
融合评分与评论的深度评分预测模型
2023-04-19 05:12:16李昆仑
小型微型计算机系统 2023年4期
李昆仑,林 娜,王 珺
(河北大学 电子信息工程学院,河北 保定071000) E-mail:likunlun@hbu.edu.cn
1 引 言
尽管现在已有许多基于评分实现用户偏好与物品特征建模的推荐模型,但是依然存在两个主要的挑战[1-3].一方面,实际应用场景中用户-物品的交互数据十分稀疏,训练出精准的推荐模型十分困难,导致物品有效推荐具有很大的局限性.另一方面,仅仅依赖评分数据很难完整地解释用户的兴趣偏好和物品的属性特征.
很多研究者选择添加各种辅助信息增强推荐性能[4,5],如:物品属性标签、用户评论等.充分的利用这些信息,可以进一步获取用户的偏好与物品的特性.其中,用户评论文本是提高推荐性能的重要信息资源.各大电商平台积极鼓励用户发表相关评论,希望借助语义信息丰富的隐式评论特征,更好地理解用户偏好与物品属性,从而提高推荐算法性能.将评分信息与评论文本信息相结合,不但可以捕捉更多的用户偏好特征和物品属性特征,还可以更好的理解用户是如何给该物品进行打分,使用户的潜在偏好与物品潜在属性具有可解释性.文献[6]利用评论文本信息作为辅助信息,从文本信息中学习特征分布.该模型仅仅从物品整体评论进行特征建模,没有关注每个用户的历史评论,忽略了用户与物品的交互行为,很难把握用户具体偏好.文献[7]为了避免文本信息在不同情况下因含义不同带来的差异性,该模型将用户偏好与物品特征分别建模.同一用户的所有历史评论构成了用户的评论文本,而物品收到的所有用户评论构成物品评论文本.利用卷积神经网络(Convolutional neural network,CNN)分别对用户评论文本信息与物品评论文本信息进行特征提取,得到相对应的特征表示.单纯利用CNN进行文本特征提取,捕捉的是文本局部特征,很难捕获长距离特征以及上下文信息.
已有各种不同技术被应用于推荐评论的建模,特别是卷积神经网络(CNN),且取得较好的效果.但CNN针对自然语言处理方面具有一定的局限性.CNN进行文本特征提取主要通过滑动窗口加池化的方式捕捉文本局部特征.但获取精准的语义信息仅考虑局部语义是不足够的,需结合文本的上下文关系.如“这个版本不如原版那样经典,但其仍然丰富有趣”很可能因为CNN模型捕获到“不如”该字眼,被分类为消极情感,而非整体情感倾向.因此,CNN进行文本特征提取很难同时考虑到语义的局部与全局信息,导致语义信息特征提取不准确,尤其对于长文本信息更加明显.
针对以上问题,本文提出了融合评分与评论的深度评分预测模型DMRR(Deep Model combining Rating and Review).该模型在进行文本特征提取时,将CNN与GRU(Gated Recurrent Unit)进行有效的结合,希望可以从局部与全局两方面提取文本特征.并根据用户-物品历史评分信息引入了物品可推荐度与用户偏好程度.为了有效结合评分与评论信息,该模型利用融合策略将二者构建的特征矩阵进行融合.提取融合特征的高阶特征向量,并通过矩阵分解预测用户评分.
2 相关工作
目前已经有一些基于用户-物品历史评分提供精确推荐的相关工作,基于用户的协同过滤(User-based collaborative filtering)是最为经典的推荐算法[8].其核心是利用用户个人偏好信息寻找与用户相似的目标用户.但是无论新老用户,个人偏好信息总是很难捕获,这一关键信息的缺乏导致了推荐的冷启动问题.
为了缓解冷启动问题,文献[3,5]在协同过滤算法中引入矩阵分解.目的是将用户偏好和物品属性分别表示成两个隐向量,然后将这两个向量进行内积运算得到预测评分.研究表明,矩阵分解技术的引入一定程度缓解了冷启动问题,提升了推荐性能.但是,矩阵分解模型也存在一些不足,如数据稀疏性、以及该模型单纯的利用显示评分特征很难捕获用户的具体偏好以及物品属性等.为了克服矩阵分解模型的不足,许多研究者引入各种辅助信息,如标签、社交网络、用户隐性行为、评论文本等[4,5,9].目前,结合评分与评论进行预测的方法较为受欢迎.一方面,在推荐系统的可解释性方面会做得更好;另一方面,可以利用评论隐式特征弥补评分稀疏性问题.
基于评论文本的推荐算法大多利用传统的NLP模型进行文本特征处理,如LDA、TF-IDF等[10].文献[11]将LDA主题模型应用于评论文本,并将主题与评分映射到相同空间,以提高预测精度.该方法判断文本相似度时没有考虑语义间的关联,导致推荐效果不理想.随着深度学习网络在各个领域的成功应用,人们尝试利用深度学习网络模型对用户-物品评论进行特征提取,捕获文本语义信息[12].特别是卷积神经网络在ImageNet图像分类竞赛中取得巨大成功后,该网络模型在图像、文本、音频等各个领域广泛使用.文献[13-15]则均通过CNN自动提取文本特征信息,进一步增强了评分预测准确率.
相对于卷积神经网络,自然语言处理领域更常用的是循环神经网络(Recurrent Neural Network,RNN).因为文本信息之间具有很强的依赖性,然而卷积神经网络恰恰忽略掉了这点,无法将发生的事情给出关联分析.文献[16]利用LSTM模型进行文本特征提取,希望考虑词序,使文本特征提取更准确,从而提高推荐性能.文献[17]利用了改进循环神经网络双向GRU从用户评论和商品评论中分别提取用户和商品的深层非线性特征向量,来预测出用户对商品的评分.
深度学习的应用开辟了推荐系统的新天地,其“黑盒效应”导致推荐算法可解释性差[18].文献[19]提出了基于评论的深度注意力推荐模型ADR.该模型从评论文本中学习到用户和物品特征,并通过注意力网络得到权重矩阵,从而动态调节文本特征的重要性,提高推荐性能.文献[20]提出了基于注意力机制的GRU模型,结合矩阵分解得到的潜在因子,有效增加了模型可解释性.
综上所述,本文将CNN与GRU进行有效结合,并融合用户-物品评论与评分,构建深度评分预测模型.与之前工作最大不同的是,本文不仅在语义特征提取阶段考虑了上下文信息,还将评分与评论信息结合,以提高推荐算法的泛化能力.
3 融合评分与评论的深度评分预测模型
本节中重点讨论本文提出的DMRR模型(Deep Model combining Rating and Review),该模型是一个利用评分与评论文本特征预测用户评分的模型.该模型主要包含3个模块:文本特征处理模块、特征融合模块以及高阶特征提取模块.具体模型结构如图1所示.
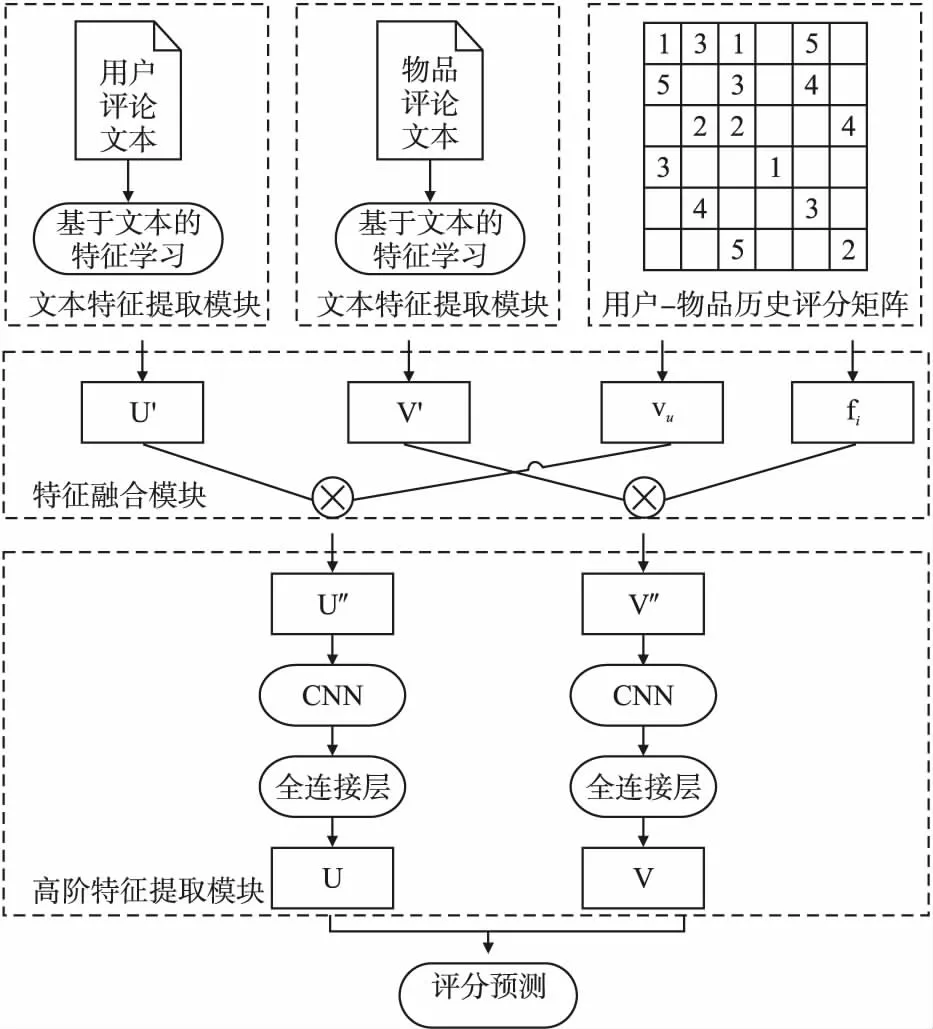
图1 DMRR模型结构Fig.1 Model structure of DMRR
在文本的特征提取模块中,有效的结合了GRU与CNN网络,可以更加精准地从文本中获取语义信息,并利用了注意力机制网络(Attention Mechanism)增强算法可解释性.在特征融合模块中,希望大量的评分数据与评论文本信息结合,可以进一步提高推荐系统的推荐精度.将文本特征提取模块学习构建的用户文本特征矩阵与物品文本特征矩阵,分别与用户-物品评分数据得到的用户偏好程度与物品可推荐度,通过融合策略进行特征融合.高阶特征提取模块,通过卷积操作的得到用户与物品的高阶特征向量.最后,通过矩阵分解进行评分预测.
3.1 文本特征提取模块
由于用户评论文本更多包含用户偏好,而物品评论更多包含物品属性.因此,本文将同一用户的所有历史评论形成一个单独的文件作为用户评论文本.同样,将同一物品收到的所有用户评论构成一个单独文件作为物品评论文本.本模型在评论文本特征学习阶段,主要希望通过联合学习用户-物品评论文本,构造出潜在特征向量.卷积神经网络在很多自然语言处理与信息检索任务中取得较好成就,WU等人提出的CARL模型便选择利用CNN进行文本特征学习,取得很好的结果[7].但是,CNN很难把握序列关系以及上下文信息.本文在进行文本特征提取时,不仅利用CNN,同时还利用了GRU网络学习文本之间的序列关系以及上下文信息,进一步捕获更精准的语义信息特征.然后,利用注意力机制网络层动态调节用户、物品特征向量,获取重要特征信息,构造用户文本特征矩阵以及物品文本特征矩阵.图2给出了文本特征提取的基本过程.
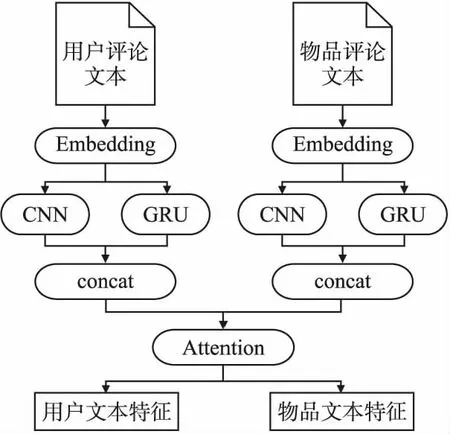
图2 文本特征提取模块Fig.2 Architecture of the review-based feature learning
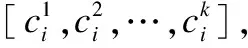
通常,一个用户评论文本中对于不同物品的偏好程度是不同的.也就是说,评论文本中并非所有信息对于预测评分都是必要的.为了获取有效信息,Attention分别对u,v特征进行处理.先将u,v映射在同一潜在空间,然后利用一个注意力矩阵T∈Rf*f,根据用户文本特征u和物品文本特征v,得到用户-物品文本特征的相关性矩阵R,如公式(1)所示:
R=tanh(uTTv)
(1)
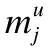
(2)
(3)
再根据文本特征的相关性,分别计算文本特征在用户u和物品v中的重要性,从而获取用户偏好特征以及物品的属性特征:
(4)
(5)
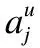
最后,结合注意力权重矩阵构造用户文本特征矩阵U′∈Rn*k和物品文本特征矩阵V′∈Rn*k:
U′=diag(au)uT
(6)
V′=diag(av)vT
(7)
文本特征提取模块算法描述如算法1.
算法1.
输入:用户评论文本Du,物品评论文本Di
输出:用户文本特征矩阵U′和物品文本特征矩阵V′
Step 1.评论文本经过embedding,得到词向量特征表示wi∈R1*t;
Step 2.词嵌入向量表示分别送入CNN和GRU中进行语义信息特征提取;
Step 3.将局部与全局特征进行融合,得到用户文本特征u以及物品文本特征v;
Step 4.通过Attention,得到用户注意力权重矩阵au以及物品注意力权重矩阵av;
Step 5.利用式(6)、式(7)构造用户文本特征矩阵U′和物品文本特征矩阵V′.
3.2 特征融合模块
Tan和Zhang提出联合用户-物品评分来增强之前根据文本信息学习得到的潜在特征,可以更好地对物品属性特征与用户偏好特征进行建模[21].本文利用用户-物品历史评分数据计算出物品可推荐度与用户偏好程度,更明确地区分不同物品评论之间以及不同用户评论之间语义信息的不同.同一单词对于不同语境,表达的语义有时可能偏差较小,有时可能相差甚远.评分的高低,则可以直接表达用户对该物品的喜欢程度,同时间接表明对应评论的情感倾向.利用评分辅助评论,可以更明确地确定其代表的情感倾向,有助于更精准提取语义信息.二者融合方式如公式(8)、公式(9)所示:
U″=vuU′
(8)
V″=fiV′
(9)
其中,vu为用户偏好特征分布,fi为物品可推荐特征分布,U′为结合注意力权重矩阵构造的用户文本特征矩阵,V′为结合注意力权重矩阵构造的物品文本特征矩阵.
3.2.1 物品可推荐度
为每一个物品计算可推荐度,并与物品文本特征进行特征融合,达到评分对文本语义增强的效果.也就是说,一个物品平均评分和整体平均分差值为正时,则值得推荐,该物品收到的评论文本语义应偏向积极情感,且值的大小代表其情感倾向程度.该物品从文本中提取到的所有特征会按照对应可推荐度得到增强.一个物品平均评分和整体平均分差值为负时,则不值得推荐,该物品收到的评论文本语义应倾向消极情感.物品从文本中提取到的所有特征会按照对应可推荐度减弱.即使某些物品评分较高,但评分数量可能过少,故仅考虑物品平均分是不合理的.本文不仅考虑了平均评分等级,还考虑了评分数量.对于评分高且评分数量多的物品,则表明该物品可推荐性较强,更应该值得被推荐.可推荐度fi计算公式如下:
(10)
(11)
(12)
3.2.2 用户偏好程度
首先,定义用户u对物品i的偏好程度gu,i=ru,i-mu,其中mu是用户u历史评分的均值.本文选择将每个用户历史评分的均值作为其衡量界限的原因是不同用户打分偏好可能不同.即同一单词对于不同用户,其表达语义可能存在偏差.也就是说,用户u对物品i的偏好程度gu,i为正值时,该用户评论文本包含的语义信息应正面积极,表达用户对物品的喜爱.值越大,则用户u对物品i喜欢程度越高;反之,gu,i为负值时,为消极评论.值越小,则表明用户u对物品i的不喜欢程度越高.用户u对所有打过分的t个物品的偏好程度构成了向量Gu=(gu,1,gu,2,…,gu,t)∈R1*t,代表了用户偏好特征的重要性.该t个物品的可推荐特征分布为F=[f1,f2,…,ft]∈R1*t,得到最终的用户u的偏好程度vu:
(13)
3.3 高阶特征提取模块
文本特征提取以及评分融合处理后,可能导致用户评论文本与物品评论文本中涉及到的无关信息占很大比例.为了避免该操作引入过多的噪声,本文选择利用卷积操作对融合特征向量U″,V″,提取更高阶的语义特征.首先,通过卷积-池化操作进行更高阶的特征提取.
(14)
(15)
hu=[h1,…,hf]
(16)
hi=[h1,…,hf]
(17)
其中,Wj是卷积核大小,f是relu激活函数,mean()则代表平均池化操作.
其次,将物品向量hi以及用户向量hu分别送入全连接层,得到物品的高阶特征向量ti与用户高阶特征向量tu:
tu=f(W*hu+b)
(18)
ti=f(W*hi+b)
(19)
其中,W是权重矩阵,b为偏置.
3.4 评分预测
本文选择因子分解机(Factorization Machine,FM)进行评分预测.不同用户有不同的打分习惯,所以在进行评分预测时,不仅考虑了全局偏置,还考虑了相关的用户与物品偏置.希望通过该变量调节评分预测,提高预测性能,具体计算如公式(20)-公式(22)所示:
zu,i=tu⨁ti
(20)
(21)
(22)
其中,⨁是concatenation操作,μ是全局偏置,bu和bi分别是用户偏置和物品偏置,m是潜在特征向量zu,i的系数向量,M是二阶交叉特征向量的权重矩阵(其对角元素为0),vj∈Rv,vk∈Rv和分别是特征向量zu,i维度j,k,相关的潜在特征向量,y′是预测评分.
在参数优化时,本文选用了平方差作为损失函数,并加入了正则化项避免过拟合.
(23)
其中,T是用户-物品的评分集合,y是用户u对物品i的真实评分,y′则是预测评分,θ是所有参数,λ是正则系数.本文评分预测算法如算法2.
算法2.
输入:用户-物品历史评分矩阵M,用户评论文本Du,物品评论文本Di
输出:用户评分预测y′
Step 1.利用文本特征提取模块,学习构建用户文本特征矩阵U′和物品文本特征矩阵V′;
Step 2.利用式(10)-式(13)求解物品可推荐度和用户偏好程度,并构建相应的特征分布;
Step 3.根据融合规则,得到融合特征矩阵;
Step 4.通过卷积和池化操作进行高阶特征提取;
Step 5.通过全连接层,得到用户高阶特征tu以及物品高阶特征ti;
Step 6.利用式(21)进行评分预测.
4 实验与讨论
4.1 实验环境与数据集介绍
本实验均在CPU为i7-9750H和GPU为GTX 1660 Ti,内存为16.00GB的计算机上运行的.实验环境为python3.6,运行工具为PyCharm2019.为了评估本模型的性能,本文在数据集Amazon 5-core的4个不同子数据集上(Musical Instruments,Automotive,Office Products,Tools Improvement)以及Yelp数据集上分别进行了实验.每一个子数据集均来自Amazon上同一类别产品,包含“用户ID”,“物品ID”,“评分(1-5)”以及“用户对物品评论”4个特征.数据集具体信息统计如表1所示.最后一列给出了各种数据集的稀疏度,可以看出其数据是十分稀疏的.数据稀疏度指无评分数据占整体评分数据的比率,即:
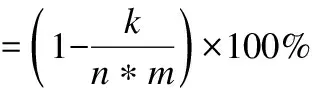
(24)

表1 数据集基本信息Table 1 Basic information of datasets
其中,n为用户数量,m为物品数量,k为评分数量.
4.2 参数设置
本实验词向量维度为300,bach_size均为100,选用Adam优化器更新模型参数.FM预测层的潜在特征向量维度在{15,30,50,100,200}上进行优化调节.卷积核大小为3*3,卷积核数量为45,GRU的隐藏单元个数与卷积核个数保持一致.正则系数和dropout分别为0.01和0.5.Musical Instruments,Automotive,Office Productss 3个数据集的学习率为0.001,Tools Improvement和Yelp两个较大数据集的学习率为0.01.对于基线模型的超参数设置,是根据其原论文相关参数进行设置的.
4.3 性能评估
为了对本文提出模型进行性能评估,选用了6种相关模型进行比较,分别为PMF,DeepCoNN,D-attn,NARRE,CARL和RPR.以上方法只有PMF是利用用户-物品评分数据的经典算法,其他均为近几年较为新颖且具有代表性的方法,且这些方法均结合了评论文本构建深度评分预测模型.
PMF:概率矩阵分解模型(Probabilistic Matrix Factorization),一个仅仅用到评分数据的标准矩阵分解模型[22].
DeepCoNN:深度协同神经网络模型(Deep cooperative Neural Networks),是首个同时结合用户评论集和商品评论集的深度学习模型,其性能优越[7].该模型使用两个并行的CNN网络从物品评论文本以及用户评论文本中提取潜在特征,然后利用矩阵分解进行评分预测.
D-attn:双重注意力模型(dual attention-based model),利用双重注意力机制模块从局部与全局两方面学习潜在特征表示,实现评分预测[23].
NARRE:具有评论可解释性的神经注意力评分回归模型(Neural attentional rating regression with review-level explanations),利用两个平行的CNN对评论中的词进行特征提取,并利用注意机制学习评论的有效性[24].
CARL:感知上下文的表示学习模型(context-aware user-item representation learning model),利用卷积操作与注意力机制方法共同进行文本特征提取,并结合历史交互的评分数据进行用户评分预测[14].
RPR:基于评论两极性的推荐模型(Review Polarity-wise Recommender model),利用CNN结构分别从积极评论和消极评论中提取用户喜欢以及不喜欢相关语义信息,进行用户-物品评分预测[25].
在实验过程中,为了避免因数据处理过程导致模型性能评估的偏差,所有方法的数据处理过程均一致.将随机打乱的数据按8:2分为训练集和测试集,采用十折交叉验证在训练数据上进行模型训练.评论文本数据只会用于用户偏好特征以及物品属性特征建模,不会出现在验证集以及测试集.具体文本处理过程如下:
1)将文本中所有字母都转换为小写并进行标点移除;
2)将每个句子拆分为一系列的词;
3)去除停用词;
4)利用TF-IDF计算词频,忽略高于0.5的文档频率的词条,并选择前20000个词构建词典;
5)移除评论文本中所有超出词典的词;
6)将所有文本长度固定为300,若文本长度大于300,则只取前300个词;若文本长度小于300,则进行填充.
为了评估预测性能,本文选用均方差(MSE)和平均绝对误差(MAE)作为评价指标.模型性能与MSE和MAE值成反比例关系.各种方法性能对比结果如表2所示.
(25)
(26)
其中,T是测试样本,yui是用户u对物品i的实际评分,而y′ui是预测评分.
根据表2可知,PMF方法性能整体表现均最差,尤其对于数据集较大且稀疏性较高的Tools Improvement和Yelp数据集.其原因是PMF是唯一一个只利用评分进行评分预测的方法,而其他方法均融合了评论文本信息.从此,可以看出评论信息作为辅助信息有效提高了评分预测准确性,且一定程度上缓解了推荐算法的数据稀疏性问题.DeepCoNN和RPR方法相对其他方法,在评论文本信息较长的Automotive和Yelp数据集上性能表现不是很好,其原因可能是该方法仅仅选用CNN进行文本特征提取.也就是说,CNN对于提取长文本信息不是很优秀.D-attn、NARRE和CARL等方法引入注意力机制,相比DeepCoNN性能提高较大,说明注意力的引入有利于帮助CNN从文本特征中捕获重要信息,减少噪声和不相关信息.考虑特征提取引入噪声问题,CARL进行了高阶特征提取.相比NARRE方法,CARL方法在5个不同类别数据集上性能均有较大的提升.上述方法基本均是基于CNN进行文本特征提取,虽然取得不错的成果,但是考虑CNN结构对于捕获长距离文本特征效果不是很理想.因此,本文提出了结合GRU和CNN的DMRR模型,以增强对长距离文本特征的提取.
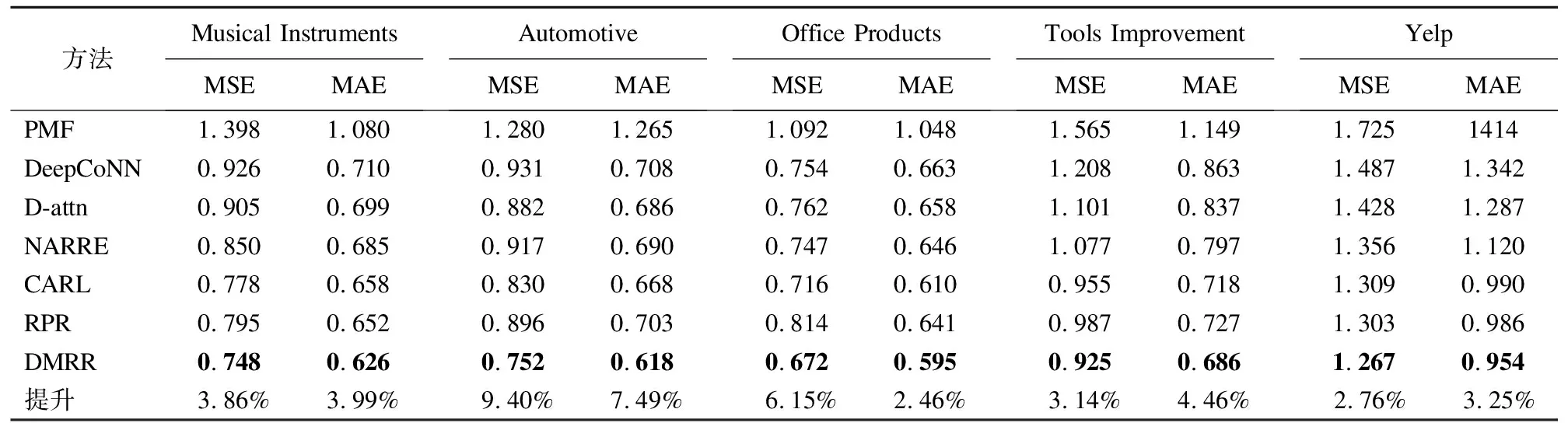
表2 各种方法MSE和MAE对比结果Table 2 MSE and MAE of various methods
实验结果表明,在5个数据集上,DMRR模型的MSE值和MAE值均是所有基于评论基线模型中最小的.对于DeepCoNN、D-attn模型,性能具有很大的提升,MSE分别平均降低了19.69%、15.18%.在评论文本信息较长的Automotive和Office Products数据集上表现极为突出,相对性能最好CARL模型提升了9.40%、6.15%,但对于过长评论的Yelp数据集性能提升一般.分析其主要原因是,评论文本过长,评论之间差异性很大,基于文档构建会引入过多噪声,导致模型性能下降.但根据整体实验结果表明,DMRR对于不同类型数据集的评分预测均有效可行,MSE平均降低了5.10%,MAE平均降低了4.33%.为了进一步验证DMRR模型的有效性,下文将给出相关实验及分析.
4.4 DMRR模型分析
本文融合了评论隐式特征与评分显示特征进行评分预测,并提出利用GRU与CNN同时进行文本特征提取,以及利用评分得到用户偏好程度和物品可推荐度,从而提升推荐性能.为了更清晰地说明DMRR模型的有效性,本节对该算法进行了横向对比分析.表3展示了基于评论特征提取以及基于评分矩阵分解两部分分别在5个数据集上对评分预测的影响.

表3 DMRR模型MSE和MAE结果Table 3 MSE and MAE of DMRR
值得注意的是,各个参数设置会影响模型性能.在比较相关模块对模型影响时,本实验涉及到的基本参数设置相同(如,潜在特征向量维度等).根据表3实验结果,无论MSE评价指标还是MAE评价指标都可以发现,结合GRU和CNN进行文本特征提取均比单纯利用CNN进行文本特征提取更有效,特别是在Amazon的数据集上提升较为明显.这是因为文本之间具有严重的依赖性,GRU相对于CNN更适合处理该问题.本文选择将二者进行结合,而不是仅仅用GRU取代CNN的原因是,当句子的情感分类是由整个句子决定的时候,GRU会更容易判断正确;当句子的情感分类是由几个局部的key-phrases决定的时候,CNN会更容易判断正确.本文则希望从局部与全局两方面提取文本特征,使语义信息提取更加精准.CNN对关键词进行逐个特征提取,获取评论的所有关键词特征.而GRU从整句评论进行特征提取和分析,进一步增强关键词之间的关联性.对于Yelp数据集,结合GRU和CNN进行文本特征提取效果不是很显著,分析其原因可能为以下两点:一是,GRU对于过长文本序列仍然很难准确捕捉上下文信息;二是,基于文档构建评论文本,可能会引入大量不相关信息,尤其对于过长文本.根据DMRR-CNN和DMRR-re的实验结果对比,可以明显看出模型性能的提升.验证了根据评分数据引入物品可推荐度以及用户偏好程度以增强文本语义信息的方法,可以有效提升推荐模型性能.由此说明,评分与评论信息的有效结合,可以有效提升预测准确性.
4.5 模型超参数调节
在保证实验数据集和实验环境相同的条件下,本文分析研究了不同超参数对该模型的性能影响.
1)潜在特征向量维度l
图3展示了分别在{15,30,50,100,200}不同潜在特征向量维度上对模型的影响.根据实验结果,可以发现DMRR在很大范围内性能变化均较小,即潜在维度数量对该模型的影响不大.虽然个别数据集(Office_Products)在一定范围内,性能随着维度增加略微有所提升,但FM利用二阶交叉特征进行评分预测的计算消耗也越大.本实验最终选择了l=15.
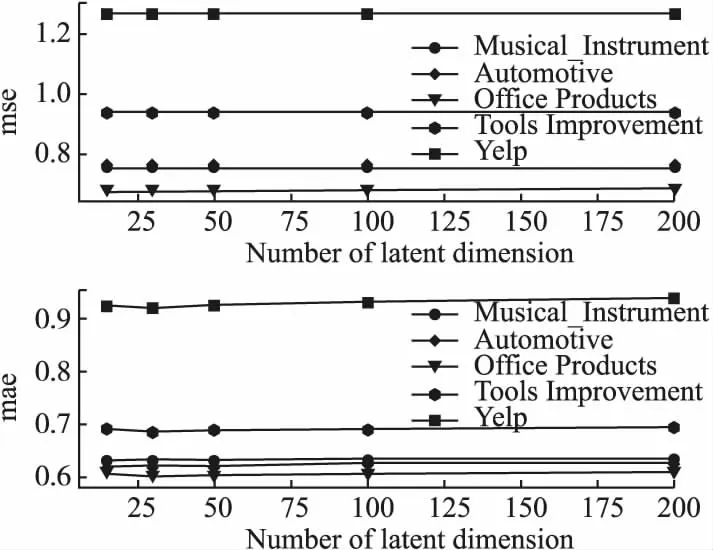
图3 潜在特征向量维度l对模型的影响Fig.3 Impact of dimension number l across the six datasets
2)dropout
在训练过程中会选择抛弃一些神经元避免过拟合,提升模型性能.但是如果抛弃率选择不合适,甚至可能会对降低模型性能.图4展示了不同dropout对模型的影响.根据实验结果可以发现,随着dropout比率增大,MSE值先逐渐减小后又持续上升.刚好符合前面得到的结论,dropout需选择适当.在该实验过程中,当dropout为0.5,模型性能最好.
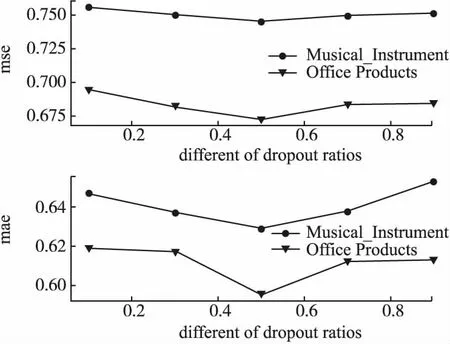
图4 dropout对模型的影响Fig.4 Impact of the different dropout ratios
3)正则系数
在训练过程中,模型的空间大小对模型在训练数据上的表现具有很大的影响.当模型空间很大,挑选到合适模型的概率就会降低,易于出现过拟合现象;当模型空间很小,很难找到数据拟合很好的模型.正则化实则是一种控制模型空间的方法,限制参数空间大小,减少泛化误差.如果正则系数过大,模型空间可能较小,导致模型可能因没有学习到训练数据中一些特征属性而产生欠拟合;如果正则系数过小,模型空间会很大,能够将训练数据特征属性学习很好,但测试性能可能不高.因此理想的正则系数可以让模型拥有较好的泛化能力,提高模型性能.本实验在[0.001,0.005,0.01,0.05,0.1]进行调节,根据图5可以看出,正则系数为0.01时,模型性能最好.
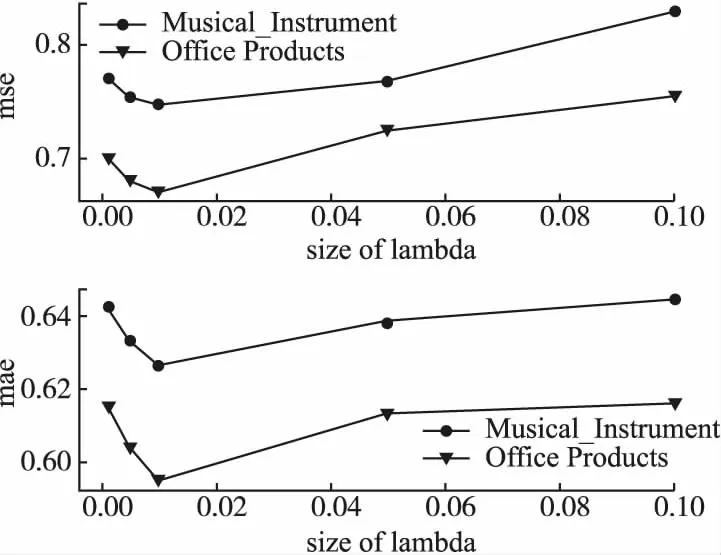
图5 正则系数对模型的影响Fig.5 Impact of the size of lambda
5 总 结
本文提出了融合评分与评论的深度评分预测模型DMRR.该模型有效结合评分与评论信息,提高模型的泛化能力.一方面,利用用户-物品评论文本更好的理解用户给出评分的原因;另一方面,利用评分数据进一步增强从评论文本中学习到的文本特征.理论分析与实验结果均表明,DMRR较目前相关模型,进一步提高了评分预测准确性.
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31 08:33:14
疯狂英语·初中天地(2021年11期)2021-02-16 00:38:58
少年漫画(艺术创想)(2019年2期)2019-06-06 07:47:02
电子制作(2018年19期)2018-11-14 02:37:08
自动化学报(2017年11期)2017-04-04 02:52:58
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
南都周刊(2015年1期)2015-09-10 07:22:44
南都周刊(2015年3期)2015-09-10 07:22:44
南都周刊(2015年4期)2015-09-10 07:22:44
小天使·一年级语数英综合(2015年8期)2015-07-06 06:23:32
