
改进YOLOv4的安全帽佩戴检测方法
2023-03-15 08:47李浩方李孟洲马军强
计算机应用与软件 2023年2期
张 震 李浩方 李孟洲 马军强
(郑州大学电气工程学院 河南 郑州 450001)
0 引 言
“十三五”时期,我国仍处于新型工业化、城镇化持续推进的过程中,安全生产工作面临许多挑战。特别是在建筑、电力、矿山等行业的施工过程中,因为违章施工而导致事故频发。一方面存在企业主体责任不落实、监管环节有漏洞、执法监督不到位、规范施工安全体系不完善等;另一方面存在施工一线的操作人员安全意识和操作技能较差等因素。安全帽是个体防护装备中的头部防护装备,在施工过程中佩戴安全帽是有效保护一线施工人员头部的有效防护性措施,可以减少因意外事故导致的头部损伤。因此,在需要佩戴安全帽的施工现场中,采用视频监控手段替代人工检测是否佩戴安全帽,不仅可以减少人工成本,同时在一定程度上保证一线施工人员的生命安全。
随着深度学习的广泛运用,目标检测在智能监控系统中的快速发展,通过计算机视觉减少人力资本的消耗在安全施工中有着较好的发展前景。目前,不需要使用区域选取直接获取物体的类别概率和物体坐标位置方法有着快速的发展,典型检测算法有YOLO[1]、SSD[2]和CornerNet[3]等,这类算法优点在于在保证精度的前提下,有着较高的检测速度,可以满足视频监控检测实时性的要求。
综合考虑,本文针对安全帽佩戴提出如下检测算法:首先采用K-means聚类算法针对本文自制佩戴安全帽数据集获取适合本文算法的先验框;然后在YOLOv4[4]网络增加通道注意力和空间注意力整合的Attention Block模块,增强网络内的信息流动;接着采用CIoU[4]边界回归损失函数作为新的边界回归损失函数;最后采用多候选框学习策略减少漏检的概率。实验表明,改进后的方法在视频监控下满足安全帽佩戴检测的准确性和实时性。
1 YOLOv4原理
1.1 特征提取网络CSPDarkNet53
YOLOv4使用新的特征提取网络CSPDarkNet53代替YOLOv3[5]中采用的darknet53特征提取网络。新的特征提取网络首先借鉴CSPNet[6](Cross Stage Partial Network)网络结构,将梯度变化整合到特征图中,增强卷积网络的学习能力,在保证检测准确率的同时降低计算量,减少运算过程中内存消耗。其次,特征提取网络结构中采用平滑的Mish[7]激活函数替换原有leaky-ReLU[8]激活函数,提高信息在网络中传播的准确性。最后,特征提取网络采用了DropBlock[9]正则化方法,该方法在训练的不同阶段灵活修改删减特征图中连续区域的概率,加强网络对重要特征的学习能力。特征提取网络CSPDarkNet53网络结构如图1所示。
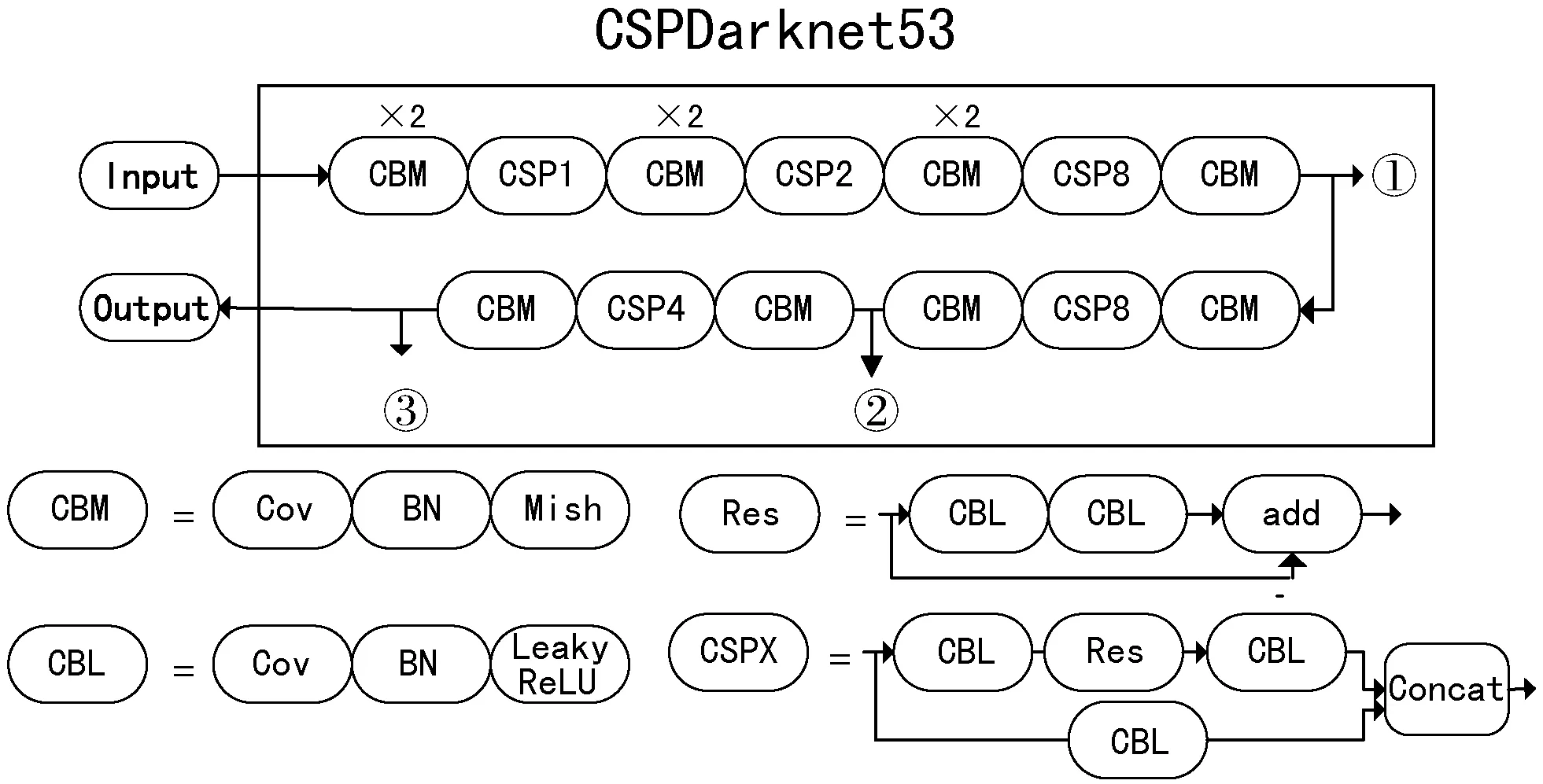
图1 CSPDarkNet53网络结构
1.2 YOLOv4网络结构改进
在网络结构改进方面,YOLOv4网络结构首先在骨干网络和输出层中引入了SPP[10](Spatial Pyramid Pooling)模块。该模块可以将输入不同尺寸大小的图像转化为固定大小输出,且与特定的网络结构相对独立,因此采用SPP模块既能提升感受视野,提高尺度不变形,还可以降低过拟合现象。其次,借鉴路径聚合网络PANet[11](Path Aggregation Network)中采用从下向上的路径增强策略,缩短信息传播的路径,充分利用底层特征的位置信息,实现与FPN[12](Feature Pyramid Networks)自上而下的特征信息聚合,提升小目标的检测效果。
在数据处理方面,YOLOv4引入马赛克[4]与自对抗训练SAT(Self-adversarial-training)方式对数据集进行扩展。马赛克数据增强采用增加一定训练时间,将四幅图片合为一幅,通过长宽随机变化产生新的数据,其优点在于增加检测物体的背景。自对抗训练在反向传播中改变图像中的信息但不改变网络中参数,并且改变后的图片可以正常进行目标检测。两种方式结合能有效提升模型泛化能力。
2 改进分析
对于安全帽佩戴检测,本文结合现有YOLOv4网络模型,通过增加通道注意力和空间注意力整合的Attention Block模块,选择CIoU边界回归损失函数,采用多候选框学习策略[13]和先验框K-means聚类算法,提升安全帽佩戴检测效果。
2.1 引入注意力机制
目标检测中引入注意力机制可以聚焦安全帽的重要特征,同时抑制和忽略同行背景中不必要的其他特征信息。由于Woo等[14]提出同时采用通道注意力和空间注意力卷积模块方法CBAM(Convolutional Block Attention Modul)能有效提升网络性能,所以本文将通道注意力和空间注意力整合后的Attention Block模块增加到YOLOv4网络中,提升安全帽佩戴检测的准确率。
注意力模块主要由通道注意力模块和空间注意力模块构成。通道注意力模块对输入维度为C×1×1的特征图,C为通道数,通过使用全局平均池化和全局最大池化对输入特征图像的所有特征值进行计算压缩。然后使用1×1的卷积降低网络维度,利用ReLU激活函数学习特征之间的非线性关系,再用1×1的卷积重新构建计算压缩前的维度。最后输出的维度与前面全局平均池化和全局最大池化计算的权值通过Sigmoid运算得到归一化的权值,生成新特征图像的特征值。通道注意力模块得到的特征图能有效地向下传播,其模块构成如图2(a)所示。
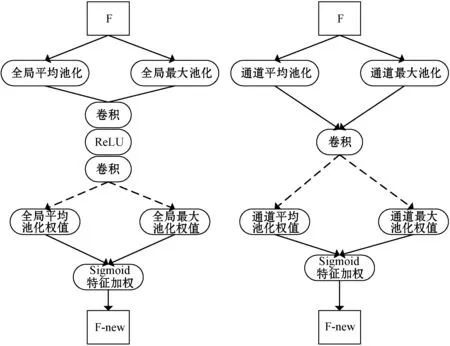
(a) 通道注意力构成(b) 空间注意力构成图2 注意力机构结构
空间注意力模块主要是获取特征图中特征信息的位置信息。空间注意力模块首先将输入尺寸为W×H×C的特征图通过通道平均池化和通道最大池化突出新的特征信息得到新的特征图,W×H为原始图像压缩后的尺寸。然后经过一个卷积层后得到一个通道为1的特征图,卷积层中卷积核大小为7×7,padding为3。最后通过Sigmoid函数将加权后的空间注意力特征与输入特征图相乘,得到增加空间注意力的特征图。其模块构成如图2(b)所示,其中:F代表输入特征图;F-new为更新特征图。
本文将通道注意力和空间注意力整合为一个Attention Block模块,并与CSPDarknet53特征提取网络中卷积层第54层、85层和104层相连接,其中卷积54册、85层和104层分别对应图1中①、②、③三个位置,增加Attention Block模块后对应大、中、小三个尺寸的融合特征图。三个不同尺寸的特征图通过FPN和PANet网络结构实现对特征图的上采样和下采样的缩放操作,使尺寸相同的特征图相互融合。融合后的三个尺寸特征图通过大、中、小三个YOLO层,进行安全帽佩戴检测的识别。增加Attention Block模块后的网络如图3所示。
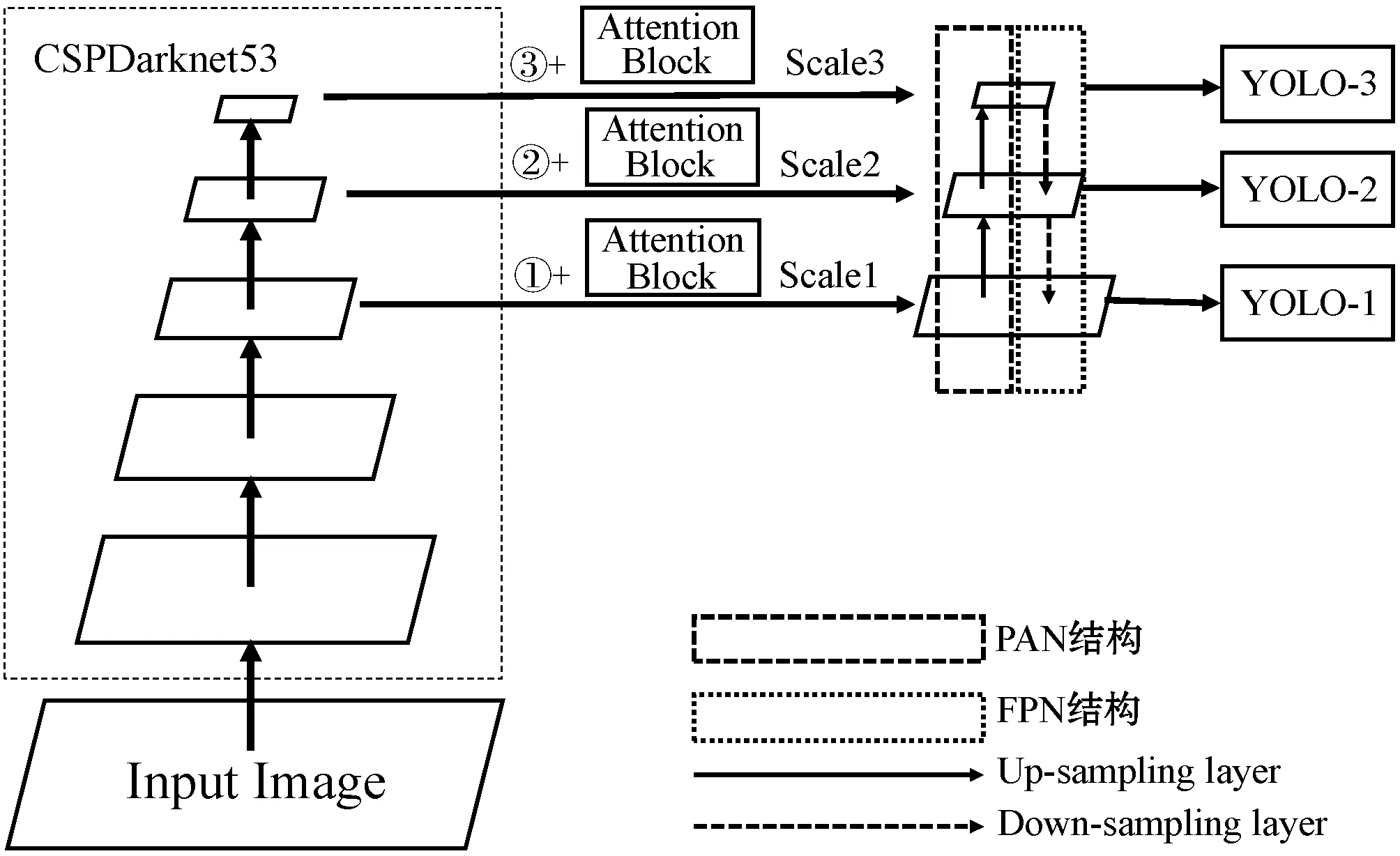
图3 改进网络结构
2.2 边界框回归损失函数选择
目前,边界框回归损失函数经常采用交并比IoU[15](Intersection-over-Union)来评价目标检测算法的检测效果。其计算公式如式(1)所示。
(1)
式中:A表示真实标定框;B表示预测候选框。
但在实际训练中发现,当遇到预测框与真实框不相交时,根据IoU定义此时损失为零,无法进行训练,因此为解决边界框不重合时的问题,而Rezatofighi等在IoU的基础上提出的GIoU损失函数不仅能解决重合区和非重合区域的重合度信息,还能维持IoU的尺度不敏感特性。GIoU[16]计算公式如式(2)所示。
(2)
式中:C为包含A与B的最小框。但是IoU和GIoU没有考虑到真实标定框与预测候选框中心的距离信息和长宽比信息,因此Zheng等[17]提出了两种边界框损失函数DIoU和CIoU。其中:DIoU损失函数考虑边界框的重叠面积和中心点距离;而CIOU损失函数在DIoU损失函数的基础上增加真实标定框和预测候选框的长宽比一致性的衡量。DIoU与CIoU的计算公式如式(3)-式(5)所示。
(3)
(4)
(5)
式中:ρ表示为预测框中心与真实框中心点的欧氏距离;c表示预测框与真实框中的最小包区域的对角线距离;b和bgt表示预测框与真实框的中心点;wgt和hgt表示真实框的宽和高;w和h表示预测框的宽和高。
综合以上边框回归损失函数优点和缺点,本文根据自制的安全帽检测数据集的特点,选用CIoU边界回归损失函数,不仅能在目标框相互包裹重叠情况下快速收敛,还能进一步提升安全帽检测模型的性能。
2.3 采用多候选框学习策略
在直接获取安全帽检测物体与安全帽位置时,由于是否佩戴安全帽与图中安全帽的位置信息不存在直接联系,因此在改进网络使用DIoU-NMS[17]时,存在安全帽的位置确定而是否佩戴分类检测结果低的情况,这会在使用DIoU-NMS时过滤掉候选框而导致漏检。因此为解决是否佩戴安全帽和安全帽定位置信度之间不匹配问题,本文借鉴多候选框学习策略MAL(Multiple Anchor Learning)改善这个问题。
多候选框学习策略先将待检测目标候选框的位置信息与分类置信度信息进行整合优化,计算得到新的候选框位置与分类置信度,然后将计算后的候选框参数在迭代过程中优化训练损失,最终选出置信度和位置最高的候选框,进而提升目标检测效果。本文采用多候选框学习策略的过程为:先将某个是否佩戴安全帽目标的i个候选框构成一个数组Ai。再采用式(6),评估数组中每个候选框的分类置信度与位置信息,选取待检测目标分类置信度和位置得分最高的候选框更新模型参数。然后使用更新后的模型,重新评估是否佩戴安全帽目标候选框的分类置信度与位置。最后经过多次迭代,得到安全帽佩戴检测最优的候选框信息。最优候选框可以有效减少因使用DIoU-NMS过滤掉位置确定而分类置信度低的情况发生。目标函数计算公式如式(6)所示。
(6)
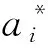
从数组Ai中找到分数较高的候选框需要采用选择深化方法。选择方法是在学习过程中线性地降低Ai中候选框的数量直到为1。深化方法是使未被选择的候选框参加训练,降低得分较高的候选框得分。其选择计算公式如式(7)所示。
(7)
式中:t为当前迭代次数;T为总迭代次数;λ=t/T;Φ(λ)为候选框的索引。
通过选择深化方法选取最优解是一个对抗过程。选择方法选出分类置信度与位置分数较高的候选框降低检测损失得到局部最优解。然后通过深化方法学习未被选中候选框中的特征,减低候选框的得分使损失上升脱离局部最优解。最后,重复选择深化过程,在收敛时得到最优解。其选择深化过程如图4所示。
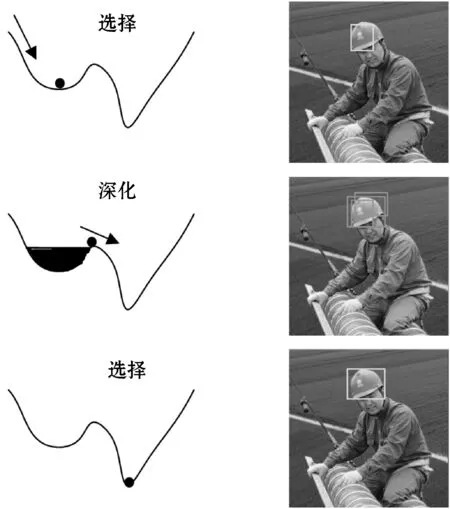
图4 选择深化过程示意图
2.4 先验框聚类
YOLOv4延续了YOLOv2[18]和YOLOv3中采用K-means聚类算法得到先验框的尺寸。由于YOLOv4算法中的9个先验框是从COCO[19]数据集中聚类产生的,不能应用于本文的数据集,因此需要对自制数据集中的先验框进行重新聚类,聚类效果如图5所示。
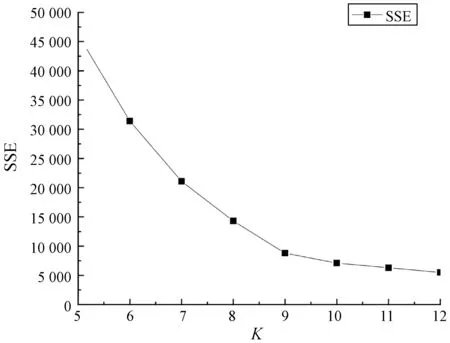
图5 K-means聚类分析图
如图5所示,聚类效果的评价指标采用误差平方和SSE。当选取K=12时误差平方和最小,可以考虑选取K=12作为聚类数量。但依据肘部法,图像在K=9时曲线畸变程度得到极大改善,因此本文选取聚类数为9。对自制数据集重新聚类依次获取的9组先验框是:(15×23)、(18×27)、(22×31)、(35×42)、(47×51)、(64×78)、(79×82)、(92×109)和(108×116)。
3 实 验
3.1 数据集和实验平台
安全帽实验数据集一部分采用开源的安全帽数据集SHWD(SafetyHelmetWearing-Dataset)。该数据集一共包含了7 581幅图片,其中:标注佩戴安全帽的正样本有9 044个;未佩戴的负样本有111 514个。由于开源数据集中正负样本数量差距明显,在预测过程中容易出现预测偏向负样本的分类,降低模型的泛化能力。考虑以上因素,本文通过网络爬虫和视频截取安全帽图像,借助LabeLImg标注工具,在原有数据集中新增4 000幅图像,手动扩充数据集中的佩戴安全帽中佩戴安全帽的数量18 326个。增加标注数据后的数据集,是否佩戴安全帽的正负样本数量比接近1 ∶4,一定程度上提升模型的泛化能力。
本文实验在PC端进行。实验平台采用i7- 8700K处理器,显卡采用NVIDAIA GeForce 2080Ti,操作系统为Ubuntu 18.04。训练过程中对每次输入的图片采取随机翻转、添加噪声、调整饱和度和曝光度方法,一共训练100个epoch。其中训练过程中的学习率为0.016,采取等间隔调整学习率StepLR,调整间隔(step_size)为25,动量参数(momentum)为0.832。
3.2 算法性能对比实验
为验证YOLOv4算法引入注意力后的网络性能,本文对YOLOv2、YOLOv3、YOLOv4和YOLOv4引入注意力机制在自制安全帽数据集上,都采用训练100个epoch后的训练结果进行对比分析。其中输入尺寸都使用尺寸为608×608的图像,对比结果以mAP数值、计算量次和每秒识别帧速率为算法性能指标,其性能参数对比结果如表1所示。

表1 网络性能对比表
由表1可知,虽然YOLOv4算法在引入注意力机制后算法增加了一定的计算量,但是检测mAP数值相比较YOLOv2、YOLOv3、YOLOv4分别提升了15.98百分点、8.73百分点、4.06百分点。虽然YOLOv4在增加注意力机制后的帧速率不及前面三种算法,但是在满足视频监控实时检测帧率大于25帧/s的实际需求下,采用引入注意力机制适当增大一定计算量,可以提升安全帽佩戴的检测效果。
3.3 损失函数对比实验
为验证不同损失函数对目标检测算法的影响,本文采用YOLOv4网络分别使用IoU、GIoU、DIoU和CIoU四种损失函数使用自制安全帽数据集在100个epoch后的结果进行对比分析,其对比结果以mAP数值作为评价指标,对比结果如表2所示。其不同边界损失函数在50个epoch后训练过程结果如图6所示。

表2 不同边界框回归损失函数对比表
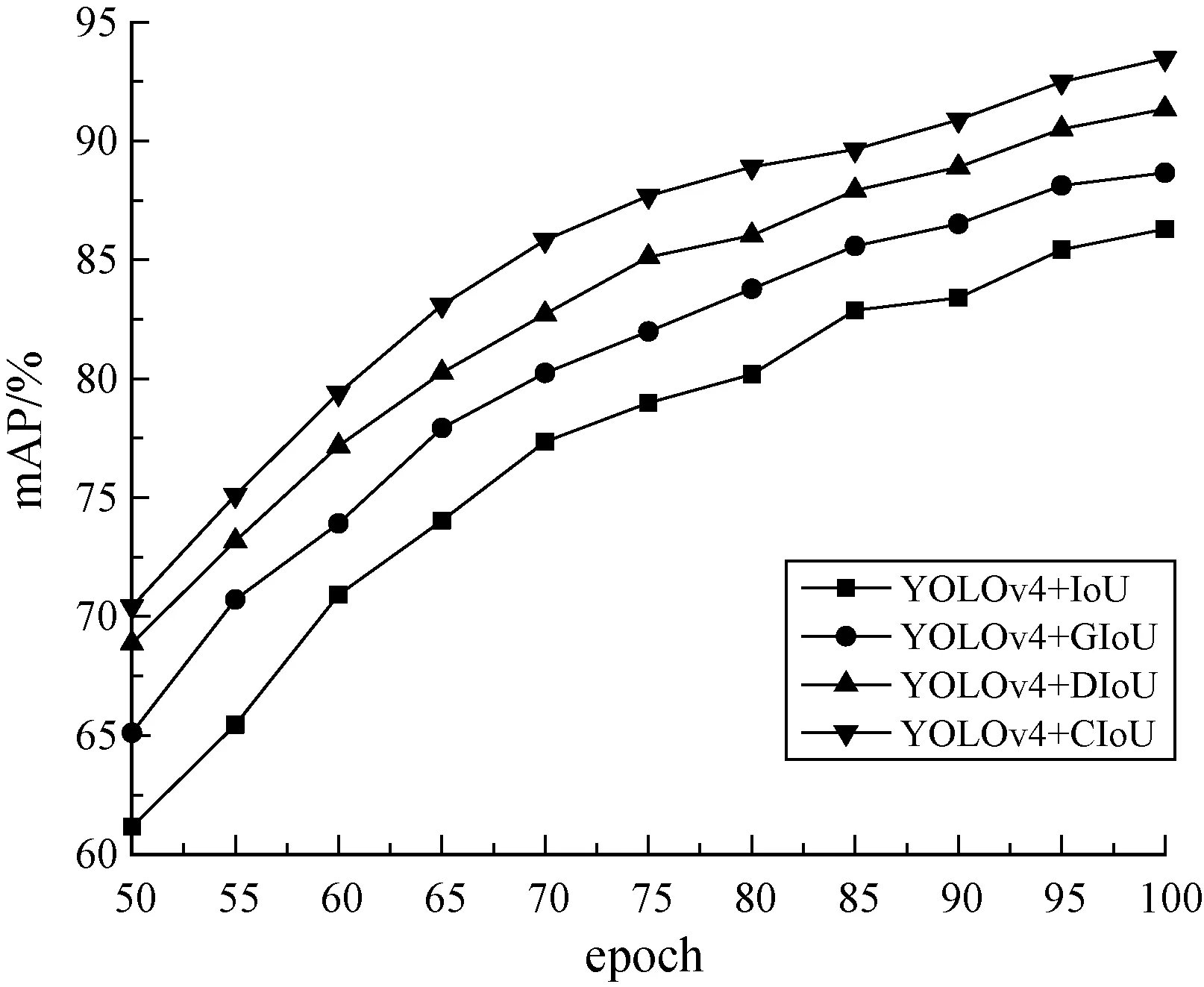
图6 不同边界框回归损失函数训练图
由表2可知,在使用四种不同的损失函数时,都能在一定程度上提升YOLOv4的检测性能。本文选择CIoU边界回归损失函数,相比较IoU、GIoU和CIoU在性能上分别提升了7.18百分点、4.81百分点、2.12百分点。并且由图6可知,本文选择的CIoU边界框回归损失函数在训练时相比其他损失函数更容易快速收敛并达到稳定。因此,选择CIoU作为损失函数可以在一定程度上提升安全帽佩戴检测性能。
3.4 检测效果对比实验
为验证采用多候选框策略对安全帽检测算法的影响,实验将YOLOv4算法结合引入注意力机制,使用CIoU边界框损失函数,分别对是否采用多候选框策略进行对比实验。实验结果以mAP数值为评价指标,检测对比结果如表3所示,检测效果如图7所示。
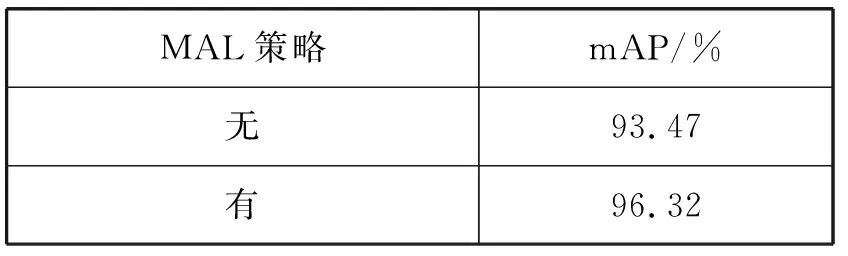
表3 采用MAL策略性能对比表

(a) 未引入MAL策略 (b) 引入MAL策略图7 采用多候选框策略对比图
由表3可知,采用多候选框策略在安全帽佩戴检测的mAP数值上提升了2.85百分点。由图7可知,在安全帽佩戴检测存在目标遮挡时,由于YOLOv4采用DIoU-NMS存在过滤掉有位置信息但目标得分置信度不高的候选框,从而导致漏检现象的出现。综合考虑,本文采用多候选框学习策略既可以提升佩戴安全帽检测性能,还能减少漏检现象的出现。
3.5 不同网络对比实验
本文将优化后的检测算法与Faster RCNN[20]、SSD和YOLOv3[5]在自制数据集上进行安全帽佩戴检测的对比实验,以mAP以及每秒识别帧率作为检测评价的性能指标,其对比结果如表4所示。
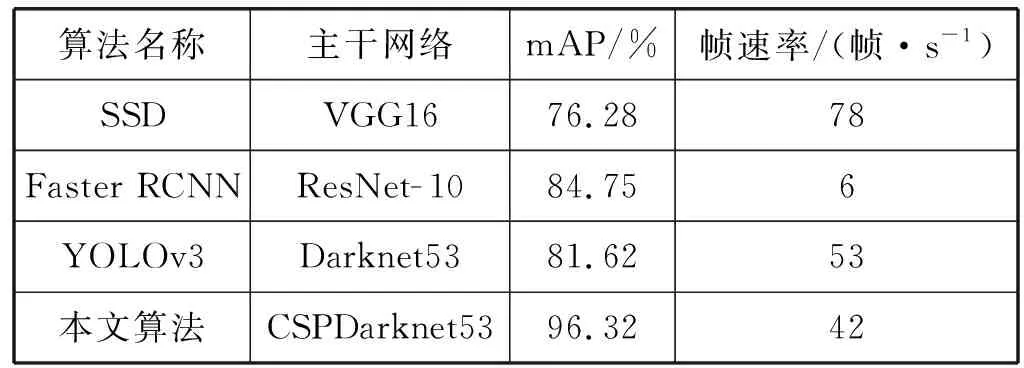
表4 不同算法的性能对比表
由表4可知,本文安全帽佩戴检测算法不仅mAP数值比Faster RCNN和YOLOv3算法分别高11.57百分点和14.7百分点,并且检测速率上是Faster RCNN的7倍。虽然本文算法的检测安全帽佩戴的帧速率相比较SSD算法低,但是检测帧率也满足视频监控检测实时性要求。通过不同网络的性能对比,本文算法在准确率和实时性上可以较好地完成安全帽佩戴检测的要求。本文优化后的安全帽检测效果如图8所示。

图8 本文算法检测效果
4 结 语
本文提出一种改进YOLOv4网络和视频监控相结合检测佩戴安全帽的方法。通过对自制的安全帽佩戴检测数据集,采用K-means聚类算法获取适用于安全帽数据集的先验框,在YOLOv4网络增加注意力机制模块聚焦安全帽特征,接着选用新的边界框回归损失函数CIoU提高检测精度,最后使用多候选框学习策略减少漏检概率。本文方法能够快速、准确地检测是否佩戴安全帽,并可以通过监控视频手段减少因未佩戴安全帽造成的意外安全事故。
猜你喜欢
机电安全(2022年4期)2022-08-27
光学精密工程(2022年13期)2022-08-02
小雪花·成长指南(2022年1期)2022-04-09
计算机工程与应用(2022年1期)2022-01-22
计算机工程与科学(2021年4期)2021-05-11
课外生活·趣知识(2019年4期)2019-09-10
火力与指挥控制(2018年3期)2018-04-19
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
华东理工大学学报(自然科学版)(2014年3期)2014-02-27
