
基于孪生网络的单目标跟踪算法综述
2023-03-24 13:24王梦亭杨文忠武雍智
计算机应用 2023年3期
王梦亭,杨文忠,武雍智
(新疆大学 信息科学与工程学院,乌鲁木齐 830046)
0 引言
目标跟踪源于计算机视觉,以图像、视频数据为基础,融合了图像处理、模式识别、人工智能、自动控制等多个领域,在安防监控[1-3]、智能交通[4]、自动驾驶[5]、人机交互[6]、自主机器人[7]、运动[8]、海洋探索[9]等领域广泛应用。视觉目标跟踪按照跟踪物体的数量分为单目标跟踪和多目标跟踪,本文主要介绍单目标跟踪。单目标跟踪指给定第一帧用边界框标记的感兴趣目标后,在视频的后续帧中自动给出目标的位置和形状,如图1 所示。在标注感兴趣行人(矩形框内的人)后,跟踪算法逐帧地找出监控视频下该行人的位置。在给定边界框的情况下,跟踪算法需要面对光照变化、快速运动、遮挡、目标形变、背景干扰、尺度变化等挑战,而且随着时间跨度的增长,这些挑战会进一步放大,因此开发一种高精度、鲁棒性和实时性的跟踪算法充满挑战性。为了应对这些挑战,研究者们已经提出了许多优秀的目标跟踪算法。

图1 单目标跟踪示意图Fig.1 Schematic diagram of single target tracking
目前的目标跟踪算法根据工作方式分为基于相关滤波和基于深度学习的跟踪算法。基于相关滤波的跟踪算法可进一步分为传统的相关滤波算法和结合深度特征的相关滤波算法[10];基于深度学习的跟踪算法可进一步分为基于孪生网络的算法和其他算法。表1 列出了不同类型的经典算法使用的特征和它在OTB2015 数据集上的成功率图中的曲线下面积(Area Under Curve,AUC)及帧率。可以看出,KCF(Kernelized Correlation Filters)[11]和FDSST(Fast Discriminative Scale Space Tracker)[12]等传统相关滤波算法使用手工设计的特征(灰度、颜色(Clolor Names,CN)、方向梯度直方图(Histogram of Oriented Gradient,HOG)等)进行目标描述,特点是速度快,可以在中央处理器(Central Processing Unit,CPU)上实时运行,但精度一般。相较于手工提取的特征,卷积神经网络(Convolutional Neural Network,CNN)提取的特征更具鲁棒性,包含更多的语义信息。DeepSRDCF(Deep Spatially Regularized Discriminative Correlation Filters)[13]和ECO(Efficient Convolution Operators for tracking)[14]等结合深度特征的相关滤波算法使用在图像分类数据集中预先训练好的CNN 的特征,精度大幅提高,但因提取特征耗费了大量时间,在图形处理器(Graphics Processing Unit,GPU)上实时性较差。随着深度学习的进一步发展和大型跟踪数据集的建立,出现了许多基于深度学习的跟踪算法。MDNet(Multi-Domain Network)[15]等其他深度跟踪算法性能虽好,但需要在线使用随机梯度下降以适应网络的权值,严重影响了系统的运行速度。SiamFC(Fully Convolutional Siamese network)[16]和SiamRPN(Siamese Region Proposal Network)[17]等基于孪生网络的跟踪算法因特殊的网络结构,在精度和速度之间取得了很好的平衡,受到研究者的广泛关注。本文将详细介绍基于孪生网络的跟踪算法,并根据现有的不足讨论该研究方向的发展趋势。

表1 不同类型跟踪算法比较Tab.1 Comparison of different types of tracking algorithms
1 孪生网络的结构和应用
孪生网络结构如图2 所示,由双网络组成,这两个网络的输入不同,但结构一般相同,并且参数共享,即参数一致。孪生网络结构的主要思想是找到一个可以将输入映射到目标空间的函数,使目标空间中的简单距离近似于输入空间的“语义”距离。更准确地说该结构试图找到一组参数,使相似度度量在属于同一类别较小,在属于不同类别时较大。孪生网络结构另一个特点是可以自然地增加训练数据量,即每次输入一对图像。这样就可以充分利用有限的数据集来训练网络,这一点在目标跟踪领域非常重要,因为和目标检测相比,跟踪领域的训练数据集较少。
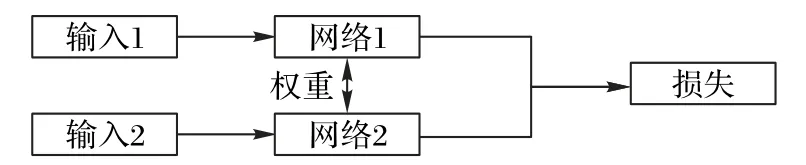
图2 孪生网络结构示意图Fig.2 Schematic diagram of Siamese network structure
孪生网络首先应用在签名验证领域,1993 年,Bromley等[18]提出用于签名验证的双流孪生架构。之后,孪生网络架构被用于人脸验证[19-20]、地对空图像匹配[21]、局部块描述符学习[22-23]、立体匹配[24]与一次性字符识别[25]等领域。随着SiamFC 的出现,研究者将孪生网络引入目标跟踪领域,开创了深度学习目标跟踪方法的一个范式,后续出现了大量的相关改进算法。大多数目标跟踪算法都可以表述为一个类孪生架构,它的主要结构可以概括为三个部分:用于模板和搜索区域特征提取的孪生网络、用于嵌入两个孪生分支信息的相似度匹配模块和用于从相似度图中提取特征的跟踪头。
2 基于孪生网络的跟踪算法
Tao等[26]提出的SINT(Siamese INstance search Tracker)算法是基于孪生网络的跟踪算法的开山之作。该算法训练一个孪生网络来识别与初始目标外观匹配的候选图像位置,将目标跟踪问题转化为匹配问题。此外,该算法结合光流和边界框回归以改进结果,但光流的计算成本很高,系统仅以2 frame/s 的帧率运行,远未达到实时性。同年Bertinetto等[16]提出SiamFC,在初始离线阶段训练一个全卷积网络以解决更一般的相似性学习问题,然后在推理期间对学习到的匹配函数进行简单的在线评估,该方法以远超过实时的速度实现了极具竞争力的性能。相较于SINT,SiamFC 由于轻量化的结构和性能速度的平衡,受到了更多关注。SiamFC 的结构如图3 所示,有两个分支:一个用于模板z(第一帧给定的边界框),另一个用于搜索区域x(当前帧的一个大搜索区域)。两个分支共享同一个参数为θ的网络φ,并产生两个特征图然后,使用互相关运算f组合特征图并生成单通道响应图,响应图中的每个元素表示x中对应的子区域与模板z之间的相似性,那么目标的中心很可能位于响应最高的位置。
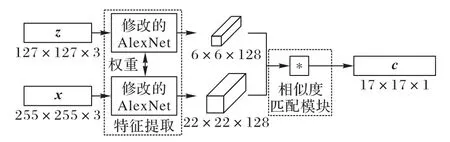
图3 SiamFC架构Fig.3 SiamFC architecture
其中:φ(·)是全卷积嵌入函数;*表示互相关运算;b∈R 表示在每个位置的偏置项。
之后,很多基于孪生网络的跟踪算法被提出,根据它们的架构组成可分为改进特征提取的网络、改进相似度匹配模块和改进跟踪头。
2.1 改进特征提取的网络
2.1.1 增加模块或用更深层网络
SiamFC 之后,很多研究者改进了主干网络。CFNe(tendto-end represention learning for Correlation Filter in deep neural Network)[27]将相关滤波器解释为一个可微分的神经网络层,整合到SiamFC 的模板分支上,彻底将相关滤波和CNN 结合起来。SA-Siam(Semantic and Appearance features Siamese network)[28]增加语义分支,分别训练语义分支和外观分支,但在推理时进行组合,以相互补充,提升跟踪算法的判别力。RASNe(tResidual Attentional Siamese Network)[29]使用残差注意力、通道注意力和通用注意力对SiamFC 特征的空间和通道进行加权,分解特征提取和判别性分析的耦合,以提升判别能力。StructSiam(Structured Siamese network for real-time visual tracking)[30]添加局部模式检测模块,用判别模式识别目标,并且为了加强局部模式之间的结构关系,使用消息传递模块考虑来自相关模式的上下文信息,从而进一步细化预测的局部模式。SPM-Tracker(Series-Parallel Matching for realtime visual object Tracking)[31]和C-RPN(siamese Cascaded RPN)[32]分别采用轻量关系网络[33]和堆叠RPN 作为细化模块,进一步提高跟踪算法的判别能力和精度。
SiamFC、SiamRPN 等早期孪生跟踪算法使用的骨干网络相对较浅(如AlexNet[34]),不能充分利用现代深度神经网络的能力。SiamRPN++[35]和SiamDW(Deeper and Wider Siamese network)[36]从不同角度解决由于填充破坏严格的平移不变性而导致的不能使用深层网络的问题,SiamRPN++从数据增强和特征融合的方向来解决这个问题,而SiamDW 从网络架构设计方向解决该问题,它们都成功地将现代深层网络(如ResNet[37]、ResNeXt[38]和Inception[39])引入了基于孪生网络的跟踪算法。
2.1.2 设计特定网络
现有的基于深度学习的跟踪算法使用具有平移不变性的CNN,能有效解决平移问题,但不适合解决旋转和尺度问题。Gupta等[40]为了解决平面内旋转问题,提出旋转等变孪生网络(Rotation-Equivariant Siamese Network,RE-SiamNet),该网络由可控滤波器组成的组等变卷积层构建,可以适应旋转变化,而不需要额外的参数成本。Sosnovik等[41]为解决尺度变化问题,提出了具有尺度等价不变性的模块替换传统的卷积层、池化层和互相关运算,构建了一个内置尺度等变属性的卷积网络,能准确捕获目标的尺度变化。
2.1.3 优化网络
Huang等[42]发现在跟踪场景中大部分都是简单场景,较难的部分在整个跟踪视频中仅占一小部分,为此提出了一个自适应的深度特征流的跟踪算法EAST(EArly-Stopping Tracker),用强化学习的思想选择可以判断跟踪结果的特征层,避免了继续的前向操作从而大幅节省了时间,在GPU 上的帧率达到了158.9 frame/s。Yan等[43]认识到现有的优秀的跟踪算法模型越来越大、计算成本越来越高,这限制了它们在资源受限的应用程序中的部署,提出了LightTrack(finding Lightweight neural networks for object Tracking),使用神经架构搜索(Neural Architecture Search,NAS)设计更轻量级和高效的目标跟踪算法,并引入了有效的搜索空间,缩小了目标跟踪任务中学术模型和工业部署之间的差距。
2.2 改进相似度匹配模块
2.2.1 改进互相关
在基于孪生网络的跟踪算法中,相关操作是嵌入两个分支信息的核心操作。如图4(a)所示,SiamFC 将模板特征作为核和搜索帧特征进行互相关,即一个卷积操作,模板帧特征在搜索帧特征上滑动,逐通道之间互相作内积,最后输出单通道数响应图。考虑到每一个位置对前景的贡献不同,RASNet 在注意力机制的基础上提出了一种加权互相关运算,有选择性地利用特征图的各个位置。在SiamRPN 中引入锚(anchor),通过多个独立模板层对一个检测层的卷积操作以获得多通道独立的张量,而这导致了RPN 层的参数量远大于特征提取层,因此SiamRPN++设计了一种轻量化的深度互相关运算用于嵌入模板和搜索区域分支的信息,如图4(b)所示,使用两个分支的特征图执行逐通道的相关操作。借鉴文献[44]的思想,Alpha-Refine(AR)[45]采用逐像素相关,如图4(c)所示,模板特征的HzWz个1×1×C特征与搜索帧特征进行卷积,最后生成通道数为HzWz、大小为Hx×Wx的响应图。考虑到传统的互相关操作带来了大量的背景信息,PGNet(Pixel to Global matching Network)[46]利用一种像素-全局匹配的方法抑制背景的干扰,相当于经过了两次的逐像素相关。考虑到相关操作为启发式设计,严重依赖人工经验,并且单一的匹配方法无法适应各种复杂的跟踪场景,AutoMatch(Automatic Matching network design for visual tracking)[47]中引入了6 种新的匹配算子来替代互相关。通过分析这些算子在不同跟踪挑战场景下的适应性,结合6 种算子进行互补,并借鉴NAS 思想提出二进制信道操作(Binary Channel Manipulation,BCM)来搜索这些操作符的最优组合。

图4 相关操作Fig.4 Correlation operations
2.2.2 设计新信息嵌入模块
认识到因为提取以目标中点为中心的固定大小的区域的特征会导致提取到部分背景信息或丢失部分目标信息,因此SiamGAT(Siamese Graph Attention Network)[48]中提出了一种目标感知区域选择机制,并应用图注意机制将目标信息从模板特征传播到搜索特征,以适应不同对象的大小和宽高比变化。Zhou等[49]设计了一种细粒度的显著性挖掘机制,以捕获目标的局部显著性,这些显著性在搜索图像中具有鉴别性和易于定位的特点。然后,建模这些显著性之间的相互作用,并关联捕获的显著性,学习目标样本与搜索图像之间的全局相关性,从而准确地反映搜索图像中的目标状态。考虑到相关操作无法充分受益于大规模的离线学习,并且容易被干扰物影响,对目标边界的识别能力较弱,Han等[50]提出了一个可学习的非对称卷积模块(Asymmetric Convolution Module,ACM),该模块学习如何在离线训练期间更好地从大规模数据中捕获语义信息,就可以轻松集成到现有的基于深度互相关或互相关的孪生跟踪算法中。Chen等[51]认为相关操作容易丢失语义信息并陷入局部最优,提出一种基于Transformer 的特征融合网络,利用注意机制将模板和搜索区域特征有效地结合起来。设计的特征融合网络包括一个自我注意的自我上下文增强模块和一个交叉注意的跨特征增强模块。这种融合机制有效地融合了模板特征和感兴趣区域(Region Of Interest,ROI)特征,产生了更多的语义特征映射。
2.3 改进跟踪头
2.3.1 目标状态估计
在真实的视频中,目标的比例和纵横比也会随目标或摄像机的移动和目标外观的变化而变化。准确估计目标的尺度和长宽比是视觉跟踪领域的难题。然而,早期许多跟踪算法[16,28]忽略了这一问题,仅依赖于多尺度搜索来估计目标的大小。多尺度搜索由于固定长宽比的预测和大量的图像金字塔运算,既不够精确又耗时。
SiamRPN 引入了目标检测中的区域候选网络(Region Proposal Network,RPN)[52],用一组预定义的锚框来估计目标边界框。如图5 所示,将原始的相似度计算问题转化为分类和回归问题,分类分支用于锚的背景-前景分类,回归分支用于候选的细化,在提高精度的同时也提升了速度。
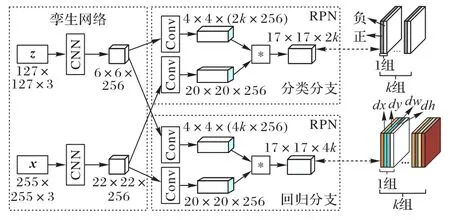
图5 SiamRPN架构Fig.5 SiamRPN architecture
SiamRPN 系列的跟踪算法虽然可以处理尺度和长宽比的变化,但需要仔细设计和确定锚框的参数。设计参数通常需要启发式调整,并涉及许多技巧。无锚方法结构简单、性能优越,近年来在目标检测任务中越来越流行。研究者也开始将它应用于跟踪领域,提出了SiamFC++(Fully Convolutional Siamese tracker++)[53]、SiamCAR(Siamese based Classification And Regression network)[54]、SiamBAN(Siamese Box Adaptive Network)[55]和Ocean(Object-aware anchor-free networks)[56]等无锚跟踪算法,实现了最先进的跟踪性能。如图6 所示,将跟踪任务作为联合分类和回归问题处理,采用一个或多个头部直接预测客观性,并以逐像素预测的方式从响应图中回归边界框。
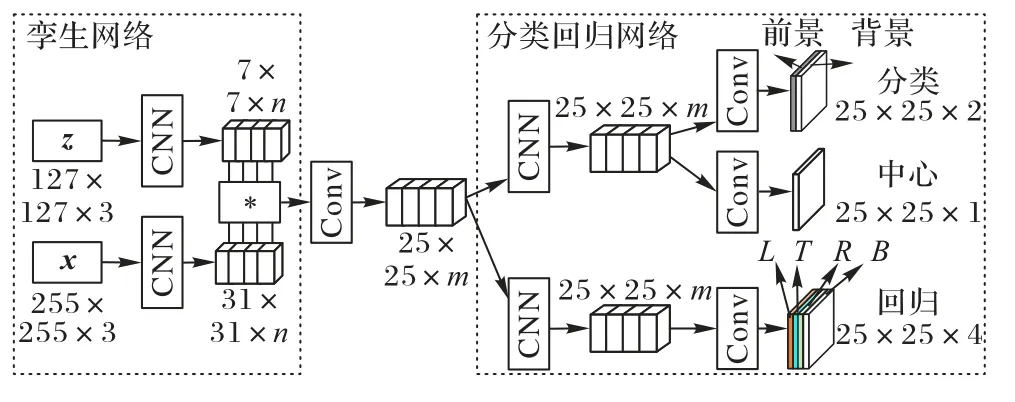
图6 SiamCAR架构Fig.6 SiamCAR architecture
还有一些无锚算法如CGACD(Correlation-Guided Attentional Corner Detection-based tracker)[57]在两个阶段进行相关引导的注意角检测。首先,利用高效的孪生网络区分开目标与背景,获得感兴趣区域;其次,像素方向相关引导的空间注意模块和通道方向相关引导的通道注意模块利用目标模板与感兴趣区域之间的关系来突出角点区域,对增强感兴趣区域的特征进行角点检测。相关引导的注意模块提高了角点检测的准确性,实现了精确的边界框估计。受文献[58]启发,RPT(Representative Points based Tracker)[59]提出将跟踪目标表示为一系列特征点,通过监督学习目标区域内的语义关键点与极值点,实现更精细的目标状态估计。
2.3.2 基于分割生成掩膜(mask)
在视觉目标跟踪任务中,为了方便真值标注与特征提取,目标状态通常用与坐标轴垂直的矩形框表示,但矩形框是对目标区域的一种粗略表示,引入了多余的背景,不能很好地呈现跟踪结果。从2014 年开始,VOT(Visual Object Tracking)使用旋转边界框作为更准确的目标位置近似值。2020 年开始使用分割掩码标注数据集。SiamMask[60]使用YouTube-VOS[61]训练额外分支以生成二进制分割掩码,使跟踪结果更加准确。AR[44]采用角点预测头和辅助掩模头作为核心组件,该模块独立训练,可以以即插即用的方式直接应用于任何现有的跟踪算法(如:SiamRPN,DiMP-50(learning Discriminative Model Prediction for tracking)[62]),实验结果表明基础跟踪算法的性能得到显著提高。
2.3.3 在线模型更新
早期的孪生跟踪算法通常不使用模型更新策略。目标模板在第一帧中初始化,然后在视频的剩余部分保持固定。在许多常规跟踪场景中运行时,具有良好的性能和实时跟踪速度。然而,当目标出现剧烈的外观变化、非刚性变形和部分遮挡时,目标模板会严重漂移,并且无法从跟踪失败中恢复。在这种情况下,使模型适应当前目标的外观很重要。
1)简单线性更新策略:许多跟踪算法,包括GOTURN(Generic Object Tracking Using Regression Network)[63]、SINT[26]和SiamRPN[17]等,为适应目标外观变化,假设在视频的所有帧中,以及在不同的视频中,目标外观变化的速率恒定。但实践中对目标模板的更新需求因不同的跟踪情况有很大的不同,这取决于运动、模糊或背景混乱等外部因素的复杂组合。因此,简单的线性更新往往不足以应付不断变化的更新需求,也不足以概括所有可能遇到的情况。此外,线性更新在所有空间维度上也是恒定的,因此不允许局部更新。这在部分遮挡的情况下尤其具有破坏性,因为只有模板的某一部分需要更新。
2)记忆网络:RFL(Recurrent Filter Learning tracking)[64]使用长短时记忆网络(Long Short-Term Memory network,LSTM)来更新每一帧目标外观模型。MemTrack(learning dynamic Memory networks for object Tracking)[65]利用LSTM 结构挖掘历史帧的模板信息以更新当前帧的模板。STMTrack(Space-Time Memory networks Tracker)[66]在时空记忆网络中,通过查询帧自适应地检索存储在多个记忆帧中的目标信息,使跟踪算法对目标变化具有较强的自适应能力。
3)模板更新策略:孪生跟踪算法设计各种策略在线更新模板,以提高基于孪生的跟踪算法的目标识别能力。DSiam(Dynamic Siamese network)[67]中提出了一种具有快速转换学习模型的动态孪生网络,能实现有效的模板更新和杂波背景抑制。DaSiamRPN(Distractor-aware Siamese Region Proposal Network)[68]在SiamRPN 的基础上设计了一个干扰感知模块,实现对语义干扰的增量学习,获得了更多的识别特征。UpdateNet[69]训练了一个独立的卷积网络并利用历史模板在下一帧预测一个最优的模板特征。GradNe(tGradient-guided Network)[70]通过梯度信息更新模板,一定程度上可以抑制模板中的背景信息。MLT(Meta Learning Tracking)[71]引入元学习网络学习特定目标的特征,与传统孪生网络提取的通用特征融合后,得到自适应的目标特征,再进行后续的相似性计算。GCT(Graph Convolutional Tracking)[72]采用时空图卷积网络进行目标建模。Wang等[73]考虑到在视频目标跟踪中,连续帧之间存在丰富的时间上下文,而这些在现有跟踪算法中被严重忽视,因此尝试连接单个视频帧,并通过一个Transformer 架构来探索它们之间的时间上下文,以实现鲁棒性目标跟踪。该架构采用类孪生结构,将编码器和解码器分成两个并行分支:编码器通过基于注意的特征增强来提升目标模板,有利于高质量的跟踪模型生成;解码器将跟踪线索从以前的模板传递到当前帧,平滑外观变化并纠正上下文噪声,同时转换空间注意力,突出潜在的目标位置。这些多重目标表示和空间线索使目标搜索更加容易。最后,在解码后的搜索块中跟踪目标。Yan等[74]提出了一种新的基于编码器-解码器的用于视觉跟踪的时空结构STARK(Spatio-Temporal trAnsfoRmer network for visual tracKing)。该架构包含三个关键组件:编码器、解码器和预测头。编码器接受初始目标对象、当前图像和动态更新的模板的输入。编码器中的自注意模块通过特征依赖关系学习输入之间的关系。由于模板图像在整个视频序列中不断更新,编码器可以同时捕获目标的空间和时间信息,在空间和时间维度上捕捉长期依赖关系。解码器学习一个查询嵌入以预测目标对象的空间位置。基于角的预测头用于估计当前帧中目标对象的边界框;同时,通过学习得分头来控制动态模板图像的更新。
4)在线更新网络参数:Ocean[56]中设计了一个在线更新模块,采用快速共轭梯度算法在推理过程中在线训练分支,使它能够在推断期间捕获对象的外观变化。RPT[58]的分类子网在线训练在干扰物存在时能获得高分辨能力,通过聚合多个卷积层提供更细粒度的定位和更详细的目标结构信息。
5)深度判别相关滤波器:相关滤波器是一种训练线性模板以区分图像以及平移的算法。它非常适用于目标跟踪,因为它在傅里叶域中的公式提供了快速的解决方案,使检测器能够每帧预先重新训练一次。CFNet[27]将相关滤波器解释为将孪生跟踪框架中的可微分层进行端到端的训练,彻底结合相关滤波和CNN。之后研究者采用梯度优化的方法来端到端地优化基于相关滤波器算法的深度框架。CREST(Convolutional RESidual learning scheme for visual Tracking)[75]使用随机梯度下降(Stochastic Gradient Descent,SGD)法优化正则化最小二乘损失(即岭回归),并学习一个类似于相关滤波器的、具备前景背景区分能力的卷积核。RTINet(Representation and Truncated Inference Network)[76]结合了CNN 与高级相关滤波器跟踪算法。FlowTrack(Flow correlation Tracking)[77]利用连续帧中丰富的光流信息来提高特征表示和跟踪精度,在光流信息的引导下,将前一帧转化为指定帧,并进行聚合,以进行后续相关滤波跟踪。针对自适应聚集,FlowTrack 中引入了一种新的时空注意机制,在空间注意中,利用空间相似性对特征图进行平面位置加权,然后将特征图的通道重新加权以考虑时间注意力。ATOM(Accurate Tracking by Overlap Maximization)[78]采用共轭梯度策略结合深度学习框架进行快速优化。DiMP[62]进一步将该思想扩展到了端到端的学习中,并通过神经网络学习跟踪模型所需的各种参数。PrDiMP(Probabilistic DiMP)[79]引入了概率回归,进一步改进了DiMP 跟踪算法。ROAM(Recurrently Optimizing trAcking Model)[80]使用可调大小的卷积滤波器来适应目标的形状变化,使用元学习更新跟踪模型,对于使用边界框回归代替多尺度搜索估计目标框的模型命名为ROAM++。
2.4 其他
2.4.1 训练样本增强
早期的孪生跟踪算法(尤其是SiamFC 和SiamRPN)在训练期间仅从同一视频中采样训练图像对,这种抽样策略不关注具有语义相似的干扰对象。DaSiamRPN[68]引入了难负样本挖掘技术,通过在训练过程中包含更多语义负对来解决数据不平衡的问题。DaSiamRPN 构建的负对由相同和不同类别的标记目标组成,这种技术更多地关注细粒度的表示以帮助DaSiamRPN 克服漂移。同样,Siam R-CNN[81]提出了另一种使用嵌入网络和最近邻近似的难负样本挖掘技术。对于每个真值目标边界框,使用预训练网络提取嵌入向量以获得相似的目标外观,然后使用索引结构估计近似最近邻,并使用它们来估计嵌入空间中目标对象的最近邻。SINT++[82]在SINT 基础上引入正样本生成网络(Positive Samples Generation Network,PSGN)和难正样本变换网络(Hard Positive Transformation Network,HPTN)。PSGN 通过遍历构造的目标流形来采样大量不同的训练数据,以提升正样本的多样性。HPTN 生成较难的正样本用于算法的识别,使跟踪算法对遮挡具有更强的鲁棒性。
2.4.2 无监督跟踪
现有的深度跟踪算法需要大量标注数据进行训练,每一帧都需要进行标注,这是一件工程量很大的工作。UDT(Unsupervised Deep Tracking)[83]尝试在大规模无标签视频上以无监督的方式训练;同时,UDT 还使用一个多帧验证方法(multiple-frame validation)和代价敏感的损失函数(costsensitive loss)去加强这个无监督学习的过程。无监督框架显示利用无标记或弱标记数据进一步提高跟踪精度的潜力。
还有一些研究者从其他方面设计跟踪算法。GOTURN[63]串联成对的连续帧,并通过回归学习的方式学习目标跟踪状态。文献[84]将三元组损失引入孪生跟踪框架,考虑正负样本之间的关系,使跟踪算法更加具有判别力。
3 基准数据集与评估指标
视觉跟踪基准为单目标跟踪算法提供公平和标准化的评估。本章介绍最常用的视觉跟踪基准数据集和评估指标。
3.1 数据集
现有的视觉跟踪数据集根据是否包含训练数据可以分为两大类。如表2 所示,早期的数据集只包括测试视频,之后为了训练深度跟踪算法,提出了几种大规模的跟踪数据集,可以对跟踪算法进行训练和测试。目标在跟踪过程会受到各种干扰因素的影响,为了全面评估跟踪算法在各种挑战下的准确性和鲁棒性,数据集中每个视频都标注了一个或多个属性,包括尺度变化(Scale Variation,SV)、出视野(Out-of-View,OV)、形 变(DEFormation,DEF)、低分辨 率(Low Resolution,LR)、光照变化(Illumination Variation,IV)、平面外旋转(Out-of-Plane Rotation,OPR)、遮挡(OCClusion,OCC)、背景干扰(Background Clutter,BC)、快速运动(Fast Motion,FM)、平面内旋转(In-Plane Rotation,IPR)、运动模糊(Motion Blur,MB)、部分遮挡(Partial Occlusion,POC)、镜头运动(Camera Motion,CM)、长宽比变化(Aspect Ratio Change,ARC)、完全遮挡(Full OCclusion,FOC)、视角变化(Viewpoint Change,VC)、相似物体(Similar OBject,SOB)、目标旋转(ROTation,ROT)、运动变化(MOtion Change,MOC)、目标颜色变化(Object COlor change,OCO)、场景复杂度(Scene COmplexity,SCO)、绝对运动(Absolute Motion,AM)、对抗样本(Adversarial Sample,AS)、热交叉(Thermal Crossover,TC)、模态切换(Modality Switch,MS)等。表2 也给出了每个数据集的描述。
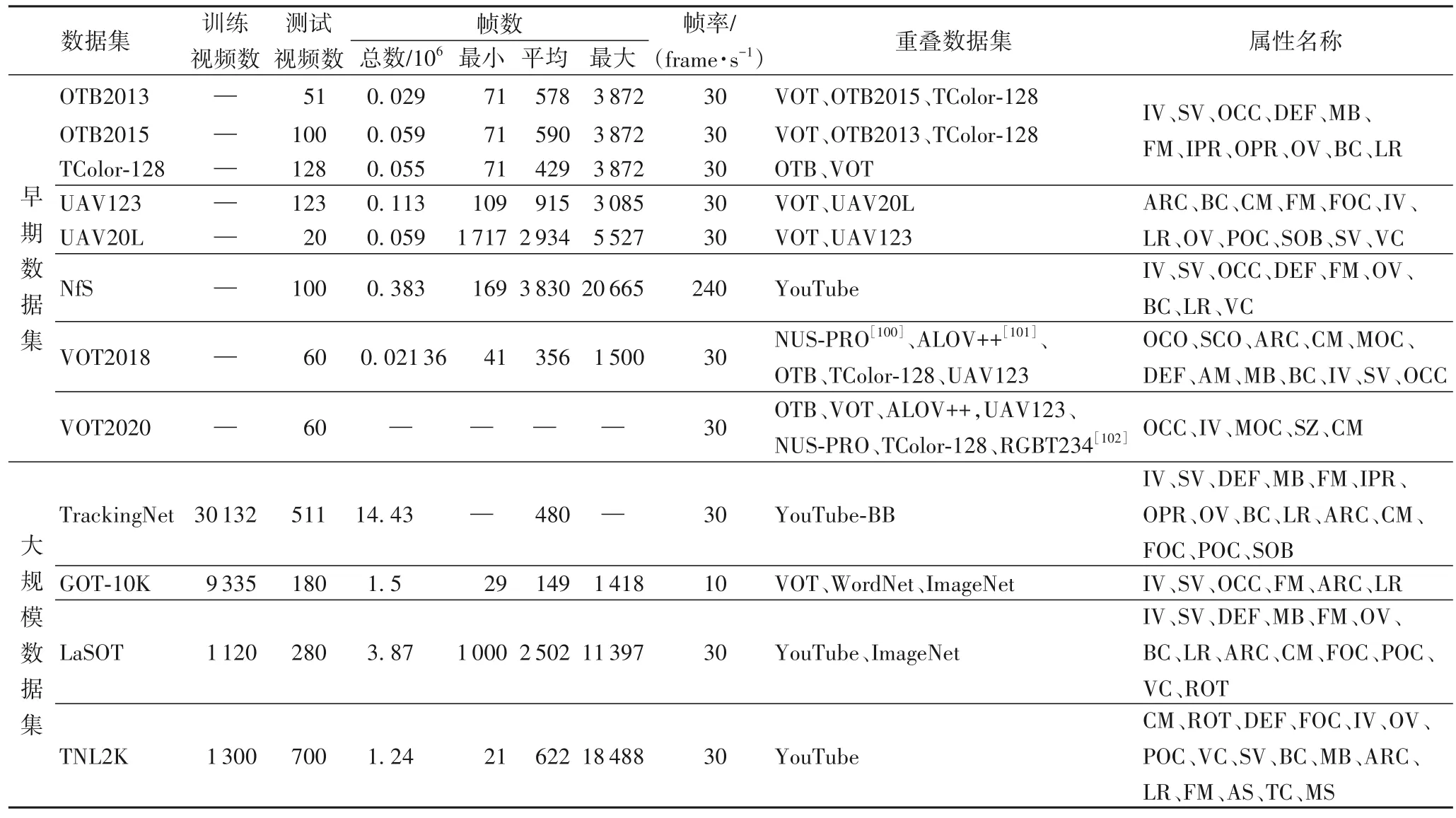
表2 常用跟踪数据集的详细信息Tab.2 Details of commonly used tracking datasets
3.1.1 早期数据集
早期数据集只有测试集,旨在对跟踪算法进行一致性的评估及比较。
OTB(Object Tracking Benchmark)是最早的视觉跟踪公开数据集,包括OTB2013[85]和OTB2015[86],用于解决几个视频序列因为初始条件或参数不一致导致跟踪结果受影响的问题,旨在进行无偏的性能比较。OTB2015 在OTB2013 的基础上增加到100 个序列(Jogging 因标注对象不同,可以看作两个视频序列)。常用的还有OTB50(TB50)和OTB100(TB100)。OTB50 是Visual Tracker Benchmark 网页的前50 个视频序列(SKating2 因标注对象不同,可以看作两个视频序列),OTB100 则与OTB2015 一样。由于OTB50 中一些目标物体相似或不太具挑战性,OTB2013 从OTB50 和The rest of TB-100 Sequences 中,选取了51 个困难的和有代表性的物体进行深入分析。
之后,为了比较视觉跟踪算法在颜色序列上的性能,Tcolor-128(Temple Color 128)[87]收集了一组128 个完全注释的彩色视频序列,其中78 个不同于OTB 数据集。为了探索高帧率的影响,NfS(Need for Speed)[88]收集了100 段高帧率(240 frame/s)的视频,还通过间隔8 帧采样和运动模糊渲染生成了正常帧率(30 frame/s)的视频。UAV123(Unmanned Aerial Vehicles)[89]包含从低空航空视角捕获的123 个完全标注的高清视频序列,因无人机的运动相机视角在不断改变,UAV123 中相较于初始帧,边界框大小和纵横比的变化非常显著,导致利用该数据集进行跟踪具有挑战性。此外,相机被固定在无人机上,可以随着物体移动,能够产生较长的跟踪序列,因此切割出了一个长期无人机跟踪数据集UAV20L。
VOT(Visual Object Tracking)数据集来自每年一次的VOT 比赛,从2013 年至今已有9 个(2013—2021 年),旨在评测复杂场景下单目标跟踪算法的性能。下面主要介绍近年来常用的VOT2018 和VOT2020。从VOT2018[90]开始,增加了长期目标跟踪挑战,记为VOT-LT,对短暂离开视野和遮挡情况下算法的性能进行评测。VOT-ST2020[91]中,数据集的标注完全放弃了边界框,目标位置由精确的每帧分割掩码编码。
3.1.2 大规模数据集
随着深度跟踪算法的出现,提出了几种大规模跟踪数据集,这些数据集包括训练集和测试集,旨在对跟踪算法进行训练和评估。
TrackingNet[92]是目标跟踪领域的第一个大规模数据集,是视频目标检测基准YouTube-BoundingBoxes(YT-BB)的子集(选择31K 序列),测试集包含511 个没有公开真实标注框的视频。它涵盖了不同的对象类和场景,要求跟踪算法具有判别和生成能力,有效解决了基于深度学习的数据需求型跟踪算法缺乏专用的大规模数据集的问题。结果通过在线评估服务器获得。
GOT-10K(Generic Object Tracking)[93]是由中国科学院发布的建立在WordNet[94]结构主干上的目标跟踪数据集,同时也是目标跟踪领域第一个使用WordNet 的语义层次指导类填充的数据集。它的主要特点是测试集与训练集在目标类上没有重叠,目的是评估视觉跟踪算法的泛化性。因此按照GOT-10K 的测试协议,只使用GOT-10K 训练集训练跟踪算法。与TrackingNet 一样,测试集的真值标注框被保留,跟踪结果必须通过评估服务器获得。
LaSOT(Large-scale Single Object Tracking)[95]是一个大规模、高质量、密集标注的长期跟踪数据集。为了减小潜在的类别偏差,为每个类别提供相同数量的序列。共包含85 个类,其中70 个类,每类包含20 个视频序列;另外15 类,每类包含15 个视频序列。此外,考虑了视觉外观和自然语言的联系,不仅标注了边界框,而且增加了丰富的自然语言描述,以描述目标物体的外观。
TNL2K[96]致力于按自然语言进行跟踪,包含663 个字。对于每一个视频序列,用英语注释了一个句子。该句子描述第一帧目标物体的空间位置和相对其他物体的位置、属性和类别。
除上述跟踪数据集之外,ImageNet DET、ImageNet VID[97]、YT-BB[98]、COCO[99]数据集 也经常 用于训 练跟踪算法。
3.2 评价指标
首先介绍两个最基本的度量指标:中心位置误差和重叠分数,如图7 所示。
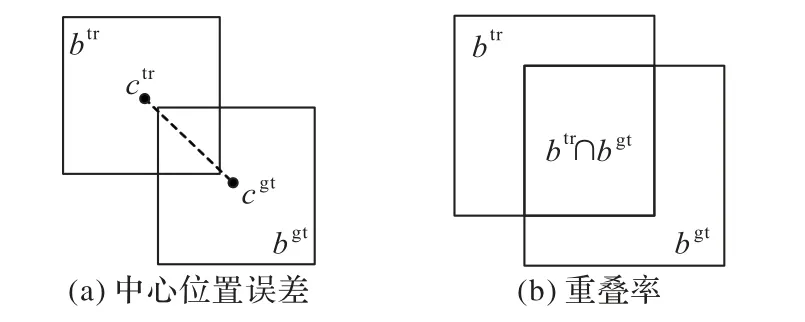
图7 度量指标Fig.7 Evaluation metrics
中心位置误差:人工标注(ground-truth)的边界框的中心点cgt与跟踪算法估计的边界框的中心点ctr之间的距离‖ctr-cgt‖2(以像素为单位)。
重叠率得分(overlap score,os):如式(1)所示,跟踪算法估计的边界框btr和人工标注框边界框bgt的交集与并集之比,其中 |· |表示结果区域的像素数目。
在OTB 基准中将中心位置误差和重叠率进一步扩展为精确率图和成功率图。Tcolor-128、UAV123 等数据集都沿用了OTB 提供的评价指标。
精确率:中心位置误差小于给定阈值的视频帧占所有帧的百分比。不同的阈值得到的百分比不一样,因此可以获得一条曲线。使用精确率图中阈值为20 时的值对跟踪算法进行排名,但该指标无法反映目标物体大小与尺度的变化。
成功率(Success Rate,SR):当某一帧的重叠率大于设定的阈值时,则该帧被视为成功,总的成功的帧占所有帧的百分比即为成功率。重叠率的取值范围为0~1,因此可以绘制出一条曲线。使用成功率图的曲线下面积(Area Under Curve,AUC)对跟踪算法进行排名。SR0.50和SR0.75为阈值为0.5 和0.75 时SR 的值。
正则化的精确度:TrackingNet 为了减小目标尺寸对精确率指标的影响,提出了正则化的精确率指标:
平均重叠率(Average Overlap,AO):所有帧重叠率得分的平均值。
自VOT2015 以来,VOT 基准通过基于重置的方法评估跟踪算法。当跟踪算法与真值没有重叠时,跟踪算法将在5 帧后重新初始化。主要评价指标是准确率(Accuracy,A)、鲁棒性(Robustness,R)和预期 平均重 叠(Expected Average Overlap,EAO)。VOT2020 提出了一种新的基于锚(anchor)的评估协议,对目标跟踪的评价更加公正。
跟踪失败:人工标注目标位置与预测目标位置的重叠小于0.1 且至少10 帧后未超过0.1 的帧。
准确率:跟踪失败前帧的平均重叠,在所有子序列上取平均值。数值越大,准确度越高。
鲁棒性:成功跟踪的子序列帧的百分比,在所有子序列上取平均值。数值越大,稳定性越差。
预期平均重叠:跟踪准确率和鲁棒性的结合。计算方式没有改变,只是划分子序列的方式由原来的根据重启位置划分变成现在的根据anchor 的位置划分。
速度:单目标跟踪的数据集基本都使用25 frame/s 或30 frame/s 的相机混拍,因此当跟踪算法的速度大于25 frame/s,可认为满足实时性要求。
4 实验与结果分析
本文利用OTB Matlab Beachmark 对25 个经典跟踪算法进行对比,其中:DeepSRDCF[13]属于结合深度特征的判别式相关滤波跟踪算法;MDNet[16]属于深度跟踪算法;剩余23 个是孪生跟踪算法。图8 为25 个算法在OTB2015 上的成功率图,图9 为25 个算法在OTB2015 上6 个更常见属性(IV、SV、BC、LR、DEF、OCC)的成功率图,使用的原始结果文件从作者官方网站获得,[ · ]为每种算法取得的最高AUC 值。表3 为23 个基于孪生网络的跟踪算法在OTB2015 剩余5 个属性(FM、MB、OV、IPR、OPR)、LaSOT 和GOT-10K 测试集上的性能结果,结果从原论文或数据集中获取,此外还列出了每个算法的速度。

图8 算法在OTB2015数据集上的成功率Fig.8 Success rate of algorithms on OTB2015 dataset

图9 在OTB2015数据集上各属性的成功率Fig.9 Success rate of algorithms for each attribute on OTB2015 dataset
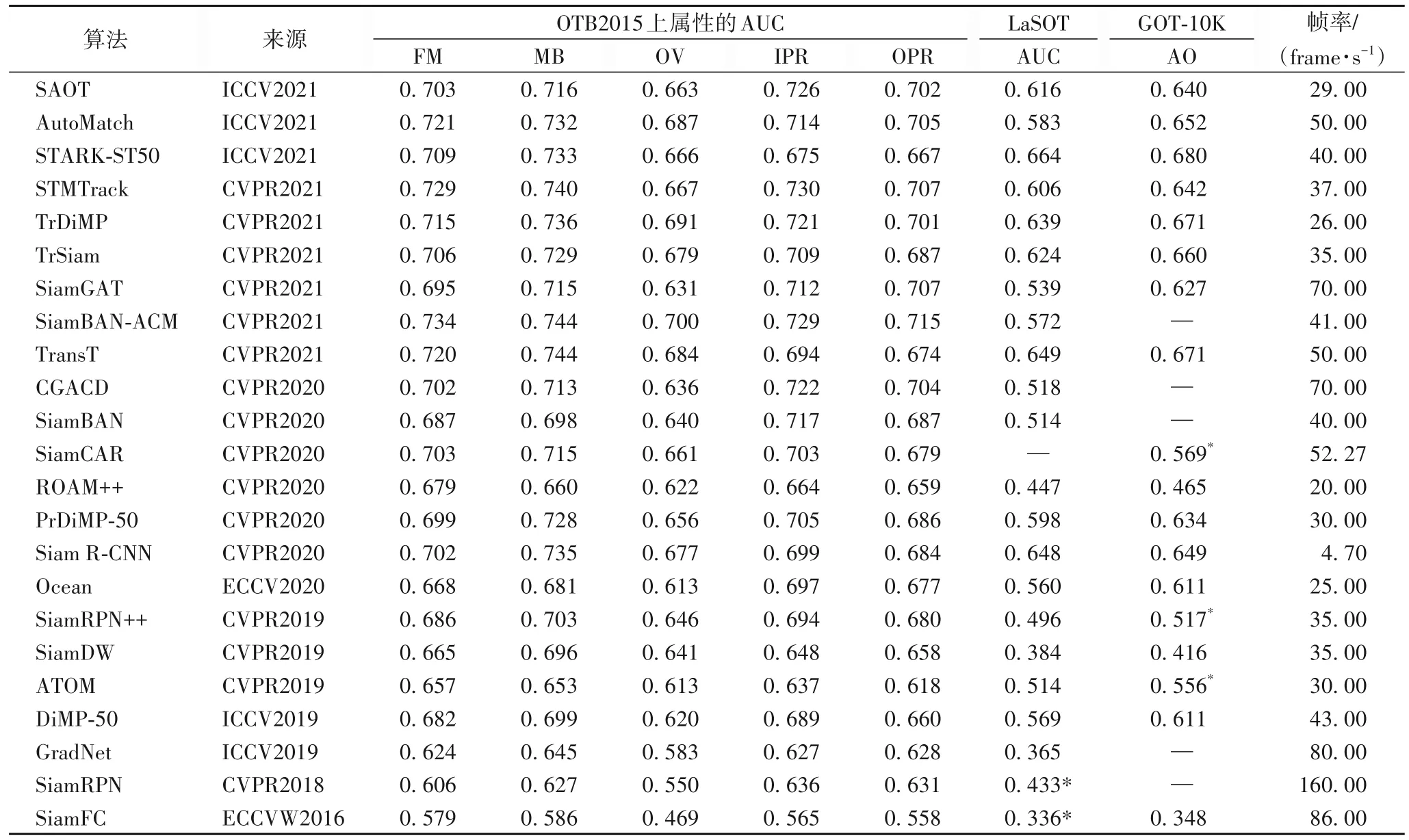
表3 基于孪生网络的跟踪算法的性能比较Tab.3 Performance comparison of Siamese trackers
从图8、9 和表3 中可以看出:
1)用可学习的ACM 替换深度互相关的SiamBANACM[50]在OTB2015 数据集上的平均AUC 为0.724 4,取得了最好的跟踪结果。对于光照变化、平面外旋转、运动模糊、快速运动以及超出视野挑战,始终保持着最优的性能。
2)基于时空记忆网络框架的STMTrack 在OTB2015 数据集上的平均AUC 为0.714 6,取得了次优的结果。它利用与目标相关的历史信息来适应跟踪过程中的外观变化,在尺度变化、平面内旋转、背景干扰的挑战下,表现出最优性能。
3)利用细粒度的显著性挖掘模块捕获局部显著性的SAOT[49],在OTB2015 数据集中面对遮挡、形变挑战时,性能最好。
4)多尺度估计(SiamFC)、锚 框(SiamRPN)和无锚(SiamBAN、SiamCAR)三种目标状态估计方法对比,无锚框跟踪算法通过丢弃多尺度搜索以及预定义候选框策略获得了更好的性能。
5)最早的孪生跟踪算法SiamFC 性能低于结合深度特征的相关滤波器跟踪算法DeepSRDCF 和多域学习的MDNet(一部分训练集来源于测试集,存在过拟合的可能)。随着孪生跟踪算法的发展(SiamRPN++),很快超越了其他跟踪算法,展现出优越性。
6)使用深层网络的跟踪算法SiamRPN++和SiamDW 相较于使用浅层网络的跟踪算法(SiamFC、SiamRPN),精确率得到了很大提高。
7)现有孪生跟踪算法对于光照变化(最高AUC 0.750)、运动模糊(最高AUC 0.744)问题已经取得不错的结果,而对于遮挡(最高AUC 0.693)、形变(最高AUC 0.696)、超出视野(最高AUC 0.700)挑战还不能很好处理。
8)Siam R-CNN 采用重检测设计,在长期跟踪数据集LaSOT 中取得了优异的结果,但速度远未满足实时性要求。ROAM++离线训练一个递归神经优化器,在元学习设置中更新跟踪模型,速度也未满足实时性要求。
9)STARK-ST50[74]和TransT[51]两个基于Transformer 的跟踪算法在大规模LaSOT 和GOT-10K 测试集中取得了最优和次优的结果,且推理速度超越了实时性要求(25 frame/s)。
10)用端到端学习的深度网络扩展现有的在线判别框架的跟踪算法ATOM、DiMP-50、PrDiMP-50[79]和TrDiMP[73]等相较于纯粹的孪生跟踪算法SiamRPN++、SiamBAN、SiamCAR和TrSiam[73]等性能更优,但速度要慢一点。
11)Ocean 在推理过程中在线更新模型参数,跟踪速度较慢。
5 结语
本文根据基于孪生网络的跟踪算法架构的不同改进,介绍了近年来的主要研究,并将23 个代表性孪生跟踪算法和2个其他算法在OTB100 基准数据集上进行了评估,表明了孪生跟踪算法在性能方面的优越性。虽然基于孪生网络的跟踪算法与其他算法相比具有一定的优势,但是在实际场景的应用中,仍然难以满足跟踪任务对速度和性能的需要,存在着进一步研究和发展的空间。结合文章对各算法的总结分析和实验部分的对比结果,并且考虑目前视觉领域的研究热点,基于孪生网络的目标跟踪算法未来可以从以下方面考虑:
1)现有目标跟踪算法大多将视频帧孤立处理,没有利用跟踪任务的时间特征和连续帧之间的时间关系。虽然已有研究利用图神经网络、时空正则化、光流等探索时间信息,但并没有充分挖掘,需要进一步研究。
2)现有跟踪算法模型尺寸大、计算成本高,阻碍了在无人机、工业机器人和驾驶辅助系统等领域的应用。如何在模型精度和复杂度之间找到一个好的平衡点,以缩小目标跟踪任务中学术模型和工业部署之间的差距,需要进一步研究。
3)相似度计算对于孪生跟踪算法至关重要,在该过程中引入特征融合网络,可以有效地将模板和搜索区域特征结合起来,以提高跟踪算法的精确度。
4)Transformer 结构本身关注全局信息、能建模长距离依赖关系,可与关注局部信息的CNN 互补。孪生架构结合Transformer 的跟踪算法虽处于基础阶段,但在各种跟踪数据集中展现出竞争性甚至更好的性能,未来有巨大的挖掘空间。
5)为了提高现有深度跟踪算法的泛化能力,需要使用大量的数据来训练网络,然而数据集的制作需要花费大量的时间和人力,可考虑借助无监督方式,使用未标记的原始视频训练网络,摆脱对标注数据的严重依赖。
6)相较于短时跟踪,长时跟踪更接近真实场景,即目标经常消失或长时间被遮挡。孪生跟踪算法依据视频中上一帧图片目标的中心位置为中心,在一定像素范围内进行匹配查找。但是当视频中目标被长时间遮挡后,跟踪算法无法确定目标的位置,因此设计一个在长期任务中能稳定跟踪的算法具有重要研究价值。
7)在基于分割的跟踪方法中,一般根据分割结果推导目标的外接矩形框,两者之间缺乏协同学习的机制。实际上分割和跟踪结果之间存在一定的空间关系,利用这种空间关系作为约束也许可以提高跟踪网络的准确率。
猜你喜欢
建材发展导向(2022年23期)2022-12-22
建材发展导向(2022年12期)2022-08-19
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
数学小灵通·3-4年级(2017年9期)2017-10-13
中国房地产业(2016年24期)2016-02-16
中国卫生(2015年9期)2015-11-10
河南科技(2014年23期)2014-02-27
中学英语之友·上(2008年2期)2008-04-01
中学英语之友·上(2008年2期)2008-04-01
