
基于CAN数据的渣土车驾驶行为分析
2023-04-26 08:39:58姚文钦黄伶俐
计算机测量与控制 2023年4期
李 洋,苟 刚,姚文钦,黄伶俐
(1.贵州大学 计算机科学与技术学院 公共大数据重点实验室,贵阳 550025;2.花溪区人民检察院,贵阳 550025)
0 引言
随着互联网技术的发展与城镇化进程的加快,城市的发展离不开城市建设工程以及汽车工业的支持。由于人口的发展,建筑工程会不断增加,城市的渣土量会日益增多,近年来渣土车的数量也在逐年攀升。在货运行业中,一直以来,渣土运输行业普遍存在着一些管理难的现象,使管理者无法有效的管控车辆的运行、安全及驾驶员等情况。
2019年9月6日,交通运输部、我国税务总局发布了《网络平台道路货物运输经营管理暂行办法》,对网络货运经营者的法律定位、行为规范和对监督管理机关的监管责任等提出了明确要求,也为货运行业规范健康发展提供了良好的制度环境。一辆渣土车[1]在国道上的超限站限重50吨,合法载重34吨左右,在记重收费的高速公路上限重45吨,合法载重29吨左右。在渣土车运输的情况下,其扬尘、遗漏建筑垃圾、驾驶行为不端等不良现象会给道路交通安全[2]造成一定的威胁。在交通安全中,有以下因素主要影响着道路交通安全:交通参与者、交通量、道路线形、自然环境等各方面的影响。其中交通参与者对交通安全的影响程度最大[3]。同时为了协助驾驶员增强行车安全意识,降低安全事故的产生,国内外在这一方向的研究者们针对驾驶行为开展了大量的研究工作,研究发现,记录下行车过程中的不良驾驶行为并使驾驶员能够及时看见自身驾驶行为的反馈情况,可有效降低驾驶员在驾驶过程中危险性驾驶行为的出险概率。
廖向阳[4]等人通过OBD接口来接入车辆的CAN(CAN,controller area network)总线,通过收集和分析CAN总线报文,得到了车辆正常行驶时的十二个主要运行特征参数及具体数据。从而实现了对车辆运行状况的数据化、可视化展示以及对异常工作情况的及时预警。许静雯[5]等人通过因子分析提取与驾驶员行为相关的特征参数,来筛选特定的车辆样本,通过聚类来对车辆驾驶行为危险程度进行分级,探究高速公路上重点营运车辆的驾驶行为规律,以便及时确定驾驶行为具有危险性的车辆。高宇[6]等人通过对车辆上某保险公司外接的北斗系统内的车辆数据进行分析,来分析车主的驾驶行为和驾驶习惯,并分析其对出险概率的影响,以此降低电力行业工程车的出险概率,提高车辆的利用效率。U.Fugiglando[7]等人利用无监督学习,将不同群体的司机聚集在一起,运用一种验证方法来检测实验中测试聚类的稳健性,同时还提出了一种利用选定的 CAN 总线信号子集对驾驶员行为进行分析和分类的新方法。S.Arumugam[8]等人通过对管理驾驶方式模型的类别来进行详细调查,提出一种解决方案,通过考虑驾驶员的行为和情绪因素来发现侵略性驾驶和路怒事件所带来的风险,有助于保险行业更准确地评估驾驶风险。
研究通过对急加速、急减速、超速、平均速度、发动机平均燃油率等九种驾驶员驾驶行为数据进行分析、检测其个人驾驶倾向[9]以及对其进行驾驶行为进行评分[10],以达到提高渣土车驾驶员的驾驶素质、规范其日常驾驶行为和行车安全意识,减少安全事故发生的目的。
1 数据处理
1.1 数据来源
在数据来源方面主要分为两部分,一部分为CAN总线数据,来自汽车生产商在生产渣土车辆时自主安装的CAN总线,这一安装是为了便于后期车辆在使用时能向上级平台传输CAN总线数据,其相对于使用车辆的OBD接口外接其他设备而言没有更多的外加电路,更具安全性。一部分为车辆的北斗卫星定位数据[11],这一数据由北斗数据运营商提供。这两部分数据的结合能更好的对渣土车驾驶员的驾驶行为进行分析。通过实际考察某公司70位渣土车驾驶员在3个月中的CAN总线数据和北斗定位数据,其中车辆在启动时将以3秒每次的速率发送数据,最终共接收CAN数据3 633 874条,接收北斗定位数据3 424 516条。
1.2 数据解析
渣土车辆北斗定位数据电报的内容包含:时间、经度、纬度、当前时速、方向以及海拔等。在后续工作中,根据报文格式与数据位长度,使用字符串截取函数对报文进行截取,然后将其从16进制转换为10进制,以供研究其它部分使用。其短报文通信定义来自于:《JT/T808-2011道路运输车辆卫星定位系统终端通讯协议及数据格式》,其北斗定位数据解析信息如表1所示,数据组列表中由数据块信息组成,CAN数据解析上传的部分数据块含义如表2所示。

表1 北斗定位数据解析信息

表2 CAN数据部分数据块信息
CAN数据解析首先需判别此段信息的自定义通讯协议的数据传输方式,再获取消息体ID、消息体、消息体属性、消息流水号等信息,若自定义消息体ID为0706,则此信息为车速、开关、油耗等信息,需获取块ID与块个数,根据块ID来区分块的类别,也就是消息属于开关量还是数字量。开关量数据需根据块个数来切分块列表的信息长度,以此获取到偏移时间与数据项列表,通过解析数据项列表来得到需要的信息;数字量数据则需根据块ID与数据项位图确定数据块长度,然后调用相应方法来解析数据块列表信息。
若自定义消息体ID为0785,则此信息为超速行驶、空挡滑行、急转弯等行为信息。根据自定义消息体中数据ID的信息来判别当前的异常行为是什么状态,进而在解析其当前状态的位置与开始结束时间后,存入数据库。
若自定义消息体ID为0200,则此信息为车辆位置数据。同样可获取到消息体ID、消息体、消息体属性、消息流水号等信息。还可获取到8位的16进制报警标识与状态标识,以及经纬度、速度、方向、海拔高度等信息。此时需要对报警标志位进行设定相应内容,拆分消息体报警标志,存入char[]类型的warningMarkChar中,通过循环来获取相应的报警标志位,并对应标志位内容进行解析。
2 驾驶行为倾向性分析
驾驶行为分析模块包含了周行驶里程统计、周行驶速度统计、驾驶员评分、驾驶员倾向性判别。驾驶行为分析主要分析驾驶员在驾驶过程中车辆的CAN总线数据与北斗数据,以此来实现对驾驶员的驾驶行为倾向性判别与驾驶员评分等功能。其中驾驶员的驾驶行为倾向性判别是在利用车辆行驶中驾驶员的定位数据、超速次数、平均速度、发动机平均油耗率、疲劳驾驶次数等数据的基础上,使用K-means聚类算法对渣土车驾驶员的驾驶倾向性进行判别。其中驾驶员评分功能需先使用熵权层次分析法来构建驾驶行为评分模型,再确定模型中每个指标的权重,以此分析每个指标的分值,最后结合实际来对渣土车驾驶员进行综合评分。
2.1 K-means聚类算法
聚类分析即根据数据中描述对象与其关系的信息,将数据对象进行分组。目的是,组内的对象相互之间是相关的,而不同组中的对象是不相关的。相关性越大,组间差距越大,表明聚类效果越好。聚类分析也是数据挖掘的重要手段,它也称为群分析,是研究分类问题的一种统计分析方法。
K-means(K-means clustering algorithm)聚类算法[12]是在聚类分析中一个常用的算法,亦为K-均值聚类,是一种由Macqueen在1967年提出的无监督学习算法,它也是一种简单的迭代性聚类算法,使用距离作为它的相似性指标。所谓无监督学习是指无需知道所要寻找的目标,直接通过算法得到数据的共同特征。K-means算法需指定数据集中的K值,也就是使数据最终分为几个簇(类),迭代时需要使用的每个类的中心也为质心,它是根据类中所有值各维度取平均值得到的。其目的是让每个样本到每个簇中心点的距离越小越好,也就是通过连续迭代的方式将m个样本点划分为K个簇,使得相似的样本被尽可能的分到同一个簇中。该算法具备原理简单、容易理解、速度快等优势,可处理数值、文本、图像等数据,但得事先得确定K值的选取。其具体步骤如下:
1)数据集D中有m个样本点,首先指定需要划分的簇数k,并随机初始化其各自的质心(μ1,μ2,μ3,…,μk∈R)。

(1)
3)次计算每个簇的中心点作为新的质心。
(2)
4)算数据集D中m个样本点的误差平方和Ei,如果|Ei+1-Ei|<δ则表明质心位置变化不大,算法停止,否则返回步骤2再次进行迭代。
(3)
2.2 基于K-means的驾驶倾向性识别
基于CAN数据的解析结果,获取驾驶倾向性分类中所需的特征参数[13],具体包含平均车速、超速次数、行驶里程、急加速、急刹车、发动机转速、超速次数、行驶里程、驾驶时长等特征,每车3秒会发送一次数据,将70辆车每天的数据量进行整合,成为驾驶员当天的数据总和,具体的特征参数如表3所示。

表3 部分样本数据
进行K-Means聚类后,把驾驶员的驾驶行为分成稳健型、一般型、激进型3种,经过K-meams聚类后,对急加速次数、急刹车次数、超速次数等特征数值较大的数据对象,可以推测这一类型为激进型驾驶员;同理,对于急加速次数、急刹车次数、超速次数、平均车速较低的数据对象,可推测这一类为稳健型驾驶员;剩下的数据介于二者之中的为一般型。不同驾驶员不同日期的样本有2514条,其中共有分类类别为“0”的一般型驾驶员的标签1176条,共有分类类别为“1”的激进型驾驶员的标签867条,共有分类类别为“2”稳健型驾驶员的标签471条。其统计结果如图1所示,可知,一般型的驾驶员占比达到47%,稳健性的驾驶员占比19%,激进型的驾驶员占比高达到34%,本研究对改善驾驶员行为具有重大意义。

图1 驾驶行为倾向性聚类分布图
3 评分模型构建
3.1 熵权法
熵是一种热力学的概念,是用于衡量体系的无序与混乱程度的,熵越大,表明事务越混乱,它广泛应用与工程技术、社会经济等领域[14]。信息熵这一概念最先由信息奠基人香农(Shannon)引入的,他把信源所含有的信息量称为信息熵。熵权法是计算权重指标的经典算法之一,是用来判断某个指标的离散(混乱)程度的,它通过指标的变异性大小来判断客观权重,即信息熵越小,离散程度越大,信息量越大,标对综合评价的影响(权重)也就越大,反之亦然[15]。熵权法的客观性与适应性较强,精度高,能够很好的分析权重结果。因此,可以使用计算熵值来确定某一事件的随机性和无序程度,也可以通过它判断某些指标的离散程度,熵权法的赋权具体步骤如下:
1)数据归一化,由于各指标的计量单位不同,因此在计算权重时需要对它们进行归一化处理,使数值在0-1之间浮动。如给定了n个指标X1,X2,X3,…,Xn,转化后的指标值为:Y1,Y2,Y3,…,Yn,则:
(4)
2)计算指标的比重Pij,其中i为行,j为列。
(5)

(6)
4)计算信息熵冗余度d。
dj=1-ej
(7)
5)计算各项指标权重
(8)
3.2 层次分析法
层次分析法AHP(analytic hierarchy process)是美籍运筹学家萨蒂在20世纪70年代初期根据网络系统理论和多目标综合评价方法而提出的一种层次权重决策分析方法[16]。它是利用多因素分析方法来判断指标权重的一种主观赋权方式,能够对多目标决策问题进行灵活处理。所确定的指标权重相对合理,所以在各个领域都得以广泛的运用。但层次分析法对定量因素的运用还有不足,其判断矩阵大多依赖决策者经验判断,主观因素往往对权重计算的结果产生了较大的影响。它的基本思想是把所有需要加以分析的问题层次化处理,按照问题的基本特性及其最后要达到的目标,来把问题划分为不同的构成因素。层次分析法的具体步骤如下:
1)建立层次结构,要把决策的目标、对象和影响因素按照它们之间的关系分为目标层、指标层、方案层。目标层为决策的目的,指标层为需要考虑的因素,方案层为决策的方案,设评分模型有m个标准层、n个指标层、指标内对应n1,n2,…,nk个指标。
2)构建判断矩阵。这里使用了一致矩阵法,即将所有因素两两相互比较,尽可能减少性质不同的因素相互比较的困难,以此增加准确度。判断矩阵Aij的标度方法见表4所示。
3)计算各层要素对应权重。这里采用算数平均法计算权重,先求出判断矩阵A每列的和,之后再进行按列归一化(计算该值所占该列比例)得矩阵B,最终对每行求算数平均值得到每行的权重Wi(i=1,2,3,…,n)。
(9)

表4 判断矩阵标度
4)进行一致性检验。计算判断矩阵A的最大特征值λmax与一致性指标CI,其中n为指标层个数。CI越大,不一致越严重,当CI越接近0,表示有越满意的一致性。
(10)
(11)
5)定义一致性比率CR。为了衡量CI的大小,引入随机一致性指标RI,其值如表5所示。当CR<0.1时,认为构建的判断矩阵通过一致性检验,构造合理,可用其权重Wi。
(12)

表5 随机一致性指标RI值
3.3 评分模型指标体系构建
熵权法为客观赋权法,层次分析法为主观赋权法,主观赋权法通常是由专家依据自身的知识经验和问题实际状况确定权重,主观性较强。客观赋权法是通过与原始数据之间的关联来判断权重,客观性较强。为此结合两种方法使用熵权层次分析法来实现驾驶行为评分模型的构建,使用熵权法来削弱层次分析法主观性的影响,同时平衡了熵权法结果的突出与局部差异[17]。熵权层次分析法的主要方法为:首先使用熵权法与层次分析法分别得出各自权重,然后把两种方法计算的权重通过组合赋权法[18]来加以综合,从而得出综合权重Wj,其中Wjs为通过熵权法计算的权重,而Wjc则为通过层次分析法计算的权重。
(13)
根据解析的数据,统计出车辆超速、疲劳驾驶、急刹车、急加速等次数。根据熵权层次分析法将车辆行驶情况、出行情况、驾驶行为表现、发动机情况列为标准层即一级指标;将平均车速、超速次数、每日里程、每日驾驶总时长、急加速次数、急刹车次数、驾驶疲劳次数、每日发动机平均油耗率、每日发动机平均转速这9个因素列为指标层即二级指标,具体信息如表6所示。

表6 驾驶行为指标分层
3.4 评分模型指标权重
结合文献[19-20]中的驾驶行为调查结果和专家建议来对各项指标进行评定,得出了驾驶行为的评分模型判断矩阵,具体见表7。通过驾驶行为评分模型判断矩阵中构建的值,通过使用式(9)~ (12)来进行一致性检验,经过运算后得出,标准层的一致性比率CR的数值为:0.003 9,其值小于0.1,即建立的判断矩阵通过了一致性检验,其构造合理。同理,指标层也依次进行一致性检验,结果构造合理。
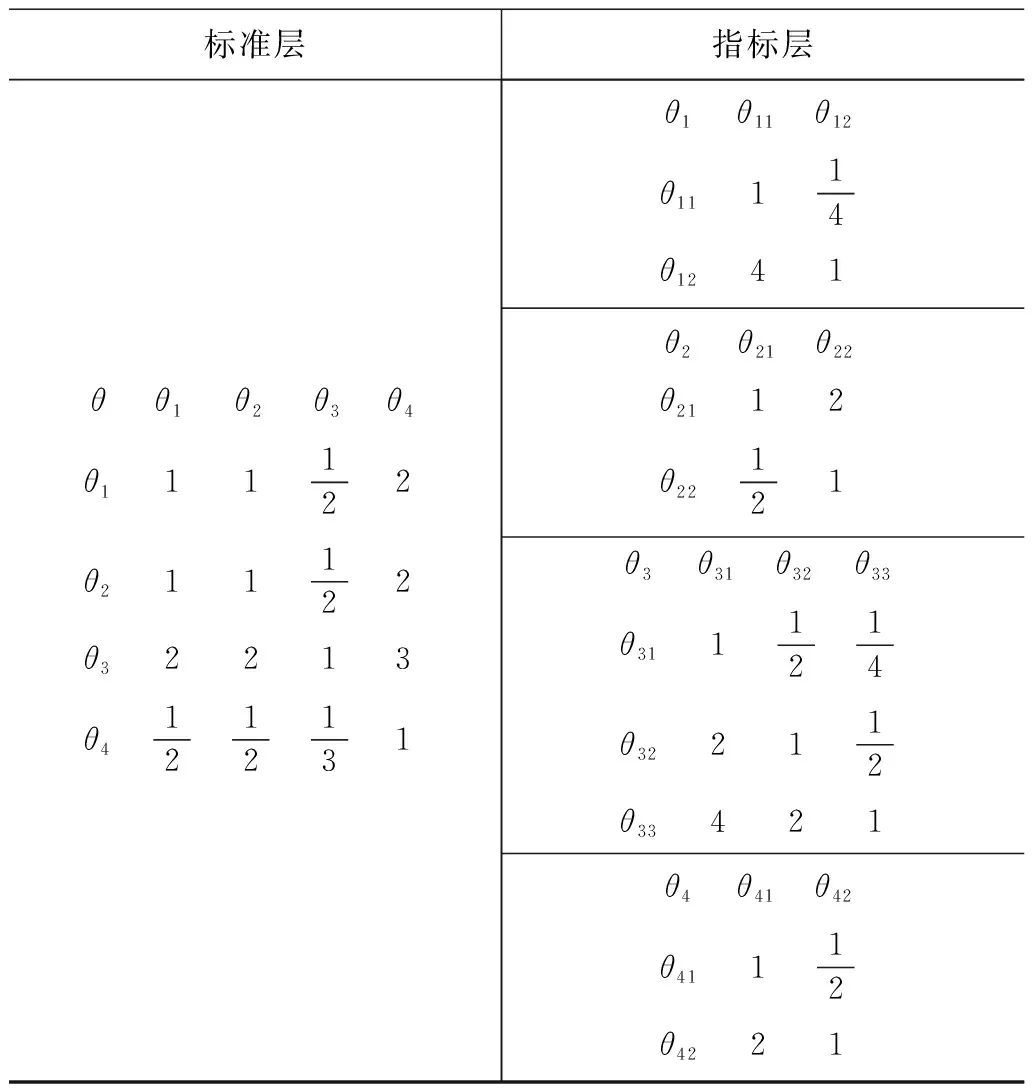
表7 驾驶行为评分模型判断矩阵
通过使用式(4)~(8)来计算熵权法中标准层与指标层权重;再根据判断矩阵的值,使用式(9)来分别计算得出层次分析法中标准层与指标层权重。最终通过式(13)使用熵权层次分析法来将权重加以综合,得出熵权层次分析法指标层的权重Wj,最终结果如表8所示。

表8 3种方法下的权重对比
由表8中的数据可知熵权法、层次分析法和熵权层次分析法这3种权重计算方法对于驾驶行为评分模型的权重计算值,其中熵权法计算的各项标准层指标权重为:0.04、0.13、0.64、0.19。层次分析法中的标准层权重分别为0.23、0.23、0.42、0.12。其中,熵权法中权重的结果值,体现了数据在局部特征之间的不同情况,它削弱了指标之间重要程度对最终结果的影响,但对于层次分析法来说,它所计算的权重结果值和判断矩阵的参数设置有很大关系,决策者对指标重要程度的知识经验对最后权重的结果值影响比较大,而熵权层次分析法则融合了熵权法和层次分析法,最终的权重值也融合了两者的权重,可以更好的体现各个指标对于驾驶行为的影响。
对上表权重的计算结果进行分析后,将采用熵权层次分析法计算出来的权重作为驾驶行为评分模型的指标分数,其中驾驶行为评分采用一百分制,按照不同指标的权重值来确定相应的指标分数,具体指标分数见表9所示。

表9 驾驶行为指标分数
3.5 驾驶行为综合评分
在确定了各个指标的分值后,还需要根据实际情况制定详细的评分标准。研究结合了文献[21]与车辆保险行业车联网解决方案白皮书以及根据现有数据的实际分布情况,采用了如表9所示的驾驶行为评分指标分数,制定了如表10所示的具体评分细则。其中a为指标所占分值,S为该指标实际的最终分值,x为指标实际值。

表10 驾驶行为评分细则
将通过驾驶行为倾向性识别后的70辆车在不同日期下产生的2 514条数据样本,按照倾向性识别类型:一般型、稳健型、激进型分类,再进行驾驶行为评分,得到如图2~4所示的不同倾向驾驶员的分值分布。

图2 一般型驾驶员分值分布情况

图3 稳健型驾驶员分值分布情况

图4 激进型驾驶员分值分布情况
由图2、图3、图4所示,激进型驾驶员的分值分布在60~75分之间的次数比较多;稳健型驾驶员的分值分布在85~100分之间的次数比较多,而一般型驾驶员的分值主要分布在65~95分之间,由此,研究所构建的驾驶评分模型具有合理性,可以为管理者和驾驶员提供驾驶行为信息,为后续驾驶员的行车操作做出警示,对于分值较高的驾驶员需要继续保持,对于分值较低的驾驶员需要加以改善。
4 结束语
研究分析了基于CAN数据的渣土车驾驶行为。首先,介绍了CAN数据的解析方案,进而获取到了数据,对CAN数据与北斗定位数据进行处理分析;其次,采用聚类的K-Means算法对渣土车司机的驾驶行为倾向性进行分析;随后介绍了熵权法与层次分析法,在计算出二者在指标层上的权重后利用熵权层次分析法集成权重;最后通过文献结合实际情况的方式制定评分细则,计算得出渣土车驾驶员的评分,以便帮助驾驶员更有针对性的改善其驾驶行为。通过实验表明,改进方法能够满足用户的需求,有利于管理员管理的同时提升驾驶员安全行车水平,能有效提升驾驶员的安全。
猜你喜欢
防爆电机(2022年4期)2022-08-17 05:59:06
导航定位学报(2022年4期)2022-08-15 08:48:28
公民与法治(2022年4期)2022-08-03 08:20:48
中成药(2017年9期)2017-12-19 13:34:30
自然资源情报(2017年7期)2017-11-26 07:56:04
中国交通信息化(2017年9期)2017-06-06 07:14:54
项目管理技术(2016年8期)2016-05-17 05:39:14
西南交通大学学报(2016年6期)2016-05-04 04:12:50
山东青年(2016年3期)2016-02-28 14:25:50
中国交通信息化(2015年3期)2015-06-05 03:53:39
