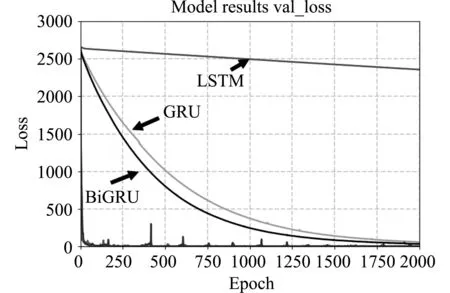
图9 模型验证损失图
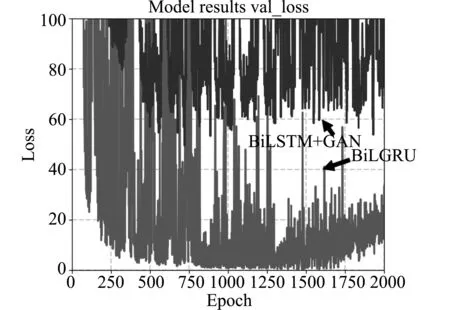
图10 模型验证损失图(局部放大图)
结语
本文提出的GAN-BiLSTM模型在小样本场景下通过GAN进行数据集的扩充,使用BiLSTM模型进行在线锂电池RUL预测,模型评估阶段采用符合实际需求的锂电池RUL预测评价指标:基于MSE变体的评价指标,并在牛津大学锂电池数据集上进行验证,通过与LSTM、GRU、BiGRU、BiLSTM模型进行对比实验,实验证明了GAN-BiLSTM在训练集和验证集上损失最低:在训练集上损失达到24.1,测试集上达到1.04。与其他时间序列模型相对比模型的泛化能力较高,因此有着更高的预测精度,即预测的锂电池RUL值更接近真实值,通过提前预测锂电池剩余循环次数,优化退役锂电池的后续处理措施,因此具有一定的工程应用价值。
猜你喜欢
数学物理学报(2021年1期)2021-03-29 03:13:38
五邑大学学报(自然科学版)(2020年4期)2020-12-09 06:28:48
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
数学物理学报(2017年5期)2017-11-23 07:51:31
山西大同大学学报(自然科学版)(2016年2期)2016-12-12 03:19:27
电源技术(2016年2期)2016-02-27 09:04:52
电源技术(2015年7期)2015-08-22 08:48:22
河南科技(2014年19期)2014-02-27 14:15:33
储能科学与技术(2014年5期)2014-02-27 07:16:12
