
分布式气象大数据快显技术的设计与实现
2023-03-15 08:46雷鸣
计算机应用与软件 2023年2期
雷 鸣
(天津市气象信息中心 天津 300074)
0 引 言
随着气象业务高速扩展,数据的种类与数据量不断增长。而与此同时,针对气象数据的服务性能和响应速度的要求却越来越高。但目前省级全国综合气象信息共享系统(CIMISS),却是2009年由国家气象信息中心负责组织建设,集数据收集、分发、处理、存储和共享于一体。2013年,该系统推广部署在全国各省级气象数据中心,并获得良好应用。但随着设备老化和技术的落后,目前其数据处理能力已经明显无法满足要求[1-3]。但省级部门却无权针对该系统进行改造。
为了进一步提升气象数据服务的敏捷性和存储动态扩展的需求。同时又能够与CIMISS进行无缝衔接,在充分参考相关行业在解决海量数据查询的成功方案基础上[4-8],利用分布式技术[9-11],构建满足省级特色需求的数据服务中心。同时,利用CIMISS的气象数据统一服务MUSIC接口(Meteorological Unified Service Interface Community)[12-14],打通多系统之间的壁垒,屏蔽异构环境,提供统一的对外数据服务功能。
1 系统架构设计
通过引入系统面向的四类用户,结合整个平台进行管理和监控运行监管体系和平台建设,并遵循气象信息标准化体系规范,针对系统的六个层次分别进行了细化与分析,其具体技术架构如图1所示。
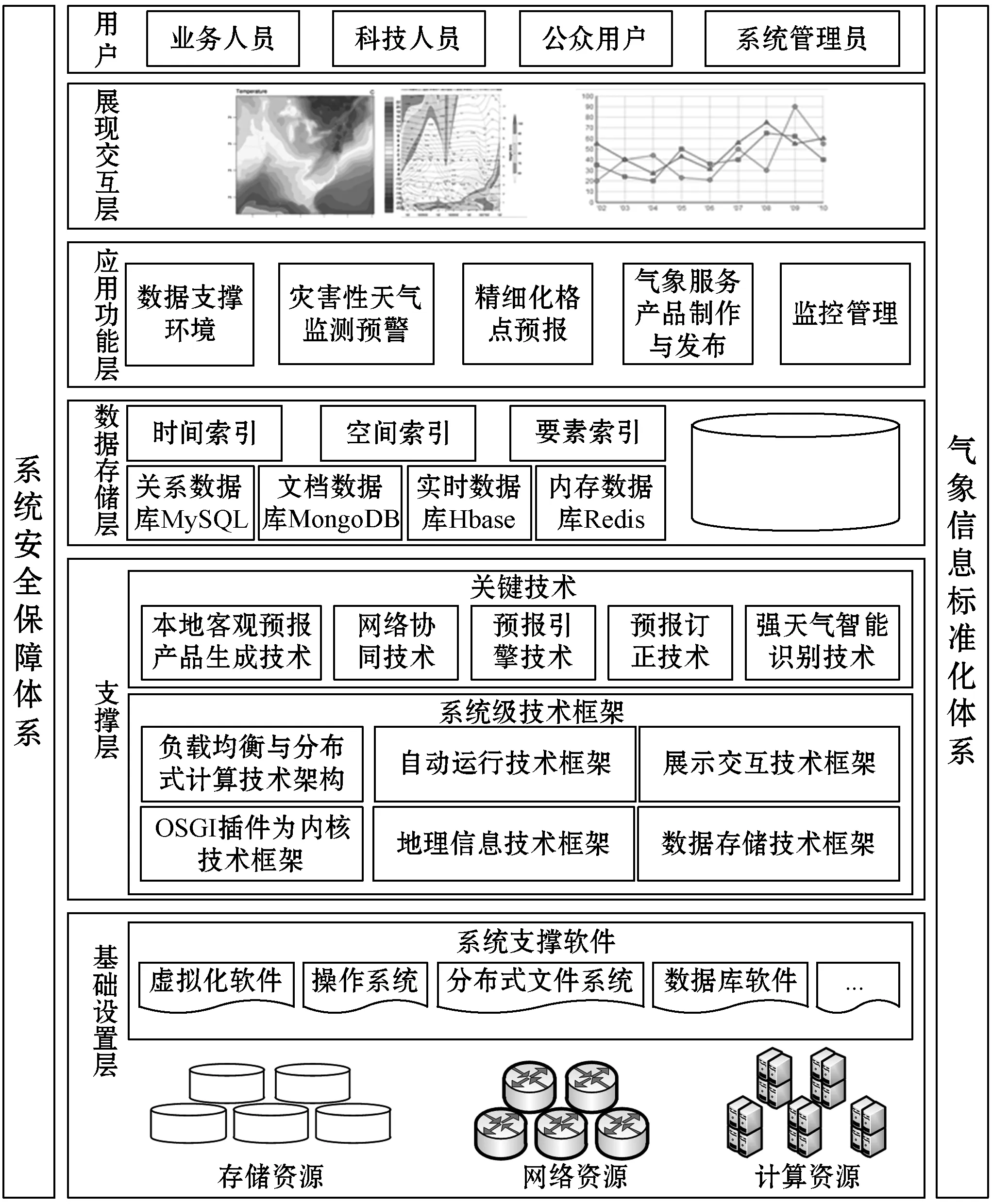
图1 系统总体框架设计
天津省级数据服务中心的总体设计机构共分为5层:展现交互层、应用功能层、数据存储层、基础支撑层与硬件层。
展现交互层:该层是天津气象大数据共享平台软件进行交互的入口,该层主要负责接收用户提交的输入请求,通过后端的接口层对业务逻辑层进行访问,从而获得、并向用户输出可视化响应。
应用功能层:应用功能层则负责接收前端用户的输入请求,并以业务逻辑过程能够理解的方式将其转化。同时,根据特定的业务逻辑向数据层有序地发送数据请求,并将返回的数据层数据进行解释和组合,形成用户所需的信息,最终再返回到展现交互层。这一层在整个应用软件系统里,是业务逻辑处理与实现的核心。
应用功能层采用基于组件化架构思想进行设计,即将天津气象大数据共享平台软件的业务功能单元封装成各个相对独立又互相联系的功能组件,通过支撑层的调度控制,各功能组件相互配合,协作完成系统的各项任务。
数据存储层:该层针对气象数据进行管理,并向应用服务层提供开放式访问的标准化接口。该层负责提供访问位于持久化容器中数据的功能,以及涉及从持久化介质中写入数据或者读取数据的工作。
基于HBase存储半结构化混合数据,基于MySQL存储结构化观测和预报资料,基于MongoDB存储非结构化数据,数据存储层为系统提供对缓存进行管理的功能,在此基础上,分别对数据库和文件库的进行统一的接口封装,为应用功能层提供统一基于时间索引、空间索引和要素索引的大数据SQL查询器。
天津气象大数据共享平台软件为加快上层访问数据存储层数据/文件的访问速度,在数据库与文件库物理存储基础上使用缓存机制。
支撑层:支撑层描述了实现天津气象大数据共享平台软件所使用的技术框架和所采用的关键技术,为应用功能层各个业务组件、功能模块起到支撑与组织的作用。支持层包括两部分:系统级技术框架及关键技术。
系统级技术框架描述支撑整个系统应用功能所使用技术架构,主要包括:展示交互技术框架、自动运行技术框架、地理信息技术框架、OSGI插件微内核技术框架、负载均衡与分布式计算框架和数据存储技术框架。
关键技术指构建系统级技术框架中所采用的技术,主要包括本地客观预报产品生成技术、网络协同技术等。
2 可扩展性设计决策
为更好适应未来气象预报业务发展,系统需具有可扩展性与开放性。可扩展性具体表现为业务可扩展性,可动态加载气象预报业务算法。
对业务扩展性需求,采用的设计决策是:将具体的算法封装成动态链接库,与具体的业务逻辑相分离,算法可替换,参数可配置,业务流程可配置。业务流程配置如图2所示。
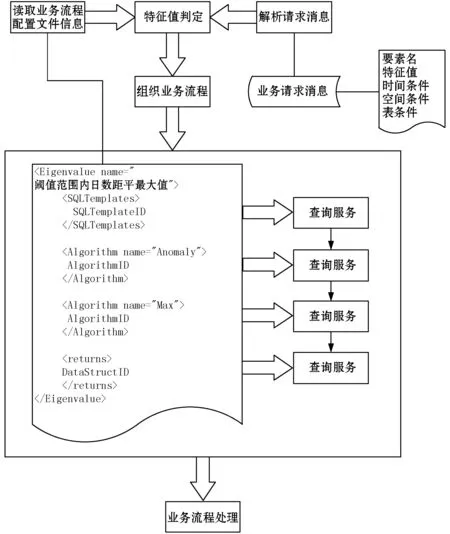
图2 业务流程配置示意说明
针对系统的扩展性需求,采用设计决策是:业务逻辑及公共服务层与展示层之间功能分离,模块之间松耦合,分别部署在不同的物理节点,可重用业务逻辑及公共服务层。
3 系统存储设计
3.1 系统存储架构设计
为了做到数据与应用分离,使用户对后台变动无感。基于MUSIC服务接口,将全部数据库打通,形成一个逻辑上统一的数据服务中心,对外透过API接口提供服务。整个存储设计架构如图3所示。
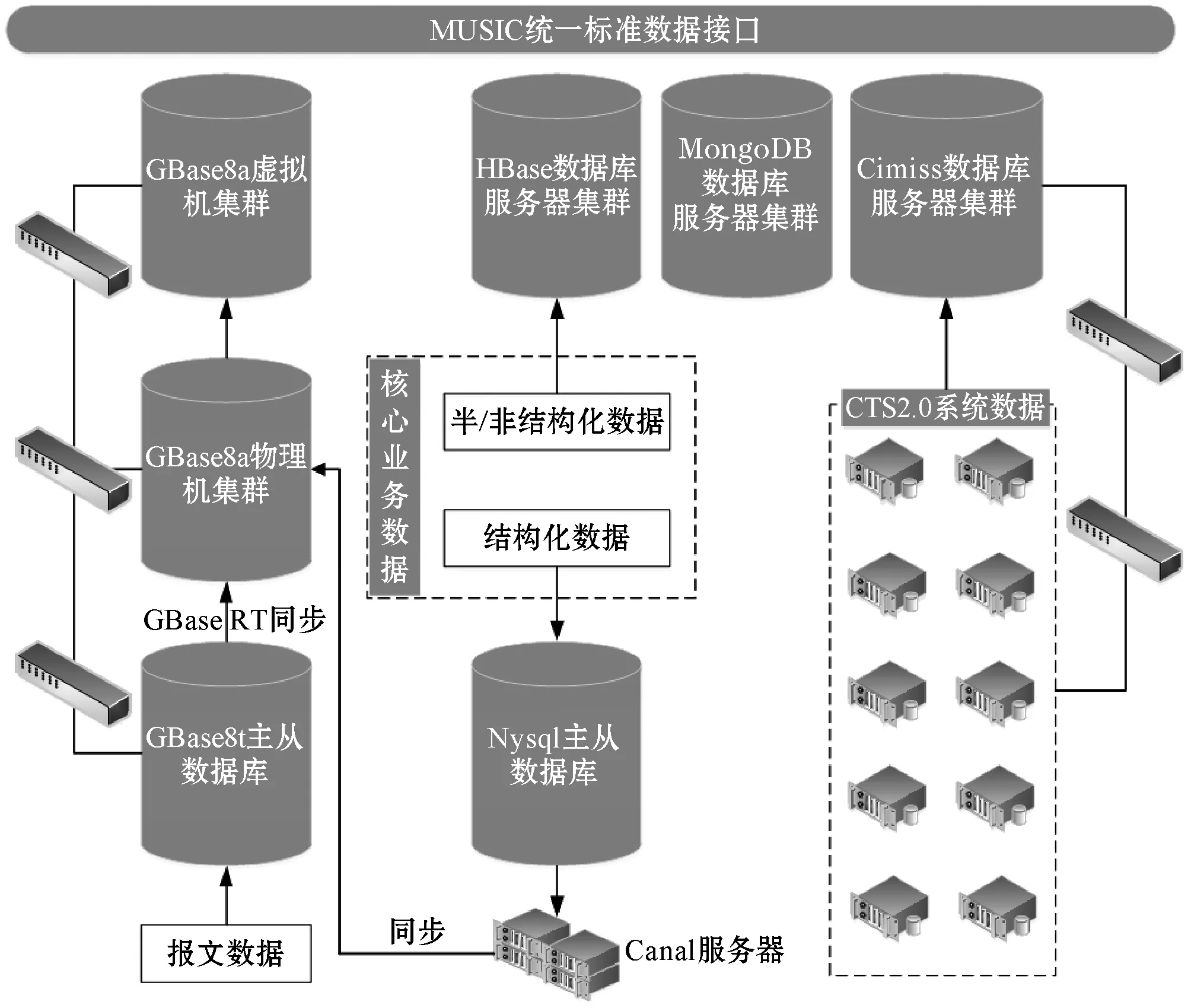
图3 系统存储架构设计图
3.2 数据库存储配置
系统涉及到多种数据库,如MySQL、MongeDB、HBase等。为进一步提升系统响应速度,特别针对各数据库分别进行了优化处理。限于篇幅,仅以MySQL优化为例:
MySQL提供了一些存储分配参数,例如:数据库的大小、锁的数目,以及使用的缓冲区大小等。但这些分配参数的默认值不能达到天津省级数据服务中心的功能需求。为进一步优化数据库性能,根据天津省级数据服务中心的特点,针对系统的配置参数进行了如下调整:
[mysqld]
server-id=115
basedir=/mysqldata
datadir=/mysqldata/data
log-bin=mysql-bin
log-bin-index=mysql-bin.index
sync-binlog=1
max-binlog-size=200M
expire_logs_day=3
skip-host-cache
skip-name-resolve
innodb_buffer_pool_size=40G
innodb_log_buffer_size=32M
max_connections=1000
event_scheduler=ON
4 并行加速算法
为了进一步提升数据服务的速度,尤其是涉及到图形渲染等高密度计算场景时,本文利用并行计算技术进行数据显示增速[15],如:针对格点数据等值线提取、色斑渲染等功能。天津省级数据服务中心所使用的WebGIS以及其他需要渲染计算等方面,均采用了并行运算。其具体策略为:结合OpenMP的CPU并行计算以及基于OpenCL的GPU并行计算技术,将其应用与气象格点数据计算处理和气象信息图形显示分析中,提高基于WeBGL地图渲染的执行效率和运算速度。
4.1 基于OpenMP的CPU并行算法
CPU并行框架底层基于OpenMP编程框架,透过使用计算机的多线程多核处理机制,提供了对CPU并行算法的高层抽象描述,以及线程粒度的控制和负载均衡,具体工作流程如图4所示。
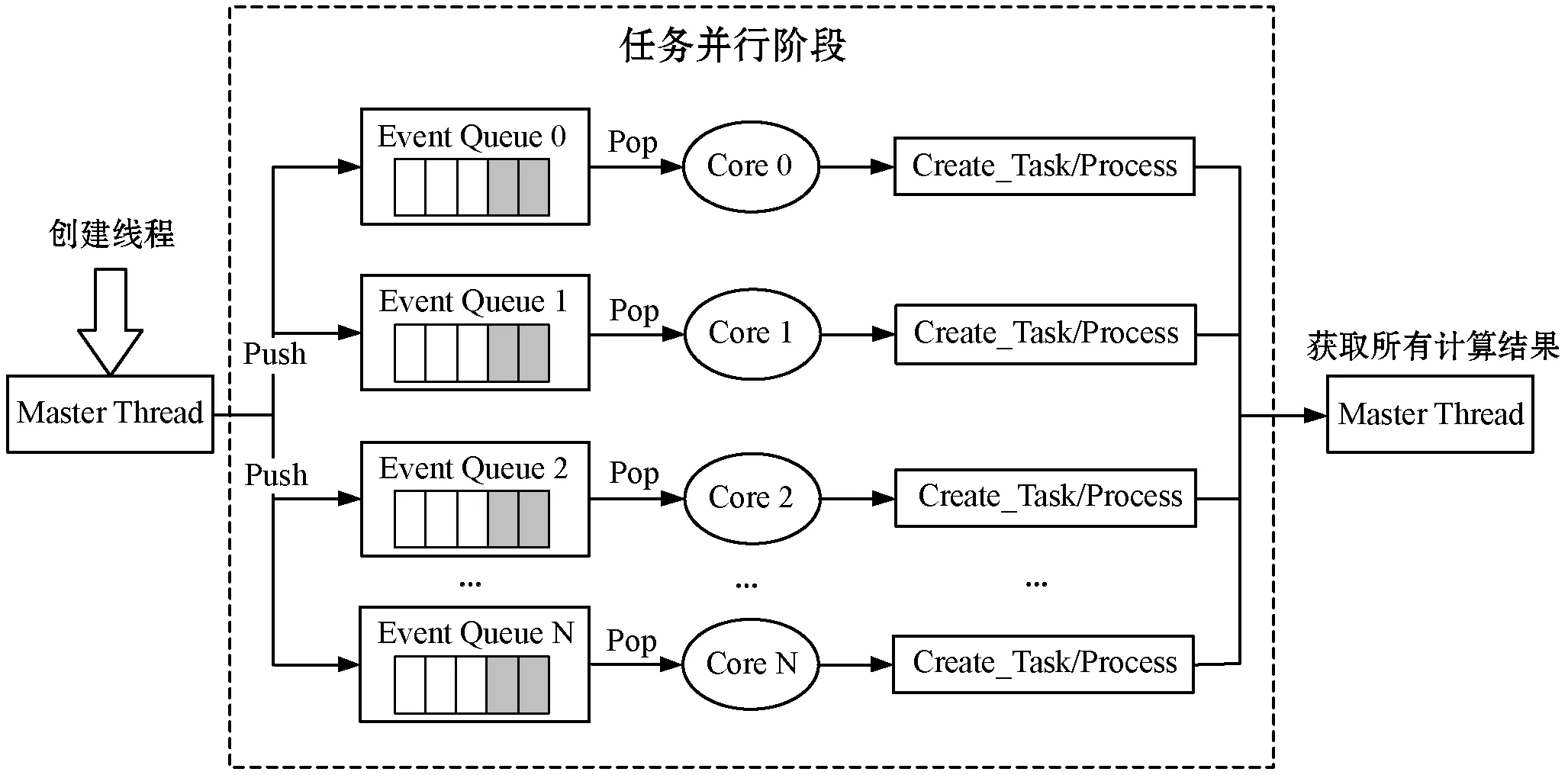
图4 并行计算工作流程示意图
OpenMP的算法设计基于如下阿姆达尔定律的最小化串行代码原则进行:
(1)
式中:a是并行计算部分占用的比例大小,n则是并行处理部分的结点个数,即处理器个数。可以看到,当没有串行,而仅有并行,即1-a=0时,最大加速比S=n;而当仅有串行,并不存在并行,即a=0时,其最小加速比S=1;最大加速比的上限发生在n→∞时,此时,极限加速比S→1/(1-a)。为了使速度最大化,在并行处理节点个数固定的情况下,应尽可能地提升并行计算部分所占的比例。
OpenMP中的执行模型采用的是fork-join,其中,fork的含义表示唤醒已有线程或者创建线程,而join则代表了多线程的会合。当Fork-join执行模型最初执行时,它仅有一个在运行的线程:即“主线程”(Master Thread)。而当需进行并行计算时,系统则会由主线程派生出新线程来执行并行任务。而此时,主线程与派生线程将会在并行执行阶段一同协同工作。当并行运算完结之后,派生线程会自动阻塞或退出,而不再继续执行,控制流程将会回到单独的主线程中。当系统涉及高密度数据计算的时候,如:数据渲染和数据时间插值等操作,计算将会由CPU转到GPU中进行处理。
4.2 基于OpenCL的GPU并行算法
GPU并行计算基于开放运算语言(Open Computing Language,OpenCL),利用GPU强大的浮点数计算能力,辅助CPU完成大规模的并行计算任务。OpenCL可运行在多种不同的平台之上(Windows、Linux、Unix等),通过对不同平台底层的抽象与封装,屏蔽了相异平台底层的不同设计,并对应用层提供了统一的接口服务。
而GPU渲染常采用构建三角形带和LOD(多细节层次)技术[16]以减少GPU固有的渲染数据量,则其渲染的数据量公式如下:
(2)
式中:m则是场景模型的总数;ky是Ny缩减的比例;Ny则是单个模型在场景中的总顶点数;x是反射次数;kb是在并行架构下顶点的冗余度系数(在2-3之间);kf是材质种类所固有的反射系数;I是平均光强值;n是场景光源的个数。
设ty为同一线程块处理面片集合的平均时间,Ab为同一批次处理的渲染数据量,T为处理渲染数据消耗的总时间,则有:
(3)
整体OpenCL并行计算框架的架构设计由设备、上下文环境、程序、内核、内存对象、命令队列六个部分组成,具体组成如图5所示。
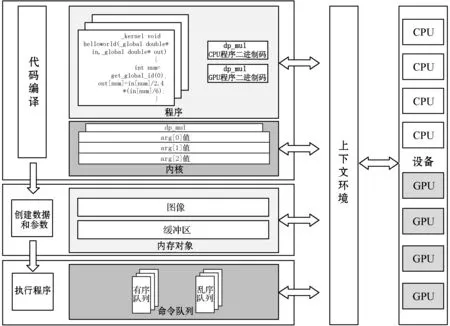
图5 并行计算系统流程图
设备:它是并行计算框架中的计算单元,一个GPU或者CPU将会对应一个设备。而设备通过命令队列,获取自己需要执行的计算指令。
上下文环境:上下文是一个抽象的容器,是整个并行计算框架的纽带,上下文环境管理在设备上的列中的有序队列与无序队列。只有在一个上下文环境上的系统的设备才能彼此交流工作。
程序:这是所有代码的集合,包含核函数和其他库。OpenCl是一个动态编译的语言,代码编译后生成一个中间文件(可根据需要实现为虚拟机代码或者汇编代码),在使用时连接进入程序读入处理器。
内核:这是在设备上运行的核函数及其参数组。为了进一步提升计算速度,在其中特别使用了单指令多数据流技术。这是一种采用一个控制器来控制多个处理器,同时对一组数据(又称“数据矢量”)里面的每一个各自进行相同操作,从而达到空间上并行性的技术。
内存对象:包括图像和缓冲区,并行计算需要在不同设备上使用的内存,内存对象由上下文创建,从而实现上下文管理的多个设备,能够将内存对象中的数据进行共享。
命令队列:这是上下文环境给每个设备提交的指令序列,通过命令队列,上下文环境将需要执行的指令,发送到每个设备上。在顺序执行命令队列里(默认),命令将会按照接收的顺序压入到命令队列中。乱序队列允许OpenCL在实现时重排命令以便高效地执行。如果使用乱序队列,须指定依赖关系以确保正确地执行顺序。
OpenCl执行分为三个阶段,第一个阶段进行代码编译,创建上下文环境以及命令队列,生成内核与程序,并完成设备的初始化;第二个阶段创建参数和数据,上下文环境创建内存对象,并将计算需要使用的数据写入其中;第三个阶段上下文环境将需要执行的计算指令发送到命令队列中,并等待设备计算完成。设备计算完成之后,上下文环境读取内核对象处理的结果(存放在内存对象中),并释放资源。
5 实践与测试
为大数据分布式存储数据中心的数据服务能力,特别对其进行了综合测试。测试使用的硬件配置为:CPU i5- 3470 3.20 GHz,内存4 GB,支持谷歌内核的主流浏览器,如Chrome。获得的系统测试指标如表1、表2所示。

表1 基于WebGIS的自动站显示指标
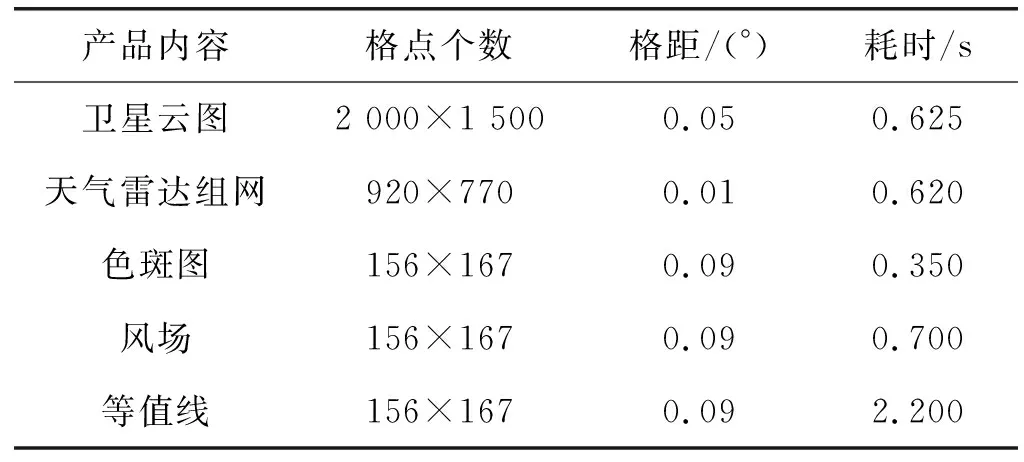
表2 基于WebGIS的数据渲染显示指标
为了进一步获得系统的查询性能,特别针对页面响应速度进行了测试,获得如表3所示的各项数据查询结果。
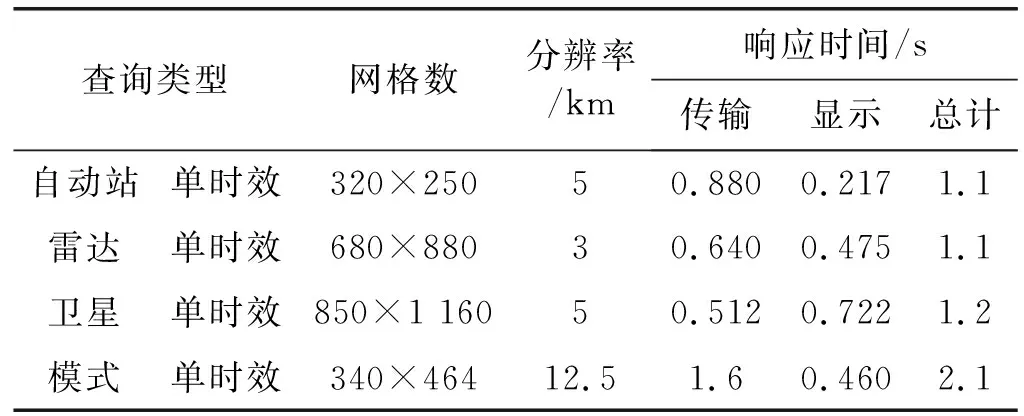
表3 页面查询响应速度表
其中,查询类型为常规产品中的典型查询项目,而响应时间中的显示则为第1次的显示耗时。页面的响应速度比基于CIMISS的速度平均提升了860%。下面展示了几类不同的查询显示效果图。
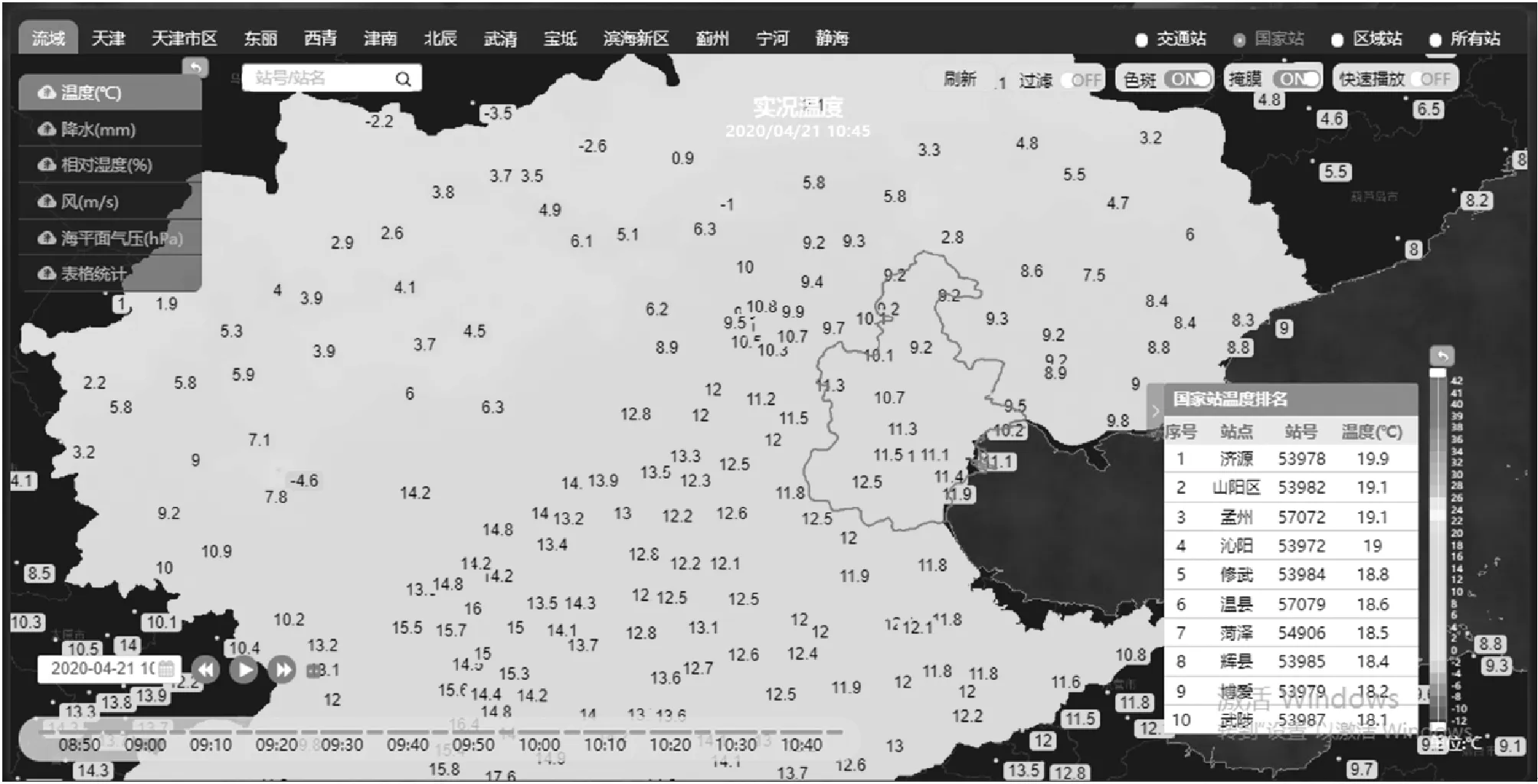
图6 自动站实况温度查询效果图

图7 EC集合统计量:24小时降水
6 结 语
本文在不改变现有业务系统和系统架构的基础上,基于MUSIC接口,利用分布式和并行计算技术构建了满足省局气象需求的大数据环境中心,提高了气象数据显示分析过程中各种复杂的气象算法运算的效率,并对系统中整个业务流程执行效率和图形显示分析的人机交互体验也有较大的提升,为气象数据的高质量服务,提供了一个可行的解决方案。
猜你喜欢
高技术通讯(2021年5期)2021-07-16
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
网络安全技术与应用(2020年1期)2020-01-07
当代陕西(2019年13期)2019-08-20
军营文化天地(2018年2期)2018-12-15
产品可靠性报告(2017年7期)2017-09-05
环球市场(2017年36期)2017-03-09
计算机与网络(2014年6期)2014-05-25
测绘科学与工程(2014年5期)2014-02-27
