
基于数理方法的语音重构研究
2023-04-29 10:16:12王咿卜李建文王术
商洛学院学报 2023年2期
王咿卜 李建文 王术

摘 要:为了维护听障患者的身心健康,探究弱听患者在不同频率段存在的分贝值衰减的现象,从语音的发音原理出发,采用自相关函数法、倒谱法分别对语音信号进行基频、共振峰提取。通过语谱图探究基频曲线与共振峰的相关性,采用曲线函数拟合法对基频进行拟合,采用帧重叠相加法实现语音合成。进一步调整特征参数值实现语音重构,总结听障患者在不同频段的分贝值变化规律。结果表明,对于语音重构函数,在特定频率段内改变分贝值能够有针对性地提升听障患者的听力效果。
关键词:听障患者;基频曲线;共振峰;帧重叠相加法;语音重构
中图分类号:TN912.33 文献标识码:A 文章编号:1674-0033(2023)02-0062-09
引用格式:王咿卜,李建文,王术.基于数理方法的语音重构研究[J].商洛学院学报,2023,37(2):62-70.
Abstract: In order to maintain the physical and mental health of hearing impaired patients, and explore the phenomenon of attenuation of decibel values in different frequency bands for patients with hearing impairment, starting from the pronunciation principle of speech, the autocorrelation function is used to extract the fundamental frequency of the speech signal, and the cepstrum is used to extract the formant of the speech signal. The correlation between the fundamental frequency curve and the formant is explored through the spectrogram. The fundamental frequency is fitted by the curve function fitting method, and the speech synthesis is realized by the frame overlap addition method. Further adjust the value of the feature parameters to realize speech reconstruction, and summarize the change rule of decibel value of hearing impaired patients in different frequency bands. The results show that for the reconstructed speech function, changing the decibel value in a specific frequency range can purposefully improve the hearing effect of hearing -impaired patients.
Key words: the hearing impaired; the fundamental frequency curve; formant; the frame overlap addition method; speech reconstruction
聲音是人们实现信息交互的重要途径之一。然而,据世界卫生组织发布的数据,目前全球有五分之一的人听力受损,在我国则有2 000多万人,听力患者人口基数大。有调查显示,长期的听力障碍会对听障患者身心的健康发展产生不良影响[1]。听障患者进行助听工作的主要途径有两种,一种是进行人工耳蜗手术,另一种是佩戴助听器。传统的人工耳蜗技术是用于重建听觉的植入式电子装置,普遍用于听力差的患者。助听器通过外部佩戴将接收到的声音放大,使患者能够听到声音[2]。韦芮[3]探讨了人工耳蜗植入前后耳鸣与焦虑、抑郁的相关性,发现对于术前伴有耳鸣的人工耳蜗植入候选者,植入人工耳蜗对耳鸣具有积极作用,但随着耳鸣严重程度增加,其焦虑及抑郁程度均增加。魏爽等[4]提出基于动态字典学习的欠定盲语音重构算法,利用正则化Sim CO字典学习对信号进行稀疏表示,依据最速下降思想得到信号恢复的总体最优解,提高了欠定盲语音的重构质量,该研究基于动态学习,依靠构建信号中最优的稀疏表示特征,但忽略了语音信号在现实情况下的复杂性,由于语音特征随时间变化,因此各个语音时段的特征都对语音重构具有不可或缺性。郝雪莹[5]提出一种语音增强算法来降低频率响应,解决了声源与附近物体之间的共振导致的频率响应问题,提高了重建语音的准确性,该研究重构了语音的正弦信号,但未考虑到汉语语音关于声调问题的影响,忽略了语音声调对汉语表意的重要性。人工耳蜗手术复杂、成本高、需要定期维护,且植入后可能引发细菌性脑膜炎等其他疾病,因此仅适用于中重度患者[6-7]。对于轻度患者,适合佩戴新型或改进型助听器,但对于听力损失较轻的患者,由于助听器的功率过大导致噪音偏大,会增加佩戴者的焦虑感,产生的听力负荷还可能会加重听力损失程度。本研究从语音的形成原理出发,旨在解决助听器可能破坏残余听力结构的问题。首先,通过语谱图分析声音的特征参数——基音频率和共振峰,探究语音参数之间的相关性。其次,通过算法将语音的特征参数进行提取,通过曲线函数拟合基频曲线,进一步形成共振峰所在曲线。最后,基于帧重叠相加法进行语音重构,通过提取特征参数、调整分贝值大小,实现听障患者的听力提升,维护听障患者身心健康。
1 语音频谱分析
1.1 语谱图
已知由振动产生的声音是由基音与泛音形成的复合音。基音由发音源振动产生,是频率最低的正弦波,各次谐波的微小振动所产生的声音称泛音。复合音的振幅是基音与泛音振幅进行带方向的叠加。复合音的振动频率包含两部分,一部分是基音的频率,简称基频,基频大小决定了语音音调的高低;另一部分是泛音产生的谐波频率,谐波频谱和包络决定了声音的音色[8-10]。
语音信号在宏观上是不平稳的,在微观上(10~30 ms)可以认为语音信号近似不变,因此首先采用时域分帧法对语音x(t)进行离散化处理,得到的语音信号为x(n)[11],分帧公式为:
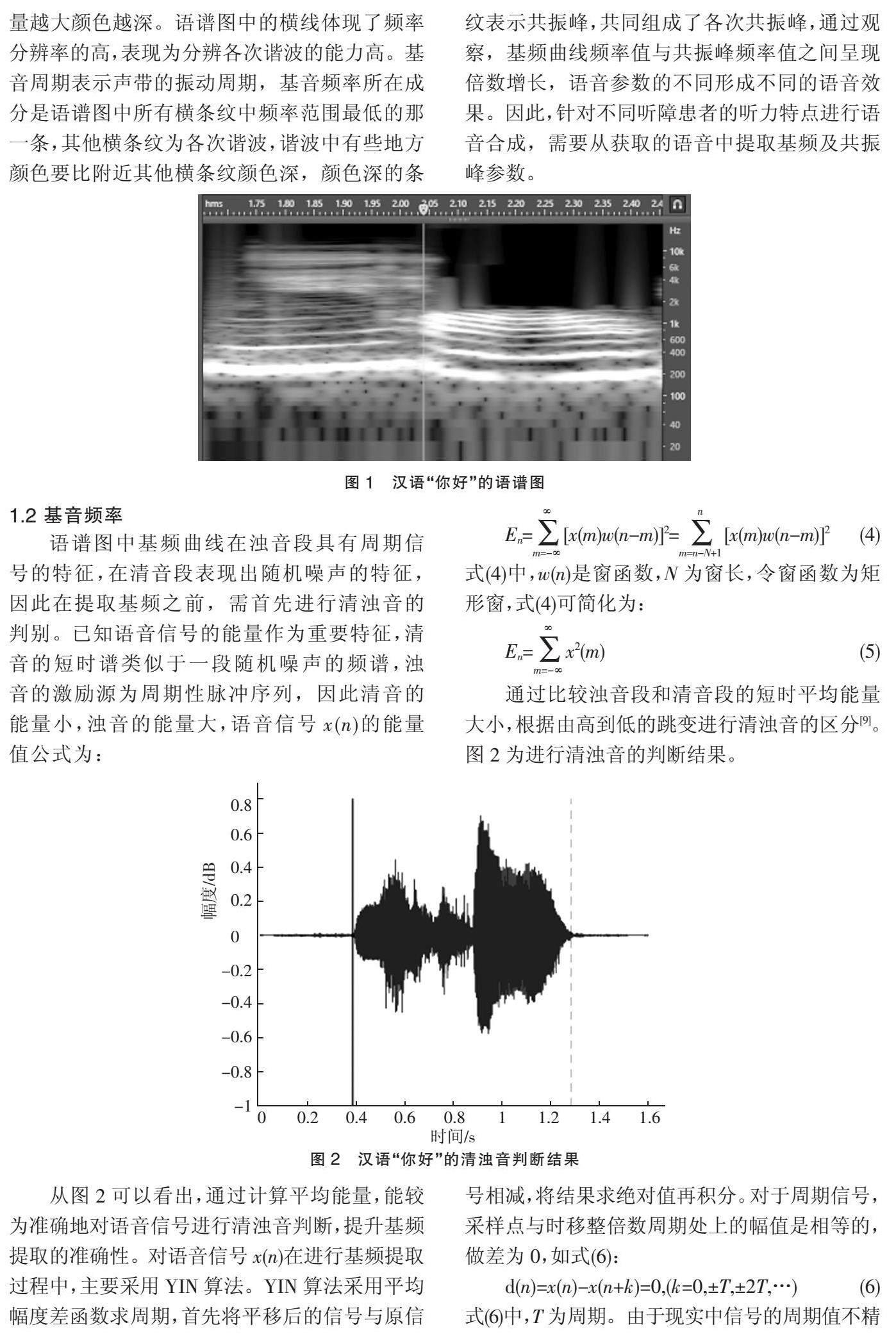
通过傅里叶变化得到的频谱函数为Xi(K),使得语音波形可以分解为不同频率正弦波的组合,如图1为汉语“你好”的语谱图。
在图1语谱图上的数据作为语音信号的特征,其中,横坐标为语音时长(单位:s),纵坐标为频率(单位:Hz),坐标点值为语音数据能量,能量越大颜色越深。语谱图中的横线体现了频率分辨率的高,表现为分辨各次谐波的能力高。基音周期表示声带的振动周期,基音频率所在成分是语谱图中所有横条纹中频率范围最低的那一条,其他横条纹为各次谐波,谐波中有些地方颜色要比附近其他横条纹颜色深,颜色深的条纹表示共振峰,共同组成了各次共振峰,通过观察,基频曲线频率值与共振峰频率值之间呈现倍数增长,语音参数的不同形成不同的语音效果。因此,针对不同听障患者的听力特点进行语音合成,需要从获取的语音中提取基频及共振峰参数。
1.2 基音频率
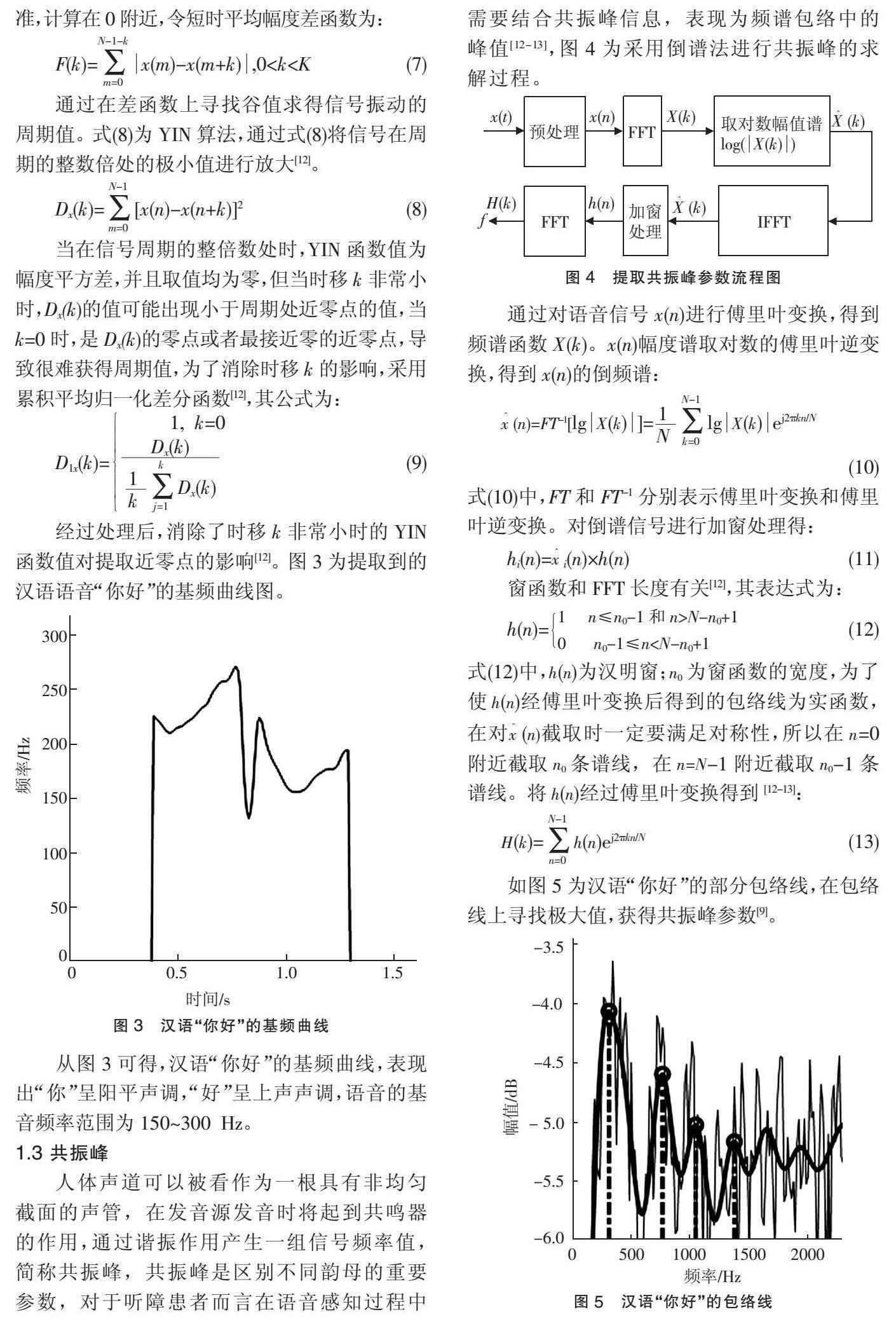
语谱图中基频曲线在浊音段具有周期信号的特征,在清音段表现出随机噪声的特征,因此在提取基频之前,需首先进行清浊音的判别。已知语音信号的能量作为重要特征,清音的短时谱类似于一段随机噪声的频谱,浊音的激励源为周期性脉冲序列,因此清音的能量小,浊音的能量大,语音信号x(n)的能量值公式为:
经过处理后,消除了时移k非常小时的YIN函数值对提取近零点的影响[12]。图3为提取到的汉语语音“你好”的基频曲线图。
从图3可得,汉语“你好”的基频曲线,表现出“你”呈阳平声调,“好”呈上声声调,语音的基音频率范围为150~300 Hz。
1.3 共振峰
人体声道可以被看作为一根具有非均匀截面的声管,在发音源发音时将起到共鸣器的作用,通过谐振作用产生一组信号频率值,简称共振峰,共振峰是区别不同韵母的重要参数,对于听障患者而言在语音感知过程中需要结合共振峰信息,表现为频谱包络中的峰值[12-13],图4为采用倒谱法进行共振峰的求解过程。
从图5可得,在共振峰频率提取过程中,对于汉语“你好”的包络线,能较为清晰地对语音起重要作用的前四个共振峰频率分别为312.50,765.62,
1 046.88,1 375 Hz,频率关系呈倍数增长。
2 语音重构
2.1 基频曲线拟合
观察语谱图,对于同一语音的共振峰曲线与基频曲线,所在频率段不一样,但曲线走势相同。因此,首先对提取到的基频曲线采用函数进行拟合,再通过平移基频曲线得到共振峰曲线。在听障患者的听觉系统中,针对患者具体的听力情况,对语谱图上不同频率段内的音频曲线进行专门调整,提高特殊频率段内曲线的分贝值,能够保证患者在听力不受损的情况下,有效地提高听力效果。
一般来讲,人通过听觉能感知的声音为20~20 000 Hz,范围为0~130 dBHL。依据世界卫生组织指定的听力障碍的分级标准,以较好耳500,1 000,2 000,4 000 Hz的平均纯音听阈为依据将听力障碍分为四级:26~40 dBHL为轻度,41~60 dBHL为中度,61~80 dBHL为重度,>81 dBHL为极重度,而将儿童听力残疾定义为:较好耳500,1 000,2 000,4 000 Hz的4个频率永久性非助听听阈级平均值≥31dB HL[6,16]。
非老年性弱听及老年性耳聋听力特点:非老年性弱听指患者在特定频率段内,出现分贝值衰减而导致的听力效果下降。老年性耳聋一般从40岁开始出现,逐渐减退,主要是由于听觉器官的衰老、退变而出现的,因此双耳对听力的感知几乎是对称的、缓慢进行的听力减退,属于生理范畴。
对于大部分听障患者来说,只有通过助听器进行语音的放大来实现语音的重构。语音中含有的能量,其中低频率段为500 Hz以下,占据60%的能量;中频率段为500~1 000 Hz,占据35%的能量;剩下的为高频率段,占据极微少的能量。麦克风主要增强中频段,而中频段内又分为很多频率,对于不同的音,发音频段的分贝值的不同会产生不同的听觉结果。
3.2 合成结果测试
对于语音合成函数,在20~20 000 Hz范围内选择性调整分贝值进而影响语音听觉效果[9]。由于分贝值在3 dB变化,人耳刚好能够感受到声音大小的差异,为了保护人耳残余的听觉,令Ampm=3k,其中k为3 dB的倍数级,根据具体听障患者的音域进行分贝值大小的调整公式為:
式(29)中m1≤m≤m2,m1=round(f1/f0),m2=round(f2/f0)。若听障患者在200~400 Hz频率段有听力衰减,如图8为再合成语音(分贝值增加)和原始语音语谱图对比结果,如图9、图10分别为原始语音不同频段的分贝值、再合成语音不同频段的分贝值。
在图8语谱图中,原始语音由于受到外界及生理因素的影响,高亮条纹处存在大量模糊的阴影,在一定程度上影响了整体语音的清晰度,而再合成后的语音,不仅有效地保留了原始语音中的重要频率段,保证了语音具有的谐振特性,还减少了外界因素的干扰,频谱曲线的边界轮廓更加清晰。试验中,若听障患者听到声音具有发飘、不坚实的现象,通过判断在300~400 Hz频段存在分贝值衰减,针对该现象,对合成的语音函数在相应频段进行分贝值增强。图9中,调整前的分贝值为-25.54 dB,在整段频域范围内,峰值周围还存在其他谐振波的现象,在非关键频率段内,谐振波的分贝值较高。图10为对基频曲线进行分贝值调整后的结果,图中基频曲线调整之后分贝值变为-22.62 dB,据测试,经过调整后能使患者具有更好的听觉效果,针对性的分贝值增强同时也保护了患者的残余听力。
试验选取30名听障患者为研究对象,被试者均为听力模糊患者,且利用助听器进行听力重建水平皆为较适水平以上(语音最大识别率在65%以上),排除因智力因素对本研究的影响。针对听障患者的听力特点,对不同语音在不同频段调整分贝值进行语音再合成,通过表2可以观察到不同频段内分贝值对人的听觉感受的影响,进一步为助听器的后续升级提供参考。
通过函数拟合原始语音进行针对性的语音再合成,对试验测试人员进行收听效果对比,如表3为不同音频补偿范围内增加分贝值得到的再合成语音,较原始语音、合成语音关于平均识别率的对比情况,再合成语音相比于普通助听器关于听损程度的变化情况。由表3可得,在不同音频补偿范围内对于20~100 Hz,再合成语音较原始语音、合成语音,关于平均识别率有一定程度地提升,在频率范围为100~500 Hz内,再合成语音较原始语音、合成语音,关于平均识别率显著提升这是由于男女的基音频率在此范围内,而对于1 000~2 000 Hz频段,处于较高频,对语音整体影响较小,因此平均识别率提升效果不明显,综合分析表3,对听障患者的听力保护均有提升。
4 结语
本研究通过观察语谱图,挖掘特征参数之间的相关性,提取语音形成的两大特征——基频和共振峰。通过分析语音的形成原理,探究语音的数理本质,根据特征参数值进行函数化的合成,形成初步的合成语音。研究进一步根据听障患者特点及语音特点,有针对性地调整函数中相关的特征参数值,进一步实现语音再合成,一方面,降低了外界及生理因素对语音产生的影响,另一方面,避免了助听器因整体扩大分贝值对听障患者听力健康产生的影响,维护了听障患者的身心健康,对于助听器产品的改善具有一定参考意义。
参考文献:
[1] 李胜利,孙喜斌,王荫华,等.第二次全国残疾人抽样调查言语残疾标准研究[J].中国康复理论与实践,2007(9):801-803.
[2] 费樱平,郑芸,张林,等.骨传导助听器选配效果分析[J].中国听力语言康复科学杂志,2022,20(5):361-363,367.
[3] 韦芮,陈善文,唐开新,等.人工耳蜗植入前后耳鸣与焦虑、抑郁相关性分析[J].听力学及言语疾病杂志,2022,30(4):432-435.
[4] 魏爽,王晓楠,杨璟安.基于动态字典学习的欠定盲语音重构算法[J].计算机工程与设计,2022,43(5):1351-1357.
[5] HAO X Y, ZHU D L, WANG X L, et al. A speech enhancement algorithm for speech reconstruction based on laser speckle images[J].Sensors,2022,23(1):330-330.
[6] 芦婷,周馨宇,赵霞,等.听障儿童人工耳蜗植入术后生活质量评估及影响因素分析[J].宁夏医学杂志,2021,43(8):718-721.
[7] SLADEN D P, NIE Y, BERG K. Investigating speech recognition and listening effort with different device configurations in adult cochlear implant users[J].Cochlear Implants International,2018,19(3):119-130.
[8] 顾晰,吴小波,林有辉,等.人工耳蜗植入术后皮瓣相关并发症的临床特点及处理方法分析[J].中华耳科学杂志,2018,16(6):765-771.
[9] 王咿卜.基于基频控制的语音合成的研究[D].西安:陕西科技大学,2021:1-82.
[10] YANG J H. The application of speech synthesis technology based on deep neural network in intelligent broadcasting[J].Journal of Control Science and Engineering,2022,2022(4):1-6.
[11] 吳进.语音信号处理实用教程[M].北京:人民邮电出版社,2015:225,230-349.
[12] 马效敏,郑文思,陈琪.自相关基频提取算法的MATLAB实现[J].西北民族大学学报(自然科学版),2010,31(4):54-58,63.
[13] 张岩,王伟.基于YIN算法的乐器单旋律音高的提取[J].沈阳师范大学学报(自然科学版),2020,38(5):438-442.
[14] 张永涛,贾延明.最小二乘法中代数多项式曲线拟合的分析及实现[J].计算机与数字工程,2017,45(4):637-639,654.
[15] 李建文,王咿卜.函数拟合实现带声调的语音合成[J].计算机应用与软件,2022,39(9):193-200.
[16] 刘艳慧.聋儿助听器佩戴前后听力检测在WHO和ANSI分级标准中的应用分析[J].中国卫生标准管理,2014,5(13):123-124.
