
改进Yolov5的手语字母识别算法研究
2023-04-19 05:12袁宇浩
小型微型计算机系统 2023年4期
陈 帅,袁宇浩
(南京工业大学 电气工程与控制科学学院,南京 211816) E-mail:1621253937@qq.com
1 引 言
手语是聋哑人进行信息交流的重要手段,而手语字母是手语的基本组成单元,手语字母识别也是人机交互的重要组成部分[1].手语识别作为一种新的交互方式,被广泛应用到虚拟现实系统、互动游戏平台、手语识别和控制机器人等领域[2].
在人机交互的过程中,为了能够准确地识别出手部信息,提高识别的准确率就显得尤其重要[3].目前,对于手部信息的识别方法主要可以分为两类:基于外部设备的识别方法,基于计算机视觉的识别方法[3].
基于外部设备的手部信息识别方法指借助外部设备对数据进行采集,根据采集的数据对手部信息进行识别,如Kinect,可穿戴数据手套等[4],该识别方法具有极高的准确性和检测速度.但价格过于昂贵且操作不方便[4].基于计算机视觉的手势识别则是通过识别图像中手部的特征来判断手势[5].
近年来,卷积神经网络在图像识别领域取得巨大成果,与传统机器学习手势识别相比,基于卷积神经网络的手势识别具有更好的自适应能力,具有更强的鲁棒性.目前,吴晓凤、张江鑫等人利用Faster-RCNN对手势进行识别,取得了较高的精度,但检测速度较慢,不能做到实时检测[6].张强、张勇[7]等人采用Yolov3网络对静态手势进行识别,该方法采用Kinect设备采集手势信息,利用K-means算法对Yolov3的锚框进行设定,在实时性和检测精度上同时取得了不错的效果[8,9].Rao等人利用前馈神经网络对手语视频进行检测,检测精度达到了90%[10].CHAUDHARY利用方向直方图,设计了一种手势识别神经网络,准确率达到了92.8%[11].
由于现有的检测设备价格昂贵,检测方法检测速度慢,不能做到实时检测,且检测精度较差,在不同的设备之间移植困难.而Yolov5网络相比于其他网络具有检测速度快,检测精度高,且方便移植到手机等便携式设备中.本文以Yolov5网络为基础进行改进,融入SE通道注意力机制[12]和ASFF自适应特征融合机制[13],并对数据集进行处理,增加在强光下带有投影以及复杂背景和进行灰度处理过的图片,使Yolov5对于图像高层的语义信息以及对底层的轮廓、边缘、颜色、形状信息利用的更加充分[14].改进后的Yolov5-ASFF-SE网络在手语字母识别准确度上达到了96.1%,平均精度均值达到了96.8%.相比原Yolov5网络,在检测速度基本保持不变的前提下,平均精度均值提高6%.
2 Yolov5算法简介
2.1 目标检测算法介绍
目标检测就是对图像中的目标物体位置和大小进行判定,随着深度学习的不断发展,基于深度学习的目标检测方法也得到了广泛普及[15].深度学习目标检测算法大体上可以分为双阶段和单阶段两种,双阶段目标检测算法虽然检测精度较高,但速度比较慢,很多时候无法满足要求[15].单阶段目标检测算法则是端到端检测,虽然单阶段目标检测算法速度较快,但检测不够准确,很多重叠遮挡的物体无法被检测到[15,16].
Yolo是目标检测领域常用的端到端的卷积神经网络模型,发展至今,共有5个版本,分别是Yolov1至Yolov5[17].Yolo在第3代发展到巅峰,网络结构基本成型,在兼顾实时性的同时保证了检测的准确性.Yolov4和Yolov5也是在Yolov3的基础上进行改进,提高了检测速度和检测精度.
与Yolov3相比,Yolov5具有更高的准确性以及更快的速度.Yolov5包括四种不同的网路结构,Yolov5s,Yolov5m,Yolov5l,Yolov5x,这4种网络结构的深度和宽度各不相同,其中Yolov5s宽度和深度最小[18].为了满足速度要求,本文选用网络深度和宽度最小的Yolov5s网络模型.根据处理内容的不同,Yolov5s目标检测网络可以分为Input输入端、Backbone特征提取端、Neck颈部端、Prediction预测端.
2.2 Input输入端
Yolov5的Input输入端,采用Mosaic图像增强来提升检测效果,采用自适应锚框计算来设定初始锚框的大小,采用自适应图片缩放固定图片的尺寸.
2.2.1 Mosaic数据增强
Mosaic图像增强是随机将4张图片拼接成一张图片进行训练,4张图片拼接成一张增加了很多小目标,提升了小目标的识别能力[19].增加了网络的稳定性,改善了网络的训练效果.
2.2.2 自适应锚框计算
自适应锚框计算,指在网络训练前,Yolov5根据不同的目标检测数据集,自动设定初始锚框的大小,而Yolov3需要单独采用K-means聚类算法人为设定初始锚框的大小,Yolov5将其嵌入到算法中.在网络训练的过程中,网络自行设定锚框的大小.
2.2.3 自适应图片缩放
自适应图片缩放,即自动缩放图片尺寸到640×640的大小,传统的图片缩放和拉伸,增添的黑边比较多,增加了网络的计算量,而Yolov5对该算法进行改进,增添最小的黑边,这样可以减少网络的训练速度和检测速度.
2.3 Backbone端
Yolov5的Backbone主干部分采用darknet53特征提取网络,特征提取网络主要由Focus结构,CSP结构和SPP结构组成.
2.3.1 Focus结构
Focus结构的功能和邻近下采样相似,对图片进行切片操作,得到了4张互补的图片,4张互补的图片长相相似,但没有信息丢失,这样一来,将W、H信息就集中到了通道空间,输入通道扩充了4倍,即拼接起来的图片相对于之前RGB三通道变成了12个通道,最后将得到的新图片再经过卷积操作,最终得到了没有信息丢失的2倍下采样特征图.Yolov5的Focus结构如图1所示.
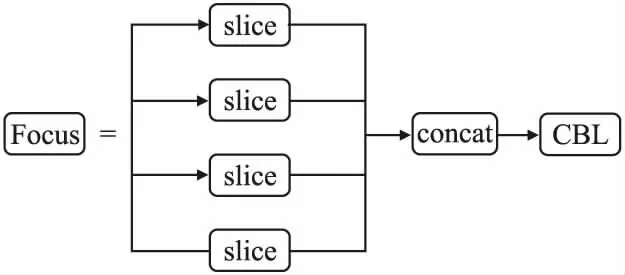
图1 Yolov5的Focus结构Fig.1 Focus structure of Yolov5
2.3.2 CSP结构
Yolov5设计了两种CSP结构,一种是带了残差的CSP1_X结构,另一种是用普通的卷积块替换残差的CSP2_X结构.带残差的CSP1_X结构使用在backbone里,不带残差的CSP2_X结构使用在neck部分.darknet53为较深的网络,增加残差结构可以避免因为网络深度的增加而带来的梯度消失.从而增强部分的泛化能力.Yolov5的CSP结构如图2所示.
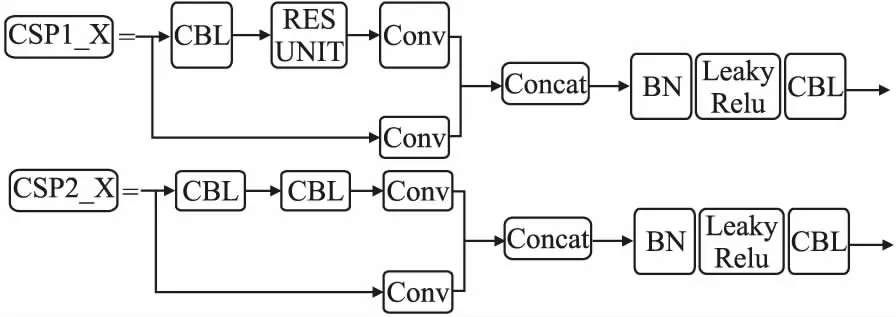
图2 Yolov5的CSP结构Fig.2 CSP structure of Yolov5
2.3.3 SPP结构
SPP结构,也叫空间金字塔池化层,通过不同大小卷积核的池化操作抽取不同尺度特征,增加了尺度的多样性,防止出现过拟合,同时加快了网络的收敛速度.SPP结构如图3所示.
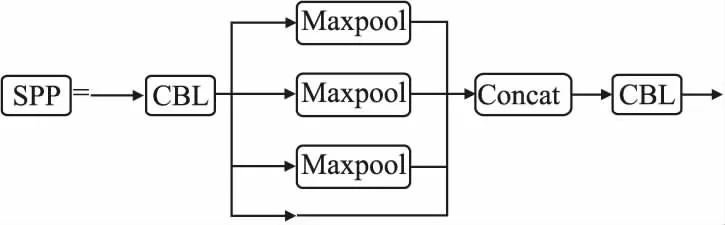
图3 Yolov5的SPP结构Fig.3 SPP structure of Yolov5
2.4 Neck端
Neck颈部端采用自顶向下的特征金字塔FPN结构以及自底向上的PAN的组合结构,FPN+PAN的组合结构中采用了不带残差的CSP2_X结构,增强了网络的特征融合能力.Yolov5的FPN和PAN结构如图4所示.

图4 Yolov5的FPN和PAN结构Fig.4 FPN and PAN structure of Yolov5
2.5 Prediction端
Yolov5的输出端,使用 GIOU作为边界框损失函数,使用加权 NMS 对非极大值进行抑制,从而获得最优目标框[20].输出层共有3个尺寸的输出通道,大小分别 19×19×255、38×38×255、76×76×255[21].
3 Yolov5改进
3.1 融入SE通道
手语字母图像相较于其他图像,不同手势的相似性太高,细节信息不够丰富,因此,手语字母识别进行细节提取就显得尤其重要.对于卷积操作,很大一部分工作是增大感受野,通过在CNN卷积神经网络中融入SE通道注意力机制,可以增大特征提取的感受野,从而可以提取到更多的手势细节信息[22].
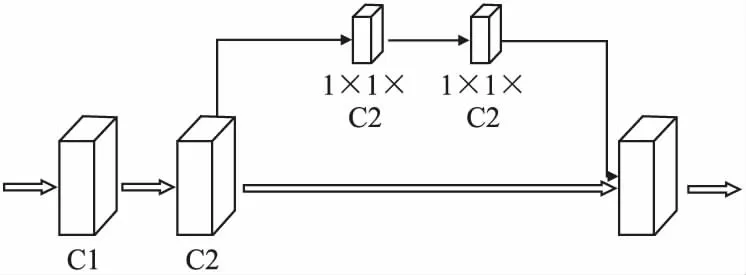
图5 SE通道注意力结构Fig.5 SE channel attention structure
SE通道注意力机制,包括Squeeze压缩操作和Excitation操作,首先对Darknet53特征提取网络提取到的特征进行压缩操作,进而对特征进行Excitation操作,最后累加Excitation操作得到的权重与初始特征图进行相乘得到的结果.进而输出.SE通道注意力结构如图5所示.
3.2 融入自适应特征融合机制
Yolov5目标检测网络采用PANet结构进行融合,这种融合方式只是简单的将特征图变换成相同尺寸,然后再相加,无法充分利用不同尺度的特征[23].为了对图像高层的语义信息以及对底层的轮廓、边缘、颜色、形状信息进行充分利用,现融入自适应特征融合机制.自适应特征融合机制的结构图如图6所示.
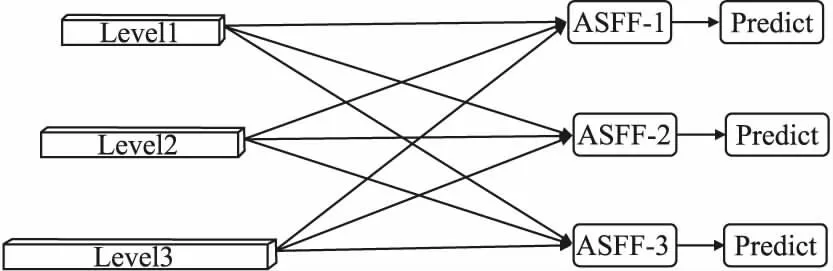
图6 ASFF的结构设计图Fig.6 Structural design diagram of ASFF
Yolov5颈部的输出为level、level2和level3特征图,图中以ASFF-3为例进行介绍,融合后的ASFF-3输出为level1、level2、level3的语义特征与来自不同层的权重α,β和γ相乘并进行相加的结果[23].如公式(1)所示:
(1)
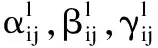
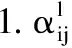
(2)
4 实验结果与分析
4.1 实验数据集及实验环境
实验从线上收集了1800张手语字母数据集.数据集包含26个数据类别,分别是′A′,′B′,′C′,′D′,′E′,′F′,′G′,′H′,′I′,′J′,′K′,′L′,′M′,′N′,′O′,′P′,′Q′,′R′,′S′,′T′,′U′,′V′,′W′,′X′,′Y′,′Z′,为了提高手语字母识别的准确性,对手语字母数据集进行处理,增加在强光下带有投影以及复杂背景和进行灰度处理过的图片,如图7所示.

图7 复杂背景下图片Fig.7 Picture with complex background
使用 LabelImg软件对图片进行标注,数据集格式选用YOLO,标签保存为txt格式,文件名和图片名称一致[24].标注的图片如图8所示.

图8 手语字母数据集Fig.8 Sign language alphabet data set
根据用途不同,对标注好的数据集进行划分,分为训练集、验证集和测试集.具体划分比例如表1所示.

表1 训练集,验证集和测试集Table 1 Training set,validation set and test set
本实验采用 Ubuntu18.04 操作系统,深度学习框架选用 Pytorch 架构,使用 GeForce GTX 2060 的显卡进行训练.具体实验配置如表2所示.

表2 实验环境Table 2 Experimental environment
4.2 模型评估指标
本文选用平均精度均值MAP作为模型的评估指标,它们的数值越大,表示手语字母识别效果越好[25,26].在介绍平均精度均值之前先介绍准确率和召回率,准确率P是检测正确的数量占预测为正的比例,召回率R是检测为正的数量占实际为正的比例[25,26].
(3)
(4)
式中:TP为手指字母检测正确的数量,FP为手指字母检测错误的数量,FN为未被检测出的数量.
AP为平均精度,其值为PR曲线下的面积,平均精度均值MAP即AP的平均值.MAP公式如下:
(5)
4.3 实验结果与分析
Yolov5s在对手语字母数据集进行训练过程中,将batch_size大小设置为16,在对模型训练200个epochs后,模型逐渐收敛.准确率,召回率,平均精度均值均已稳定.本文将训练次数设置成300.Yolov5s训练结果图如图9所示.
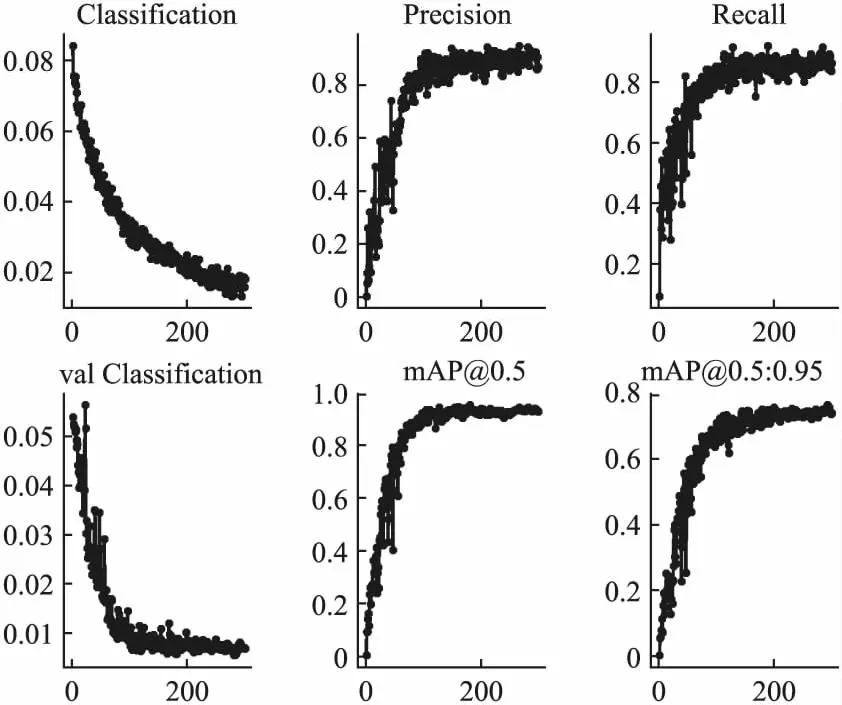
图9 yolov5s训练结果图Fig.9 yolov5s training results graph
Yolov5s模型经过300轮训练,手势识别准确度达到90.3%,平均精度均值MAP达到90.8%.实验结果如图10所示.
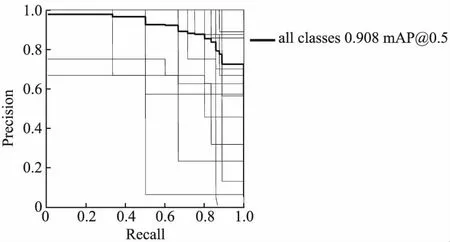
图10 Yolov5s模型的MAPFig.10 MAP of Yolov5s model
Yolov5s模型在训练300轮后,保存的权重文件仅为13.8Mb,图片大小设置为640×640,RTX2060显卡检测一张图片的速度为0.021秒,即47.6FPS,检测速度可以满足需求.
4.3.1 Yolov5s-SE实验结果
Yolov5s-SE模型经过300轮训练,手势识别准确度达到93.0%,平均精度均值MAP达到93.3%.由此可见,通道注意力机制对于手部细节信息提取较为丰富.实验结果如图11所示.
Yolov5-SE模型在训练300轮后,图片大小设置为640×640,RTX2060显卡检测一张图片的速度为0.023秒,即43.47FPS.
4.3.2 Yolov5s-ASFF实验结果
Yolov5s-ASFF模型经过300轮训练,手势识别准确度达到94.1%,平均精度均值MAP达到94.3%.由此可见,ASFF对于手部高层的语义信息和底层的细节信息较为丰富.实验结果如图12所示.
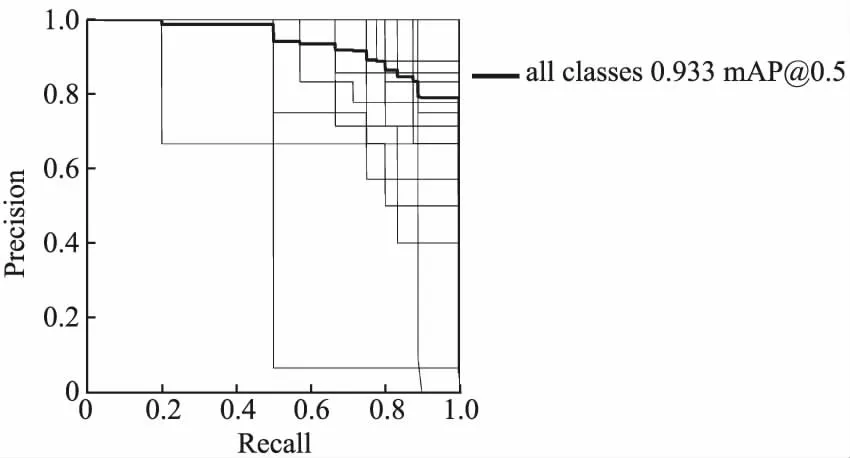
图11 Yolov5s-SE模型的MAPFig.11 MAP for the Yolov5s-SE model
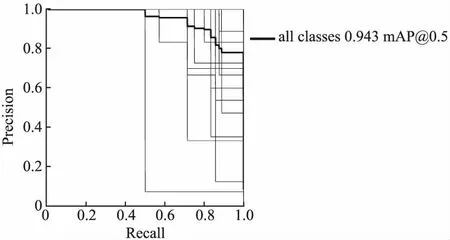
图12 Yolov5s-ASFF模型的MAPFig.12 MAP for the Yolov5s-ASFF model
Yolov5-ASFF模型在训练300轮后,图片大小设置为640×640,RTX2060显卡检测一张图片的速度为0.019秒,即52.6FPS.
4.3.3 Yolov5s-ASFF-SE实验结果
Yolov5s-ASFF-SE模型经过300轮训练,手势识别准确度达到96.1%,平均精度均值MAP达到96.8%.实验结果如图13所示.
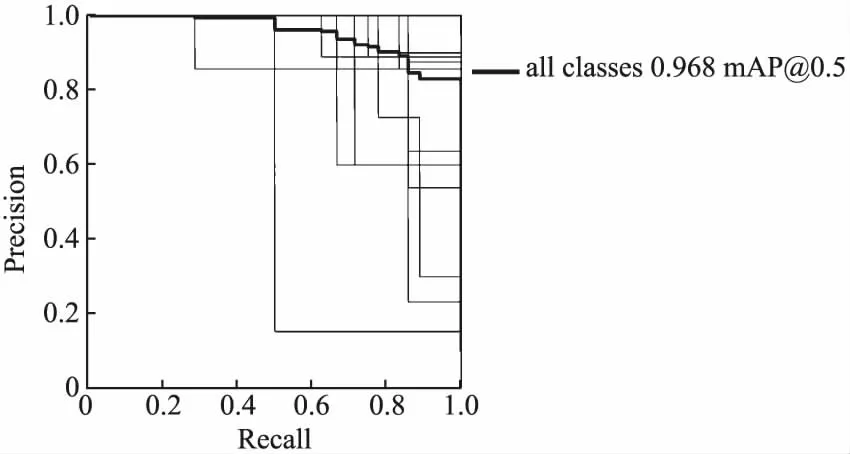
图13 Yolov5s-ASFF-SE模型的MAPFig.13 MAP for the Yolov5s-ASFF-SE model
Yolov5-ASFF-SE模型在训练300轮后,图片大小设置为640×640,RTX2060显卡检测一张图片的速度为0.022秒,即45.45FPS.
相比原Yolov5模型,Yolov5-ASFF-SE模型在检测速度基本不变的前提下,平均精度均值提升了6%.为了直观看出模型改进前后MAP的变化情况,现统计模型改进前后的MAP,绘制MAP曲线,如图14所示.
由图14可得,模型在改进前后,相比于原模型拥有更快的收敛速度,原Yolov5s模型在150轮左右逐渐收敛,改进后的模型在训练100轮时逐渐收敛,节省了大量的训练时间.在训练时间有限的前提下,能够取得较好的效果.
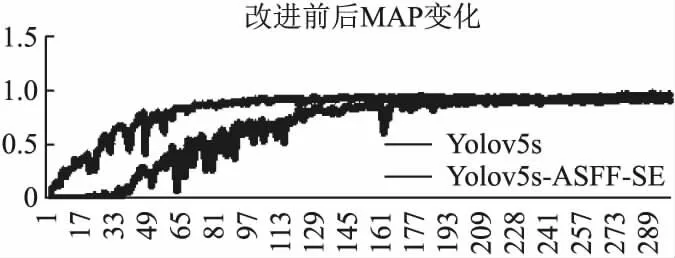
图14 模型改进前后MAP变化Fig.14 Change in MAP before and after model improvement
现对比其他一些先进的目标检测神经网络,即Faster-rcnn,Yolov3,Yolov3-tiny等,在训练集,测试集,验证集,实验设备保持不变的前提下,统计这些方法的平均精度均值和检测速度.如图15所示.
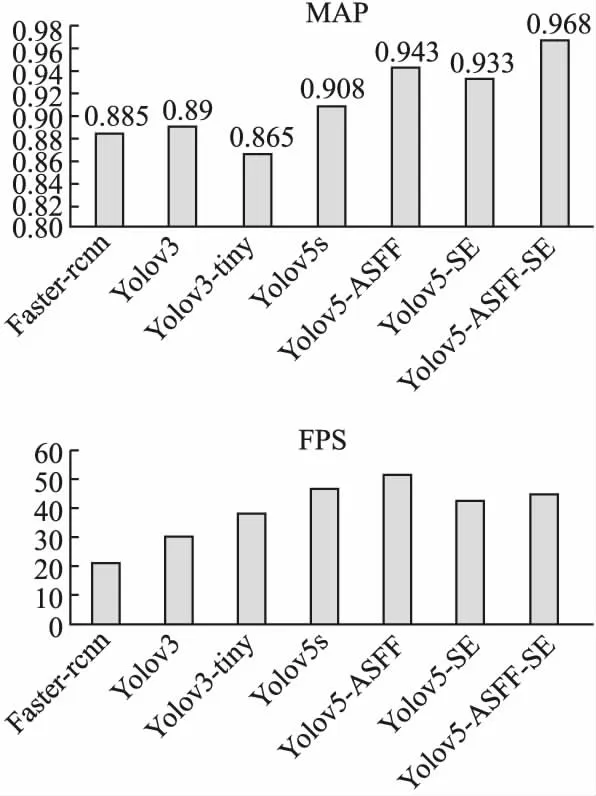
图15 主流网络MAP和FPS对比Fig.15 Mainstream network MAP and FPS comparison
由图15可得,Yolov5s模型相比其他神经网路模型,检测速度和精度均高于其他主流神经网络模型,改进后的Yolov5-ASFF-SE模型相比原Yolov5s模型在检测速度基本不变的前提下,检测精度大大提高,可以满足日常使用.
模型改进前后,每个手指字母的识别平均精度均值MAP如表3所示.
由表3可以看出,在模型改进前后,基本每个手语字母的识别平均精度均值MAP均有提升,在模型改进前,C,I,N,V字母的准确率较低,模型改进后,C,I,N,V字母的准确率提升较为明显.由此可见,改进后的Yolov5-ASFF-SE网络对于手部细节的提取更加充分.
4.3.4 Yolov5便携设备移植
Yolov5使用Android studio和Visual studio软件,可以方便的将训练好的权重移植到手机中,也可以使用Qt进行前段界面编程,方便进行摄像头调用.图16为摄像头实时监测.
5 结束语
本文基于Yolov5s网络模型提出一种改进的Yolov5-ASFF-SE模型,融入SE通道注意力机制和ASFF自适应特征融合机制,并对数据集进行处理,增加背景的复杂度,相比原Yolov5s网络,Yolov5-ASFF-SE模型在检测速度基本不变的前提下,检测精度提升了6%.但个别手语字母检测精度仍有待提升,下一步将改进Yolov5的网络结构,并扩充数据集,来提升个别字母的检测精度.另外,本文检测的手语字母为静态检测,而静态手语字母检测是动态检测的基础,以后将进一步研究动态检测.

表3 单一字母识别MAPTable 3 Single letter identification MAP

图16 摄像头检测Fig.16 Camera detection
猜你喜欢
疯狂英语·新阅版(2023年5期)2023-05-31
现代装饰(2020年6期)2020-06-22
活力(2019年15期)2019-09-25
电子制作(2018年11期)2018-08-04
学苑创造·B版(2017年3期)2017-05-03
测绘科学与工程(2016年5期)2016-04-17
青少年科技博览(中学版)(2015年8期)2015-10-28
电子设计工程(2015年3期)2015-02-27
河南科技(2014年14期)2014-02-27
少年科学(2006年1期)2006-02-07
