
融合词语多特征的汉老短文本相似度计算
2023-04-19 05:12:16周兰江周蕾越
小型微型计算机系统 2023年4期
郭 雷,周兰江,周蕾越
1(昆明理工大学 信息工程与自动化学院,昆明 650550)2(昆明理工大学 津桥学院,昆明 650160) E-mail:2432948148@qq.com
1 引 言
中老两国双边经贸关系密切,两国政府和民间交往日益密切,老挝和中国都是社会主义国家,在彼此的发展道路上相互帮助和学习,这种兄弟般的关系给中老关系注入了亲情色彩.而语言是中老两国交流的重要工具,因此对老挝语的研究有着重大的意义.文本相似度计算是文本匹配任务的一个特殊形式,返回文本之间相似程度的具体数值.跨语言文本相似度计算更是具有广泛的应用前景,例如跨语言的信息检索系统,跨语言的文本改写剽窃检测系统,机器翻译等等.跨语言文本相似度计算目前主要有基于机器翻译的方法、基于LDA主题模型的方法、基于神经网络的方法等.
由于本文研究研究的对象老挝语属于低资源语言,缺乏大规模语义词典,现有的机器翻译系统还不足以生成高质量的译文,不适合利用机器翻译的方法在目标语言层或中间语言层进行文本相似度计算.而LDA模型是一种词袋模型,忽略了文本中词语的位置信息,对文本具体语义性表征不足,实验效果一般.随着神经网络不断发展,目前采用神经网络计算文本相似度得到许多学者的广泛应用.
本文从最具有语义表达的单位词语出发,从词语形态学、词性、词性权重的角度出发,首先将汉语词语拆分成笔画的形式,老挝语词语拆分成音符的形式,利用BiLSTM和3种不同尺度的CNN提取词语的形态学特征、汉字内部结构特征,如偏旁部首等,并拼接上词性特征向量,词性权重向量,接着利用BiLSTM和CNN对嵌入层编码的词语特征向量进一步提取汉老短文本语义特征,采用ESIM交互注意力机制让汉老短文本的语义信息进行交互,最后计算汉老短文本的相似度分数.本文提出的方法在语料稀缺的情况下取得了更好的效果,F1值达到了78.67%.
本文的主要贡献如下:
1)根据汉语和老挝语的语言特点,通过对其词的研究,在汉老短文本分布式表示上融入了汉老词语的形态学特征、词性特征、词性权重,使得汉老短文本的分布式表示含有更多的语义信息,提高了模型的效果.
2)利用弱监督跨语言词向量模型,对齐汉老双语词向量,在同一语义空间里面表征汉老短文本.并利用ESIM交互型注意力机制对汉老短文本的语义信息进行交互,提高模型效果.
2 相关工作
文本相似度计算是通过一定方法计算两个文本(句子、短文本、文档),得到具体的数值.相比于单语言文本相似度计算,跨语言文本相似度计算在语序等方面存在较大的差异,使得跨语言文本相似度计算更具有挑战性.目前跨语言文本相似度计算主要有以下几种:
1)基于机器翻译的方法,石杰[1]等人利用早期的机器翻译方法,即通过语义词典Wordnet将中文和泰文翻译为中间层语言,再在中间层语言的平台上进行文本相似度计算模型的构建.Erdmann[2]等人将维基百科上的文本翻译成另一篇文章的语言,再使用机器翻译的评估指标计算文本的相似度;Wu[3]和Tian[4]等人通过机器翻译系统将不同语言转换为英语,在目标语言英语上进行语义相似度衡量.此方法针对老挝语来说并不是最优的选择,老挝语属于资源贫乏型语言,种子词典的规模较小,数量较少并不足以覆盖所要测试的中文文本,此方法正确率较低.
2)基于LDA主题模型的方法,利用LDA主题模型训练文档语料,得到文档在各个主题空间上的概率分布情况.程蔚[5]等人利用双语平行语料训练出双语LDA模型,然后利用该模型预测新语料的主题分布,结合主题分布概率,利用余弦相似度计算新的双语文档的相似度;李训宇[6]等人利用单语LDA模型分别抽取汉语和缅甸语的主题,并将主题下的主题词通过双语词典映射到同一空间进行表征,得到汉缅双语主题词向量.最后结合主题词向量和主题分布概率,利用余弦相似度计算双语文档的相似度,然后获取汉缅双语可比文档.Ni[7]等人提出ML-LDA(Multilingual Topics-Latent Dirichlet Allocation)模型来提取维基百科平行语料中的“通用”主题,该“通用”主题能被多种语言表示,使得不同语言的文档的主题能在一个空间表示.
3)基于神经网络的方法,通过神经网络建模,提取文本语义特征来计算文本相似度是目前比较主流的方法.对于单语言文本相似度计算,郭浩[8]等人利用BiLSTM和CNN相结合的孪生神经网络结构计算短文本相似度分数.对于跨语言文本相似度计算,由于不同语言文本之间带来的差异性,很多学者将其翻译成中间语言来进行文本相似度计算,如李霞[9]等人采用谷歌翻译将不同语言的文本翻译成英语,并提出将门控卷积神经网络结合自注意力机制实现了对多种语言句子级别的相似度计算.这种方法并不适用于老挝语等低资源语言,因为目前翻译系统还不足以生成高质量的译文,翻译不准确会形成累积误差,影响模型效果.针对低资源语言,赵小兵[10]等人用不同规模的藏汉文本语料训练了siames LSTM藏汉跨语言文本相似度计算模型,实验表明语料规模对模型效果影响较大.
由于机器翻译的方法需要大规模的语义词典或者效果较好的翻译系统,但对于目前研究基础较为薄弱的老挝语来说此方法还不可行,而LDA模型是词袋模型,缺乏具体语义的表征,模型效果较差.目前多数学者采用神经网络提取跨语言文本特征的方法来计算文本相似度.
3 汉语-老挝语词语形态学


表1 汉-老词语形态学特征对应表(部分)Table 1 Correspondence table of morphologicalcharacteristics of Chinese-Lao words (part)
4 融合词特征的汉老双语短文本计算模型
4.1 模型结构
本文利用jieba工具对汉语短文本语料进行分词和词性标注,利用昆明理工大学实验室开发的老挝语分词[13]和词性标注[14]工具对老挝语短文本语料进行处理,并去除停用词.考虑到词或字本身的形态或内部结构可以帮助人们直观地获取部分语义信息,本文采用BiLSTM和CNN提取汉老词语的形态学特征或汉字的内部结构特征,并将此特征向量拼接到原有的词向量上.其次由于每个词的词性不同,导致该词对短文本语义信息贡献程度的差异,本文将词语的词性向量拼接到该词的词向量上,并将每个词的词性权重也融入到短文本分布式表示里,使得汉老短文本的分布式表示含有更丰富的语义信息,模型效果更佳.
嵌入层编码完成后,本文采用BiLSTM和CNN共同对汉老双语短文本提取特征,然后采用ESIM模型的交互注意力机制,让汉老短文本的语义信息进行交互,最后通过全连接层计算汉老短文本相似度分数.其结构如图1所示.
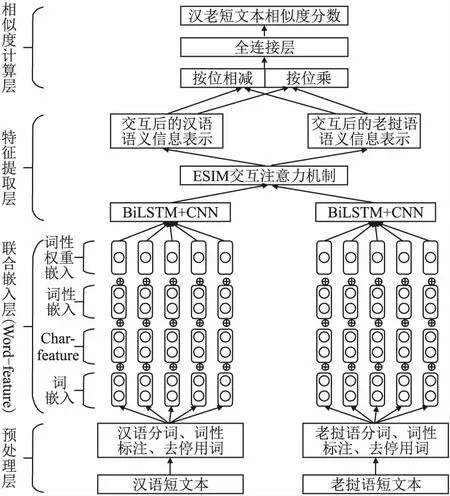
图1 融合词语多特征的汉老短文本相似度计算模型图Fig.1 Similarity calculation model of Chinese and Laotexts fused with multi-features of words
4.2 嵌入层
4.2.1 汉老词向量对齐
词向量是文本语义表征的基础,其质量对实验效果有较大的影响.针对跨语言文本相似度计算的任务,如果能使得汉语语词语和老挝语词语能映射在同一空间下,将大大提高汉老跨语言短文本相似度计算的准确率.
Artetxe[15]等人提出仅使用25对单词或简单的数字作为种子词典,将种子词典表示为二进制矩阵D,假设字典中第i个源语言单词与第j个目标语言单词对齐,则Dij=1,通过公式(1)利用SVD方法求解得到最优映射矩阵W*,使得目标语言词嵌入矩阵Xi*和源语言单词词嵌入矩阵Zj*之间的平方欧几里得距离之和最小.然后再利用求解出来的最优线性变换矩阵W*对源语言词嵌入矩阵X进行线性变换、即X′=XW*,实现源语言到目标语言的语义空间映射,其实验结果证明半监督的跨语言词向量模型也可以得到高质量的跨语言词向量.
(1)
由于有监督跨语言词向量模型对种子词典的数量和质量都有较高的要求,老挝语属于低资源语言,比较适用于使用半监督方法.效仿Artetxe等人的实验,使用半监督跨语言词向量模型得到了汉老跨语言词向量.
4.2.2 汉-老词语形态学特征提取
词或字本身的形态或内部结构可以帮助人们直观地获取部分语义信息,Cao[16]等人提出利用笔画的n-gram特征提取中文词语内部语义信息,并取得了较好地实验效果.Wieting[17]等人提出使用字符级的n-gram向量来表示英语中的单词,以捕获包括前缀、后缀、词根等语义特征.这对本文开展汉语形态学研究和老挝语形态学研究有着重要的指导意义.考虑到汉语词语最小组成单位为笔画、老挝语词语的最小组成单位为音符,本文采用BiLSTM提取笔画(音符)顺序特征,然后利用不同卷积核大小的CNN,卷积核尺度为6、7、8,提取汉、老词语笔画(音符)的词根、词缀或偏旁部首特征,其结构如图2所示.该方法也从词语形态学特征的角度解决了未登录词无法用词向量表征的问题,使得未登录词能在其形态学上得到表达,增强了文本语义信息.
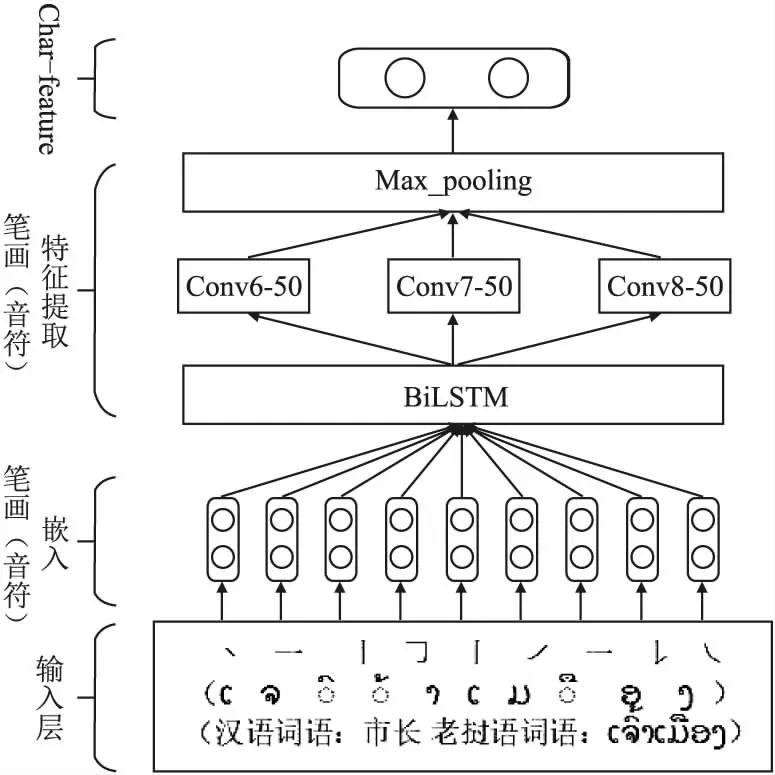
图2 提取词语形态学特征结构图Fig.2 Extracted word morphological feature structure diagram
4.2.3 汉-老词语词性和权重特征
词性分为名词、动词、形容词、数词等等,不同词性对文本语义构成有着不同程度的贡献,利用分词和词性标注工具对汉老双语语短文本进行分词和词性标注.然后参照Petrov[18]等人开发的谷歌通用词性标签(Universal POS tags)对词性标注进行统一化,并统计语料中对短文本表达贡献较大的词性(名词(NOUN)、动词(VERB)、形容词(ADJ))在所有词性中所占比重来确定其词性权重,把每个词的词性特征和其权重特征融入到汉老短文本语义表征里面,提升模型效果.其权重如表2所示.

表2 词性权重表Table 2 Part of speech weight table
4.3 编码层
本文采用BiLSTM和CNN神经网络在嵌入层的基础上进一步对汉老短文本进行编码,使用BiLSTM提取短文本上下文语义特征,考虑到汉语和老挝语在表达上的语序差异,通过CNN提取短文本的局部语义信息特征,以此减小不同语言语序带来的差异.最后将两个网络提取到的特征进行拼接,提高模型效果.
4.3.1 BiLSTM提取特征
4.3.2 CNN提取特征
由于汉老短文本语序存在差异性,本文利用CNN提取汉老短文本的局部语义特征.假设某个文本有n个单词,词向量维度为k,每个单词的词向量为xi∈Rk.卷积核窗口大小为h,通过公式(2)计算卷积核窗口每一次滑动的输出值ci,最后卷积输出向量为:
c=[c1,c2,…,cn-h+1]ci=f(WTxi:i+h-1+b)(i≤n-h+1)
(2)
式中,f为非线性激活函数,本文使用的是“relu”函数;W为卷积核输入节点的权重矩阵;b为偏置项.将卷积后的向量c再通过一个最大池化层,其中pool_size为4的时候,实验效果最好.并使用Padding对其进行补齐,其公式如(3)所示.
(3)
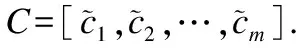
4.4 ESIM交互注意力层
当汉语短文本和老挝语短文本通过CNN和BiLSTM特征提取后后,得到了文本单词之间的上下文语义信息和文本局部语义信息,为了更加充分的利用好语义信息,本文采用Chen Q[19]等人中提出的ESIM交互注意力层,尽早的让汉语短文本和老挝语短文本进行语义信息的交互、对比,以此得到各文本强化后的向量表征.本文首先将CNN和BiLSTM提取到的汉老短文本特征特征进行拼接:
(4)
(5)
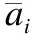
参照ESIM模型的工作,根据(6)式按位计算汉语短文本中的每个向量与老挝语短文本中的每个向量的数值关系eij,将计算得到的所有数值关系进行求和,然后将每个数值关系在求和后的数值关系中所占的比重作为权重.
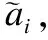
(6)
(7)
(8)
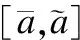
(9)
(10)
4.5 相似度分数计算层
拼接所有信息得到最后的汉老短文本的分布式表示ma、mb后,类似于shao[20]的工作,对其进行按位减(取绝对值)和按位乘的操作,并将两个结果进行拼接.
P1=(|ma○-mb|)⊕(ma⊗mb)
(11)
式中,○-表示汉老元素对应相减,⊗表示汉老元素对应相乘,⊕表示将结果进行拼接.
最后将汉老短文本的语义相似度表示输入全连接层进行计算,使用更具有鲁棒性的“elu”作为激活函数,最后得到汉老短文本的相似度分数.其计算公式如下:
P2=elu(W1P1+b)
(12)
p=sigmoid(W2P2+c)∈(0~1)
(13)
式中,W1、W2和b、c均为模型参数,p为模型最后输出的相似度分数,其输出值在0至1之间.本文采用交叉熵损失函数评估模型的鲁棒性,其公式如下:
(14)
式中pi为样本i被模型预测为正样本的分值,yi为人工评定的分值,N为每一批次样本的个数.
5 实验分析
5.1 实验数据
本文使用的数据集分为3部分,第1部分是用来预训练词向量的数据集:汉语从汉语维基百科上获得了1.27G的单语语料,并利用开源工具进行数据清洗、繁简转换,借助jieba分词工具对语料进行分词处理并去除停用词.然后利用斯坦福开发的Glove词向量训练工具得到约55.2万个汉语单词词向量(约1.54G),词向量维度为300维.老挝语从老挝语维基百科得到265M的单语语料,对数据进行清洗后,利用昆明理工大学实验室开发的分词工具对其进行分词处理.同样利用斯坦福开发的Glove词向量训练工具得到约7.3万词语词向量(约0.27G),词向量维度为300维.
第2部分数据集为汉老双语平行短文本:来源于汉语维基百科和老挝语维基百科,以及以中国国际广播电台老挝语部为依托的CRI悦生活公众号.经过老挝留学生校对后,共得到5798篇汉老平行短文本,本文以1∶7的比例构造了40586篇汉老非平行短文本.如表3所示.
将数据集按照9∶1进行训练集和测试集的划分.本文实验在固定随机种子数下使用10折交叉验证,轮流将训练集中9份作为训练数据,1份作为验证数据进行实验,每一次训练好的模型在测试集上进行验证,取10次实验结果的均值.每次训练使用的数据集划分如表4所示.
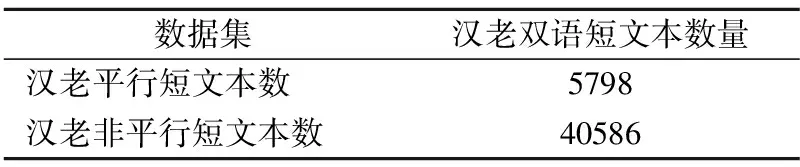
表3 汉老双语短文本数据集Table 3 Chinese-Lao bilingual short text data set

表4 训练模型数据集划分结果Table 4 Data set division results of the training model
第3部分数据集为汉语词语的笔画构成和老挝语词语的音符构成:本文从汉典字词查询网站获得了28503个简体字的笔画构成,笔画种类有25种.第2部分语料中汉语实验语料分词后,将每个词语拆分成字,将字拆分成分成笔画,然后组合成词的笔画.第2部分语料中的老挝语语料分词后,将其按照老挝语的音符匹配规则对老挝语词语进行音符拆分,音符种类有69种.
5.2 实验参数设置
本文实验环境为Windows10操作系统,显卡使用NVIDIA公司生产的GeForce RTX 2060S,使用python3.6作为开发语言,开发平台为PyCharm,以TensorFlow_gpu-1.13.1作为后端运行,使用Keras框架实现本文相似度计算方法.
在提取笔画(音符)特征的神经网络中,组成汉语单词的笔画数和老挝语单词的音符数不同,本文将汉语单词的笔画数和老挝语单词音符数设置为25,维度设置为50,并对其进行随机初始化,LSTM的隐节点数为25,老挝语音符CNN中设置4、5、6共3种不同尺度的卷积核,汉语笔画CNN中设置6、7、8共3种不同尺度的卷积核,卷积核数量各50个,步长设置为1,提取汉、老词语的形态学特征.
在提取汉老短文本词语间特征的神经网络中,本文将汉、老短文本的长度均设置为150个词语,词向量维度为300,词性向量维度为50,并对其进行随机初始化.LSTM的隐节点数量为50,CNN中的卷积核尺度为3,卷积核数量为50,步长为1.采用 Adam算法对模型进行优化,学习率设为0.01.Batch size 的大小设置为 64,Epoch为60.
5.3 评价指标
本文采用常用的评测指标:准确率、召回率和F1值.将汉老对齐短文本的标签设置为1,将汉老非对齐短文本的标签设置为0.采用0.5作为相似度阈值,当模型预测的汉老短文本相似度分数大于0.5时,判断为该汉老短文本为平行文本对.召回率、准确率、F1值计算方式如下所示.
(15)
(16)
(17)
5.4 模型对比实验
本文利用BiLSTM和CNN分别提取汉语词语笔画特征与老挝语词语音符特征,还将词语的词性向量和词性权重向量与原有的词向量进行拼接.为了能充分利用这些语义信息向量,本文使用BiLSTM和CNN提取汉老短文本上下文语义信息和局部语义信息,然后将提取到的语义特征向量进行拼接,利用ESIM交互注意力机制将汉老短文本的语义信息进行交互,并分析新旧序列的差异性,最后将所有的信息拼接到一个新的序列中.为了探索本文方法的有效性,设置了以下几个对比实验:
1)将双向长短期记忆网络(BiLSTM)作为本文的基准模型(Base Model).
2)在基准模型上加入CNN,验证实验效果.
3) 在2)实验基础上加入ESIM交互注意力机制,验证实验效果.
4)在3)实验基础上加入Word-feature(Our),验证实验效果.
本文除了探索利用不同方法计算汉老短文本相似度的实验效果,还与其他学者在文本(句子)相似度的工作做了对比:分别为郭浩[8]等人利用BiLSTM和CNN提取文本特征并与注意力机制相结合的孪生神经网络结构;李霞[9]等人提出的将门控卷积神经网络结合自注意力机制,实现句子级别的相似度计算;赵小兵[10]等人的基于注意力机制的siames LSTM相似度计算模型.以上7个模型均在相同实验环境下采用10折交叉验证法进行实验.最终实验结果如表5所示.
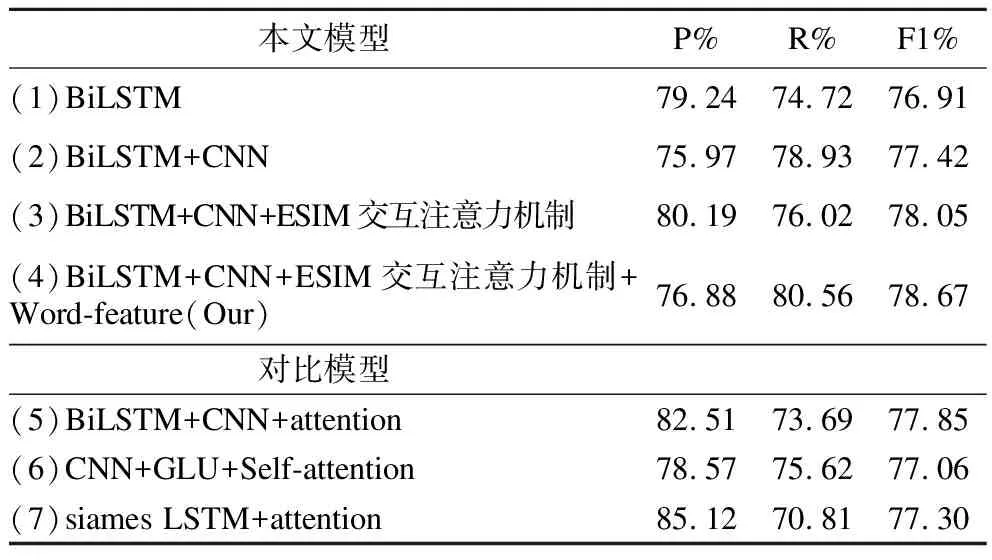
表5 不同模型实验结果Table 5 Experimental results of different models
模型(2)对比模型(1)的实验结果其F1值提高了0.51%,表明在汉老短文本特征提取的模型中加入CNN,确实能减小汉老语序差异,提升模型效果.模型(3)、模型(5)与模型(2)的实验结果对比其F1值分别提高了0.63%和0.43%,表明加入交互注意力机制或自注意力机制能使模型学到更多的语义信息.模型(3)对比模型(5)的实验结果其F1值提高了0.20%,说明交互注意力机制比注意力机制的效果更好,这是因为交互注意力机制对比自注意力机制的孪生网络模型,其能让汉老短文本进行更多的信息交互,提升模型的效果.模型(4)的结果与模型(3)的实验结果其F1值提高了0.62%,表明添加词语的形态学特征、词性特征、权重特征能提升模型的学习效果.
5.5 特征对比实验
本文采用BiLSTM和CNN提取汉老词语的形态学特征,并加入了词语的词性特征、词性权重特征.为了验证不同特征对实验效果的影响,设置了以下6个特征对比实验.特征对比实验均在相同实验环境下采用10折交叉验证法进行.最终实验结果如表6所示.
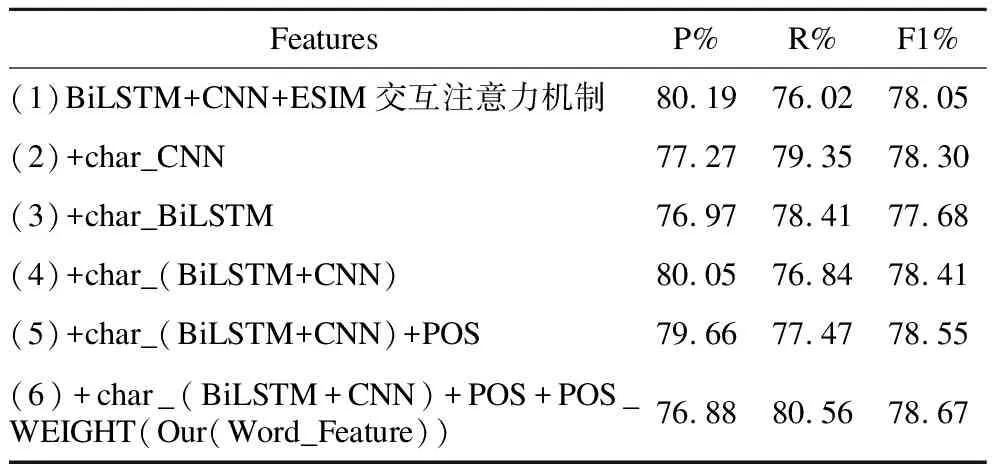
表6 特征对比实验Table 6 Feature comparison experiment
对表6中的实验结果分析,模型(2)对比模型(1)的实验结果其F1值提高了0.25%,表明CNN能较好地提取到词语的形态学特征,且该特征有利于模型效果的提升.模型(3)对比模型(1)的实验结果其F1值降低了0.37%,可能是单独利用BiLSTM对字符形态提取特征效果不佳,给模型带来了噪声数据.模型(4)对比模型(1)、模型(2)的实验结果其F1值分别提高了0.36%、0.11%,表明在CNN提取词语形态学特征之前,如果能结合BiLSTM网络提取的汉语词语中汉字笔画顺序的语义信息和老挝语词语音符顺序的语义信息,模型效果会更佳.模型(5)对比模型(4)的实验结果其F1值提升了0.14%,表明词性向量在文本语义的表征上也有贡献.模型(6)对比模型(5)的实验结果其F1值提高了0.12%,表明不同词性在文本语义贡献上不同,形容词、名词、动词对语义贡献较大.
5.6 不同卷积核尺度提取汉老字符形态学特征
考虑到汉语词根、词缀或字的偏旁部首的笔画组成与老挝语词根、词缀等形态学特征的音符组成数量不同,利用含有相同尺寸卷积核的CNN提取汉语词语和老挝语词语的形态学特征有限.本文分别设置4种不同尺寸的卷积核(汉语卷积核尺寸(6、7、8、9),老挝语卷积核尺寸(4、5、6、7))对汉语和老挝语提取形态学特征提取,其卷积核尺度对比实验均在相同实验环境下采用10折交叉验证法进行.最终实验结果如表7所示.
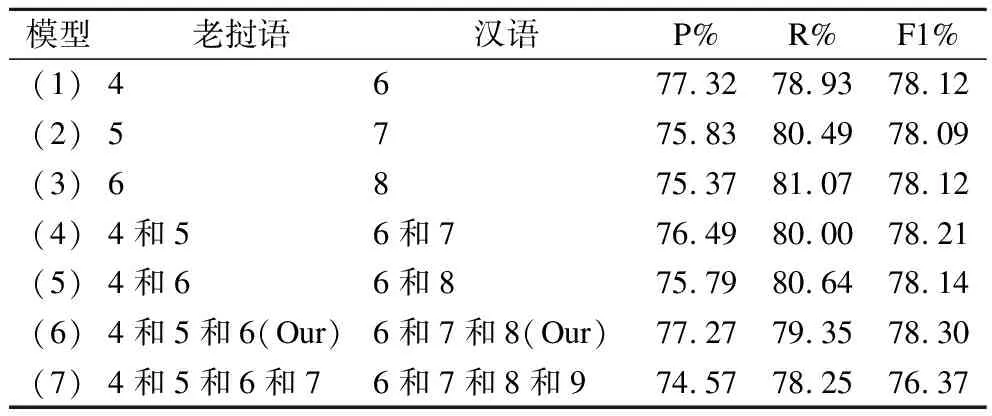
表7 不同卷积核尺度对比Table 7 Comparison of different convolution kernel scales
通过对表中的实验数据分析可知,利用不同卷积核尺度的CNN提取汉老词语的形态学特征对实验模型效果有影响.模型(6)对比模型(4)、模型(5)的实验结果其F1值分别提高了0.09%、0.16%,而模型(4)、模型(5)对比单个CNN模型(1)、模型(2)、模型(3)的实验效果也都有提高,说明不同卷积核尺度的CNN能提取到更多汉老词语的形态学特征.但是模型(7)对比模型(6)的实验结果其F1值降低了1.93%,可能是实验数据较少,参数过多,使得模型较早过拟合化.通过实验对比,本文选择模型(6)中老挝语和汉语的卷积核尺寸作为本模型的设置.
6 结 论
本文针对汉老短文本跨语言相似度计算,提出利用BiLSTM和CNN共同提取汉老词语的形态学特征,并利用汉老词语词性和词性权重的语义信息,进行联合嵌入,然后将联合嵌入层作为BiLSTM和CNN的输入,进一步对语义信息编码,提取文本的上下文语义信息和局部语义信息,以此作为交互层的输入,利用ESIM交互注意力机制对编码层提取到的汉老短文本语义信息进行交互,最后利用相似度计算层计算汉老短文本的相似度分数.与目前主流方法相比较,本文提出的方法实验效果更佳,其F1值达到了78.67%.下一步考虑利用该方法做汉老双语问答系统的研究.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
开放教育研究(2020年2期)2020-03-31 01:54:14
时代英语·高二(2018年7期)2018-12-03 09:23:06
时代英语·高二(2018年3期)2018-06-06 05:24:36
现代语文(2016年21期)2016-05-25 13:13:44
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
阅读与作文(英语高中版)(2013年12期)2013-12-11 08:20:08
