
基于神经网络的天然气双燃料发动机性能预测*
2023-04-10 06:40陈晖虞彪卢嘉专
汽车工程师 2023年4期
陈晖 虞彪 卢嘉专
(1.柳州职业技术学院,柳州 545005;2.柳州五菱柳机动力有限公司,柳州 545002)
1 前言
天然气价格低、储量大、存储与运输设施完善,是我国目前使用规模最大的燃料。柴油/天然气双燃料发动机不仅能实现高效燃烧,还能降低碳烟和NOx的排放体积分数,因此受到广泛关注[1-3]。为了使双燃料发动机在不同工况下获得最佳性能,需要对发动机的运行参数进行标定,但标定试验过程复杂、工作量大、成本高,相比于试验标定方法,基于模型的发动机标定方法可以有效提高标定效率,降低标定成本[4-5]。
人工神经网络(Artificial Neural Network,ANN)是一种类似于人脑的包含多个神经元结构和功能的信息处理系统,具有非线性映射能力、容错能力、自学习能力等特点,在科学和工程领域被广泛应用[6]。Syed 等[7]采用少量试验数据训练人工神经网络,有效预测了氢气/柴油双燃料发动机的热效率、油耗以及污染物排放量;Cay 等[8]采用人工神经网络模型预测了甲醇/汽油双燃料发动机的平均有效压力、油耗、功率和排气温度,预测结果与样本数据的平均误差<3.8%,均方根(Root Mean Square,RMS)<0.0015;Ramalingam 等[9]采用人工神经网络针对5 种不同比例的生物柴油/柴油混合燃料的性能和排放进行预测,预测结果的平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)范围为0.98%~4.26%;Taghavi 等[10]利用遗传算法优化的人工神经网络预测了均质充量压燃(Homogeneous Charge Compression Lgnition, HCCI)发动机燃烧始点;戴金池等[11]采用长短期记忆(Long Short-Term Memory,LSTM)神经网络、逆向传播(Back Propagation,BP)神经网络和支持向量机3种不同模型对柴油机NOx排放量进行预测,结果表明LSTM 神经网络预测性能最强。李昌庆等[12]利用BP 神 经网络对大 型 客车的CO2、CO 和NOx排放 体积分数进行预测,预测结果的总体相关系数R2为0.9167,线性高度相关,该模型能较准确地预测大型客车尾气排放量。
目前,对双燃料发动机性能和排放的研究主要集中在试验和模拟研究方面,基于模型预测的研究还较少,本文以发动机扭矩、转速、过量空气系数、喷油时刻、喷油压力和天然气替代率作为模型输入参数,燃油消耗率、CO、NOx和总烃(Total Hydrocar⁃bons,THC)排放体积分数作为模型输出参数,通过训练试验数据,建立基于人工神经网络的天然气双燃料发动机机性能预测模型。
2 预测模型的建立
影响双燃料发动机性能的参数很多,发动机性能和排放的预测属于多变量、多目标的非线性问题,而且目标函数无法用数学解析式给出。BP神经网络是一种多层前馈神经网络,按照误差逆向传播算法进行训练,具备处理参数之间复杂的非线性关系的能力,因此适用于多变量的变化函数建模,是目前应用最广泛的人工神经网络[13]。BP 神经网络的结构包含输入层、隐含层和输出层,每层中有若干节点,每个节点称为一个神经元,层与层之间的神经元全部相连,但同一层内的神经元不相连。BP神经网络训练包含了2 个过程,分别是输入信号的正向传播和计算误差的反向传播。在正向传播过程中,输入信号由输入层经过隐含层到达输出层,计算损失函数值:当损失函数值大于期望值时,训练进入误差反向传播过程,通过求损失函数对权值和阈值的偏导数调整网络的权值和阈值,使损失函数值不断减小,神经网络预测值不断逼近期望值;当网络输出的误差或学习次数达到设定值时,训练过程结束。本文采用BP 神经网络构建双燃料发动机性能预测模型。
2.1 数据的选取与处理
将台架试验得到的260 组数据按80%、10%、10%的比例随机分为训练样本、验证样本和测试样本3 个部分。由于样本中数据的量纲和数值量级差异性大,如转速和过量空气系数的数值量级可以相差1000 倍,因此需要通过对样本数据进行归一化处理,减小数据间的量纲和数值量级差异,提高求解速度和计算精度。常用的方法是按Min-Max标准化对数据进行线性变换,并映射到[0,1]区间,即
式中,x′为归一化后的样本数据;x为归一化前的样本数据;xmin为数据样本中的最小值;xmax为数据样本中的最大值。
2.2 输入参数和输出参数的选择
模型输入参数和输出参数的选取是构建和训练神经网络的一个重要问题,对模型的预测精度有较大影响[14]。首先选择过量空气系数和天然气替代率作为输入参数,这2 个参数表示燃料与空气的比例情况,其次,发动机扭矩、转速、喷油时刻、喷油压力是影响双燃料发动机性能和排放的重要控制参数,也选作模型输入参数,预测模型共选择6个输入参数。模型输出参数为5 个,选择燃油消耗率来表征发动机性能,CO、NOx、THC 排放体积分数和碳烟排放量来表征发动机排放情况。
2.3 神经网络结构的确定
模型的输入参数和输出参数分别为6 个和5个,因此模型的输入层和输出层的神经元数量确定为4 个和2 个。BP 神经网络采用单隐含层时即可高精度地逼近任意非线性函数,在实际应用中具有很好的预测能力,使用BP 神经网络模型进行预测要考虑如何避免模型预测出现过拟合现象。在训练数据样本量较小时,采用多层隐含层容易出现过拟合,因此本文预测模型采用单层隐含层结构。隐含层中神经元的数量是影响神经网络的预测性能的一个重要参数,可以采用试错法确定,通过逐渐递增神经元数量,对比不同神经元数量条件下计算得到的模型误差,发现隐含层节点数量为18 个时模型预测的误差最小,因此预测模型的结构最终确定为6-18-5,建立的BP 神经网络模型拓扑结构如图1 所示。模型隐含层选用Sigmoid为激活函数,输出层选用Purelin 为激活函数。
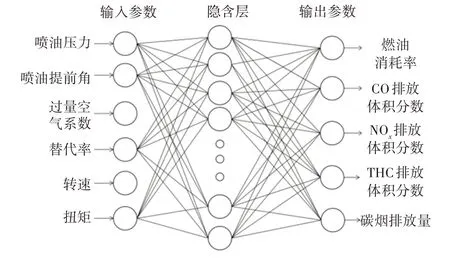
图1 BP神经网络拓扑结构
2.4 遗传算法优化
BP神经网络模型训练过程中,初始权重和阈值一般为随机赋值,对训练结果有较大影响,容易造成在训练过程中由于学习率过大或过小使得得到的结果不是全局最优解,预测结果误差较大。遗传算法是模仿生物遗传学和生物进化原理人工构造的一种优化算法,通过使个体进行选择、交叉、变异,进化出更优秀的个体,然后对个体的适应度进行比较,淘汰不适应环境的个体,从而在多个潜在解中找到最优解。为了解决BP 神经网络初始权重和阈值随机赋值导致预测性能鲁棒性差的问题,通过遗传算法对初始权值和阈值进行优化,将优化后的权重和阈值带入BP 神经网络进行训练。基于遗传算法优化的BP 神经网络称为GA-BP 神经网络,图2 所示为基于遗传算法的BP 神经网络模型优化流程。经过调试,在遗传算法中,种群规模设置为20 个、进化次数为40 次、交叉概率为0.3、变异概率为0.1时,模型预测精度高且收敛速度较快。

图2 GA-BP神经网络模型优化流程
3 结果分析
模型建立后,需对模型的预测结果进行评价,本文选用决定系数R2和平均绝对百分比误差MAPE作为评价指标,决定系数R2越接近1,平均绝对百分比误差MAPE越小,表明模型预测性能越好:
式中,ti为第i个测试集中的试验值;oi为第i个模型预测值;tˉ为测试集试验值平均值;n为测试集中的样本数量。
表1 和表2 所示分别为BP 神经网络和GA-BP神经网络的模型预测评价指标,对比表中数据可以看出,GA-BP 神经网络的模型预测误差较BP 神经网络小,说明通过遗传算法对BP神经网络初始权重和阈值的优化可提高模型的预测精度。GA-BP 神经网络对4个输出参数预测的平均绝对百分比误差MAPE均小于6%,并且决定系数R2均大于0.97,说明模型具有较高的预测精度和泛化能力。
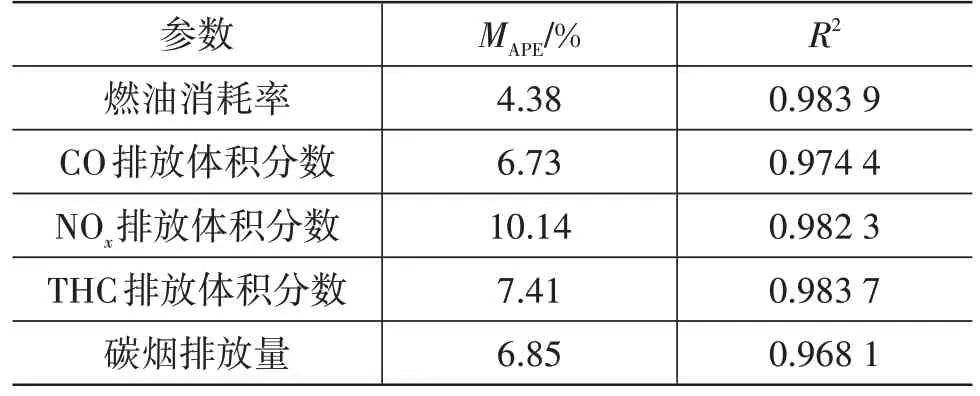
表1 BP神经网络的预测误差
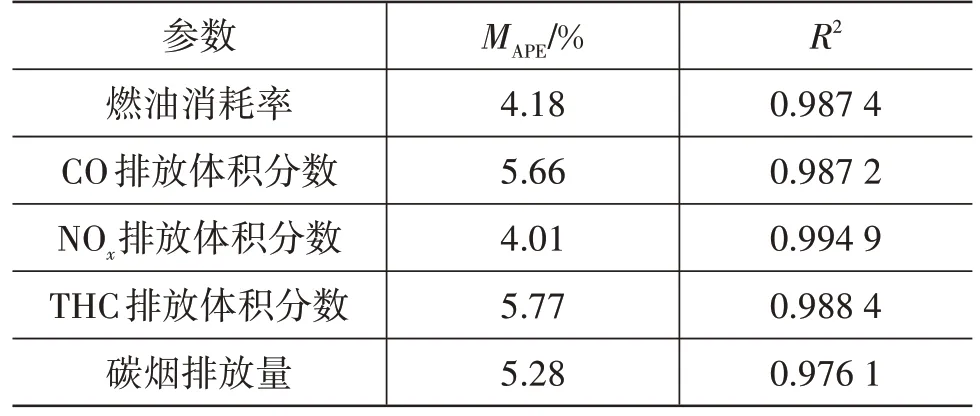
表2 GA-BP神经网络的预测误差
图3 和图4 所示分别为BP 神经网络和GA-BP神经网络模型预测结果与试验结果的对比,BP神经网络和GA-BP 神经网络模型的预测值的变化趋势与试验值基本一致,较好地反映了输出参数随输入参数的变化规律,GA-BP 神经网络模型的预测值误差更小,具有更好的预测性能。

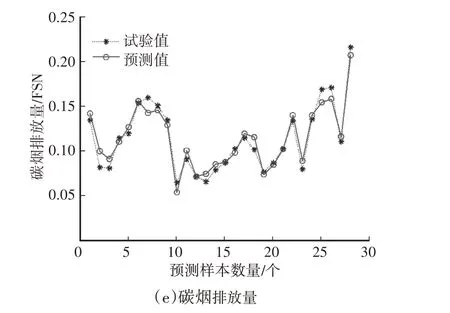
图3 BP神经网络模型预测值与试验值对比
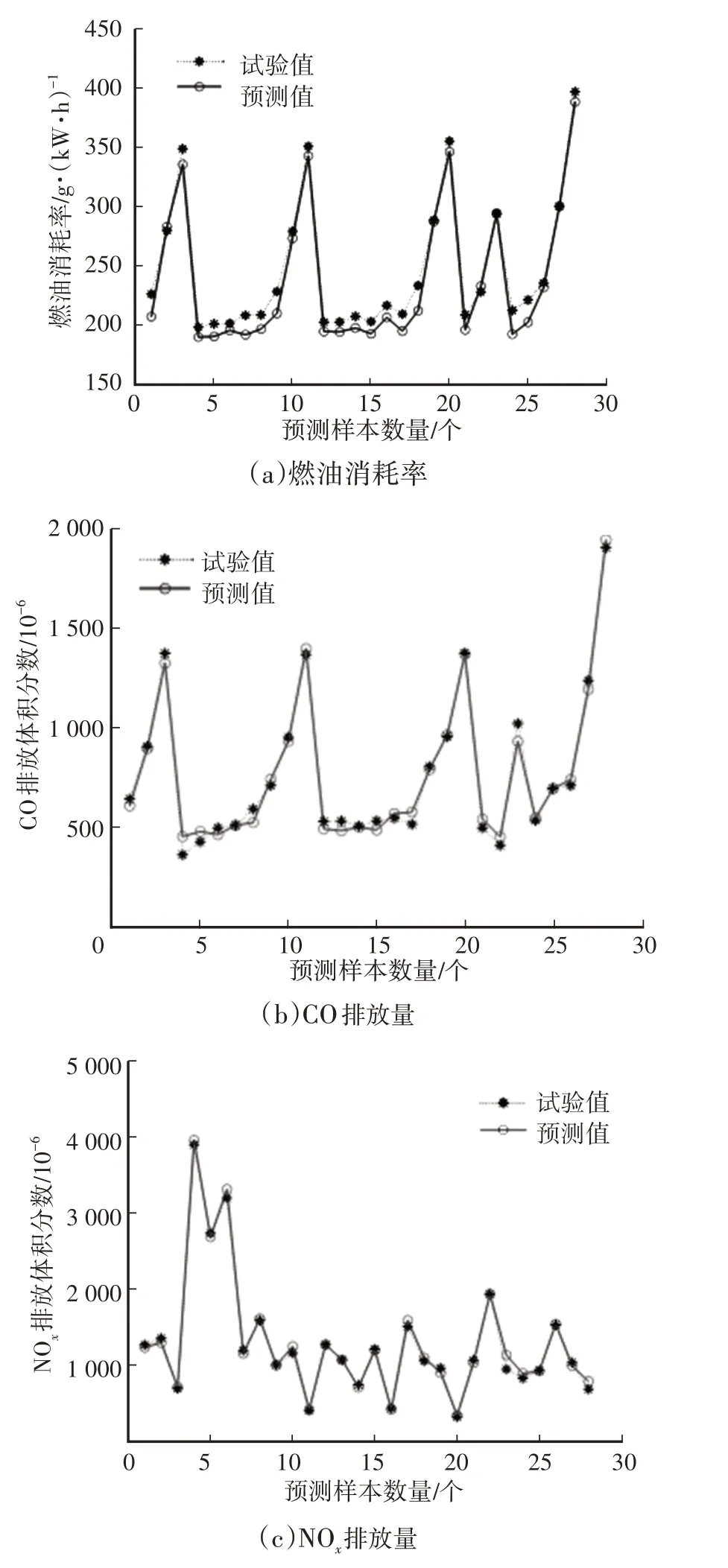
4 结束语
本文基于柴油/天然气双燃料发动机测试台架试验数据,以发动机扭矩、转速、喷油时刻、喷油压力和天然气替代率、过量空气系数为模型输入参数,以发动机燃油消耗率和CO、NOx、THC 排放体积分数和碳烟排放量为模型输出,构建了基于BP神经网络和基于遗传算法优化的GA-BP 神经网络的预测模型。与BP 神经网络模型相比,GA-BP 神经网络模型的预测结果误差更小,具有更好的预测性能。GA-BP神经网络模型对5个输出参数预测的平均绝对百分比误差MAPE均小于6%,并且决定系数R2均大于0.97,模型具有较高的预测精度和泛化能力。GA-BP 神经网络预测模型可为天然气双燃料发动机运行参数的标定及优化提供参考。
猜你喜欢
舰船科学技术(2022年10期)2022-06-17
船舶标准化工程师(2020年1期)2020-06-12
电子制作(2019年19期)2019-11-23
石油地球物理勘探(2017年2期)2017-11-23
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
统计与决策(2017年2期)2017-03-20
重型机械(2016年1期)2016-03-01
船海工程(2015年4期)2016-01-05
智能系统学报(2015年4期)2015-12-27
大连工业大学学报(2015年4期)2015-12-11
