
基于ARIMA的盾构机液压推进系统数据预测方法研究
2023-02-24 07:14杨民强
液压与气动 2023年2期
杨民强
(中铁十四局集团大盾构工程有限公司, 江苏 南京 211800)
引言
盾构法拥有较强的先进性与高效性等优势,在城市地下交通系统建设中起到了至关重要的作用[1]。盾构机作为一种集机械技术、电子技术、控制技术、通信技术等多学科融合的重型工程机械[2],是实施盾构法的主要设备,而对于泥水盾构机来说,液压推进系统又是盾构机的关键构成。因其面临工作负荷大,地质复杂性高,工作环境恶劣等环境,所以其系统故障发生频率高[3]。盾构机的每次故障都会引起停工检修,造成巨大的人力物力的损失甚至引发安全事故,所以如何提前预测盾构机液压系统数据的变化以提供有效的信息预测故障的发生是大盾构领域一个新兴的研究方向。目前,盾构机液压推进系统都配置了相关的传感器设备,用来记录盾构机液压推进系统运行时的运行参数值[4], 基于盾构机液压推进系统传感器采集的运行数据来预测盾构机液压推进系统未来时刻的待预测参数,从而构建盾构机液压推进系统待预测参数的预测模型,对盾构机的数据预测方向起重要的作用[5]。
传统的盾构机液压推进系统参数预测的方法可以概括为三类:经验预测方法、岩土力学预测方法和数值模拟预测法。其中,经验法是在1976年由SAUCER G[6]根据盾构机物理模型进行了使用,并证明了在盾构机作业中二维载荷小于三维载荷。之后在2016年,ZHANG Q等[7]基于岩土力学预测法将盾构机推进过程地层结构拓展为多层地层,在此基础上,预测盾构机与岩土力学性质之间的关系。SU C等[8]基于数值模拟预测法,通过对盾构机切削过程进行了数值分析,采用回归方法对盾构机刀盘扭矩进行研究,分析并且预测了负荷参数与多种状态之间的关系。
本研究以芜湖长江隧道项目所采用的盾构机液压推进系统的运行数据为研究对象,采用基于时间序列分析ARIMA方法,对盾构机推进过程中的数据变化进行预测分析,重点比较了基于K-means聚类的RNN预测方法与线性回归方法的预测准确率。
1 盾构机液压推进系统相关数据预处理
1.1 盾构机液压推进系统
本研究以中铁十四局集团大盾构有限公司某隧道项目中所使用的大型泥水混合式盾构机液压推进系统为研究对象,该对象具有应用普适性。如图1所示,为该盾构机液压推进系统液压泵组成结构,整个系统包括56个液压泵,分为A~F共6组。
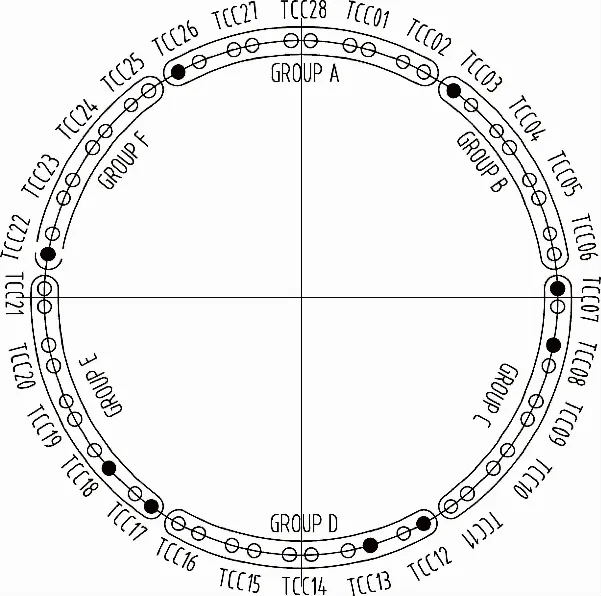
图1 盾构机推进系统液压油泵分组结构
基于该盾构机的挖掘数据,本研究所获得的原始数据主要有5种类别,如表1所示。
表1中液压推进系统区域压力共分4类:pA,pB,pC,pD,分别代表4组液压推进系统的液压泵压力。pA~pD对应了图1中A~D组液压泵。虽然图1中显示拥有A~F组的驱动单元,但是在数据处理过程中整个刀盘对称,选取A~D驱动单元的数据已经足够体现数据变化特性,为减少数据运算量,节省运算时间,本研究只针对驱动单元A~D进行分析。

表1 盾构机数据类别
1.2 数据预处理
获得的数据为2个月的盾构机液压推进系统数据,每类数据有25万数据量,因为数据量较大且数据质量参差不齐,所以针对所获得的数据需要进行数据预处理,便于后续的分析与预测过程。
针对所获得的数据的清洗, 为满足后续数据分析需要,且所有的数据组均为盾构机在正常掘进状态下采集,本研究依据以下2类方法作为预处理原则:
(1) 停机状态下的数据予以删除,包括因为拼装状态、停机状态、机械故障状态和刀盘空转状态等造成的停机;
(2) 因掘进过程中由于人为因素而导致的盾构机液压推进系统参数的数据大幅改变也视为异常值删除。
基于上述预处理原则,首先对原始数据中的异常值进行了识别与处理,删除了5种数据的异常值与空值。又因为本研究所获取的原始数据采样频率为10 s,在该采样频率下,数据量过大,不能有效的进行分析,因此本研究又采取了降采样方法,将采样频率由10 s变至1 min,得到的挖掘速度数据清洗前后时序对比图如图2所示。可以看出,数据清洗后依然能保有数据清洗前的特征,并且数据量大幅度减小可以有效的提升分析速度。
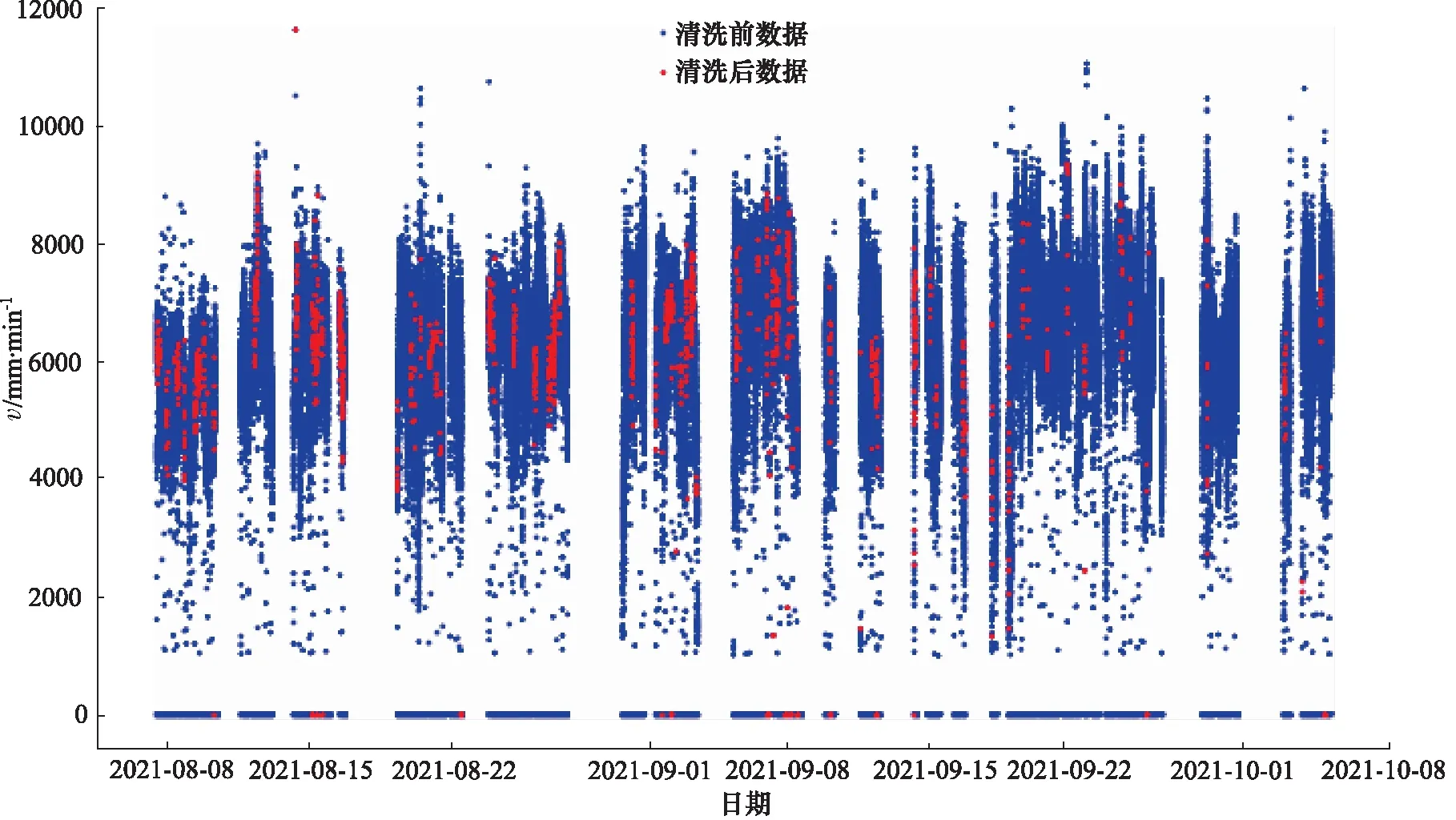
图2 掘进速度数据清洗前后对比
2 盾构机液压推进系统Pearson相关性分析
2.1 Pearson相关系数分析
基于上述清洗过后的数据,首先通过皮尔森相关系数来判定液压推进系统参数的相关性[9],该系数可以定量地描述变量之间的关系。
皮尔森相关系数r的计算公式为:
(1)
式中,X,Y—— 拟要判定相关性的参数
n—— 数据组的数量
通过式(1)计算F,pA,pB,pC,pD,T,v,s之间的相关性,如表2所示。
r越接近1相关度越高,由表2可以看出,相同参数间的相关性系数为1,与液压推进系统pA相关度最高的数据为掘进速度,与pB相关度最高的也是掘进速度,而刀盘扭矩、掘进速度与贯入度这3个参数之间相互的相关度都较高。
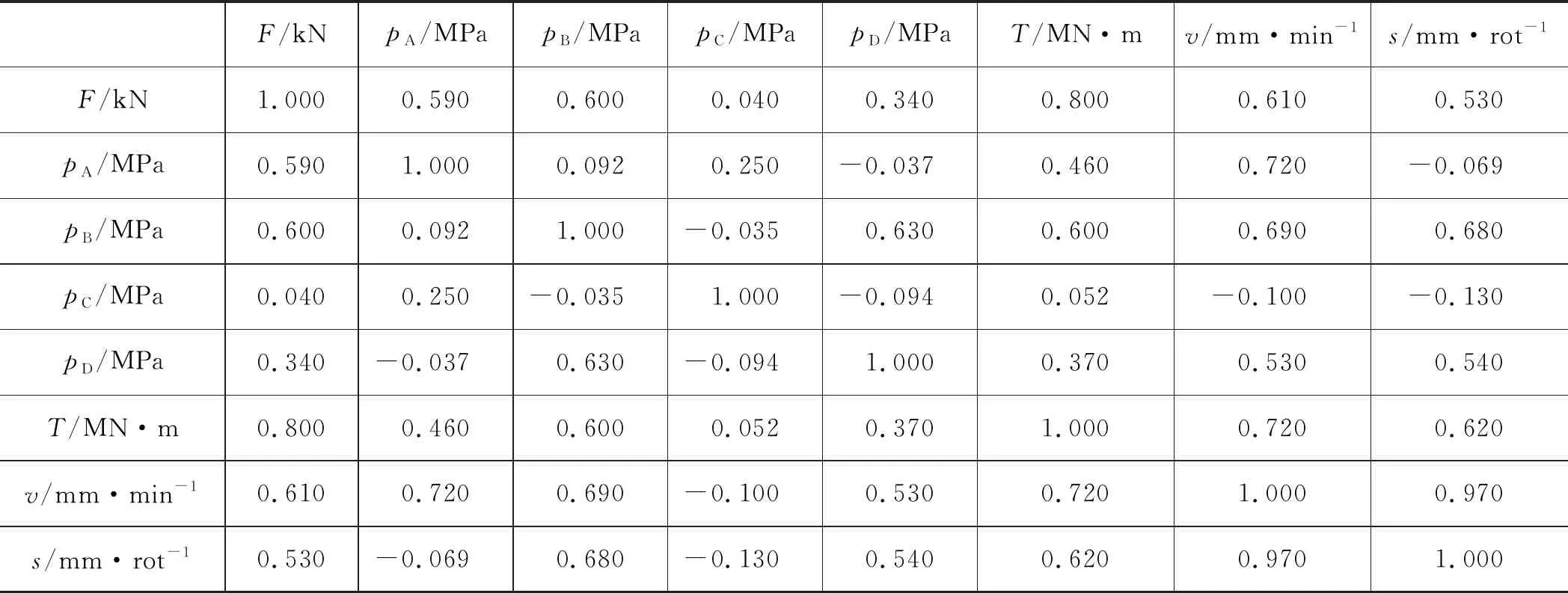
表2 盾构机液压推进系统数据清洗后相关性分析
因此,基于相关性分析结果,本研究主要从与液压力相关度较高的掘进速度来进行分析与预测。
2.2 自相关与偏相关结果
自相关指一个信号与其不同时间点自身的互相关,即信号在不同时间点下的相似度与2个时间之差的函数。因此,自相关可以用来找出并剔除掉本研究所用的数据在不同时间点下相似度高的数据,可以有效的减少无用数据。自相关函数(Autocorrelation Function,ACF)反映了同一序列在不同时序的取值之间的相关性;偏相关函数(Partial Autocorrelation Function,PACF)是严格2个变量之间的相关性。 本研究基于确定ACF与PACF结果来确定选择模型是自回归模型(Auto-regresssive,AR)、移动平均模型(Moving Average, MA)还是混合模型(Auto-regresssive Moving Average,ARMA),选择标准如表3所示。

表3 盾构机液压推进系统模型判断标准
掘进速度的自相关与偏相关分析结果如图3所示。可以看出,ACF和PACF两图都是属于拖尾,因此选择ARMA模型更为适合本研究的盾构机液压推进系统分析。
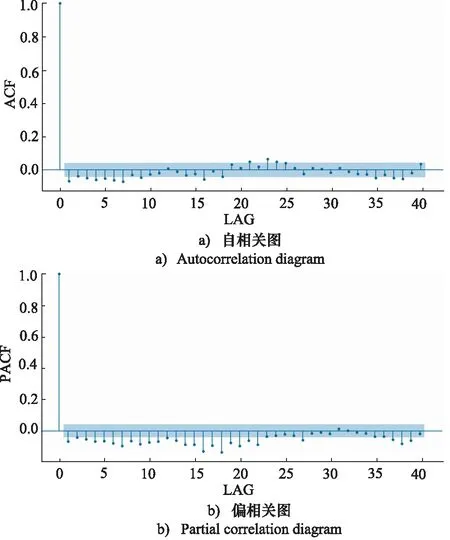
图3 掘进速度自相关与偏相关图
3 ARIMA预测模型
3.1 ARIMA模型
ARIMA模型[10]的核心思想就是在ARMA模型建立之前,采用适当阶数的差分运算,对要进行拟合和预测的时间序列进行平稳化处理,使得数据能够符合ARMA 模型对时间序列的平稳性要求,然后采用ARMA模型对时间序列进行预测。
若时间序列当前值没有外界干扰量而仅由过去时刻序列值决定,则这种线性关系能够用自回归模型(AR)来描述:
xt=δ+φ1xt-1+…+φpxt-p+εt
(2)
式中,δ—— 模型的常数项
φp——p阶回归项系数
εt—— 序列残差
xt—— 当前时刻的序列值
ARMA中的移动平均模型数学表述为:
xt=ε+ε1+μ1εt-1…+μqεt-q
(3)
由AR模型和MA模型构成的ARMA则为:
xt=φ1xt-1+…+φpxt-p+
δ+εt+μ1εt-1…+μqεt-q
(4)
而基于ARMA模型,做d阶差分可得ARIMA模型:
yt=Δdxt=(1-L)dxt
(5)
因此可对yt建模得到:
yt=φ1yt-1+…+φpyt-p+
δ+εt+μ1εt-1…+μqεt-q
(6)
该模型的特征方程为:
Φ(L)Δdxt=δ+Θ(L)εt
(7)
最后,得到 ARIMA(p,d,q)模型[11]。
3.2 一阶差分与ADF检验
d取1时,针对预处理后的掘进速度数据进行的一阶差分时序图,如图4所示。
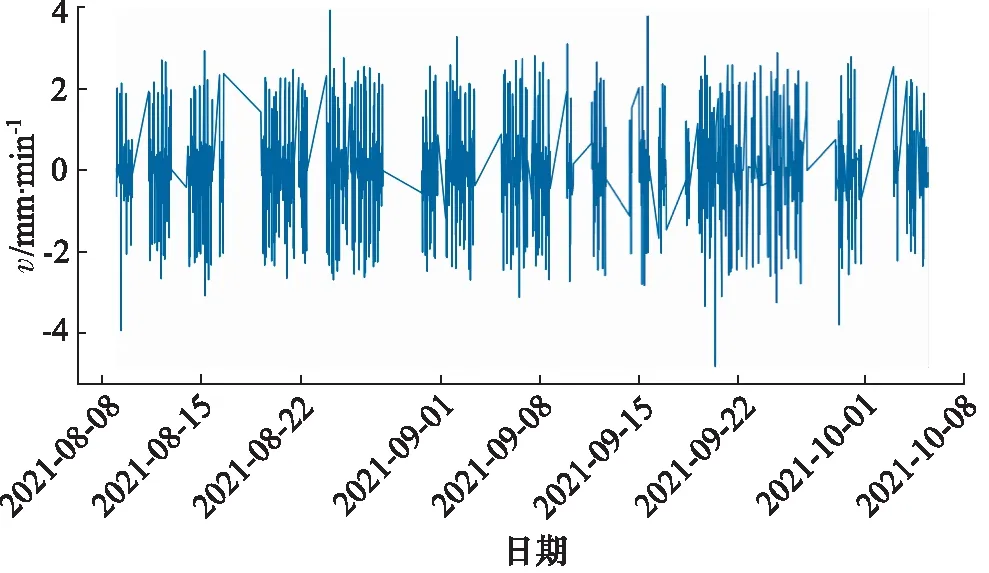
图4 掘进速度一阶差分时序图
在获得一阶差分数据后,接下来对一阶差分前的原始数据与差分后数据做平稳性检验(ADF检验)[12]。ADF检验就是判断序列是否存在单位根,如果序列平稳,就不存在单位根,否则,就会存在单位根。
因此,ADF检验的H0假设就是存在单位根,如果得到的显著性检验统计量小于3个置信度10%,5%,1%,则对应有90%,95%,99%的把握来拒绝原假设,分析结果如表4所示。
表4中的T统计量为ADF 测试结果。根据上述表格可以看出,原始序列与差分序列的3个置信度相同,而T统计量皆小于3个置信度,因此,序列拒绝原假设,也即差分后序列平稳。
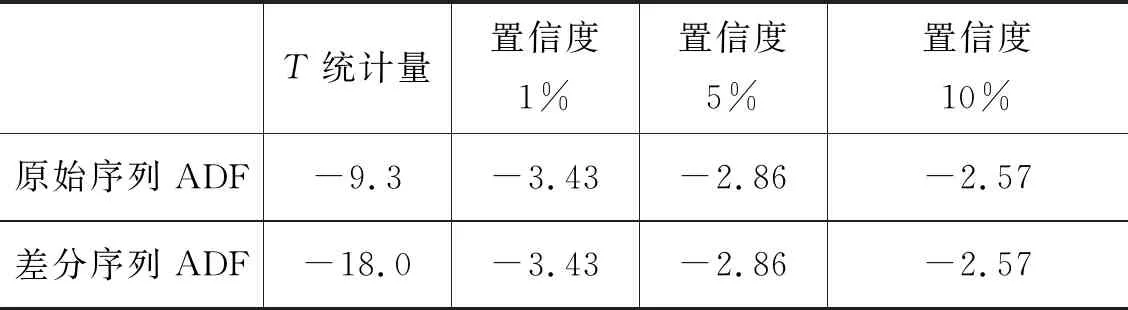
表4 原始序列与差分序列ADF检验结果对比
接下来对数据组进行白噪声检验,所获得的差分序列的白噪声检验结果为:(array([14.3781688]), array([0.00014953])),其中array([0.00014953])表示p值远小于0.05,所以可以判断所选择的数据是稳定的。
根据计算与自相关分析,选择p值为1,q值为1。
3.3 模型优化

根据贝叶斯定理有:
(8)
其中,P(y1,…,yn|Mj)为该模型的边缘概率,假设在不知道任何数据的情况下各个模型是同样合理的,则式中的P(Mj)为定值,因此,最大化后验概率等价于最大化模型的边缘概率,可得:
(9)
式中,Θj—— 模型Mj的参数向量
L—— 似然函数
gj(θj) ——θj的分布函数
使用贝叶斯方法来优化模型时,不需要考虑参数的先验概率,当很多参数先验无法求出时,比如本研究中的盾构机液压推进系统参数,可以使用贝叶斯因子比较2个模型的好坏,进而达到优化模型的目的。
4 基于ARIMA模型预测
4.1 基于K-means聚类的RNN预测方法
K-means的核心思想为:把n个数据对象划分为K个类别,并且使每一类别中的所有数据对象到该类的聚类中心点的平方和最小。RNN是一种特殊的神经网络结构,其可以考虑前一时刻的输入,而且具有对前面数据的记忆功能,该方法可以用于处理序列数据。本研究所用K-means与RNN预测算法流程如图5所示。
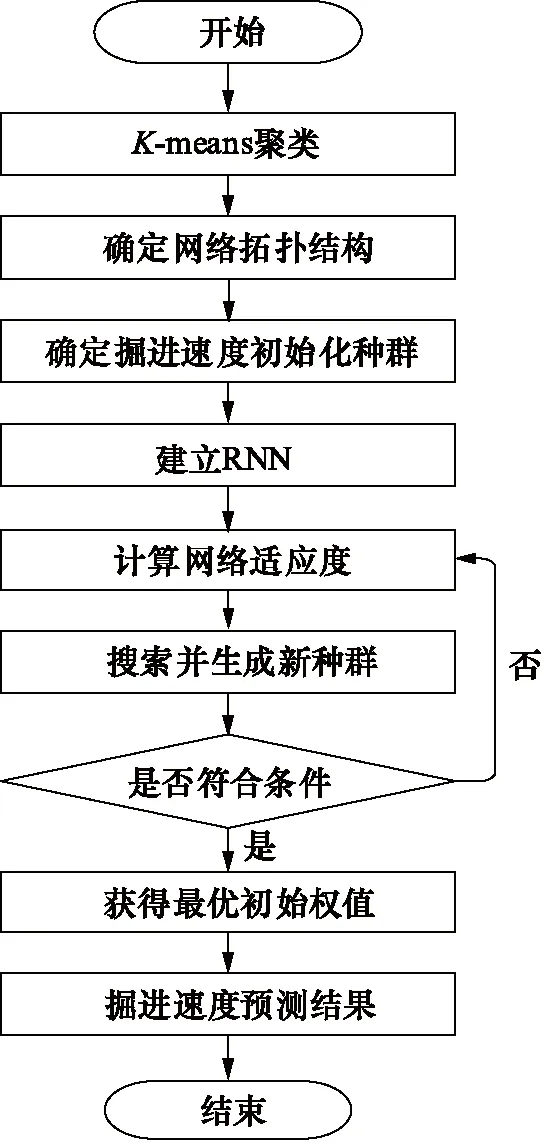
图5 基于K-means聚类的RNN预测算法流程[13]
4.2 线性回归预测方法
一元线性回归分析预测法,是根据自变量X和因变量Y的相关关系,建立X与Y的线性回归方程进行预测的方法。本研究选用一元线性回归分析掘进速度数据,式(10)为一元线性回归公式:
y=ω0+ωixi
(10)
该方法是引入自变量,将因变量与自变量作一元回归,并选出与因变量相关度最为密切或者是检验最显著的一元线性回归方程,建立最终的线性回归预测方程。
4.3 数据预测及预测结果
基于上述ARIMA模型,利用K-means方法,提取数据的前66%为训练集,后33%为测试集进行训练,基于训练结果及一阶差分结果进行预测,图6为对盾构机液压推进系统掘进速度进行的预测结果,预测数据的时间为2020-10-03~05。在预测初期不能很好的预测结果,但是后期能逐步跟随实际趋势,但是预测效果不理想。

图6 掘进速度基于K-means预测结果
之后基于该模型利用线性回归方法对数据进行预测,预测结果如图7所示,可以看出,该方法能很好的预测盾构机液压推进系统数据的变化趋势,而且能清楚的检测出数据内包含的异常值,所以相较于K-means预测方法,更能体现出对工程实际施工过程中的异常检验与趋势预测,更加符合工程应用。
图7中圆点为异常情况, 该情况下预测结果与实际结果幅值相差较大,可以看出,整体的趋势预测较为准确,在工程上,对预测结果造成的影响因素有很多,比如岩石层的结构、盾构机的状态等,所以很难获得非常准确的结果,但是基于本研究的方法,能获得盾构机液压推进系统参数的趋势预测, 且幅值误差相对较低。
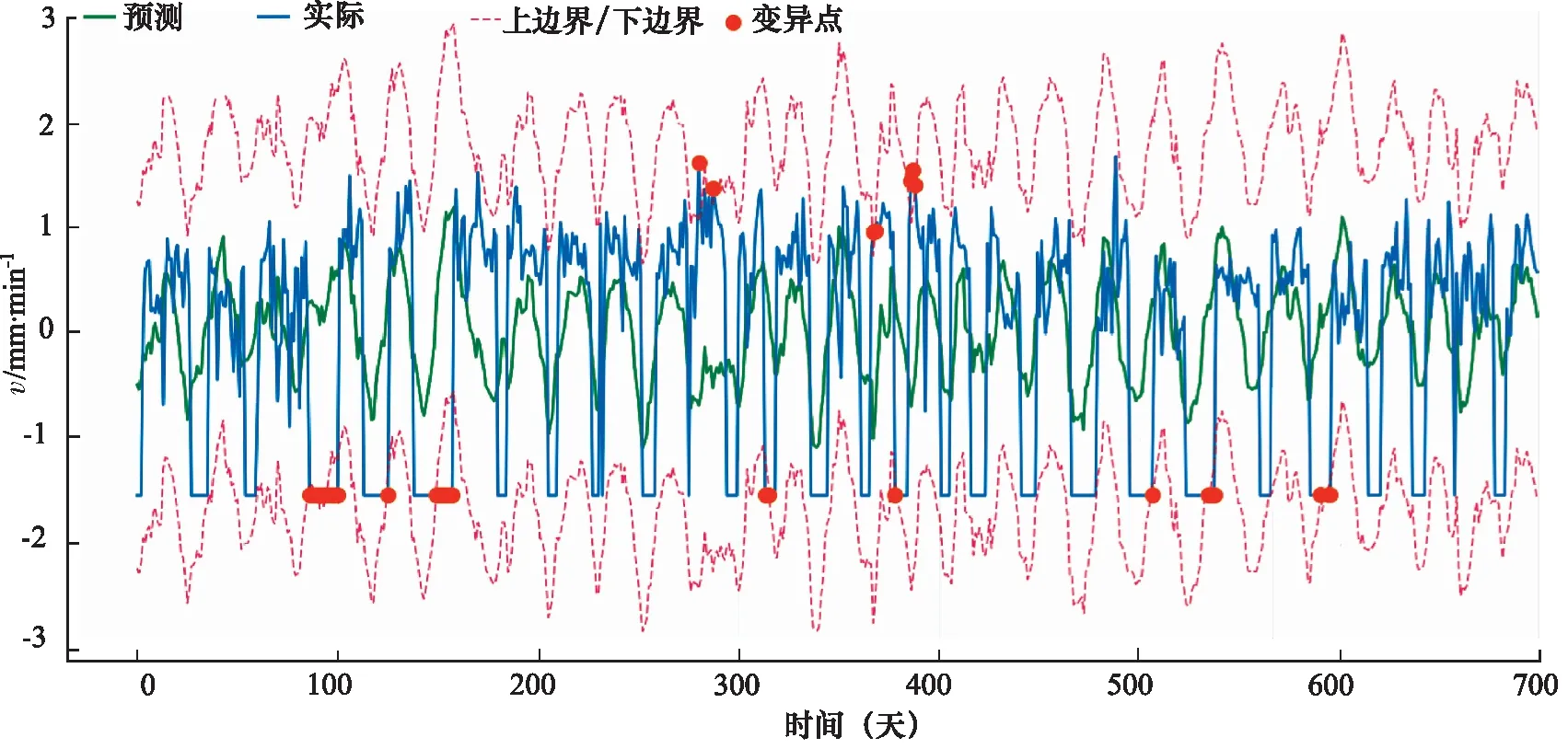
图7 掘进速度基于线性回归预测结果
5 结论
(1) 盾构机液压推进系统具有施工环境恶劣、安全性能要求高等特点。本研究基于ARIMA方法,建立了盾构机液压推进系统的预测模型,基于相关性分析及平稳性检验,获得了被用来预测的有效数据组,之后对相关模型进行搭建及模型优化。
(2) 本研究分别利用基于K-means聚类的RNN预测方法及线性回归方法对模型数据组进行了预测,可以得到,基于K-means聚类的RNN预测方法对盾构机推进系统的ARIMA模型下的数据预测结果不理想,存在着较大的误差,数据趋势不能预测准确;而基于ARIMA模型的线性回归预测方法却能很好的预测出数据的变化趋势,并且能预测出数据中的异常值,即可能会引起故障的数据。
猜你喜欢
新世纪智能(数学备考)(2021年5期)2021-07-28
重型机械(2020年2期)2020-07-24
石油化工建设(2018年2期)2018-07-11
凿岩机械气动工具(2016年2期)2016-11-11
中国房地产业(2016年9期)2016-03-01
工程建设与设计(2016年4期)2016-02-27
信息安全研究(2015年3期)2015-02-28
太空探索(2014年1期)2014-07-10
凿岩机械气动工具(2014年2期)2014-03-01
中国质量与标准导报(2014年7期)2014-02-28
