
基于语义特征提取与层次结构的问题生成方法
2023-03-09 12:49白诗瑶吕佳键
吉林大学学报(理学版) 2023年1期
白诗瑶, 吕佳键, 彭 涛,3, 刘 露,3, 崔 海
(1.吉林大学 计算机科学与技术学院, 长春 130012;2.吉林大学 软件学院, 长春 130012; 3.吉林大学 符号计算与知识工程教育部重点实验室, 长春 130012)
问题生成是自然语言处理中一个重要且具有挑战性的任务, 旨在基于给定的文本自动生成一段流畅且符合上下文语境的问题[1-4].其可应用于包括对话系统、教育[5]以及医疗[6]等多个领域.并且作为问答系统的对偶任务, 可用于扩充训练数据集以提升任务表现[7].针对问题生成任务目前主要有两种方法, 早期主要是基于规则的方法, 即使用人工构建的模式或规则将给定的文本转化为对应的问题.Heilman等[8]使用一种树形查询语言Tregex简化输入文本, 抽取出输入文本的不同成分然后制定不同的替换策略;Chali等[9]则在此基础上识别出文本中的命名实体并作为文本的话题, 然后基于话题制定问题模板.但基于规则的方法因需手动构建规则, 既耗费时间, 也浪费人力资源.近年来, 随着深度学习的不断发展, 基于深度学习的方法已有很多, 其能很好地节约人力和时间成本.Du等[10]首先提出了一种基于注意力机制生成问题的序列到序列模型.在此基础上, 考虑答案对于问题的重要性, 即生成的问题是否能用目标答案回答以及是否与答案相关等, Zhou等[11]采用BIO标记策略标记文本中答案出现的位置;Sun等[12]提出了基于目标答案显式地生成匹配的疑问词, 提出了答案;Kim等[13]将文本和答案分别编码, 并设计了一种关键词网络建模文本中除答案外的其他内容与答案的联系.针对建模文本与答案的关系, Song等[14]设计了多种答案和文本的匹配策略.
但仅考虑答案作为补充信息引导问题生成还不够, 因为当文本的语义较复杂时, 除答案外还有很多事实信息, 这些信息同样重要, 并且仅凭简单的基于循环神经网络(RNN)的模型很难完整获取到.针对上述问题, Wang等[15]提出了基于路径进行问题生成的新任务, 先使用一些工具将文本转化为知识图谱, 再将对应知识图谱中与目标答案相关的事实信息以路径的形式抽取出, 将路径作为输入生成问题.新任务通过显式地建模文本中的语义信息生成更相关的、语义更丰富的问题, 但针对该任务已有的方法目前存在以下问题: 1) 路径并不是简单的序列文本, 它是三元组的有序集合, 是文本对应的知识图谱的子集, 目前已有的方法仅使用基于RNN的模型无法建模这种复杂的输入;2) 已有方法忽略了路径的局部结构信息, 并且路径的节点并不完全相同, 而是包括实体和关系两种, 这两种节点所包含的局部结构信息不同.
为解决上述问题, 本文提出一种基于语义特征提取的方法建模路径.该方法首先使用基于自注意力的双向长短时记忆网络(LSTM)获取路径包含的序列特征作为路径的全局特征, 同时设计一种双向的卷积神经网络(CNN)结构获取路径的局部结构特征.在提取特征后, 为更好地融合特征信息以获得最终的路径表示, 额外设计了一种层次结构.该方法针对复杂语义文本设计了不同的特征提取策略及对应模型, 能更完整地建模文本的语义信息, 使生成的问题也更相关, 在数据集SQuAD[16]上的实验结果表明, 本文方法比目前已有的方法效果更佳.
1 基于语义特征提取与层次结构的问题生成框架
本文基于语义特征提取的问题生成框架共由3个模块组成, 包括文本编码器、路径编码器和解码器, 整体框架如图1所示.首先经由文本编码器编码给定的输入文本X, 然后基于文本编码利用路径编码器得到路径P的表示, 最后在路径和文本的指导下解码器生成问题Y的每个单词.
1.1 文本编码器
路径虽然已经包含了与答案相关的大部分内容, 但初始文本仍包含路径没有的信息, 如答案在文本中的位置等, 因此本文同时编码文本信息对路径进行补充.本文采用的文本编码器结构如图2所示.首先将文本中的每个单词转化为对应的词向量, 然后标注文本中路径头尾实体出现的位置, 得到位置向量与词嵌入拼接, 输入到编码层得到文本的上下文表示.

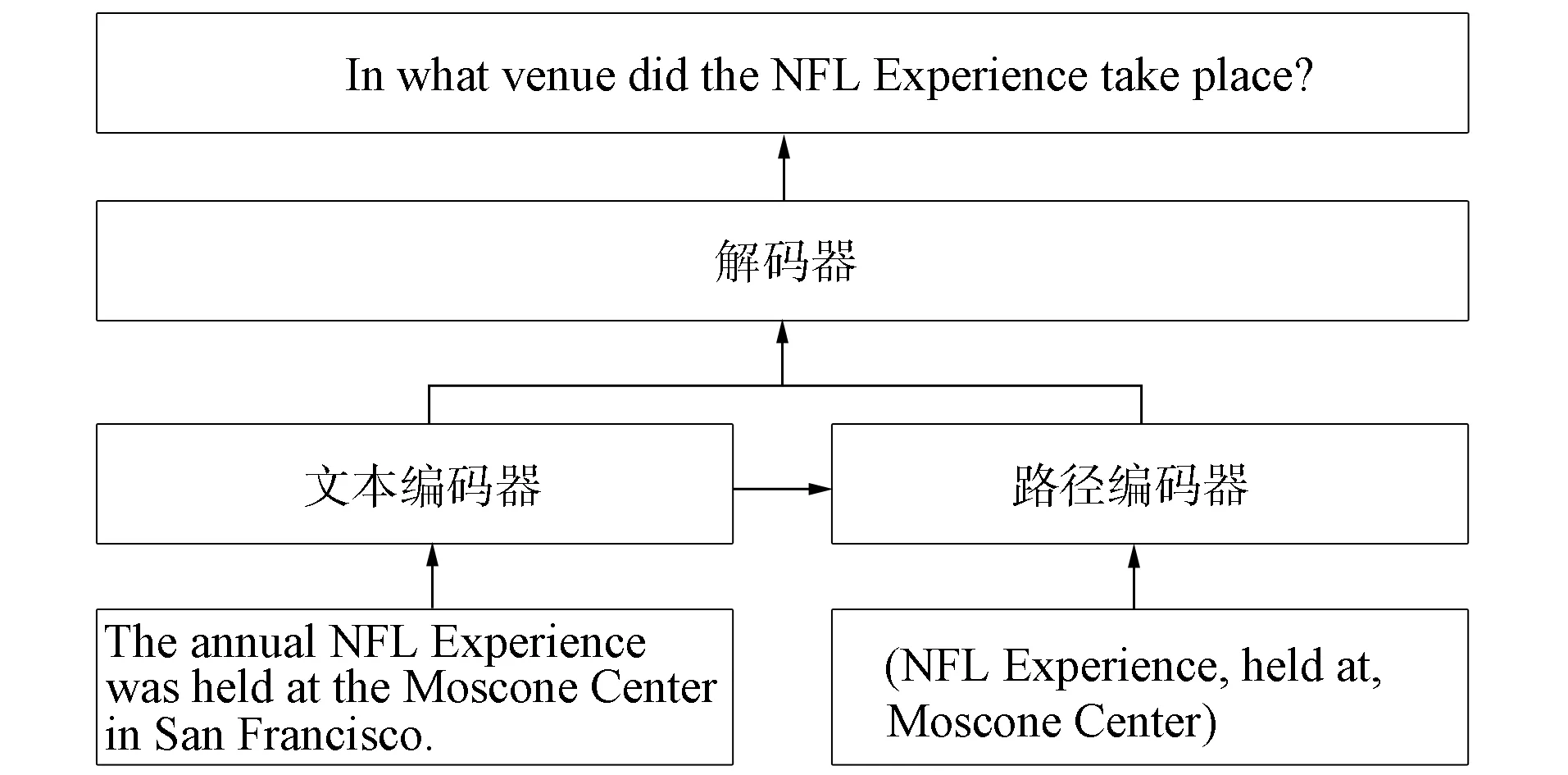
图1 本文方法的整体框架Fig.1 Overall architecture of proposed method

图2 文本编码器Fig.2 Context encoder
1.2 路径编码器

图3 路径编码器Fig.3 Path encoder
本文提出的基于语义特征提取和层次结构的路径编码过程如图3所示.由图3可见, 路径首先输入到一个上下文编码层获得其上下文信息, 然后基于此通过自注意力层提取全局特征, 并设计一个双向的CNN(BiCNN)提取路径的局部特征, 最后将节点嵌入与每个节点的特征拼接,再通过一个高层的BiLSTM得到最终的路径表示.通过设计一个层次结构即底层的输入和特征的输出拼接再利用高层网络进行融合, 能得到更富有语义信息的路径表示.同时, 本文考虑了路径复杂结构所隐含的丰富内容, 并针对性地设计了网络结构捕捉这些语义信息.
1.2.1 节点嵌入与上下文编码
因为路径中的每个节点都对应知识图谱中的实体或关系, 即每个节点可能会包含多个单词, 因此为获取每个节点的向量表示, 假设路径包含n个节点, 本文通过以下计算获得:
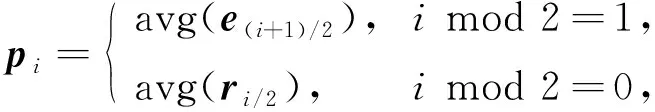
(1)
其中pi表示路径中的第i个节点, 奇数表示当前节点是实体ei, 偶数表示当前节点是关系ri, 即对于路径上的每个节点, 都对节点中的每个单词得到词嵌入, 然后取平均作为节点嵌入向量, 由此得到路径嵌入表示P=(p1,p2,…,pn).
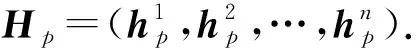
1.2.2 全局特征提取
路径中每个节点在整个路径中的重要程度不同, 为衡量这种重要性, 赋予重要程度更高节点更大的权重, 本文使用自注意力层计算每个节点与整条路径的匹配性, 得到每个节点的全局特征, 对于第i个节点, 计算方式如下:

1.2.3 局部特征提取
虽然路径整体上是一个时序文本序列, 但由于其为由文本对应的知识图谱中抽取出, 因此路径同时也是有序三元组的集合, 如图4所示, (holy cross father john francis, was elected, president)和(present, of, notre)是路径中所包含的两个三元组, 这不能在使用RNN模型时同时获得.考虑到对于每个节点, 局部结构都是三元组的情况, 以及受文献[17]在自然语言处理任务上使用CNN的启发, 并且CNN的卷积层能提取输入的局部结构信息, 因此本文使用基于CNN的模型提取每个节点的局部特征.此外, 由图4可见, 节点是实体或关系所具有的局部结构不同.当节点是实体时, 其可作为头实体出现在一个三元组中, 同时也可作为尾实体出现在上一个三元组中, 即实体具有两个局部特征的共同信息;当节点是关系时, 它只参与到一个三元组中.因此为不丢失信息, 本文提出一种BiCNN结构, 与BiLSTM思想相近, 考虑路径的原始序列以及反转序列作为CNN的输入, 将每次提取三元组的特征作为三元组中每个节点的局部结构特征.在输入原始序列时, 每次CNN对三元组中的实体-关系-实体进行卷积计算, 提取出其特征作为3个节点具有的共同特征, 即对于尾实体, 其所具有的也只是作为尾实体时三元组的特征, 而没有同时获得作为头实体的三元组特征.当原始序列输入结束后, 再输入反转的序列进入另一层CNN, 即能得到它作为头实体时具有的结构信息.图4给出了具体的实例, 其中箭头表示BiCNN的每一步.同时, 为了每次都对三元组结构提取特征, 将核大小设为3, 步长设为2.最后将两个方向的输出进行拼接, 即可得到每个节点的局部特征.

图4 路径局部结构Fig.4 Local structure of path
1.2.4 层次结构设计
为更好地融合节点的特征信息, 本文提出一种层次结构, 将上文得到的全局和局部特征以及节点的嵌入向量拼接起来, 输入到一个高层的BiLSTM中进行编码, 得到路径的最终表示.
1.3 解码器
本文采用单向的LSTM作为解码器生成问题, 将上述模块得到的最后时刻的文本表示和路径表示拼接起来初始化解码器.在t时刻, 解码器读取上一时刻生成的单词yt-1和隐层状态st-1更新当前时刻的隐层状态st, 因为每一时刻生成的单词关注的原文信息不同, 故本文采用注意力机制计算每一时刻的文本注意力向量ct和路径注意力向量pt, 以文本注意力向量为例, 计算方法如下:
最后将得到的当前时刻隐层向量、文本注意力向量和路径注意力向量拼接起来, 使用一个两层的全连接网络预测问题的下一个单词:
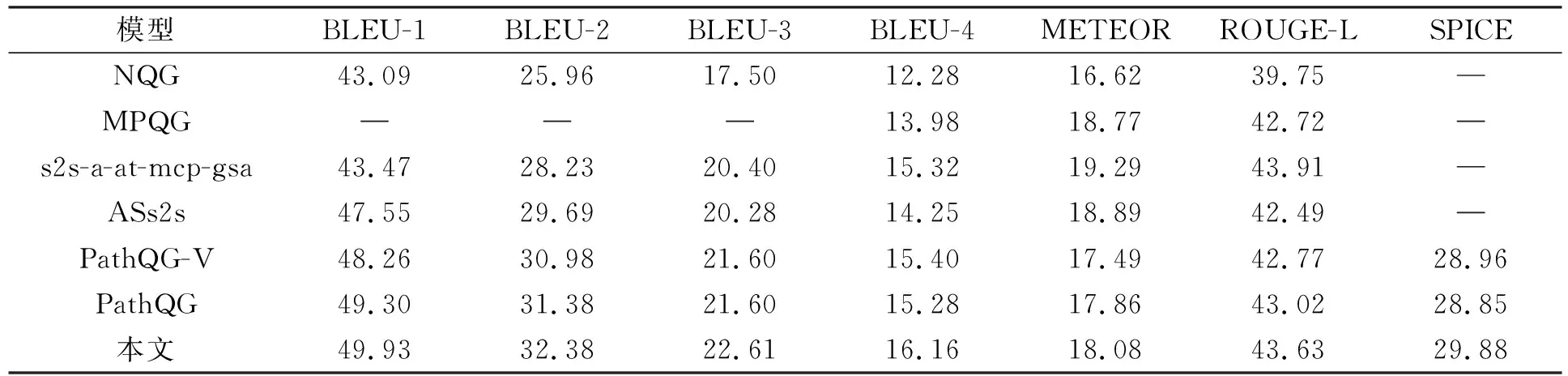
P(yt|y (7) Stanford问答数据集(the Stanford question answering dataset, SQuAD)是问题生成任务和机器阅读理解领域常用的数据集.该数据集来源于维基百科的536篇文章, 共有近10万个问题-答案对.为公平地对比模型的性能, 遵循文献[15]的方法构建事实路径, 即首先利用解析器将文本转化为知识图谱, 然后将答案作为尾实体, 参考问题中出现的实体作为头实体, 在知识图谱中找到对应的路径, 过程中忽略关系的方向. 本文提出的模型基于Pytorch实现, 其中词向量使用300维的GloVe[18]进行初始化;CNN 层卷积后的特征向量为50维;批量大小为32;迭代次数设为20;学习率为0.001;使用Adam进行优化. 为评估本文方法在问题生成任务上的性能, 选取多个基于端到端模型的方法进行对比, 包括基于注意力机制的NQG模型[10], 采用多种策略建模答案和文本之间关系的MPQG模型[14], 提出一种最大化的指针机制优化源复制的s2s-a-at-mcp-gsa模型[19], 关注答案本身信息的ASs2s模型[13], 基于事实路径抽取语义信息的PathQG模型和基于前者的变分模型PathQG-V[15]. 本文使用衡量生成任务表现的BLEU1-4,METEOR和ROUGE-L作为评价指标.同时, 为更好地衡量生成的问题所具有的语义信息, 本文额外采用了SPICE[20]评价生成的问题和参考问题之间的语义相似度, 将生成的问题和给出的参考问题都转化为知识图谱, 计算生成问题含有共同事实的准确率和召回率, 进而计算出指标值.假设生成的问题为y, 参考问题为r, 则计算方法如下: 其中: 函数G返回输入对应的知识图谱; 函数O,E,K分别表示输入所具有的实体、关系以及有关系的实体, 基于以上函数能得到输入对应的事实信息;P和R分别为计算出的准确率和召回率, 通过平均准确率和召回率计算出指标值, 能更全面地评估模型的性能. 本文模型以及对比模型在各评价指标上的结果列于表1.由表1可见, 本文模型在大部分指标上都得到了最优结果, 尤其是在BLEU-4上提升达4.9%, 表明本文模型不仅在每个单词的预测上都优于已有模型, 而且在粒度更大的词语预测中准确率也比其他模型更高.同时, 相比于同样使用路径建模事实的PathQG和PathQG-V模型, 本文模型性能更好, 证实本文方法能更好地建模路径的复杂结构信息. 表1 本文模型与对比基线模型的实验结果 为考察本文方法各模块的作用, 进行不同模块的消融实验, 结果列于表2, 其中w/o表示方法未使用对应的那一模块. 表2 本文方法的消融实验 由表2可见, 移除本文方法的各模块都使模型的性能有不同程度的下降, 说明了本文方法各模块的有效性.并且移除局部特征提取模块导致了性能的最大下降, 也说明局部结构所含有的语义信息补充了时序编码的不完整语义, 本文设计的BiCNN结构能提取出这些信息. 为更直观地验证本文方法的性能, 表3列出了两个真实案例, 对于每个实例分别给出参考问题、本文方法生成的问题以及PathQG模型生成的问题, 文本中下划线部分为答案.例1中, PathQG模型生成的问题所包含的信息不完整, 同时对于选举年份这部分也有一部分歧义, 因为给定文本中有两个选举年份, 不同年份表示的职位不同.而本文方法则生成了与参考问题几乎一致的问题, 并且也指明了选举职位, 说明本文方法生成问题的语义较完整且准确.例2中, 对于答案为体育馆这一情况, PathQG模型生成的问题只有主语与体育馆相关, 而其他内容并不是给定文本相关的内容, 并且也未识别出路径中棒球这一相关事实, 而本文方法生成的问题则建模出了这一事实, 但相比于参考问题, 缺少了位置这一信息, 这可能是因为抽取的路径中并不包含该信息. 表3 生成问题的实例 综上所述, 针对输入语义复杂情况下传统方法建模语义可能不完整的问题, 本文提出了一种基于语义特征提取与层次结构进行问题生成的方法, 提取出了路径的全局特征和局部特征, 并为提取局部特征提出了基于CNN的新结构.同时, 为更好地融合特征到路径表示中, 还设计了一种层次结构.实验结果表明, 本文方法能更完整地建模语义信息, 并且该方法的每个模块都具有一定效果.2 实 验
2.1 数据集
2.2 参数设定
2.3 对比模型
2.4 评价指标
2.5 实验结果与分析


猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12
国际眼科杂志(2021年9期)2021-09-15
山西大学学报(自然科学版)(2021年1期)2021-04-21
装备制造技术(2020年2期)2020-12-14
开放教育研究(2020年2期)2020-03-31
五邑大学学报(自然科学版)(2019年3期)2019-09-06
计算机技术与发展(2018年12期)2018-12-20
现代语文(2016年21期)2016-05-25
中国卫生(2015年12期)2015-11-10
大连民族大学学报(2015年2期)2015-02-27
