
融合累积分布函数和通道注意力机制的DeepLabV3+图像分割算法
2023-03-24 13:25何雪东宣士斌王款陈梦楠
计算机应用 2023年3期
何雪东,宣士斌,2*,王款,陈梦楠
(1.广西民族大学 人工智能学院,南宁 530006;2.广西混杂计算与集成电路设计分析重点实验室(广西民族大学),南宁 530006)
0 引言
语义分割是计算机视觉中最重要的密集预测任务之一[1]。它将图像或视频帧划分为多个片段和对象,并在医学图像分析(如肿瘤边界提取和组织体积测量)、自动驾驶汽车(如可导航的表面和行人检测)、视频监控、增强现实等领域[2-5]中应用广泛。
近些年来,全卷积网络(Fully Convolutional Network,FCN)[6]使语义分割技术快速发展,大量语义分割模型相继被提出。分析近些年著名的语义分割模型后发现,大部分工作集中在整合丰富的上下文信息以及对注意力机制的使用[1,5,7-15]。尤其是对通道注意力的使用,引起了广泛的关注。其中最具代表性的是SENet[10],它通过SE(Squeeze-and-Excitation)模块建立通道特征之间的依赖关系以提高网络模型精度,之后的一些研究大多通过更复杂的通道依赖改进SE 模块。CBAM(Convolutional Block Attention Module)[16]和ECA-Net(Efficient Channel Attention for deep convolutional neural Network)[15]又相继提出加入最大值池化的通道注意力和更轻量的通道注意力。但是这些通道注意力模块仍然需要少量参数进行训练,增加了网络的训练负担。文献[17]中提出将自适应注意力机制加入主干网络,以增强主干网络提取特征的能力,但忽略了高分辨率的低级特征。
DeepLab 系列网络[11-14]是整合上下文信息的代表模型,并且目前仍是最流行的语义分割网络模型之一。DeepLabV1[11]将空洞卷积引入主干网络,以减少一系列卷积操作导致有效信息丢失的问题。因为基于优化卷积结构的空洞卷积可以在不损失分辨率的前提下扩大卷积核的感受野[18],DeeplabV2 引入空洞空间金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)聚合不同空洞率的空洞卷积生成的多尺度特征,以增强网络对不同尺度目标的预测能力[12]。DeepLabV3+[14]拥有简单有效的解码模块以及聚合多尺度特征的ASPP 模块,因此在DeepLab 系列中更有效,并且多次被应用于实际应用。
经过多次实验发现,DeepLabV3+在解码阶段只使用了主干网络多阶段浅层特征中的一个用作解码模块的融合,因此会造成部分信息丢失、分割不连续以及大尺度物体错误分割等问题。而直接将高级特征与主干网络中的低级特征进行拼接融合,显然会忽略不对齐的高低级特征向特征图中引入噪声的问题[19],影响语义分割的精度。
因此,本文提出累积分布通道注意力DeepLabV3+(Cumulative Distribution Channel Attention DeepLabV3+,CDCA-DLV3+)模型以提高DeepLabV3+的语义分割效果。本文的主要工作为:1)在高低特征跨层融合前加入一种注意力机制,即本文提出的累积分布通道注意力(Cumulative Distribution Channel Attention,CDCA)模块,在减少噪声干扰的同时对特征通道进行加权,抑制通道信息冗余,整合更加丰富的上下文信息;2)在解码阶段进行多次高低级特征融合,充分利用特征提取阶段中的浅层特征,阻止图像还原时图像边缘和纹理信息丢失,以提高模型细节的表征能力。本文提出的改进策略能有效强化重要特征学习,增强网络学习能力,且只少量增加模型参数。
1 相关工作
作为DeepLabV3 的改进网络,DeepLabV3+在解码阶段增加一个简单的解码器模块来提取分割结果,该模块通过逐步恢复空间信息以捕获更清晰的目标边界[14]。实际上,对于边界特征的提取可以通过注意力机制提高表征能力,像人类一样关注视野中的重要部分,忽略不重要的干扰物[16]。
1.1 DeepLabV3+网络
DeepLabV3+网络结构如图1 所示,主要分为用于特征提取、还原的编码层与解码层,R为空洞率。
编码层,即下采样编码部分,用于提取输入图像的高级语义信息。目前主流的主干网络有ResNet(Residual Network)[20]、MobileNet[21-23]、Xception[24]、VGG(Visual Geometry Group)[25]等。又因为空洞卷积[18,26]可以在与普通卷积具有相同参数量的情况下获得更大的感受野并且不损失特征图的分辨率,所以DeepLabV3+对ResNet-101 进行改进,即在特征提取的最后的位置使用了空洞率分别为2、4、8的空洞卷积以提高特征提取的效果。主干网络下采样完成之后,经过ASPP 模块处理后得到编码层最终输出的特征图。
解码层,即DeepLabV3+网络的解码部分,首先对编码层最终的输出特征图直接进行4 倍上采样并与ResNet-101 下采样操作所产生的1/4 大小的特征图经过一次1×1 的卷积(Conv)后在通道维度进行拼接(Concat),然后对所得特征图进行两次3×3 的卷积,最后经过一次4 倍上采样所得到特征图即该网络的最终预测结果。
本文使用全新的通道注意力以获得更加有效的低级特征,并且采用特征金字塔网络(Future Pyramid Network,FPN)逐步还原特征图,以避免多次大倍数上采样造成的特征缺失,最终得到更加精准的分割效果。
1.2 通道注意力机制
注意力机制可以看作一种根据特征图的重要性重新分配资源的机制[7],并且效果显著,因此注意力机制近几年被大量应用于深度卷积神经网络(Deep Convolutional Neural Network,DCNN)。在SENet 中首次使用通道注意力(Channel Attention,CA)[10],它利用了通道之间的关系生成通道注意图。随后,许多研究将它应用于视觉任务。Wang等[15]基于SENet 在ECA-Net 提出一种高效通道注意力(Efficient Channel Attention,ECA)模块,使用一维卷积来规避SENet 中的降维操作,实验结果表明不仅提升了模型的性能,并且降低了复杂度。SENet 只使用平均池化获取通道中的空间聚合信息,但最大池化也可以收集独特的物体特征,因此在CBAM 中提出了同时使用最大池化和平均池化的通道注意力结构[16]。但这些模块仍然存在一定量的参数需要进行训练。为解决这一问题,本文基于上述通道注意力机制提出了一种不需要任何参数的通道注意力。
1.3 空间金字塔池化
空洞空间金字塔池化[12]模块基于空间金字塔池化(Spatial Pyramid Pooling,SPP)[27]思想,采用不同大小、空洞率的空洞卷积获得图像的精确特征,之后通过1×1 卷积将通道数降低到合理范围。ASPP 模块对语义分割网络的特征提取部分尤为重要。文献[28]中提出一种采用不同空洞率组合的ASPP 模块,并在实验中取得了明显的改进效果。本文在改进的模型中分别采用上述两种ASPP 模块进行对比实验。
2 CDCA-DLV3+网络模型
原始DeepLabV3+只是通过简单的卷积与拼接进行空间信息恢复以及边界特征提取。而文献[28]中改进的DeepLabV3+虽然结合了1/8 和1/16 大小的特征图并将它融入解码模块中,但由于只是通过简单的金字塔结构拼接且没有对编码阶段的特征图作特征选择,编码阶段的噪声也融入了解码模块。在实验中发现这些模型存在许多错误分割以及漏分割部分,为此本文在原始DeepLabV3+的解码部分加入基于通道注意力机制和累积分布函数的CDCA 模块,并将模型命名为CDCA-DLV3+。
2.1 模型总体架构
CDCA-DLV3+网络结构如图2 所示,依旧分为编码层与解码层。在编码层的特征提取部分的主干网络与原网络相同均采用ResNet-101。受CBAM 和ECA-Net[15]以及累积分布函数在图像增强方面应用的启发,提出了CDCA,该模块的优点在于提升网络性能的同时不增加网络的复杂度。在编码部分下采样的每个阶段都会产生不同尺度的特征图,最终输出的特征图分辨率为原图1/16 大小。首先将1/16 大小的特征图送入ASPP 模块中进行处理,然后将ASPP 中所得到的所有特征图经过Concat 进行融合,最后对融合后的特征图使用1×1 卷积操作进行降维,至此编码部分完成。
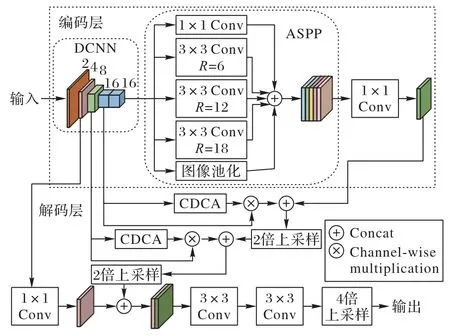
图2 CDCA-DLV3+网络结构Fig.2 CDCA-DLV3+network structure
原始DeepLabV3+网络在解码部分没有充分结合高分辨率特征,并且经过两次4 倍上采样得到最终预测的这种较大倍数的上采样会丢失一些重要像素,从而使网络最终的输出结果不准确。而文献[28]虽然在解码模块中结合高分辨率特征,但会将噪声融入解码模块,导致精度下降。因此本文提出一个更有效且灵活的解码模块,并且提出全新的CDCA。因为原网络只应用了下采样阶段1/4 的特征图,但是在编码层下采样操作时所产生的每一个特征图都会对网络的分割结果有影响,所以CDCA-DLV3+网络利用特征金字塔思想在应用1/4 大小的特征图的同时又加入1/8 和1/16 大小的特征图,即将1/8 以及1/16 的特征图先后与ASPP 模块输出的特征图进行拼接作为解码部分特征融合的重要部分,具体操作如图3 所示。其中:A、B为编码层下采样时产生的特征图,大小分别为1/8、1/16,通道数分别为512、1 024;C为ASPP 模块输出的特征图进行1×1 卷积降维后得到的1/16 大小的特征图。将B输入CDCA 模块得到特征图B各个通道的权重,并与B相乘,再与C拼接得到大小为1/16 的特征图D。对D使用1×1 卷积进行降维,然后通过2 倍上采样得到分辨率为原图1/8 的特征图E。特征图A与A经过CDCA 的输出值进行相乘,再与E拼接得到新的特征图,对它使用1×1 卷积降维,再使用2 倍上采样,得到分辨率为原图1/4 的特征图F。最后,对图1 中下采样过程中1/4 大小的特征图进行一次1×1 卷积后与特征图F拼接,所得结果再经过两个3×3 卷积和一个4 倍上采样得到的输出即网络预测结果。
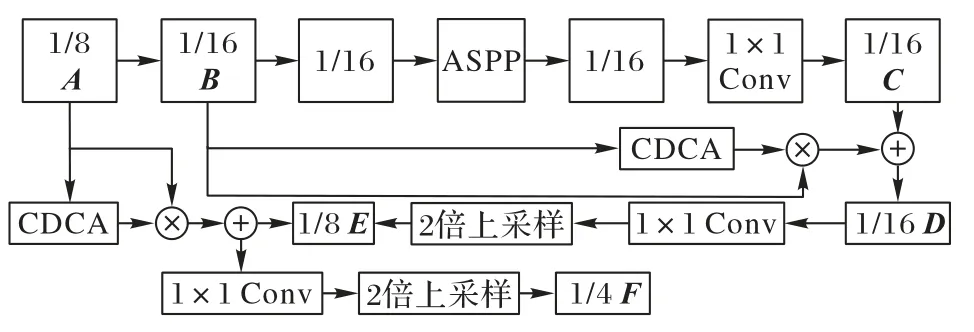
图3 CDCA-DLV3+网络结构细节Fig.3 CDCA-DLV3+network structure details
相较于文献[28]中直接将1/8 和1/16 大小特征图通过特征金字塔网络(FPN)[29]融合后与编码层的输出特征图拼接的操作,本文的解码模块更加灵活,可以只对1/8 或1/16 大小的特征图进行处理;并且相较于文献[28]提出的改进模型,本文的改进策略拥有更少的参数以及浮点运算量,且精度更高,具体对比将会在实验部分列出。
2.2 累积分布通道注意力
在ECA 模型中,只使用了平均池化以聚合空间信息,却忽略了最大池化这一重要线索。因为最大池化可以收集对象不同的重要特征[16],以此推断出更加精确的通道注意力。并且文献[16]通过实验证实,同时利用这两种特征可以极大地提高网络的表示能力,所以为了获得更丰富特征信息,在提出的CDCA 模块中使用平均池化和最大池化来获得更加精细的通道注意力。由于通道注意力最终输出的数值为每个特征图的权重,目的是强调某些特征图的重要性。而累积分布函数可以增加图像的对比度,为了增强通道注意力中参数的作用,即令重要特征图的权重更大且减小不重要特征图的权重,最终决定使用累积分布函数分别重新计算平均池化和最大池化后的数据,实验结果表明CDCA 能有效提升模型精度。CDCA 模块的结构如图4 所示。
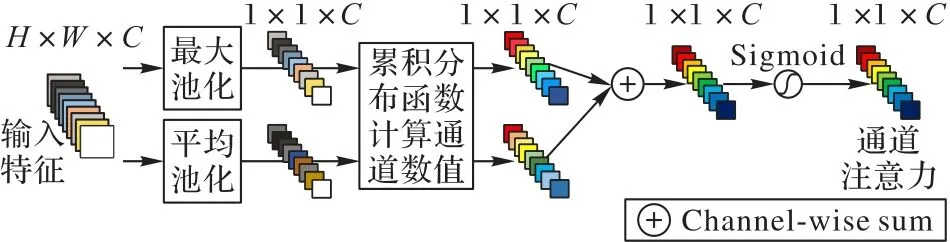
图4 累积分布通道注意力模块结构Fig.4 Structure of CDCA module
CDCA的输入特征图Fin∈RH×W×C,通过通道维度的最大池化 和平均 池化可 以分别得到Fmp∈R1×1×C和Fap∈R1×1×C:
其中:Squeeze(·)代表降维操作;P表示降维后的张量;F表示最大池化和平局池化后1× 1×C的张量;pj表示张量P在j位置的数值;rj表示pj映射为[0,255]的数值;nk表示灰度值小于等于rk的像素数;n表示张量中数据的总数;L表示张量中可能的灰度级;pr(rk)为灰度值小于等于rk的像素在该张量中的概率;Rep(·)为替换操作,即将张量P中像素值为rk的所有像素替换为pr(rk)的数值;Unsqueeze(·)为升维操作。
CDCA 模块使用累积分布函数,每使用一个CDCA 只增加少量参数。但是CDCA 本身并不存在参数,增加的参数为处理特征图通道数的卷积操作,因此CDCA 是一个轻量级的模块,可以通过只增加少量参数就提升网络的分割精度。累积分布函数对平均池化和最大池化后的数据重新赋值,所以每一个通道的权重会发生改变。使用累积分布函数不会使下采样后得到特征图信息缺失,也可以抑制噪声对输出结果的影响,同时会提高权重较大的通道的重要性,并且整个操作过程运算量很小,对于整个网络模型速度的影响并不大。
2.3 特征金字塔思想
FPN 如图5 所示,可以融合不同分辨率的特征图(主要为主干网络中的特征图与ASPP 模块输出的特征图)。图5左侧是4 个由下向上分辨率由大变小的特征图,虚线部分为FPN 进行融合操作的具体过程,使用对应通道相加的方式进行融合。不同的是,本文模型均在通道维度采用Concat 操作完成特征融合。因为原始的FPN 使用对应通道相加的方式进行特征图融合,有可能导致重要特征缺失,然而使用Concat 操作会保留所有特征图,因此特征更加丰富且不会造成信息缺失。本文将编码层下采样阶段中的特征图B,即大小和通道数分别为1/16、1 024 的特征图通过CDCA 与ASPP的输出进行拼接正是使用这一思想。虽然这两部分都是1/16 大小,但因为主干网络中特征图经过更少的卷积和下采样,所以会留存一些更精细的语义信息。通过图2 网络中的两次横向连接,自底向上的语义信息得到了增强。
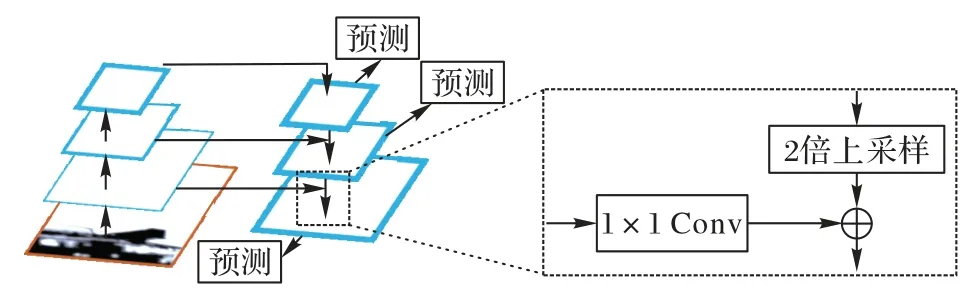
图5 特征金字塔网络结构Fig.5 Feature pyramid network structure
3 实验与结果分析
3.1 数据集
本文实验使用Pascal VOC(Pascal Visual Object Classes)2012 标准数据集和SBD(Semantic Boundaries Dataset)组合成的Pacal 加强数据集[30]以及Cityscapes[31]数据集。其中Pacal加强数据集的标准数据集中训练、验证、测试的图像数分别为1 464、1 449、1 456;SBD 中训练和验证所用图像数分别为8 498 和2 857,将合并后的数据集用于训练、验证、测试图像数分别为10 582、1 449、1 456。所有图像的分语义分类有21个,其中有20 个前景分类以及1 个背景分类。Cityscapes 数据集包含5 000 幅高质量像素级注释的图像(训练集、验证集和测试集数量分别为2 975、500 和1 525)和2× 104张粗注释图像,共分30 个类别。
3.2 实验环境
本文中所涉及程序均使用Python+Pytorch 框架实现。表1 为运行环境的配置。
表1 机器软硬件配置Tab.1 Machine software and hardware configuration
对学习率采用一种“poly”的学习策略,如式(7)所示:
式(7)中各参数在程序中的初始值分别为:base_lr=0.001 4;iter为当前程序运行的次数;max_iter为程序最大可运行次数;power=0.9。原始图像分辨率会被预处理为513×513 再送入神经网络,主干网络为ResNet-101,优化器为随机梯度下降法,batch size 以及Epochs 分别为16、100。平均交并比(mean Intersection over Union,mIoU)为语义分割领域最重要的指标评价方法,它表示真实值和预测值的重合度,因此本文使用mIoU 进行评估,计算方法如下:
其中:N为数据集的类别数量;Ti为图像中像素为i类像素的总数;Xii为像素为i类像素并且预测结果也是i类像素的总数;Xji为像素为i类像素但预测结果为j类像素的总数。
3.3 Pacal数据集实验结果对比
3.3.1 CDCA模块以及ASPP空洞率对网络的影响
CDCA 模块可以只增加少量参数,在下采样编码阶段提取有效的信息特征,而选择合适的高分辨率特征图以及在多个高分辨率特征图中选择出合适的细节特征尤为重要。
表2 为CDCA-DLV3+对不同尺度的高分辨率特征图使用CDCA 模块的测试结果对比,√表示CDCA 模块对编码时所产生的对应尺度特征图进行处理。对ASPP 采用两种不同的空洞率,其中:(6,12,18)空洞率组合为原DeepLabV3+提出;(4,8,12,16)空洞率组合为文献[28]中提出的改进ASPP 的空洞率组合。由于DeepLabV3+没有对1/8 以及1/16 的特征图作任何处理,所以将它加入对比实验。在ASPP 模块使用(6,12,18)空洞率组合,对1/8 大小的特征图使用CDCA 模块并与ASPP 模块的输出特征图进行通道维度的拼接,相较于原模型,mIoU 提高了0.45 个百分点,参数量与浮点运算量增长很小;对1/16 大小的特征图作同样处理,mIoU 提高了0.17个百分点;同时使用这两个阶段的特征图,因此参数量以及浮点运算量有明显提高,相较于原模型,mIoU 提高了0.71 个百分点。在ASPP 模块使用(4,8,12,16)空洞率组合,使用CDCA 模块对1/8 大小的特征图进行融合,mIoU 值提高了0.95 个百分点;对1/16 大小的特征图作同样处理,mIoU 提高了0.15 个百分点;使用CDCA 模块同时融合两个阶段的特征图,mIoU 提高了0.66 个百分点。综上所述,当ASPP 使用(6,12,18)空洞率组合时,对1/8 和1/16 大小的特征图同时使用CDCA 模块进行融合可以取得最好结果。当ASPP 使用(4,8,12,16)空洞率组合时,只对1/8 大小的特征图使用CDCA模块进行融合可以取得最好结果,优于上述所有结果。
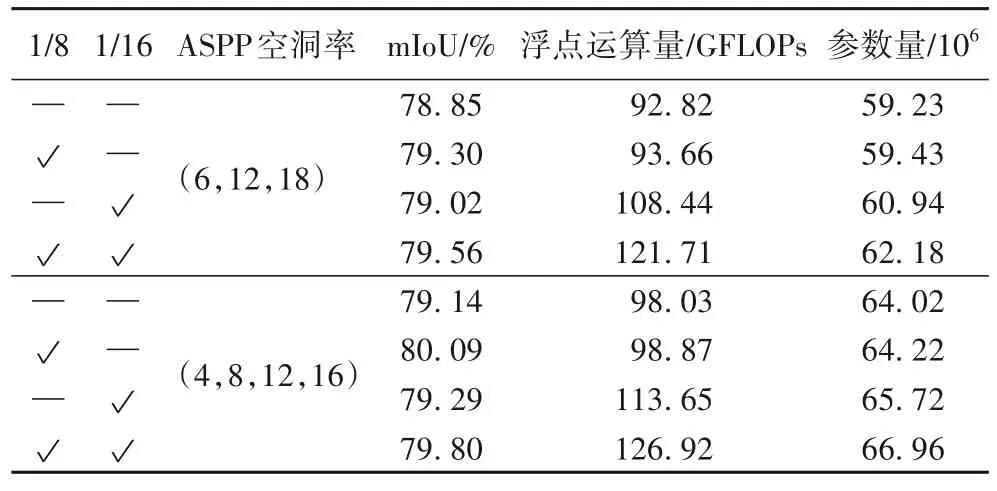
表2 CDCA模块以及ASPP空洞率对网络的影响Tab.2 Influence of CDCA module and ASPP atrous rate on network
3.3.2 不同模型对比
如表3 所示,模型1 为CDCA-DLV3+采用(6,12,18)空洞率组合的ASPP 模块+融合1/8 特征图的CDCA 模块,只增加了少量参数和浮点运算量得到了比DeepLabV3+更优秀的性能。模型2 为CDCA-DLV3+使用文献[28]中所提出的ASPP空洞率组合+融合1/8 特征图的CDCA 模块,mIoU 优于所有模型。相较于DeepLabV3+,模型2 的mIoU 提高了1.24 个百分点。由于模型1、2 相较于DeepLabV3+增加了额外的计算量,因此模型训练时间会随浮点运算量增加而增加。
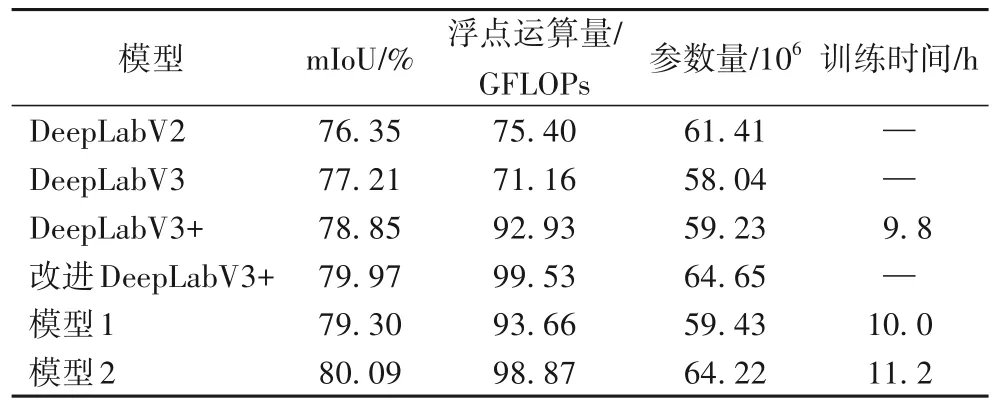
表3 不同模型的对比结果Tab.3 Comparison results of different models
3.3.3 预测图对比
如图6 所示为模型2 与DeepLabV3+输出预测图的对比。语义分割的目的是准确分割出图像中存在的目标,因此网络最终预测的结果的精细程度与mIoU 正相关。网络预测结果与标签越接近,mIoU 越高,最终预测结果的边缘越清晰。

图6 PACAL数据集上模型2与DeepLabV3+网络预测图对比Fig.6 Prediction graph comparison between Model 2 and DeepLabV3+network on PASCAL dataset
可以看出,在图像1 中,DeepLabV3+对图像中的牛存在错误预测,且轮廓的预测不够精细;采用模型2 预测则减少了错误预测的像素,尤其是牛的右侧,错误预测完全消除,且牛的轮廓更加清晰。在图像2 中,DeepLabV3+分割出来的沙发上存在大块错误识别像素,右侧也存在错误识别部分;模型2 的输出结果更优,沙发上的错误识别部分更小,右侧错误像素基本消除。在图像3 中,DeepLabV3+预测出的电视机基本准确,但是右侧存在大块的错误分类部分;模型2 正确预测出电视机,并且右侧错误分类像素大幅减少。图像4中,模型2 成功预测出飞机,并且没有错误预测的像素,飞机更加完整;而DeepLabV3+中的飞机尾部预测缺失严重。图像5、6 中,DeepLabV3+存在将人物左上方和汽车的上方背景错误分割为人的问题,模型2 则完全避免了这些问题。图像7 中,DeepLabV3+预测出的电视机轮廓模糊且存在大量错误分割,模型2 的预测图像错误分割部分大幅减少且轮廓更加清晰。图像8 中,DeepLabV3+对于大尺度物体内部存在像素预测错误,模型2 则完全解决了这一问题。综上所述,CDCA-DLV3+模型的mIoU 值更高,预测结果更加准确,边缘更加清晰、更具鲁棒性。
3.4 在Cityscapes数据集上的精度对比
表4 为模型1、2 与DeepLabV3+在Cityscapes 数据集上的mIoU 对比。其中DeepLabV3+的mIoU 结果来源于文献[32],输入模型的图像大小为512×1 024,batch size 为8,epoches 为108,主干网络依旧使用ResNet-101。采用相同的配置,模型1、2 的mIoU 相较于DeepLabV3+提高了0.59、1.02 个百分点。进一步说明了本文模型的有效性。

表4 在Cityscapes数据集上的mIoU对比 单位:%Tab.4 mIoU comparison on Cityscapes dataset unit:%
4 结语
本文提出一种累积分布函数的通道注意力(CDCA)并结合FPN 加入DeepLabV3+网络,以利用编码层下采样阶段产生的有效的低级特征。实验结果表明通过CDCA 模块提取低级特征存在的有效信息时,网络的参数量增加很少,当只融合1/8 特征图时运算速度也较低。通过两次2 倍上采样的操作缓解了大倍数上采样所造成的图像中大量有效信息丢失的问题,使最终预测结果更加精确。经过大量实验结果表明,CDCA-DLV3+优于DeepLabV3+。
在本文中所使用的DeepLabV3+网络参数较多,不利于终端设备上部署,未来可以考虑对SegFormer[33]网络使用ASPP 模块以及其他注意力机制进行改进,在终端设备上获得更好的精度和预测结果。
猜你喜欢
科学技术与工程(2023年3期)2023-03-15
小雪花·成长指南(2022年1期)2022-04-09
软件导刊(2022年3期)2022-03-25
新一代信息技术(2021年22期)2021-12-29
计算机技术与发展(2019年1期)2019-01-21
传媒评论(2017年3期)2017-06-13
故事作文·高年级(2017年2期)2017-03-01
第二课堂(课外活动版)(2016年2期)2016-10-21
新闻传播(2015年20期)2015-07-18
世界科学(2013年11期)2013-03-11
