
基于实例分割的车道线检测算法*
2023-03-08 05:53武志斐李守彪
汽车工程 2023年2期
武志斐,李守彪
(太原理工大学机械与运载工程学院,太原 030024)
前言
车道线检测是高级辅助驾驶系统乃至自动驾驶系统的关键感知技术,基于车道线检测的车道线偏离预警系统和车道保持辅助系统对于改善汽车的主动安全性及减少交通事故有着至关重要的作用[1-2]。
传统的车道线检测算法大多数依赖车道线的颜色[3-4]、灰度[5-6]、边缘[7-8]等手工特征提取,易受车辆遮挡和不良光线等因素的影响,难以适应自动驾驶实际应用的复杂场景。
随着深度学习的发展和车载处理器性能的提升,基于深度学习的车道线检测得到快速发展。相比传统的车道线检测算法,基于深度学习的车道线检测算法可以自动根据图像信息提取车道线特征,拥有更高的准确率和鲁棒性,主要分为基于分割的算法[9-11]、基于行分类的算法[12-13]和基于参数预测的算法[14-15]。
基于分割的车道线检测算法将车道线看作像素的集合并进行分类,又可以细分为基于语义分割的算法和基于实例分割的算法。基于语义分割的车道线检测将每条车道线和背景看作不同的类别进行多类别分割,将增强对车道线的感知作为研究重点。Pan 等[9]设计了一种空间卷积网络(spatial convolutional neural network,SCNN),通过捕获图像中行和列的空间关系来增强对车道线的检测效果。Hou 等[10]提出一种自注意力蒸馏(self attention distillation,SAD)模块,通过模块间输出特征的相互学习来有效地提取车道线特征。然而基于语义分割的车道线检测算法只能检测预定义且固定数量的车道线,不能灵活应对驾驶路面上数量变化的车道线。Neven 等[11]基于实例分割的思想提出了LaneNet 算法,通过对每一个像素分配一组多维嵌入向量来区分不同的车道线实例,可以在不预定义车道线数量的前提下进行多车道线检测,但其检测精度不高,且利用Meanshift 聚类算法导致后处理耗时长,无法满足自动驾驶实时性要求。
基于行的车道线检测利用车道线的形状先验,通过行方向上的分类实现对车道线的定位。Qin等[12]提出了一种超快车道线检测(ultra fast lane detection,UFLD)算法,利用行分类公式显著降低了计算成本。Yoo 等[13]提出了端到端的行分类车道线检测网络(E2Enet),并设计了一种水平压缩模块提高检测的性能。虽然利用行分类可以简化模型的输出,但其未能有效解决车道线的实例级检测问题。
基于参数预测的车道线检测将车道线用曲线方程表示。Tableini等[14]提出了PolyLaneNet,首次利用深度网络直接回归车道线曲线方程。为更好地预测曲线方程的参数,Liu 等[15]提出基于transformer 的车道线检测算法(LSTR),利用transformer 的自注意力机制来建模车道线的细长结构。虽然这类算法可以预测数量变化的车道线,但是抽象的曲线方程参数难以优化,导致其在复杂场景下的性能较差。
综合上述分析,车道线检测一方面须增强模型的感知来应对复杂的自动驾驶场景,另一方面须实现实例级车道线检测来应对道路中数量变化的车道线。因此本文提出一种基于实例分割的车道线检测算法,设计基于扩张卷积的残差模块来增强模型的感受野,并提出一种基于车道线位置的实例分割方法来实现车道线的实例级检测。
1 车道线检测网络模型设计
针对本文所提出的车道线检测算法,设计的车道线检测网络模型整体框架如图1 所示。总体结构分为编码网络和解码网络。
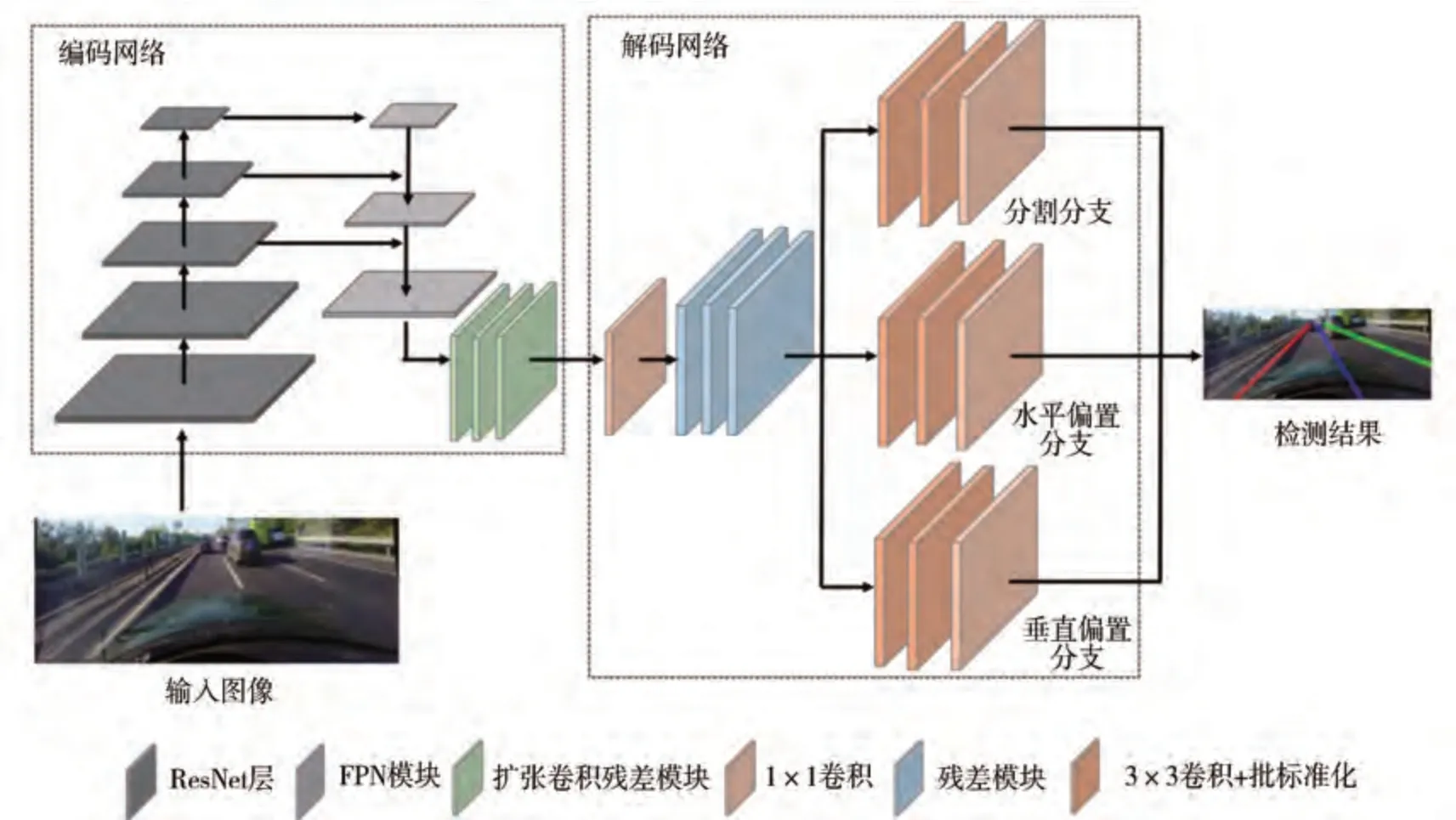
图1 车道线检测网络整体结构
1.1 编码网络
通过分析车道线的颜色和结构可知,车道线与道路边沿等具有一定的相似性,且被遮挡、磨损后会造成特征提取困难。为准确提取图像的车道线特征,须采用深度网络进行特征提取,然而深层次的网络在训练时会出现退化现象,造成网络的性能下降。为解决这一问题,残差网络[16](residual network,ResNet)提出了残差学习的网络结构,通过在网络的不同层之间增加跳跃连接(skip connection)为训练时的梯度提供了恒等映射的通道,使浅层网络信息可以快速传递到深层,在一定程度上解决了深度网络训练出现的性能退化,增强了网络提取图像特征的能力,被广泛应用于车道线检测研究。为提高车道线检测的实时性,本文中采用残差网络系列中最轻量的ResNet18 作为主干网络提取图像的多尺度特征,并在大规模数据集ImageNet[17]上进行预训练来提高特征提取效果,当输入网络的图像尺寸为800×320×3时,ResNet18 网络结构及输出特征尺寸如表1所示。
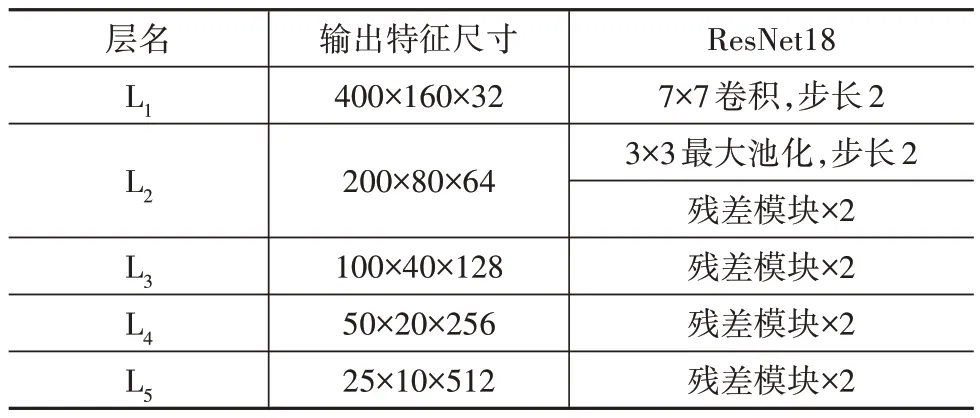
表1 ResNet18网络结构
其中残差模块结构如图2 所示。图中w0为输入残差模块的特征通道数,w为各卷积输出特征的通道数,并采用ReLU激活函数进行非线性映射。

图2 残差模块
由于车道线的细长结构,使检测网络既需要车道线的高层次语义特征,同时也需要局部的细节特征,因此采用特征金字塔网络[18](feature pyramid network,FPN)来融合多尺度的特征信息,结构如图3所示。将ResNet18的L3、L4和L5层输出的特征,首先通过1×1 卷积来匹配通道数,同时采用双线性插值匹配不同特征层的尺寸,最后输出尺寸为100×40×128的特征。
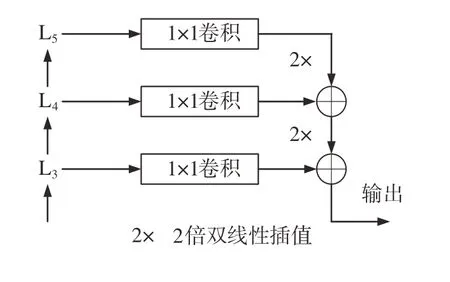
图3 特征金字塔结构
由于本文采用轻量化的主干网络,模型会存在感受范围不足的情况,因此采用扩张卷积[19](dilated convolution)来增强模型的感受野。扩张卷积的原理是在卷积中引入扩张率(dilation rate)的新参数,通过扩张率来控制卷积核各点的间距,相较于普通卷积,在卷积核尺寸相同时,参数量不变,但是扩张卷积的感受野更大,单层扩张卷积的感受野大小遵循公式为
式中:k为原始卷积核的感受野大小;kd为扩张后卷积核的感受野大小;d为扩张率。
图4 为不同扩张率的扩张卷积。如图4(a)所示,当扩张率d为1时,3×3 的扩张卷积相当于标准卷积,单层感受野只有3×3大小;图4(b)为当扩张率d为3的3×3扩张卷积,单层感受野增大到7×7大小。
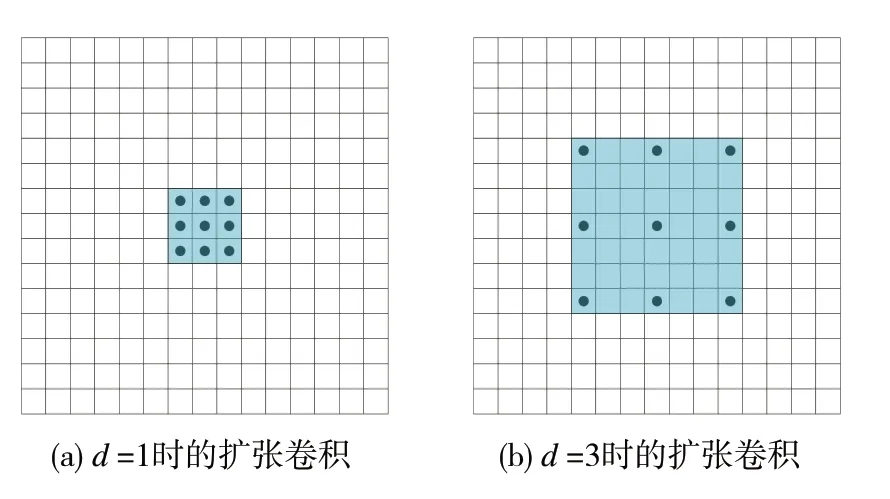
图4 不同扩张率的扩张卷积
利用扩张卷积的原理,本文中提出一种基于扩张卷积的残差模块,如图5 所示。整体上采用残差结构,并采用4层3×3的扩张卷积。虽然扩张卷积可以有效提高模型的感受野,但当采用相同或成倍数的扩张率时会存在网格效应[20],造成特征图上卷积中心点的不连续,导致像素信息的缺失,因此叠加卷积的扩张率不应有大于1的公约数,本文将4层卷积的扩张率分别设置为1、3、7 和11,采用小的扩张率来获取图像的局部信息,并利用递增的大扩张率增强中远距离车道线信息的联系。在编码网络中采用3 个扩张卷积残差模块增强模型的感受野,来提高车道线检测的精度。
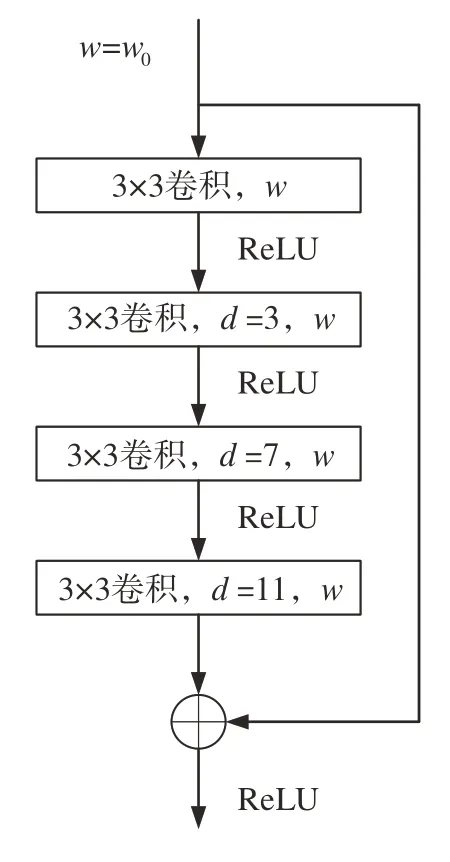
图5 扩张卷积残差模块
1.2 解码网络
解码网络负责将提取的车道线特征进行解码输出。主要由分割分支、水平偏置分支和垂直偏置分支组成。首先通过一个1×1 卷积核将通道数缩小一半,然后通过双线性插值将特征图的尺寸扩大两倍,通过3 层残差模块后分别连接分割分支、水平偏置分支和垂直偏置分支,3 个分支结构相同,都由3 层3×3 的卷积组成。本文中将各分支输出特征尺寸固定到输入图片尺寸的1/4,而不是像大多数分割模型输出高分辨率的特征,这样一方面可以简化模型的输出,提高网络的推理速度,另一方面可以提高模型后处理聚类的速度。解码网络是实现实例分割的基础,各分支的具体作用参考2.1节。
2 车道线实例分割
2.1 基于车道线位置的实例分割原理
实例分割是计算机视觉领域的一个经典任务,其不仅要区分不同类别的物体,且须区分同一类别物体的不同实例。具体到车道线检测任务,实例分割须区分车道线类别与背景类别,然后将对每条车道线实例进行区分。
为准确区分不同的车道线实例,本文中提出一种基于车道线位置的实例分割方法。首先利用模型分割分支来预测二分类的车道线分割图,通过Argmax 函数获取每一个像素的类别,属于车道线类别的每个像素视为一个车道线点,每张图片上的所有车道线点可以用一组坐标表示:
式中:P表示车道线点的集合;xi表示第i个车道线点的水平坐标位置;yi表示第i个车道线点的垂直坐标位置;F表示车道线点的最大数量。
车道线点的预测结果示意图如图6 所示。此时只能区分车道线点与背景,而不能区分车道线点的实例。由图中车道线点的空间位置分布可知,不同实例点的车道线点相互分离,已具备一定的聚类特性,但由于车道线的细长结构,使车道线点分散严重,且相邻的车道线在远处时相互聚集,不能简单地利用聚类算法对车道线点进行实例区分。

图6 车道线点分布示意图
为更好地区分不同实例的车道线点,本文算法为每个车道线点预测一个对应的聚类点,让不同实例但却相邻的车道线点对应的聚类点相互分离,并使同一实例车道线点对应的聚类点更加聚集,提高每个实例的点密度,从而更易区分不同的车道线实例。因此利用模型的水平偏置分支和垂直偏置分支,分别预测一个水平偏置图和垂直偏置图,根据车道线点位置提取出其对应每个点的水平位置偏置和垂直位置偏置,如式(3)和式(4)所示。
利用车道线点的位置和预测的水平偏置与垂直偏置来计算对应的聚类点,其原理如图7 所示。图中黑点表示预测的车道线点,红色点表示第i个车道线点经过式(5)和式(6)位置计算后对应的聚类点。聚类点的分布示意图如图8所示。
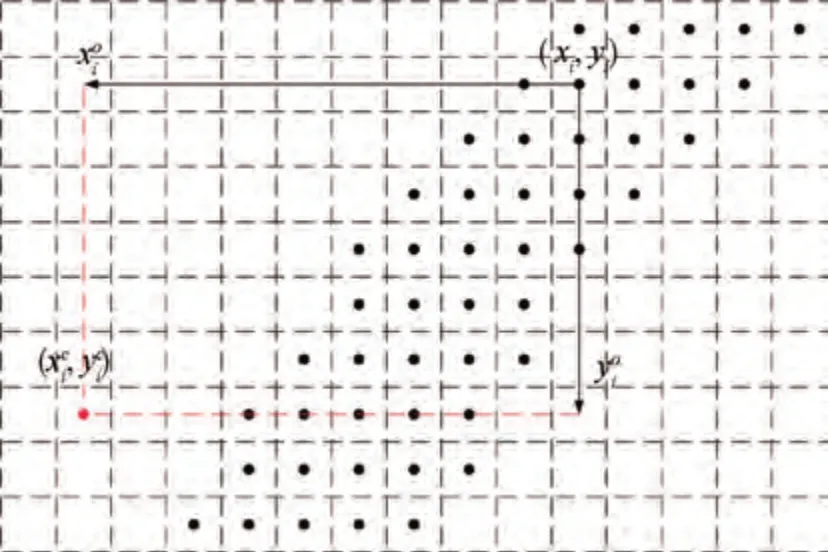
图7 聚类点位置计算原理

图8 聚类点分布示意图
最后采用基于密度的DBSCAN[21](densitybased spatial clustering of application with noise)聚类算法对聚类点进行实例区分,DBSCAN 有邻域搜索半径(Eps)和搜索邻域内包含的最小点数(Minpts)两个关键参数,根据这两个关键参数将聚类点区分为3 类:核心点、边界点和噪声点。其中核心点是Eps内聚类点的数量不小于Minpts的聚类点,而不属于核心点但在某个核心点邻域内的聚类点称为边界点,既不属于核心点也不属于边界点的聚类点则为噪声点。同时定义了点与点之间存在的3 种关系,对于聚类点集合,如果聚类点q在点p的Eps领域内,p为核心点,则称p对q直接密度可达;对于聚类点集合,给定一串聚类点p1,p2,p3,…,pn,p=p1,q=pn,若对象pi从pi-1直接密度可达,则对象q从对象p密度可达;存在聚类点集合中的一点o,若对象o到对象p和对象q都密度可达,则p和q密度相连。
DBSCAN算法的具体流程如下:
(1)从聚类点集合中任意选取一个聚类点p;
(2)如果对于参数Eps和Minpts,所选取的聚类点p为核心点,则找出所有与p密度可达的聚类点,形成一个簇;
(3)如果选取的聚类点p是边缘点,则选取另一个聚类点;
(4)重复步骤(2)、(3),直到所有聚类点被处理。
最终形成的每个簇即为聚类点的每个实例集合,然后根据聚类点来区分对应车道线点的实例。从以上DNSCAN 的算法原理可知,其不必在聚类前确定聚类簇的个数,因此本文算法可以在不预定义车道线数量的情况下进行多车道线检测。本文设置Eps为10,Minpts为150,实例区分结果如图9(a)所示,对应的车道线点区分结果如图9(b)所示。

图9 实例区分结果
2.2 损失函数
损失函数主要分为两部分:分割损失和位置损失。由于车道线在图像中所占像素相对背景较少,像素分类不平衡,因此选用带有权重的交叉熵损失函数作为分割损失,即
式中:Lseg表示分割损失;N表示像素数目;M表示类别数量,因为本文采用二分类分割,因此M=2;wij表示当前类别的权重,背景类别设为0.4,车道线类别设为1;yij为样本的真实值,当样本i的类别等于j时取1,否则取0;pij为观测样本i类别属于j的预测值。
为使车道线点对应的聚类点可以自适应地得到聚类中心,位置损失参考LaneNet中基于距离的度量学习方法,并引入车道线的位置信息,主要由方差损失和距离损失两部分组成,即
式中:Lloc表示位置损失;Lvar表示方差损失;Ldist表示距离损失。
方差损失是为减小属于同一车道线聚类点之间的距离,如式(9)所示;距离损失是为增大不同车道线聚类点之间的距离,如式(10)所示。为方便模型训练拟合,对车道点的水平位置和垂直位置均进行开方来减小尺度,因此在预测时,车道线点对应的聚类点位计算公式如式(11)和式(12)所示。
式中:C为车道线的数目;Nc为每条车道线中车道线点的数目;uxc为同一车道线点的水平位置平均值;uyc为同一车道线点的垂直位置平均值;δv为方差阈值;δd为距离阈值。
综上所述,本文算法的总损失为
式中:L为总损失;α为分割损失的权重系数,设为1.0;β为位置损失的权重系数,设为0.5。
3 实验验证
实验所用处理器为Intel(R)Xeon(R)Gold 5218 CPU @ 2.30 GHz,运行内存为64 GB,GPU 为NVIDIA RTX3090,采用PyTorch深度学习框架,均通过Python代码实现。
3.1 数据集
为评价本文提出的车道线检测算法,使用车道线检测最通用的CULane 数据集和TuSimple 数据集对模型进行训练与测试,两个数据集的图像分辨率、总帧数以及对应的训练集、验证集和测试集划分如表2 所示。其中CULane 数据集是一个包含城区、郊区和高速公路等多种道路类型的大规模车道线数据集,除正常场景外,还包含拥挤、夜晚、无线、阴影、箭头、眩光、弯道和路口这8个复杂场景,最多标注4条车道线,可以用于测试算法在面对复杂场景时的车道线检测情况。TuSimple 只包含高速公路类型的车道线,最多标注5 条车道线,是最广泛使用的车道线检测数据集之一。

表2 车道线数据集
3.2 评价标准
为便于与其他的车道线检测算法进行对比,所有实验均采用数据集的官方评价标准。
CULane 数据集将车道线看做30 像素宽的细长曲线,通过计算预测车道线与真实车道线之间的交并比(intersection over union,IOU)来判断是否预测正确。交并比大于0.5 的车道线表明预测正确,视为真正例(true positive,TP);小于0.5 则认为预测错误,视为假正例(false positive,FP);因漏检而未被检测出的车道线作为假负例(false negative,FN)。因为路口场景不含车道线,所以采用FP 的数量作为评价标准,FP 数量越小,表明检测效果越好,其余场景采用调和平均值(F1)作为最终评价标准,精确率、召回率和F1的计算公式分别为
式中:Pprecision表示精确率;Precall表示召回率;PF1表示调和平均值F1;NTP表示真正例的数量;NFP表示假正例的数量;NFN表示假负例的数量。
TuSimple 数据集有3 个评价指标分别是假阳率(false positive rate,FPR)、假阴率(false negative rate,FNR)和准确率(accuracy)3个评价指标,分别为
式中:PFPR表示假阳率;PFNR表示假阴率;Paccuracy表示准确率;Npred为所有预测的车道线数;Ngt为真实的车道线数;Ci为第i张图片正确预测的车道线点数量;Si表示第i张图片真实的车道线点数量。
同时本文将F1 作为TuSimple 的最终评价标准,如果超过85%的预测车道点在真实车道线点的20像素以内,则预测车道线为TP,否则为FP,漏检的车道线视为FN。
3.3 数据预处理与参数设置
在模型训练时需要对数据进行预处理,对CULane 和Tusimple 数据集中的每张图像分别裁减掉其上部240 和160 行像素,然后缩放到800×320 的分辨率,并进行随机旋转、随机水平移动和随机垂直移动等数据增强。
使用自适应矩阵估计(adaptive moment estimation,Adam)算法作为优化器,批处理数据量(batch size)设为16,初始学习率设为1×10-4,使用polylr 学习率[22]下降策略,在CULane 和Tusimple 训练集上分别训练20和40个迭代轮次(epoch)。
3.4 实验结果与分析
在CULane 数据集上对比SCNN、SAD、UFLD和E2Enet的结果如表3所示。其中SAD、UFLD 和E2Enet分别采用Enet、ResNet34和ERFNet作为主干网络。本文算法在正常场景和夜晚、无线、阴影等多个复杂场景取得了最高的检测性能,综合F1 达到75.2%,对比SCNN、SAD、UFLD 和E2Enet 算法分别高出3.6、4.4、2.9和1.2个百分点,证明了本文算法在复杂场景下具有更高的检测精度和鲁棒性。
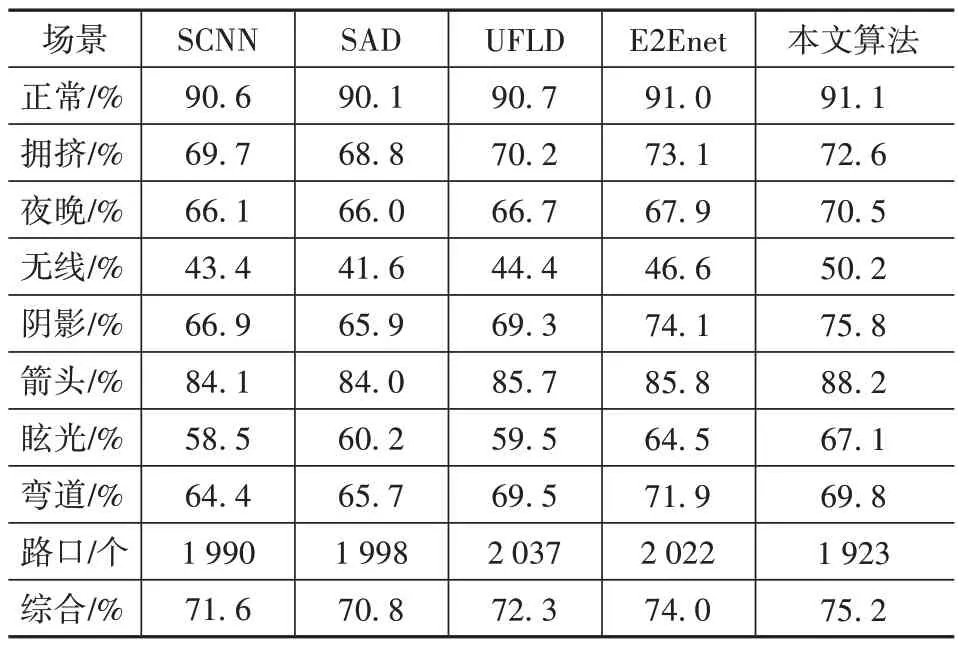
表3 CULane数据集结果
图10 列举了本文算法在不同场景下的车道线检测效果。可以看出,本文网络可以有效地应对车辆遮挡和不良光线等复杂场景,且可以检测数量变化的车道线。

图10 多场景下的车道线检测
在TuSimple 数据集上增加了与LaneNet、PolyLaneNet 和LSTR 算法的对比,结果如表4 所示。由于TuSimple 数据集都是高度规则化的高速场景,且大多光线良好,因此不同车道线检测算法性能差距较小,本文算法取得了最高的F1 指标,假阳率显著降低,说明不易错误预测车道线,对于汽车安全意义重大。

表4 TuSimple数据集结果
由于车道线检测算法须满足驾驶的实时性需求,因此对本文算法的模型推理速度和DBSCAN 聚类速度进行测试,通过500 张图像测试平均时间,结果如表5 所示。其中车道线检测网络模型利用GPU推理加速,聚类算法在CPU 运行。本文模型的推理时间为7.91 ms,DBSCAN 算法进行聚类所用时间为7.23 ms,即使包括聚类,本文算法的FPS(frames per second)仍然可以达到66.05,可以实时检测车道线。
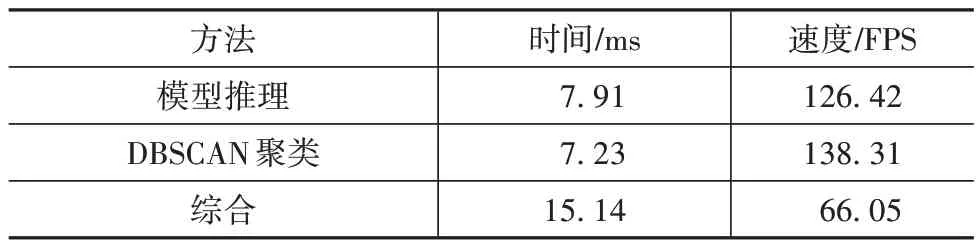
表5 网络推理与聚类时间
3.5 消融研究
为验证本文设计的扩张卷积残差模块对车道线检测的提升效果,将模型中的扩张卷积残差模块去掉后,采用相同的训练参数在CULane数据集进行训练,对比结果见表6。加入扩张卷积残差模块后取得了更好的检测结果,精确率提高0.3 个百分点,召回率提高1.2 个百分点,F1 提高0.8 个百分点,证明了本文提出的扩张卷积残差模块可以有效提高车道线检测的精度。

表6 网络性能对比结果 %
为验证本文所提的实例分割方法的有效性,将实例分割方法与只使用DBSCAN 对分割图像进行聚类的方法进行对比。由于分割图像中车道线点的分布密度低,因此直接进行聚类的DBSCAN 算法中Eps和Minpts参数分别设为2 和10,在CULane 数据集检测结果如表7 所示。通过数据对比可知,直接对二分类车道线分割运用DBSCAN 算法检测结果并不理想,F1 指标只有40.9%,而本文实例分割方法可以达到75.2%,相比提高34.3个百分点。

表7 实例分割方法对比 %
如图11所示,当二分类分割出的车道线远处不连接时,直接采用DBCSAN对二分类图像进行聚类,也可以取得与本文实例分割方法同样的实例区分效果。

图11 分割车道线远处不连接
当分割得到的左侧两条车道线远处密集连接时,由于DBSCAN 会将连通的点看作同一实例,导致不能有效地对车道线进行实例区分,从而导致模型精确率和召回率大幅降低,而本文实例方法得到的聚类点无论车道线远处是否聚集,属于同一车道线的聚类点相互聚集,密度更高,不同车道线的聚类点相互分离,更易被区分实例,且预测的车道线聚类点聚集在对应的车道线附近,说明预测的聚类点充分利用了对应车道线的位置信息,检测结果更加准确,如图12所示。

图12 分割车道线远处连接
3.6 实际道路测试
为测试模型在实际道路的有效性,利用如图13所示的智能车在校园内采集实际道路图像,并利用在CULane数据集上训练的模型进行车道线检测。

图13 实际道路测试车
实际道路的车道线检测结果如图14 所示。可以看出,本文算法可以在拥挤、箭头、阴影和眩光的实际道路准确地检测车道线,表明该算法鲁棒性强,具有良好的泛化性和实用性。

图14 实际道路检测结果
4 结论
提出一种基于实例分割的车道线检测算法,可以在不预定义车道线数量的情况下进行复杂场景的多车道线检测。算法采用轻量残差网络作为主干网络,利用特征金字塔进行特征融合,并设计基于扩张卷积的残差模块来提高车道线检测的精度,提出一种基于车道线位置的实例分割方法,充分利用了车道线的位置信息,通过计算车道线点对应的聚类点实现更好的实例分割。在CULane数据集和TuSimple数据集上的F1 指标分别达到75.2%和97.0%,在复杂场景表现出优秀的检测性能。所提出的实例分割方法对比只采用DBSCAN 聚类的方法,在CULane数据集上可以提高34.3 个百分点,且即使包括聚类,本文算法的检测速度仍能达到66.05帧/s,可以实现实时车道线检测。最后通过实际道路测试,验证了该算法在复杂道路的适用性。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
卫星应用(2021年11期)2022-01-19
科学大众(2021年9期)2021-07-16
中国交通信息化(2020年11期)2021-01-14
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
中国交通信息化(2015年10期)2015-06-06
河南科技(2015年8期)2015-03-11
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
