
基于BERT-GCN的因果关系抽取
2023-04-29 22:47李岳泽左祥麟左万利梁世宁张一嘉朱媛
吉林大学学报(理学版) 2023年2期
关键词:自然语言处理
李岳泽 左祥麟 左万利 梁世宁 张一嘉 朱媛


摘要: 针对自然语言处理中传统因果关系抽取主要用基于模式匹配的方法或机器学习算法进行抽取,结果准确率较低,且只能抽取带有因果提示词的显性因果关系问题,提出一种使用大规模的预训练模型结合图卷积神经网络的算法BERT-GCN. 首先,使用BERT(bidirectional encoder representation from transformers)对语料进行编码,生成词向量; 然后,将生成的词向量放入图卷积神经网絡中进行训练; 最后,放入Softmax层中完成对因果关系的抽取. 实验结果表明,该模型在数据集SEDR-CE上获得了较好的结果,且针对隐式的因果关系效果也较好.
关键词: 自然语言处理; 因果关系抽取; 图卷积神经网络; BERT模型
中图分类号: TP391 文献标志码: A 文章编号: 1671-5489(2023)02-0325-06
Causality Extraction Based on BERT-GCN
LI Yueze1,ZUO Xianglin1,ZUO Wanli1,2,LIANG Shining1,ZHANG Yijia3,ZHU Yuan3
(1. College of Computer Science and Technology,Jilin University,Changchun 130012,China;
2. Key Laboratory of Symbol Computation and Knowledge Engineering of Ministry of Education,Jilin University,Changchun 130012,China;
3. College of Software,Jilin University,Changchun 130012,China)
Abstract: Aiming at the problem that the traditional causality extraction in natural language processing was mainly based on pattern matching methods
or machine learning algorithms,and accuracy of the results was low,and only explicit causality with causal cue words could be extracted,we proposed an algorithm BERT-GCN using large-scale pre
training model combined with graph convolutional neural network. Firstly, we used BERT (bidirectional encoder representation from transformers)
to encode the corpus and generate word vectors. Secondly, we put the generated word vectors into the graph convolutional neural network for training. Finally,we put them into the Softmax
layer to complete the extraction of causality. The experimental results show that the model obtains good results on the SEDR-CE dataset,and the effect of implicit causality is also good.
Keywords: natural language processing; causality extraction; graph convolutional neural network (GCN); bidirectional encoder representation from transformers model
收稿日期: 2022-01-07.
第一作者简介:
李岳泽(1997—),男,汉族,硕士研究生,从事自然语言处理和因果关系的研究,E-mail: yzli19@mails.jlu.edu.cn.
通信作者简介: 左万利(1957—),男,汉族,博士,教授,博士生导师,从事Web挖掘、 自然语言处理、 机器学习、 深度学习和网络搜索引擎的研究,E-mail: zuowl@mails.jlu.edu.cn.
基金项目: 国家自然科学基金(批准号: 61976103)、 吉林省技术攻关项目(批准号: 20190302
029GX)和吉林省自然科学基金(批准号: 20180101330JC; 20180520022JH).
因果关系抽取是目前自然语言处理领域中的主要难题,已引起研究者们的广泛关注. 因果关系表示客观事件之间的一种普遍联系,由两个事件组成,即原因事件和结果事件. 因果关系抽取目标任务主要分为两类: 显式因果,即含有明显因果关系提示词(如因为,所以等); 隐式因果,即没有明显的因果关系提示词,只能通过语义以及上下文进行推理得到.
传统的因果关系抽取主要使用基于模式匹配、 机器学习、 或者将两者结合的方法. 基于模式匹配的方法使用符号特征以及语义特征抽取出文本中的因果关系. 文献[1]使用模式匹配及语言信息从《华尔街日报》中提取了因果关系知识; 文献[2]使用句法模型抽取因果关系,然后使用语义约束判断候选事件实体对是否含有因果关系; 文献[3]使用一种依赖语法关系及显性因果提示词构建模板进行因果对提取的方法. 完全依赖于模式匹配的方法通常只能提取出显性因果关系,且不具有可迁移性,对于特定的文本可能效果较好,如果更换文本类型可能会导致结果较差. 基于模式匹配和机器学习相结合的方法主要使用Pipeline方法解决因果关系抽取任务. Pipeline方法将因果关系抽取分为两个子任务: 提取候选因果对和关系分类. 先使用模板或者因果提示词提取出可能含有因果关系的事件实体,然后结合语义特征建模,用机器学习方法对候选事件实体进行分类,最终得到因果事件实体对. 但基于Pipeline的方法存在几个不足: 1) 误差累积,第一阶段实体识别产生的错误不能在下一阶段得到纠正,会产生错误传播,影响因果关系抽取; 2) 交互缺失,忽略了前后两个任务之间的内在联系和依赖关系; 3) 实体冗余,由于先对抽取的因果关系实体进行两两配对,然后再进行分类,没有关系的候选实体对所带来的冗余信息会提升错误率,增加计算复杂度. 文献[4]使用因果提示词提取英文文本中的因果关系; 文献[5]从网络爬取的大规模文本语料库中提取因果关系事件实体,然后使用点互信息的统计方法衡量网络因果关系实体之间的因果强度. 随着计算机技术的发展,使得深度学习模型的训练成为可能,深度学习的主要优势在于其有强大的表征学习能力,能有效捕捉隐性因果关系,因此使用深度学习的方法已成为该领域发展的趋势. 文献[6]使用卷积神经网络对文本的因果关系进行了分类; 文献[7]使用卷积神经网络从含有干扰信息的文本中提取背景知识分类常识性的因果关系; 文献[8]使用面向知识的卷积神经网络,使用词汇库等先验知识辅助因果关系分类; 文献[9]使用长短期记忆网络(long short-term memory,LSTM)模型,根据模型提取的文本深层次特征抽取因果关系.
目前在因果关系抽取领域缺乏公开的数据集,并且不同的数据集使用不同的标注方法. 针对该问题,本文从系列数据集SemEval以及数据集DocRED中抽取数据,制定规则重新标注. 并将BERT(bidirectional encoder representation from transformers)以及图卷积神经网络(GCN)[10]應用到因果关系抽取领域. 本文采用BERT-GCN模型进行因果关系抽取,先使用BERT将文本信息转换为词向量,再以词向量为节点,构建因果关系权重图,使用图卷积神经网络进行学习,抽取事件之间的因果关系. 在因果关系文本数据样本信息较少、 因果关系本身的语义特点隐晦并且较难抽取的情况下,使用BERT和图卷积神经网络能取得较好的结果.
1 BERT-GCN的模型结构
1.1 BERT
BERT是基于Transformers的预训练模型[9],Transformers是一个包含多层堆叠的编码器和解码器结构的模型. 多头的注意力网络和全连接的前馈神经网络是该模型的两个核心组成部分.
1.1.1 词表示层
由于计算机并不能像人一样可以直观理解文字的含义,只能识别数字0和1组成的字符串向量,因此需要将文字转化为计算机可以理解的向量形式,这种转化方式称为词向量. 传统的词向量主要有word2vec和glove. 但这些词向量的表示无法解决多义词的现象. 一个词在不同的语境中有不同的含义,但使用这些词向量的表示,一个词只有一个词向量,无法解决一词多义问题. 例如“这张书桌是一个老古董”和“这个人简直是一个不可理喻的老古董”中的“老古董”含义是不相同的,前者形容书桌年代久远,有收藏价值,是褒义词; 后者形容人思想老旧顽固,是贬义词. 使用BERT生成词向量即可解决该问题,在BERT中一个词可根据上下文语义从多个词向量中进行选取,提高了模型准确率.
BERT词向量由三部分组成,即Token Embedding,Segment Embedding和Position Embedding. Token Embedding包含当前单词的上下文信息; Segment Embedding主要用来区分文本中句子的顺序; Position Embedding主要是表示当前单词的位置属性,可区分不同位置的相同单词. BERT模型的Embdding表示如图1所示.
2 实 验
2.1 数据来源
本文实验数据集为SemEval 2010 Task8,SemEval 2020 Task5和DocRED,选取SemEval 2010 Task8中的1 368个句子,SemEval 2020中的2 485个句子,并从DocRED中摘取了500篇文档,进行重新标注,最终得到8 205个包含因果关系实体的句子,并加入8 000条不含因果的句子作为负样本,实现正负样本均衡. 本文将最终得到的数据集命名为SEDR-CE,并按7∶2∶1将数据分为训练集、 验证集和测试集.
2.2 数据标注规则
使用BIO(B-begin,I-inside,O-outside)标注规则,对因果实体短语进行标注,将每个因果实体对标注为“B-X”、 “I-X”或者“O”. 其中: “B-C”表示该因果实体对所在的片段属于原因类型,并且该元素在该片段的开头; “I-C”表示该元素所在的片段属于原因类型,并且该元素在该片段的中间位置; “B-E”表示该因果实体对所在的片段属于结果类型,并且该元素在该片段的开头; “I-E”表示该元素所在的片段属于结果类型,并且该元素在该片段的中间位置; “O”表示不属于任何类型. 具体标注方法列于表1.
2.3 模型评估
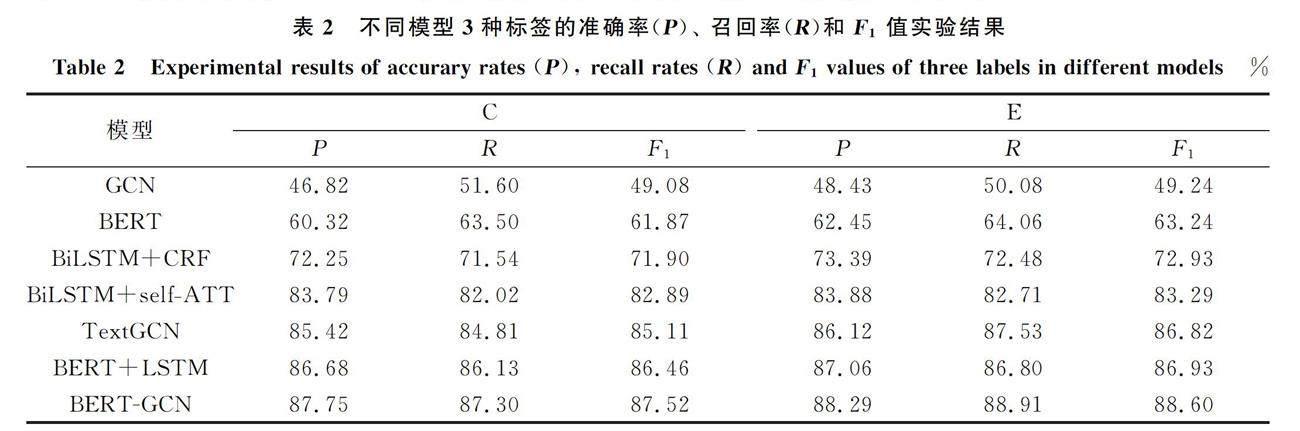
本文主要使用抽取3种标签的“原因”(C)、 “结果”(E)和“其他”(O)的准确率(P),召回率(R)以及F1值作为评价指标. 由于文章中大部分的单词被标注为“其他”(O),并且“其他”(O)不是本文实验的关注重点,因此本文主要根据抽取的标签“原因”(C)和“结果”(E)的3个指标判定模型性能.
2.4 对比模型
为验证本文BERT-GCN模型抽取因果关系实体的性能,本文选取6个模型做对比实验,其中包含3个基准模型: GCN,BERT,BERT+LSTM; 以及3个主流模型: TextGCN[14],BiLSTM+CRF[15],BiLSTM+self-ATT[16]. 本文将上述模型中的语义角色标签修改为本文标注格式进行因果关系抽取.
2.5 实验结果与分析
本文主要考虑因果关系的抽取,因此主要关注“原因”(C)和“结果”(E)的各项粗粒度指标,实验结果列于表2. 由表2可见,本文提出的BERT-GCN模型优于其他模型,在本文所构建的数据集上有较好的识别效果,“原因”(C)的准确率达87.75%,召回率达87.30%,F1值达87.52%,“结果”(E)的准确率达88.29%,召回率达88.91%,F1值达88.60%. 在本文构建的数据集上,对比实验效果最好的是BERT+LSTM和BERT-GCN,这主要是因为BERT模型有大量的预训练语料,使构建的词向量表征能力更强,更好地学习到了文本中的因果关系,证明使用大规模的预训练模型对因果关系抽取任务有显著提升. 实验结果表明,GCN模型相比LSTM在因果关系抽取任务上的性能更好,这主要是因为图卷积神经网络中的卷积操作相比LSTM中的单向按语序学习到更多的上下文信息,有助于因果关系的抽取,使用Softmax对卷积结果进行分类筛选对模型的性能也有提升.
综上所述,针对自然语言处理中传统因果关系抽取主要用基于模式匹配的方法或机器学习算法进行抽取,结果准确率较低,且只能抽取带有因果提示词的显性因果关系问题, 本文提出了一个基于大规模预训练和图神经网络的模型,通过在因果关系抽取任务中引入图卷积神经网络,结合大规模预训练模型,不仅能提取出每个单词更丰富的序列特征,而且使模型能更好地提取单词的局部信息. 使用图卷积神经网络不仅能考虑到所有事件实体对之间的隐含关系,而且能较好地解决关系重叠的问题. 在本文数据集上评估该方法的实验结果表明,该方法性能较优.
參考文献
[1] KHOO C S G,KORNFILT J,ODDY R N,et al. Automatic Extraction of Cause-Effect Info
rmation from Newspaper Text without Knowledge-Based Inferencing [J]. Literary and Linguistic Computing,1998,13(4): 177-186.
[2] GIRJU R,MOLDOVAN D. Text Mining for Causal Relations [C]//Proceedings of the 15th International Florida Artificial Intelligence Res
earch Society Conference. Palo Alto,CA: AAAI Press,2002: 360-364.
[3] ITTOO A,BOUMA G. Extracting Explicit and Implicit Causal Relations from Sparse,Domain-Specific Texts [C]//Proceedings of 16th In
ternational Conference on Applications of Natural Language to Information Systems. Berlin: Springer,2011: 52-63.
[4] GIRJU R. Automatic Detection of Causal Relations for Question Answering [C]//Proceedings of the ACL 2003 Workshop on Multilingual S
ummarization and Question Answering. Stroudsburg,PA: Association for Computational Linguistics,2003: 76-83.
[5] LUO Z Y,SHA Y C,ZHU K Q,et al. Commonsense Causal Reasoni
ng between Short Texts [C]//Proceedings of the 15th International Conference on Principles of Knowledge Representation and Reasoning. Palo Alto,CA: AAAI Press,2016: 421-430.
[6] DE SILVA T N,XIAO Z B,ZHAO R,et al. Causal Relation Identification Using Convolutional Neural Networks and Knowledge Based Features [J]
. World Academy of Science,Engineering and Technology: International Journal of Mechanical and Mechatronics Engineering,2017,11(6): 703-708.
[7] KRUENGKRAI C,TORISAWA K,HASHIMOTO C,et al. Improving Event Causality Recognition with Multiple Background Knowledge Sources Using M
ulti-column Convolutional Neural Networks [C]//Proceedings of the 31st AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2017: 3466-3473.
[8] LI P F,MAO K Z. Knowledge-Oriented Convolutional Neural Ne
twork for Causal Relation Extraction from Natural Language Texts [J]. Expert Systems with Applications,2019,115: 512-523.
[9] DASGUPTA T,SAHA R,DEY L,et al. Automatic Extraction of Causal Relations from Text Using Linguistically Informed Deep Neural Networks
[C]//Proceedings of the 19th Annual SIGdial Meeting on Discourse and Dialogue. Stroudsburg,PA: Association for Computational Linguistics,2018: 306-316.
[10] KIPF T N,WELLING M. Semi-supervised Classification with Graph Convolutional Networks [EB/OL].
(2016-09-09)[2022-03-01]. https://arxiv.org/abs/1609.02907.
[11] VASWANI A,SHAZEER N,PARMAR N,et al. Attention Is All
You Need [C]//Advances in Neural Information Processing Systems. New York: ACM,2017: 5998-6008.
[12] 付剑锋,刘宗田,刘炜,等. 基于层叠条件随机场的事件因果关系抽取 [J]. 模式识别与人工智能,2011,24(4): 567-573. (FU J F,LIU Z T,
LIU W,et al. Event Causal Relation Extraction Based on Cascaded Conditional Random Fields [J]. Pattern Recognition and Artificial Intelligence,2011,24(4): 567-573.)
[13] 許晶航,左万利,梁世宁,等. 基于图注意力网络的因果关系抽取 [J]. 计算机研究与发展,2020,57(1): 159-174. (XU J H,ZUO W L,LIANG
S N,et al. Causal Relation Extraction Based on Graph Attention Networks [J]. Journal of Computer Research and Development,2020,57(1): 159-174.)
[14] YAO L,MAO C S,LUO Y. Graph Convolutional Networ
ks for Text Classification [C]//Proceedings of the AAAI Conference on Artificial Intel-Ligence. Palo Alto,CA: AAAI Press,2019: 7370-7377.
[15] HUANG Z H,XU W,YU K. Bidirectional LSTM-CRF Mode
ls for Sequence Tagging [EB/OL]. (2015-08-09)[2021-11-11]. https://arxiv.org/abs/1508.01991.
[16] TAN Z X,WANG M X,XIE J,et al. Deep Semantic Role Labelin
g with Self-attention [C]//Thirty-Second AAAI Conf on Artificial Intelligence. Palo Alto,CA: AAAI Press,2018: 1-8.
(责任编辑: 韩 啸)
猜你喜欢
计算技术与自动化(2017年3期)2017-10-26
魅力中国(2017年24期)2017-09-15
中国市场(2016年39期)2017-05-26
电子技术与软件工程(2016年24期)2017-02-23
计算机应用(2016年12期)2017-01-13
电脑知识与技术(2016年10期)2016-06-16
求知导刊(2016年10期)2016-05-01
电脑知识与技术(2016年5期)2016-04-14
科技视界(2016年5期)2016-02-22
电脑知识与技术(2015年11期)2015-06-24
