
基于生成对抗网络结合Transformer的半监督图像增强方法
2023-05-08 12:44:53马天李凡卉席润韬安金鹏杨嘉怡张杰慧
西安科技大学学报(社会科学版) 2023年6期
马天 李凡卉 席润韬 安金鹏 杨嘉怡 张杰慧

摘 要:針对成对数据集获取成本较高、光照分布不均衡图像增强效果欠佳以及增强结果易产生十字形伪影的问题,提出了一种基于生成对抗网络结合Transformer的半监督图像增强方法。首先,采用Transformer网络架构作为生成对抗网络中生成器的主干网络,提取不同像素块间的依赖关系以获取全局特征,并通过非成对数据集进行半监督学习;其次,使用灰度图作为生成器网络的光照注意力图,以平衡增强结果在不同区域的曝光水平;最后,在生成器和鉴别器网络中交叉使用均等裁剪策略和滑动窗口裁剪策略,增强网络提取特征的能力并解决十字形伪影问题,并引入重建损失来提高生成器对图像细节的感知能力。结果表明:提出方法取得了更好的光照和色彩平衡效果,自然图像质量评估指标平均提升了2.37%;在图像修饰任务中,图像峰值信噪比、相似结构度和感知损失同时达到了最优;在低光照增强任务中,图像峰值信噪比提升了13.46%;充分验证了提出方法在图像增强2个子任务上的有效性。关键词:半监督;图像增强;生成对抗网络;Transformer;光照注意力中图分类号:TD 391
文献标志码:
A
文章编号:1672-9315(2023)06-1207
-12
DOI:10.13800/j.cnki.xakjdxxb.2023.0619开放科学(资源服务)标识码(OSID):
Semi-supervised image enhancement method based on
generative adversarial network combined with transformer
MA Tian1,LI Fanhui1,XI Runtao2,3,AN Jinpeng1,YANGJiayi1,ZHANG Jiehui1
(1.College of Computer Science and Engineering,Xian University of Science and Technology,Xian 710054,China;
2.CCTEG Changzhou Research Institute,Changzhou 213015,China;
3.Tiandi(Changzhou)Automation Co.,Ltd.,Changzhou 213015,China)
Abstract:To address the issues of high cost in acquiring paired datasets,inadequate enhancement effects due to uneven lighting distributions,and the occurrence of cross-shaped artifacts in the enhanced results,a semi-supervised image enhancement method based on the combination of generative adversarial network and Transformer was proposed.Firstly,the Transformer network architecture was employed as the backbone network of the generator in the GAN to extract the dependency relationships between different pixel blocks for obtaining global features,and semi-supervised learning was performed using non-paired datasets.Secondly,a grayscale image was used as the illumination attention map for the generator network to balance the exposure levels of the enhanced results in different regions.Finally,equal cropping strategy and sliding window cropping strategy were cross-used in the generator and discriminator networks to enhance the feature extraction capability of the network and solve the problem of cross-shaped artifacts.Additionally,a reconstruction loss was introduced to improve the generators perception capability of image details.The results demonstrate that the proposed method has achieved better lighting and color balance effects,with an average improvement of 2.37% in the evaluation of natural image quality.In the image modification task,the peak signal-to-noise ratio,structural similarity,and perceptual loss simultaneously reach their optimum values.In the low-light enhancement task,the peak signal-to-noise ratio is improved by 13.46%.These results fully validate the effectiveness of the proposed method in the two subtasks of image enhancement.Key words:semi-supervised;image enhancement;generate adversarial network;Transformer;light attention
0 引 言
图像是人类获取信息的重要途径,但是由于光照条件和设备性能等的限制,会导致所拍摄图像存在过暗、细节不清晰、颜色失真等问题,因此需要采用图像增强技术进行修复。文中以图像增强领域的2个子问题:图像修饰和低光照图像增强为研究对象。图像修饰的目的在于对图像的曝光、色彩、饱和度等进行综合调整;而低光照图像增强则旨在提升光线不足场景下获得图像的视觉感知质量,以得到更多有效信息。图像增强自提出以来已经历了几十年的发展。传统方法通常采用直方图均衡化[1]、伽马校正[2]或是利用图像在频域上的特性[3]进行图像增强。此外,还有学者应用Retinex理论[4]对图像亮度和颜色信息进行调整,以增强图像的细节和对比度。尽管这些方法在处理具有单一问题的图像时表现出色,但它们缺乏对图像整体或局部特征的关注,在处理一些综合多种问题的復杂场景时存在局限性。近年来,基于深度学习的图像增强方法受到了广泛关注。目前,大多数基于CNN的图像增强方法都依赖于成对数据集进行全监督训练。LORE等首次提出一种称为Low-Light Net(LLNet)的深度自编码器,以增强图像亮度、对比度和降低噪声[5]。随后,很多基于成对数据集的全监督方法被提出。然而这些方法的增强性能很大程度上依赖于数据集,这容易导致模型过拟合和缺乏泛化性。为了解决这一问题,一些方法开始在没有成对数据集的情况下进行训练。 基于此,EnlightenGAN[6]作为一种基于无监督学习的方法被提出,该模型采用了条件生成器和全局-局部鉴别器的设计,能够在不需要配对监督数据的情况下实现高质量的低光照图像增强。但由于该方法采用了2个生成器和2个鉴别器的结构,计算成本较高。此外,HU等提出了一个White-Box照片后处理框架,该框架通过学习根据图像的当前状态做出决策来改进照片后处理的效果[7];CHEN等采用强化学习进行图像修饰,并提出了一种改进的双向生成对抗网络(GAN),以非配对学习的方式进行训练[8]。然而,当输入图像
较暗或包含噪声时,该模型可能会放大噪声的问题。
另一方面,在图像增强任务中,成对数据集可以提供监督信号,即对于每个输入都有一个对应的输出。这种监督信号可以帮助深度学习模型更快地学习和调整参数,从而提高模型的准确性。然而,获取和准备成对数据集的成本较高。为了获得成对数据集,通常需要专家修图人员手动修复低质量图像或者人为破坏高质量图像。因此,获取成对图像需要耗费大量的时间和人力。针对以上问题,文中提出了一种基于生成对抗网络结合Transformer的半监督图像增强方法(Semi-supervised Trans GAN Image Enhancement,STGIE)。STGIE的整体架构采用GAN的架构,生成器主要由 Transformer编码器和曲线调整工具构成,鉴别器则由全注意力特征编码器和多层感知机作为主要结构。为了解决增强结果曝光不均衡的问题,STGIE采用了光照注意力图来辅助生成器进行光照调整;同时,在生成器和鉴别器中采用了不同的图像裁剪策略,有效地消除了十字形伪影问题。此外,STGIE使用非成对数据集进行训练,以避免因训练数据有限导致的模型过拟合问题。通过低光照图像增强和图像修饰的对比试验,证明了其在性能上相较于其他方法更为优越。STGIE不仅能够有效地调整不同区域的光照分布,还在整体对比度和色彩饱和度方面表示出色。
1 相关研究理论概述
1.1 生成对抗网络近年来,生成对抗网络(Generative Adversarial Nets,GAN)已广泛应用于图像增强任务中。GAN利用生成器网络生成更真实、更清晰的图像,并通过鉴别器网络对生成的图像进行评估,从而不断优化生成器网络,使其生成的图像更真实、更接近实际图像。ZHANG等提出HarmonicGAN方法,通过在训练数据上引入一个平滑项来加强源域和目标域之间的平滑一致性,来学习源域和目标域之间的双向转换[9]。JIANG等提出了EnlightenGAN方法,该模型包含一个自正则注意力引导的U-Net生成器和一个全局-局部鉴别器。研究者还提出了基于局部和全局的自我特征保留损失函数,可以更加精确地保留图像的细节和纹理信息,从而生成高质量的增强图像。CHEN等采用双向GAN架构结合自适应加权方案,提高了训练稳定性。DPE能够感知高质量图像特征,并利用这些特征对低质量图像进行增强。KOSUGI等提出的UIE方法可在不需要成对数据集的情况下,通过单个强化学习智能体来控制图像编辑软件,学习如何调整编辑软件的参数,以达到更好地图像增强效果[10]。
1.2 Transformer由于卷积操作的局限性,导致CNN和GAN在处理大尺寸图像时需要大量的计算资源和时间。相比之下,Transformer通过自注意力机制能够更好地处理大尺寸图像,并学习到全局的图像特征。最初被应用于自然语言处理领域的Transformer,近几年也被广泛应用于图像分类、语义分割、图像增强等图像处理领域。DOSOVITSKIY等提出Vision Transformer(ViT)模型将图片划分为多个不重叠的区域,然后将自然语言处理中使用的标准 Transformer编码器应用在图像识别任务中,取得了优于CNN架构的效果[11]。随后,ZHENG等提出了一种基于Transformer的序列到序列语义分割方法[12]。该方法将图像分割成若干个小块,并通过 Transformer模型进行处理,输出每个像素的分类结果,从而实现对图像语义的准确划分。LIU等提出的Swin Transformer成为计算机视觉领域的主干网络,在多种任务中取得SOTA水平[13];ESSER等提出了一种基于Transformer的高分辨率图像合成模型[14];JIANG等将Transformer与GAN相结合,提出了TransGAN方法,该方法利用2个Transformer网络完成高分辨率图像生成任务[15];ZHANG等提出了一种称为STAR的Transformer架构,通过捕获图像之间的长期依赖关系和不同区域的结构关系以实时进行图像增强,但该方法在图像亮度和色彩调整之间难以取得平衡[16]。
xout和xtarget分别为生成的图像和非成对的真实图像。3 试验分析根据不同的任务需求,使用不同的数据集进行训练。对于图像修饰任务,采用FiveK数据集进行训练,该数据集包含5 000张由不同摄影师拍摄的照片,涵盖了各种场景、主题和照明条件;对于低光照图像增强任务,为了扩展训练数据的动态范围,使用LOL数据集和SCIE数据集进行训练。LOL数据集包含500对不同场景和不同摄像机拍摄的低光照和正常光照图像。SCIE数据集包含5 389张图像,它们是通过相机使用不同曝光时间拍摄的,每个场景都包含低曝光、正常曝光和过曝光图像。需要说明的是,非成对训练是指在生成对抗网络中使用不成对的训练数据。尽管FiveK和LOL数据集均为成对数据集,但在试验过程中,将数据集进行了打乱,形成低质量图像和非成对的高质量图像作为成对数据输入模型,进行半监督图像增强。试验过程采用Adam优化器,批大小设置为8,Epoch设置为20 000,生成器和鉴别器学习率均设置为0.000 3。为了保证STGIE在不同分辨率图像上增强效果的稳定性,在输入模型前图像会被压缩至224×224的固定分辨率。同时,通过对图像随机裁剪、旋转、翻转操作进行数据增广。整个训练过程在Nvidia 3090 GPU上不超过半个小时(Epoch训练8 000次左右),模型即可达到收敛。为了客观评估试验结果,使用全参考评价指标和无参考评价指标进行定性和定量分析。全参考图像质量评价是一种广泛应用于增强算法评估的评价体系,需要全面考虑生成图像和全参考图像的信息。使用到的指标包括:峰值信噪比(PSNR)、结构相似度(SSIM)和感知损失(LPIPS)。其中,PSNR用于衡量生成图像与参考图像像素点的相似度,数值越高表示2幅图像越相似。SSIM用于评估生成图像与参考图像的相似性,综合考虑了亮度、对比度和结构等因素,提供了更全面的相似性度量。LPIPS是一种基于感知学习方法的指标,用于评估图像增强质量,它综合考虑了像素值之间的差异以及人眼对图像的感知,更好地模拟了人类对图像质量的感知。无参考图像质量评价是一种不依赖参考图像的评价体系,常用的评价指标为自然图像质量评估器评价(Natural Image Quality Evaluator,NIQE)。NIQE是一种基于自然图像统计规律的无参考图像质量评估方法。它通过计算输入图像的自然度、锐度和噪声等特征,综合评估图像质量,其值越小代表图像质量越高。
3.1 消融试验
3.1.1 光照注意力图消融试验 为了增强模型对光照变化的适应能力,STGIE采用光照注意力图对图像不同区域进行加权处理。这种方法能够更好地区分不同区域的光照强度,并实现曝光补偿和减弱。为了验证光照注意力图对图像增强结果的影响,在保持其他条件不变的情况下,比较了使用三通道(RGB)图像和四通道(RGB、Gray)图像作为输入的增强效果。图4展示了在LOL数据集下的增强结果。
为更清晰地比较2组试验在背光区域处理上的差异,将红色框内的场景放大并置于原图下方。
总体来看,2组试验结果在图像亮度、整体色彩和细节方面均有明显的提升。在图像亮度方面,加入光照注意力图的试验结果亮度提升更加明显,也更加接近目标图像。此外,2组试验在背光区域表现出了明显差异。红色框内的场景,例如柜子内的物品、保龄球和看台下方,均为背光区域,需要进行额外的曝光补偿。在未加入光照注意力图的情况下,该区域的增强结果仍存在光照不足的问题。同时,加入光照注意力图的试验结果中,该区域的光照提升较为显著,对该区域细节信息有较好的再现,并且整张图像上没有出现过曝光问题。这主要得益于光照注意力图在增强局部对比度和调整光照方面的有效性。
3.1.2 重建损失消融试验为验证重建损失对生成器的作用,在保持其他条件不变的情况下,对比去除重建损失前后的增强效果,并通过对比VGG网络不同卷积层作为特征提取器产生的增强效果,探究不同卷积层对重建损失的影响。在FiveK数据集下试验结果见表1。
从表1可以看出,只使用对抗损失的增强效果最差。对抗损失只通过训练生成器来欺骗鉴别器,而不约束生成图像的质量,这可能导致真实图像缺乏重要特征。而仅使用VGG网络第1层卷积计算重建损失的效果最好。因为生成器使用Transformer模型进行特征提取,它更关注图像的高级特征,而浅卷积层更有可能捕获纹理和边缘等低级特征。这些自下而上的特征有效地反映图像的细节,从而更好地弥补了生成器对底层特征的忽略。
3.1.3 滑动窗口分割消融试验为了验证不同图像裁剪方法对增强效果的影响,在保证其他条件不变的情况下,分别对生成器和鉴别器使用不同的裁剪策略,在FiveK数据集下进行定性和定量对比见表2。其中,Average代表使用ViT的均等裁剪策略,Sliding代表使用滑動窗口裁剪策略。
从表2数据可以得出,交叉使用2种裁剪策略的情况下,增强结果在SSIM和LPIPS上的表现相对较好。此外,当生成器使用均等裁剪策略,鉴别器使用滑动窗口策略时,具有更好的增强效果。不同图像裁剪策略下生成器和鉴别器的增强结果如图5所示,使用红色框将图像中容易出现伪影的区域进行标注。
试验结果表明,生成器和鉴别器使用相同的裁剪策略容易导致图像出现十字形伪影。这是因为相同的裁剪策略会产生相同的分割边界,使得编码器难以获取分割边界两侧像素点之间的依赖关系,导致增强效果较差。另外,这些分割边界也可能沿着图像的纹理和形状边缘形成十字形伪影。通过采用生成器使用均等裁剪而鉴别器使用滑动窗口裁剪策略,可以有效缓解十字形伪影问题。这种策略改善了图像的色彩调整能力,并减少了伪影的出现。
3.2 试验结果定量分析
3.2.1 图像修饰定量分析为了验证所提出方法在图像修饰任务中的有效性,使用FiveK数据集,在分辨率为512×341下对比了STGIE和EnlightenGAN、DPE、Zero-DCE[17]、RUAS[18]、 3DLUT[19]方法的增强效果,这些方法均无需成对数据集,使用PSNR、SSIM、LPIPS指标对上述方法进行评估,结果见表3。
试验结果表明,相较于其他使用非成对数据集的方法,STGIE在PSNR、SSIM和LPIPS这3项指标中均表现最佳。其中,在SSIM方面,STGIE的提升得益于Transformer中多头注意力机制的全局特征提取,使其更好地调整图像的整体结构。在LPIPS方面,STGIE也具有显著优势。这说明使用STGIE增强的结果在图像整体结构方面更接近原始图像,并证明STGIE对高级语义信息更加敏感。
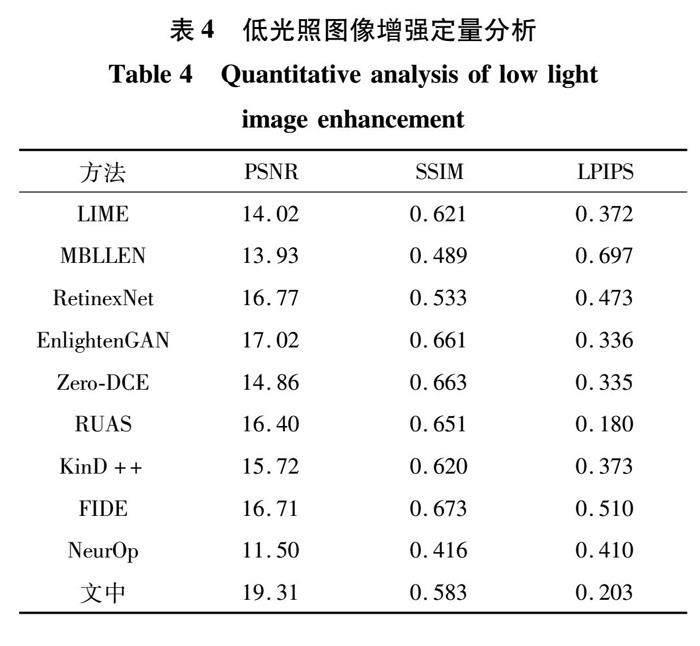
3.2.2 低光照增强定量分析为了评估STGIE 在低光照增强任务中的有效性,从2个方面进行验证。首先使用LOL数据集,对比STGIE与EnlightenGAN、Zero-DCE、RetinexNet、RUAS、LIME[20]、MBLLEN[21]、KinD++[22]、FIDE[23]、NeurOp[24]在PSNR、SSIM、LPIPS方面的表现,结果见表4。
从试验结果可以看出,STGIE在3个全监督评价指标上表现比较均衡,并优于大多数算法。其PSNR成绩优异的原因在于,采用基于曲线调整函数进行逐像素调整,能够更好拟合目标图像的像素值分布情况。在SSIM方面,FIDE方法取得了最优结果,这得益于其独特的网络结果设计。在LPIPS方面,RUAS表现最好,这得益于其通过结构搜索方法设计了一个高效的特征提取网络,能更好地提取图像全局特征,具有更好的增强效果。
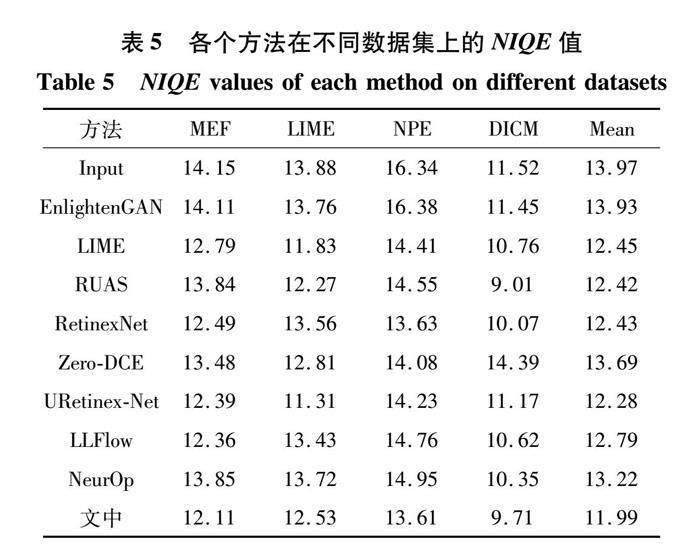
另一方面,为评估STGIE 作为半监督图像增强方法的泛化能力和处理光照不均衡图像能力,在4个非成对数据集MEF、LIME、NPE和DICM 上进行了增强效果测试,这4个数据集涵盖了各种曝光条件下的图像。由于缺乏参考图像,半监督图像增强方法难以直接评估图像增强的效果,因此采用NIQE作为评价指标。试验比较了STGIE和其他8种方法的性能差异,结果见表5。
从表5可以看出,STGIE在MEF和NPE这2个数据集上表现最优,LIME和RUAS分别在LIME数据集和DICM数据集上表现最优。STGIE在4个数据集上的NIQE平均值均为最优,这是由于加入光照注意力图,使得STGIE能更好处理光照不均衡的图像,因此,在这类数据集中具有较好的表现。值得注意的是,相比于同样采用GAN架构的EnlightenGAN方法,STGIE的性能有着显著的提升,STGIE方法具有良好的泛化性能。
3.3 试验结果定性分析
3.3.1 图像修饰定性分析使用FiveK数据集,以512×341的分辨率为基准,对比了STGIE与其他同时代方法的增强效果。选取了代表性结果进行定性分析,结果如图6图像修饰对比试验定性分析所示。为了更清晰地观察图像中差异明显的区域,将红色和绿色框内场景进行放大,并将其显示在图像空旷区域或图像右侧。
相较于其他方法,STGIE在整体亮度方面调整得更为合适,它充分考虑到了背光区域和曝光区域,并对光照不平衡区域进行了曝光补偿,使得整体亮度与目标图像较为接近,这得益于光照注意力图的设计。在颜色和细节方面,STGIE具有更加鲜艳的视觉效果,在色彩还原度方面表现优异,并且整体的色彩分布也较为接近目标图像结果。
3.3.2 低照度增强定性分析在常规低光照图像数据集LOL以及具有挑战性的低光照数据集MEF、LIME、NPE和DICM下,对低光照图像增强方法性能进行评估。其中,LOL数据集包含成对数据,而其余4个数据集仅包含待增强的低光照图像。由于这些数据集光照极不平衡、色彩分布差异较大,在低光照图像增强领域被认为是具有挑战性的数据集。
在LOL数据下,对STGIE及其他7种低光照增强模型进行比较。图7为不同方法的增强结果。STGIE在局部区域会产生色彩偏差,这是基于GAN生成方法难以避免的问题,例如编制饰品的颜色发生偏差。不过,图像的整体色彩分布仍然接近目标图像,符合人的视觉感知。在图像亮度方面,STGIE的增强结果最接近目标图像。在纹理细节方面,STGIE的增强结果在整体调整和细节保留方面表现良好,物体边缘和细节更接近目标图像。综上所述,STGIE在低光照增强方面表现出色,优于其他模型。
另一方面,为了验证STGIE处理光照分布极不均衡图像的能力,在MEF、LIME、NPE和DICM这4种数据集上对比了STGIE和其他8种不同方法的表现,结果如图8所示。STGIE方法能够合理地调整不同区域的光照分布,同时在整体对比度和色彩饱和度方面表现出色。这可能归因于光照注意力图的设计,使得模型对光照分布更加敏感,能够根据不同区域光照的差异进行不同处理。
综上所述,在成对数据集和非成对数据集下的定性试验结果表明,STGIE方法在处理低光照图像和挑战性较强的图像方面均表现出较好的效果。该方法能够合理地调整图像的色彩和光照,并且在多个数据集下均有较好表现,进一步证明了STGIE方法的泛化性能和鲁棒性。
3.4 模型轻量化和实时性对比为了比较不同方法在模型参数量和实时性方面的差异,对RetinexNet、EnlightenGAN、Zero-DCE、RUAS和3DLUT与STGIE方法进行了对比。采用增强图像的每秒帧数(FPS)作为衡量模型实时性的指标,并计算在处理FiveK数据集500张图像时的平均速度,结果见表6。STGIE方法在模型参数量和增强效率方面具有一定优势。其参数大小为0.311 MB,比RetinexNet、Zero-DCE等方法更为轻量化,更适合在计算资源有限的环境下使用。同时,STGIE方法的处理速度较快,能够以每秒89帧的速度进行图像增强,优于RetinexNet和EnlightenGAN。综上所述,STGIE方法具有轻量级模型和高效率的优点,能够在实际应用中提供更好的性能和用户体验。
4 结 论
1)从颜色调整的角度出发,STGIE使用Transformer网络架构作为生成器主干网络解决了全监督和半监督下的图像增强问题。与其他深度学习方法相比,STGIE使用非成對数据集进行训练,可以充分利用数据集易于获取的优势,提升模型的泛化能力。2)设计了光照注意力图和滑动窗口裁剪策略。通过灰度图,STGIE可以引导光照调整,实现了对光照不同区域的不同调整。采用滑动窗口裁剪策略来增强鉴别器对裁剪区域的特征提取能力,有效避免了图像出现十字形伪影。
3)通過试验验证了STGIE在图像增强2个子任务上的有效性。在图像修饰任务中,图像峰值
信噪比、相似结构度和感知损失分别达到22.97,
0.902和0.089 dB;在低光照增强任务中,图像峰值信噪比提升了13.46%。此外,在无监督评价指标NIQE表现显著提升,平均参数提升了
2.37%。4)针对半监督方法在处理色彩丰富的图像时出现的色差和色彩饱和度不足等问题,虽然STGIE相较于其他方法有显著改善,但仍存在一定的局限性。未来的研究可以尝试从多种色彩空间对图像颜色调整进行约束,以平衡色彩和光线的调整,解决半监督图像增强中色彩饱和度不足的问题。
参考文献(References):
[1]
丁畅,董丽丽,许文海.“直方图”均衡化图像增强技术研究综述[J].计算机工程与应用,2017,53(23):12-17.DING Chang,DONG Lili,XU Wenhai.Review on histogram equalization image enhancement techniques[J].Computer Engineering and Applications,2017,53(23):12-17.[2]RAHMAN S,RAHMAN M M,ABDULLAH M,et al.An adaptive gamma correction for image enhancement[J].EURASIP Journal on Image and Video Processing,2016,35:1-13.[3]KINGSBURY N.Image processing with complex wavelets[J].Philosophical Transactions of the Royal Society of London.Series A:Mathematical,Physical and Engineering Sciences,1999,357(1760):2543-2560.
[4]LAND E H,MCCANN J.Lightness and retinex theory[J].Journal of the Optical Society of America,1971,61(1):1-11.
[5]LORE K G,AKINTAYO A,SARKAR S.LLNet:A deep autoencoder approach to natural low-light image enhancement[J].Pattern Recognition,2017,61:650-662.[6]JIANG Y,GONG X,LIU D,et al.Enlightengan:Deep light enhancement without paired supervision[J].IEEE Transactions on Image Processing,2021,30:2340-2349.[7]HU Y,HE H,XU C,et al.Exposure:A white-box photo postprocessing framework[J].ACM Transactions on Graphics,2018,37(2):1-17.
[8]CHEN Y S,WANG Y C,KAO M H,et al.Deep photo enhancer:Unpaired learning for image enhancement from photographs with gans[C]//Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE,2018:6306 6314.[9]ZHANG R,PFISTER T,LI J.Harmonic unpaired image-to-image translation[C]//International Conference on Learning Representations,Washington DC:ICLR,May6-9,2019.
[10]KOSUGI S,YAMASAKI T.Unpaired image enhancement featuring reinforcement-learning controlled image editing software[C]//Proceedings of the AAAI conference on artificial intelligence.Menlo Park:AAAI,2020,34(7):11296 11303.[11]DOSOVITSKIY A,BEYER L,KOLESNIKOV A,et al.An image is worth 16×16 words:Transformers for image recognition at scale[C]//International Conference on Learning Representations.Washington DC:ICLR,May3-7,2021.[12]ZHENG S,LU J,ZHAO H,et al.Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition.Piscataway,NJ:IEEE,2021:6881-6890.[13]LIU Z,LIN Y,CAO Y,et al.Swin transformer:Hierarchical vision transformer using shifted windows[C]//Proceedings of the IEEE/CVF international conference on computer vision.Piscataway,NJ:IEEE,2021:10012-10022.[14]ESSER P,ROMBACH R,OMMER B.Taming transformers for high-resolution image synthesis[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition.Piscataway,NJ:IEEE,2021:12873-12883.[15]JIANG Y,CHANG S,WANG Z.Transgan:Two pure transformers can make one strong gan,and that can scale up[J].Advances in Neural Information Processing Systems,2021,34:14745-14758.[16]ZHANG Z,JIANG Y,JJIANG J,et al.STAR:A structure-aware lightweight transformer for real-time image enhancement[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision.Piscataway,NJ:IEEE,2021:4106-4115.[17]GUO C,LI C,GUO J,et al.Zero-reference deep curve estimation for low-light image enhancement[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition.Piscataway,NJ:IEEE,2020:1780-1789.[18]LIU R,MA L,ZHANG J,et al.Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhancement[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition.Piscataway,NJ:IEEE,2021:10561-10570.[19]ZENG H,CAI J,LI L,et al.Learning image-adaptive 3d lookup tables for high performance photo enhancement in real-time[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2020,44(4):2058-2073.[20]GUO X,LI Y,LING H.LIME:Low-light image enhancement via illumination map estimation[J].IEEE Transactions on image processing,2016,26(2):982-993.[21]LYU F,LU F,WU J,et al.MBLLEN:Low-light image/video enhancement using CNNs[C]//British Machine Vision Conference.UK:BMVA,2018,220(1):4.[22]ZHANG Y,GUO X,MA J,et al.Beyond brightening low-light images[J].International Journal of Computer Vision,2021,129:1013-1037.[23]XU K,YANG X,YIN B,et al.Learning to restore low-light images via decomposition-and enhancement[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition.Piscataway,NJ:IEEE,2020:2281-2290.
[24]WANG Y,LI X,XU K,et al.Neural color operators for sequential image retouching[C]//European Conference on Computer Vision.Berlin:Springer,2022:38-55.[25]王媛彬,李媛媛,齐景锋,等.基于引导滤波的多尺度自适应矿井低质图像增强方法[J].西安科技大学学报,2022,42(6):1214-1223.WANG Yuanbin,LI Yuanyuan,QI Jingfeng,et al.Multi-scale adaptive mine image enhancement method based on guided filtering[J].Journal of Xian University of Science and Technology,2022,42(6):1214-1223.
[26]WANG Y,WAN R,YANG W,et al.Low-light image enhancement with normalizing flow[C]//Proceedings of the AAAI Conference on Artificial Intelligence.Menlo Park:AAAI,2022,36(3):2604-2612.[27]LI M,LIU J,YANG W,et al.Structure-revealing low-light image enhancement Via robust retinex model[J].IEEE Transactions on Image Processing,2018,27(6):2828-2841.
[28]邵小強,杨涛,卫晋阳,等.改进同态滤波的矿井监控视频图像增强算法[J].西安科技大学学报,2022,42(6):1205-1213.SHAO Xiaoqiang,YANG Tao,WEI Jinyang,et al.Mine surveillance video image enhancement algorithm with improved homomorphic filter[J].Journal of Xian University of Science and Technology,2022,42(6):1205-1213.
(责任编辑:刘洁)
猜你喜欢
通信学报(2022年10期)2023-01-09 12:33:40
中国机械工程(2022年8期)2022-05-09 12:32:02
燃气涡轮试验与研究(2021年6期)2021-08-01 03:09:10
中国机械工程(2021年8期)2021-05-07 05:49:10
海洋信息技术与应用(2020年4期)2021-01-18 06:21:36
国防科技大学学报(2019年4期)2019-07-29 03:40:14
中国生物医学工程学报(2019年5期)2019-07-16 07:56:50
音乐教育与创作(2019年8期)2019-05-16 04:06:34
北京航空航天大学学报(2017年3期)2017-11-23 05:14:58
系统工程与电子技术(2016年5期)2016-11-02 00:37:48
