并行路径与强注意力机制遥感图像建筑物分割
2023-02-14 12:22杨坚华张浩花海洋
光学精密工程 2023年2期
杨坚华,张浩,花海洋
(1.中国科学院光电信息处理重点实验室,辽宁 沈阳 110016;2.中国科学院 沈阳自动化研究所,辽宁 沈阳 110016;3.中国科学院机器人与智能制造创新研究院,辽宁 沈阳 110169;4.中国科学院大学,北京 100049)
1 引言
随着遥感卫星技术的不断发展,遥感数据随之受到了越来越多的关注,在许多领域都得到了广泛应用。例如在军事领域上被应用于地面目标的识别、在国土资源领域上被应用于环境变化等方面。其中城市区域是遥感数据中应用较为广泛的部分,建筑物作为城市区域的主要元素,对遥感影像中建筑的分割,有助于人口居住变化分析、目标建筑检测及城市规划等。由于建筑物与非建筑物之间的差异较小,且建筑物之间存在尺度大小变化较大、建筑物阴影与建筑物边缘难以区分、建筑物遮挡、建筑之间密集度较大等问题,因此如何提高建筑物的分割精度是一个重要难点。
当前提取遥感影像中建筑的方法可以大致分为两类:传统的图像处理方法和基于深度学习的方法。传统的图像处理方法提取遥感影像中建筑,往往是利用遥感图像本身的光谱、几何形状、纹理等[1-3]特征来组合,设计合理的特征值,通过阈值或机器学习的方法对建筑及背景进行分类,提取建筑。文献[4]通过滑动窗口进行计算地物的特征,提取后的特征图通过拟合分类算法进行预测每个窗口内的地物类别信息,进而从分类后的遥感图像中进行对建筑的提取。此方法提取建筑的效率较高,但精度方面仍有较大的改善空间。文献[5]通过对光学图像、地理信息系统及数字地表模型3 个数据源进行结合,以此来区分非建筑物和建筑物,多源数据大大提高了建筑物提取的鲁棒性,但是多源数据相较于单一来源的遥感图像,获取成本较高。
相较于传统提取遥感影像中建筑的方法,深度学习主要通过其网络模型自动去学习建筑与非建筑之间的深层次特征,对其进行分类提取建筑。MFDC-ResNet[6]以ResNet 为基础,通过结合空间金字塔模型及空洞卷积,获取建筑不同尺度的特征并进行融合,其分割效果相较于ResNet表现更好。全局局部一体化D-LinkNet[7]通过改进条件随机场,增加了网络对全局局部细节的感知,避免了传统条件随机场丢失边界信息的情况,并且通过局部的边缘分割先验,增强建筑边缘提取的准确度。CU-Net[8]在FCN 的基础上增加了多重约束来增强多尺度特征表示,增加多重约束后网络在建筑物分割方面比FCN 表现更好。SiU-Net[9]针对多尺度输入设计了两个权重共享的分支,通过此方法可以有效提高分割精度,在大型建筑物分割方面尤为突出,但其计算复杂度将会大大增加。SRI-Net[10]基于ResNet101 进行修改,提出空间残差模块生成多尺度特征并进行融合,网络通过融合高分辨率的特征,保留了较多的局部细节信息,能有效提高网络性能。EU-Net[11]提出了深度空间金字塔结构,这个结构通过提取多尺度特征增加了对多尺度建筑的提取及边缘定位的精度。并且网络中采用了focal loss 损失函数,有效提高了训练的稳定性。HRNetv2[12]采用多路径方式提取不同尺度的建筑特征,通过中间不断融合不同尺度信息,增加单一路径中的多尺度信息,提高了分割的准确性。
上述模型在遥感图像建筑物分割领域表现较好,但其在遥感影像中建筑之间尺度变化较大时,由于其对建筑物多尺度特征提取不充分,往往只对其中尺度居中的建筑物分割较为精确,对像素占比超过训练图像1/5 以上的大型建筑分割不够完整、对像素占比小于训练图像的1/100 的小型建筑边缘分割不够精细。且当建筑物被其他非建筑物遮挡时,无法准确分割出被建筑被遮挡的部分,而建筑物阴影也易被分割为建筑。针对上述问题,提出了一种基于并行多尺度加强注意力机制的语义分割网络提取目标建筑物的轮廓。提出的模型以ResNet 为基础网络,采用多路径同时提取不同范围的建筑物特征,适应不同尺度建筑物的特征提取,以减少建筑物之间尺度变化较大的影响。在多路径提取不同尺度特征后,引入路径之间强关联性注意力机制,对弱特征进行增强,抑制建筑物被遮挡的影响,增强建筑物与建筑物阴影之间的区分度。并在融合后的单尺度特征中加入空间池化金字塔结构,减少提取建筑物内部空洞的产生,提升分割的性能。
2 并行路径与强注意力机制网络PPA-Net
2.1 并行路径网络
当前获取高分辨率特征图的方法主要有两种:(1)编码器-解编码器网络:由网络(例如ResNet)输出的低分辨率特征图上采样获得高分辨率特征图,或从可选的中间层中等分辨率特征图上采样并反卷积获得高分辨率特征图,如Hourglass,SegNet[13],DeconvNet[14],U-Net[15],编码器-解码器(encoder-decoder)等。即通过对下采样后获取的特征图进行上采样来获得高分辨特征图;(2)并行多路径网络:主路径对高分辨率特征直接卷积不进行下采样保持高分辨率,并通过并行路径下采样获取低分辨率特征图,提取多尺度信息,例如HRNetv2。
第一种网络由于对高分辨率特征存在下采样操作,导致后续恢复高分辨率过程中可能出现边缘定位不清晰,而第二种网络在主路径中并未对高分辨率特征图进行下采样,边缘定位相对较好,因此本文基于HRNetv2 网络进行改进,采用并行路径网络得到多尺度信息,以减少下采样过程中细节信息的损失。
2.2 并行路径与强注意力机制网络
基于编码器-解编码器的网络在编码器阶段由于过度下采样操作损失了较多的空间细节信息,尽管解编码器阶段可能通过融合浅层特征图进行空间细节信息恢复,但融合的浅层特征具备的空间细节信息属于低级特征,与高级特征一同进行特征提取效果可能较差,最终导致建筑物边缘细节定位不够精确。考虑到建筑物分割对边缘定位要求较高,相较于编码器-解编码器类型的网络,多路径网络在保留较多空间细节信息的同时,能够提取多尺度信息,较为适合遥感影像中建筑物分割领域。
本文所提的并行路径与强注意力机制网络首先通过两个阶段逐步生成三个并行路径,以ResNet 残差思想为基础组成卷积块提取网络特征,每个路径中的特征空间分辨率皆为定值,当路径分为三个后,在对各个路径卷积的同时,也进行互相融合,聚合各个路径中不同尺度的信息。然后引入强注意力机制,从多条路径中自适应的学习各个路径特征的重要程度,以提高多尺度特征融合的效果。随后进行金字塔空间池化操作[16],增强特征的全局信息,减少建筑物内部孔洞的产生。
本文提出的PPA-Net(Parallel Path Attention Net)主要包括以下两部分:
(1)并行多路径网络,用于提取多尺度高级语义特征,同时保留空间细节信息,且在提取高级语义特征的同时路径之间互相融合,加强各个路径包含的信息,有助于分割尺度变化较大的遥感影像建筑物;
(2)在并行网络提取末端,加入路径之间强相关的多尺度注意力机制,使网络更加注重于建筑物的特征及尺度信息,有助于建筑物尺度识别及抑制建筑物遮挡、阴影等影响。在注意力机制后加入金字塔空间池化结构,抑制干扰特征,减少建筑物分割结果内部出现孔洞的现象。网络结构如图1 所示。

图1 PPA-Net 网络结构图Fig.1 PPA-Net network structure
2.3 多路径及特征融合机制
多路径特征提取网络相较于基于编码器-解编码器的网络,由于路径的增多网络的参数量相较于同样深度的编码器-解编码器网络,会产生明显提升。因此所提模型仍采取了一定的最大值池化下采样,以减少网络的复杂度。由于模型只对原输入图像进行了1/4 下采样,损失的定位信息较少,因此相较于编码器-解编码器网络对边缘定位精度影响较低。在多路径提取特征的同时,卷积只提取了单个尺度的信息,缺失了其他尺度的信息,因此在提取过程中加强各个路径之间的融合,能够有效增加对各个尺度信息的提取。所提模型的并行路径为3 个,提取尺度分为1,1/2,1/4,经过并行路径之间的相互融合,提取的尺度更加细分,对建筑的识别效果也更好。其中多路径融合过程如图2 所示。
2.4 强尺度注意力机制及金字塔空间池化
从不同路径提取的特征图具有不同的空间分辨率,通过注意力机制对不同路径特征聚合需要对低空间分辨率的特征图进行上采样恢复空间分辨率。如图3 所示,低分辨率特征通过线性插值将特征上采样至原始图像的1/4,再通过3×3 卷积将特征转化为64 通道,并建立相邻路径之间的注意力机制,对相邻路径特征进行逐层融合。

图2 多路径融合机制Fig.2 Multi-path fusion mechanism

图3 强注意力机制Fig.3 Strong attention mechanism
从图3 可以看出,注意力机制首先通过卷积学习得到最小尺度的空间注意力权重,再根据这个权重,对其进行处理,得到一个相关的权重,将其注入到相邻的并行路径中去,形成相邻并行尺度之间空间注意力的强相关。最终实现对目标建筑的尺度自适应识别分割,且能有效增强网络对阴影及建筑相似物的识别能力,减少建筑物遮挡的影响。本文所提强注意力机制基于传统空间注意力机制改进,相较于传统多路径空间注意力机制,强注意力机制结合并行路径中多尺度特征互补特性,路径之间所学注意力权重图相加和为1,以本文三个并行路径为例具体描述为:最小分辨率路径所学注意力权重图为A,中间路径所学注意力权重图为B,则最终中间路径权重图为(1-A)×B,最高分辨率路径注意力权重图可由另外并行路径权重图得到为(1-A)×(1-B)。并行路径之间注意力权重图相加和为1,可以更好地控制空间注意力的学习趋势。因为图像中每个像素的尺度是固定的,多尺度信息必然有所侧重而不存在每个尺度信息重要程度一样,而本文所提强注意力机制中某一尺度注意力权重越大,其相邻尺度注意力权重必然会越小,可以更好区分多尺度信息的重要程度,进而提高像素尺度信息识别。
其中Conv 结构与atten 结构相似,区别在于最后atten 结构输出结果为单通道,Conv 结果输出为多通道,这样可以尽可能使得两个结构提取出的特征属于同一水平深度特征,权重图可以更好地表示对应位置特征的重要性。其结构如图4所示。
为了获得完整性更好的建筑物分割结果,在网络末端加入金字塔空间池化模块,以增强特征的全局相关性。其中金字塔空间池化模块主要由4 个具有不同大小的最大值池化层组成,这些最大值池化层根据建筑物尺寸进行设计,以提取建筑物的全局特征。通过池化层得到的特征图与原始特征图进行级联以实现全局空间增强。在网络末端增加金字塔空间池化模块可以避免全局信息在网络提取过程中被抑制,能更好地提高建筑物的分割完整性,减少建筑物内部孔洞的产生。金字塔空间池化结构如图5 所示。

图4 Conv 结构示意图Fig.4 Schematic diagram of Conv structure
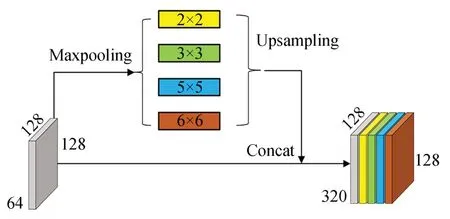
图5 金字塔空间池化模块Fig.5 Pyramid space pooling module
3 实验设置与结果
3.1 实验数据及实验平台
本文研究是基于TensorFlow 框架,在具有12 GB 显存的单个2080Ti GPU 上进行的。网络训练采用Adam 优化器,设置初始学习率为0.001,并 将beta1 和beta2 设置为默认 值,batch_size 设置为4,迭代次数为80 次。通过对数据集进行随机旋转及翻转操作进行数据集扩充。对比模型为 ResUNet-a[15],PSPNet[17],ResNet101[18],HRNetv2 和SCAttNet[19]。
因为涉及到像素级二分类,所以采用sigmiod 交叉熵函数作为损失函数,计算方式如公式(1)所示:
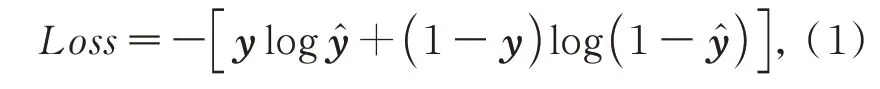
其中:代表当前像素的真实值,y代表当前像素的预测值,Loss为损失量。
实验数据集选 择WHU 建筑数据集[9]及Massachusetts Buildings 数据集[20],两个数据集都为已标注数据集。其中WHU 数据集样本来自新西兰土地信息服务网站,数据集有约22 000个独立建筑,图像分辨率为0.3 m。图像为RGB遥感影像,每个图像尺寸为512×512 pix。数据集共有8 188 个图像,其中训练数据集为4 736个图像,验证集为1 036 个图像,测试集为2 416个图像。
Massachusetts Buildings 数据集由波士顿地区的151 个遥感图像组成,每张遥感图像的像素为1 500×1 500,覆盖面积为2.25 km2。其中训练集包括137 个图像,测试集包括10 个图像,验证集为4 个图像。相较于WHU 数据集,Massachusetts Buildings 数据集阴影干扰及建筑物密集程度较高,Massachusetts Buildings 中每个512×512 输入图像中建筑物个数普遍存在200 个左右,WHU 数据集中则大多只存在40 个左右,且Massachusetts Buildings 数据集中多数建筑存在阴影干扰,且阴影面积占建筑面积接近1/3 影响较大,WHU 数据集中阴影干扰较少,难以判断网络在阴影干扰条件下的分割效果。因此采用Massachusetts Buildings 数据集可以验证本文算法在不同场景下的性能。WHU 数据集与Massachusetts Buildings 数据集部分区域对比如图6所示。

图6 WHU 数据集与Massachusetts Buildings数据集对比Fig.6 Comparison of WHU dataset and Massachusetts Buildings dataset
3.2 分割性能评价指标
本文采用精确率(precision),召回率(recall),F1-score 和平均交并比(MIoU)像素级度量指标来评估PPA-Net 和其他不同方法的性能,具体公式如下:

其中:TP指对正样本的正确预测,FN指对正样本的错误预测,TN指对负样本的正确预测,FP指对负样本的错误预测。precision表示预测为正样本的数据中预测正确的样本数量比例,recall表示总正样本中预测正确的样本数量比例,F1-score是precision和recall的调和平均值,可以更好的反映模型的分割性能,IoU表示预测为正样本的数据及标签中正样本数据的交集除以两个数据集的并集,MIoU为总数据集的平均IoU。
3.3 模型对比试验结果分析
在WHU 数据集上,本文模型与其他对比模型的分割结果对比如图7 所示。
从图7 可以看出,第一个场景中,在建筑物被附近植被部分遮挡的情况下,本文算法相较于其他算法,对被遮挡部分的建筑物分割效果较好,能够有效抑制建筑物遮挡的影响。第二个场景中,本文算法相较于其他算法,在小型建筑之间的间隙识别中具有更好的性能,其他算法则将相邻建筑之间的背景识别为了建筑。第三个场景中,本文算法精确识别出了边缘的小型建筑,而其他算法则识别不全或识别不出。第四个场景中,本文算法对大型建筑边缘分割较为精确,且大型建筑内部不存在孔洞。从图7 整体的结果可以看出,HRNetv2 由于在并行多路径提取特征后只是简单的将多尺度特征级联到一起,没有很好地结合多尺度特征,导致分割结果并不好。ResUNet-a 模型以U-Net 为基础架构,基于残差连接的思想提出Resunet-a 模块增加网络深度及多尺度信息,但其仍将编码器对应阶段的特征复制融合到解码器中相应阶段中,引入了浅层特征中的大量噪声,最终导致分割效果较差。ResNet模型网络层数较深,能够提取到深层的语义特征,但由于下采样操作导致信息的缺失,最终导致分割边缘精度的下降。PSPNet 模型基于ResNet50,引入金字塔结构,但只是简单地提取了多尺度的信息,对多尺度信息融合较为简单,导致分割结果并不好。SCAttNet 模型以Seg-Net 为基础网络,在网络上采样恢复分辨率前加入空间注意力及通道注意力模块以提高分割精度,但其模型仍存在下采样过程中损失过多细节信息的问题。相较于这些算法,PPA-Net 在提取多尺度特征之后,采用强相关多尺度注意力机制,很好地融合了多尺度信息,在这之后采用金字塔空间池化结构,增强网络分割建筑边缘的精确度和孔洞的减少,在建筑物被遮挡及建筑物之间尺度变化较大的情况下,分割效果较好。

图7 在WHU 数据集分割结果对比Fig.7 Comparison of segmentation results in WHU datasets
表1 给出了各个模型对WHU 数据集分割的指标对比,其中参数量及计算量以百万为单位(Million,M)。

表1 在WHU 数据集分割指标对比Tab.1 Comparison of segmentation indicators in WHU dataset
从表1 中不同算法再WHU 数据集上所,分割后的结果的定量分析可以看出,本文所提模型PPA-Net 在MIoU,Recall 及F1-score 表现皆为最优,而在指标Precision 上并不是最优,表明本文所提模型在整体分割性能上是要优于其他算法,但在预测结果为建筑部分的准确率仍有待提高,仍需降低其误分类概率。从参数量及计算量可以看出,由于本文所提模型PPA-Net 是基于HRNetv2 进行了改进的,对比HRNetv2 本文所提模型参数量及计算量皆有所下降,且分割性能得到了一定提高。
在Massachusetts Buildings 数据集上,本文模型与其他对比模型的分割结果如图8所示。

图8 在Massachusetts Buildings 数据集分割结果对比Fig.8 Comparison of segmentation results in Massachusetts Buildings dataset
从图8 中,第一个场景的分割结果可以看出,ResUNet-a 对大型建筑分割非常差,缺失了一大部分建筑,ResNet101 和PSPNet 则未识别出两个建筑物之间的间隙,HRNetv2 和SCAttNet 则对叉形建筑存在误分割现象,相对而言本文所提模型PPA-Net 在两个建筑之间间隔较小时,可以准确分割出其间隙,且未对叉形建筑内部非建筑物产生误分割现象。从第二个场景的分割结果可以看出,在方框区域内,PPA-Net 对小型建筑及大型建筑分割效果较好,对其边缘定位较为精确,而HRNetv2 未分割出一部分三角形建筑,其他对比模型则对小型建筑分割效果较差,边缘定位不够准确。从第三个场景的分割结果可以看出,方框区域内的建筑物属于圈型建筑,其内部存在阴影的干扰,对比的模型对建筑内部分割较差,存在严重的误分割现象,而本文所提PPANet 在阴影干扰下对建筑内部分割较好。从数据集Massachusetts Buildings 的分割结果来看,本文算法对阴影抗干扰性较强,且能在密集型建筑物中准确分割出其边缘。
表2 给出了各个模型对Massachusetts Buildings 数据集分割指标的对比。
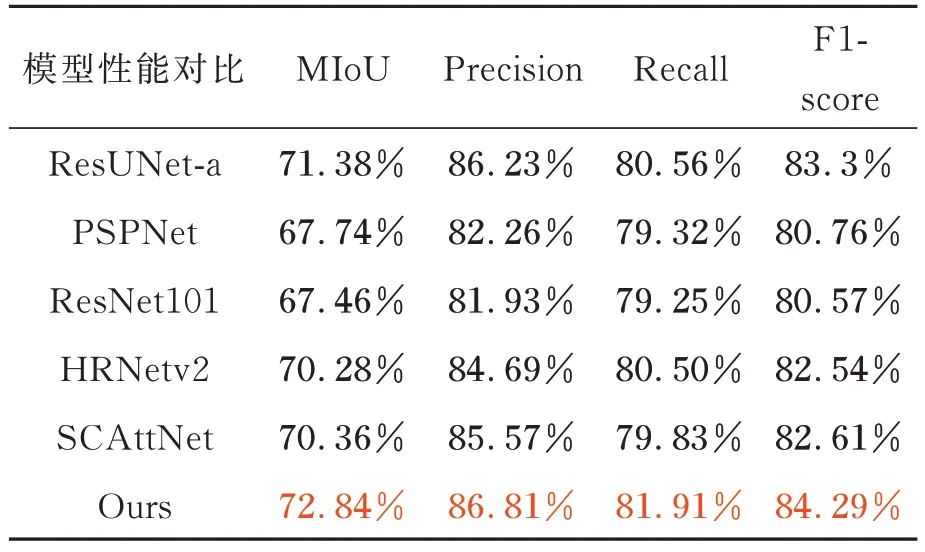
表2 在Massachusetts Buildings 数据集分割指标对比Tab.2 Comparison of segmentation indicators in Massachusetts Buildings dataset
从表2 指标对比可以看出,本文模型相较于对比模型在各个指标上都有较大提升,MIoU 指标相较于ResUNet-a 提升1.46%,分割性能更佳,通过两个数据集的指标提升对比,可以发现PPA-Net 在建筑物密集且阴影干扰较多的数据集上表现更好。
3.4 与其他现有模型对比
本部分将所提模型与目前一些较新的建筑物分割模型进行对比,由于相关论文代码并未开源,因此在WHU 数据集上的性能指标直接采用相应文章的结果,对比如表3 所示。SRI-Net[10]采用修改后的ResNet-101 编码器生成多级特征,以空洞卷积拓宽感受野,并提出空间残差初始(SRI)模块以融合多尺度信息。DE-Net[21]以编码解编码为主要架构,在下采样过程中采用最大池化层及跨部卷积级联,并用密集型上采样卷积获得建筑分割结果。DS-Net[22]采用深层次监督子网络对模型的多尺度输出进行监督学习,并采用多尺度注意力模块对多尺度信息进行融合输出分割结果。AGEDNet[23]以修改后的ResNet-50 为基础网络,加入空间注意力及空间金字塔池化模块以提高建筑物分割精度。RBUNet[24]在编码部分加入了自注意力模块以提高模型对显著区域的关注度,在解编码部分采用多个大型卷积进行上采样以加强模型解编码能力。由表3 中数据可以看出,本文所提模型在MIoU,Recall 及F1-score 指标中均优于所比较的建筑物分割模型。
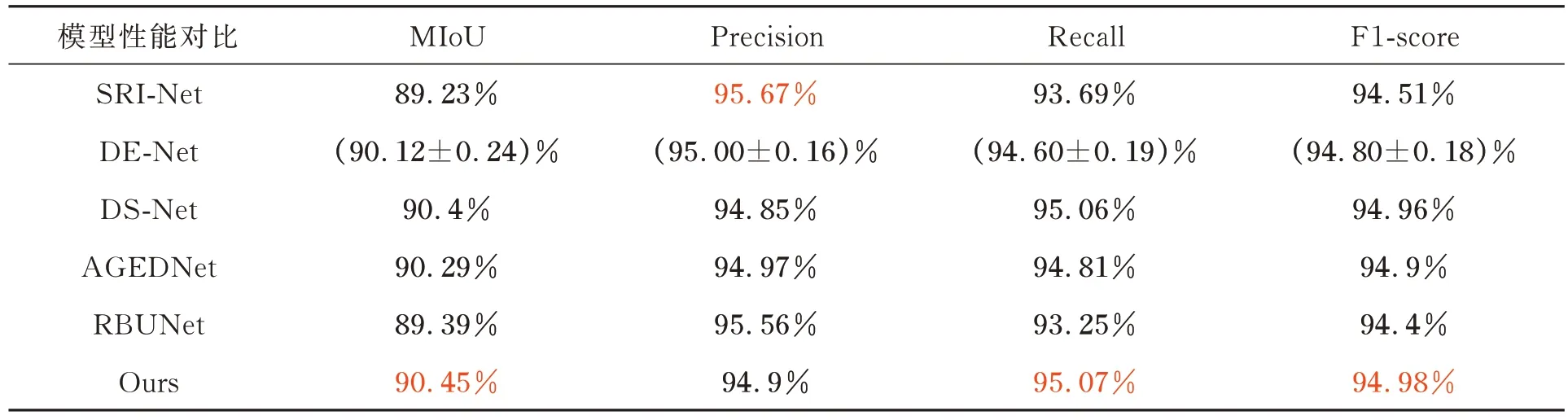
表3 与现有模型在WHU 数据集上对比Tab.3 Comparison with existing models on the WHU dataset
3.5 模型消融实验分析
为了分析强注意力机制和金字塔空间池化模块对分割精度的影响,本文对整体模型在WHU 及Massachusetts Buildings 数据集上进行消融学习实验。首先,本文在没有添加任何模块的基础模型(baseline)上进行实验,然后在基础模型上增加强注意力机制模块(baseline+A)进行实验,最后在基础模型上增加金字塔空间池化模块(baseline+P)进行实验。在WHU 及mass build 数据集上的分割指标对比如表4 所示,部分区域分割结果对比如图9 所示。

表4 消融实验指标对比Tab.4 Comparison of ablation experimental indexes

图9 消融实验分割结果对比Fig.9 Comparison of ablation experiment segmentation results
由表4 的数据对比可以看出,baseline 加入强注意力机制模块及金字塔空间池化模块能够有效提高建筑分割的准确度,其中金字塔空间池化模块的增加对模型的计算量及参数量增加较少,但其分割性能上提升也不多,强注意力机制模块对模型的计算量及参数量增加较多,模型的分割性能上提升也较为明显。总的来说,金字塔空间池化模块及强注意力机制模块能够有效提高模型分割精度,且两个模块存在一定的互补关系,整体网络相较于增加单个模块分割性能更优。
由图9 的分割结果对比可以看出,场景一方框区域内,当建筑被植被遮挡较多时,增加了强注意力机制模块的模型相较于未增加强注意力机制模块的模型能够识别出更多被遮挡的建筑,分割效果更好。在场景二的方框区域内,当模型未增加金字塔空间池化模块时,对大型建筑分割内部存在孔洞现象,增加金字塔空间池化模块后能够有效抑制孔洞现象的产生。在场景三的方框区域内,建筑存在被阴影干扰的现象,增加了强注意力机制模块的模型在建筑与阴影相交边界的分割效果更好,能够有效增加对阴影的抗干扰作用。由消融实验对比结果可以看出,强注意力机制模块能够有效增加模型在建筑遮挡、阴影干扰现象中的分割精度,金字塔空间池化模块能够有效抑制模型对大型建筑分割时内部孔洞的出现。
4 结论
对遥感影像中的建筑物提取,本文提出一个并行多路径网络,在多路径提取特征的过程中对并行路径特征进行融合,加强各个路径之间的多尺度信息;在多路径提取的最后阶段,加入强相关注意力机制,融合各个路径的特征,增强特征之间信息的互补,对特征进行有效加强,提升网络在建筑物被遮挡及建筑物阴影干扰下的分割性能。在最后阶段加入金字塔空间池化结构,减少建筑内部孔洞的产生,并提高建筑分割的精确度。实验证明,本文所提的模型在遥感影像中对建筑分割效果较好,相较于对比的算法,在WHU 数据集及Massachusetts Buildings数据集上IoU 指标,F1-score,Recall 指标都是最好的,但在WHU 数据集上Precision 不是最优的,说明预测中将背景误认为建筑较高,且边缘并不是很精确,是下一步改进的方向,后续也可将此网络改进推广到遥感图像其他元素的分割中。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
铁道建筑技术(2021年4期)2021-07-21
黑龙江水利科技(2020年8期)2021-01-21
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
小学生学习指导(低年级)(2019年9期)2019-09-25
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
太空探索(2016年5期)2016-07-12
小天使·二年级语数英综合(2015年12期)2015-12-04
时代英语·高三(2014年5期)2014-08-26