
一种针对轨交大客流环境的新型目标检测算法研究
2023-02-28 09:12李心怡姚世严李天宇郑剑飞
数字通信世界 2023年1期
石 旭,李 辉,李心怡,姚世严,李天宇,郑剑飞
(北京轨道交通路网管理有限公司,北京 100101)
1 研究背景
人工智能技术在安防、金融等诸多行业已经有了较为广泛的应用,但是通过深入调研分析,伴随应用场景的差异化,其所能够选用的算法也是千差万别的,而且同样的算法可能在轨交行业精准度大幅下降,难以满足业务需求。因此,轨道交通行业在引入人工智能技术的过程中,绝不能简单地一蹴而就,需要做好充分准备,针对自身行业特性,对所选用的各类智慧化方案核心算法加以改造、优化,以便更加契合实际应用场景,从而实现精度、成本和稳定性达到行业应用水平的目标。基于当前智能视频分析算法精准度普遍难以满足应用要求的现状,为此,本文提出了一种针对轨道交通行业大客流环境的新型目标检测算法。
2 研究新型目标检测算法的必要性
2.1 目标检测算法概述
目标检测是一种计算机视觉技术,它使我们能够将视频中的对象进行识别和定位。通过这种识别和定位,目标检测可用于计算场景中的对象并确定、跟踪它们的精确位置,同时准确地标记它们[1]。在视频图像分析研究中,核心问题包括运动目标检测、目标跟踪、图像分割与行为理解。而目标检测算法是其中最为基础、最重要的算法,其存在是为了解决计算机视觉里的一个最基本任务,那就是我们感兴趣的目标在图像中的什么位置。
目前,业界比较通用的检测模型可分为两阶段模型(two-stage)和单阶段模型(one-stage)两类。两阶段检测模型精度高而耗时长,往往对硬件配置的需求高,且难以做到实时检测,在实际项目中无法规模化应用。单阶段模型选择牺牲一定的精度,换取速度上的大幅提升。就单阶段模型而言,在一些复杂场景下,由于目标尺寸分布广泛,如果骨干网络过浅,检测网络设计又过于简单,参数利用不充分,就会导致目标特征信息提取不到位,从而导致检出困难,误检多;反之,如果骨干网络过深,检测网络较为复杂,又会导致模型速度过慢,无法做到实时检测,也就失去了应用价值。
2.2 目标检测算法改进思路
正是鉴于目标检测算法的这种基础性地位,我们选取了一部分厂商的现有算法来进行有针对性测试,进而发现在面对轨道交通行业的大客流、远视角的特有环境条件时,现有算法均存在一定概率的漏检和误检,无法满足正式使用要求。对于这些现有技术的不足之处,以更加适应轨道交通行业的特有环境为出发点,基于单阶段检测网络进行了以下改进,从而解决上述这些技术问题。
(1)提出了一个由20层卷积神经架构组成的骨干网络。
(2)检测网络部分采用特征金字塔的思想,对骨干网络最后一层的输出进行两次上采样,从而获取到3个尺度的特征图,同时将深层语义信息和浅层轮廓信息进行特征融合,并分别在3个尺度的特征图上对不同尺度的目标进行检测。
2.3 新型目标检测算法核心架构
依据目标检测算法改进思路,本文提出了一种新型目标检测算法,核心模块由两个网络组成。
(1)20层的骨干网络:该骨干网络全部由卷积构成,由尺寸为3×3、步长为2的卷积完成图像的下采样,总共对图像进行了6次下采样。
(2)检测网络:我们参考了FPN金字塔结构,对最后一个尺度的特征图进行两次上采样(upsample),并且利用通道数拼接(concat)的方式来融合对应尺寸的浅层特征信息(backbone feature map),然后再对其进行一次特征提取,来进行检测校验。
2.4 新型目标检测算法研究的工作流程
新型目标检测算法利用以下步骤,都能够以一定的精度将视频中的目标物体进行定位和识别[2]。
第一步,准备模型训练所需要的图片及其对应的预标注文件。在预标注文件里标注的是待检测目标的最小外接框(x,y,w,h),其中,x表示标注框中心点的横坐标,y表示标注框中心点的纵坐标,w表示标注框宽,h表示标注框高。
第二步,开始设定每张尺度特征图上所使用的锚框(anchor)个数。为了保证模型训练的效果,即精度与速度达到预先想要的平衡,我们需要在每张尺度特征图上选取3个尺寸的锚框。因此,在上述模型中一共需要使用三个尺度的特征图,每个尺度的特征图上使用3个锚框,锚框总数为9。在下述过程中,我们会默认每个尺度的特征图上都使用3个尺寸的锚框[3]。
第三步,要对训练集中的标注框分别按照尺寸进行聚类,聚类的簇数与锚框总个数一致,采用聚类得到的结果来做为锚框尺寸。其可视化说明如图1所示。
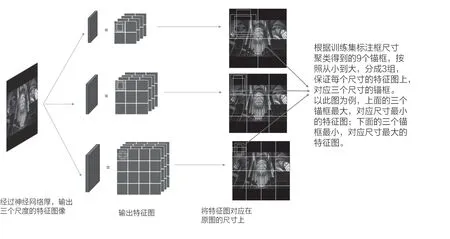
图1 关于步骤三的可视化说明
第四步,设置网络检测层所要输出的通道数,通道数用C_out来表示:
C_out=(num_cls+4+1)×num_anchor (1)式中,num_cls表示待测类别数量;num_anchor表示每个尺度的特征图上所选用的锚框个数(例如,在步骤二的前提下,num_anchor=3);4表示预测框中的4个位置坐标信息;1表示1个用于判定正负样本的参数。
第五步,设定负样本的判别阈值。在我们所研究的这个模型下,为了确保模型能够有较高的召回率,选取了预测框与真实值(ground truth)IoU≥0.3的预测框来作为正样本保留,其余预测样本作为负样本,后续不参与分类损失的计算。
第六步,对我们所构建的这个卷积神经网络进行规模化样本训练,保存最终模型及参数。
第七步,随机准备一张待检测的图片,加载进入我们已经训练完成的卷积神经网络模型,通过对所得出的检测结果进行验证,评价该模型可靠性。
2.5 目标检测算法经典模型选择
目标检测的目的是定位和分类视频图像中的现有目标,并用矩形边界框对其进行标记,以显示存在的可信度。一种方法遵循传统的目标检测管道,首先生成区域建议,然后将每个建议分类为不同的对象类别。另一种方法是将目标检测视为一个回归或分类问题,采用统一的框架直接获得最终结果(类别和位置)[4]。基于区域建议的方法主要包括R-CNN、R-FCN、Fast R-CNN、Faster R-CNN、SPP-net、FPN和Mask R-CNN,其中一些方法相互关联,如SPP-net使用SPP层修改RCNN[5]。基于回归或分类的方法主要包括MultiBox、G-CNN、AttentionNet、YOLO、SSD、YOLOv2、DSSD和DSOD[6]。
3 新型目标检测算法研究预期效果
相比以往目标检测算法,新型目标检测算法将在以下3个方面有明显提升。
(1)设计的20层卷积神经架构参数量少,在利用feature extra block模块降低参数量的同时,还能加深网络深度,从而使得网络对图像中所需要关注的特征提取更加充分[7]。相比较于通常的下采样方式,选用步长为2的卷积来完成下采样工作(pooling),能够在扩大感受野的同时,提取更多有效特征信息。
(2)在检测网络部分,分别在3个尺度的特征图上做检测,其中大特征图感受野小,用于对应小目标,而小特征图感受野大,用于对应大目标。采用这种方式使得模型对于尺度、比例分布广的目标具备更强的鲁棒性。除此之外,通过浅层网络提取出来的特征更多是作为物体的边缘以及轮廓相关信息,而深层网络提取的特征则多作为物体的语义信息。随着网络的不断加深、感受野的加大,这就会导致一些小目标的语义信息丢失,通过将深层语义信息与浅层轮廓信息相结合的方式,可以相对提升图像中小目标的检测效果。
(3)由于整体上需要定义的参数量很少,能够在确保精度的同时,大幅地提升检测速度,使FPS能够达到130以上,完全满足实时视频监控系统的应用需求。
4 目标检测算法研究在轨交行业的应用前景
首先,该算法模型在搭建之初就是完全按照轨道交通行业特有的环境条件来进行设计的,在训练过程中所使用的数据也全部基于线路、站厅及车辆等环境中现有视频监控系统来进行采集。这使得该模型对于轨道交通行业业务场景的适配性非常强,能够有效实现场景中所需各类目标的检测,从而为进一步进行数据分析奠定了良好基础[8]。例如,当使用在对换乘通道人员密度、流向等进行分析的场景中时,由于该检测网络模型能够很好地识别图片中出现的各种尺寸的目标,尤其是小目标,就可以更为准确地检测出大客流、远视角情况下,每一帧图像中的头肩数。
其次,该算法模型性能优越,能够快速完成在单帧图像中对目标内容的检测,FPS≥130的帧率已覆盖并超越轨道交通行业现有视频监控系统全部前端采集设备的标准帧率[9]。在上述例子中,通过这种高速检测,我们可以获取视频每一帧画面内所需要关注的目标,并通过数据分析手段,判断出每一个单独目标的运行轨迹及运动趋势,从而明确了解到该监测环境下的乘客走向,为精准导流的实现奠定了技术基础。
最后,基于该算法模型简单的结构以及更少的参数量,其对于硬件资源的消耗也较为友好,使得以边缘计算形式进行利用成为可能,这既符合行业发展大方向,又能够有效节约各类改造项目中的资源需求。
5 结束语
得益于近两年云计算、物联网、大数据等先进技术的发展和成熟,智能视频监控获得了强有力的技术支撑,未来视频监控系统将从根本上改变信息采集、视频传输处理、系统控制的方式和结构形式,有效提高视频监控的智能化程度和使用价值。
本文通过分析智能视频分析技术中最基础、最核心的目标检测算法的技术现状,结合轨道交通行业特定的应用需求和场景,提出一个适应轨交行业大客流环境的新型目标检测算法的技术思路,力争解决智能视频分析技术在轨道交通行业落地难的难题。后续,我们将深入研究各个应用场景的业务需求,在算法设计和研发过程中,根据测试效果对新型目标检测算法的技术思路进行验证和优化,为后续试点应用奠定坚实的技术基础,为“智慧地铁”的建设提供有力支撑。■
猜你喜欢
信号处理(2022年11期)2022-12-26
计算机与生活(2022年11期)2022-11-15
计算机工程与科学(2022年8期)2022-08-20
中南民族大学学报(自然科学版)(2022年3期)2022-05-08
北京航空航天大学学报(2021年9期)2021-11-02
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
太空探索(2016年5期)2016-07-12
