
污染场地修复环境中人体姿态估计算法研究
2023-03-15 08:47张宝峰朱均超
计算机应用与软件 2023年2期
张宝峰 田 宇 朱均超 刘 娜
(天津理工大学天津市复杂系统控制理论及应用重点实验室光电器件与通信技术教育部工程研究中心 天津 300384)
0 引 言
污染场地中存在着大量的污染土和污染水,以及由这二者散发出的具有突发性、隐蔽性和高致死性的有毒气体。因此在污染场地中,通过对施工人员进行实时监控及人体姿态估计来保证人员生命安全,是具有重要意义的。
近年来,人体姿态估计方法被大量提出并取得了卓有成效的进展。基于深度学习的多人姿态估计[1-5]主流框架有自顶向下的两步法框架和自顶向上的基于部件的框架两大类[6]。Cao等[7]提出CMU-Pose模型,利用人体关键点亲合场推测出人体的全部骨架信息。Fang等[8]提出RMPE模型,利用对称空间变换网络进一步校正人体检测框,提高模型整体性能。单人姿态估计按照输出表示可分为基于坐标回归、基于热图检测和二者的混合模式三种。Deep Pose模型[9]采用多阶段回归思想,将图像直接回归到人体骨骼关键点的二维坐标。基于热图检测的模型用概率图heatmap来表示关节点坐标。例如堆叠沙漏网络[10],通过heatmap学习各个关节点的位置特征,利用多尺度感受野机制了解各个关节点之间的结构特征。
堆叠沙漏网络虽然通过学习关节点之间的特征提高了各个关节点的关联性,但传统残差模块有效感受野较小,仍存在着复杂背景环境下不能准确检测关键点,以及肢体遮挡情况下鲁棒性较低等问题[11]。针对以上问题,本文提出一个基于感受野与注意力机制的人体姿态估计模型(RF-IA MPEN)。其中姿态估计网络(RF-IA Hourglass Net)采用设计出的大感受野残差模块(Large receptive field residual module)与改进型残差注意力模块(Improved residual attention module),以改进堆叠沙漏网络中的传统残差模块[12-14]和原有的跳级连接结构。RF-Residual模块通过扩大有效感受野面积,使模型更有效地利用图像多尺度信息,进而精准定位局部人体部件和关节,提高姿态估计的准确性与鲁棒性;IA-Residual模块通过给人体区域添加掩膜,进而有效地保留图像中关键人体信息,过滤掉复杂的背景干扰。
1 RF-IA MPEN模型框架
RF-IA MPEN多人姿态估计模型基于自顶向下框架,其包括人体检测网络(Mask R-CNN[15])、对称空间变换网络(SSTN[16])、姿态估计网络(RF-IA HN)、参数化姿态非最大值抑制网络(Parametric Pose NMS)四部分。首先,将污染修复场地中拍摄到的视频图像作为输入,传输到Mask R-CNN网络中对人体进行目标检测,并输出人体检测框。然后利用SSTN网络对人体检测框进行校正,提高其输出精度。RF-IA HN网络对校正后的单人人体检测框进行姿态估计,并利用PP-NMS网络消除冗余姿态。最终输出人体姿态估计结果。RF-IA MREN多人姿态估计模型整体结构如图1所示。
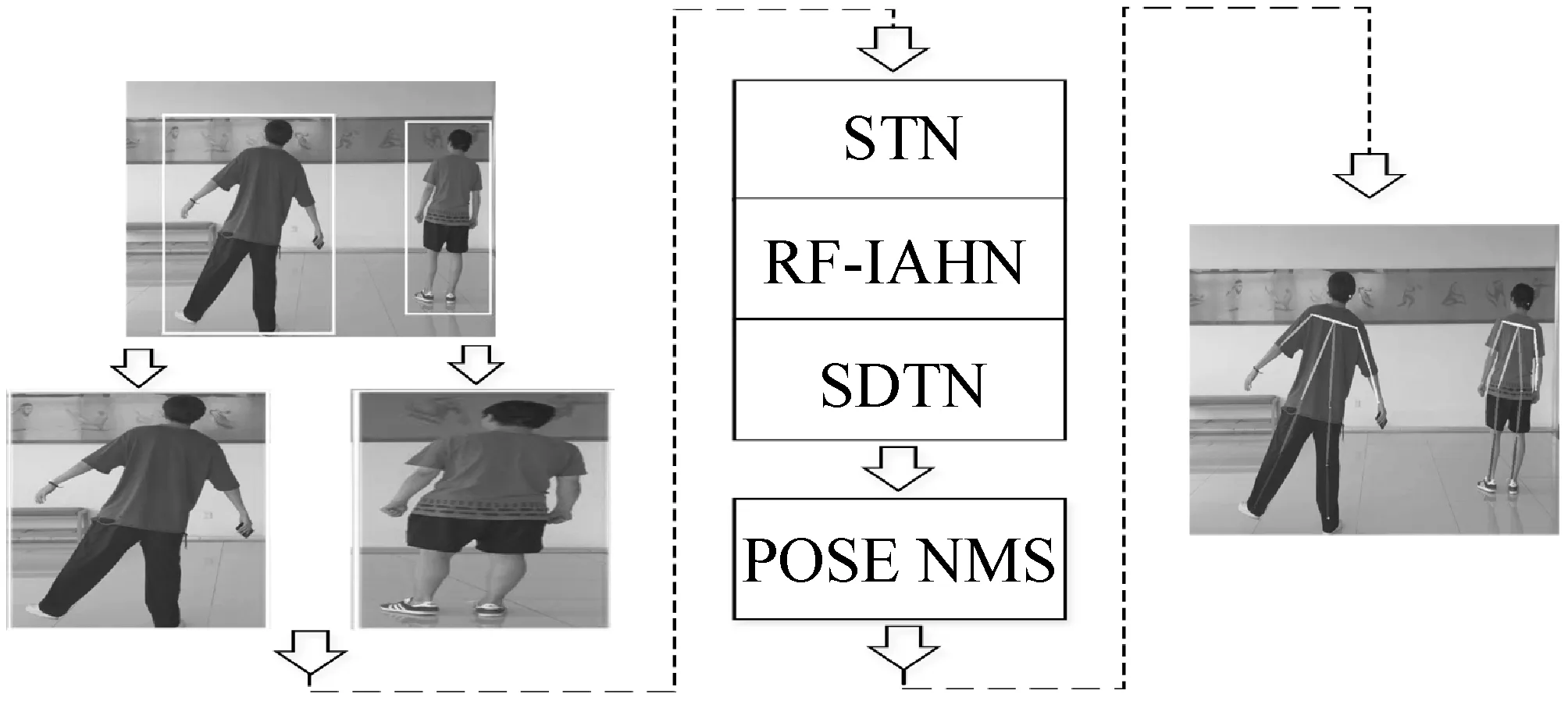
图1 RF-IA MREN多人姿态估计模型结构
2 姿态估计网络(RF-IA HN)
2.1 改进沙漏子网络
姿态估计模型在沙漏网络基础上,对传统残差模块与跳级连接结构进行了改进,改进点为:采用设计出的大感野受残差模块(RF-Residual)和改进型残差注意力模块(IA-Residual)。改进沙漏子网络如图2所示,其由池化层、上采样层、大感野受残差模块和改进型残差注意力模块构成。特征图在经过下采样前,先通过上半路的改进型残差注意力模块保留原尺度信息;然后特征图经过下半路的下采样层降低分辨率后通过大感受野残差模块以获得更大范围内的特征信息;特征图在上采样后与上一尺度信息融合,逐层进行放大融合至输入特征图原尺度。
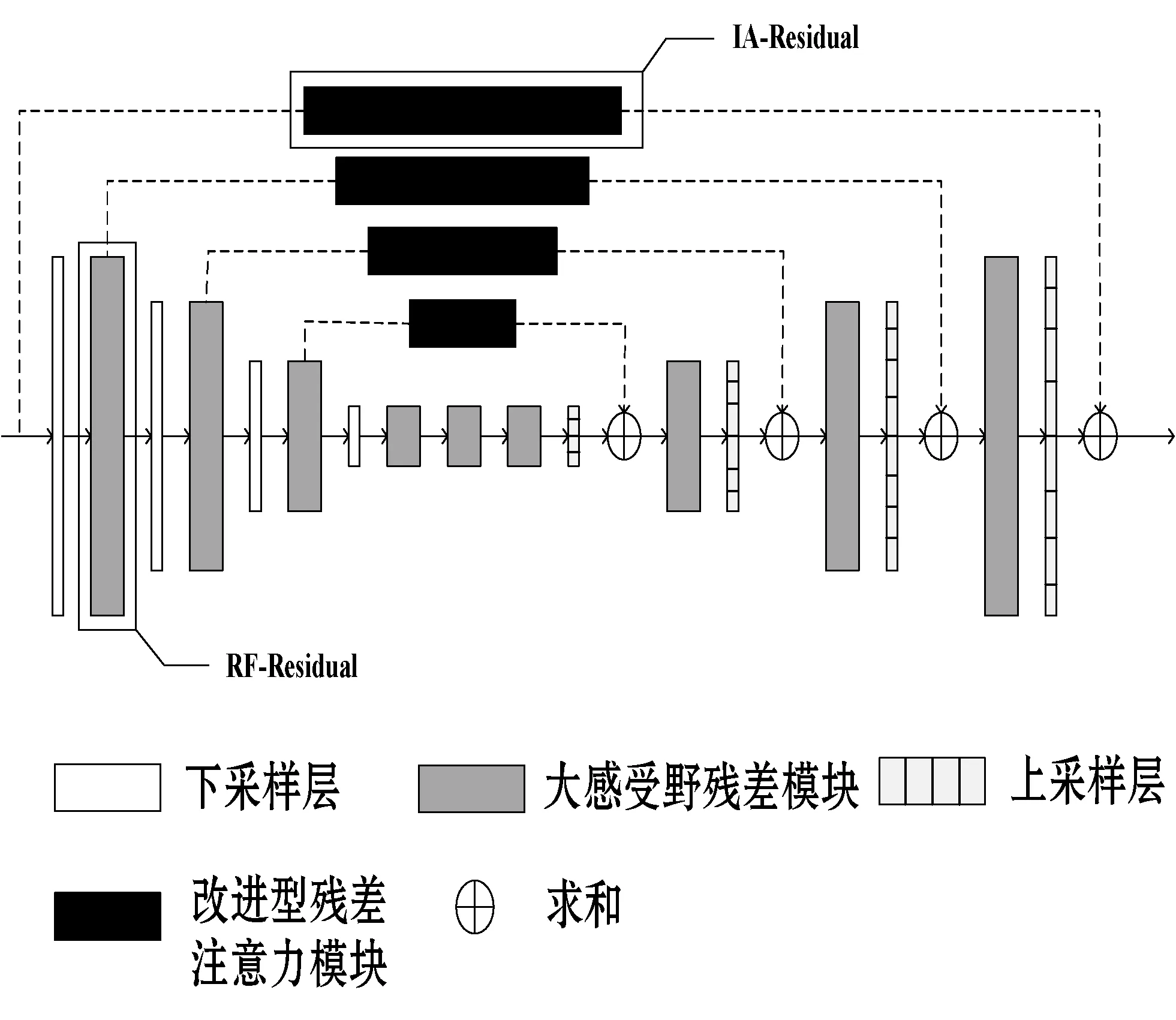
图2 改进沙漏子网络示意图
2.2 大感受野残差模块(RF-Residual)
本文设计出RF-Residual模块,其结构如图3所示,其中:M为卷积层输入端神经元数量;N为卷积层输出端神经元数量;K为Kernel。为解决传统残差模块中恒等映射带来的影响,分支(1)采用归一层、RReLU激活层和1×1卷积,改进原有的恒等映射分支。此种方法的优点是:网络可有效减小恒等映射产生的响应方差,以达到提高网络整体性能的目的。分支(3)为大感受野分支,包含两个3×3卷积层,两个卷积层前都设置了归一化层和激活层。通过分支(3)的加入,输出层感受野可被有效扩大,进而提升关节点之间的关联性,提高检测准确性。
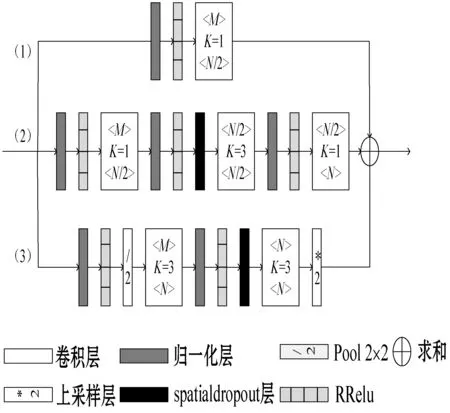
图3 大感受野残差模块结构
在卷积神经网络中,感受野是图像上的一块区域,其由输出特征图上的像素点映射而来。准确定位人体骨骼关键点对有效感受野面积的大小有较高要求。感受野表达式为:
RFi=(RFi+1-1)×Si+Ki
(1)
式中:RFi为第i层卷积层的感受野;RFi+1为第i+1层上的感受野;Si为卷积的步长;Ki为当前层卷积核大小。
本文设计的RF-Residual模块表达式如下:
(2)
式中:pi和Pi+1分别为第i个残差模块的输入和输出;F、Q、W代表分支中卷积、归一化、RReLU激活函数的作用。RF-Residual模块共包含三个分支:
分支(1)为h(pi)。其包含一个1×1卷积层、归一化层、激活层。输出层感受野为1×1。
分支(1)和分支(2)保留了原始残差模块的高分辨率信息,分支(3)扩大了有效感受野。
2.3 改进型残差注意力模块(IA-Residual)
本文设计出IA-Residual模块,其结构如图4所示。IA-Residual模块主要用于检测图像中较为模糊的人体姿态区域,通过给人体区域添加掩膜可以有效地过滤掉复杂的背景干扰。将掩膜之前以及掩膜之后的特征张量全部作为下一层的输入,能够在获得较大感受野的同时更好地注意关键特征,进而有效保留图像中的局部信息,剔除掉复杂的背景干扰。IA-Residual模块包含三个分支,分别为:1×1卷积分支、主干残差分支、柔化掩膜分支。
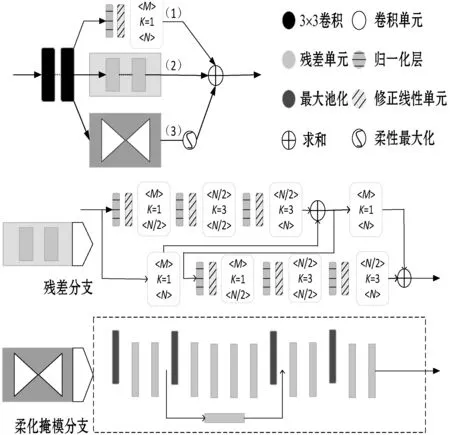
图4 改进型残差注意力模块结构
本文设计的IA-Residual模块表达式如下:
(3)
IA-Residual模块中,分支(1)为h(pi)。其包含一个1×1卷积,卷积前面添加了归一化层和RReLU激活层。
注意力机制数学原理为:
(4)
式中:K、V表示键值对;q为查询向量;s为注意力得分。注意力机制首先是生成总体特征:
δ=f(W⊗α+b)
(5)
式中:δ为总体信息特征;f为非线性激活函数;⊗为卷积操作;W为权重;α为输入;b为偏置。经过柔化掩膜分支的激活函数可以得到人体区域的大致掩膜范围:
(6)
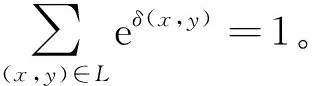
柔化掩膜分支是一个嵌入式的微型堆叠沙漏网络。其先通过多个最大池化层,经过少量残差单元后快速增加感受野。当特征图降到最低分辨率后,便能获得整幅图像的全局信息。随后通过对称的网络结构将特征放大回去,即在残差单元后使用与最大池化数量一致的线性插值,保证获得的掩膜区域还原为原图像大小。柔化掩膜分支能够集中注意力于图像关键信息,有效地屏蔽掉复杂背景的干扰,提高整体网络的准确性与鲁棒性。
3 实 验
本文通过多组对比实验与消融实验,对提出的多人姿态估计模型(RF-IA MPEN)的有效性及实用性进行验证。实验环境如下:操作系统为Ubuntu 16.04,CPU环境为2×Intel Xeon Gold5120 CPU,GPU环境为8×32 GB V100 SXM2 NVLINK GPU。多人姿态估计模型将基于PyTorch深度学习框架,在MPII数据集[17]和MSCOCO数据集[18]中进行验证。
3.1 评估数据集
MPII Human Pose多人数据集通过输出人体的头、肩膀、肘、手腕、髋关节、膝盖、脚踝这七个部位的识别准确度来评估模型。数据集由3 844个训练组和1 758个测试组组成,测试组中存在遮挡重叠的人体样本。本文使用单人数据集中的全部训练数据和90%的多人训练集来训练模型,剩下10%用以验证。
MSCOCO数据集包含超过33万幅图片和150万人体实例,训练集包含超过100万个标记的关键点。本文在MSCOCO Keypoints的训练集与验证集的合并集上对模型进行训练,用5 000幅图像进行验证。
3.2 对比实验
本文在相同的硬件环境下进行了多组对比实验,以更直观地展示本文方法的性能。训练过程采用Adam优化算法,初始学习率为1E- 3,降低学习率因子为0.1,沙漏子网络个数为4。模型在MSCOCO2017 Test-dev数据集上的评估结果如表1所示(其中精度指标AP右上角数字为IoU阈值)。
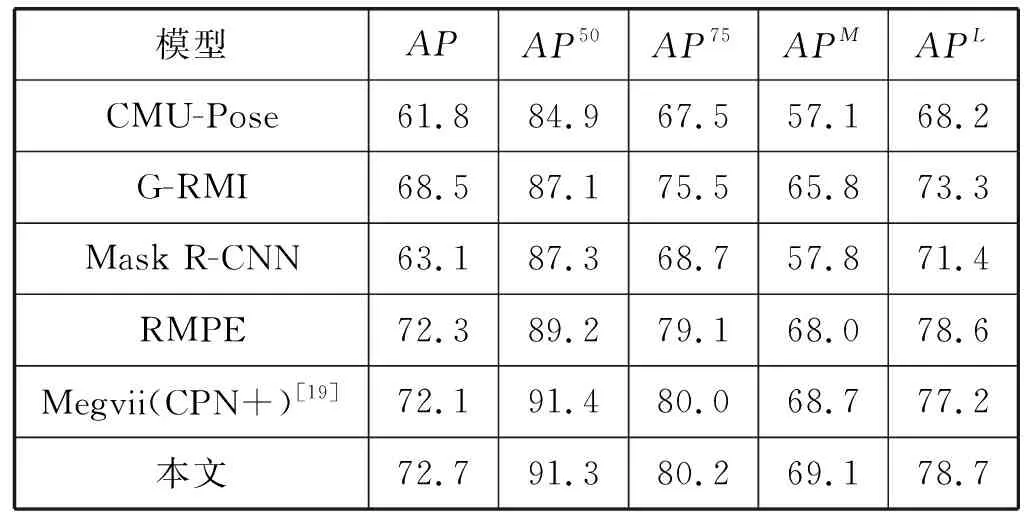
表1 MSCOCO2017 Test-dev数据集评估结果(%)
RF-IA MPEN模型在MSCOCO关键点测试集上取得了较好的结果,平均精度较Mask R-CNN模型提升了9.6百分点,较RMPE模型提升了0.4百分点。同时,模型在处理一些背景遮挡、人群密集等情况时取得了较好效果。在MSCOCO数据集上的部分可视化结果展示在图5中;在实际污染修复场地中的部分检测结果展示在图6中。

图5 在MSCOCO数据集上的可视化结果

图6 在实际污染修复场地中的可视化结果
3.3 消融实验
本文设计了三组消融实验,评估大感受野残差模块(RF-Residual)和改进型残差注意力模块(IA-Residual)的有效性。首先测试了移除这两个模块的传统堆叠沙漏网络框架的效果;其次测试了分别移除其中一个模块的改进堆叠沙漏网络框架的效果。消融实验在MPII数据集上进行验证,实验结果如表2所示。
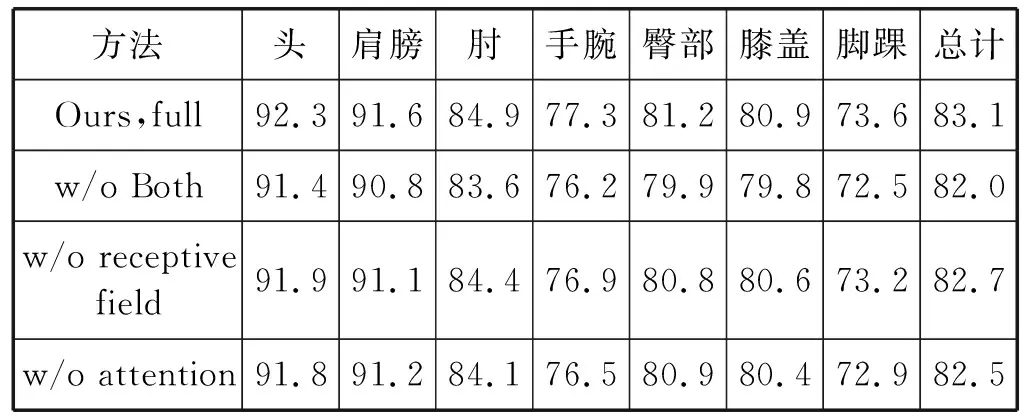
表2 消融实验结果对比(%)
表2中,“Ours,full”表示RF-Residual模块与IA-Residual模块均被采用;“w/o X”表示从模型中移除X模块。
3.4 实验分析
通过消融实验结果可以看出:当移除RF-Residual模块,仅采用IA-Residual模块取代沙漏网络原有跳级连接结构时,模型性能结果下降了0.4百分点,相较传统堆叠沙漏网络模型结果提升了0.7百分点。实验结果说明柔化掩膜分支有效屏蔽掉复杂背景的干扰,集中注意力于图像关键信息,提高了检测精度。当移除IA-Residual模块,仅采用RF-Residual模块取代沙漏网络传统残差模块时,模型性能结果下降了0.6百分点,相较传统堆叠沙漏网络模型结果提升了0.5百分点。说明RF-Residual模块有效增大了有效感受野面积,进而提高了局部人体部件和关节的检测精度。实验结果从两个角度验证了RF-Residual模块和IA-Residual模块的有效性。
4 结 语
本文建立了基于大感受野与注意力机制的多人姿态估计模型,通过扩大有效感受野面积,提高人体关键点之间的关联性,更加有效地利用了图像中的多尺度信息;通过对人体区域添加掩模,在有效保留关键人体信息的同时,过滤掉复杂背景,提高整体网络的准确性与鲁棒性。一定程度上解决了污染场地修复环境中背景复杂、人体遮挡、视点变化等突出问题。实验表明,本文算法结果在MPII多人数据集上mAP检测精度达到83.1%,在MSCOCO Test-dev数据集上平均精度较Mask R-CNN、RMPE模型分别提升了9.6百分点和0.4百分点。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
人工晶体学报(2021年3期)2021-04-17
学生天地(2019年28期)2019-08-25
数学大王·低年级(2018年3期)2018-03-27
数学物理学报(2018年1期)2018-03-26
制造技术与机床(2017年10期)2017-11-28
儿童故事画报·自然探秘(2017年2期)2017-09-26
儿童故事画报·自然探秘(2017年1期)2017-06-12
青年歌声(2017年12期)2017-03-15
液晶与显示(2014年4期)2014-02-02
