
事件抽取技术综述及应用
2023-03-08 10:57:36岳思雯
软件导刊 2023年2期
肖 乐,岳思雯
(河南工业大学 信息科学与工程学院,河南 郑州 450001)
0 引言
事件抽取(Event Extraction,EE)涉及自然语言处理、机器学习等多个研究领域,旨在从非结构化的自然语言中抽取出特定类型的事件信息,并以结构化形式呈现。与传统知识图谱的单个实体相比,事件能够更加清晰准确地描述事实信息,能够在完成“when”“who”“what”“where”问题的同时,进一步回答“how”及“why”问题。因此,事件抽取技术在各领域监控监测、智能问答以及决策支持中被广泛应用[1-3]。例如,生物医学领域将事件抽取用于分子识别,帮助工作人员理解生物医学事件的上下文深层意义,避免传统抽取方式产生的错误传播问题[4-6];新闻领域通常用事件抽取技术进行热点监测,事件属性与时间特性是新闻热点的关键要素,事件抽取在新闻热点监测任务中,能够及时识别热点事件传播过程中关键事件的爆发与演变,有助于当局迅速作出决策[7]。此外,经济事件抽取在金融市场日常决策中起着至关重要的作用[8-9]。除上述领域外,事件抽取技术在其他热门领域也发挥着积极作用。
本文以事件抽取为核心进行研究,并就相关研究提出的方法进行分析对比。对事件抽取技术应用于飞行器维修领域的案例进行研究,抽取飞行器维修事件知识,构建飞行器维修知识图谱,进而实现飞行器维修决策支持系统,为维修人员提供决策辅助,为飞行安全提供强有力支撑。
1 事件抽取概述
1.1 事件
事件是现实世界中信息的一种表现形式,不同领域对事件的定义存在差异。在知识图谱领域,ACE(Automatic Content Extraction)将事件定义为发生在特定时间点或时间段、特定地域范围内、由一个或者多个角色参与的一个或者多个动作组成的事情或者状态的改变。
1.2 事件抽取
事件抽取任务旨在抽取非结构化自然语言文本中特定类型的事件信息,并以结构化形式呈现给用户,有助于计算机以人类认知方式理解复杂场景下的具体问题,为用户提供更好的体验。
事件抽取包含2 个子任务,涉及4 个相关概念。事件抽取任务通常被定义为事件检测(Event Detection,ED)和事件论元抽取(Event Argument Extraction,EAE)。①ED:事件检测任务首先从文本中抽取出事件触发词,然后对触发词所代表的事件类型进行分类,事件类型分别对应唯一的事件Schema;②EAE:事件论元抽取任务首先进行论元识别,然后辨别论元在事件中扮演的角色。在ED 任务中已经确定了事件类型,EAE 任务需根据预先定义好的事件Schema识别文本中的事件元素,并确定元素角色。
这两个子任务中涉及的4 个概念分别是:①事件:能够描述事件的短语或句子,包括触发词和论元;②事件触发词:事件发生的核心词(通常为动词或名词),是决定事件类别的重要特征;③事件论元:事件中的参与者,与事件触发词共同构成事件Schema;④论元角色:论元与它所参与事件之间的关系。事件抽取示例如图1所示。

Fig.1 Example of event extraction图1 事件抽取示例
2 事件抽取技术
近年来,多种事件抽取方法被相继提出,部分研究者对相关研究及未来趋势进行阐述[10-12]。本文在查阅大量文献的基础上,采用建模领域的经典区分方法将事件抽取技术大致分为3 类:①基于数据驱动的事件抽取,这类方法通过使用统计学、机器学习、线性代数等将数据转换为知识;②基于专家知识驱动的事件抽取,该方法利用专家知识进行事件抽取,最常见的是基于模式的事件抽取;③混合事件抽取方法,结合专家知识和数据驱动方法进行事件抽取。
2.1 基于数据驱动的事件抽取
基于数据驱动的事件抽取主要使用概率论、线性代数等定量方法以及词频统计、TF-IDF、N-Gram 和聚类等自然语言处理方法发现事件知识,需要大型文本语料库开发语言模型。基于数据驱动的事件抽取可细分为有监督、半监督和无监督3 种学习方法。有监督的方法首先要进行数据标记,再将其提供给决策树和神经网络等学习算法;无监督的方法适用于没有标记数据的场景,能够根据预先标记好的数据生成新事件;研究发现,结合使用标记与未标记数据可以提高抽取精度,这种情况通常使用半监督学习方法。
(1)有监督。事件抽取研究中有不少机器学习和深度学习方法,它们通常采用监督学习,将事件抽取看作一个分类任务[13-14]。常见的方法有卷积神经网络CNN、递归神经网RNN、图神经网络GNN 等。CNN 能够基于连续和广义的单词嵌入学习文本隐藏特征,有效捕捉句法和语义。Kodelja[15]等将全局上下文表示集成到CNN 模型中进行事件抽取。然而,在语言建模中句子通常被视为一系列单词,RNN 由一系列相连的长短期记忆(LSTM)神经元组成,能够缓解CNN 事件抽取存在的错误传播问题。Zhang等[16]基于RNN 模型构建了以目标词为中心的树LSTM,提高抽取精度。Li 等[17]利用外部实体知识进一步扩充树LSTM,抽取生物医学事件。此外,有研究将GNN 应用于事件抽取以更好地学习事件关系。例如,LIU 等[18]利用GCN学习上下文表示,聚类相互联系事件间的信息,改善同一句子中多事件抽取效果。Cao 等[19]利用GNN 的归纳学习能力增强相关知识,有效检测事件;PENG 等[20]在GNN 上实现了跨语言的社会事件抽取。此外,近期研究侧重于结合使用不同的神经网络进行事件抽取。刘赫等[21]设计一个联合神经网络事件抽取模型,提升电力调度文本在业务场景的应用效果。CNN、RNN、GNN 事件抽取示例如图2—图4所示。
(2)半监督。监督学习方法需要经过标记的高质量语料库进行模型训练。然而,获取标记语料库需要大量专业知识,成本高,且现有标注语料库规模小、覆盖率低。例如,ACE 2005 语料库只定义了33 种事件类型,对不同应用的覆盖率非常低。并且,在标记的事件中,约60%的事件类型实例少于100 个,3 个事件类型的实例甚至少于10 个。针对有监督事件抽取方法准确性低的问题,Ferguson 等[22]提出一种自训练事件抽取方法,对训练数据进行重复抽样,避免因数据稀疏而产生问题。

Fig.2 Example of CNN event extraction图2 CNN事件抽取示例
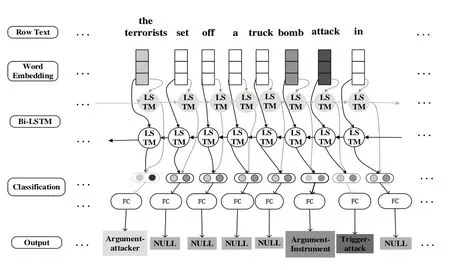
Fig.3 Example of RNN event extraction图3 RNN事件抽取示例
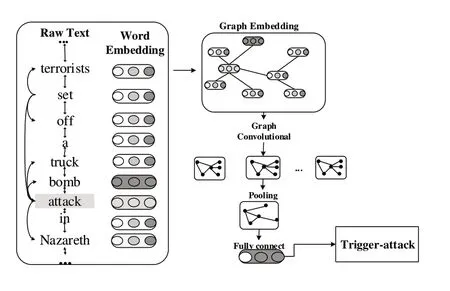
Fig.4 Example of GNN event extraction图4 GNN事件抽取示例
(3)无监督。与有监督和半监督学习不同,无监督学习主要关注开放域事件抽取任务,根据相似性对事件要素进行聚类[23]。梁月仙等[24]通过基于语义相似性的聚类算法抽取出重要事件,并根据TF-IDF 计算时空维度事件权重,设计模型抽取时空突发事件;Wang 等[25]采用AMR 解析信号作为预训练的无监督信号,将事件抽取任务转化为子图识别问题,使模型更好地理解事件知识与事件结构。
基于数据驱动的事件抽取侧重于发现语料库中的统计关系,既不需要语言资源,也不需要专家知识。但由于隐含在数据中的语义没有被明确考虑,统计关系的语义有效性以及抽取结果的可解释性都较差。
2.2 基于知识驱动的事件抽取
基于知识驱动的方法通常使用由专家知识预定义的词汇句法模式或词汇语义模式进行事件抽取,缓解了数据驱动方法忽略文本语义的问题[26]。本文主要围绕基于模式的事件抽取展开讨论。
研究发现,多数文献侧重于基于词汇句法模式的事件抽取。例如,崔莹[27]提出基于相似义原和依存句法的抽取方法,提高政外新闻抽取的召回率和准确率。Hung 等[28]使用词汇—句法模式匹配和语义角色标注,设计常识事件抽取框架。吴雨等[29]采用间接句法信息模式,使深层句法信息得到更有效的利用。此外,词汇句法模式在金融和政治领域的事件抽取也得到广泛应用[30]。
基于模式的事件抽取需要具有特定含义或关系的概念,但部分概念由于缺乏模式表达能力,在词汇句法模式中不被使用。为解决上述问题,研究者提出基于词汇语义模式的事件抽取方法。罗明等[31]采用层次化词汇—语义模式进行事件抽取,简化工作流程,提高工作效率。万齐智等[8]在句法依存树的基础上增加语义依存关系,建立事件间语义关联,解决事件成分缺失问题。
基于知识驱动的事件抽取无需大量数据,使用专家构建的高质量事件模式,具有较高抽取精度。然而,构建大规模事件模式需要大量专业知识,成本高昂。并且,事件模式在其他领域的应用容易产生适应性和泛化性问题。
2.3 混合事件抽取
尽管基于数据驱动和知识驱动的事件抽取方法均有优势,但实际应用时难以确保应用环境的单一性。研究表明,基于数据驱动的方法可以通过添加专业知识进行约束与改进,基于知识驱动的方法在获取事件模式前通常要利用统计方法进行初始聚类。基于上述分析,越来越多的研究人员将这两种方法结合使用。
文献中已有许多用于事件抽取的混合方法,多数方法用数据驱动辅助知识驱动,以解决缺乏专家知识的问题。例如,Jungermann 等[32]将词汇句法模式与条件随机场(CRF)相结合,从记录中抽取会议事件。Piskorski 等[33]采用带聚类的弱监督学习算法,设计用统计数据引导词法技巧的模型,从在线新闻中高精度、高召回率地抽取暴力事件。
尽管混合方法所需数据量相较于知识驱动方法有所增加,但仍低于数据驱动方法。并且,由于统计方法可以弥补专业知识的缺乏,混合事件抽取所需的专业知识量较少,但多种技术结合使模型训练时间和算法复杂度显著增加。
总体而言,基于知识驱动的方法能够用接近自然语言的方式进行事件抽取,不必担心统计细节和模型微调,适合为喜欢用交互、查询方式的用户提供服务;基于数据驱动的方法和混合方法较少受到语法方面的限制,更适合研究人员等用户使用。如表1 所示,对上述各类方法中具有代表性的模型进行比较分析。
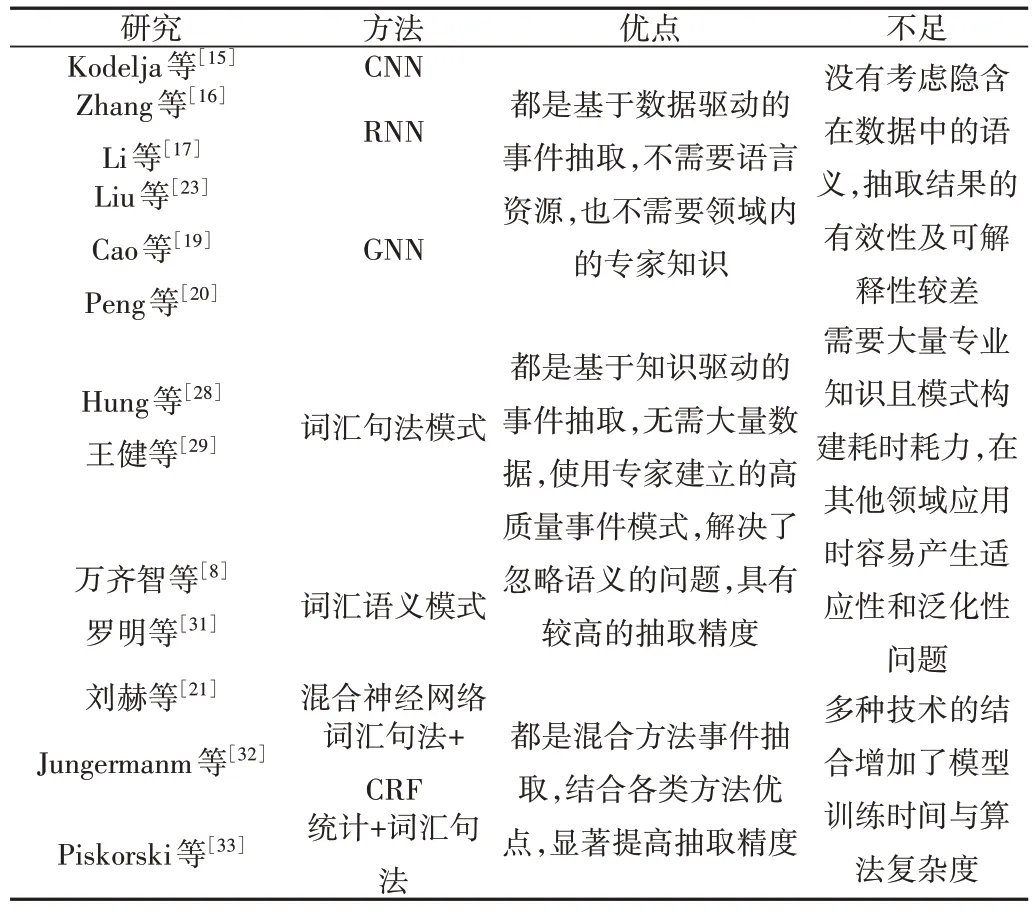
Table 1 Model analysis and comparison(1)表1 模型比较分析(1)
上述3 类方法各有优劣,为进一步优化事件抽取技术,近期研究侧重于通过问答、阅读理解、生成等方式进行事件抽取[34-36]。Du 等[34]将事件抽取定义为问答范式,避免传统方法中出现的错误传播问题;Liu 等[35]为了解决语序差异问题,设计了用于多语言协同训练的共享句法顺序事件检测器,有效缓解标注极差的情景;Li 等[37]提出多轮问答事件抽取框架,充分利用触发词、事件类型和论元之间的交互信息,捕捉相同事件类型中不同论元角色之间的依赖;Xiang 等[38]等利用标签层次结构对事件检测进行优化,提高事件抽取的准确性;Sheng 等[39]将CasRel 范式迁移到事件抽取任务中,解决事件抽取中的重叠问题;Si等[40]将基于prompt的学习策略引入到事件抽取框架中,自动利用标签语义以达到提高抽取准确率的目的。如表2所示,对上述模型进行比较分析。

Table 2 Model analysis and comparison(2)表2 模型比较分析(2)
3 事件抽取在飞行器维修领域的应用
以某航空公司提供的飞行器技术跟踪信息和故障维修手册为数据源,通过数据分析发现,飞行器维修领域的数据量庞大且结构复杂,多数信息以事件形式存在,且关联性较强。其中,故障描述复杂、排故方案变化频繁。对现有飞行器维修信息的抽取而言,抽取飞行器维修信息事件元素,构建飞行器维修知识图谱,对理解故障信息、优化维修决策具有重要作用。
3.1 事件抽取模型
本文采用CLEVE 对飞行器维护信息进行事件抽取。传统方法通常基于监督范式,不能充分利用大规模无监督数据,存在数据稀疏性和泛化性问题。CLEVE 使用对比学习技术,引入AMR 解析信号作为语料库进行预训练的无监督信号,使模型更好地理解事件知识与事件结构。AMR将一个句子的语义抽象为一个有向无环图,概念作为节点,语义关系为边。其优点有:①AMR 可以为语料库中所有文本进行标注,解决数据稀疏问题;②AMR 不局限于事件类型和事件Schema,解决泛化性问题。CLEVE 事件抽取模型如图5所示。

Fig.5 CLEVE event extraction model图5 CLEVE事件抽取模型
3.2 数据集
本文以某航空公司提供的飞行器技术跟踪信息与维修手册为数据源进行事件抽取,飞行器维修数据集统计信息如表3 所示。数据集中标注了大量的实体和事件信息,可为事件抽取模型提供充足的训练样本。此外,数据集中部分实体及对应关系如表4所示。
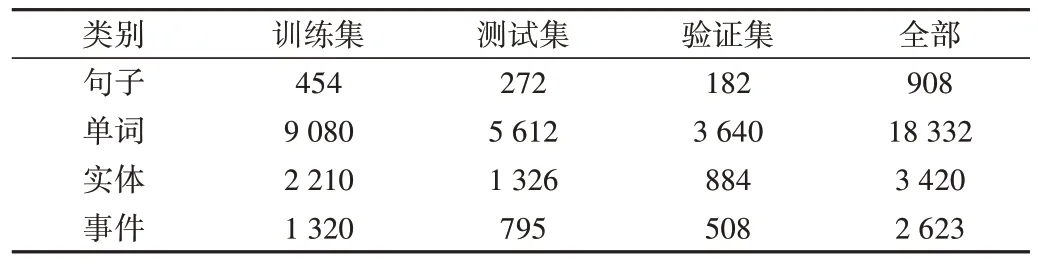
Table 3 Aircraft maintenance data statistics表3 飞行器维修数据统计信息

Table 4 Entity-relationship correspondance表4 实体关系对应
3.3 实现细节
对获取到的飞行器技术数据进行预处理,包括数据清洗和自然语言处理:①针对数据缺失和冗余等问题,建立属性和完整性约束并进行数据筛选与冗余清除;②将经过预处理的文本信息进行分词,参照停用词典去除标点符号、停用词等。之后进行事件抽取,旨在抽取出某种事件类型的触发词及相关论元。表5 定义了几类飞行器维修事件。本文围绕表5 中定义的主要事件类型进行抽取,其中,“重大故障”“较大故障”和“其他故障”3 类事件为可嵌套事件。

Table 5 Definition of primary events表5 主要事件定义
使用自动AMR 解析器将预先处理好的飞行器维修语料库中的句子解析为AMR 结构。具体而言,给定句子s,经AMR 解析后得到其AMR 图gs=(Vs,Es),其中Vs为单词合并后的节点集,Es为边集,再使用GNN 对AMR 图进行编码,抽取事件结构信息。为了对不同的事件语义进行建模,学习上下文事件语义表示,采用RoBERT 作为文本编码器进行训练。最后,在无监督环境中直接使用预先训练的CLEVE 生成的表示作为所需触发词论元表示和事件结构表示以进行飞行器维修事件抽取。如例1所示,句子中可抽取出两个飞行器维修事件,事件1(E1)是液压系统故障类型的事件,包括事件触发词“液压系统”和故障类型事件元素“压力开关失效”;事件2(E2)是D 检类型的事件,包括事件触发词“更换”,故障类型事件元素E1 和措施类型事件元素“更换压力开关”。其中,事件E2 是一个嵌套事件,参与的故障类型事件元素是E1。
例1:句子“2021 年3 月10 日,机组反映起落架收放液压系统故障。经维修人员检查,导致故障产生的原因是起落架收上到位后,上管路压力达不到标准,压力开关失效。工程师决策更换压力开关。”事件的结构化表示为:E1(类型:液压系统故障,触发词:液压系统,故障:压力开关失效);E2(类型:D 检,故障:E1,措施:更换压力开关)
3.4 实验结果
本实验采用5 种模型,以F1值为评价指标对比事件抽取结果,飞行器维修事件抽取结果如表6 所示。F1计算如式(1)所示。

Table 6 Comparison of extraction results of aircraft maintenance events表6 飞行器维修事件抽取结果比较
实验结果表明,基于CLEVE 模型事件抽取准确率高于BiLSTM-CRF 等模型,更适合飞行器维修领域的事件抽取。
3.5 飞行器维修知识图谱可视化
使用抽取出来的维修知识,受段梦诗等[41]的启发,采用自底向上的方法构建飞行器维修知识图谱。数据以实体为中心进行存储,每个数据信息,如“机号”“故障描述”等都是一个独立的节点,实体间的联系存储为“关系”。飞行器维修知识图谱如图6所示。
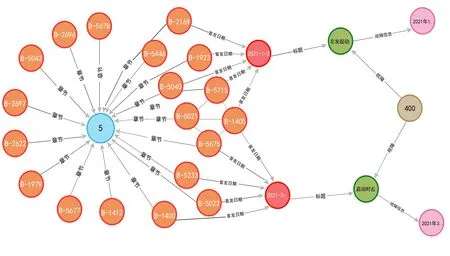
Fig.6 Aircraft maintenance knowledge graph图6 飞行器维修知识图谱
3.6 飞行器维修决策支持系统
本文构建基于知识图谱的737NG 飞行器维修决策支持系统,首先以“维修人员”的角色登录进入主页面,进行相关功能操作,如图7 所示。基于知识图谱的决策支持能够更准确地理解复杂问题,匹配图谱中的实体作为答案返回给用户。例如,输入故障名称,知识图谱经过分析、推理、比较,返回该故障所需采取的排故方案以及建议措施。在一定程度上丰富维修手段、提高维修效率。维修决策查询及结果显示界面如图8、图9所示。
4 结语

Fig.7 Maintenance personnel login page图7 “维修人员”登录界面

Fig.9 Result display page图9 结果返回界面
事件抽取作为自然语言处理领域的热点和难点,近年来得到了广泛研究与应用。本文对事件抽取主要方法进行全面梳理,并对各类方法进行比较分析。在此基础上,将事件抽取技术应用于飞行器维修领域进行案例研究,抽取飞行器维修事件信息,构建飞行器维修知识图谱,并对飞行器维修图谱及其应用进行了可视化展示。基于大量调研与实验发现,与资源丰富的领域和深度垂直领域相比,飞行器维修领域中的可用资源较少,联合使用多份数据集、减少资源消耗、挖掘复杂语境中的事件是未来潜在研究点。
猜你喜欢
凤凰动漫(军事大王)(2022年1期)2022-04-19 11:35:10
少先队活动(2020年12期)2021-01-14 01:47:40
电子制作(2018年2期)2018-04-18 07:13:25
中成药(2017年3期)2017-05-17 06:09:01
韶关学院学报(2017年4期)2017-04-13 20:25:22
海外华文教育(2016年3期)2017-01-20 08:22:14
领导科学论坛(2016年9期)2016-06-05 14:59:58
小朋友·快乐手工(2015年5期)2015-06-06 00:46:12
江西师范大学学报(哲学社会科学版)(2014年1期)2014-09-05 07:44:12
杂草学报(2012年1期)2012-11-06 07:08:33
