
基于时序Sentinel-2的河北地下水漏斗区作物单双季种植遥感监测
2023-05-12 00:49:28郑翔宇李存军孟浩然杨铁利张方娟
江苏农业科学 2023年7期
郑翔宇, 李存军, 刘 玉, 孟浩然, 杨铁利, 卢 闯, 张方娟
(1.北京市农林科学院信息技术研究中心,北京 100097; 2.辽宁科技大学土木工程学院,辽宁鞍山 114051;3.农业部农村农业遥感机理与定量遥感重点实验室,北京 100097)
作为重要粮食主产区的河北平原种植制度主要以1年2熟种植方式为主,1年1熟种植方式为辅。1年2熟作物对水资源的刚性需求,决定了小麦生育期70%~80%的水需要通过灌溉来满足,导致河北平原近年来每年地下水以1.0~1.5 m的速度下降[1-2]。研究表明,春玉米生长期与华北平原降水的时空分布耦合度最好,可基本实现生育期最小灌溉或零灌溉[3]。准确获取大区域田块尺度单双季作物种植信息对于种植结构调整、农业水资源保护和合理利用有重要价值[4]。
随着遥感大数据时代的来临,高空间分辨率的遥感数据全球陆续免费开放获取,为农业领域带来了新的选择[5-6]。遥感提取作物种植范围研究发展有近50年时间,目前农作物种植制度遥感提取的方法主要有多时序遥感数据曲线分析和遥感分类2类。多时序遥感数据曲线分析法主要依靠长时间序列光谱分析结合物候信息进行不同熟制农作物空间分布情况获取。黄翀利用中分辨率成像光谱仪(MODIS)数据获取水稻归一化植被指数(NDVI)年时间序列曲线,提取柬埔寨水稻熟制信息[7];Xiao等基于MODIS数据多源信息融合方法获得了南亚和东南亚单双季水稻农业制图,该方法多采用中、低分辨率的多光谱影像,在提取大尺度区域性农作物方面具有明显优势[8]。遥感分类方法可以通过阈值或遥感分类器获取不同种植制度农作物空间分布情况。王双等基于SPOT-5卫星数据,采用最大似然法分类的方式,对河北省三河市单季玉米和棉花进行提取[9];Son等基于哨兵2号(Sentinel-2)卫星数据采用遥感分类方法对我国台湾地区单双季水稻种植面积进行提取[10],该方法在提取精度方面具有明显优势,但由于大气、云层等因素的影响,较难获得长时序的农作物空间分布情况且计算量较大。然而,河北平原地区作物遥感检测过去多采用250 m MODIS长时间序列分析方法[11],空间分辨率低且混合像元严重,缺乏大范围田块尺度作物种植制度监测信息;如何选择合理的遥感时间序列组合减少遥感数据量以提高分类效率有待进一步研究[12]。
本研究利用10 m空间分辨率的Sentinel-2影像,提取并分析河北平原地下水漏斗区作物全年NDVI曲线,筛选分类时间节点和分类特征构建分类场景,筛选农作物关键时间节点组成最优时序特征组合,制作大范围田块尺度农作物单双季种植分类图,并分析和提出地下水漏斗区作物种植调整建议。
1 试验部分
1.1 研究区概况
研究区为河北平原地下水漏斗区。利用国家30 m数字高程模型,计算河北省南部地区的坡度值,基于坡度和高程将河北省南部平原地区提取出来作为研究区。研究区位于河北省南部(图1),地处36°40′~39°10′N,114°30′~117°00′E,研究区面积为66 020 km2。研究区内地物种类众多,分布零散,气候类型为温带大陆性季风气候,适合多种作物生长。研究区主要农作物为小麦、玉米、棉花,有少量大豆,种植制度仅包含1年1熟和1年2熟[13]。
基于中国气象数据网(http://data.cma.cn)和河北省统计局提供的中国农作物生长发育数据集,归纳总结得出研究区范围内1年1熟作物和1年2熟作物主要物候信息见图2。

1.2 数据获取与预处理
本研究基于谷歌地球引擎(google earth engine,GEE)平台获取Sentinel-2 Level-2A级产品。选取2020年10月至2021年9月的影像数据,进行作物单双季种植遥感监测。Sentinel-2影像经过拼接、裁剪、去云、波段计算和融合等预处理工作,获得Sentinel-2的耕地时间序列数据集。
2020年11月对研究区域进行实地调查和走访,共获取实地调查样本点650个,其中包括1年1熟作物地块样点309个、1年2熟作物地块样点341个,按照7 ∶3的比例将其分为训练样本和验证样本,然后将待分类场景与训练样本输入到分类器中[14]。
1.3 试验方法
1.3.1 技术路线 本研究技术路线见图3。

1.3.2 光谱和植被指数 根据研究区作物种植情况,本研究选用NDVI、增强植被指数 (enhanced vegetation index,EVI)、归一化水指数 (normalized difference water index,NDWI)、叶绿素植被指数 (green chlorophyll vegetation index,GCVI)、土壤耕作指数 (soil tillage index,STI)、差异耕作指数(normalized difference tillage index,NDTI)6种植被指数和哨兵2号数据的B3、B4、B8、B11这4个波段数据作为特征集,用于作物单双季种植遥感监测。
1.3.3 分类场景设计 本研究通过地面实测数据,结合周年卫星影像数据,对比1年1熟作物和1年2熟作物的光谱曲线,挑选出6个关键时间节点,进行作物单双季种植遥感监测最佳时相组合试验。关键时间节点分别为:3个峰值,K1:12月,K2:4—5月,K3:7—8月;1个谷值,K4:6月;2个作物不同趋势时间节点,K5:11月,K6:3月。
本研究设计9种不同时间序列特征组合的分类场景(图3)。
1.3.4 分类方法 本研究采用随机森林算法进行作物单双季种植遥感监测,并与传统的阈值法和最大似然法对比。
随机森林法是基于决策树的自学习集成式机器学习算法,运算速度快、模型稳健、泛化能力强,是农作物遥感制图的常用技术手段。
阈值法采用多时相遥感数据和HSV(色调、饱和度、明度)变化提取1年2熟作物范围[15-16],采用NDVI阈值法提取夏季作物范围并减去1年2熟范围得到1年1熟作物分布范围。将哨兵2号数据的B4、B8、B11这3个波段的数据融合,并转化为HSV(色调、饱和度、明度)数据以分离出色调(hue,H)和明度(value,V)的数据,通过小麦和非小麦地物在H-NDVI空间上的差异,采用HSV阈值法初步识别冬小麦疑似区域。
根据实测数据,采集冬季作物的NDVI和H,构建H-NDVI图(图4),可以看出研究区内冬季作物主要分布在NDVI大于0.33且H处于 100~220之间的区域,采用此阈值对其进行初步提取。

随着冬季农作物的生长发育,其色彩饱和度(saturation,S)逐渐增加,而其他地物并不会有明显的S变化或者随着气温的降低,S会略微降低,故可以采用S去除土壤等易混淆地物。根据实测数据,采集农作物与非农作物12月的S和11月的S并作差,得到的即为饱和度S的变化值,农作物S差值主要集中在0.05以上,而非农作物S差值主要集中在0以下。综上所述,提取1年2熟作物的阈值设置为NDVI>0.33,H处于100~220之间,12月和11月S差值大于0。
1年1熟作物种植范围阈值提取,通过NDVI对7—8月耕地掩膜后的影像进行提取,阈值设置为NDVI>0.45,提取结果减去1年2熟作物范围得到1年1季作物范围。
1.4 精度评价
精度评价采用构建混淆矩阵的方法,计算分类结果的制图精度(PA)、用户精度(UA)、总体精度(OA),Kappa系数和F1分数。F1分数同时兼顾了分类模型的精确率和召回率。其公式如下:
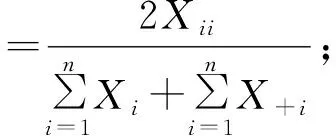
其中:N表示训练样本的个数;n表示分类类别数;i表示某一具体类别;Xjj代表混淆矩阵某一类地物正确分类的个数;X+j代表该类别真实参考总数(混淆矩阵该地物X对应列的总和);Xii代表正确分到该类的像元总数(混淆矩阵对角线值);Xi+代表整个影像分类为该地物的像元个数(混淆矩阵该地物X对应行的总和);X+i代表整个影像正确分类为该地物的像元个数;Xij代表所有像元个数;OA指在验证样本集上分类器预测正确的概率;F1分数由用户精度和制图精度计算得到,是用户精度和制图精度调和均值,用于表征模型输出的好坏,取值范围位于 0~1之间,其值越接近1表示模型输出越好;Kappa系数是检测验证样本与预测结果吻合度的指标,其值的大小通常位于0~1之间,越接近1表示吻合度越高[17]。
2 结果与分析
2.1 作物周年光谱变化曲线
本研究基于GEE遥感云平台,以月为单位组合拼接30 d内高质量影像,结合野外调查,制作的1年1熟作物和1年2熟作物NDVI变化曲线见图5。
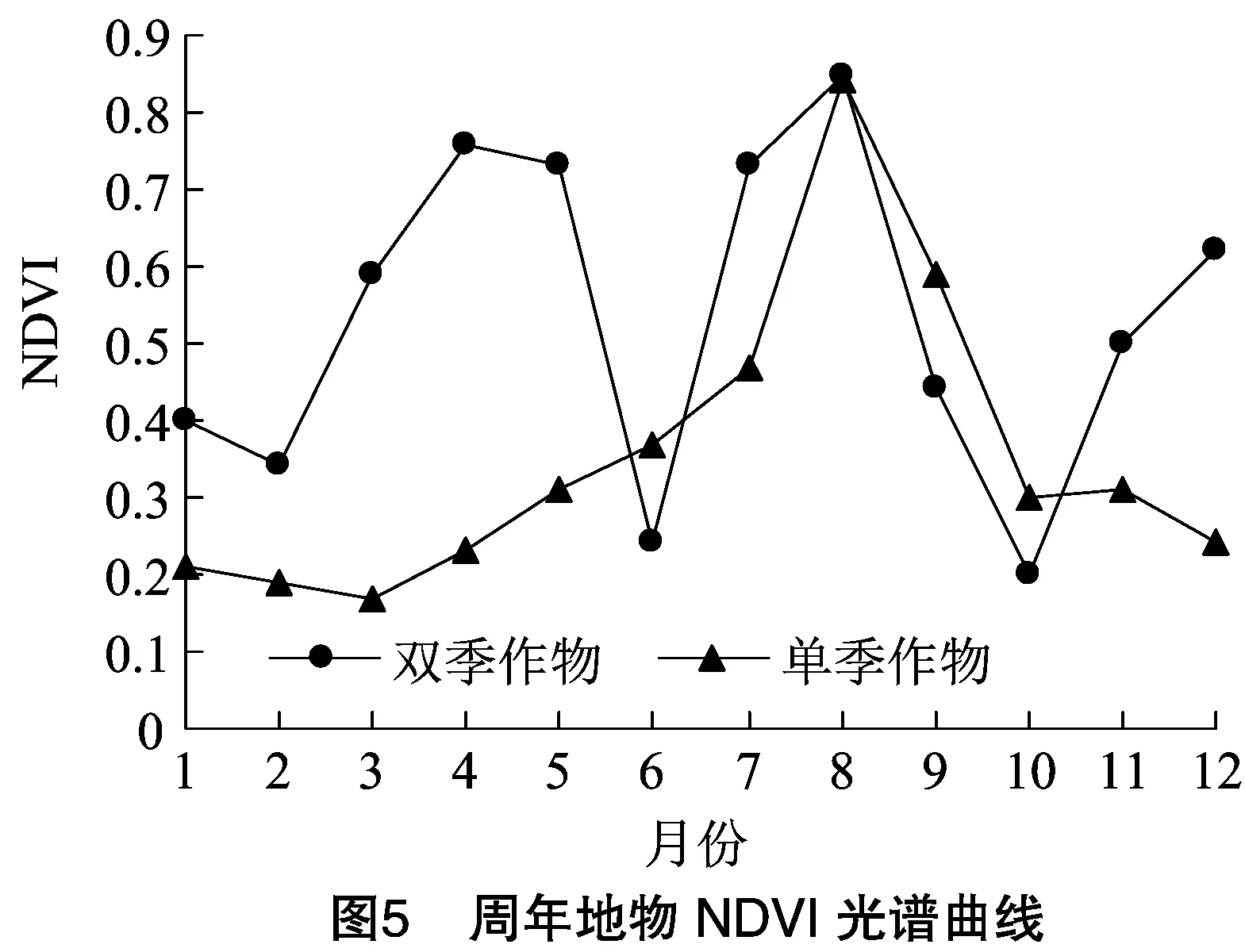
1年1熟作物(如春玉米、棉花)在4—5月开始陆续种植,NDVI开始升高,在7—8月NDVI达到顶峰后于9—10月陆续收割,NDVI迅速降低,在10月中下旬收割完成,周年NDVI光谱曲线呈单峰趋势。1年2熟作物在秋季末期开始种植,并在10—11月份迅速生长,在冬季初期(12月)形成小峰值,由于冬季雨、雪、气温降低等气候因素的影响,NDVI在1—2月有所降低,在初春时期开始继续生长发育直到4月份达到第2个小高峰。1年2熟作物在5—6月成熟和收割,并在6—7月重新种植夏季作物,故在6月呈现裸地情况,显现出NDVI光谱曲线的深谷,又在7—8月迅速生长发育,呈现出NDVI最高峰值现象。故1年2熟作物NDVI周年光谱曲线呈现1年3峰情况,与1年1熟作物有较大差别,时序遥感信息可以帮助有效区分2种种植制度。
对比2种光谱曲线,遥感监测的关键时间节点分为峰值、谷值和不同趋势时间节点3种情况,第1个峰值在12月,第2个峰值在4—5月,第3个峰值在7—8月,谷值在6月;趋势时间节点是指1年1熟作物和1年2熟作物NDVI增减趋势不同的时间节点,主要有3—4月时1年1熟作物还没开始种植,NDVI无明显变化,而1年2熟作物NDVI快速增加的时间节点;11—12月1年1熟作物已经收割完成,NDVI无明显变化,而1年2熟作物开始生长发育,NDVI开始增加。
2.2 不同时序数据组合遥感监测精度
不同时序遥感数据组合分类场景作物单双季种植监测结果见图6,其F1分数指数见表1。
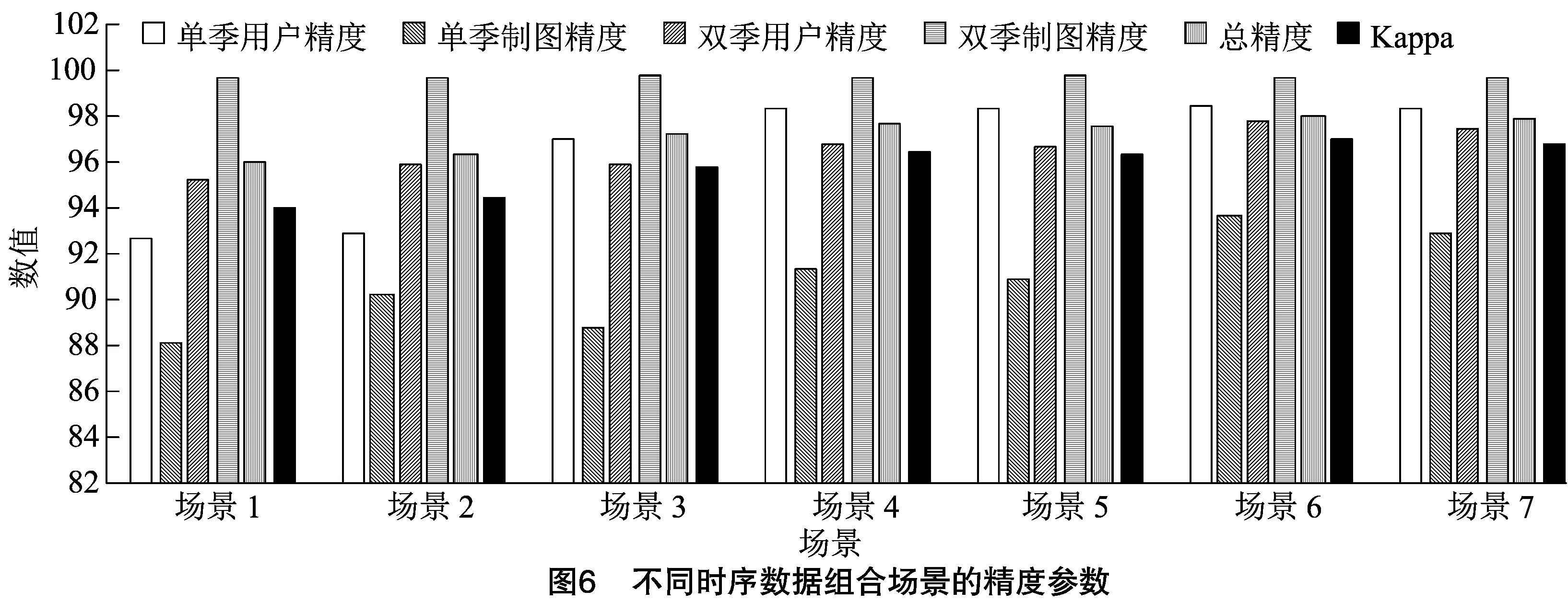

表1 不同时序数据组合场景F1分数精度评价
由图6、表1可知,区分1年1熟作物和1年2熟作物的最佳分类场景为场景6,即所有关键时间节点(8个月)组成的特征时序,该场景对1年1熟作物和1年2熟作物分类的F1分数指数都是最高的。
分析场景1~场景7(表1)可以发现,在关键时间节点峰值场景中,峰值时间序列对区分1年1熟作物和1年2熟作物具有较好的效果,3个峰值关键时间节点的精度要高于2个峰值关键时间节点(场景1~场景2)。对比谷值和2个趋势不同时间节点,其中11—12月的趋势不同关键时间节点影响较大,对区分精度的影响略高于3—4月的关键时间节点和6月的谷值时间节点(场景3~场景5)。对比所有关键时间节点时序融合影像和周年时序融合影像的区分精度(场景6~场景7),仅使用关键时间节点的时序遥感数据精度略微高于周年遥感数据精度,说明关键时间节点的时序遥感数据能明显地将2种种植制度进行区分,可能是由于研究区范围非常大,同一作物存在物候差异,且周年遥感影像数据无法做到完全无云情况,故会对区分精度产生一定的影响,导致精度下降。
2.3 不同分类方法遥感监测精度
利用传统的阈值提取方法、最大似然法与随机森林方法的作物单双季种植遥感监测结果见图7,F1得分精度见表2。其中最大似然法采用所有关键时间节点融合影像,训练集和验证集同随机森林分类场景一致。

从图7可以看出,无论是针对1年1熟作物提取还是1年2熟作物提取,随机森林算法的精度优于阈值法和最大似然法,最大似然法的区分精度次之,阈值法的区分精度最低。
通过对比不同分类方法的F1分数(表2),随机森林算法的分类精度最优,阈值法和最大似然法相对较低,这种情况是由于不同方法的分类原理所导致的。阈值法是通过对影像光谱分析和数据分析制定合理的阈值,区分不同类别,阈值的设置和光谱数据的选择都会对精度产生较大的影响;由于研究区跨度较大,研究区范围内地物种类繁多且分布不均匀,增加了通过似然度区分地物的难度,导致最大似然分类法精度较低;而随机森林算法可以在一定程度上避免一次分类错误导致的误差,且随机森林分类的多棵决策树更容易把握光谱值上的细微差异,可以获取较高精度,对区分不同耕作方式具有较好的效果。
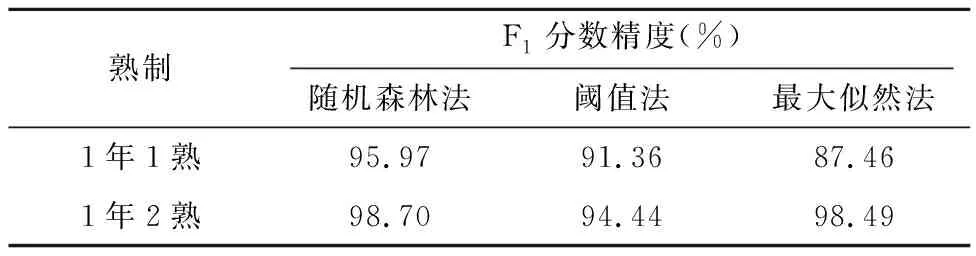
表2 3种不同分类方法F1分数精度对比
2.4 作物单双季种植监测结果
基于NDVI、EVI、NDWI、GCVI、STI、NDTI等6种植被指数和哨兵2号数据的B3、B4、B8、B11这4个波段共10个特征,结合场景6中6个关键时间节点共8个月的时序组合数据进行分类监测,获得河北平原地下水漏斗区1年1季作物和1年2季作物分布图,对研究区内2块田块进行分类细节展示,结果见图8。
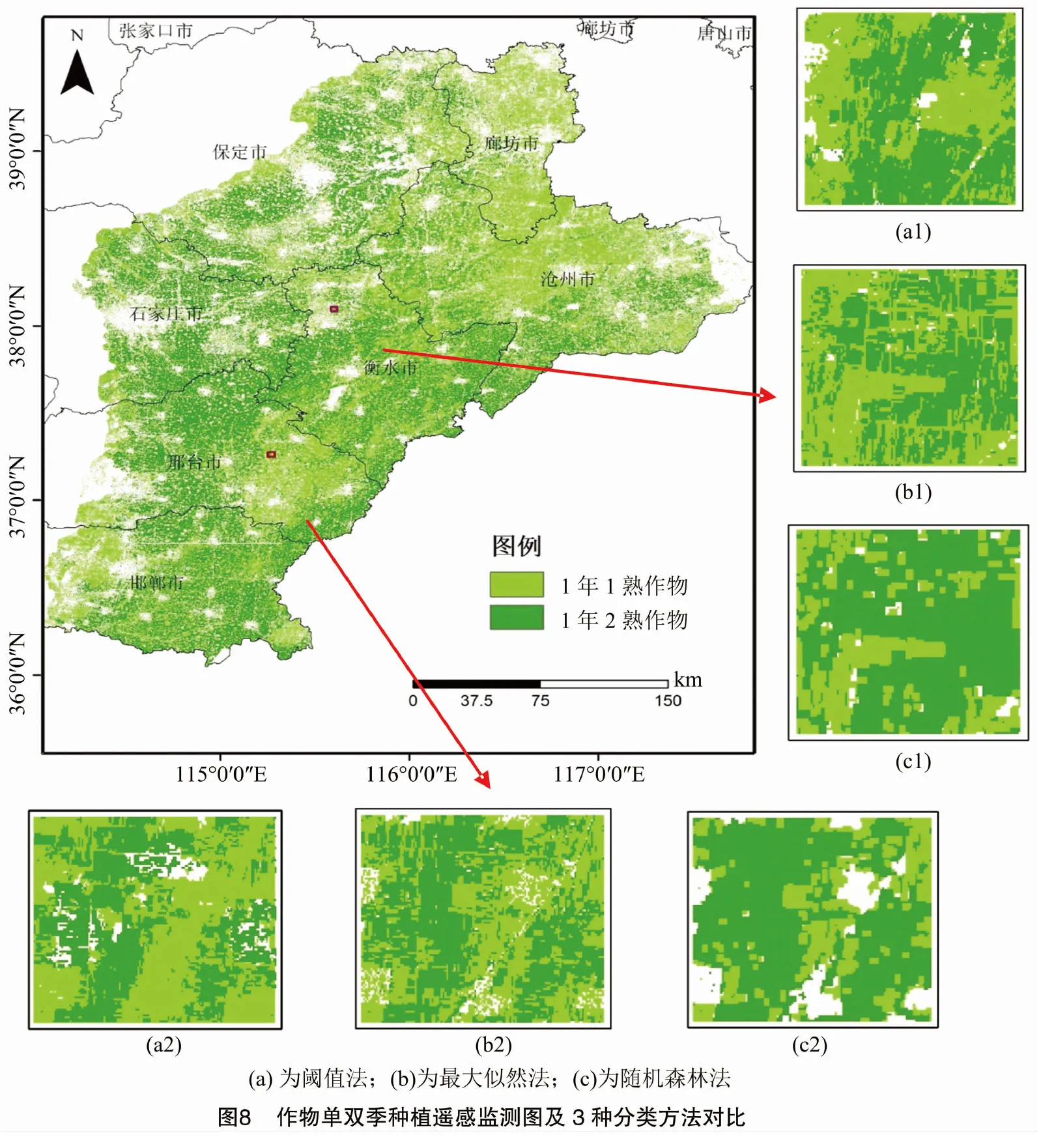
由图8可知,1年1熟作物主要分布在研究区的东北部和南部地区,其中沧州市、廊坊市、邢台市分布较多,在西部和中部也有少量分布;1年2熟作物主要集中在中部和西部大部分地区,研究区北部和东部也有少量分布;部分地区1年1熟作物种植和1年2熟作物种植并存。造成这种情况的原因可能是由于河北平原西部水资源较东部多,1年2熟作物冬季耕作以灌溉为主,需要大量地下水资源,而1年1熟作物分布与河北省地下水漏斗区域较吻合。由图8可知,随机森林算法效果最优,表现为分类后地块较为完整,地块连续性较好,漏分误分错分现象较少,能够区分出绝大部分农田;该地块范围内阈值法产生了大量的错分现象,地块较为零碎,分类效果最差;最大似然法分类结果尚可,区分出了区域内绝大多数地块,但是地块零碎,连续性较差,误分情况较多。
2.5 地下水漏斗区作物种植调整建议
为更加直观地比较不同区域单双季作物种植分布情况,结合河北省县市图,制作1年2熟作物优势度分布图(图9)。优势度是该熟制作物面积与耕地总面积的比值,可以有效描述作物在某一地区种植面积所占比例[18]。对比地下水缺水区域大致分布图(图10),提出地下水漏斗区作物种植制度调整建议,以达到减少地下水消耗的目的。
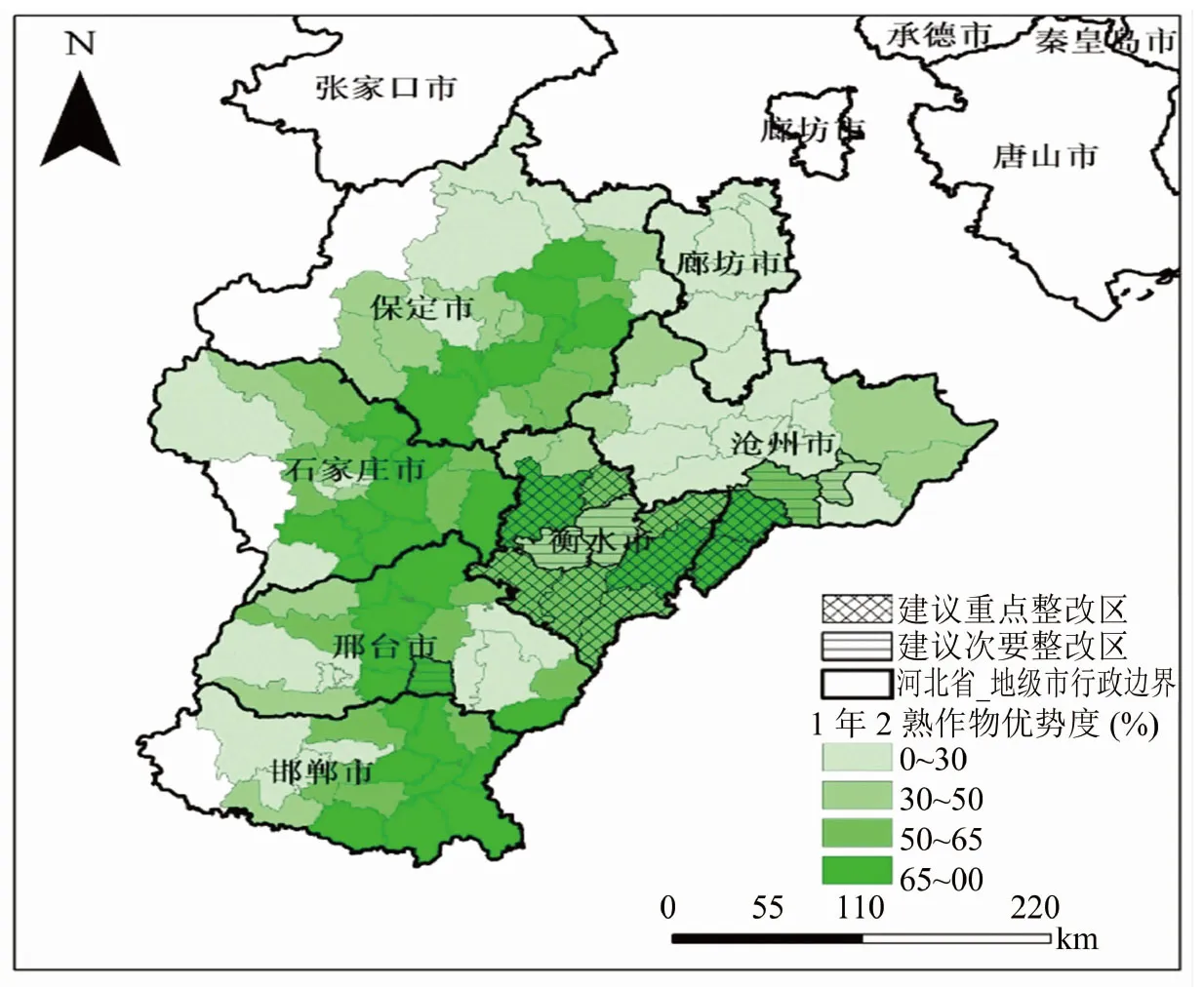

河北平原地下水漏斗区1年1熟作物种植面积占所有耕地的45.04%,1年2熟作物种植面积占所有耕地的54.96%。其中,沧州市单季作物占全市耕地的65.18%;石家庄单季作物占全市耕地的31.63%;衡水市单季作物占全市耕地面积的44.21%;保定市单季作物占全市耕地面积的47.60%;廊坊市单季作物占全市耕地面积的88.07%;邯郸市单季作物占全市耕地面积的41.75%;邢台市单季作物占全市耕地面积的42.72%。
对比10 m田块尺度单双季作物分类结果、河北平原漏斗区1年2熟作物优势度图和河北深层地下水等水埋深分布,可以看出主要地下水漏斗区作物类型以1年1熟作物为主,1年2熟作物优势度较低,但也有一些漏斗区作物类型依旧以1年2熟作物为主。图9中网格线区域(衡水部分县市)为地下水漏斗区的核心地区,但是其1年2熟作物占比较大,需要较大的农业用水,不利于地下水位的保持,建议作为重点管控区减少1年2熟作物的种植;图中横线区域(衡水、沧州、邢台部分县市)为地下水漏斗区边缘地区,且其1年2熟作物种植比例略小于网格线区域,建议作为次要管控区减少1年2熟作物的种植来保持地下水水位。
3 结论与讨论
3.1 结论
本研究基于2020年10月至2021年9月的周年哨兵2号遥感数据,通过随机森林法监测河北平原地下水漏斗区作物单双季种植情况,得到以下结论:(1)1年2熟作物和1年1熟作物周年光谱曲线之间的差异主要有6个关键时间节点,且使用6个关键时间节点(共8个月)时序数据分类效果最佳,相比全年时序数据(12个月)减少了遥感数据量、运算时间,同时取得了更高的精度。(2)用3种不同的分类方法开展作物单双季种植提取,随机森林方法精度最高,最大似然法精度次之,阈值法精度最低。采用随机森林算法和最佳时序组合,制作了河北平原地下水漏斗区10 m空间分辨率田块尺度的作物单双季种植分布图,从图中可知河北平原地下水漏斗区1年1熟作物主要分布在东北部和中南部地区,1年2熟作物主要分布在西部和中部地区。(3)对比地下水漏斗区1年2熟作物优势度图与河北平原主要地下水漏斗区域发现,地下水漏斗区多为1年1熟作物种植,但衡水大部分地区、沧州南部和邢台部分县市1年2熟作物的种植比例较多,建议减少1年2熟作物的种植面积以控制地下水资源损耗。
3.2 讨论
本研究主要针对时间序列特征对区分1年1熟作物和1年2熟作物进行分类和精度评价,虽然取得了较高的精度,但也存在可优化和待解决的问题,有待进一步提升提取精度:(1)冬季农作物植被较为稀疏,植被光谱信息与裸地易产生混淆,光谱值较为相似,对提取精度产生了影响,考虑后续可以针对提取的植被指数进行调查分析,筛选更加适合的植被指数和光谱指数进行提取。(2)1年2熟作物1年内收割和种植时间非常接近,土地空闲时间非常短,采用重访周期为5 d的哨兵2号数据且考虑云层覆盖问题,对关键时间节点的影像抓取有一定的难度,也会对区分精度产生一定的影响。(3)由于研究区面积广、东西南北有较大跨度,不同的气候条件会导致各个地区作物生长速率、耕作时间存在一定的差异,影响提取精度,后续可以考虑针对同纬度大范围农场进行调查分析以提升精度。
猜你喜欢
中国农业信息(2023年3期)2023-03-18 08:19:04
中国农业信息(2021年3期)2021-11-22 06:44:48
今日农业(2020年20期)2020-12-15 15:53:19
今日农业(2020年17期)2020-12-15 12:34:28
世界农药(2019年4期)2019-12-30 06:25:10
制造技术与机床(2019年9期)2019-09-10 07:36:54
西南交通大学学报(2018年6期)2018-12-18 02:22:28
河北遥感(2017年2期)2017-08-07 14:49:00
电子制作(2016年15期)2017-01-15 13:39:08
上海农业学报(2016年2期)2016-10-27 00:49:58
