
基于特征融合的6D目标位姿估计算法
2023-02-21 12:54:04李占利何志强
计算机工程与设计 2023年2期
马 天,蒙 鑫,牟 琦,2+,李占利,何志强
(1.西安科技大学 计算机科学与技术学院,陕西 西安 710054; 2.西安科技大学 机械工程学院,陕西 西安 710054)
0 引 言
6D目标位姿估计是指对于已知类别的目标,获取目标到相机坐标系的单应性变换,通常使用旋转R和平移t组成的齐次变换矩阵表示该单映性变换[1],被广泛应用于机器人抓取[2,3]与增强现实[4]等领域。
基于深度学习的位姿估计方法根据输入类型划分,分为基于RGB图像和基于RGB-D图像的方法。Mahdi等[5]和Tekin等[6]通过神经网络在RGB图像中确定目标3D边框顶点的2D坐标,形成2D-3D对应点对,并使用PnP算法计算目标位姿。该方法对于弱纹理目标有较好的效果,但是难以处理对称目标,于是Xiang等[7]提出端到端的网络PoseCNN解决了该问题。基于RGB图像的方法能够以较快的速度完成位姿估计,并且能在一定程度上解决弱纹理目标位姿估计问题,但是易受光照和遮挡影响[8]。RGB-D图像能够在RGB信息的基础上,提供额外的Depth信息进行补充[9],从而获得更高的位姿估计精度。Wadim等[10]使用RGB图像获取目标初始位姿;然后结合Depth图像,采用ICP算法进行优化。Li等[11]提出密集融合网络DenseFusion,该网络将Depth图像中的分割目标转化为点云,使用PointNet[12]提取点云特征作为特征融合的几何输入,然后逐像素的将RGB图像中目标的颜色特征与几何特征进行融合,输出初始位姿。Hu等[13]借助DenseFusion网络获得目标融合特征,然后通过Dual-Stream网络学习不同图像中目标特征之间的一致性,从而获得位姿估计结果。Li等和Hu等的方法在特征融合时,单独的对每个点进行操作,较少考虑点云之间的联系[14],导致几何特征提取不足。
本文的位姿估计算法在特征融合时,通过局部区域建立点云之间的联系,从细粒度的局部几何特征扩展到全局,并实现几何特征与颜色特征的融合,完成位姿估计。
1 算法思想
高精度位姿估计需要充分、准确的提取目标特征。RGB图像和Depth图像分别含有目标的颜色特征与几何特征。通常一定大小的局部区域内的目标点云,共同涵盖着目标的细节结构信息,对局部区域的点云进行特征提取,能够获取点云之间存在的细粒度几何特征。然而,不同区域点云密度不一定均匀,稠密区域提取精细几何特征的方式,可能会破坏稀疏区域的局部结构。因此,本文通过PSA(point set abstraction)[15]模块将点云划分为不同的局部区域,在局部区域内对不同半径尺度空间内的点云提取特征;当局部区域的密度不同时,对容量相同,分布相近的点云提取特征,从而增强提取局部几何特征的鲁棒性,获得较为精细的点云局部几何特征。然后通过一个多层感知机(multilayer perceptron,MLP)在局部几何特征的基础上提取全局几何特征。这样通过PSA模块,将点云划分为不同的局部区域,从小区域中获得精细的局部几何特征,然后进一步获取更大区域的局部几何特征,最后通过MLP获得点云的全局几何特征,为位姿估计提供充足的目标几何特征。
2 算法步骤
本文的位姿估计算法分为3个阶段,如图1所示。第一阶段:目标分割。对RGB图像进行语义分割,得到目标掩码及最小包围框;利用目标掩码在Depth图像中分割目标,并将其转化为点云;利用最小包围框在RGB图像中分割目标。第二阶段:特征提取与特征融合。首先在RGB图像和点云中,分别提取目标的颜色特征和点云特征。然后选择N个位置点,将N个位置点的点云特征与颜色特征进行融合,形成点融合特征;使用PSA模块将点云划分为不同局部区域,并提取局部几何特征,与颜色特征融合形成局部融合特征;使用一个三层MLP,对PSA模块提取局部几何特征后的点云,提取全局几何特征;最后将点融合特征、局部融合特征和全局几何特征进行融合,形成最终的目标融合特征。第三阶段:位姿估计与迭代优化。首先使用融合后的特征训练网络,输出初始位姿;然后对初始位姿进行迭代优化,获得更加精确的位姿估计结果。
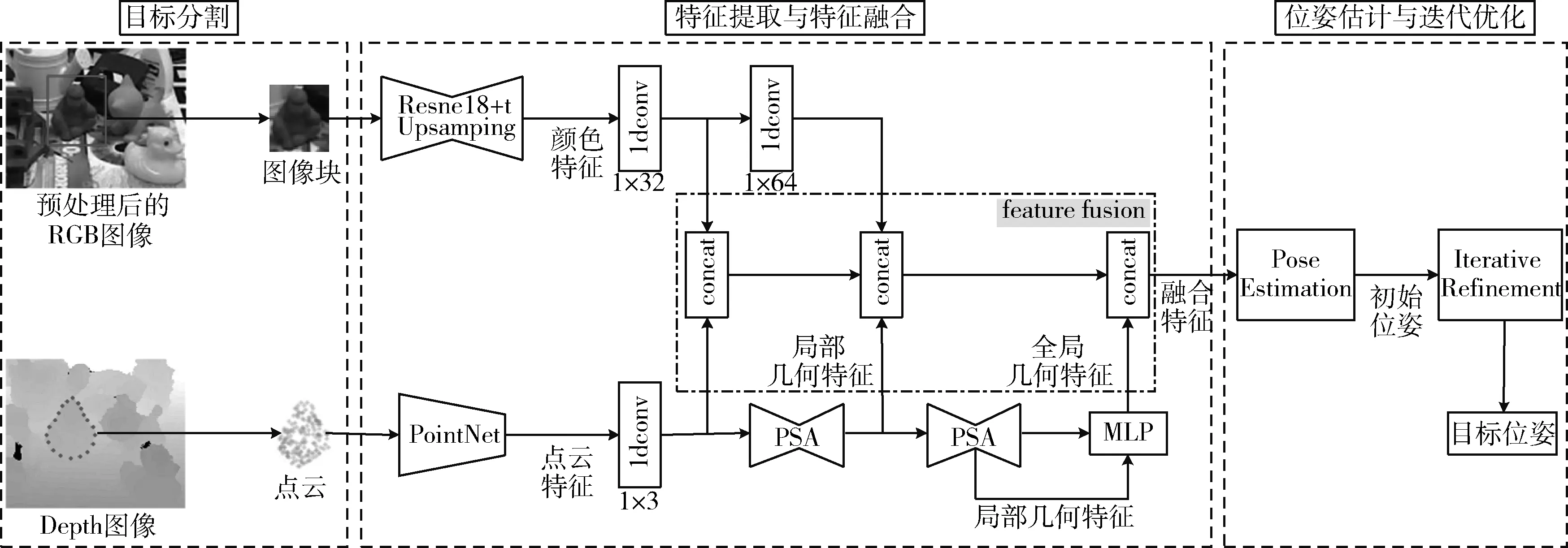
图1 本文6D位姿估计算法
2.1 目标分割
在目标分割阶段,对RGB-D图像中的目标进行分割。首先使用PoseCNN[7]网络的语义分割结构对RGB图像进行分割,得到目标掩码及最小包围框;然后使用目标掩码在Depth图像中分割目标,并通过相机内参将其转化为点云,同时,使用最小包围框在RGB图像中分割目标。Depth图像像素坐标 (u,v) 变换为点云 (X,Y,Z) 公式如式(1)
Z=z(u,v)
(1)
其中,Depth图像中每一个像素值z(u,v) 表示现实场景中的点到相机镜头的距离。fu和fv分别代表水平焦距和垂直焦距, (u0,v0) 为相机中心坐标。
2.2 特征提取与特征融合
在特征提取与特征融合阶段,获取目标的颜色特征与点云特征,并将两者进行融合。特征提取在RGB图像和点云中,分别提取目标的颜色特征和点云特征,作为特征融合的输入。与DenseFusion[11]算法相同,本文使用Resnet18网络进行编码,提取目标的颜色特征,通过4个上采样层进行解码,同时,使用PointNet[12]网络提取点云特征。
特征融合在点云中选择N个位置的点云,并借助相机内参在图像中找到对应投影位置的像素点,对N个位置点的特征进行融合,这样对目标可见部分的特征进行融合,可以降低目标遮挡以及目标分割可能存在偏差的影响。首先将N个位置点的颜色特征与点云特征进行融合,形成点融合特征;然后使用PSA模块在局部区域内对点云提取局部几何特征,与颜色特征融合后形成局部融合特征。PSA模块提取局部几何特征过程如下:①使用最远点采样的方式,找到特定数量且在空间中均匀分布的点云。②分别以这些点云所在位置为中心点,将固定半径的球体划分为一个局部区域。③使用PointNet网络在局部区域内,分别对不同半径尺度球体内的点云提取特征,并将特征进行连接聚集。④用整个局部区域的特征表示位于中心点位置点云的特征。以二维举例,PSA模块如图2所示。最后对PSA模块提取局部几何特征后的点云,使用一个三层MLP提取全局几何特征,将点融合特征、局部融合特征和全局几何特征进行融合,形成最终的目标融合特征。
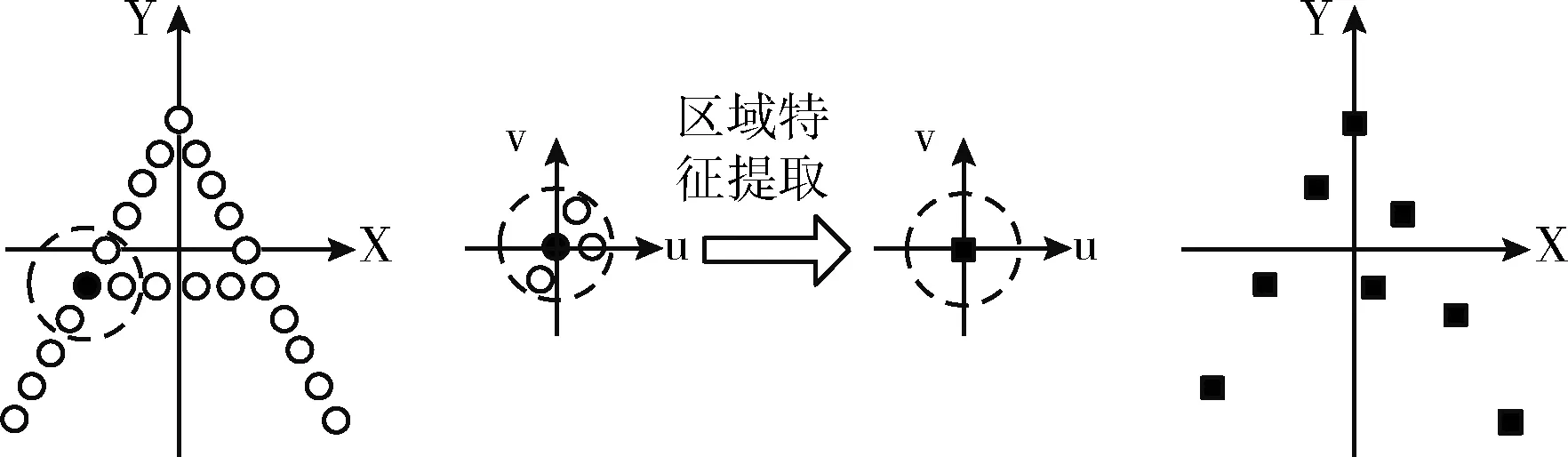
图2 二维PSA模块
2.3 位姿估计与迭代优化
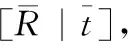
2.3.1 损失函数
损失函数通过置信度对位姿损失进行加权,并借助对数函数将置信度作为正则化项。位姿估计网络整体损失函数如式(2)
(2)
(3)
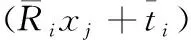

(4)
其中,xk表示与xj距离最近的点。
2.3.2 迭代优化
迭代优化需要以上一步获得的位姿为基础,为满足这一要求,将点云通过初始位姿变换为新点云,新点云便可对上一步的位姿进行隐式编码;然后,将新点云输入到网络中,提取点云几何特征,与颜色特征融合后预测位姿残差,进而调整位姿结果。迭代优化部分由4个全连接层组成,经过K次迭代后,最终位姿估计结果计算公式如式(5)
(5)
其中, [RK|tK] 表示第K次迭代后的位姿估计结果。本文K设置为2。
3 实验及分析
3.1 实验环境
本文提出的基于特征融合的6D目标位姿估计算法,实验环境见表1。

表1 实验环境配置
3.2 数据集及评价指标
3.2.1 数据集介绍
本文采用的数据集为位姿估计标准数据集LineMOD以及YCB-Video。
LineMOD数据集由Hinterstoisser团队维护,包含15种复杂背景下弱纹理目标的RGB-D图像序列。每个序列仅对一种目标进行位姿估计,该目标被放置在带标记平面板的中心位置,除该目标之外的另外14种目标随意摆放,标记用于提供目标相应的Ground Truth位姿。每个序列包含1100~1300张RGB-D图像。LineMOD数据集对13种目标进行实验,分别为Ape、Benchvise、Camera、Can、Cat、Driller、Duck、Eggbox、Glue、Holepuncher、Iron、Lamp以及Phone。其中,Eggbox与Glue两种目标具有旋转对称性,每种目标尺寸均不相同。
本文对以上13种目标序列进行实验,将每种目标15%的RGB-D图像划分为训练集,其余为测试集。训练集包含13种目标总2372张RGB-D图像,测试集包含13种目标总13 406张RGB-D图像。
YCB-Video是近年来开始使用的大型位姿估计视频数据集,由Xiang团队维护。数据集根据21种不同尺寸、不同纹理的YCB目标,从中任意选取3-9种目标搭建不同真实室内场景,每个场景中的目标都存在遮挡情况。对于不同场景的目标,使用RGB-D相机拍摄制成92个视频,然后对各视频间隔7帧提取一个关键帧,保存为RGB-D图像,并且使用合成图像扩大数据规模。YCB-Video还提供目标Ground Truth位姿和分割掩码。
本文使用编号0000-0047、0060-0091视频序列,以及合成的80000帧RGB-D图像数据用于训练,使用0048-0059视频序列共2949帧RGB-D图像进行测试。
3.2.2 评价指标
(6)
其中,M表示目标3D模型采样点集合,x表示采样点集合的第x点,m表示采样点数量。ADD精度为:正确位姿估计的数量占全部Ground Truth位姿数量的百分比;如果ADD小于阈值,则认为位姿估计正确。ADD精度计算公式如式(7)
(7)
其中,Numpre表示正确位姿估计的数量,NumGT表示全部真实位姿的数量。
(8)
其中,M表示目标3D模型采样点集合,x1,x2表示属于不同变换的采样点,x2为与x1距离最近的点。
ADD-S精度为:正确位姿估计的数量占全部Ground Truth位姿数量的百分比;如果ADD-S小于阈值,则认为位姿估计正确。ADD-S精度计算公式与式(7)相同。
(3)AUC面积。使用ADD-S指标计算不同阈值(最大阈值为0.1 m)下的位姿估计精度,然后绘制阈值—精度曲线(accuracy-threshold curve)。AUC面积表示阈值-精度曲线与阈值坐标轴围成的面积。
3.3 实验结果对比与分析
本文实验,对于LineMOD数据集,使用ADD精度评价非对称目标,使用ADD-S精度评价对称目标,阈值均设置为目标最大直径值的10%。对于YCB-Video数据集,使用ADD-S精度(阈值设定为0.02 m)与AUC面积评价全部目标。
图3为本文位姿估计算法在LineMOD数据集和YCB-Video数据集的可视化结果。LineMOD数据集只对位于标记板中心位置的目标进行位姿估计,红色点为当前目标3D模型上的采样点,经过估计位姿变换,然后投影到图像上的点,投影点与目标越契合,表示位姿估计结果越准确。YCB-Video数据集对场景中的全部目标进行位姿估计,不同目标投影点颜色不同。框选的目标表示,与对比算法相比,位姿结果差异较大的目标;从可视化结果可以直观看出,本文算法结果较优。

图3 位姿估计可视化结果
表2为LineMOD数据集,本文算法分别与其它算法未优化和优化的精度对比。表2第一行为目标实例名称,名称带有“*”号标记表示目标具有旋转对称性,最后一列为13种目标的平均位姿估计精度。

表2 LineMOD数据集精度结果对比/%
表中数值表示不同算法对于当前目标的位姿估计精度,数值越大说明该方法对当前目标的位姿估计效果越好。加粗表示该方法对于当前目标的位姿估计精度最高。
对于LineMOD数据集,本文算法分别与Real-Time[6]、PoseCNN[7]、DenseFusion[11]以及Dual-Stream[13]算法进行对比。Real-Time算法不需要对位姿估计结果进行优化,PoseCNN算法未优化时精度较低。因此,此处只与Real-Time算法未优化,PoseCNN算法优化结果进行对比。其中,PoseCNN使用ICP算法进行优化,Dual-Stream与本文均使用DenseFusion提出的迭代优化算法进行优化。
实验结果显示,未对位姿估计结果优化时,本文算法13种目标的平均精度与Real-Time算法平均精度相比提高31.5%,与DenseFusion相比提高1.4%,与Dual-Stream相比提高0.5%。位姿估计结果进行优化之后,对于13种目标的平均精度,本文算法优于其它算法;与本文算法未优化相比,平均精度提高7.7%。本文算法未对位姿估计结果进行优化时,对Ape、Duck和Holepuncher这3种目标位姿估计精度相对较低,原因可能有两种,其一,本文实验使用点集抽象提取局部几何特征时,13种目标选择相同的多尺度半径,导致上述3种目标提取的局部几何特征与其它目标相比不够精细;其二,本文算法位姿估计网络损失兼顾全部目标,而验证时要求ADD小于目标最大直径的10%则认为位姿估计正确,以上3种目标的最大直径较小,均低于0.14 m,Ape目标最大直径仅有0.1 m,评价阈值相对较低,导致精度降低。除小型目标之外,本文算法对其它目标的精度均有较优的表现,说明本文算法充分提取目标几何特征,并与颜色特征进行融合的方法,能够提升弱纹理目标的位姿估计精度,对于弱纹理目标具有较优的表现。
表3为YCB-Video数据集,本文算法与其它算法未优化时AUC面积与精度的对比结果。表3第一列为目标实例名称,名称带有“*”号标记表示目标具有旋转对称性,最后一行为21种目标评价指标的平均值。表3数值表示每种方法AUC面积与ADD-S精度两个评价指标的结果,数值越大说明该方法对当前目标的位姿估计效果越好。加粗表示该方法对于当前目标的评价指标结果最高。
由表3可知,本文算法21种目标的AUC面积平均值与PoseCNN算法的AUC面积平均值相比提高5.6%,与DenseFusion相比提高1.0%,与Dual-Stream相比提高0.5%。本文算法ADD-S精度平均值与PoseCNN相比提高16.3%,与DenseFusion相比提高0.9%,与Dual-Stream相比提高0.4%。本文算法对于051_large_clamp和052_extra_clamp目标表现与其它目标相比较差。这是因为,两个目标差别较为细微,网络难以对两者进行区分,导致位姿估计表现与其它目标相比较差。除上述两种目标,本文算法对于其它目标均有较优的表现,说明本文算法充分提取目标几何特征,并与颜色特征进行融合,能够提升遮挡目标的位姿估计精度,对于遮挡目标具有较优的表现。
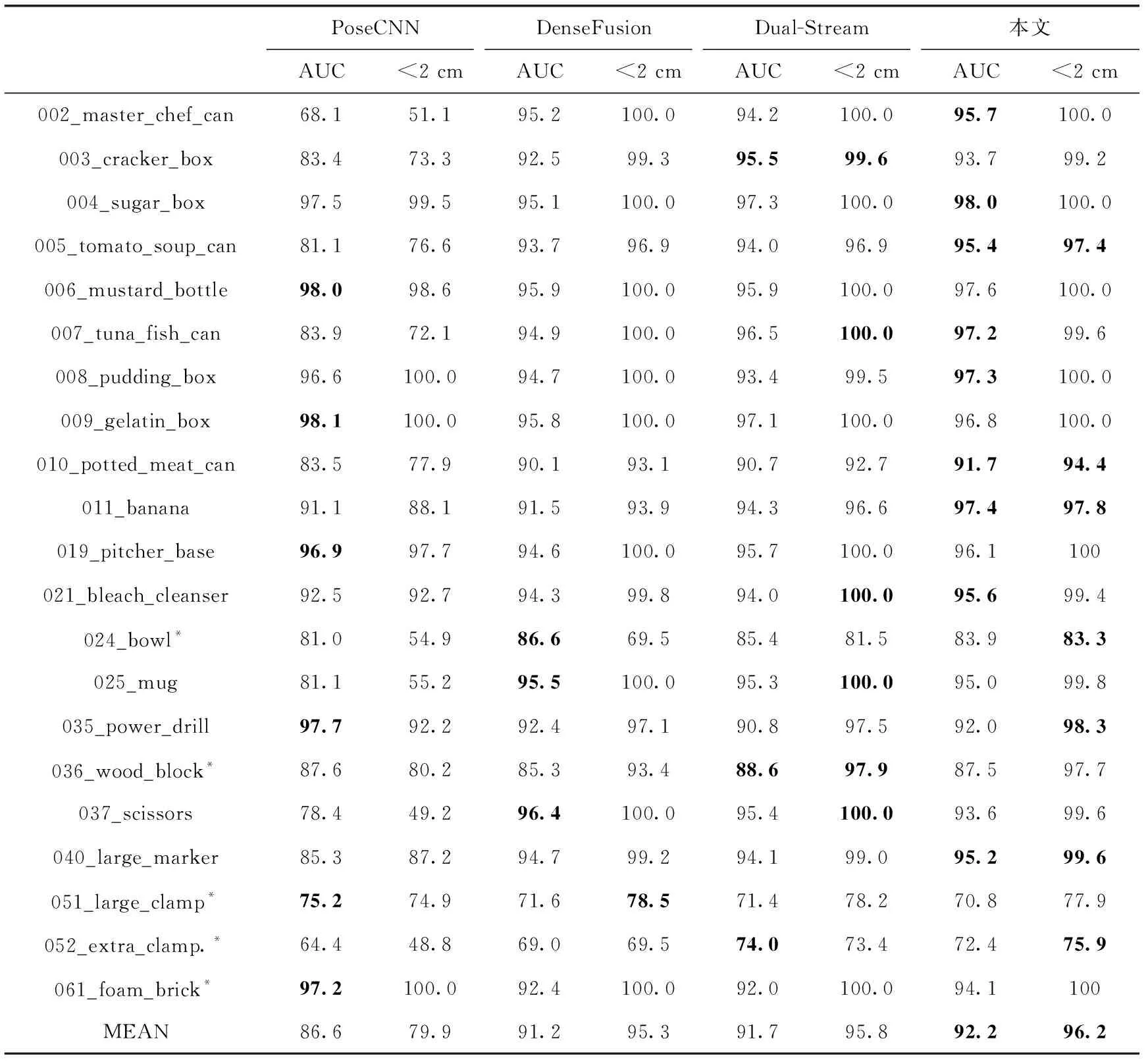
表3 YCB-Video数据集AUC面积及ADD-S精度结果对比/%
表4为Real-Time、PoseCNN和DenseFusion这3种算法与本文算法位姿估计所用总时间的对比结果。主要分为,分割时间、位姿估计时间以及优化时间进行对比。
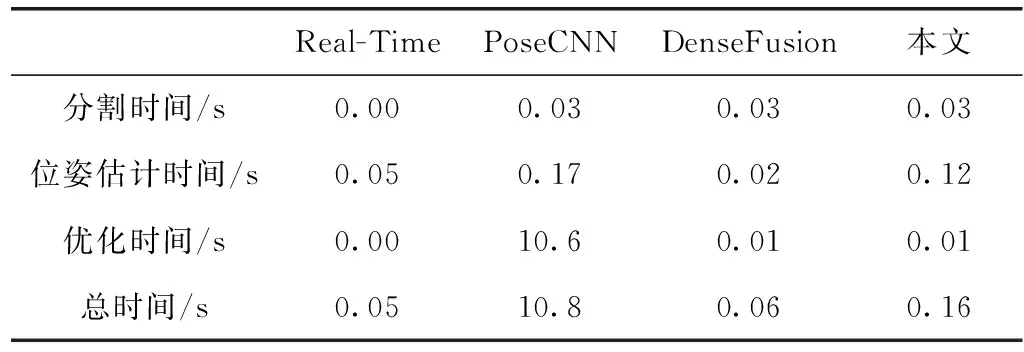
表4 Real-Time、PoseCNN、DenseFusion和本文算法运行时间对比/s
Dual-Stream算法原文未提及算法用时,且论文代码尚未开源,此处不与其作对比。Real-Time算法不需要进行分割,分割时间为零。PoseCNN、Densefusion与本文算法均使用相同的语义分割方法,因此,分割时间相同。不同算法使用不同优化策略进行优化,优化用时也不相同。其中,Real-Time算法不需要对位姿估计结果进行优化;PoseCNN使用ICP算法进行优化,耗时最长;本文使用DenseFusion算法的迭代优化方法,优化时间为0.01 s。由表4可知,本文算法完成一次位姿估计总时间与最快的Real-Time算法相差0.11 s,时间表现中等。这是因为,使用点集抽象提取局部几何特征,需要在3D空间确定局部区域中心点位置,耗费一定时间。
4 结束语
本文算法在局部区域内获取点云精细的几何特征,并与颜色特征进行融合,实现位姿估计。实验结果表明,该算法对于LineMOD数据集中体积中等或较大的目标,位姿估计精度有明显提升,对于LineMOD数据集与YCB-Video数据集所有目标的平均位姿估计精度均有较优的表现。但是,由于提取局部几何特征需要耗费一定时间确定区域中心位置,算法时间表现中等。
续上表由于提出的算法是一种先进行特征提取,然后进行特征融合的方法。所以,在特征提取过程中,两个分支没有交互,限制了提取的目标特征的表征能力。因此,在未来工作中,考虑在特征提取的过程中进行特征融合,并且从获取点云局部几何特征的角度降低算法耗时。
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-22 22:13:22
数学物理学报(2021年2期)2021-06-09 08:54:42
电子制作(2018年11期)2018-08-04 03:25:38
光学精密工程(2016年5期)2016-11-07 09:05:55
光学精密工程(2016年4期)2016-11-07 09:05:11
发明与创新(2016年38期)2016-08-22 03:02:50
艺术生活-福州大学厦门工艺美术学院学报(2016年3期)2016-07-31 19:42:13
测绘科学与工程(2016年5期)2016-04-17 06:51:15
湖北工业大学学报(2016年5期)2016-02-27 13:14:48
电子设计工程(2015年3期)2015-02-27 12:03:45
