
融合MultiHead Attention 和BiGRU 的入侵检测模型*
2023-05-12 02:25樊景威葛丽娜李登辉
计算机与数字工程 2023年1期
樊景威 葛丽娜 张 壕 李登辉
(1.广西民族大学电子信息学院 南宁 530006)(2.广西民族大学人工智能学院 南宁 530006)(3.广西民族大学网络通信工程重点实验室 南宁 530006)
1 引言
随着网络流量变得越来越庞大,网络攻击手段也变得也越来越新颖,这就对构建一个高效的入侵检测系统提出了更高的要求[1]。入侵检测系统用于检测系统的内外部入侵、潜在入侵和可疑活动的异常[2]。根据检测所用数据的来源不同,可将入侵检测系统分为三类:基于主机的入侵检测系统(Host-based Intrusion Detection System,HIDS);基于网络的入侵检测系统(Network-based Intrusion Detection System,NIDS);基于混合数据源的入侵检测系统(HIDS+NIDS)[3]。
随着机器学习技术的发展,机器学习技术被广泛用于入侵检测系统中。一些研究人员在入侵检测模型中使用k-均值算法[4]、决策树[5]、随机森林[6]和支持向量机(Support Vector Machine,SVM)[7]等机器学习算法,取得不错的效果。但是浅层机器学习的方法无法应对日益严峻的网络安全挑战,而深度学习技术在降维和分类任务方面显示出了其有效性,深度网络可以自动降低网络流量复杂度,无需人工干预就能发现数据之间的相关性,当下热门的卷积神经网络(Convolution Neural Network,CNN)[8]、循环神经网络(Recurrent Neural Network,RNN)[9]门控循环单元(Gate Recurrent Unit,GRU)已经被使用在入侵检测模型中。
GRU和LSTM都属于RNN类型的神经网络,许多研究人员把它们放在了入侵检测模型中。文献[10]使用CNN、RNN 和自动编码器(autoencoder,AE)等不同神经网络架构来构建分类模型,实验表明,CNN 和LSTM 在入侵检测的分类中表现良好。文献[11]提出在物联网领域使用GRU 进行入侵检测研究,但实验仅在KDD-Cup 99 数据上进行,未实现应用于物联网相关数据集的设想。文献[12]提出一种基于CNN 与BiGRU 融合的神经网络入侵检测模型,通过综合采样(SMOTE-Tomek)方法完成对数据集的平衡处理,将CNN 和BiGRU 模型进行特征融合并引入注意力机制进行特征提取,从而提高模型的总体检测性能。文献[13]提出一种新的特征驱动的入侵检测模型X2-BiLSTM,模型集成了X2统计模型和BiLSTM。统计模型用于特征排序,并使用最佳搜索算法搜索最优子集,BiLSTM模型对最优子集进行分类。文献[14]提出一种结合CNN 和BiGRU 的网络入侵检测模型,使用一种结合自适应合成采样的混合采样算法和逆向工程神 经 网 络(Reverse Engineering Neural Networks,RENN)相结合的算法进行采样处理,采用随机森林算法和皮尔逊相关系数(Pearson Correlation Co⁃efficient)相结合方法进行特征选择,并用CNN 提取空间特征、BiGRU提取远距离相关特征。
来自谷歌的机器翻译团队在2017 年发表的一篇论文中提出了一种包括self-attention 和multi-head attention 的神经网络架构[15],该架构在机器翻译任务中取得了优异的成绩。之后,许多研究人员将注意力机制应用于入侵检测模型。文献[16]提出一种基于LSTM 和注意力机制的检测模型,并使用卡方分布(chi-square distribution)、统一流形近似与投影(uniform manifold approximation and projection for dimension reduction,UMAP)、主成分分析(principal component analysis)和互信息(mu⁃tual information)四种约简算法,实验在NSL-KDD数据集上评估了所提出的方法,实验表明,使用具有所有特征注意力和03 成分的主成分分析具有最好的性能。为了检测更多的攻击类型,文献[17]提出一种基于多头注意力机制,其结构更适合捕获网络流量中的分散证据,该模型整体检测性能提高29%。
尽管许多研究已经将深度学习应用于入侵检测系统,但仍然存在一些问题。例如,一些入侵检测模型难以处理复杂和高维的网络流量,导致特征提取不佳,还有一些模型在二分类的时候准确率普遍很高,但处理多分类问题时的效果不佳。针对这些问题,本文提出了一种融合多头注意力和双向门控循环单元的入侵检测模型。
2 基于MultiHead Attention 和BiG⁃RU的入侵检测模型
所提模型主要由两部分组成:数据预处理模块和神经网络模块,模型结构如图1所示。

图1 模型流程图
2.1 数据预处理
在数据预处理模块中,由于数据集中存在缺失值,首先使用缺失值所在列的均值进行填充,接着使用独热编码对字符数据进行数值化处理,再对所有数据进行最大最小标准化以减少冗余。最后考虑到UNSW-NB15 数据集中的Worms 攻击种类样本数据较少,遂使用随机过采样方法以解决数据不平衡的问题。最大最小标准化公式如下:
2.2 神经网络模型
1)输入层:输入层使用LeakyReLU 激活函数,他是修正线性单元的改进版本,它的提出就是为了解决神经元“死亡”问题。LeakyReLU 与ReLU 仅在输入小于0的部分有差别,ReLU输入小于0的部分值都为0,而LeakyReLU 输入小于0 的部分值为负,且有微小的梯度。
2)最大池化层(MaxPooling1D)和批量标准化(BatchNormalization):使用一维最大池化层对时域一维信号进行最大值池化,最大池化层的池化大小(pool_size)可以成倍的降低数据维度,减少参数数量,去除冗余信息,从而对特征进行压缩以简化网络的复杂。使用批量标准化对最大池化层的输出数据进行规范化,进一步提高模型性能和减少训练时间。
3)融合多头注意力和BiGRU 的包装层(wrap⁃per layer):该层使用多头注意力包装了4 层BiGRU网络,GRU 是在LSTM 的变种[18],双向GRU 是由两个GRU 组成的序列处理模型,一个是正向输入,一个是反向输入。考虑到网络数据作为一种时间序列,状态是相关的,所以使用BiGRU 代替GRU 可以更好地处理数据。虽然BiGRU 可以很好地处理长期序列,但仍然无法并行计算,因此BiGRU 很难单独处理海量数据的网络流量。多头注意力可以用来捕捉输入和输出的关系,计算单元的数量由模型决定,从而实现高性能的并行计算。多头注意力机制的计算过程如下。
Step1:初始化向量Query、Key、Value,将输入序列每一个字符对应的embedding向量与已经训练的三个矩阵Wq、Wk、Wv相乘得到Query 向量、Key向量、Value向量:
Step2:计算Attention Score 与Softmax Score。Attention Score 反映了此字符和其他位置字符的相关程度,同样就反映了对其他位置的“关注程度”。对Attention Score 进行缩放和归一化操作,得到Softmax Score,公式中dk表示维度:
Step3:最后将每个Value 向量乘以Softmax Score 得到加权的V1和V2,将V1和V2求和就可以得到第一个输入的Attention Value,再对原始的向量Query、Key、Value 做多次的线性映射,把每次的结果映射到多个空间中去,重复进行上面的过程,每次得到的结果称作一个“头”。简言之,多头注意力机制就是让每一个注意力去关注输入信息的不同部分,然后进行拼接。
如图2 所示,包装层用多头注意力机制包装了4 层BiGRU 层后,在每一层的每一个输入输出的时间步都对数据计算注意力值,并行化后形成一种多通道结构,这样在每个通道都可用来在输入输出中对特征加权,并且每一个通道输出不同的结果,最后将其连接起来进行推断。

图2 MultiHead-BiGRU包装层
引入多头注意力机制后,模型能够更加方便的捕获序列中任意位置的字符之间的关联关系,从数据整体计算目标,信息能够使用不同序列位置的不同子空间的表征信息来进行序列数据处理;而且,多头注意力机制使用权重求和的方式产生输出向量,使其梯度在网络模型中的传播更加容易。
4)平展层(flatten layer)和全连接层(dense lay⁃er):使用平展层用来连接包装层和全连接层,将上一层包装层的输出“压平”,即把多维的输入一维化输出给全连接层,全连接层的最后一层作为输出层,输出类别的概率。
3 实验与分析
实验在UNSW-NB15 与CIC-IDS2017 数据集上进行,并使用分层k 折交叉验证(stratified k-fold cross validation)方法来寻找最佳模型,使用控制变量的方法,对比池化层的池化大小对模型产生的影响,最终选择一个最优模型,并将模型与其他入侵检测模型进行比较。
3.1 评估指标与数据集介绍
实验使用准确率(Accuracy,Acc)、精确度(Pre⁃cision,Pr)、召回率(Recall,R)和F1 分数(f1-score)衡量模型分类的结果,在下方公式中,TP 表示正确预测流量数据为正常的数量,TN 表示正确预测流量为攻击的数量,FP 表示错误预测流量数据为正确的数量,FN 表示错误预测数据流量为攻击的数量。
实验在UNSW-NB15 数据集和CIC-IDS2017数据集上进行测试。将UNSW-NB15 的训练集和测试集用panda 的concat 方法结合在一起,提高样本数量,结合后的数据共有257673 条数据,CI⁃CIDS2017 数据集的分类包括Portscan,Dos,DDoS,Web,BENIGH 四种,最终的数据集有1042557 条数据。
3.2 实验设置
本文设置以下实验:
实验一:分层k 折交叉验证模型性能分析试验。
实验二:不同池化大小对模型性能影响分析实验。
实验三:模型性能对比实验。
实验使用Python 语言,Python 版本为3.8,使用Tensorflow 2.20在Jupyter Notebook下开发。试验基于Windows11 系统进行,硬件参数为CPU 为Intel Core i7-9700,内存为32GB。
模型的基本参数设置如表1所示。

表1 模型设置参数
3.3 结果与分析
本节所做的工作是进行分层k 折交叉验证模型性能实验,模型分别进行二分类和多分类实验。
3.3.1 分层k折交叉验证模型性能分析实验
UNSW-NB15和CIC-IDS2017数据集上的二分类召回率和f1 分数随k 值的变化趋势如图3 和图4所示。从中可以看出,随着k 值的增加,两个数据集二分类的召回率和f1 分数整体呈上升趋势。这是因为随着值的增大,数据集被分割的越来越多,作为训练集的数据也越来越多,所以准确率也更高。对于CIC-IDS2017 数据集,当k 为4 时,召回率和f1分数取得了不错的效果,k取5的时候,模型稳定性较差。对于UNSW-NB15数据集,k值取7、8和9 时,对应模型识别正常流量和攻击流量的效果较好。

图3 二分类召回率

图4 二分类f1分数
UNSW-NB15 数据集多分类实验各类别检出的精确率和f1 分数如表2 和表3 所示。从表中可以看出,在k 取2、5 和10 的时候,模型无法识别出Analysis 和Backdoor 攻击,这是由于k 较小时,训练样本较少,交叉验证容易有较高的误差,k 偏大时,模型总体方差变大,模型性能下降。

表2 UNSW-NB15数据集的多分类精确率

表3 UNSW-NB15数据集的多分类f1分数
在k 取8 时,Backdoor 攻击能很好地被检测到,且Reconnaissance、Fuzzers、Shellcode、Worms 和Ge⁃neric 攻击的精确率和f1 分数也能取得不错的结果。针对攻击类型Worms使用随机过采样后,该类的检测效果有了很大的提升,在k 为8 的模型实验中,该类的f1 分数达到36.04%。实验表明,使用随机过采样可以在一定程度上解决数据不平衡的问题。
图5 和图6 是CIC-IDS2017 数据集的多分类的精确率和f1分数,从图中可以看出所有类别的检测精度和f1 分数均高于98.5%。当k 为3 时,模型对正常流量和DDos、PortScan攻击的检出都取得了很好的效果。k 值为10 时Dos 攻击的检测精度最好,达到99.906%,k 值为5 时Dos 攻击的f1 分数最高,达到99.858%。
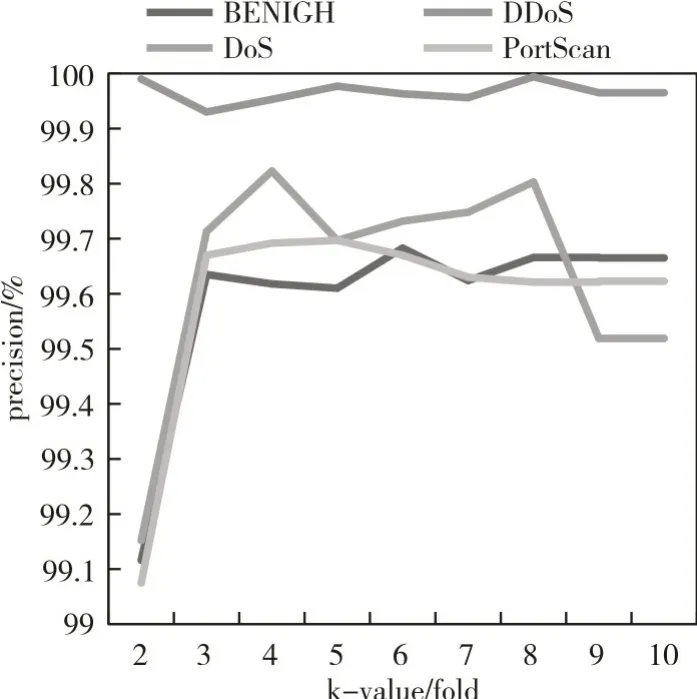
图5 CIC-IDS2017多分类精确率

图6 CIC-IDS2017数据集的多分类f1得分
不同k值的模型在UNSW-NB15和CIC-IDS2017数据集上实现了上述实验结果,根据上面的分析可以看出,为了保证多分类和二分类的性能以及每个攻击类别都能被模型检出,应选择k 值为8 的模型。
3.3.2 不同池化大小对模型性能影响分析实验
从表4可以看出,当池化大小设置为4时,模型在两个数据集的多分类下可以达到最好的准确率。当池化大小设置过大时,神经网络的参数减少,特征减少,导致模型性能下降。池化大小设置过大也违背了最大池化层的初衷,即最大池化层不仅是为了数据降维,也是为了维护数据的边缘纹理信息,以方便模型提取数据边缘特征。

表4 不同池化大小对应准确率
3.3.3 模型性能对比实验
在本节中,基于UNSW-NB15 和CIC-IDS2017数据集,在相同的实验条件下,我们选择k-means算法[4]、决策树算法[5]、随机森林算法[6]和GRURNN[18],CNN-BiLSTM[20]和WaveNet-BiGRU[20]模型与本文提出的模型进行比较。设置对比实验是为了进一步验证该网络入侵检测模型的综合性能。表5 和表6 是不同模型的多分类总体准确率、精确率、召回率和f1分数比较。
从表5 和表6 可以看出,所提出的模型在准确率、准确率、召回率和f1 分数这四个指标上都能取得较好的表现。与决策树、随机森林和k-means 等传统机器学习方法相比,由于神经网络具有很强的非线性拟合能力,可以映射任何复杂的非线性关系,因此本文模型具有更强的特征提取能力。

表5 UNSW-NB15数据集多分类性能比较

表6 CIC-IDS2017数据集多分类性能比较
与GRU-RNN 和CNN-BiLSTM 模型相比,本文的模型融合了注意力机制和BiGRU,可以捕捉网络流量中任意位置的序列之间的关系,使整个模型更容易学习上下文长句的依赖。最大池化层可以进一步提取边缘特征,从而获得更好的分类结果。在UNSW-NB15数据集的实验中,WaveNet-BiGRU 模型的整体效果优于所提模型,但在CIC-IDS2017 数据集的实验中,所提模型在精确率、召回率和f1 分数优于WaveNet-BiGRU。
4 结语
为解决一般入侵检测系统难以处理复杂、高维的网络流量,特征提取效果不佳导致网络入侵检测效果不佳的问题。本文提出了一种融合多头注意力和BiGRU 的入侵检测模型,模型使用随机过采样来解决入侵检测中的数据不平衡问题,融合多头注意力和BiGRU 处理长距离序列,使用最大池化层平衡模型训练速度和性能,同时提取序列边缘特征,论文使用k 折交叉验证的方法选择最佳模型,模型在精确率、准确率、召回率和f1 得分都有一定提高。通过对比实验证明了多头注意力和BiGRU相结合的入侵检测模型具有研究前景。然而对比WaveNet-BiGRU 所提模型的多分类能力仍有进一步提升的空间,处理不平衡数据的能力也有待进一步提升。针对这两个问题,下一阶段我们将重点关注数据集的处理和分类模型的优化。
猜你喜欢
科学技术与工程(2023年3期)2023-03-15
小雪花·成长指南(2022年1期)2022-04-09
软件导刊(2022年3期)2022-03-25
新一代信息技术(2021年22期)2021-12-29
科技创新与应用(2021年23期)2021-08-30
无线互联科技(2020年15期)2020-11-10
科技传播(2020年6期)2020-05-25
计算机技术与发展(2019年1期)2019-01-21
雷达科学与技术(2018年3期)2018-07-18
传媒评论(2017年3期)2017-06-13
