
一种用于自然场景文本识别的多路并行位置关联网络
2023-04-19 05:12:14叶东毅陈羽中
小型微型计算机系统 2023年4期
陈 敏,叶东毅,陈羽中
(福州大学 计算机与大数据学院,福州 350116) (福建省网络计算与智能信息处理重点实验室,福州 350116) E-mail:yzchen@fzu.edu.cn
1 引 言
文字具有丰富的语义信息,可以作为一种信息交流的方式嵌入到文档或自然场景中,是人类信息传递与交互的主要途径之一.自然场景中的文字识别可以帮助我们客观地理解世界,在无人驾驶、图像检索、机器人导航、遥感图像识别等领域获得了广泛应用.目前,传统的用于文档文本的光学字符识别系统已经非常成熟,但如何在自然场景下精确识别文本仍然是一个具有挑战性的问题.主要原因在于文本图像中存在字体变化多样、光照不均、文本布局不规则、文本过度弯曲等问题,导致模型所输出的字符序列和输入图像之间存在错位,严重影响模型的文本识别精度.因此,研究者逐渐开始关注现实生活中理解难度较大的复杂场景下的不规则文本识别任务.
随着卷积神经网络CNN(Convolutional Neural Network)和循环神经网络RNN(Recurrent Neural Network)得到广泛的应用,提升了场景文本识别网络的上下文建模能力并且取得了很好的效果.然而,目前大多数的模型鲁棒性较差,不规则文本的各种形状和弯曲模式对识别造成了更大的困难.一方面,由于图像背景复杂,相邻字符黏连紧密,容易产生识别误差,需要对单个字符进行顺序定位.另一方面,主流识别网络只考虑局部序列上下文依赖关系,在预测字符序列时,缺少全局语义信息的监督,会错误识别边缘特征,需考虑获取全局语义信息作为补充.由此可见,对于自然场景下的文本识别,不仅依赖于图像的视觉特征,还取决于相邻字符间的位置信息和全局语义信息.
要正确识别文本图像中的内容,必须准确感知每个字符的顺序.通常,一个文本中的字符大小是相同的.然而,不同场景文本中的字符布局可能不同.因此,从场景图片中获取字符的位置信息将有利于对数据信息更深层次的挖掘.基于上述分析,本文提出了位置关联模块,该模块通过将高维特征图逐列分离成一维向量,在每个时间步上将一维向量连接到长短期记忆单元,并采用多层连接设计顺序关联一维向量,不仅对上下文信息进行编码,而且对位置信息进行编码.最后通过双层卷积神经网络归一化序列特征,生成与形状和字符排列相适应的特征图,有助于顺序获取字符间的位置信息以大致确定字符位置.
针对全局语义信息不足问题,主流的文本识别方法[1,2]都采用单向串行传输的方式,递归地感知当前解码时间步的语义信息.但这些方法都只能从每个解码时间步中获取有限的语义信息,并且第1个解码时间步没有可用的语义信息,甚至会向下传递错误的语义信息,导致错误积累.同时,串行传输模式效率较低.针对上述问题,本文提出了一个并行注意力模块,该模块基于多路并行传输的方式获取全局语义信息,通过多头自注意力机制进行上下文通信,可以同时感知一个字符或一行中所有字符的语义信息,选择性地关注文本关键信息而忽略其他次要信息,提升了模型的高效性.
基于上述问题,本文提出了一种基于多路并行的位置关联网络(Multi-Path Parallel Location Association Network,MPLAN),MPLAN能够有效对齐字符,确保字符间位置信息相关联,同时能够并行捕获全局语义信息,避免了注意力漂移问题.主要贡献如下:
1)MPLAN通过关联字符位置信息与全局语义信息,提高了场景文本识别网络的准确性和有效性.
2)MPLAN提出了位置关联模块,在序列特征中顺序捕获相邻字符间的位置信息,使得特征向量表达出空间位置特性.解决了缺少字符间位置信息的问题.
3)MPLAN提出了并行注意力模块来获取全局语义信息,该模块通过关联局部特征的相关性,采用多路并行的传输方式获取全局语义信息,解决了场景文本识别中全局语义信息不足的问题.
4)MPLAN在训练阶段只需要单词级注释,可充分利用真实数据和合成数据进行训练.并在包括规则文本、不规则文本在内的几个测试数据集基准上达到了最先进的性能.
2 相关工作
早期的场景文本识别方法[3,4]大多基于逐个字符分类的方法完成场景文本识别,即先通过滑动窗口检测单个字符,利用设计好的字符分类模型识别出每个字符类别,再采用动态规划的方法将其整合得到文本单词内容.但这些方法依赖于人工设计的特征工程和验证规则,将难以满足复杂的自然场景文本识别需求.随后,又提出了基于单词分类的识别方法,即直接从整个图像中预测文本实例,以单词表为依据,进行单词类别识别,不需要检测单个字符.Jaderberg等人[5]将场景文本图像的识别任务转换为文本分类任务,将整张文本图像输入到CNN网络中,以高召回率的区域建议方法和过滤阶段来进一步回归字符边界框,采用字典分类模型输出目标文本序列.Almazan等人[6]提出从输入图像中预测标签嵌入向量,将输入图像和对应的文本标注映射到同一个公共的向量空间中计算最近距离.文献[7]采用具有结构化输出层的卷积神经网络与条件随机场CRF(Conditional Random Field)相结合的模型,实现了无字典约束的文本识别.
近年来,随着深度学习的进一步发展,场景文本识别算法取得了巨大进展.场景文本通常以字符序列的形式出现,因此通常将其建模为序列识别问题,并使用RNN对序列特征进行建模.Sutskever等人[8]用序列特征表示图像,采用递归神经网络将输入特征映射成固定维度的向量,再使用另一个递归神经网络从向量中解码目标字符序列.Shi等人[9]将CNN与RNN相结合运用到场景文本识别中,使用CNN从输入文本图像中提取图像特征,使用RNN对其进行序列重构,采用联结主义时间分类损失来识别字符数,实现字符序列预测.由于这类方法赋予不同位置上的序列特征相同的权重,将难以定位关键字符识别区域,并且串行计算降低了运算效率.因此,Yang等人[10]提出了一种基于Transformer[11,12]的注意力解码器,可以有效地处理长序列,而且能并行地执行训练,提升了模型的收敛速度.
随着注意力机制[13]在自然语言处理领域的成功,越来越多的研究者将其运用到场景文本识别领域.Lee等人[14]提出使用具有注意力建模的递归卷积神经网络来构建更加紧密的特征空间和捕获长距离的上下文依赖关系.该模型将输入文本图像水平编码为一维序列特征,然后利用上一个时间步骤的语义信息引导视觉特征隐式建模字符级语言模型,之后由解码器生成目标字符序列.Cheng等人[15]指出现有注意力机制存在的注意力漂移问题,并提出了一个关注注意力网络FAN(Focusing Attention Network),使得偏移的注意力重新聚焦在目标区域上,从而确保解码阶段的字符与序列特征能够对齐.FAN能够自动调整注意力网络的注意力中心,但需要额外的字符级的标注.Wang等人[16]提出了一个解耦注意力网络DAN(Decoupled Attention Network),该网络设计了一个卷积对齐模块CAM替换传统注意力解码器中的递归对齐模块,将对齐操作与历史解码结果解耦合,避免了错误信息的积累,使得识别算法的性能进一步提升.Litman等人[17]提出了一个选择性上下文优化网络SCATTER(Selective Context ATtentional Text Recognizer),采用堆叠特征监督块的方式,细化视觉特征表示,编码上下文相关性,并将视觉特征与上下文特征拼接,提升了选择性解码器的识别精度.
上述模型主要针对水平方向上的规则文本图像,难以准确识别存在透视失真或任意形状弯曲的不规则文本图像中的字符.为了准确识别复杂场景下的不规则文本图像,研究人员尝试在预处理阶段对不规则文本图像进行矫正.Shi等人[18]提出基于空间变换网络STN(Space Transformer Network)[19],使用薄板样条算法TPS(Thin Plate Spline)将不规则的文本矫正为线性排列的文字序列,并采用双向长短期记忆网络进行序列建模,提高了识别性能.ESIR[20]采用一种新颖的线性拟合变换估计文本行中的字符位置,并通过多次迭代空间变换网络的方法产生更精确的失真矫正.Yang等人[21]提出一种对称约束的矫正网络ScRN(Symmetry-constrained Rectification Network),使用每个文本实例的中心线,并通过一些几何属性(包括文本中心线方向、字符方向和比例)添加对称约束.由于对文本形状的详细描述和对称约束的显式描述,ScRN在文本矫正方面具有较强的鲁棒性.Lin等人[22]提出了一个以分解为核心思想的图像矫正网络STAN(Sequential Transformation Attention-based Network),利用空间变换网络将仿射变换独立作用在分割后的图像块上,通过网格投影子模块平滑相邻块之间的连接来矫正不规则文本.由于文本矫正网络无法有效解决复杂场景中的模糊、光照不均等问题,一些研究人员考虑通过获取2D空间信息进行不规则文本识别.Li等人[23]设计了一个二维注意力编码器网络SAR(Show-Attend-and-Read),通过额外添加一个二维注意力分支,为单个字符选择局部特征和字符领域信息,提升了文本识别精度.Huang等人[24]提出了有效区域注意网络EPAN(Effective Parts Attention Network),该网络引入了两阶段注意力机制,第2阶段的注意力机制从第一阶段的注意力机制生成的过滤特征中选择辅助信息用于定位有效字符区域.
为了获取字符位置信息,一些研究工作采用语义分割的方法对单个字符位置进行分割.Wan等[25]设计了一种基于语义分割的双分支识别系统TextScanner,两个分支可以独立预测字符的类别和几何信息,借助字符间的位置顺序提高了模型识别性能.Two-Attention[26]是基于FCN(Fully ConvolutionalNeural Networks)的语义分割识别网络,将不规则文本识别视为图像分割问题,设计了二维注意力编码器网络,通过搜索字符的空间位置关系提升了识别性能.不过基于分割的方法需要精确到字符级的标注,训练代价较大.
3 模 型
3.1 模型框架
本文所提出的并行位置关联网络MPLAN的框架如图1所示.MPLAN是一个可端到端训练的网络模型,包括文本矫正模块、特征提取模块、位置关联模块、并行注意力模块和字符预测模块.给定一个输入图像I,由文本矫正模块对输入图像进行归一化矫正,得到矫正图像Ir,然后通过特征提取模块从矫正图像Ir中提取视觉特征F,位置关联模块从视觉特征F中逐列捕获字符位置信息,其输出是一个包含不同字符位置信息的特征向量M.并行注意力模块通过多通道对位置关联模块输出的特征向量M并行解码,生成N个对齐的一维序列特征P,每个特征对应文本中的一个字符,并捕获对齐后的全局语义信息.最后,将对齐后的特征向量征P输入字符预测模块,输出N个预测字符.
3.2 文本矫正模块
在自然场景中,过度弯曲文本和透视失真文本十分常见,给识别工作带来了极大的挑战.本文在图像预处理阶段针对不规则文本进行水平矫正.文本矫正网络是以空间变换网络STN为基础,并结合TPS进行参数变换.其中,TPS是基于二维空间的插值方法,针对弯曲文本进行非刚性变换,广泛运用于在文本图像的变换和匹配.STN由定位网络、网格生成器和采样器3个部分组成.定位网络会沿输入图像I中文本的上下边界预测一组固定数量的控制点,通过控制点间的线性关系计算TPS变换矩阵,网格生成器根据控制点的位置和TPS变换矩阵确定采样点的位置,将采样点的位置信息输入到采样器中生成最终的矫正图像Ir.

图1 MPLAN整体框图Fig.1 Overall framework of MPLAN
3.3 特征提取模块
在特征提取阶段,通过不断堆叠卷积层和最大池化层,并使用残差连接加深网络的深度,从而提取更丰富的视觉特征.特征提取模块以改进的ResNet50作为骨干网络.改进的ResNet50每层对应于一个输出,且将Block3、Block4、Block5这3个残差块中的步幅由(2,2)改为(1,1),并额外添加3个最大池化层用于对特征图进行下采样操作.其中,最大池化层的卷积核大小为(2,1),可以在水平轴上保留更多的信息,有利于避免多字符的粘连问题.特征提取模块以采样器输出的矫正图像作为输入,最后一层输出特征图,F∈H×W×D,H为高,W为宽,D为通道的数量.为了保持原始的高宽比,调整输入图像的大小,使其具有固定高度和可变宽度.
3.4 位置关联模块
要正确地识别文本图像中的内容,就必须依赖于顺序读取字符的位置信息.针对复杂背景下的不规则文本,不仅要关注相邻字符间的上下文语义信息,还需捕获字符位置信息.常用的方法都需要将输入图像转换为中间序列表示,并使用RNN对其进行编码和解码,在解码过程的后几个时间步中,将会出现字符位置信息不足,从而导致字符对齐不一致的错误识别.针对在特征图上精确定位字符的问题,MPLAN提出了位置关联模块来顺序捕获字符间的位置信息,使输出的特征映射带有字符位置信息.位置关联模块的详细架构如图2所示.
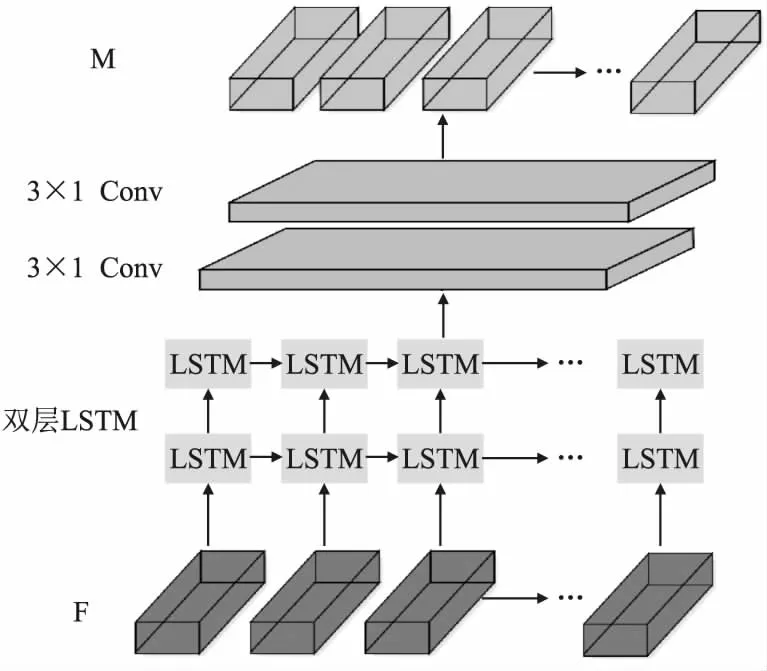
图2 位置关联模块结构图Fig.2 Structure of location association module
位置关联模块直接对特征提取模块输出的视觉特征映射F以宽度为基准,采用两层单向的LSTM逐列使用512个隐藏状态大小来顺序捕获字符位置信息和关联上下文语义信息.对于所有特征行,可在LSTM单元内共享参数,以克服过拟合和减少参数量.然后,使用两个3×1的卷积层,并在层间插入了一个ReLU函数来输出包含位置信息的特征向量Fk.位置关联模块生成特征向量Fk的运算过程如下:
(1)
(2)
Fk=f(F2)
(3)
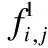
位置关联模块将特征提取模块的输出F与Fk进行级联相加得到最后的输出特征M∈dmodel,其中dmodel表示输出的特征维度.这使得输出特征能够学习表示字符的位置信息.
3.5 并行注意力模块
注意力机制广泛应用于序列识别问题,其核心思想是特征对齐,将输入特征的相关信息对齐对应的输出信息.在识别问题上,使得字符之间的特征相关性可以在高阶特征中相互关联.传统的注意力机制存在时间依赖和串行计算的问题.本文提出了一个并行注意力模块,并行注意力模块由多头注意力机制和前馈神经网络构成的网络堆叠2次而成,使用残差网络连接每一个子层,通过并行训练增强网络性能.并行注意力模块采用多头注意力机制在不同特征子空间中学习相关信息,并使用前馈神经网络作用于注意力机制输出的每一个位置上,进而从多角度得到更全面的特征表示.
多头注意力机制是集成多个独立运行的自注意力机制,可以在不同的位置联合处理来自不同特征表示子空间的信息,从而实现并行编码.其中,自注意力机制是注意力机制的一个特例,可以快速提取局部特征内部的依赖关系,并且只针对重要信息进行学习.自注意力机制主要采用缩放点积注意力,首先将位置关联模块的输出特征M通过3次不同的线性变换得到3个维度均为dk的输入矩阵:查询Q、键K、值V,输出是根据Q与K的相似度计算V上的加权和.缩放点积注意力计算公式如下:
(4)
Softmax可以将Q和K的点积运算结果进行归一化处理.并行注意力模块可以并行计算n_head次缩放点积注意力,然后将n_head次的缩放点积注意力结果进行拼接得到多头注意力权重求和结果C=[c1,c2,c3,…,cN],计算公式如下:
(5)
ct=MultiHead(Q,K,V)=Concat(head1,…,headn_head)W0
(6)
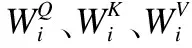
前馈神经网络包含了两个线性变换,中间有一个ReLU激活函数.将多头注意力机制的输出C经过前馈神经网络得到并行注意力模块的输出P=[p1,p2,…,pN].前馈神经网络的定义公式为:
FFN(x)=max(0,xW1+b1)W2+b2
(7)
其中,W1、b1、W2和b2都是可训练参数.此外,运用同一个线性变换作用在不同的位置上,权重参数在层间是共享的.
3.6 字符预测模块
字符预测模块的作用是将输入的序列特征向量转换为目标字符串,能够输出任意长度的字符序列.字符预测模块是一个单向的循环网络,由注意力机制和字符级的门控循环神经网络GRU组成.识别阶段的注意力机制用于捕获输出字符间的依赖关系,使得模型在每个时间步骤上聚焦于目标字符区域.该网络更新每一个解码步骤处的状态都可以再次访问序列特征中的所有状态,会更明确关注到目标字符部分.每个序列特征都将迭代N次,产生长度为N的目标字符序列,表示为Y=(y1,…,yN).
在第t步,识别网络根据并行注意力模块的的序列输出P、GRU内部隐藏层状态st-1和上一步的预测yt-1来预测目标字符或序列结束符号(EOS).当预测出一个“EOS”时,将停止预测.整个识别网络采用GRU学习注意依赖关系.在时间步长t时,输出yt,公式如下:
yt=Softmax(WoutSt+bout)
(8)
其中,st是第t时间步GRU单元的隐藏层状态.隐藏层状态st通过GRU的循环过程进行更新,公式如下:
st=GRU(yp,gt,st-1)
(9)
其中,yp是上一时间步输出yt-1的嵌入向量,gt表示上下文向量,计算特征P=[p1,p2,…,pN]的加权和,公式如下:
(10)
其中,T表示特征长度,pi∈P表示在第i时间步的序列特征向量,αt,i是注意力权重向量,公式如下:
(11)
et,i=Tanh(Wsst-1+Whpi+b)
(12)
其中,et,i为对齐得分,表示高级特征表示与当前输出的相关度,st-1是GRU单元的上一时间步的隐藏层状态,Wout、Ws、Wh、bout和b分别表示线性变换和分类器的偏差,都是可训练参数.
4 实验结果
4.1 数据集与对比模型
本文在两个合成数据集Synth90K[28]和SynthText[29]上进行训练,并在6个公开数据集上进行测试,包括IIIT5K-Words(IIIT5K)[30]、Street View Text(SVT)[31]、ICDAR 2013(IC13)[32]、ICDAR 2015(IC15)[33]、SVT-Perspective(SVT-P)[34]、CUTE80(CUTE)[35].其中,IIIT5K、SVT和IC13属于规则文本数据集,IC15、SVT-P和CUTE属于不规则文本数据集.
实验中采用的对比模型有文本矫正模型Aster[18]、Esir[20]和ScRN[21],语义分割模型TextScanner[25]和Two-Attention[26],以及注意力机制模型SAR[23]、EPAN[24]、Holistic[10]、DAN[16]、Seed[27]、STAN[22].
4.2 实验设置和评估指标
本文实验中,原始图像调整为64×256输入到文本矫正模块中,采用较大的输入尺寸是为了保留高分辨率.文本矫正模块输出大小为32×100的矫正图像作为识别网络的输入图像,控制点数量设为20.特征提取模块中采用改进的ResNet50作为骨干网络.其中,最大池化层采用2×1的下采样步幅,有利于沿横轴保留了更多的分辨率以区分相邻特征.骨干网络之后是两层单向连接的LSTM单元,每一层的LSTM采用512个隐藏单元,LSTM的输出经过两个3×1卷积层和ReLU激活函数将特征图线性投影为512维.并行注意力模块是由2个Transformer单元块组成,其中head=8,隐藏单元数为512,最后由字符预测模块输出最终的字符序列.模型训练采用ADADELTA作为优化器,批处理大小为128,初始学习率为0.8.设置输出序列N的最大长度为25.性能评估指标采用单词级的识别精度.
在测试推理阶段,模型采用波束搜索法,即每步保持累积分数最高的k个候选项,k=5.
4.3 模型性能分析
表1展示了MPLAN和对比模型在6个测试数据集上的实验结果.除MPLAN模型外,其他对比模型的相关数据均来自相关文献.从表1的实验结果可以发现,在仅使用合成训练数据集的情况下,MPLAN模型在IIIT5K、SVT、IC13、IC15、SVT-P和CUTE这6个测试数据集上的精度为94.7%、91.5%、93.2%、82.2%、82.5%、88.2%,总体识别表现优于其他对比模型,特别地,与其他对比模型相比,MPLAN在具有挑战性的不规则文本数据集IC15和CUTE上性能提升显著.MPLAN只在IC13和SVT-P测试数据集上的精度略低于TextScanner和EPAN.但是,TestScanner在训练阶段需要额外的字符级注释,EPAN在不规则文本数据集上的识别精度不高.
与文本矫正模型Aster、Esir和ScRN相比,MPLAN在规则文本数据集和不规则文本数据上均有显著提升.与语义分割模型Two-Attention和TextScanner相比,MPLAN在IIIT5K、SVT、IC13、IC15、SVT-P和CUTE 这6个测试数据集上的精度相比Two-Attention模型分别提升了0.7%、1.4%、0.5%、5.9%、0.2%、1.4%.MPLAN在SVPT数据集上略低于TextScanner,在IIIT5K、SVT、IC13、IC15和CUTE 5个测试数据集上的精度相比TextScanner则分别提升了0.8%、1.4%、0.3%、2.6%、4.9%.与基于注意力机制的模型SAR、EPAN、Holistic、DAN、Seed、STAN相比,MPLAN在IC15、SVT-P和CUTE 这3个不规则文本数据集上至少获得2.2%、0.3%和2.8%的提升,证明MPLAN在不规则文本数据集上更具优势.与采用语义分割或传统注意力机制的模型相比,MPLAN考虑了相邻字符间的位置信息与全局语义信息,能够顺序捕获字符位置信息,并关联上下文语义信息,从而提升了识别精度.
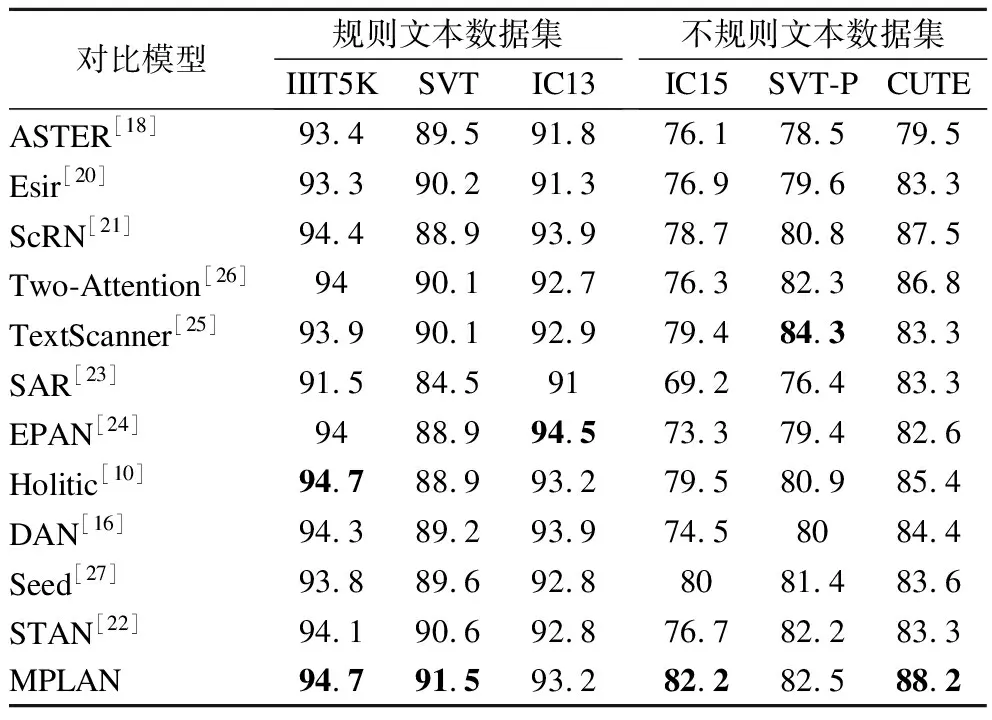
表1 MPLAN与基准模型的性能对比Table 1 Overall performance of MPLAN and baseline models
4.4 消融分析
本节通过消融实验评估不同模块对模型总体性能的影响.为了公平起见,训练以及测试设置均相同.MPLAN的消融模型包括了MPLAN w/o RECT、MPLAN w/o LAPA、MPLANw/oLOCATION 这3个实验.其中,MPLAN w/o RECT表示从MPLAN去除文本矫正网络,将原始图像直接输入到识别网络中.MPLANw/oLAPA表示从MPLAN中去除位置关联模块和并行注意力模块,仅采用Bi-LSTM进行序列建模.MPLANw/oLOCATION表示去除位置关联模块,使用Transformer中的正余弦位置编码进行替换.
实验结果如表2所示,可以看出各模块对MPLAN的整体性能均有提升作用.与MPLAN相比,MPLAN w/oRECT在数据集IIIT5K、SVT、IC13、IC15、SVT-P、CUTE上分别下降了0.7%,0.8%、0.6%、2.9%、2.7%、2.8%.上述结果表明文本矫正网络可以将不规则文本调整为线性排列的规则文本,在一定程度上降低弯曲文本的识别难度.与MPLAN相比,MPLANw/oLAPA在数据集IIIT5K、SVT、IC13、IC15、SVT-P、CUTE上分别下降了0.7%,0.6%、0.9%、2.6%、0.6%、4.2%.上述结果表明使用Bi-LSTM进行序列建模的效果不佳,因为Bi-LSTM为不同的特征分配相同的权重,使得模型难以识别到字符的有效区域,相反,结合位置关联模块和并行注意力模块的序列建模可以高效的顺序定位字符的有效区域,为字符区域分配更高的权重.与MPLAN相比,MPLANw/oLOCATION在数据集IIIT5K、SVT、IC13、IC15、SVT-P、CUTE上分别下降了0.7%,0.8%、1.5%、2.4%、3.7%、3.8%.因为Transformer中基于正余弦的位置编码只学习特征的相对位置表征,无法隐式地学习序列特征的位置信息,相反,位置关模块能在序列特征中顺序捕获相邻字符间的位置信息,使得特征向量表达出空间位置特性,有助于提高序列特征与目标字符的对齐准确度.

表2 不同模块对MPLAN性能影响Table 2 Effect of different modules on the performance of MPLAN
位置关联模块是本文提出的MPLAN模型的重要改进.为了进一步验证位置关联模块的有效性,本文在当前最先进的自然场景文本识别模型ASTER模型中添加位置关联模块,观察位置关联模块对ASTER模型的性能影响.ASTER模型由文本矫正网络和注意力识别网络组成,在文本识别阶段采用Bi-LSTM进行序列建模.由于Bi-LSTM存在难以准确识别字符有效区域的问题,因此在ASTER模型添加位置关联模块用于顺序定位字符有效区域,在相同实验参数设置下,实验结果如表3所示.从实验结果可以发现,在不规则文本数据集IC15、SVT-P和CUTE上,添加了位置关联模块的ASTER+LOCATION模型相较ASTER模型在精度上分别提升了5.2%、1.7%与3.8%.上述实验结果表明位置关联模块通过捕获字符位置信息,能够显著提高序列特征与目标字符的对齐准确度,有效提高模型的识别性能,进一步证明了位置关联模块的有效性.

表3 位置关联模块对ASTER模型的性能影响Table 3 Effect of location association module on the performance of ASTER
4.5 参数分析
本节通过实验分析MPLAN模型中的Transformer单元块数量对MPLAN的性能影响.MPLAN在并行注意力模块中,使用Transformer的处理单元并行编码字符的全局语义信息,从而达到传播字符上下文通信的作用.并行注意力模块中Transformer单元块的数量是影响MPLAN实验效果的重要参数.表4给出了相同实验参数配置下,不同Transformer单元块数量对MPLAN模型性能的影响.在包含常规文本、不规则文本在内的6个测试数据集上,当Transformer单元块为2时,获取全局语义信息的效果最佳,识别精度最高,且在CUTE数据集上显著高于其余两个参数实验,表明模型的稳定性还有待提高.当Transformer单元块为1时,存在无法有效捕获长距离依赖关系,使序列特征缺少完整的全局语义信息.当Transformer单元块为4时,单元块数过多导致引入了一些无关信息,赋予复杂背景过多的权重而错误识别为字符前景.上述实验表明,在堆叠两层Transformer处理单元时,模型的性能最佳.

表4 不同Transformer单元块对MPLAN性能影响Table 4 Effect of different number of transformer unit blocks on the performance of MPLAN
5 总 结
本文认为字符位置信息和全局语义信息对于自然场景下的文本识别是重要的.基于这一发现,本文提出了一个并行位置关联网络用于解决文本识别问题.MPLAN将字符位置信息和全局语义信息相结合,从而获得准确的序列表征向量.为了有效定位字符的位置,MPLAN提出了一个位置关联模块来顺序捕获字符间的位置信息.在全局语义信息的获取上,MPLAN采用了多路并行的思想,通过多通道并行获取语义信息,有效建模目标字符间的关联信息.在包括规则文本和不规则文本在内的6个公开数据集中,MPLAN都取得了最佳的识别精度效果,表明该算法明显优于现有算法.经过验证,本文所提出的MPLAN在针对不规则文本数据集上表现出了鲁棒性.在未来工作中,本文将会扩展该方法来处理无明显上下文信息的文本识别问题,将字符位置信息同更深层次的序列建模相结合也是值得研究的一个方向.
猜你喜欢
电脑爱好者(2022年15期)2022-05-30 01:29:23
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
开放教育研究(2020年2期)2020-03-31 01:54:14
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
