
融合多尺度残差注意力的图像修复算法
2023-02-21 12:53:56钱冠宇邓红霞刘健虎李海芳
计算机工程与设计 2023年2期
钱冠宇,邓红霞,刘健虎,李海芳
(太原理工大学 信息与计算机学院,山西 晋中 030600)
0 引 言
传统的图像修复方法主要有两种,一种是使用偏微分方程修复的方法,采用扩散的思路,将信息缺失部分附近的信息扩散到待修复部分[1-3]。但这种修复方法仅适用于缺失面积较小的情况。之后学者提出另外一种块匹配方法[4,5]。从图像中未缺失的部分进行检索匹配出与缺失部分相似的区域,然后再进行对修补缺失部分,能够达到较好的修复效果。但这类修复方法比较依赖待修复图像中存在的信息,如果不能匹配到与缺失部分相似的信息块,那么它修复缺失区域的效果则不会很好。
针对传统方法的局限性,提出神经网络[6-15]的方法来提高图像修复的质量。李等[16]提出了一种多尺度生成对抗网络图像修复算法,提高了图像修复的精确度,但在某些情况下修复图像会看起来很不自然,出现这种情况的原因可能是由于网络在卷积过程中提取了一些无效像素的特征。肖等[17]提出了结合感知注意力机制的生成对抗网络图像修复算法,得到更合理语义信息的修复效果;然而,该方法无法修复不规则破损区域的图像。针对以上的问题,本文采用生成对抗模型来修复图像,引入残差注意力模块提取缺失区域的有效信息以及通过多尺度判别器对全局和局部信息的一致性约束,最终实现缺失图片的修复。通过实验的对比,进一步探讨本文算法的性能。
1 生成对抗网络
生成对抗网络(generative adversarial network,GAN)是Goodfellow等[18]提出的一种新理念深度学习模型,它是在相互博弈中达到平衡的一种网络模型。原始的GAN模型将一个随机的噪声向量Z输入到生成网络中,然后输出一张生成的假图片,与真实的图片一起送入判别网络中判定图片真假的概率,并将判别的结果反馈给生成网络。原始GAN模型由于模型易崩塌的缺点,只能生成低分辨率图像,生成的图像较为模糊。GAN网络问世以来,大多数学者开始研究一系列变种GAN网络,例如把条件控制信息加入到GAN网络的训练中,以控制输出的结果属性。Arjovsk等[19]提出的一种新的截断损失函数可以极大提高GAN网络训练的稳定性,避免模型崩塌,能够合成质量更好的样本。之后引起了一系列GAN网络的研究及应用,以及能够生成高分辨率图像的GAN网络被提出,例如DCGAN,CycleGAN等网络。随着这些变种GAN网络的出现,GAN网络的各种应用研究也因此极大增加。例如在低质量数据的提升上有超分辨率重建,图像的去雨去雾和去除模糊,图像的修复这些方面GAN网络都有一定的效果,通过改进GAN网络的结构和约束范式可以进一步提高这些低质量数据方法的提升效果。
2 融合多尺度残差注意力的修复方法
MRS-Net(multiscale residual squeeze-and-excitation networks)模型与生成对抗网络相似,整体网络框架分为一个修复网络和D1、D2两个不同尺度的判别器网络以及一个预训练的Vgg16网络。MRS-Net模型整体框架如图1所示。

图1 MRS-Net框架
修复模型结构如图2所示,将256*256修复模型图片通过编码器进行4次下采样,下采样后会增大感受野,但会造成部分特征丢失,因此采用24块残差序列注意力块来强化重要通道的特征,弱化非重要通道的特征,进行更好的特征提取,提高模型计算能力,最后通过解码器进行4次上采样输出256*256修复后的图片,同时在下采样和上采样之间使用跳跃连接层可以更好地利用图像原始信息,能够更好推测出缺失部分信息。将修复的结果进行重构损失、感知损失、风格损失、全变分损失、多尺度联合判断修复图像与真实图像的相似程度,判断修复结果的好坏,并将结果反向传播给修复模型,网络依据反馈结果进行梯度下降寻找最优模型参数,可以让修复的图片在完成修复的情况下近似于真实图片,能够“骗过”判别器,以达到较好的修复效果,同时可以提高模型的鲁棒性。
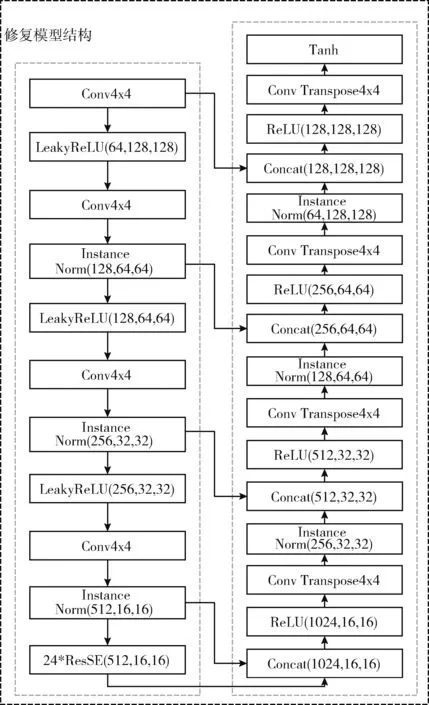
图2 修复模型结构
多尺度判别器网络结构如图3所示,使用了两个较为浅层的网络作为判别器,通过使用二进制的交叉熵损失来反馈给判别网络,判别网络依据反馈结果进行梯度下降寻找最优模型参数,可以更好地判别修复结果。经过两个网络的相互迭代博弈使模型达到最优修复的效果。

图3 多尺度判别器网络结构
算法整体流程是在修复模型输入添加不同形状掩码后生成的256*256缺损图像,经过修复模型的修复,然后输出256*256修复图像,计算修复后图像的重构损失,全变分损失,通过一个预训练的Vgg16模型来提取图像的浅层和深层特征来计算感知损失,风格损失,并且将修复后的图像下采样为128*128的图像,指导其修复图像,同时可以避免生成器在博弈过程中产生过拟合现象,提高模型的泛化能力。两个判别器模型对图像的修复会有不同的约束,大尺度的判别器增强了图像全局结构的完整性,小尺度的判别器增强了图像的纹理细节,增强了修复后图像的真实感。将修复模型修复后的图像和原始完整图像输入第一个判别器网络,下采样的修复图像和下采样的原始完整图像输入第二个判别器网络,然后联合两个判别器网络输出的结果进行计算。通过加权融合多种损失结果来反向传播给修复模型。
2.1 残差注意力模块
在计算机视觉中,注意力的目的是让神经网络在学习过程中能够忽视无用信息并且重点关注有用信息。SE注意力[20]可以加强重要的通道信息,弱化不重要的通道信息,加强了子通道信息之间相关性。它通过全局平均池化、全连接层让特征映射提高全局感受野,能够利用图像的全局信息进行预测修复。本文提出的残差注意力模块结构如图4所示,输入模块中的是512*16*16的特征图。图像缺损区域的信息通常不仅和同一子通道的上下文像素点有紧密联系,在不同子通道之间也会有密切联系。因此,将SE注意力[20]模块嵌入到残差结构中,可以增加特征图中通道之间的联系。通常加深网络层数会在学习过程中提高网络的计算能力,但是会发生过拟合现象,梯度传播困难,同时造成资源浪费。而残差机制能使网络层次不断加深并且可以有效防止梯度消失以更好的提取图像缺失部分特征,确保前面层的特征被再利用,从而避免过深的计算造成的信息损失。因此残差注意力模块能帮助提取图像缺损区域的有效信息,尽管整个网络会稍微增加了一点计算量,但是能够达到比较好效果。
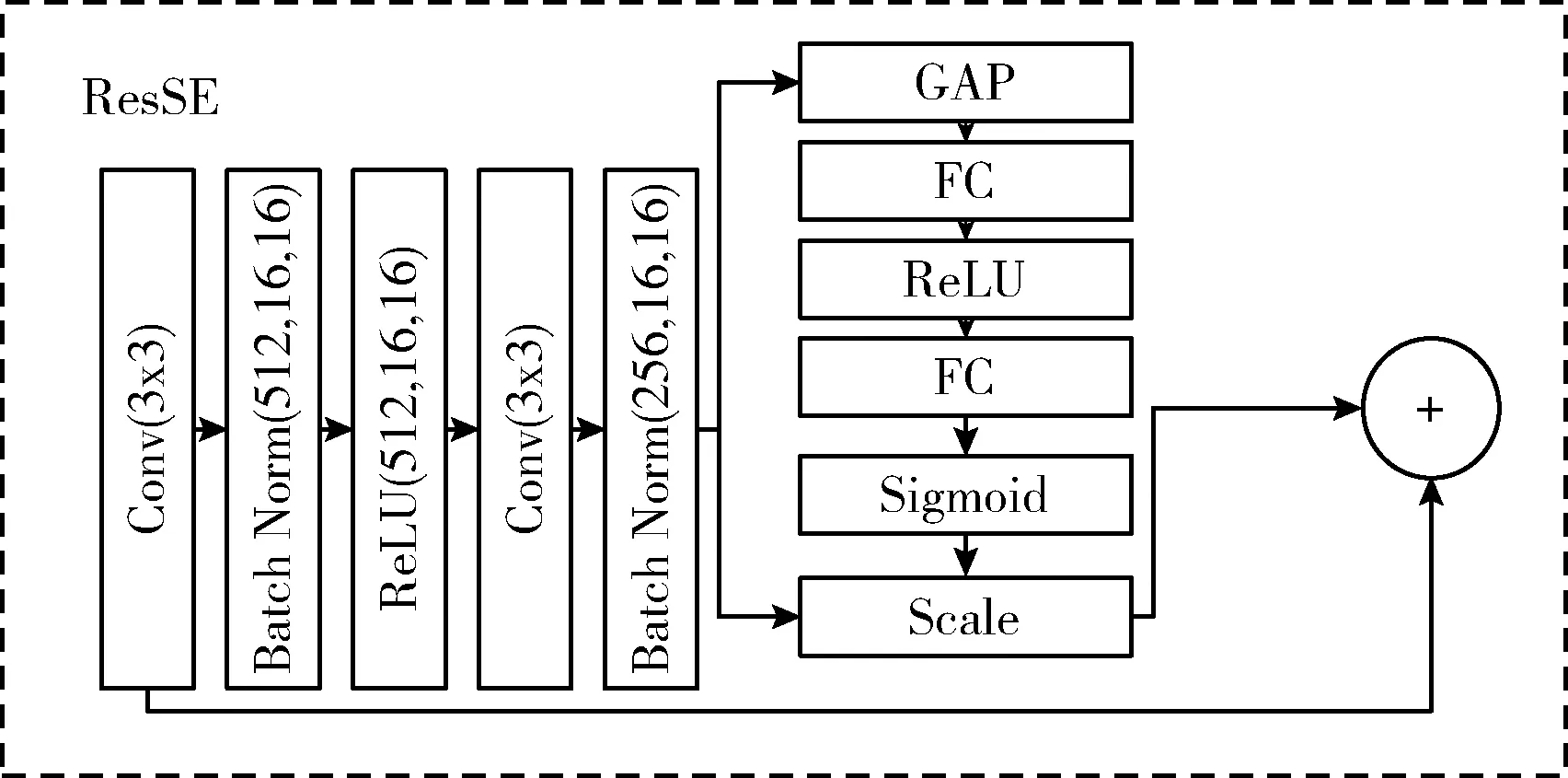
图4 残差注意力结构
2.2 多尺度判别器
多尺度判别器是两个网络结构相同,尺度不同的判别器,它对生成256*256的图像以及下采样后128*128的图像进行鉴别,输出一个到0,1之间的分数。不同尺度的判别器往往具有不同的感受范围。因为修复后的图像往往产生模糊以及高频信息的丢失,因此,结合图像全局和局部信息提高修复结果能够反馈给生网。
2.3 损失函数的构建
2.3.1 重构损失
在图像转换问题中,重构损失是一种基于输出图像与真实图像之间的差值方法,计算两幅图片中所有对应位置的像素点之间的均方差,最小化差值就会使两幅图像更相似

(1)
其中,1代表“1范式”。注意,N是使用缺失面积调整惩罚的分母。它意味着如果一个面被一个小的遮挡所干扰修复的结果应该非常接近实际情况,如果缺损程度较大,只要结构和一致性是合理的,则可以重新限制。
2.3.2 感知损失
通过最小化重构损失,来优化输出图像的数据,最终输出高质量的图像。但该方法的弊端是效率低下,实时性差。感知损失在度量图像相似性方面比重构损失更具鲁棒性。感知损失函数是两幅图像输入Vgg16网络后所提取特征之间的欧式距离,i表示修复后图像与原始图像在网络第i层特征图的欧氏距离
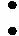
(2)
2.3.3 风格损失
风格损失函数是两幅图像输入Vgg16网络后所提取特征之间的格拉姆矩阵的欧氏距离。j表示修复后图像与原始图像在网络第j层特征图格拉姆矩阵的欧氏距离
(3)
2.3.4 总变分损失
总变分损失在低质量图像数据提升中经常应用于图像的去噪处理和修复处理。通常像素信息缺失图像的总变分和完整图像的总变分相比会有显著性差异。总变分是计算图像数据梯度幅值的积分。限制了总变分就会使图像变得更为平滑
(4)
2.3.5 生成对抗损失
修复网络将对抗损失最小化来反向传播更新网络,两个尺度的判别器网络将对抗损失最大化来反向传播更新网络。Pdate(Igt) 代表真实图像的分布,Pmiss(I) 代表输入图像的分布,D(.) 是判别器网络对于输入的图像是修复图像和真实图像的概率预测

(5)
2.3.6 联合损失
通过加权融合多种损失结果来判断修复图像与真实图像的相似程度,并将结果通过反向传播给修复模型,网络依据反馈结果进行梯度下降寻找最优模型参数
l=αladv+βlpixel+δlprec+εlstyle+ωltv
(6)
3 实验和结果分析
3.1 实验数据集
实验采用数据集CelebA和数据集Oxford Buildings,CelebA数据集是包含20万张人脸数据的公共数据集。实验选取48 100张图片,划分为训练数据集和测试数据集,训练数据集包括44 100张图片,测试数据集包括4000张图片。数据集Oxford Buildings包含上百万张各式建筑物图片,实验选取20 000张图片,使用19 800张为训练数据集,200张为测试数据集。在数据处理部分,对于每张图片检测人脸并裁剪成256*256大小的图片。实验数据使用的是成对的数据,完整图片相对的缺失数据较少且不容易收集,所以实验设计了中心矩形掩码,随机矩形掩码,随机数量的不同形状掩码,由已有完整图片添加缺失掩码生成缺失图片,从而产生成对的数据集。
3.2 实验设置
实验使用现较流行的深度学习框架Pytorch框架,实验软件配置为python3.6,硬件配置为i7+Nvida2080Ti,使用Linux操作系统。实验中Batch_size设置为1,使用Adam优化算法来优化模型,学习率设置为0.0002,beta1为0.5。实验设置30个epoch。
3.3 评价方法
实验中使用了SSIM(结构相似性)与PSNR(峰值信噪比)两种评价指标来测评修复后图像与真实的图像的差异性和相似性。这两种评价方法经常用来作为低质量的图像数据提升为高质量的图像数据的评价指标。SSIM的原理是从两幅图像的3个方面(亮度l、对比度c、结构s)来评测两幅图像的相似性。它的取值的范围为[0,1],数值接近1就代表着两幅图像越相似
SSIM(X,Y)=l(X,Y)*c(X,Y)*s(X,Y)
(7)
PSNR的原理是计算两幅图像对应的像素点之间的差异性,公式中MSE代表两幅图像的均方误差,较大的PSNR数值就代表着图像失真的程度较小
(8)
3.4 实验结果
本节针对不同的实验结果分为3部分进行讨论分析与总结,第一部分是与不同模型的方法在公共数据集上的性能指标对比,以及与不同模型方法中修复后的可视化结果对比。第二部分是消融实验,同时讨论了残差注意力块层数和使用的不同损失函数对于MRS-Net的影响。第三部分是与不同模型方法在不同缺失面积的修复结果之间的比较,以及与不同模型方法在大面积的缺失的修复结果之间的比较。
3.4.1 对比实验
将MRS-Net与CE、GL、PIC-Net、Shift-Net等在图像修复方面具有代表性的算法进行比较。在图5的结果对比中可以看出CE算法无法推测出图像中合理的缺失信息;GL算法可以计算出图像中较为合理的缺失信息,但是在一些地方有较明显的差异性;PIC-Net算法可以使图像的修复结果较为合理,但和真实的图片有些差距,同时修复局部地区存在一些伪影;Shift-Net算法能够计算出图像中合理的缺失信息,并达到较好的效果,但是在图像的细节不具有较好的一致性;MRS-Net修复图像的结果相比于其它几个模型有进一步提高,同时具有更加精细的纹理细节,修复的结果有更好的一致性。图6可视化了不同修复算法在4种缺失类型的图片,从图6的结果可以看出MRS-Net在4种缺失类型可以较好完成修复任务。在较大面积缺失时其它的算法对于修复效果有一定的偏差,而MRS-Net可以较好弥补这些缺陷,合理修复缺失部位;在局部细节信息缺失时,对比的算法对于像眼睛、眉毛等部位的缺失达达不到较好的修复水平,而MRS-Net的修复结果对于局部精细部分有更好的修复效果。

图5 不同算法对比结果

图6 不规则破损图算法对比结果
为了验证MRS-Net具有较好的修复性能,使用PSNR和SSIM两个图像评价指标来对比经典修复算法与MRS-Net在测试集上的修复效果。从表1的对比实验结果可看出,MRS-Net在SSIM指标上相比于其它几个算法能提高2%~5%左右,在PSNR指标上能提高1~3左右。由于人脸图像的结构大体轮廓有一定的相似性,而Oxford Buil-dings数据集图片复杂度较高,相似性较低,所以对于建筑物图像修复的任务具有一定的挑战性,图5的第五行到第八行对在Oxford Buildings数据集上的修复结果进行了可视化,对于建筑物图片的修复任务,其它几个算法的修复结果不是很理想,而由于MRS-Net的方法可以较好推断出建筑物图像缺失信息并且提高修复图像的清晰程度,因此可以达到较好的修复效果。同时,从表1的结果中可以看出,MRS-Net在SSIM指标上比其它3个模型能提高2%~7%左右,在PSNR指标上能提高1~4左右。

表1 评价指标不同算法对比结果(PSNR/SSIM)
3.4.2 消融实验
为了验证MRS-Net改进的效果,进行了消融实验。在消融实验中算法使用相同的损失函数,从表2中可以看出,在修复缺失图像上MRS-Net的方法在SSIM指标上比其它4个消融模型提高1%~5%左右,在PSNR指标上能提高1~3左右。第一行是基础的编码器解码器网络的修复结果存在修复后图像质量差,相似度低的问题。第二行M是使用多尺度判别器和第三行是使用残差注意力上修复结果的指标均低于MRS-Net的指标,从而可以看出MRS-Net改进的有效性。第四行M3是使用3个判别器和残差注意力的时候,模型的性能反而会降低,推测可能是因为判别器的性能过于强大,从而打破了博弈的平衡性,在博弈中修复模型处于劣势,造成修复模型性能的降低。
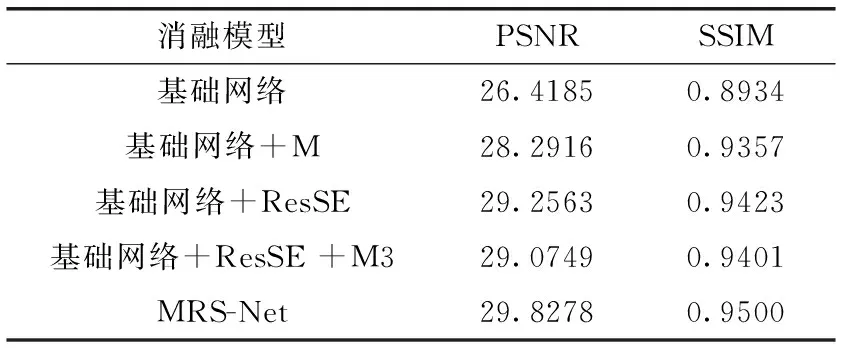
表2 在CelebA数据集评价指标消融结果(PSNR/SSIM)
不同的残差注意力块层数对于修复结果的影响,在深度学习中更深的网络往往可以学习到更好的预期结果,但过深的网络也会导致不良的结果,因此探索阶段选择使用12层、24层、36层不同的层数进行实验验证,图7的结果中表明12层残差注意力块可以较好修复缺失图片,但在眼睛和眉毛部分会存在些许模糊;24层残差注意力块能够较好地推测出缺失部分的语义信息;36层残差注意力块的修复结果会出现大范围的模糊伪影。所以实验中最终选取加入24层残差注意力模块的改进模型作为算法的修复网络。之后探索了在MRS-Net上使用不同损失函数对于修复结果的影响。如图8的结果显示,列1使用了生成对抗损失之后,修复的结果比较模糊,修复的部分会有伪影,达不到预期的修复效果,所以需要加入重构损失来消除修复后模糊现象。列2加入重构损失后可以提高图像的清晰度,但是在眼睛部位存在些许伪影,而在列3加入了全变分损失后,可以较好地消除眼部伪影,但修复后额头部位有不平滑的修复现象,列4中加入了Vgg16提取图像高层特征计算感知损失使得图像结构近似于原图内容,但是与原图内容相比在图像风格方面过于暗淡,在列5中加入了Vgg16提取图像低层特征风格损失后,提高了图像与原图风格的相似度,同时提高修复图像清晰度,达到预期想要的结果。

图7 在CelebA数据集不同残差注意力块数结果

图8 在CelebA数据集不同损失消融结果
3.4.3 模型鲁棒性实验
为了验证模型的鲁棒性,实验对比了不同算法在缺失面积占比为5%~10%、11%~20%、21%~30%、31%~40%、41%~50%时的性能表现,见表3和表4。MRS-Net在不同面积的缺失图像上修补均有最高的峰值信噪比和结构相似性指标数值。此外,随着图像缺失面积的增大,两个指标的下降幅度比较低,在图9的结果中使用不同形状和不同数量的特大面积缺失的图像进行修复,GL算法在图像修复效果都很不理想,对于特大面积缺失的图像不能进行较好的修复;PIC-Net算法对于前三行的图像修复效果相比于GL算法有些许提高,可以合理修复缺失部位,在第四行与第五行的图像修复效果相比于GL算法降低了,几乎没有修复图像的缺失部位;Shift-Net算法可能是由于泛化能力不足导致图像的修复结果不理想;相比于其它算法,MRS-Net有较好的图像修复效果,可以体现MRS-Net具有较好的鲁棒性。

图9 不规则特大面积缺失结果
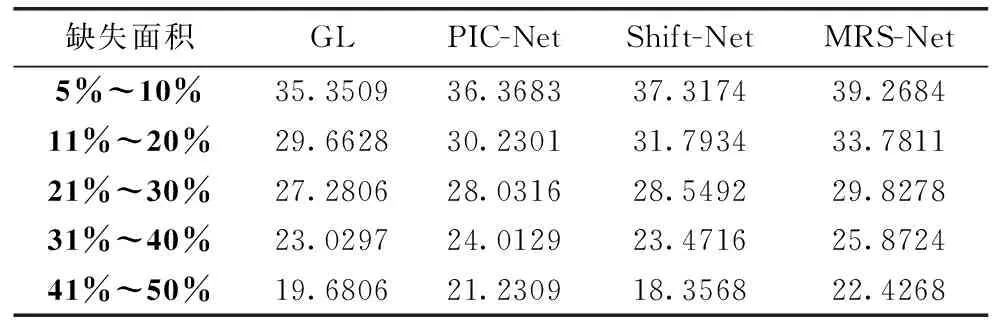
表3 在CelebA数据集不同面积峰值信噪比对比结果(PSNR)
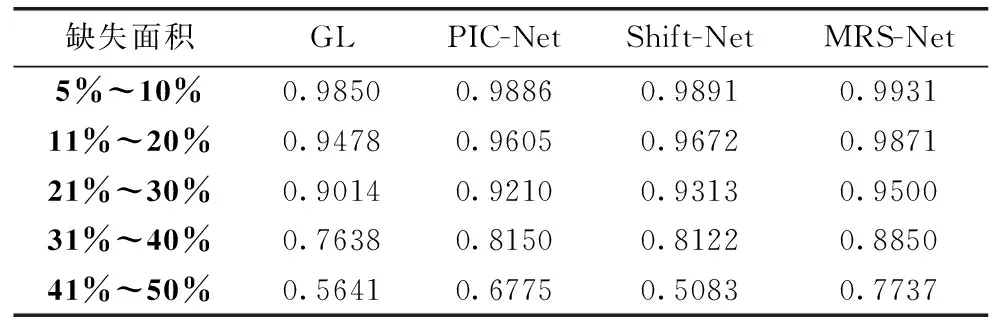
表4 在CelebA数据集不同面积结构相似性对比结果(SSIM)
MRS-Net对于普通的图像修复效果较好,但对于色彩过于复杂或者形状奇特的图像修复效果不可观,如图10所示,后续会寻找相应的解决办法。

图10 复杂形状修复结果
4 结束语
本文提出一种融合多尺度残差注意力的修复缺失图像模型。使用融合的残差序列提取注意力,提高图像中缺损区域特征图子通道之间的相关性,使得提取的图像特征预测图像结构和语义信息是缺损区域的有效信息,多尺度判别器来约束修复的内容。实验结果表明,与先前的算法相比,MRS-Net在修复多种形状缺失块图像和大面积缺失块图像的清晰度与相似性取得了较好的效果,图像修复的结果与真实的图像有较好的一致性。MRS-Net可以应用在人脸去遮挡修复和建筑物的修复。最终会得到修复质量较好的图像。
但是本文所提方法也存在一定不足,对于特大面积缺失和缺失部分图案复杂的图像修复效果会有部分降低,下一阶段将对特大面积的缺失和缺失部分图案复杂的图像修复进行研究,提高模型对于特大面积缺失图像的修复能力。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
江西教育·职教版(2022年9期)2022-04-29 00:44:03
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
今日农业(2019年15期)2019-01-03 12:11:33
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
