
SwinBN:一种基于Swin Transformer的针织物疵点检测模型
2023-02-14 01:59:08胡越杰蒋高明
丝绸 2023年1期
胡越杰, 蒋高明
(江南大学 a.纺织科学与工程学院; b.针织技术教育部工程研究中心, 江苏 无锡 214122)
在纺织工业中,疵点的检测与分类至关重要,可以为纺织生产的质量控制提供指导性建议。纺织企业常用的检测方法是人工检测,即检测人员按个人经验或评分标准对织物做出等级评定[1]。这种检测方式存在众所周知的局限性,如检测人员注意力易分散、易疲劳及易受主观因素影响,据调查其准确率仅为60%~70%[2]。因此,自动化的机器视觉检测方法已成为当前研究的热点,但是关于针织物疵点的检测与分类比其他类织物更少涉及,这主要是由于针织物本身良好的弹性,及其较为松散的线圈结构,容易导致下机后织物无法在尺寸上保持稳定,因而使得疵点信息相对模糊。
传统的织物疵点检测方法可以总结为统计法[3]、模型法[4]和频谱法[5-6]。这些方法主要依赖人工设计的特征提取器对织物特征进行提取,需要具备专业的知识并且调参过程复杂,因此存在一定的局限性。近年来随着人工智能技术的发展,深度学习因其能够自适应、智能地学习关键信息,被广泛应用于织物疵点的检测与分类任务中。Xie等[7]基于全卷积通道注意力和自底向上路径增强设计了一种改进的头部结构(Head),有效地提高了缺陷定位精度。Wen等[8]使用PE算法(Patches extractor)提取缺陷图像的片段,再通过卷积神经网络(CNN)来预测片段的类别和图像的最终类别。在文献[9]中同样遵循二阶段思想,以Inception-V1模型预估局部区域疵点是否存在,最终使用LeNet-5模型识别织物中的缺陷类型。Biradar等[10]设计三层结构的CNN,在TILDA数据库上的分类精度高达99.06%,但是该模型无法提供疵点的位置信息。此外,YOLO系列的目标检测模型具备端到端(End-to-end)的特性,并且兼顾了检测精度,因此不乏其应用于织物疵点检测的场景。例如参照YOLOv5提出的师生结构(Teacher-student)[11],以及根据YOLOv4设计的实时检测系统[12]。Liu等[13]提出了一种基于生成对抗网络(GAN)的织物缺陷检测框架,不仅实现了像素级别的分割还能够自动适应不同的织物纹理。与之类似,文献[14]中设计的DLSE网络,引入了注意力机制以提高对陌生样本的适应性。值得一提的是,上述两种模型似乎更适合显示疵点的形状,然而这种分割过程将消耗大量的计算资源,如何设计合理的结构以满足工业检测的实时性需求是该领域面临的巨大挑战。另外,Wang等[15]搭建的监督神经网络模型只需要少量的无缺陷样本进行训练,在一定程度上缓解了数据集不足的问题。
以上织物缺陷检测和分类的深度学习框架都是基于CNN模型。CNN提取局部有效信息效果显著,但缺乏整合全局信息的能力。Transformer可以弥补这一缺陷[16],其独特的自注意机制专注于建立远程元素之间的联系,使每个像素包含全局特征。Alexey等[17]提出ViT网络模型,将Transformer从自然语言处理应用到图像识别任务。ViT直接分割输入图像成16×16的片段(Patch)并输入Transformer,该模型只能处理分类任务。Zheng等[18]提出一种名为SETR的网络,该网络将Transformer的输出从向量重塑为特征图,随后上采样、反卷积解码得到分割结果。虽然基于Transformer的算法极大地提高了目标检测的效果,但在计算机视觉领域仍然存在严重问题:1) 向量运算需要涉及所有像素,对大尺寸图像操作会非常耗时并且占据计算资源。2) 忽略了文本信号和视觉信号的差异,没有与视觉信号本身的特点结合。
针对上述问题Swin Transformer(ST)模型被提出[19],ST采用层级结构设计,在各个窗口区域执行注意力计算。ST开创性地引入卷积操作的局部性和层次性,同时大幅降低计算复杂度,使其与输入图像的尺寸呈线性关系。作为一个通用的视觉网络,ST在图像分类、目标检测[20]和语义分割[21-22]等任务中表现出SOTA(State-of-the-art)的性能。然而处理针织物疵点检测任务时,ST对上下文信息编码的能力有限,需要进一步改善。此外,现有的目标检测网络大多通过深度监督处理不同层次的特征图,或者只使用最终的抽象特征,导致无法充分整合多尺度特征信息,影响检测精度。
因此,本文提出了一种多尺度自适应网络模型SwinBN(Swin transformer and bidirectional feature pyramid network),该模型以改进的BiFPN网络为颈部结构,有效地区分各个特征层对于输出的重要性,实现不同尺度之间的加权特征融合。考虑到CNN提取全局信息能力弱及针织物疵点的形状特点,模型的骨干网络DCSW(Deformable convolution and swin transformer)将可变形卷积和ST各自的优势相结合,有助于提取局部特征和整合全局信息。由于现有的图像数据不足,本实验在纺织工厂现场采集图像,人工标注并创建了针织物疵点图像数据库。真实工业数据集的实验结果表明,SwinBN在针织物疵点检测任务上优于现有先进的目标检测模型,验证了该方法的准确性与可行性。
1 数据集和SwinBN模型
1.1 针织物疵点图像数据集
关于针织面料疵点检测的研究很少,本实验图像采集于江南大学针织技术工程研究中心和无锡新祥瑞纺织品有限公司,如图1所示。采集图像时使用一台2 600万像素的高分辨率相机(分辨率固定为300 dpi),镜头距坯布垂直距离200 mm,竖直向下聚焦拍摄,侧面补光角度为30°以达到图像没有暗影和坯布反光的效果,采集的图像大小为900×600 pixel。本文主要针对实际生产中出现的四种最常见的疵点类型,包括破洞、漏针、油针、横档(图2),具体描述如下:
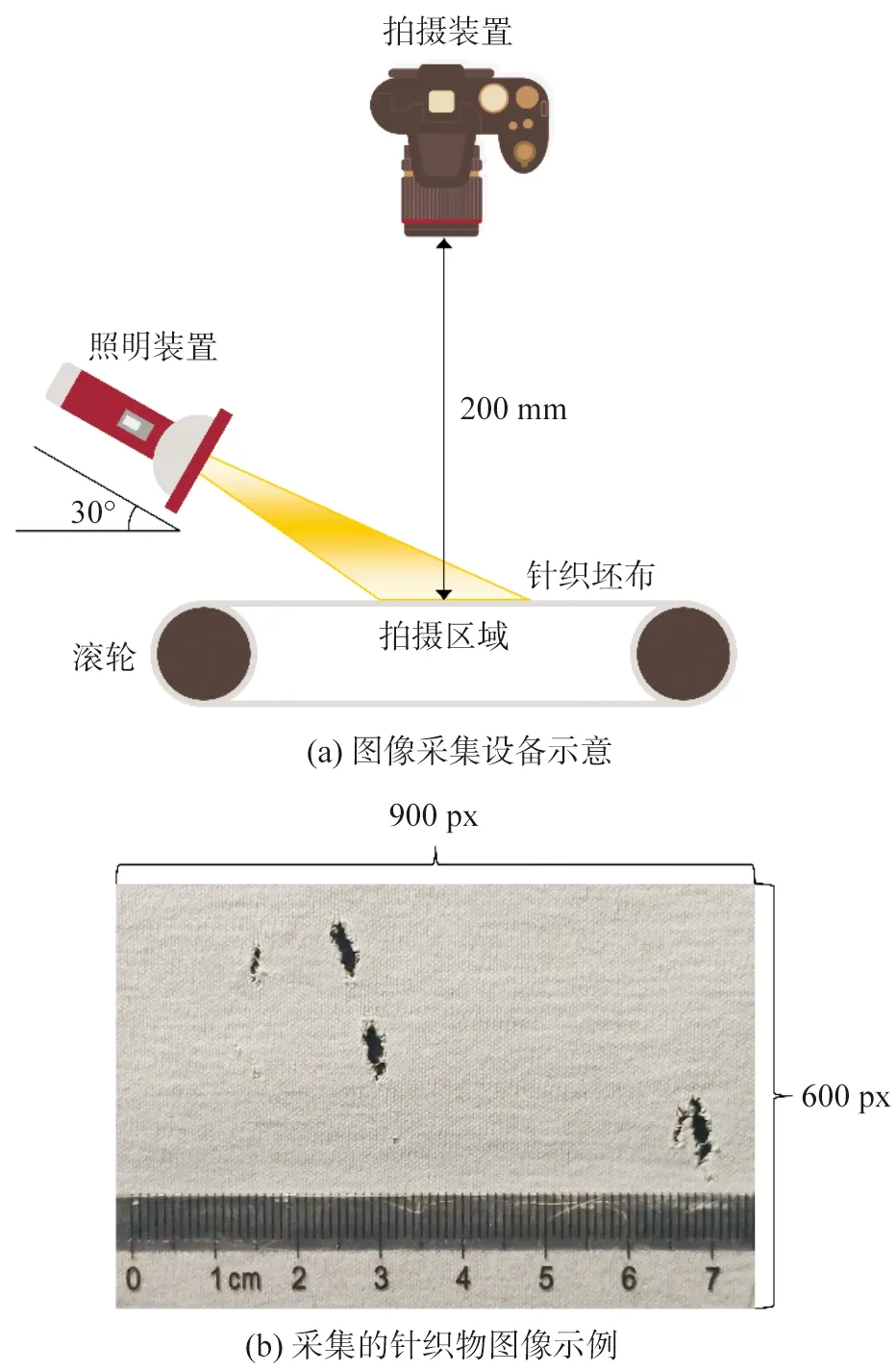
图1 针织物图像采集Fig.1 Acquisition of knitted fabric images
1) 破洞:纱线在编织过程中受到了超过其自身断裂强度的力,导致纱线被拉断,形成布面上的洞孔。
2) 漏针:纬编针织物在织造时,织针没有勾到毛纱或勾到毛纱后又脱出针钩而造成线圈脱散,在布面出现垂直的条痕及小孔的现象。
3) 油针:由于机台供油过多或者漏油,跟随织针的运转污染坯布,在布面上呈现为一条黑线直落。
4) 横档:一种视觉上非主观性设计的,重复且连续状的条形图案,通常平行于针织物的线圈横列,又称为横条或横路。
实验中,为了避免因计算原因影响图像特性,采集的图像从原始大小裁剪并缩放至320×320 pixel。经过人工标注后建立的数据集包含3 524张针织物图像,其中负样本935张,破洞、漏针、油针、横档疵点分别为890、784、439、476张。训练集、验证集和测试集的比例设置为8︰1︰1,此外,采用水平翻转、垂直翻转和旋转(90°、180°和270°)等数据增强方式扩充样本数量。

图2 针织物疵点图像Fig.2 Images of knitted fabric defects
1.2 DCSW骨干网络结构
针织是一种将纱线顺序地弯曲成圈并相互穿套而形成织物的工艺。由于其线圈是纱线在空间弯曲而成,并且每个线圈均由一根纱线构成,因此当织针损坏,沉降片位置不对或者纱线本身出现问题时,产生的瑕疵具有连续性,如图3所示。以图像的视角看,疵点的长宽比例非常高,为细长状,并且疵点区域相对总图像面积占比较小。
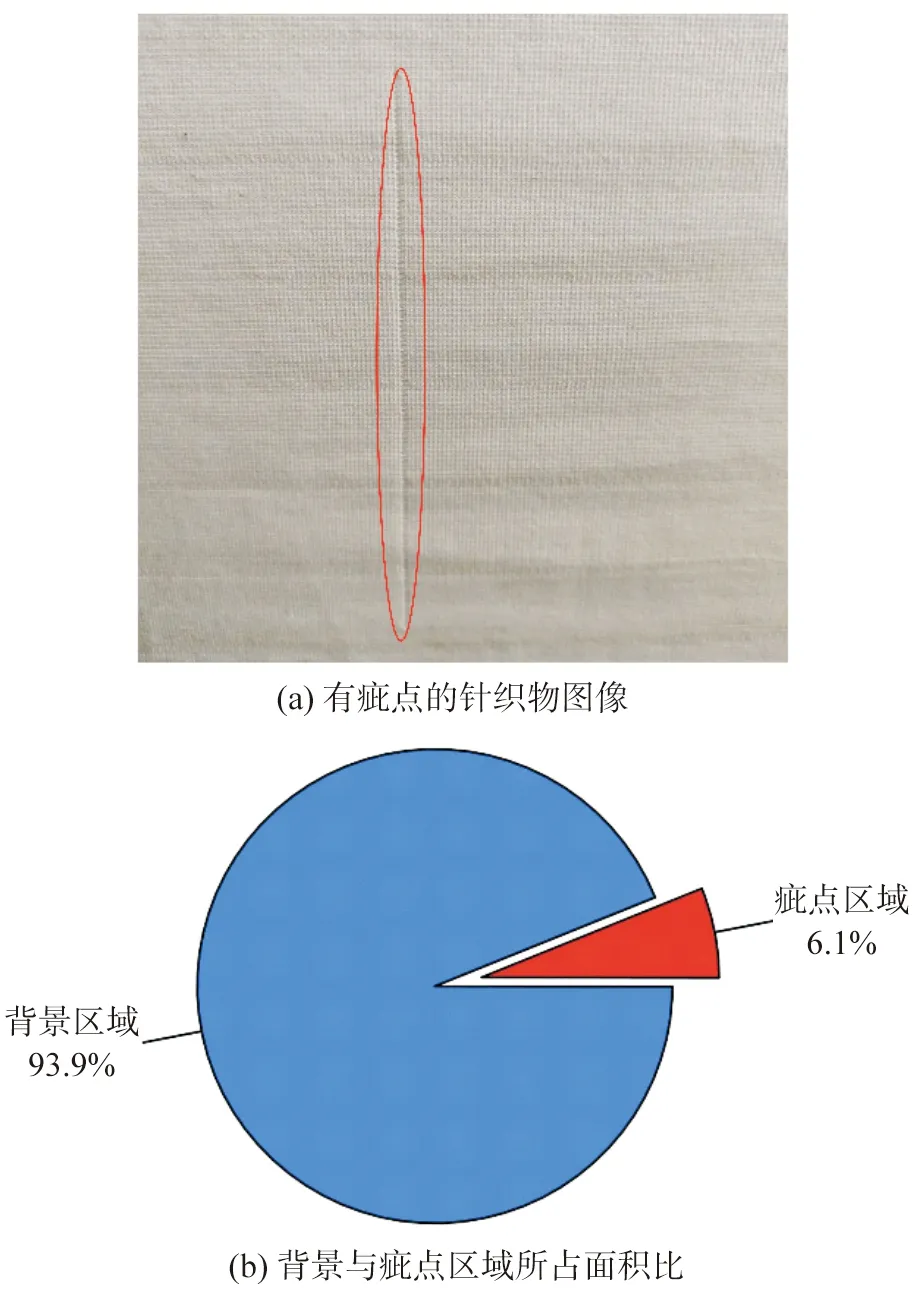
图3 针织物疵点的形状特征Fig.3 Shaped characteristics of knitted fabric defects
考虑到上述织物疵点本身的形状特征,本文致力于将CNN和Transformer的先验优势有效结合,改进Swin Transformer骨干网络。本文在每个检测层中加入可变形卷积模块,加强网络对于细长疵点的局部感知能力,以便更好地融合高语义的特征信息。DCSW网络由Patch Merging层、可变形卷积模块和ST模块等部分组成,其整体结构如图4所示。

图4 DCSW主干网络总体结构Fig.4 Overall structure of DCSW backbone network
1.2.1 Swin Transformer模块
从图4(b)可以看出,与Transformer模块[16]相比,ST将标准多头自注意单元(MSA)替换成窗口多头自注意单元(W-MSA)和移动窗口多头自注意单元(SW-MSA),并分别应用于两个连续的ST模块。此外,在每个(S)W-MSA和多层感知机MLP前安插归一化层使得模型训练稳定,并添加残差连接。该部分可以用下式表示:
(1)
(2)
(3)
zl+1=MLP(LN(zl+1))+zl+1
(4)

如图5(b)所示,ST模块中的W-MSA首先将特征图按M×M的比例划分为一系列不重叠的窗口,而且在每个窗口中执行注意力计算。该方式减少了网络计算量,并控制模型复杂度与图像尺寸线性相关。然而窗口分割的实现会导致不同区域之间缺乏跨窗口的信息交流,因此,SW-MSA通过将规则分区的窗口沿垂直和水平方向平移(M/2,M/2)像素的距离,并循环移位(Cycle shifted)获得一种新的窗口布局,如图5(d)所示。在此基础上,像素的全局相关性得以保证。

图5 移动窗口的作用机制Fig.5 Action mechanism of shifted windows
1.2.2 可变形卷积模块
尽管ST以W-MSA和SW-MSA两种滑动窗口方案为主体构建了层次结构,但基于位置编码的模式容易忽略图像的局部相关性和结构信息,以致无法高效地编码空间上下文信息。为了缓解这个问题,本文设计了可变形卷积模块改进主干网络,它被嵌入在ST模块的前面,其组成如图4(a)所示。
由于ST模块中不同层次以向量组成的数据流传递信息,而不是传统卷积中的特征映射,因此在输入可变形卷积模块之前需要将其重塑为特征图的形式。例如数据流维度大小为(B,H×W,C),首先将其重塑为(B,C,H,W)的特征图。随后,一个1×1的卷积层使其维度从C减小到C/4。再添加一层3×3的可变形卷积增强对局部特征的提取,并保持维度在C/4。然后设置一个1×1卷积层恢复维度,并使用残差连接防止网络退化,同时提升网络的表征能力。为了加速神经网络的收敛及提高模型训练的稳定性,每一个卷积层后面添加一个BatchNorm2D层和一个Relu激活函数。最终,将特征图重塑为(B,H×W,C)的数据流,作为ST模块的输入。
图6展示了3×3可变形卷积的特征提取过程,其直观效果是卷积核采样点的位置会根据图像内容自适应调整,从而应对不同物体的形状、大小等几何形变[23]。相比Pascal VOC[24]和COCO[25]这些大型数据集的检测目标(人脸、行人和车辆等),织物疵点的形状特征更复杂多变。例如对于一张漏针图像,其检测对象的长宽比可达30倍,而疵点区域面积仅占整幅图像的1/19。因此,可变形卷积这种对图像特征更细粒度的定位、提取方式与本文研究的需求匹配。

图6 3×3可变形卷积的特征提取过程Fig.6 Feature extraction process of the 3×3 deformable convolution
1.3 改进的特征融合网络
在深度网络中,深层的特征图通常包含更丰富的全局语义信息,而浅层的特征图包含更多的局部纹理和结构信息。如何有效地表征和处理多尺度特征是目标检测任务的主要难点之一,常见的做法是在主干网络和预测层之间添加颈部结构(Neck)以整合信息流[26-27]。如图7(a)所示,特征金字塔网络(FPN)首次提出一种自顶向下的结构来组合多尺度特征[28]。而NAS-FPN将其与神经搜索相结合[29],自动设计特征网络拓扑结构。但是该方法对算力的要求极高,并且从图7(b)可以看出,其生成的特征网络不规律,缺乏可解释性。本文旨在以更直观的方式平衡不同尺度的特征信息,受文献[30]的启发设计了一种改进的颈部结构I-BiFPN,如图7(d)所示。

图7 4种不同的颈部结构设计Fig.7 Four different designs of the neck structure
已有研究表明,具有不同分辨率的各层次特征,对于输出结果的作用各不相同[31-32]。因此改进的网络在各节点设置输入权重,以加权融合的方式衡量不同特征层的重要性。具体而言,引入可学习参数wi=1(i表示各节点的输入特征个数),将其作为不同输入特征的权重与模型一起优化。此外,网络在原始输入节点与输出节点之间采用跨层连接的方式,以便在不消耗过多计算资源的情况下有效地聚合多尺度特征。假设输入图像尺寸320×320 pixel,网络输入特征F2至F5的分辨率分别为80×80、40×40、20×20、10×10。本文以图7(d)中F4所在层为例,其特征融合过程可以用下式表示:
(5)
(6)
式中:F4td表示自顶向下路径中的特征,F4out表示该层的输出特征;Resize是上采样或者下采样操作以保证特征维度的匹配;ε=0.000 1,用于防止数值不稳定。
所有其他特征都以类似的方式构造。另外,在每个深度可分离卷积后添加批量归一化层和Relu激活函数。值得注意的是,为了实现更高级别的特征融合,每个双向路径被视作一个特征网络层,并在颈部结构重复m次(m在下文3.2节中加以讨论)。
1.4 SwinBN
SwinBN网络模型的整体结构如图8所示。给定一张大小为H×W×3的输入图像,其中空间分辨率为H×W。首先将图片输入Patch Partition模块进行分块,即每4×4相邻的像素为一组在通道方向展平,特征图的尺寸由[H,W,3]重塑为[H/4,W/4,48]。随后输入至DSBL1(Deformable convolution and swin transformer block 1)。通过Linear Embedding层将其映射到维度C,再设置一个可变形卷积模块加强局部信息的提取并且不改变特征图的大小。DSBL1包含两个连续的Transformer模块,分别应用WMSA和SW-MSA,不仅可以关注全局信息还能实现跨窗口的信息传递。输出DSBL1的特征图尺寸为H/4×W/4×C。与DSBL1相似,DSBL2包含一个可变形卷积模块和两个Transformer模块,区别是将Linear Embedding层替换成Patch Merging层。Patch Merging层类似CNN中的池化层用于下采样以得到多尺度特征信息,其中每2×2的相邻像素划分为一个片段并依次拼接,再通过全连接层调整通道数。由于可变形卷积模块和ST模块不改变特征图的尺寸,因此DSBL2的输出尺寸为H/8×W/8×2C。DSBL3、DSBL4与DSBL2高度相似,区别在于DSBL3中包含6个ST模块,可以看作是DSBL2中的3倍。最终,DSBL1至DSBL4的输出特征为F2、F3、F4、F5,通过颈部结构I-BiFPN实现多尺度特征信息的融合。预测层参照文献[11]和文献[33]的设计方式,对4种不同尺度的特征图进行预测。

图8 SwinBN网络模型Fig.8 SwinBN network model
2 评价指标
在本实验中,主要使用mAP值评估目标检测模型的性能,影响mAP值的相关指标的含义及计算方法如下。
IoU表示真实边界框和预测框的交集与并集的比值,如下式所示:
(7)
TP(True positive)是指正确检测出对象的预测框数量。在本文中,该对象是织物疵点,当预测框与真实边界框的IoU>0.5,并且类别预测正确,即被判定为TP。FP(False positive)表示IoU<0.5,或者分类错误的预测框数量。FN(False negative)表示未被检测到的对象个数。
精确率P(Precision)指预测正确的边界框占所有预测框的比重,具体如下式所示:
(8)
召回率R(Recall)指预测正确的边界框占所有真实边界框的比重,具体如下式所示:
(9)
以召回率为横轴、精确率为纵轴,可以得到P(R)曲线。AP指P(R)曲线与坐标轴所包围区域的面积,mAP值代表多个类别的平均AP值,mAP值越高则表示模型的检测性能越好。因此,mAP可以通过下式计算:
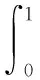
(10)
3 实验与讨论
3.1 实验设置
本实验的操作系统是Windows10,64位,CPU配置Inter I7-10700,GPU配置NVIDIA GeForce RTX 2060(12 G)。软件环境为CUDA 11.1、Python 3.8.8和Pytorch 1.9.0。采用随机梯度下降(SGD)方法对模型进行优化,训练的迭代次数设置为200。此外,本文在自制的针织物疵点数据集上比较Faster RCNN[34]、Efficientdet[30]、YOLOv3[35]、YOLOv5、DETR[36]、SwinBN模型的性能。所有目标检测模型都是基于Pytorch深度学习框架实现的,其初始化参数如表1所示。

表1 网络初始化参数Tab.1 Initialization parameters of networks
3.2 综合实验结果
参考Swin Transformer提供的4个版本(Swin-T、Swin-S、Swin-B和Swin-L),本文设计的DCSW主干网络通过缩放系数λ调整网络大小。此外控制颈部结构深度的参数m需要合理优化,因此使用控制变量法来分析参数对检测效果的影响。实验中不同参数的模型均在同一台设备训练直至收敛,训练次数不固定,结果如表2所示。

表2 不同参数配置下模型检测mAP指标Tab.2 Model detection mAP indexes under different parameter configurations
由表2可以看出,在[1,4]内模型的mAP值随着m值的增大提升明显,这是因为随着特征融合网络I-BiFPN加深,多尺度特征之间的加权融合更加充分。当m≥5,模型的表现略有下降,此时训练模型所需迭代次数过多,导致模型难以训练无法完全收敛。图9展示了在该参数下对于破洞疵点的检测结果,学习不足的模型容易将织物背景误判为疵点对象。

图9 不同参数配置下的检测结果Fig.9 Detection results under different parameter configurations
在另一组对照实验中,SwinBN模型的检测效果并非与骨干网络大小呈现正相关趋势,这可能是由于本实验的整体数据规模较小,SwinBN-b和SwinBN-l过于复杂以致无法良好地拟合其他数据。图10(m=4)和表2共同说明了当λ=s时检测效果最佳,但是推理速度达不到实时监测的要求38 ms/image。综上分析,选取λ=t和m=4的参数配置较为合理,模型的mAP值达到74.53%,并且在准确性和实时性之间取得折中。本文后续与该模型相关的实验中全部使用此参数配置。

图10 模型的性能与骨干网络大小的关系讨论Fig.10 Illustration on the relationship between a model’s performance and the size of the backbone network
表3对比了SwinBN模型与其他五个模型的检测性能。由表3可以明显地看出,在所有模型中二阶段算法Faster RCNN的检测效果最不理想。其精确率、召回率和mAP值分别为54.35%、50.67%和46.75%,皆是最差的实验结果。并且检测一幅图像的耗时最长为0.237 s,因此不适合针织物疵点的检测。

表3 不同目标检测模型的性能比较Tab.3 Performance comparison of different object detection models
此外,基于Transformer的网络模型一定程度上表现出在视觉领域的优越性。具体而言,DETR和SwinBN的平均mAP值达到了70.26%。分析主要原因在于自注意力机制的使用,它能够捕捉全局上下文信息,建立像素之间的远程相关性,从而提取更有价值的特征。因此在计算机视觉领域,基于Transformer的模型与CNN相比,拥有更具竞争力的性能及可观的改进空间。总的来说,SwinBN以同一水平的参数量和计算成本在各指标上取得了最佳的表现。对于综合指标F1-score,SwinBN分别比YOLOv3、Efficientdet、YOLOv5和DETR高19.18%、13.82%、10.39%和2.23%。就目标检测的基准指标mAP而言,本文提出的方法比上述模型高12.24%、11.91%、7.80%和1.63%。在检测速度方面,SwinBN模型的参数量仅为39.72 M,预测一张图片所需时间0.032 s,快于YOLOv5m和DETR,比YOLOv3模型略慢。上述实验结果证明,该方法在检测速度和检测精度之间取得了平衡,能够高效、快速地检测出针织物疵点。
3.3 消融实验
为了验证不同改进技术的必要性和对模型性能的影响,本文进行了消融实验。在模型设计阶段,以ST为主干网络原型,在DSBL1至DSBL4中配置可变形卷积模块以提取更丰富的局部特征(表4)。

表4 可变形卷积模块对检测性能提升效果验证Tab.4 Verification of the improvement effect of deformable convolution modules on the detection performance
表4评估了各可变形卷积模块的重要性,“√”和“×”分别表示其在DSBL中是否被应用。实验结果证明,在添加可变形卷积模块后模型性能有显著提升。相比不使用可变形卷积模块的Modela,SwinBN的mAP值提升了3.33%,并且针对横档、漏针两种细长型疵点的检测效果改善明显(图11),其AP值分别提升了5.02%和3.03%。
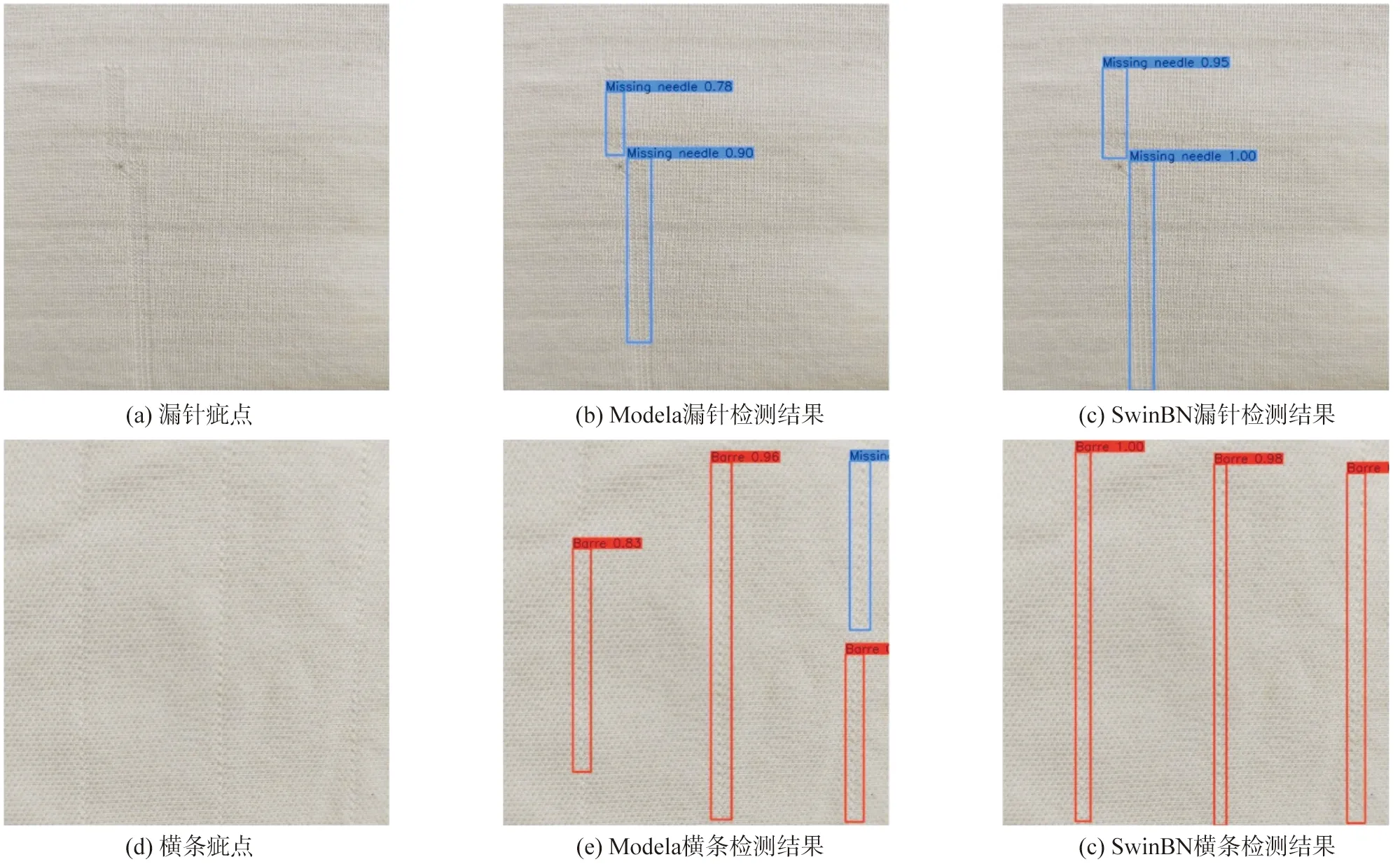
图11 Modela和SwinBN模型的检测效果对比Fig.11 Comparison of the detection effect between Modela and SwinBN models
从图11可以更直观地看出,Modela将部分横档疵点误检为漏针,而且对于瑕疵区域的界定不及SwinBN精准。除此之外,在模型早期添加可变形卷积对检测性能的影响更为关键。例如只在DSBL1添加可变形卷积的Modelb,其mAP值提升了1.78%,而SwinBN相比Modeld的mAP增值只有0.12%。这是由于浅层的输出包含丰富的颜色和纹理特征,更有利于动态卷积核自适应地定位细长疵点。总之,可变形卷积模块非常契合地弥补了Transformer对于局部特征提取能力弱的缺陷。
消融实验还对比了FPN、PAN、BiFPN和I-BiFPN四种颈部结构对模型性能的影响,实验结果如图12所示。由图12可以看出,相比其他3种双向结构,单向网络FPN特征融合效果最差,mAP值仅为68.25%。结合DCSW和PAN的模型通过自底向上金字塔传递底层定位特征,对于漏针疵点的检测效果显著,但无法弹性地控制特征层深度,因此整体性能并不突出。实验结果显示,使用改进的BiFPN自适应整合多尺度特征对各疵点类型的检测效果均有提升,mAP值提升了1.02%,验证了此结构比BiFPN能更大程度地利用融合权重的各尺度特征。

图12 不同颈部结构对检测模型性能的影响Fig.12 Effects of different neck structures on the performance of detection models
4 结 论
本文提出了一种名为SwinBN的深度学习模型应用于针织物疵点检测任务。首先,SwinBN以DCSW为主干特征提取网络,充分结合了CNN和Transformer各自的优势:通过自注意力机制高效地整合全局信息;根据疵点的形状特征,引入了可变形卷积加强提取局部特征的能力。其次,模型以改进的BiFPN网络为颈部结构促进多尺度特征之间的加权融合,有效地提高了缺陷定位精度。综合实验测试阶段,SwinBN与其他现有研究的最新方法在针织物疵点数据集上进行比较,各项指标都取得了最好的表现,例如精确率、F1-score和mAP值等。此外,本文还通过消融实验说明提出模型中关键组件的有效性和合理性。研究结果表明,SwinBN提供了一种精确满足针织行业需求的疵点检测方案,在织物疵点的检测与分类任务中有着可观的应用前景。

《丝绸》官网下载

中国知网下载
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
纺织科技进展(2021年5期)2021-07-22 08:41:34
纺织科技进展(2021年3期)2021-06-09 08:07:20
电子技术与软件工程(2019年22期)2020-01-16 07:39:14
电子制作(2019年11期)2019-07-04 00:34:38
四川蚕业(2018年3期)2018-11-19 09:12:02
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
国际纺织导报(2016年12期)2016-02-24 08:05:41
纺织科技进展(2015年1期)2015-11-28 05:56:29
现代纺织技术(2015年2期)2015-02-28 14:03:11
