
安徽师范大学图书馆馆藏徽州文书数据库平台建设研究*
2023-03-07 02:23王毓铭张霞云董家魁刘和文
图书馆研究 2023年1期
王毓铭,张霞云,董家魁,刘和文
(安徽师范大学图书馆,安徽 芜湖 241002)
近年来,馆藏特色资源数据库平台建设成为业界和学界的研究热点,国外如Ball,MJ等通过学术信息管理系统(IAIMS)整合老年医学、高血压相关馆藏内容形成特色资源[1],国内图书馆特色资源数据库系统平台建设起步较晚,主要涉及到的技术包括DIPS、TRS、TPI 等[2]。部分图书馆利用C/S或B/S 架构站点自建特色资源平台,如:国家海洋中心使用TRS系统构建海洋数字资源库[3];杭州市图书馆建设的民国图书、民国期刊、古籍、家谱、地方文献等数据库[4]。现有特色资源数据库平台功能包含混合索引、并行检索、搜索引擎、主题词字典、多风格多类型自定义资源发布等,最新技术方案中逐步实现全文检索、数据挖掘、知识图谱等最新功能服务。而徽州文书作为特色资源之一,数量巨大、类型丰富,可以充分反映区域政治经济、风俗民情等社会形态,各收藏单位相继建设了特色数据库,如:安徽大学“徽州文书书目数据库”(2005 年),黄山学院“徽州文书特色文献数据库”(2007年),上海交通大学“中国地方历史文献数据库”(2015 年),中山大学“徽州文书数据库”(2019年),等等。此外,日本京都大学的“中国清代民国公私文书”(2003 年)也包含大量徽州文书资源数据。从数据库类型上看,已建设的各类徽州文书数据库中,除“中国地方历史文献数据库”为全文文本数据库外,其他均为图像库或书目库;在运行方式上,大多数已建设的徽州文书数据库并未提供开放预览,仅广西师范大学的“徽州文书数据库”等少数数据库提供半开放资源浏览,但数据库仍需授权后方可使用。在总结已建设图书馆特色资源数据库的技术、管理、服务经验后,充分考虑馆藏徽州文书现状与保存利用需求,建设安徽师范大学图书馆(以下简称我馆)馆藏徽州文书特色数据库平台。
1 馆藏徽州文书管理平台建设方案
我馆馆藏徽州文书近千件八千余页,涵盖土地关系文书、赋役文书、商业文书、宗族文书等类型,具有整体时间跨度长、地域分布广、归户性强、种类多样等特点。我馆馆藏文书具有极高价值,主要体现在:一是善本多,据统计,近千件徽州文书中有600 余件为清乾隆以前保存均较为完好的善本,宋、元至明代嘉靖时期者近200件,迄今国内公布的同时期的徽州文书档案总量仅数百件;其中《元至正五年二月初九日休宁县朱右宠卖山契约》《元至正六年二月十二日陆保黄卖山契约》更为国内仅存为数不多的元代徽州文书。二是孤本多,民间契约往往具有唯一性的特点,我馆馆藏中多为徽州民间契约,且均为孤本。其他的鱼鳞图册、保甲册、户口环册等也为国内仅存的孤本。
为了加强特色资源的利用,2019 年我馆启动馆藏徽州文书资源平台建设,平台建设分为徽州文书数据化与数据库管理平台建设两个阶段,徽州文书特色数据库平台建设流程图如图1所示。
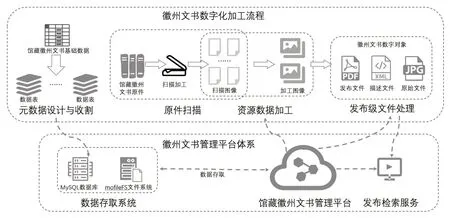
图1 徽州文书特色资源数据库平台建设流程图
文书数据化包括元数据设计与收割、徽州文书原件扫描、资源数据加工、发布级文件处理等步骤,主要是对徽州文书基础数据、原件扫描图像、应用发布文件进行流式处理。数据库管理平台建设包括数据存取系统建设、馆藏徽州文书管理平台开发、徽州文书发布检索服务平台建设,主要用于徽州文书元数据的存储、数据库平台管理以及徽州文书数据库检索等。
2 徽州文书资源数据化
2.1 徽州文书元数据设计
特色资源的数据库设计需要建立规范的资源建设标准,确保特色数字资源建设长期稳定运行[5]。元数据设计是特色资源数据库建设首先要考虑的问题,目的在于通过将不同类型特色资源按标准化的采集方案汇聚形成各类特色资源元数据,最终满足不同用户对于各类特色资源数字化和元数据采集的不同需求[6]。由于徽州文书外部特征独特,内容涉及各个方面,笔者结合通用资源的元数据设置,参考图书、论文、音视频、人物等类型资源的元数据设置和《民间历史文献整理概论》[7],定义了17 个徽州文书元数据字段(具体如表1 所示)。其中:描述字段包括财产号/标识符、题名、尺寸、人物及机关团体、主题词/关键词、实物形态、保存状况、馆藏信息、语种、相关资源等10个;内容字段包括时间、涉事地点、归户、谱系、金额、赋役、页数等7 个。描述性字段与内容字段的设计在于以标识符、资源文件路径为主要字段连接资源元数据与资源文件,以实现检索发现、分析统计、资源服务等功能,充分揭示徽州文书的内容特征和形式特征。
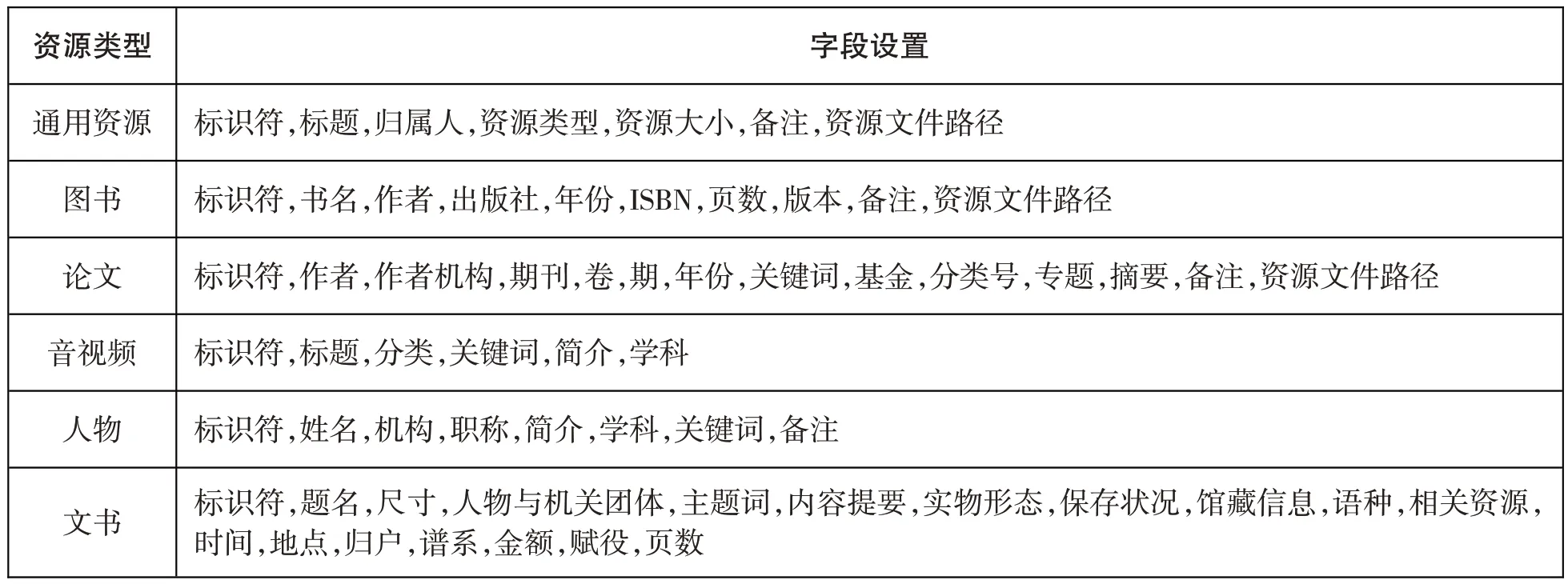
表1 特色资源通用平台元数据字段设置
2.2 馆藏徽州文书扫描
资源数字化是特色资源库建设的基础工作,针对数据库平台的功能要求和文书的品相,徽州文书数字化采取拍摄式扫描和资源收割的方式。数字化资源的图像质量具体要求定为:300DPI(像素密度),24 位色彩色阶和JPEG/JPEG2000(压缩方式)。为保证后期校正处理和使用服务时的色彩准确性,在每一份文书扫描后添加专用色卡拍摄图。
由于文书的品相不同,在数字化加工过程中,针对文书页面褶皱、残缺、破损等现实情况,事先做了修复处理,在数字化过程中专门标注。
针对大开本的文书,采取图片裁剪和分页的形式来处理,保证每件文书数字化资源“一图一页”,清晰完整。
2.3 徽州文书数据化加工
数据化加工是将徽州文书扫描件转化至用户可用资源文件的主要步骤,包括对资源文件加工、元数据关联和补全。考虑可用资源在传输速率和使用效果两个维度的切实矛盾,资源加工的要素主要为资源文件版式、容量、DPI、分辨率。在数据化加工流程中:首先,对每件资源进行“一图一页”的统一版式、一致的压缩分辨率和DPI控制处理,在可清晰辨识内容基础上,容量限制在200 KB 至1 MB 之间,以同时满足读者浏览资源时对加载效率和使用体验的要求。其次,将徽州文书加工资源进行元数据关联匹配,最终形成文书资源散件727份,多页或成册文书203份,总计8 809页。最后,针对发布应用的实际使用场景和用户资源需求,在完成元数据补充基础上,进行整体和独立分页的发布应用级数字对象生成,包括PDF 资源文件、基于都柏林核心集字段的元数据描述文件、目录结构信息文件、资源封装信息文件和资源原件图像。
此外,由于存在鱼鳞图册、保甲册、户口环册等类型的成册文书资源,需按古籍文献规范要求对页面布局、放大率、默认打开页等项进行配置,并添加导览标签,便于读者用户对此类文书资源的高效使用。
3 徽州文书资源库平台建设
我馆馆藏徽州文书资源库平台的建设是以规范化、通用性为建设指导原则,以数据存取子系统、徽州文书管理平台、检索服务子系统为节点,完成对徽州文书的归类、元数据著录、整理、数字化扫描、资源加工和加工成品发布的整体工作流程。
3.1 数据存取子系统
在馆藏徽州文书管理平台系统中,需要进行数据资源存储的包括徽州文书元数据、资源原始数据和加工数据。其中,元数据存储于结构化数据库中,资源原始数据和加工数字对象存储于文件存储系统中。
徽州文书元数据在建设过程中使用MySQL+Redis 数据库的混用方案。MySQL 数据库作为结构化数据存储节点,Redis 作为内存缓存存储系统,对资源集数据进行同步并向前端服务提供高速数据读取服务。基于以上架构,形成管理平台和发布检索服务在元数据使用层面的读写分离数据存取方案。在数字对象与资源文件存储方面,子系统使用mofileFS分布式文件存储方案,利用其适用于海量小文件的特性,充分满足大量容量为1 MB至10 MB大小的徽州文书数字化对象文件的高效存取需求。
基于以上数据存取子系统建设,为馆藏徽州文书管理平台提供完整的数据、文件读写底层方案,进而完成馆藏徽州文书管理平台的功能和服务开发。
3.2 徽州文书管理平台
徽州文书管理平台和发布检索服务使用ThinkPHP5.1+Vue.js的开发框架进行前后端分离,前后端通过鉴权与业务API 通信实现数据流通,平台以功能模块化的思路进行开发建设,结合徽州文书扫描和数据化加工过程中的具体流程节点,整体设计为6个主要模块,分别是管理控制、资源数据上传、资源加工管理、数据标引管理、数据集管理、发布管理,平台的一、二级功能模块如图2所示。

图2 图书馆特色资源通用平台架构设计
3.2.1 平台管理
管理控制模块对馆藏徽州文书平台的非业务操作和功能进行整体管理,模块建设以RBAC 模型(Role-Based Access Control:基于角色的访问控制)进行开发建设,使得平台具有高自由度、可持续优化更新等优势,具体功能包括管理员管理、菜单管理、权限管理和日志统计。管理员以自身角色所拥有的菜单和功能访问权限对平台系统进行管理,平台建设完成后通过限制管理员账号对平台管理进行管控,后续的功能更新和优化可基于菜单管理和权限管理模块进行自定义配置。
3.2.2 数据加工管理
数据加工流程在平台中由资源数据上传模块、资源加工管理模块和数据标引管理模块组成。
首先,资源数据上传模块包含标准管理、元数据管理、文件管理、数据关联子模块。标准管理模块在本平台中仅额外添加有徽州文书类型字段标准,作为元数据管理中徽州文书元数据导入的字段标准。标准管理模块在通用平台中设计对更多类型的资源导入预处理;元数据管理和文件管理分别向徽州文书元数据和扫描图片提供入库、管理功能,完成入库后可通过数据关联子模块以特定识别字段进行元数据与资源文件的关联操作,完成数据初始导入。
其次,资源加工管理模块则主要对导入扫描图片的进一步加工,包括图像裁剪、图片分页、图像压缩等。此外,在通用平台框架中该模块还设计有文本OCR提取、音视频处理、压缩转码等功能模块。
最后,数据标引模块管理主要进行徽州文书元数据字段的补充标目,包括基于切词匹配、年代转化等的自动标目过程和面向图书馆处理人员的手动标目模块。标目过程需符合对应标目规则子模块中预设的内容,包括可标目字段,字段类型范围等。
3.2.3 数据集发布管理
发布管理模块实现对徽州文书发布检索服务的管理,包括发布审核、检索设置和可视化配置。在功能上,发布审核子模块完成对发布字段、发布资源内容、发布资源描述信息等内容的审核;检索设置实现对资源关联数据表、统一检索模式和高级检索字段与数据表字段对应关系进行配置;可视化配置子模块提供对资源集检索服务的可视化展示方式进行配置选择。
3.3 徽州文书检索服务子系统
检索服务子系统是对馆藏徽州文书资源加工数据的应用。子系统由Vue.js 框架搭建,通过后端鉴权API 实现数据通信。服务以徽州文书资源检索发现为核心,通过栏目分类、检索发现、排序筛选和关联推荐实现对资源的多维度揭示。检索过程主要使用元数据中的题名、人物、主题词/关键词、馆藏信息、相关资源、时间、地点、页数字段等字段,通过统一检索、高级检索、结果集二级检索、关联推荐等揭示、发现方式,进一步提升用户使用检索服务的效率和体验。资源详情页面提供资源明细浏览、资源分享下载、自定义批注等功能,充分满足用户资源使用需求。同时,以开放众包的服务理念进一步通过用户浏览批注行为,完善馆藏徽州文书资源服务内容。
4 徽州文书资源数据库功能特色
我馆徽州文书资源库平台的建设,除了具备存储和检索服务功能外,还形成具备量化分析和一定数字人文研究能力的特色。相较于现有其他徽州文书数据库,本平台特色主要聚焦:技术层面对数据管理规范化;内容层面融入数字人文思想,构建资源知识点并引入检索发现服务;服务层面更多体现在共建共享机制和多维检索发现服务中。
4.1 完善数据管理维护机制
特色资源建设是一个长期的过程,完善资源数据管理机制应该融入整个工作流程中。馆藏徽州文书数据库对元数据标准、数据采集、文件上传、资源加工、资源数据化、发布文件处理全流程进行有效管理,明确数据加工、存储、传输、备份环节的维护细节。
具体包括:(1)数据库系统的性能优化和数据安全保障。平台结构化数据通过MySQL + Redis的数据库方案进行读写,数据加工管理与资源数据服务实现读写分离,提高使用服务中资源加工数据传输效率,控制数据库写入渠道入口,提升数据安全保障。(2)数据流中任一环节可追溯机制,管理平台前后端分离,模块化功能通过鉴权API获取使用数据,简化内部数据流,便于追溯资源数据化过程的任一环节,降低数据维护难度,提升数据更新效率。(3)资源数据流式处理。在现有徽州文书资源采集加工发布流程下,对于数据可进行流式处理,以现有930 件(8 809 页)馆藏徽州文书为例,自数据入库、加工直至发布级文件生成并更新至检索系统,全部流程可控制在60-90分钟。
4.2 构建知识点发现索引
平台数据标引管理中开发有知识点半自动标引模块,以节点名称、类型、上级节点、关联词字段自动构建知识点数据,在经由人工审核修正后,知识点按关联关系组建多维度多层级的知识点网络,在检索服务中提升优化数据发现和关联资源推荐的有效性。以图3为例,在平台徽州文书资源中,与“税”相关的文书类型通过知识点网络可直接提取为税契、税银、税课、税单、收税汇票、推税汇票、归户票。聚焦到“地税”类型,提取包含14份散件资源,可进一步按朝代、年份、地域、类型等进行进一步关联、细分。此类关联数据的形成可用于后续检索发现和资源推荐服务,帮助用户在寻求相关资源时可自行快速获取更多关联研究内容。
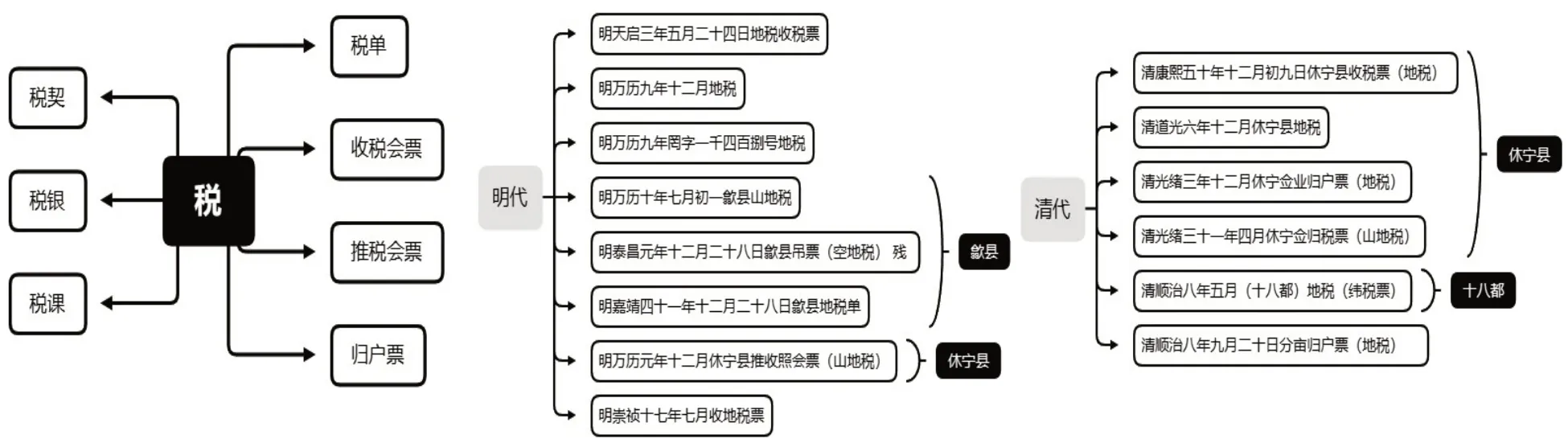
图3 徽州文书数据“税”相关类型与地税数据知识节点提取
4.3 实现徽州文书数据共建共享
特色数据库建设往往需要耗费大量人力物力,而图书馆也面临资源有限、经费匮乏的现状[8]。因此,合理的共建共享机制将直接影响资源共建、机构合作。在本平台徽州文书资源的共建共享机制上共设计有3层独立方案,包括数据库层面元数据字段标准化、接口层面鉴权API 数据共享、服务层面资源授权下载,以多层次的数据共建共享,充分保障资源的通用性和专业性。
数据库层面元数据字段标准化,平台在分析徽州文书特征基础上定义了其元数据的17 种字段,其中充分考虑兼容都柏林核心集(Dublin Core Element Set)元素字段,保证与其他类型数据库的兼容性,提供数据共建共享的底层标准基础。
接口层面鉴权API数据共享,API是元数据标准可解析后数据实现同步获取的主要途径之一,平台API 可通过请求令牌信息识别访问者身份实现数据通信,对平台合作机构可提供全面且可定制化的数据支持。
服务层面资源授权下载,平台支持授权个人用户按权限导出资源字段标准、资源发布文件和原始文件,通过基于合作平台的用户互认等机制,即可扩大平台间用户群体,在用户层面实现资源共享。
4.4 资源高效多维度检索发现体系
徽州文书资源库平台资源发现通过多维度多渠道的方式,降低平台资源发现难度(具体见图4所示)。具体服务中以自主检索、复合检索、多维筛选、关联推荐等形式组合,通过多个入口提取命中资源数据,增加服务广度;结合资源主题词、类型、年代、地域等特征信息,便于简化数据字段索引设置,提升数据提取效率,提升发现深度;遵从主题词匹配优先并使用浏览量、资源评分等参数的混合排序规则,优化展示排序。最终实现从元数据、分析数据、知识点关联数据等多个维度完成资源数据的整体发现,实现用户对所需资源的高效准确定位和发现。
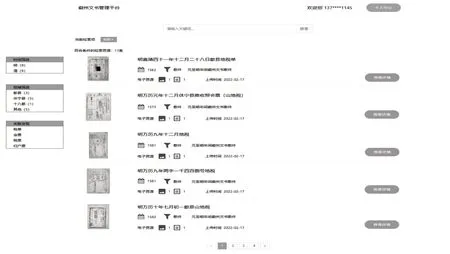
图4 徽州文书检索服务页面
5 结语
徽州文书资源库平台实现对我馆徽州文书资源的数字化存储、管理和检索功能,初步建设徽州文书知识图谱和资源推荐系统。在建设过程和试用过程中,笔者对徽州文书资源库平台拟定了进一步完善平台通用性功能的完善方向。同时,在知识图谱构建和检索发现上进一步挖掘资源内容中的人、物、事节点,进而组建更完善的语义网,使资源使用者尤其是研究学者可以更好地进行内容发现、挖掘和分析。但还存在加工过程遵从以专用元数据标准处理收割数据资源、以发布应用文件规范对资源加工进行各维度阈值限制、平台资源加工仅支持人工输入构建全文数据等不足,在数字人文理论与技术发展的当下,这也是本平台后续发展需要重点攻克的内容。
猜你喜欢
现代装饰(2022年6期)2022-12-17
中老年保健(2022年5期)2022-08-24
邯郸学院学报(2022年2期)2022-07-05
江淮法治(2022年3期)2022-03-16
安徽警官职业学院学报(2020年6期)2020-07-21
韶关学院学报(2020年5期)2020-07-17
艺术品鉴(2019年11期)2019-12-27
西夏学(2019年1期)2019-02-10
大观(书画家)(2018年6期)2018-07-08
火花(2016年7期)2016-02-27
