
基酒FT-NIR光谱预处理与特征波筛选方法的比较
2023-02-13 07:25:32朱雪梅庹先国张贵宇翟双罗林罗琪
现代食品科技 2023年1期
朱雪梅,庹先国*,张贵宇,2*,翟双,罗林,罗琪
(1.四川轻化工大学自动化与信息工程学院,人工智能四川省重点实验室,四川宜宾 644000)(2.西南科技大学信息工程学院,四川绵阳 621010)
白酒是我国传统产业的代表之一,是我国特有的蒸馏酒[1]。白酒大都以谷物为原料,通过发酵得到高度白酒基酒[2]。基酒经过长期储存、陈化老熟、勾兑降度后包装为成品酒。由于发酵过程中不同的使用酒曲、原料、辅料以及不同的发酵工艺条件,形成了不同香气、口感的白酒[3,4]。白酒基酒作为粮食到成品酒的一个中间产物,对最终的成品酒质量有重大的影响。在生产车间,白酒基酒的分段主要依靠现场工人的经验,他们通过看花摘酒以及品尝口感来快速区分不同等级的基酒[5]。但是,刚馏出的基酒含有大量的二甲酸二甲酯、邻苯二甲酸二异丁酯、邻苯二甲酸二丁酯、邻苯二甲酸二丁酯等有害物质,这些物质对人体伤害较大,不适合长期饮用[6]。实现基酒智能分级技术将是后期白酒酿造自动化一个重要的技术点,将会推动白酒向标准化、无人化、智能化发展[7]。
近年来,随着计算机科学、模拟技术以及分析化学的快速发展,有多种手段可以从近红外光谱里发现丰富的物质信息,近红外谱图的高效解析已经逐渐变得可行,近红外的应用前景越来越广泛[8]。同时,近红外光谱由于其快速便捷、清洁环保、低成本的特点,以及较好的检测效果备受关注[9]。如今,近红外分析技术广泛应用于石化企业[10]、饲料生产[11]、食品[12,13]、制药[14]、制烟[15,16]等各个行业[17]。近红外光(Near Infrared,NIR)是一种波长范围在780 nm~2 526 nm的电磁波[18],近红外光谱区域内,物质内部的含氢官能团发生基频、合频振动,得到的物质吸收谱能较好的反映样本中的含氢基团信息。但这个谱区内存在吸收强度弱,灵敏度相对较低,吸收带宽且重叠严重等问题,这就使得最后获得的光谱与理论上的光谱有误差。此外,由于近红外光谱仪运行过程中湿度、温度等外界环境以及仪器自身噪声的影响使得获得的光谱包含大量的无关干扰信息严重影响了后续建模效果[19]。加之,基酒的微量成分的种类多,含量少,图谱间差异不明显,良好的光谱预处理以及特征波筛选就备受关注。
1 材料和方法
1.1 样本获取
本实验选择某品牌酿酒车间酒糟馏出的白酒基酒为样本。为减少个人主观因素对分段结果的影响,选取了4位有10~20年摘酒经验的师傅来分段摘取基酒,跟踪这4位师傅的摘酒情况,在师傅的指导下获取实验样本并贴好标签。为模拟现场摘酒环境中基酒震荡产生酒花的情况,样品通过注射器注入外接流通池,待酒花稳定后进行光谱获取,表1是具体分类情况。
1.2 样本光谱数据采集
本研究采用德国Bruker公司傅里叶变换近红外光谱仪 Matrix-F以及配套的近红外光纤探头获取样品透射光谱,使用软件OPUS 7.8控制光谱仪。在实验前,先确保光谱仪在温度为(20±2)℃、空气相对湿度<80%RH的条件下预热近红外光谱仪50 min左右。在扫描样品前先检查信号,使得干涉图能量达到最大,获取背景光谱,消除水蒸气以及二氧化碳等对光谱结果的影响。使用的光纤通道长度为5 m、流通池的光程为2 mm、光谱扫描范围为4 000 cm-1~12 500 cm-1,相位分辨率为32 cm-1,以10 kHz的频率、16 cm-1的分辨率累积扫描64次后取每个光谱点上的平均值为最终光谱。
1.3 光谱预处理以及特征波筛选方法
本实验预处理使用The Unscrambler X 10.4为工具,将扩展多元散射校正(Extended Multiplicative Scatter Correction,EMSC)、多元散射校正(Multiple Scatter Correction,MSC)、标准正态变换(Standard Normal Variate Transformation,SNV)、导数、归一化、平滑以及其组合方法用于原始数据的预处理。后期通过matlab自编程序实现特征波筛选以及基酒等级回归预测,完成基酒等级分类的目标。良好的预处理以及光谱特征波筛选有助于减少杂峰、突出检测主体,减少后期建模数据的复杂度,增加光谱数据的代表性,降低后期建模难度,提高处理精度。
1.3.1 预处理
EMSC、MSC、SVN都主要用于消除颗粒分布不均造成的散射效应对样品光谱的影响[20]。MSC通过计算所有样本的平均光谱,将每条光谱与平均光谱做一元线性回归,得到线性回归方程的斜率和截距,以此对原始光谱数据进行校正,整个过程中样品的成分含量信息在整个过程中不受影响,光谱信噪比提高了,每个光谱的基线平移和偏移都在参考平均光谱后被校正[21]。EMSC就是在MSC的基础上通过波长相关效应或先验信息更好地分离物理光散射效应和化学光吸收效应。SNV相较MSC来说通常需要计算每条光谱的平均值,而不是所有样本的平均值,然后除以光谱集的标准偏差,这就使得 SVN更适合于差异较大的样本。通过求导可以使得光谱更加平滑,能够得出物质吸收峰所在位置,可以明显消除基线和背景干扰,分析重叠峰,提高分辨率以及灵敏度,但同时会引入噪声,降低信噪比。归一化在可以一定程度上去除由于待测基酒含量不同所导致的数据集的方差。平滑可以消除光谱信号中叠加的随机误差从而提高信噪比,是一种最基础的去噪方法。以卷积平滑(Savitzky-Golay Smoothing)为例,它核心思想是最小二乘拟合移动窗口中的数据。
本实验使用光谱仪获得的图1a的光谱图光谱范围在34 000 cm-1~12 500 cm-1,但是待测基酒本身、实验仪器以及实验环境的影响,使得光谱头部9 017.738 cm-1~12 500 cm-1之间样本差异不大,会增加建模数据量,尾部34 000 cm-1~4 343.017 cm-1数据混乱无章,容易引入错误的建模规律。因此,在预处理前,剔除光谱头部以及尾部的数据,得到后期用于预处理的光谱图1b。由图1b中的信息可以发现波段内有两个较明显的吸收峰分别位于6 896 cm-1、5 128 cm-1附近,以及三个不明显的波峰,位于5 600 cm-1~6 000 cm-1波段附近,除此以外,波段8 000 cm-1~9 000 cm-1之间有一个较平缓的吸收峰。结合相关近红外谱图知识可知6 896 cm-1、5 128 cm-1附近的峰是水的特征区间,因此,水含量作为基酒分类的一个较小的影响因素,这两个波段位置可以在后期特征筛选中适当减少选取的数据。图1c~1f是不同预处理对光谱的影响。
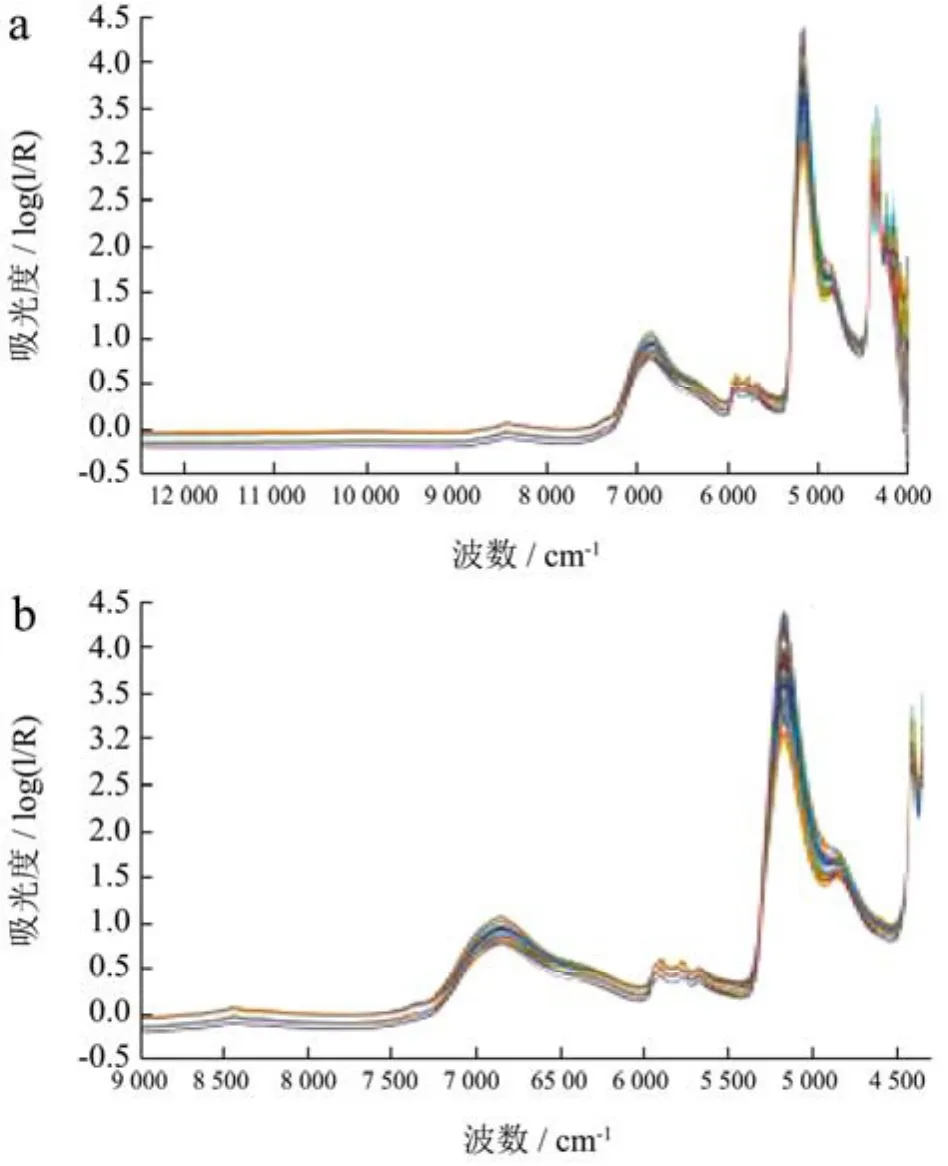

图1 原始光谱以及其预处理效果Fig.1 Original spectrum and its pretreatment effect
1.3.2 特征波筛选
特征波筛选算法中的主成分分析(Principal Component Analysis,PCA)是光谱特征波提取,竞争性自适应重加权算法(Competitive Adaptive Reweighted Sampling,CARS)和无信息变量消除法(Uninformative Variables Elimination,UVE)是光谱特征波选择。光谱特征波提取就是通过寻找光谱数据间的关系,使用新的方法表示光谱数据,这些更加简洁高效的数据就可以更好地代表以前的数据,例如:PCA、线性判别分析(Linear Discriminant Analysis,LDA)、独立成分分析(Independent Component Analysis,ICA)等。光谱特征波选择就是利用信号处理方法,在不改变原有数值的基础上将原始光谱中的决定性波数或波段筛选出来,例如:CARS、UVE、子区间最小二乘法(Interval Partial Least Squares,IPLS)等。特征波选择适用于特征峰相对集中的光谱,特征波提取主要用于特征变量分散的复杂数据。特征筛选的主要目的是降低数据维数,减少后期处理难度,剔除无用或者错误信息对最后分类结果的干扰。
1.3.2.1 竞争性自适应重加权算法(CARS)
CARS[22]是一种应用于筛选、剔除冗余光谱数据的方法,这个方法将每个波长变量当作一个独立个体,对波长进行逐步淘汰。本实验中,进行1 000次蒙特卡洛迭代采样与偏最小二乘回归,以此来获取CARS的最佳主成分数。筛选前期,变量随着采样次数的增加,筛选出的变量数快速减少,后期,即使采样次数增加,波长数量也很难减少了,最后,通过最小的交叉验证均方根误差(RMSECV)值来确定保留的波数。下图是以 CARS对基酒光谱进行处理的一个图,图2a~2c中最上面是筛选波的数量随着采样次数变化的曲线图,中间是RMSECV值随ARS运行次数变化的曲线,下面是变量回归系数路径随ARS运行次数的变化趋势图。图2d是没有经过预处理,只使用了马氏距离(Mahalanobis Distance,MD)剔除异常的CARS选取的数据结果,图中加粗的蓝色为选出的特征波。

图2 CARS选取及结果Fig.2 Selection and results of CARS
1.3.2.2 无信息变量消除法(UVE)
UVE是基于偏最小二乘回归系数构建的波长选择算法,以回归系数作为波长选择的最重要的衡量指标,剔除包含无效信息的光谱数据[23]。图3a是UVE处理的一个图,图中右边深红色为添加的1 215个随机光谱噪声数据,两条水平轴为变量选择的阈值,两轴之间的黑色部分是被剔除的无用数据,绿色部分为稳定的光谱数据值,是筛选出来的超过阈值的波数,这些数据将用于后期建模。图3b是没有经过预处理,只使用了马氏距离剔除异常的UVE选取的数据结果,图中加粗的蓝色为选出的特征波。

图3 UVE选取及结果UVEFig.3 UVE selection and results
1.3.2.3 主成分分析(PCA)
PCA是利用线性变化简化数据集的一种算法,这个算法的原理是将原矩阵变量组合成一组新的相互正交的几个综合变量,然后根据精度需要从前到后选择信息互不重复的新变量去反映原来的变量[24]。一般来讲,新变量的综合指标是通过方差来表示,方差越大,包含的原光谱信息就越多。PCA不同于前面的两种特征选择算法,它在保留原始特征的基础上将高维数据降为低维数据。图4是未经过预处理的光谱PCA降维结果,在帕累托图中可以看出,前两个维度就提取出了大于90%的原光谱特征,在保留数据特征的基础上,很好的压缩了数据量。但是为了避免选取太少的波数从而出现过拟合,在本实验中规定PCA的贡献大于1的成分是选取的成分,但是由于PCA能够通过很少的主成分极大限度地表征被测样品的性质以及物质组成,因而导致后期建模过程出现过拟合,因而,额外规定PCA选取主成分至少为20个。
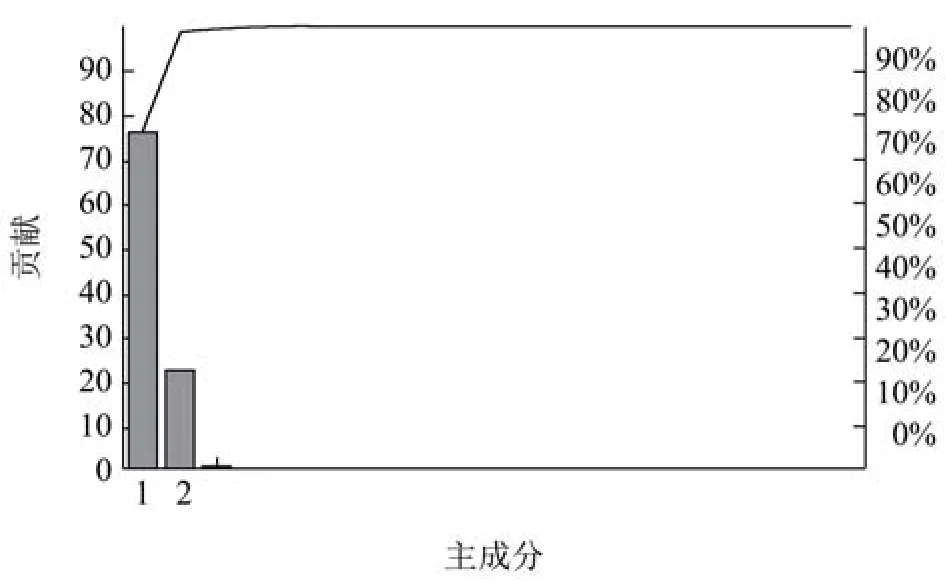
图4 PCA提取特征波Fig.4 PCA extraction of characteristic bands
2 分类模型的建立及分析
2.1 模型的建立与结果比较
为验证预处理方法:扩展多元散射校正(EMSC)、多元散射校正(MSC)、标准正态变换(SVN)、一阶gap导数(gap)、一阶SG导数(SG)、卷积3点平滑(SG+[3])、卷积5点平滑(SG+[5])、卷积7点平滑(SG+[7])、高斯滤波、移动均值滤波、中值滤波、单位向量归一化、面积归一化、均值归一化、基线偏移、基线偏移+gap一阶导数(基线+1D)、基线偏移+线性基线校正(偏移+线性校正)、基线偏移+卷积平滑(偏移+卷积)的有效性,所有数据样本通过光谱理化值共生距离法(SPXY)给数据集分类,然后使用预处理校正样本数据以及MD剔除异常数据,随后分别选取PCA、UVE、CARS去筛选光谱特征波,最后通过支持向量回归(SVR)预测基酒种类。在筛选特征变量的过程中,使用了决定系数(R2)、交叉验证均方根误差(RMSECV)来衡量CARS算法,校正集标准偏差(RMSEC)、相关系数(R)来衡量UVE算法,使用预测集集标准偏差(RMSEP)、预测集相关系数来(Rp)衡量PCA算法,表3是具体测试结果。
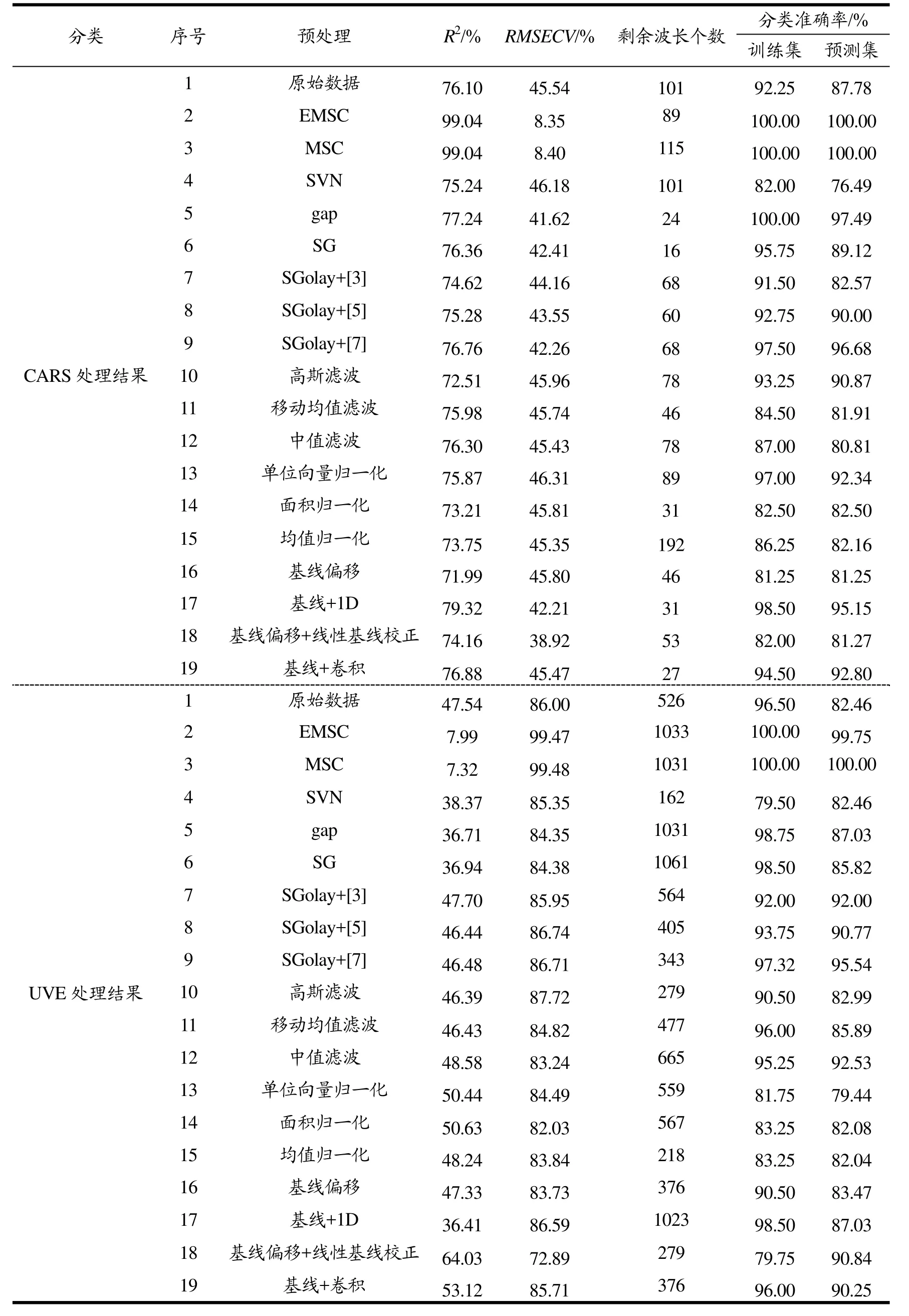
表3 具体测试结果Table 3 Specific test results
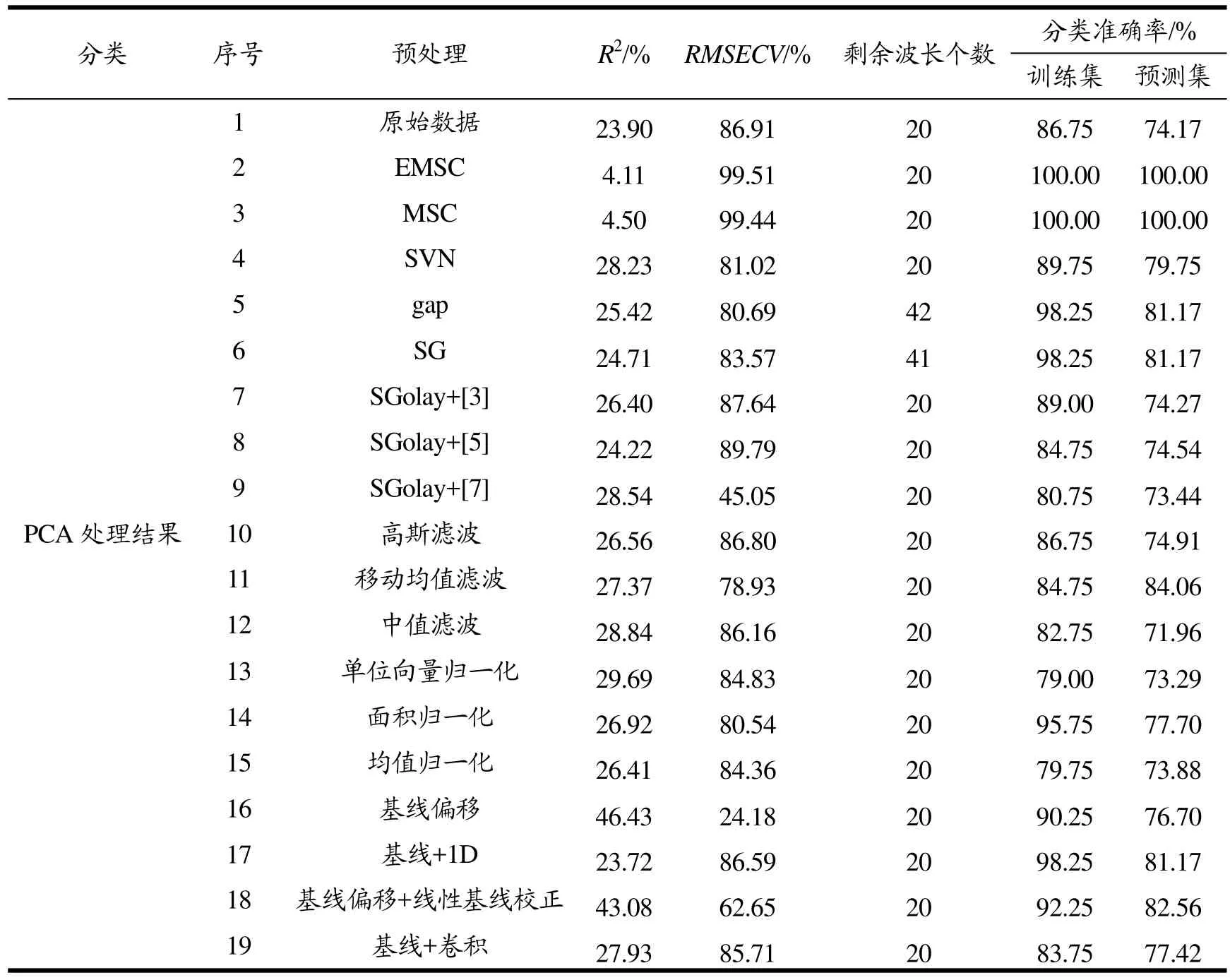
续表3
2.2 分类效果分析
2.2.1 评价指标
上述预处理与特征波筛选算法结合后的分类效果中,通过计算18种预处理方法、3种特征波筛选方法的平均准确率以及准确率的绝对偏差平均值来评价算法整体,具体数据如下表所示:由这些数据可以看出,原始数据经过三种预处理算法后的平均正确率为81.47%,除了SVN、面积归一化、均值归一化、基线偏移以外的预处理方法均能提高分类正确率,其中EMSC、MSC算法预处理处理后的数据经过3种特征波算法筛选后分类效果接近100%;CARS、UVE、PCA结合本实验的所有预处理方法后预测集的平均分类准确率分别达到 88.48%、88.02%、79.59%,准确率的绝对偏差平均值分别为6.28%、5.00%、5.60%。由此可以看出,EMSC、MSC、gap、SG+[3]、SG+[5]、SG+[7]、高斯滤波、移动均值滤波、基线+1D、基线+线性偏移、基线+卷积、CARS和UVE均能提高后期回归模型的分类准确率。
2.2.2 预处理结果对比分析
通过图5可以看出EMSC和MSC的分类效果稳定且分类准确率明显要高于其他预处理方法,这两个算法经过三个不同的波长筛选算法后训练集和预测集都能达到近100%的正确率,由于EMSC较MES更复杂,所以同样准确率的情况下更加倾向于使用 MES处理光谱。在理论上有同样处理效果的 SVN的平均准确率只有接近80%,这说明白酒基酒光谱差异不大,需要通过所有样本的平均光谱来校正误差。除了两个明显提高准确率的预处理算法外,还有部分预处理算法与适当的特征波筛选算法结合后可以较好地提高精度。Gap导数、SGolay+[7]、基线+1D、基线+卷积、单位向量归一化、高斯滤波的预处理结合CARS后预测集的准确率分别为97.49%、96.68%、96.68%、92.80%、92.34%、90.87%;SGolay+[7]、SGolay+[5]、SGolay+[3]、中值滤波、基线偏移+线性基线校正、基线+卷积的预处理结合 UVE预测集的准确率分别为 95.54%、90.77%、92.00%、92.53%、90.84%、90.25%,均能满足酒企基酒分级需要。除EMSC、MSC外的预处理方法结合PCA后不能使得预测集的准确率高于90%,因此目前选取的预处理算法不太适合与PCA结合。此外,由图5可知,不是所有预处理都能提高基酒分类准确率,以归一化为例,均值归一化后的数据,经过特征提取后的数据比原始数据都有所降低,而且经过单位向量归一化、面积归一化后有部分数据最后的分类准确率出现了下降。分析可知,基酒光谱经过处理后可能会使得特征光谱区被当成噪声处理后失去代表性,降低最后的分类准确率。
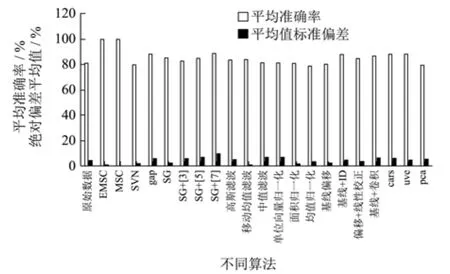
图5 不同算法的平均值与绝对偏差平均值Fig.5 Mean and absolute deviation mean of different algorithms
2.2.3 特征波筛选结果对比分析
在 CARS、UVE、PCA三个特征波筛选算法中CARS和UVE能实现较好的特征波提取。三个特征波筛选算法选择后剩余的平均波数为分别为 69、578、22,通过选取的数据点可以看出,后期分类耗时PCA<CARS<UVE。CRAS最后的选取结果是以RMSECV最小为依据,忽略了选取的波数越多,RMSECV更容易偏大,导致最后的选取结果中可能包含波数过少,不能完全表征光谱信息的情况,因此筛选结果差异较大,筛选稳定性不好。CARS通过先通过指数衰减的两个阶段去粗筛和精筛变量,然后通过ARS以竞争的方式去剔除权重较小的数据,两次的筛选可以很大程度地剔除无用数据,使得后期分类速度与分类正确率都较高。UVE的剔除后的剩余数据量占全光谱数据的47.57%,剩余波长的数量相对其他两种算法来说最多,导致后期分类时间较长,但是也因此具有较好的、稳定的分类准确率。对于PCA来说,通过相互正交的几组特征向量来表示光谱特征,使得光谱特征被极大保留,后续数据量不大,在不同的预处理方法下分类结果比较稳定,但是PCA主要是针对线性数据降维,对于非线性的基酒光谱数据来说,这个过程中损失了部分重要特征,因此分类的过程中需要其他算法相互配合才能达到较好的分类准确率,例如结合预处理算法EMSC、MSC,此时PCA降维后基酒分类准确率较高的同时还极大程度减少了输入SVR算法的数据量,极大提高了分类速度。
2.2.4 结果对比
目前,已经有很多学者结合近红外光谱技术对各种酒的质量检测以及品质分级技术进行了研究。以高畅[25]为例,他选取白酒基酒为研究对象,使用间隔偏最小二乘法(BiPLS)筛选特征波,偏最小二乘法(PLS)建立分析模型,得到决定系数为93.37%,RMSEC及RMSEP值分别为1.72%、1.77%的总酯定量模型。朱宏霞[26]使用4种归一化、两种导数单独或组合处理的方法做预处理,利用主成分回归法(PCR)和PLS建立定标模型,最终得到最佳效果验证集决定系数0.99,验证集预测偏差0.13。陈林[27]利用近红外光谱与气象色谱结合标定基酒甲酸含量,校正集决定系数99.25%,验证集决定系数97.6%。在本实验中,通过对比18种预处理方式,选出最优预处理 EMSC、MSC,结合CARS后得到最高决定系数99.04%,以及最低交叉验证均方根误差 8.35%;结合 UVE后得到高相关系数99.48%,最低RMSEC为7.32%;结合PCA后得到最高RP为99.51%,最低RMSECP为4.11%。由上述数据可以看出,本实验评估后选取的预处理与特征波筛选算法组合后的模型具有良好的性能。
3 结论
使用不同预处理方法以及特征波选取方法来将原始的高维光谱降成低维数据可以在很大程度上避免维度灾难,使得后面对数据进行回归处理时更加高效稳定,且具有一定得泛化性能。实验证明上述大部分预处理方法以及2种特征筛选方法可以提高白酒基酒分类准确率,实现白酒基酒分类的目的。实验表明,EMSC和MSC可以很好地处理白酒基酒酒花散射对最后结果的影响,提高分类准确率,但是 MSC算法更加简单。Gap导数、Sgolay+[7]、基线+1D、基线+卷积、单位向量归一化、高斯滤波、Sgolay+[7]的预处理结合 CARS,SGolay+[7]、SGolay+[5]、SGolay+[3]、中值滤波、基线偏移+线性基线校正、基线+卷积的预处理结合UVE能使得预测集分类准确率于90%,可以应用于实际的白酒分级过程,只有EMSC、MSC与PCA结合可以使得预测集实现较高分类。由于 PCA只有结合特定算法可以实现快速高效分类,因此建立的模型泛化性较低,需要注意算法的搭配,可以在不断调试优化后投入实际应用,CRAS的分类速度较快,可以考虑以后用于酒厂实时白酒摘酒,UVE的分类效果稳定,可以考虑用于基酒入库时的基酒分类。
猜你喜欢
农业科技通讯(2023年1期)2023-02-12 07:07:50
高技术通讯(2021年3期)2021-06-09 06:57:46
支点(2020年12期)2020-12-23 09:35:11
酿酒科技(2020年11期)2020-12-18 22:49:43
科学(2020年5期)2020-11-26 08:19:14
酿酒科技(2018年5期)2018-01-17 03:29:33
制导与引信(2017年3期)2017-11-02 05:16:56
舰船电子对抗(2016年5期)2016-12-13 08:41:14
工业设计(2016年11期)2016-04-16 02:50:19
环境科技(2015年6期)2015-11-08 11:14:26
