
多源异构区块链数据质量评估模型*
2023-05-12 02:25:32宋宝燕单晓欢王俊陆
计算机与数字工程 2023年1期
张 冉 宋宝燕 单晓欢 王俊陆
(辽宁大学信息学院 沈阳 110036)
1 引言
区块链[1~3]是一种新型分布式技术,其基于块链式结构、共识算法和智能合约[4~5]实现了数据信息从记录到传输再到存储的过程,且节点间无需第三方信任机构的约束,实现了无信任关系[6~7]节点之间的价值通信。国内外大型企业单位如谷歌、百度、阿里巴巴等都建立了自己的企业联盟区块链系统。目前区块链中存储的企业经营活动信息大多来自于不同的行业和机构,这使得信息质量参差不齐,歧义性较大,同时受公司自身信誉度及环境制约,无法保证区块中数据的准确性和价值,因此,在创建区块时,会出现一系列问题。传统的评估方法没有利用区块链全程留痕、不可篡改、可追溯的特征,评估效率及准确性均较低,导致企业用户及相关监管部门无法快速筛选出满足需求的区块链,也无法建立统一的分析[8~9]模型。因此,评估区块链的质量十分有必要。
针对这些问题,本文提出一种面向企业经营活动的多源异构区块链数据质量评估模型,实现对经营活动信息一致性、可信度以及价值的高效评估。本文主要贡献如下:
1)针对区块链中企业经营活动异构信息一致性差的问题,提出CEKQRL 模型,用三元组的形式表示企业经营活动信息,并引入注意力机制[10]对三元组和活动类别进行关联;同时还考虑了实体上下文信息对一致性评估的影响,进而构建上下文结构图模型,进一步提高区块链的相似度计算效率。
2)在此基础上,针对区块链中企业经营活动信息的可信度评估困难问题,综合考虑了信息源、信息评价的可信度,然后将这两部分的表征结果进行融合[11]。
3)针对区块链中活动信息的价值评估问题,提出了一种信息价值评估方法,通过信息量的大小表述信息的不确定度,进而衡量区块中企业经营活动的价值量。最后,综合区块间语义相似度、区块链内容评估以及价值评估,得出面向企业经营活动的多元异构区块链数据质量评估模型。
2 相关工作
目前,许多学者对数据质量评估方法进行了深入研究,并取得了一定的研究成果。
在区块链信息一致性评估方面,文献[12]提出一种结构化梯度树提升(SGTB)算法进行实体消歧,该方法在跨领域的评估中有较好的性能,但它忽略了实体的上下文信息对计算过程的作用;文献[13]提出一种基于因子图的不一致记录对计算方法,该方法对实体进行解析,但未关联实体表示与其所属类别;文献[14]提出具有多视角关注的神经网络,从而捕捉更多的信息特征,但该方法未关注实体上下文信息。
在区块链信息可信度评估方面,文献[15]提出一种综合信誉计算方法,整合了多维度数据,但却只注重相关评价而未重视信息源这一因素;文献[16]提出基于多源异构信息融合的数据可信度评估方法,该方法在提高计算收敛性方面效果较好,但忽略了信息内容的可信度;文献[17]提出一种用于用户生成内容可信度评估的监督机器学习方法,但该方法只关注相关评论信息,忽略了对信息内容及其来源的关注。
在区块链信息价值评估方面,文献[18]提出一种基于置信度的可靠性评估方法,该方法能准确地得到数据所属分布,但忽略了数据本身的价值所在;文献[19]构建VW&ICM 计算模型进行风险评估,该模型削弱了主观因素对评估结果的影响,但忽略了数据整体价值信息;文献[20]从主观和客观两个方面确定总体权重和评估标准,克服了单一模型的限制,但却只适用于信息不确定性较大的情况。
综上所述,本文针对区块链质量评估方法的不足之处,基于企业经营活动信息的一致性、可信度及价值三个方面,提出了面向企业经营活动的多源异构区块链质量评估模型。
3 基于上下文信息的区块间语义相似度计算
由于区块链中企业经营活动信息多来自于不同数据源,导致异构信息表征方式不一致,如数据格式、实体名称等,这使得区块链中存储的经营活动信息具有歧义性,数据质量较低。针对该问题,本文通过实体间语义相似度比较来评估区块链数据的一致性。
3.1 基于CEKGRL模型的区块实体表示
本文提出基于CEKGRL的模型,将区块实体表示为三元组形式。此外,本文还考虑了三元组信息与其所属的类别,并使用注意力分数表征其关联程度。
3.1.1 三元组信息结构
根据CEKGRL模型,本文将企业经营活动信息定义为G=(E,R,S)形式,其中E、R分别代表企业实体集和关系集,三元组集合用S⊆E×R×E表示,(h,r,t)代表一个由企业名、活动方向以及活动信息构成的三元组,c为类别。CEKGRL 模型的整体架构如图1所示。
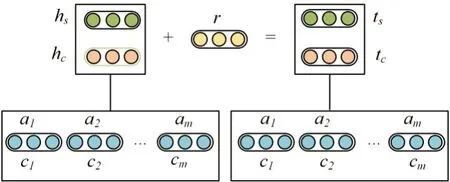
图1 CEKGRL模型整体架构
图中的hs、ts代表基于结构的三元组表示,hc、tc代表基于类别的三元组表示,a表示注意力分数,本文将融合两种表示类型的能量函数定义如式(1)所示:
其中,β表示基于类别表示的权重。
3.1.2 关联信息类别与活动表示
某企业实体名称可能属于不同的类别,基于此,本文通过注意力分数值表明关系与类别之间的相关性。
首先,利用CEKGRL 模型将关系r、类别c视为query向量、key向量和value向量,用矩阵的方式表示注意力。将企业关系与其对应的活动类别以关系矩阵R和类别矩阵C的方式进行拼接。然后,引入权重矩阵WQ、WK和WV,对其进行训练,并对矩阵进行相乘操作,运算结果和注意力分数如式(2)和(3)所示:
式中,dk为矩阵的维度,att(C,R)值越大,表明与关系r越可能属于类别c。
3.2 基于上下文信息的相似度计算
在区块链企业经营活动信息中,单一企业实体的名称指代可能存在“一对多”映射关系,使信息表达具有歧义性,导致相似度计算的准确率较低。本文引入上下文信息,构建上下文结构图模型进行区块之间相似度的计算。
3.2.1 上下文信息关联图模型构建
本文以企业实体名称、经营交易活动为例进行实体歧义性计算。把某企业实体的上下文关系描述为实体相关图模型G=(V,E),V、E分别代表顶点集和边集。模型的构造分为以下两步。
1)顶点集合构造
图模型中的各顶点由企业经营活动信息的上下文构成,其上下文信息ci的可信程度用置信度(Confidence Measure,CM)衡量,置信度的计算如式(4)所示:
其中,ResultScore(ci)是基于知识图谱得出的匹配分数,值的大小反映了上下文信息的准确程度。
2)边集合构造
图模型的边由该企业活动所对应上下文信息的路径关联度组成。本文利用信息A到信息B的前向最短路径FShortPath和后向最短路径BShortPath判断两个节点之间的最短路径,并将最短路径转化为节点之间的关联程度,计算如式(5)所示:
节点之间的关联程度计算如式(6)所示:
从该公式可得,节点间的路径越短,其关联程度越高。
3.2.2 块间相似度计算
本文对企业经营活动信息的实体名称、具体内容进行语义相似度的计算,SimText(A,B)代表区块A与B的语义相似度,采用余弦相似度计算如式(7)所示:
归一化处理如式(8)所示:
最后,取首块与其他区块的相似度平均值作为最终的一致性计算结果,计算如式(9)所示:
其中,SimText(A,i)表示首块与其他区块的相似度度量结果。
4 区块链质量评估模型构建
评估模型由区块链一致性、信息可信度以及价值综合衡量,并根据重要程度赋予不同的权重。
4.1 基于可信度理论的区块链内容评估
本文通过综合表征企业经营活动的信息源和信息评价的可信度来表示区块链内容的可信度。
4.1.1 基于源的信息可信度表征1)信息页面的可信度
通过企业经营活动信息所处页面中各链接是否可达以及所达页面是否可用进行信息页面的可信度度量。计算如式(10)所示:
其中,A、B、C分别表示页面中可达链接、不可达链接以及可达不可用链接的集合。
2)信息发布者的可信度
本文将网络中的用户看为一个整体,用户总数记为N。用户的三种状态如下:
(1)不知者(ignorant)。对于已发布的信息,用户无法判断信息真假的用户。
(2)信息可信用户(believed)。对于已发布的信息,根据自身的知识积累,认为发布信息是可信的用户。
(3)信息不可信用户(unbelieved)。对于已发布的信息,根据自身的知识积累,认为发布信息是不可信的用户。在进行信息传播时,各用户的状态转换如图2所示。
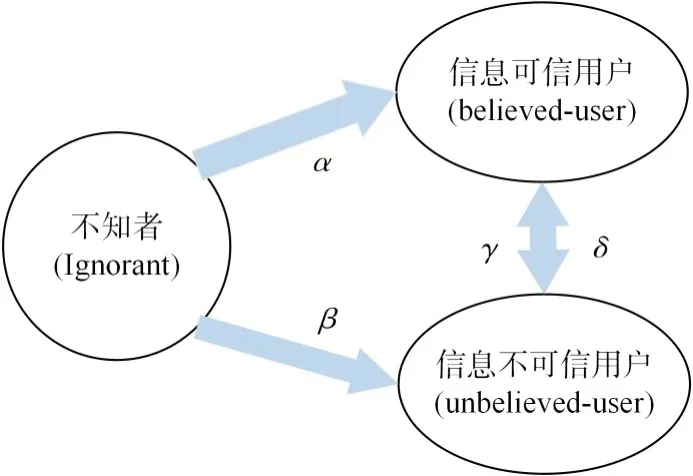
图2 节点间状态转化
对于已发布的信息,首次接触该信息的用户被称为不知者,经过t时间后,该用户认为信息可信与不可信的概率分别为α和β。
设在t时刻后,认为发布信息是可信的用户又认为信息不可信的概率为γ,此时用户的状态改变;反之为δ。信息交互规则如式(11)所示:
方程组中的I(t),B(t),U(t)表示t时刻各类用户的比例。该发布者的可信度计算如式(12)所示:
3)源的可信度表征结果融合
将发布平台、页面的可信度表征结果进行融合,计算如式(13)所示:
4.1.2 基于评价特征的信息可信度表征
当计算评价表征值时,一般分为两步:第一步是计算该条评论是否与该信息相关;第二步是进行相关表征倾向值的计算。
1)评价与信息的相关性
评价与信息的相关性具体计算如式(14)所示:
其中,I是某条信息,C为信息中的某条评价,w是评价中的某个词,用t表示主题词,即用某信息中出现各词的概率来衡量评价与信息是否相关。
2)相关评价表征倾向
对信息的评价计算表征倾向值如式(15)所示:
其中,w(R)为评价R的情感倾向得分,p(ai)为句子ai在评价R中所处的位置,count(a|R)为评价中所包含的句子数目。
最后,用信息源的可信度和信息评价的可信度来综合衡量区块链中存储的企业经营活动信息的可信度,并赋予不同的权重,计算如式(16)所示:
由于评价具有主观性,不确定性较大,因此信息源的可信度所占比值最大,信息评价次之。
4.2 基于信息量的区块链价值评估
对区块链价值的评估,本文采用计算其信息量的方法。该方法利用区块链中所包含信息量的多少来评估区块链的价值,其相关性质如下:
性质1信息量的值为非负值,并且值的大小直接反映了信息量的多少。
性质2信息量本身是一个值,可直接进行相加。
区块链中的各个区块都可视为一种离散信源,某条链X的取值集合及其概率空间如式(17)所示:
其中,pi代表区块xi中活动信息出现的概率,区块链总的信息量Validity计算如式(18)所示:
Validity的最终计算值表明这些企业经营活动信息所在区块链价值量的多少,对于给定的区块链,其价值量的大小可以由信息量的值来反映,值越小,信息量越少,区块链的价值效用越小,反之该区块链的价值效用越大。
4.3 区块链质量评估模型构建
为了评估多源异构区块链的质量,本文用企业经营活动信息的一致性、可信度以及价值三者的加权值来度量区块链的综合质量。具体的评估模型如式(19)所示:
区块链价值是衡量区块链质量的重要指标,区块链所含价值越大,该区块链的应用价值越大,其次是信息的可信度,最后是信息的一致性,因此权重γ>β>α。
5 实验结果与分析
实验平台为Intel Core i7-12700 处理器,16GB内存和64 位Windows10 操作系统。采用Block⁃chainSpider 数据收集工具箱中的数据作为本次实验的数据集,该工具箱旨在收集公链数据,包括交易子图、标签数据、区块的内部交易以及转账记录等,本次实验大约使用了10 万条数据,区块中数据的详细信息如表1 所列。本文从评估模型一致性、准确性、价值以及效率三个方面进行模拟实验,用本文所建模型(DQAM)与AHP、DSMM 等模型进行对比。
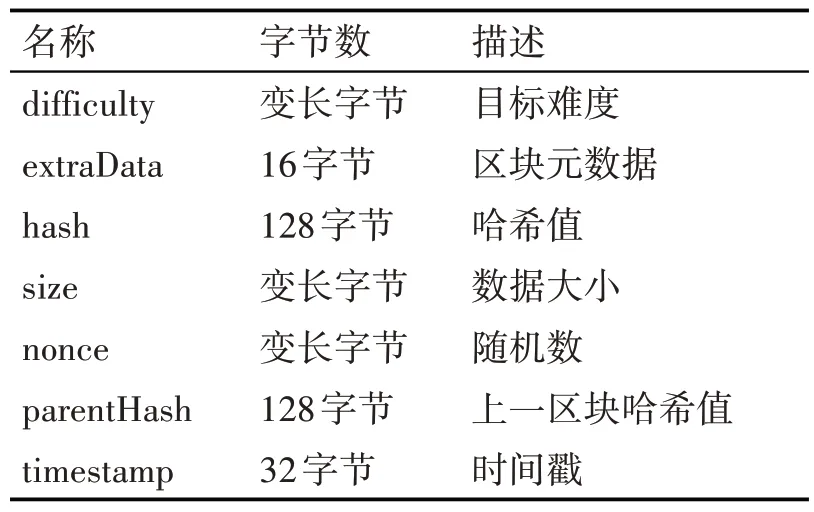
表1 区块数据
5.1 模型一致性对比
本节在表1 的数据集上评估各模型的一致性,其中横轴代表数据条数,纵轴代表一致性评估质量,通过结构化梯度树提升(SGTB)算法、基于因子图的不一致记录对消歧(DIBFM)、多视角关注的神经网络消歧(NDMP)方法和本文所提的基于上下文信息的相似度计算方法(SCBCI)进行对比,实验结果如图3所示。
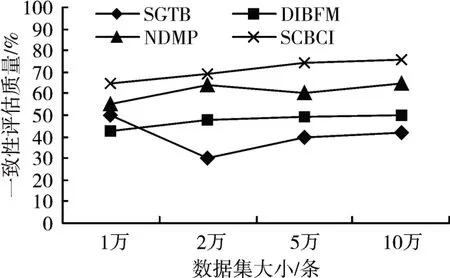
图3 一致性评估
由图3 可知,随着数据量增大,与现有方法相比,本文所提的一致性评估方法的评估质量逐步提高,这是因为该方法对区块信息采取三元组表示方法,并把这些三元组与某些类别进行关联,同时又充分考虑了实体的上下文信息,因此能获得较高的一致性评估质量。
5.2 准确性评估对比
本节验证基于可信度理论的区块链内容评估(CEBT)方法的效率,各方法在不同数据集上的准确性评估质量对比如图4所示。

图4 准确性评估
由图4 可知,CEBT 方法的平均评估质量高于其他方法。对比方法是多源异构信息的数据可信度评估(MHIF)以及用户内容可信度评估的(SML)方法。
5.3 价值评估对比
实验通过模拟采用本文所提的信息量方法(VIS)与基于数据分布的价值评估方法(VADD)、VW&ICM 计算模型的价值评估质量,横坐标表示数据量多少,纵坐标表示信息价值的评估质量,实验结果如图5所示。

图5 价值评估
由实验结果可发现,本文所提的基于信息量的方法评估质量较高。其主要原因是该方法关注数据价值本身而非其分布、规律等次要因素,因此该方法直观、明了、效率较高。
5.4 模型效率对比
本节比较各质量评估模型的运行效率,横坐标代表区块链中实体数据集,纵坐标表示各模型运行所需时间,实验结果如图6所示。
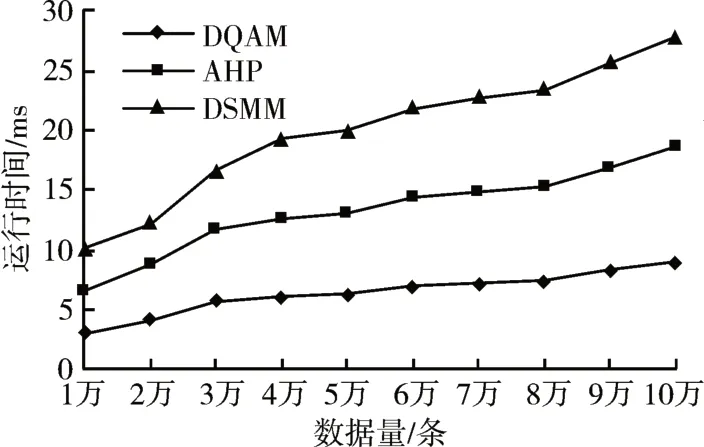
图6 模型效率对比
由结果可知,AHP、DSMM 方法的平均运行时间在10ms~15ms左右,本文提出的区块链数据质量评估模型(DQAM)评估时间在5ms 左右,并且随着数据量的增多,DQAM 模型的评估时间基本波动不大。
6 结语
本文提出了一种多源异构区块链质量评估模型,综合考虑了企业经营活动信息的一致性、可信度以及价值。一致性评估中着重考虑了实体的上下文信息对实体之间相似度比较的影响;信息可信度评估对企业经营活动信息源、信息评价的可信度表征结果进行融合;价值评估采用信息量衡量区块链的总价值。最后,通过实验验证了本文所提方法的有效性,为区块链的质量评估提供了一条有效的途径。
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31 08:40:44
公民与法治(2022年5期)2022-07-29 00:47:28
教学考试(高考物理)(2021年5期)2021-11-08 10:31:22
中医眼耳鼻喉杂志(2021年1期)2021-07-22 07:38:14
山西大学学报(自然科学版)(2021年1期)2021-04-21 03:38:02
中国外汇(2019年18期)2019-11-25 01:41:54
五邑大学学报(自然科学版)(2019年3期)2019-09-06 02:22:22
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
