
数据驱动的智能车个性化场景风险图构建*
2023-03-08 05:53崔格格吕超李景行张哲雨熊光明龚建伟
汽车工程 2023年2期
崔格格,吕超,李景行,张哲雨,熊光明,龚建伟
(北京理工大学机械与车辆学院,北京 100081)
前言
据美国国家公路交通安全管理局(national highway traffic safety administration,NHTSA)调查显示,约94%的交通事故是由人类驾驶员造成的,其中95%的致命交通事故是由不安全的驾驶行为造成的[1-2]。开发智能车辆危险预警辅助功能,针对场景中的潜在风险及时警示驾驶员,有望减少事故的发生。由于驾驶员存在经验与个性的差异,将针对特定驾驶员训练的风险识别模型应用于具有不同风险理解模式的其他驾驶员身上,必然会引起人机冲突,可能引起危险识别异常或导致驾驶员忽视警告[3-4]。如何对动态交通场景进行理解和建模,并实现驾驶员个性化危险场景识别功能已经成为当前研究的热点。
个性化危险场景识别问题的关键在于建立驾驶员个性化场景危险程度评价机理与场景特征之间的映射关系。在前期研究中,针对驾驶员个性化的研究主要采用问卷调查、驾驶模拟器仿真和志愿者观看录像并评分等方法[5]。Wang 等[6]结合自然驾驶研究和驾驶员态度问卷(driver attitude questionnaire,DAQ)建立驾驶风险评估模型。Asadamraji 等[7]使用驾驶模拟器研究驾驶员特征与道路危险感知敏感性之间的关系。Moran 等[8]利用观看危险场景视频时的时间反应研究驾驶员特性。在上述方法中,问卷法与打分法存在信息不全面且主观臆断性强的问题,仿真法存在不能真实反映道路交通状况问题。
针对行驶场景建模问题,需要尽量充分地提取传感器获得的场景特征信息对场景进行表示。前期研究多采用基于多模态数据的特征向量对场景进行表征[9-10],但相关方法缺少对动态要素间交互关系的建模,未能充分考虑行驶场景中交通参与者复杂交互行为可能对主车造成的间接危险,这将会降低模型对危险场景识别的效果。为挖掘复杂交通场景中动态要素间交互关系,使用图表示学习(graph representation learning,GRL)的方法被提出。与传统的数据表示方法相比,图模型具有表示不同对象之间关系的能力,已经在人体动作识别[11]、图像场景理解[12]、推荐系统[13]、社交网络分析[14]等领域得到了越来越多的关注。在交通领域,Wang 等[6]提出一种基于图模型的多关系图卷积网络(multi-relational graph convolutional networks,MR-GCN),首先应用图模型研究车辆与周围代理间的交互关系。Yurtsever等[15]提出一种基于图方法的通用轨迹预测框架,对多个异构、交互式的代理进行建模,提高了模型在预测误差方面的性能。
本文中提出一种数据驱动的智能车个性化场景风险图构建方法,主要贡献在于:(1)提出基于数据驱动的驾驶员危险场景评价算法,通过对驾驶员操作特征进行聚类获取驾驶员个性化危险场景评价标签;(2)提出一种基于图表示学习的动静态要素特征提取及场景图构建方法,对主车视野范围内的动静态要素属性及要素间的交互关系进行表征;(3)应用图核方法(graph kernel method)[16]对图表示数据的相似性进行度量,并基于嵌入核矩阵的支持向量机(support vector machine,SVM)模型构建分类器,最后基于不同驾驶员的实车数据,验证模型和算法的有效性。整体方法框架如图1所示。
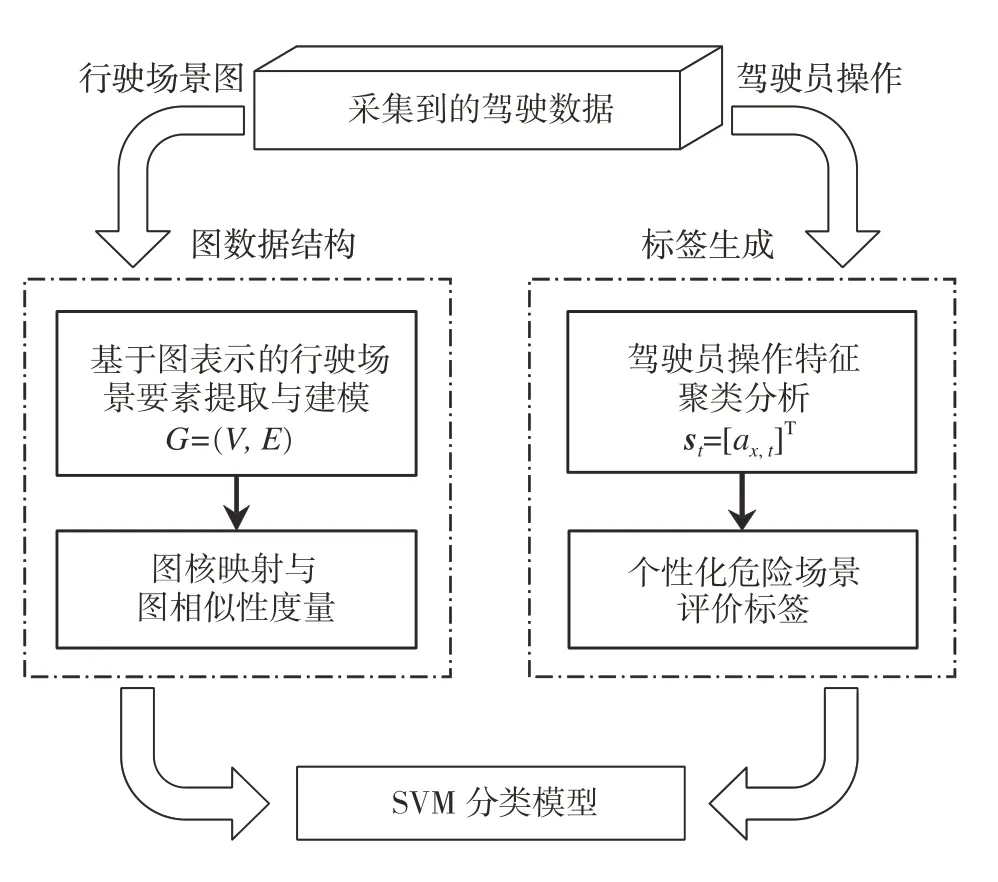
图1 数据驱动的智能车个性化场景风险图构建方法
1 基于图表示的行驶场景建模
为表征行驶场景中多交通参与者的复杂交互行为对主车造成的间接危险,需要对驾驶员视野范围内的行驶场景进行建模。由于行驶场景是动态变化的,所以在对行驶场景建模时,存在交通参与者的数量及其间交互关系不断变化的问题。因此,本文中基于图表示方法对行驶场景建模,引入图结构数据对危险行驶场景进行特征提取。定义行驶场景图模型为无向节点标记图,无向图表示成对节点间的边连接是双向的,节点标记图表示该图模型的节点含有标签。记一帧行驶场景所形成的图为G=(V,E),它包含一组由动态要素定义的节点V={v1,v2,...,vn},一组由不同动态要素间的交互关系定义的边E⊆V×V。该图的大小对应于节点个数|V|,边的个数记为|E|。图模型通过标签分配函数lV将标签集ΣV中的标签分配给图中对应的节点,函数lV记作
1.1 基于动态要素建模的场景图模型节点定义
在城市结构化道路中,路面与车道线限定了车辆通行区域。同时,受交通规则约束,机动车除换道行为外只可以在车道内行驶,因此车辆在城市道路环境下的行驶轨迹是结构化的。从城市道路的鸟瞰图观察,车辆作为动态要素,可以自然地被定义为图模型中的节点。此外,在行驶场景建模问题中,需要研究主车与周边车辆的交互关系,因此主车也是图模型中的一个节点。
将主车视角数据转换为以主车为坐标系原点的城市道路鸟瞰图,如图2(a)和图2(b)所示。由于主车视角数据由车载前置摄像头采集,所以限定所生成的鸟瞰图范围为主车的前视方向,鸟瞰图面积由车载传感器的检测范围决定。鸟瞰图的生成范围随主车的移动而动态变化,认为主车始终处于鸟瞰图的下方居中位置。图中节点由vi表示,如图2(c)所示。所有节点构成图模型节点集合V,∀vi∈V。
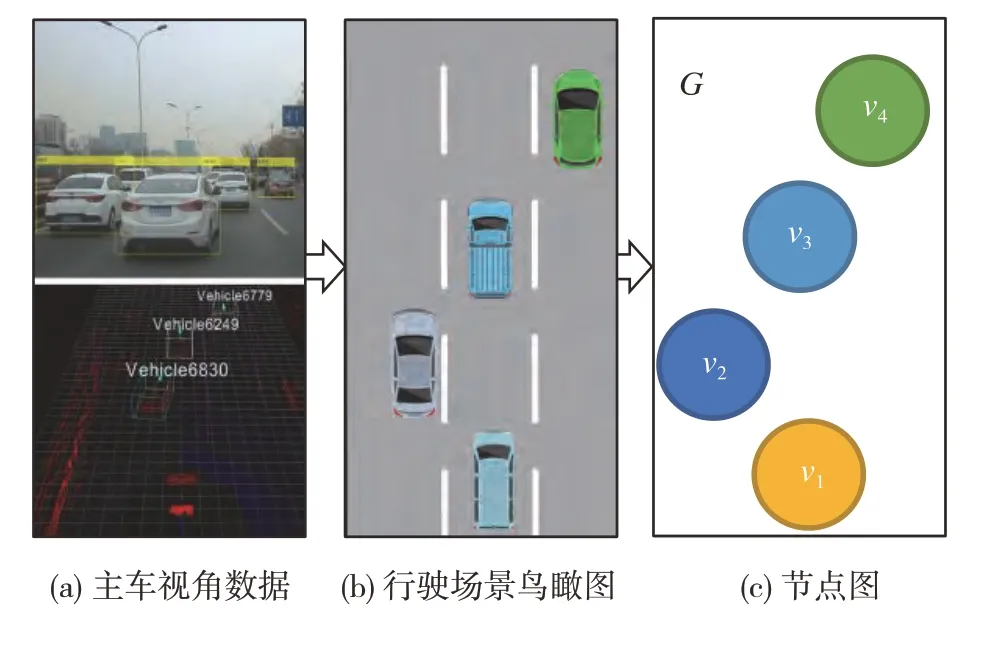
图2 图模型节点生成示例
1.2 基于静态要素建模的场景图模型节点标签定义
车道线在城市道路环境中起到车辆引导和路面划分的作用,因此将车道线作为行驶场景静态要素引入图模型具有重要意义。
基于车道线分布生成城市道路鸟瞰图网格划分。在鸟瞰图中,定义主车直行时垂直车身长度方向指向右侧为X轴正方向,主车直行时的行车方向为Y轴正方向。在X方向上,由于真实交通场景中的车辆碰撞事故一般发生在相邻的两个车道之间,所以本文以车载传感器检测出的车道线为基准,将鸟瞰图沿X轴分为3 条车道,分别为主车所在车道及紧邻两车道。在Y方向上,将车道线等间隔划分为m段,将路面划分为3 ×m的网格,其中,Ld为由车载传感器基本参数确定车辆最远检测距离,为常见轿车平均长度。为正常通行路段上同一车道内车辆之间的平均间隔距离。
根据图的网格划分结构,将交通参与者的连续位置信息离散化,如图3(a)和图3(b)所示。综合考虑车辆所在网格中的离散化位置坐标x、y,以及周边车辆对主车的相对速度vi进行编码,构造图模型的节点标签集ΣV。定义节点标签编码为
将生成的图模型节点标签记作li,编码结果如图3(c)所示。
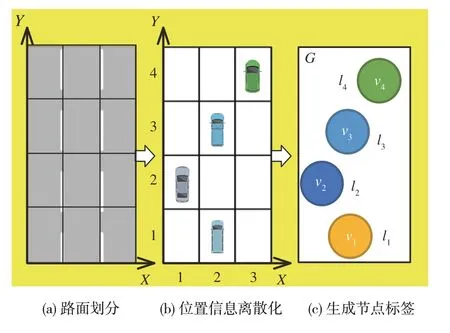
图3 图模型节点标签生成示例
1.3 基于动态要素交互关系的行驶场景图模型边定义
在图模型中,两节点之间有边连接,代表两节点之间存在联系,在行驶场景图模型中,将这种联系定义为车辆之间存在的潜在碰撞关系,利用邻接矩阵表示这种边连接。令行驶场景图模型的邻接矩阵为A∈{0,1}N×N,如果节点i和节点j之间存在边连接,则Ai,j=Aj,i=1,反之为0。为实现上述边连接的唯一表示,需要基于已划分网格定义网格位置编码,对节点间的邻接矩阵进行表征。对1.2 节中生成3 ×m的路面划分网格图由(1,1)位置起始,从“1”开始依次编码,设所有编码值的集合为H,则i,j∈H。以生成网格规模为3 × 4的行驶场景为例,编码结果如图4(a)所示。在城市道路环境中,相对距离是车辆之间发生碰撞可能性的最直观度量,认为两车距离越近,它们碰撞的概率越大。同时,因为车辆之间的碰撞一般发生在相邻两车道之间,认为被车道隔开的两车之间不存在潜在碰撞关系。因此,在网格位置编码的基础上,以每辆车为中心的3 × 3网格范围内存在的车辆被认为与中心车辆有边连接。同时,由于碰撞是相对的,所以所建立的边连接是双向的。将行驶场景图模型中的边记作ei,图模型边的生成过程如图4(b)和图4(c)所示。
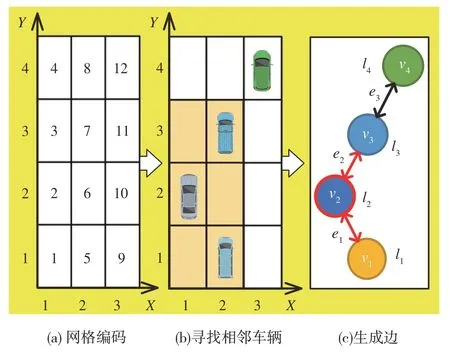
图4 图模型边生成示例
2 基于图核的危险场景识别模型
在完成行驶场景建模与图数据特征提取后,本文中提出了一种基于图核方法的危险场景识别模型。首先利用核函数对图数据特征进行从低维到高维的映射,将其结果作为训练场景分类器模型的输入。然后将分析得到的危险程度评价划分为离散的危险等级,作为训练场景分类器模型的标签。最后利用所得输入特征与评价标签训练基于线性SVM模型的危险场景识别模型。
2.1 基于图核方法的图相似性度量
利用图核方法度量图数据的相似性。图核方法既保留了非线性图数据结构具有的代表性,又结合了基于核方法的分辨能力,因此该方法能够有效地将图数据特征投影为线性机器学习方法能够处理的数据形式,从而实现对图相似性的度量。
将图核定义为图空间G上一个对称的、半正定的函数,该函数可以表示为某个希尔伯特空间H 中的内积。对给定内核k,存在从图空间G到希尔伯特空间H的映射:ϕ(Gi):G→H,使对于所有Gi,Gj∈G而言,k(Gi,Gj)=由图核定义的特征空间及其映射如图5所示。
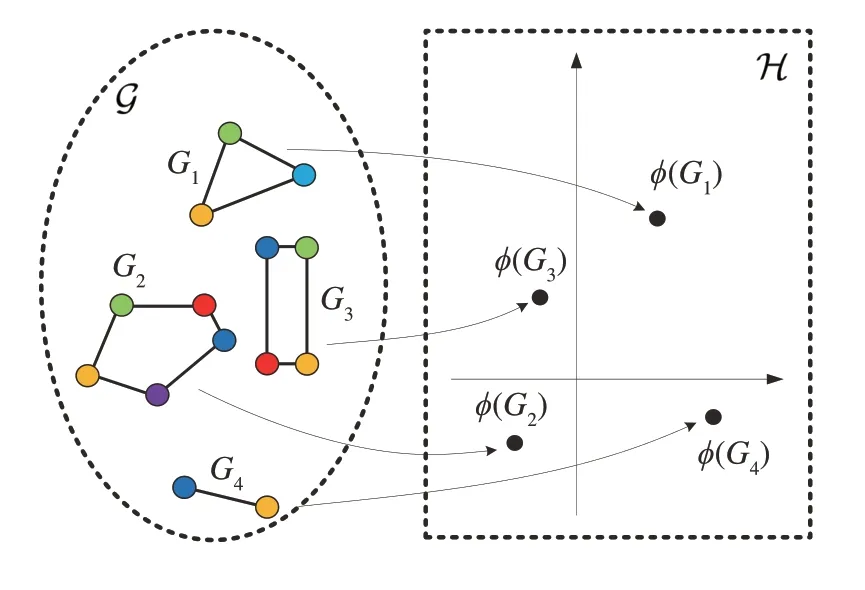
图5 由图核定义的特征空间及其映射
图核的应用包括以下两个步骤:第1步,选择合适的图核,将图的内积投影到高维希尔伯特空间H中获取抽象特征,构建核矩阵;第2步,用线性SVM模型进行训练[17],计算特征空间中的最佳流形嵌入。本文所考虑的危险场景识别问题为图层面的分类问题,采用对图进行比较的图核对行驶场景图数据的相似性进行度量。这类图核包括基于路径计算的最短路径图核、基于邻域聚合计算的邻域哈希图核等。
2.1.1 基于路径计算的最短路径图核
对于图数据,最短路径图核(shortest path kernel,SP Kernel)将每张图分解为最短路径的组合,并根据每张图的最短路径长度和路径端点的节点标签在不同图结构间进行比较[18],其时间复杂度为O(n4),可分解为如下步骤。
步骤1:将输入图转化为最短路径图。输入场景图G=(V,E),其中,V为输入图节点集合,V={v1,v2,...,vn},E为边集合,E={e1,e2,...,em}。在输入图G中,通过行走路线连接的所有节点之间都存在一条边。根据输入图结构创建其最短路径图S=(V,Es)作为新图,图S所包含的节点集与图G相同,边集是图G边集的子集。在新图转换过程中,该算法为最短路径图S的所有边分配标签,每条边的标签即其在原图G中端点之间连接路径的最短距离。
步骤2:计算图核。给定两个图G和G',它们对应的最短路径图分别是S=(V,E)和S'=(V',E')。定义最短路径核为
式中:ke为用于比较最短路径长度的核;kv为用于比较节点标签的核。ke可以使用dirac 核或布朗桥核[19],而kv通常使用dirac核。
2.1.2 基于邻域聚合计算的邻域哈希图核
邻域哈希图核方法(neighborhood Hash kernel,NH Kernel)是邻域聚合算法中的典型代表。该算法通过更新输入图的节点标签并计算它们的共同标签数量,来度量图之间的相似性,可分解为如下步骤。
步骤1:生成位标签。输入场景图G=(V,E),令函数ℓ:V→∑将节点集V映射到一个离散节点标签集∑,对输入图G的任一节点v,ℓ(v) ∈∑为节点v的标签。将每个离散节点标签转换为位标签,位标签是一个由d位数组成的二进制数组,即
式中:b1,b2,…,bd∈{0,1};d为常数并且满足2d-1 ≥|∑|。
步骤2:生成由邻域聚合表示的新节点标签。邻域哈希图核更新节点标签的方法可分为简单邻域哈希运算和计数敏感的邻域哈希运算。给定一个有位标签的输入图G=(V,E),简单邻域哈希运算使用逻辑运算中的位移运算(rotation,ROT)与异或运算(exclusive OR,XOR)对节点标签进行运算。输入一个d位的数组s=(b1,b2,…,bd),定义其位移运算ROTo为
即将其最后的o位数据向左移动o个位置,并将最初的o位数据移动到最右端。定义两个位标签si和sj之间的异或运算为
若位标签si和sj的两个值相同,则式(7)结果为1,反之为0。
对输入图中任意节点v及其邻域节点形成的集合N(v)={u1,u2,…,ud},计算节点的简单邻域哈希值NH(v)如下:
由于简单邻域哈希运算不考虑邻域节点标签集排序问题,可能产生潜在的哈希碰撞。即两个具有不同邻域点集的节点产生了相同的邻域哈希值,这会影响图核计算时的正半定自由度,从而导致图结构映射错误。为解决这个问题,在计算节点的邻域哈希值时,可以使用计数敏感的邻域哈希运算。该运算首先使用排序算法对齐邻域节点标签集N(v),然后提取N(v)中的特征标签,得到节点特征标签集set{ℓ1,ℓ2,...,ℓl},其中l为特征标签数。计算每个特征标签出现次数o,并据此对特征标签进行位移运算:
式中:ℓi为初始标签;ℓ'i为更新标签。计算节点的计数邻域哈希值CSNH(v)如下:
步骤3:计算图核。给定两个图G和G',使用简单邻域哈希运算或计数邻域哈希运算对两个输入图的节点分别运算1,2,…,h次后,两个输入图分别更新为G1,G2,…,Gh和G'1,G'2,…,G'h,以两个输入图的距离度量定义的邻域哈希图核为
式中:c为两个图共同的标签数量;h为运算执行次数;|V|和|V'|分别为图G和G'的节点总数。函数κ(G,G')用于更新后节点的比较。核函数kNH(G,G')是正半定的[20],通常被用作离散值集合之间的相似性度量。
2.2 基于SVM的危险场景分类
2.2.1 驾驶员个性化危险场景评价标签
由于年龄、性别、驾驶风格和经验不同[21],不同驾驶员对风险场景的识别能力存在差异。为了减少高级驾驶辅助系统(advanced driving assistance system,ADAS)的人机冲突,提高辅助系统的效率,提出构建个性化的辅助系统[22]。个性化ADAS 的设计体现在驾驶员个性化危险场景评价标签的生成。在本文中,危险场景被定义为可能会发生车辆碰撞等事故的行驶场景。提出一种基于驾驶员操作数据的个性化危险场景评价方法,通过对驾驶员在遇到危险场景时的驾驶数据进行分析,基于聚类生成驾驶员对危险场景的个性化主观评价标签,其流程如图6所示。
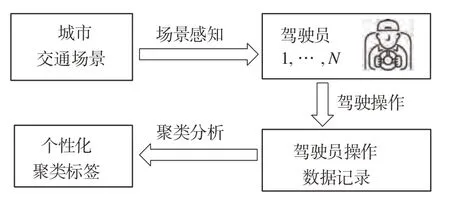
图6 基于驾驶员操作数据的个性化危险场景评价生成
在训练危险场景识别模型时,需要针对不同驾驶员,输入对应的个性化危险场景评价标签,该评价标签可以通过对不同驾驶员的驾驶行为特征分别研究获得。为对比不同行为特征对聚类效果的影响,利用驾驶员操作数据构建两种操作特征向量s1,t和s2,t:
式中:ax,t为车辆纵向加速度;ay,t为车辆横向加速度;θt为车辆前轮转角;bt为制动信号;ut为油门开度信号。
在正常驾驶情况下,驾驶员在遇到危险场景时会采取紧急制动和/或转向操作来规避危险,因此认为车辆加速表征驾驶员判断行驶场景相对安全。将加速度为正值的数据取出,并定义其类别为“不危险”,选取纵向加速度为负值的场景进行聚类分析。输入特征s1,t构建的特征集矩阵S1中只包含车辆的纵向加速度,为真实反映车辆的加速和制动情况,不对矩阵S1进行数据归一化操作。对于由输入矩阵s2,t构建的特征集矩阵S2,为使数据样本的所有特征量有相同的权重,对每个特征分别进行归一化处理。本节所使用的归一化操作是将每个特征按照式(15)所示的方法转换为-1到1之间:
式中:smax为特征中的最大值;smin为特征中的最小值。下文使用norm(S2)代表S2。
使用K-means 聚类方法对特征集矩阵S1和norm(S2)分别进行聚类操作,依据肘部法则和轮廓系数(silhouette coefficient,SC)[23]分析聚类效果,确定聚类类别数K值。在驾驶员数据集D=中,si∈RD为D维的驾驶员特征矢量,N为样本数量。K-means算法[24]将D划分为K个相异无重叠类群,每个数据点只属于一个类,并尽量提高类别内部相似性与类别间差异。上述优化目标可以描述为,通过寻找最佳的分类,使得代价函数J取得最小值:
式中:对数据点si,若它属于类群Ck,则ωk=1,反之,ωk=0;μk为类群Ck数据的中心点。
为选取理想K值,本文对统计量残差平方和(residual sum of square,RRS)应用肘部法则。首先绘制RSS 相对于类别数K的函数,然后选择曲线“肘部”(明显弯折处)对应的K值,作为聚类类别数。RSS 通常用于统计数据集中预测值与真实值之间的误差大小,对数据集D中任意数据点si,RSS的计算公式为
轮廓系数SC为所有样本轮廓值的均值。对任意数据点si,将轮廓值记作Sil(si),表示一个物体与它所属集群的相似程度和与其他集群的相似程度的比较,值越高,数据点与其聚类越匹配。Sil(si)计算公式为
式中:a(si)为数据点si与同一聚类中所有其他数据点的平均距离;b(si)为数据点与任何其他聚类中所有点的最小平均距离;d(si,sj)为数据点si与数据点sj之间的欧氏距离。
2.2.2 基于SVM的危险场景分类模型构建
在使用图核方法将图的内积投影到高维希尔伯特空间后,通过计算相似性或度量距离,解决图之间的比较问题。进而引入监督学习方法,针对具体驾驶员,基于SVM 模型训练危险场景识别模型。首先采集驾驶员操作数据,对于所获得的数据集Dd=,si∈RD为D维的驾驶员特征矢量,是经过图核计算的从行驶场景中提取的图结构特征数据,yi∈{-1,1}为SVM 模型输出,是基于聚类方法获得该驾驶员对危险程度的评价标签。经训练可得对应驾驶员个性化特征的危险场景识别模型f(s)。输出为相应有限且离散的预测量,与有限的危险场景类别对应。对于线性SVM分类器,其表达式为
式中:w为超平面Ψ:wTs+b=0 的法向量;b为截距。二者为待定参数,由以下优化目标决定:
式中参数C用于控制式(22)中,由第1 项决定的模型复杂度与第2 项决定的经验风险之间的平衡。本文中利用基于核的图核方法,将SVM 模型扩展到非线性情况。
3 实车数据实验验证
为验证基于图表示的个性化危险行驶场景识别模型的有效性,本文中利用实车数据采集平台,采集了驾驶员操作数据与真实行驶场景数据,并在实车数据上开展了评估实验。本实验利用无监督学习方法对危险场景中的驾驶员操作数据进行聚类,从而获取了个性化危险评价标签;利用所提出的基于图表示的个性化危险场景识别方法对真实行驶场景的危险程度进行评估,得出了危险场景识别结果,并开展与传统特征向量表示方法的对比实验,验证了模型的可行性与有效性。
3.1 数据采集平台建立与数据获取
实验使用的数据采集平台如图7 所示。该平台以比亚迪唐五车型为车辆平台,搭载了HDL-32 线激光雷达,一台地平线公司量产车规级单目摄像头,一套惯性导向系统与一台差分GPS。车辆自身传感器信息与驾驶员操作信息通过解析车辆底层CAN总线协议获得。车载平台上传感器数据与车辆底层数据都在ROS 系统下进行实时数据接收与保存,接入系统的不同帧率数据已完成对齐与同步,用于离线分析要求。

图7 数据采集平台
数据采集在城区环境下进行,采集地点位于北京市中关村大街、魏公村十字路口、北三环西路、北四环西路以及魏公村路段,驾驶路线全长11.2 km,行驶时间约90 min。数据包含了路况复杂、交通参与者众多、道路条件多变等容易导致交通危险发生的典型因素,满足对危险行驶场景研究的要求。
3 位参与数据采集的驾驶员基本信息如表1 所示。经过预处理,从每位驾驶员原始驾驶数据中提取出25 组数据,共75 组。每组数据的场景帧数在80~170 帧之间,3 位驾驶员共获得4 500 帧行驶场景自然驾驶数据。
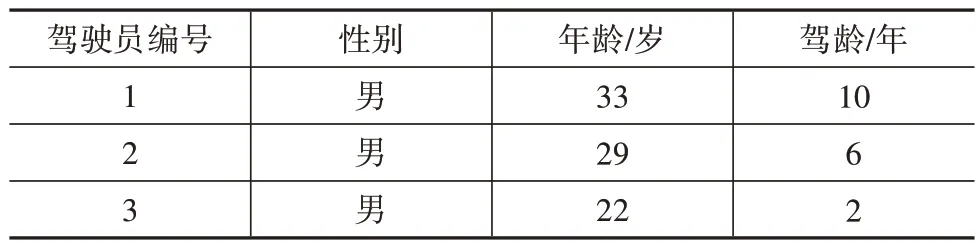
表1 驾驶员基本信息表
3.2 个性化危险场景识别
3.2.1 驾驶员个性化危险程度评价标签获取
驾驶员操作特征选择对个性化危险程度评价标签生成有重要影响,使用K-means 聚类方法对驾驶员1 的特征矩阵S1和norm(S2)分别进行K值递增的聚类,计算聚类结果的残差平方和RSS和轮廓系数SC如表2所示,将结果绘制为折线图,如图8所示。
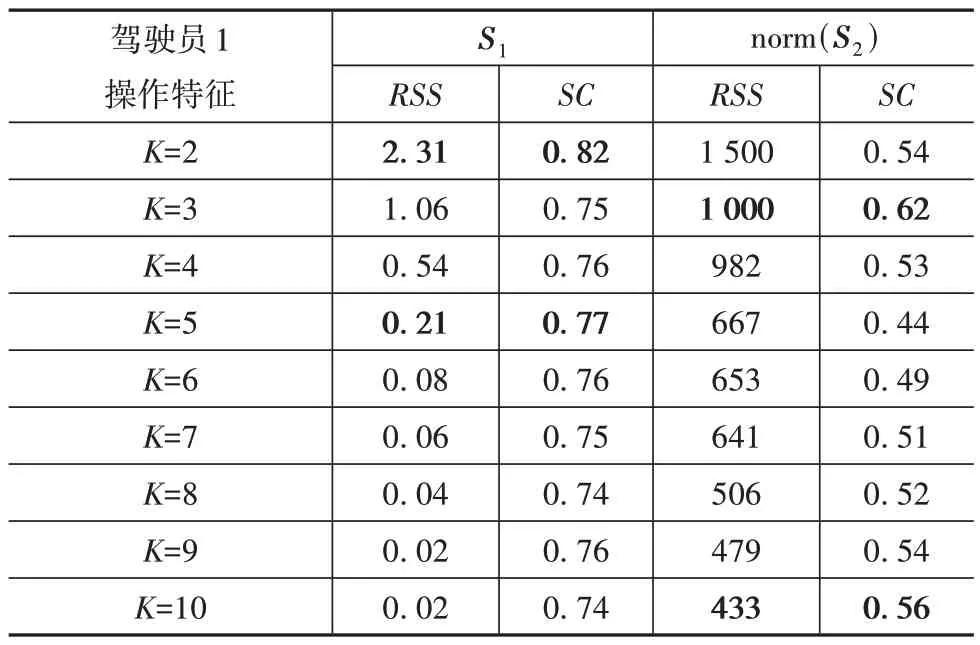
表2 驾驶员操作数据聚类特征选择表
由图8 可知:特征矩阵S1的RSS曲线在K=2 时出现明显弯折,同时SC曲线取得最大值;特征矩阵norm(S2)的RSS曲线虽然在K=2 时出现较大变化,但此时SC值没有取得最大值,说明此时聚类结果中的类别具有较高的簇内收敛性,但类别之间的差异性较低,初步表明特征norm(S2)对应的数据点之间没有明显的区别。
由于norm(S2)的RSS曲线没有出现明显弯折,进一步选择图8(b)中norm(S2)的SC曲线出现最高值和次高值时对应的K值再次聚类,做轮廓值分析,并选择图8(a)中S1相应数据聚类作为对比,绘制4组轮廓值分布图,如图9 所示。其中,轮廓值小于零表示数据被错误分类到相应类别中。由图9 可知:对于S1,SC取最高值时,各分类分布均匀且没有小于零的数据,SC取次高值时,两个类别存在数据小于零,有分类错误;对于norm(S2),两种SC取值对应聚类结果轮廓图都呈现数据分布不均匀的现象,且都有部分类别存在数据小于零的明显分类错误。对比上述4 组聚类结果可知,在特征中添加横向加速度等信息没有增强模型判别驾驶员风险感知的能力,同时削弱了纵向加速度数据的分布特征。综上所述,使用车辆的纵向加速度构造的特征矩阵S1聚类结果更优,更能表征驾驶员对于行驶场景危险程度的主观评价。
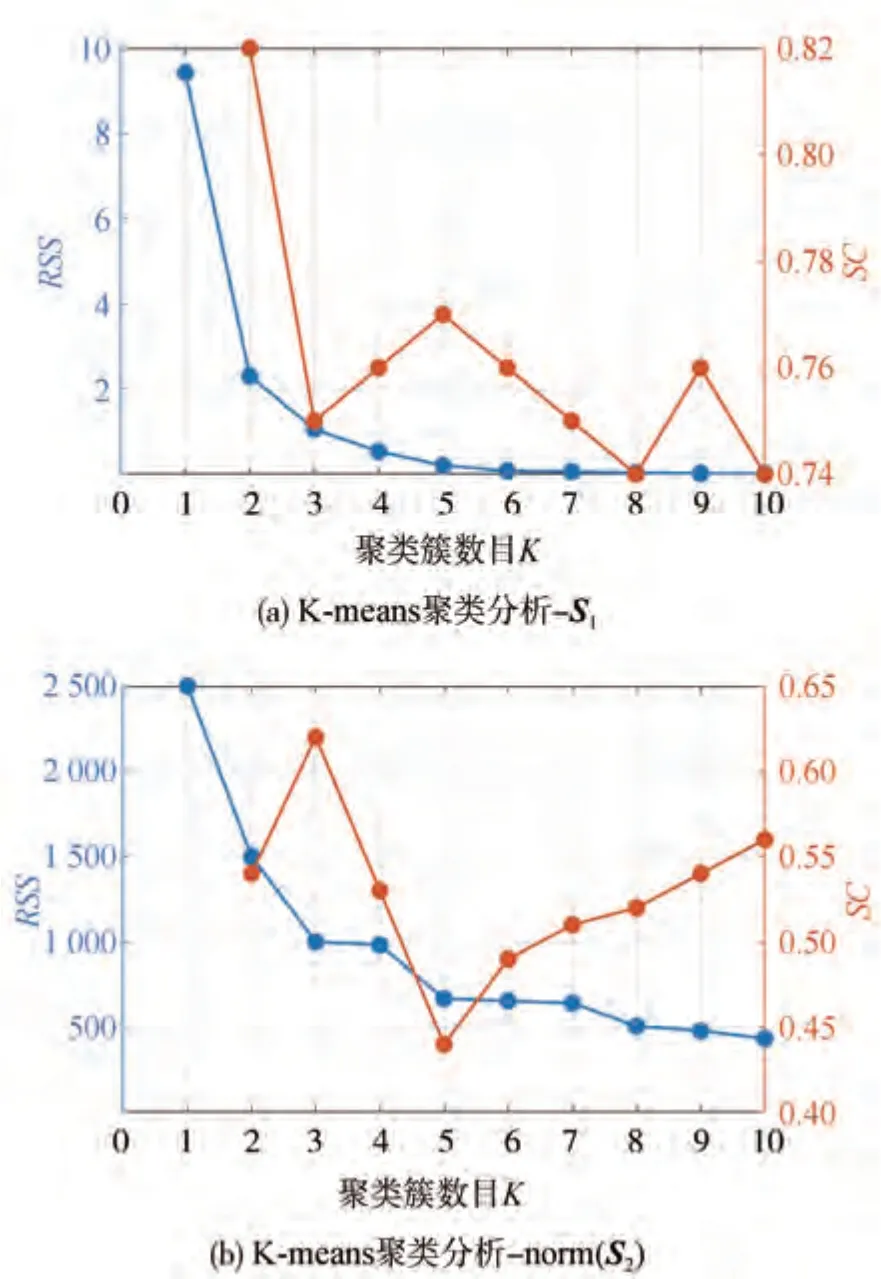
图8 对特征矩阵的K-means聚类效果分析
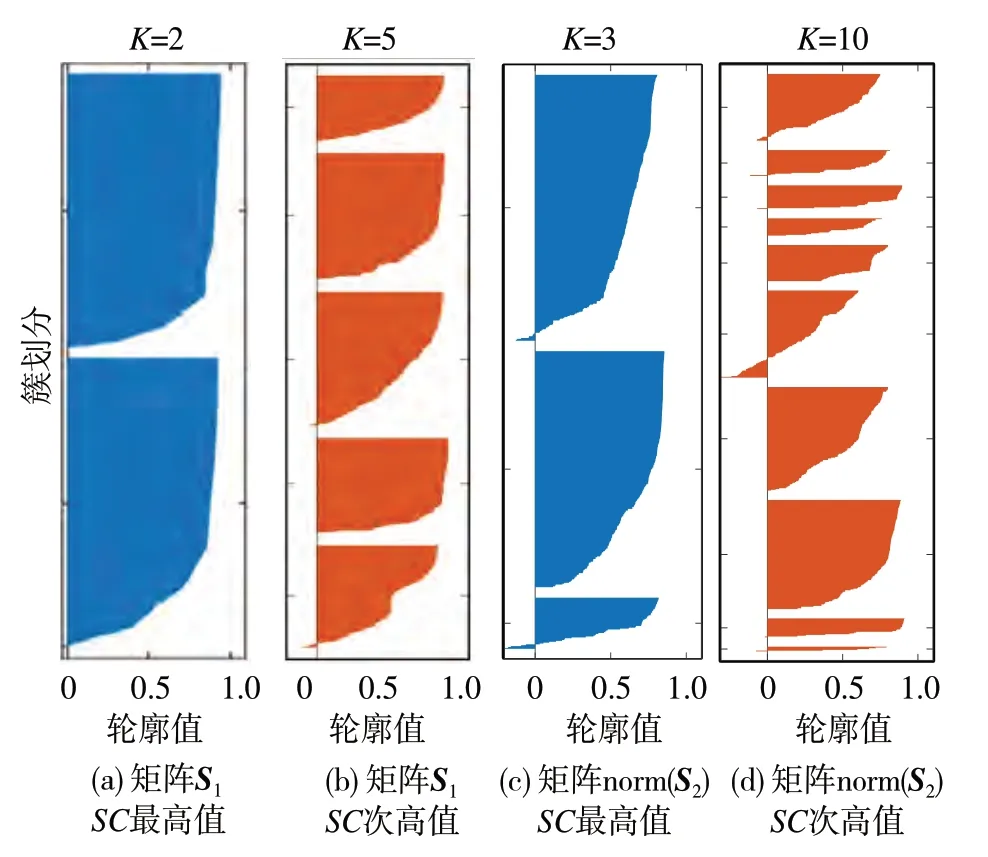
图9 驾驶员1两种特征矩阵对应操作数据轮廓图
确定以S1为聚类特征后,使用K-means 聚类方法对不同驾驶员的特征矩阵S1进行K值递增的聚类,计算对应的RSS和SC值。计算结果如表3所示,RSS转折点与SC最大值由粗体标出。由表3 可知,对驾驶员1和驾驶员2,K=2,对驾驶员3,K=5。
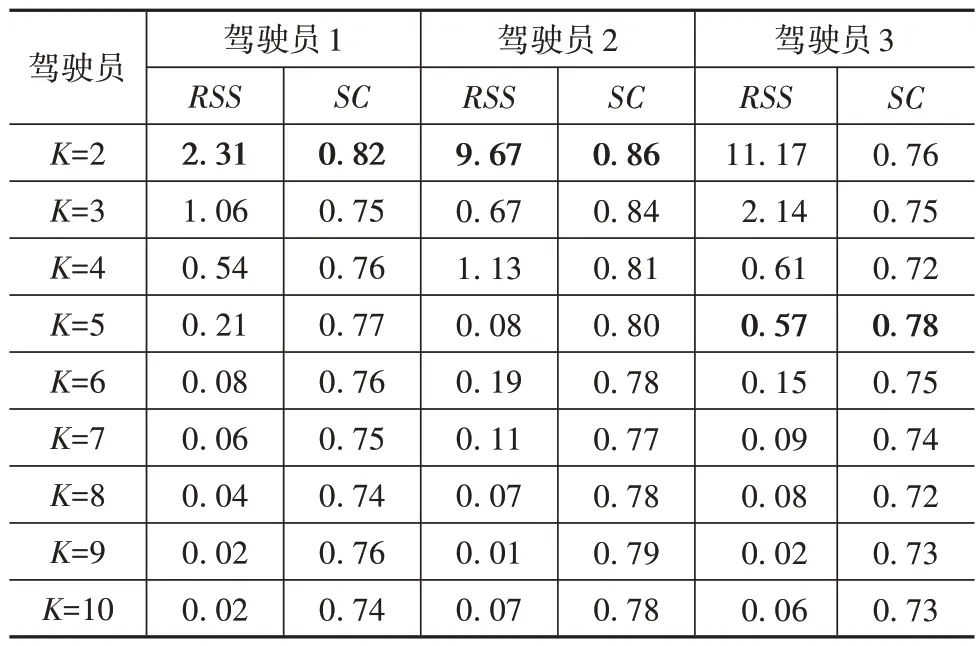
表3 驾驶员操作数据聚类K值选择表
对不同驾驶员,首先将纵向加速度为正值的场景的危险场景评价标签记为危险程度1(表示不危险),然后依据所选K值,对特征矩阵S1进行聚类,生成其他评价标签。获取表1 中驾驶员1、2、3 的个性化危险场景评价标签结果如图10 所示,分别分为3类、3 类和6类,场景危险程度随标签数值增加依次递增。

图10 驾驶员个性化场景危险程度评价标签聚类结果
3.2.2 行驶场景图表示数据提取
获取驾驶员个性化危险场景评价标签后,将已采集的真实行驶场景数据转换为鸟瞰图,并从中提取图表示数据。首先对感知数据做预处理,过滤由车载传感器检测不稳定性等因素引起的车道线检测异常的数据,对余下车道线坐标序列做平滑处理。其中,车道线坐标由主车轨迹及主车与所在车道两侧的车道线间横向距离计算获得,主车轨迹及与车道线间的距离由车载传感器获得。基于上述平滑后车道线坐标序列将路面沿X方向划分为3 车道。由于所选车载传感器最远检测距离Ld=100 m,在采集的数据中,轿车平均车长Lˉveh≈5 m,同一车道内车辆之间平均间隔距离≈2 m[25],所以2.5 ≤m≤10。为尽可能细化网格并便于编号,取m=10,将路面沿Y方向划分为10 段。完成路面网格划分后,基于主车坐标和周边车辆与主车的相对位置坐标绘制每帧场景中全部车辆,得到行驶场景鸟瞰图。图11展示了其中一帧真实行驶场景的鸟瞰图转化结果,图中红色矩形框代表主车,蓝色矩形框代表周边车辆,点状线代表车道线,红色虚线代表以主车最前部为起始的道路沿Y方向的划分标线。
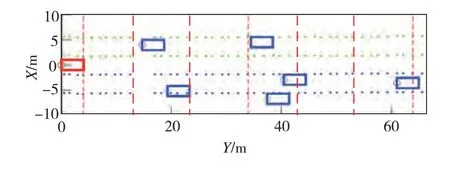
图11 基于实车数据的行驶场景网格划分与鸟瞰图生成
根据第1 节中节点、节点标签与边的定义,以网格图为依据定义图模型节点、节点标签与边。与其他所有车辆都没有边相连的车辆被视作游离节点,认为该类节点与其他车辆没有交互关系,对当前行驶场景的危险性评估不产生影响,将其从数据集中删除。记最终得到的图数据矩阵为Gt=(Vt,Et),将其作为基于图模型的行驶场景风险图构建方法所提取出的特征量。选取典型换道交互场景作为示例,从中提取图结构数据,如图12所示。
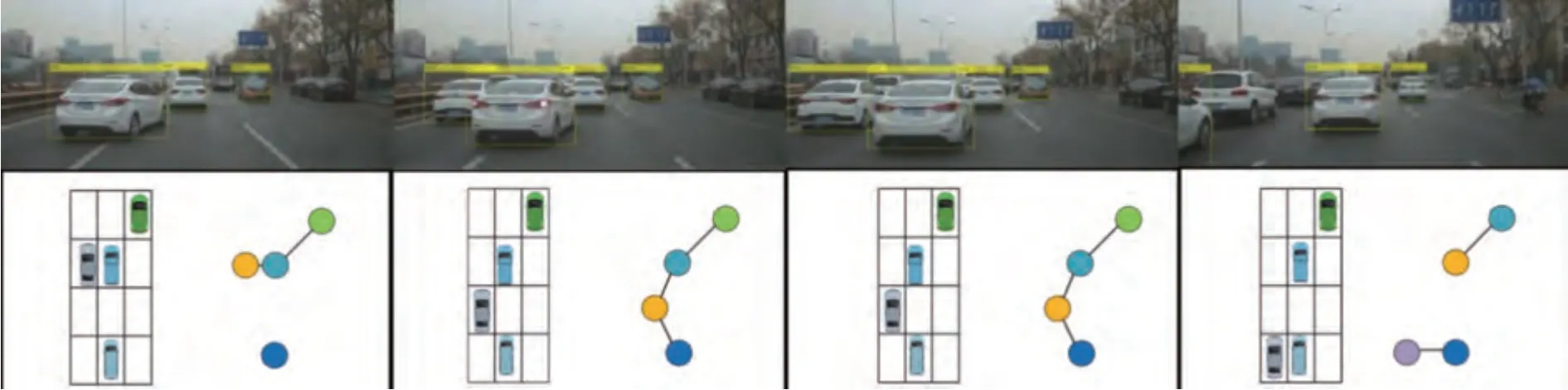
图12 典型换道交互场景图结构数据提取
3.2.3 基于图模型的危险场景识别结果分析
完成行驶场景图模型构建后,基于标签和场景特征数据训练危险场景识别模型。一方面,将基于最短路径图核和邻域哈希图核训练的SVM 模型分别命名为SP-SVM 和NH-SVM,对比基于不同计算方式的两种图核的表征效果。另一方面,将使用传统场景表示方法[26]训练的SVM 模型命名为Base-SVM,与图方法进行对比。对每位驾驶员分别进行5次重复实验,并取5 次实验结果的平均值作为最终结果,以消除偶然误差造成的影响,危险场景识别准确率如图13所示。
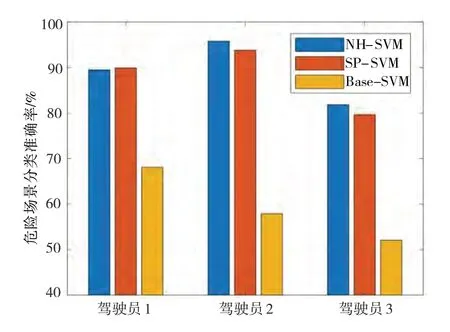
图13 危险场景识别准确率
从图13 可以看出,3 位驾驶员基于图表示方法的危险场景识别模型的准确率都在80%以上,均高于Base-SVM。其中驾驶员2 的准确率最高,NHSVM 和SP-SVM 的准确率达到了95.8%和93.8%,与Base-SVM 模型相比,准确率最高提升38.2%。与驾驶员1 和2 相比,驾驶员3 的准确率相比较低,即便如此,其NH-SVM 和SP-SVM 模型的识别准确率也达到了81.8%和80.1%。由表1 中驾驶员的基本信息可知,驾驶员1 和2 驾龄更长,这可能使其对危险场景的识别更准确,纵向加速度操作更平稳,因此危险等级评价的类别数较少,准确率更高,相较而言,驾驶员3 的危险等级评价的类别数较多,存在已采集的数据不足以让模型充分学习6 个类别的特征差异的可能。此外,从驾驶员1和2的识别准确率结果可以分析得出,随着驾驶员驾驶里程数增加和采集的数据样本数目增大,NH-SVM 和SP-SVM 的准确率也会随之提高。
本文中利用图表示方法获取行驶场景的图结构数据特征,并将其作为危险行驶场景识别模型输入的初衷在于,图结构可以反映行驶场景中动态要素之间的复杂交互信息,为提高危险场景识别模型的准确性提供可能。为分析并验证相较于使用传统向量特征表达作为输入,使用图结构数据作为输入可以提升模型对危险场景的识别效果,绘制驾驶员1的NH-SVM 模型和Base-SVM 模型的分类混淆矩阵图与分类准确率图,如图14所示。
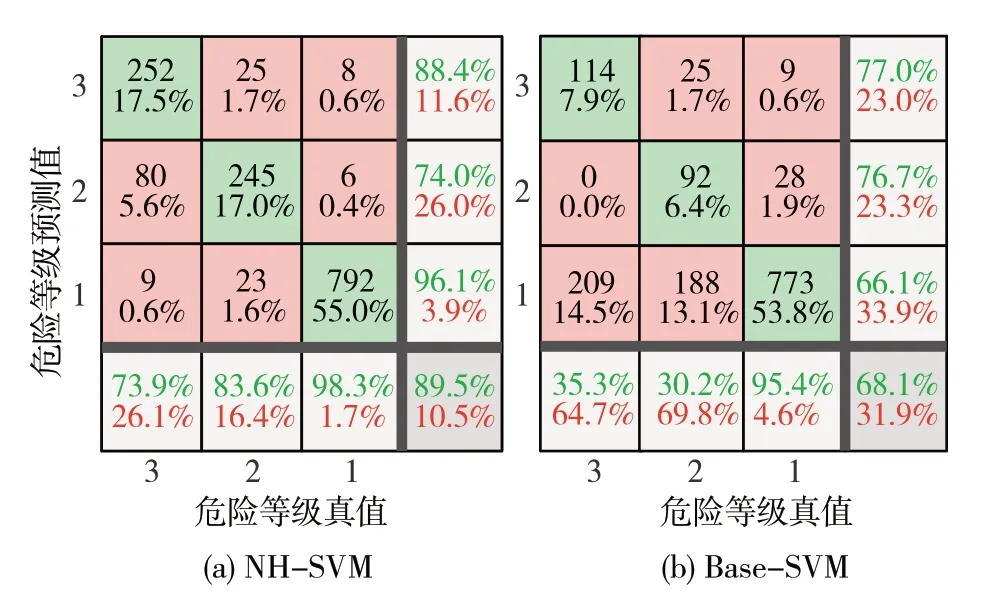
图14 驾驶员1危险场景识别结果混淆矩阵
从图中可以看出,基于传统特征向量表示的危险场景识别模型的准确率较低,其中,该模型对于危险程度更高的等级3 和2 的识别准确率只有35.3%和30.2%。这可能是因为所选特征向量仅关注了引起周边交互关系变化的某一个动态要素,而没有保留交通场景中丰富的拓扑信息。实验结果表明,将利用图表示方法得到行驶场景的图结构数据作为模型输入,可以使危险场景识别模型性能更优,更适用于高级辅助驾驶系统的危险场景识别任务。
在3.2.2 节选取的典型换道交互场景下,针对驾驶员1 对危险场景识别的结果做定性分析,绘制该场景下的驾驶员操作数据与危险程度识别结果对比展示效果,如图15 所示。图中第1 行是真实驾驶场景数据片段,第2 行是驾驶员纵向加速度数据,第3 行是基于驾驶员纵向加速度聚类分析所获得的驾驶员个性化危险场景评价。可以看出,所建立的个性化危险场景评价标签与真实道路场景能够关联对应,对于场景较为危险的视频帧,对应的驾驶员纵向加速度被聚为一类,进一步表明了纵向加速度对于驾驶员的个性化风险评价具有较好的表征能力,且基于场景风险图的个性化危险场景识别模型能够准确识别出行驶环境中的危险场景。
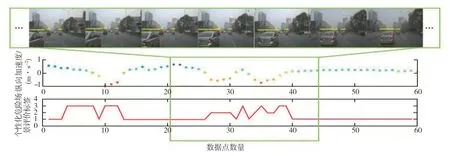
图15 驾驶员操作数据与危险行驶场景识别结果
4 结论
本文中提出了一种数据驱动的智能车个性化场景风险图构建方法,并基于场景风险图建立驾驶员个性化危险行驶场景识别模型,最后利用实车数据进行了测试验证。
(1)针对复杂交通场景表征问题,定义场景风险图及其中节点、节点标签与边的概念,并对场景中动静态要素及要素之间的交互关系建模,实现对行驶场景的结构信息与交互特征的充分表征。与基于向量表示法的建模方法相比,该方法能够更好地解决复杂城市行驶环境下交通要素数量以及要素间交互关系不断变化的问题。
(2)建立了驾驶员个性化危险评价机理与场景特征之间的映射关系。使用驾驶员操作数据聚类,生成个性化危险行驶场景评价标签,利用图表示方法获取行驶场景特征数据,基于图核方法学习场景风险图相似性,建立针对不同驾驶员特性的危险场景识别模型。
(3)基于实车数据的实验结果表明:与使用传统数据表示方法的模型相比,基于场景风险图建立的个性化危险场景识别模型有效生成了符合驾驶员认知的行驶场景危险等级,对不同驾驶员个性化风险感知的适应性得到提升,场景危险等级识别准确率提高了38.2%。
猜你喜欢
汽车实用技术(2022年14期)2022-07-30
汽车实用技术(2022年4期)2022-03-07
铁道通信信号(2019年6期)2019-10-08
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
雷达学报(2017年6期)2017-03-26
公民与法治(2016年10期)2016-05-17
公民与法治(2016年4期)2016-05-17
少儿科学周刊·少年版(2015年2期)2015-07-07
电子设计工程(2015年6期)2015-02-27
