
基于角色信息引导的多轮事件论元抽取
2023-02-10 06:14:10于媛芳张勇左皓阳张连发王婷婷
北京大学学报(自然科学版) 2023年1期
于媛芳 张勇 左皓阳 张连发 王婷婷
北京大学学报(自然科学版) 第59卷 第1期 2023年1月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 59, No. 1 (Jan. 2023)
10.13209/j.0479-8023.2022.064
国家自然科学基金(61977032)、中央高校基本科研业务费(CCNU22QN014, CCNU22QN015, CCNU20TD006)和国家语言文字工作委员会“十四五”科研规划项目(YB145-2)资助
2022–05–29;
2022–07–27
基于角色信息引导的多轮事件论元抽取
于媛芳 张勇†左皓阳 张连发 王婷婷
华中师范大学计算机学院, 武汉 430079; † 通信作者, E-mail: ychang@ccnu.edu.cn
针对通用领域的事件论元抽取研究中角色信息利用不足和论元间缺少交互两个问题, 提出角色信息引导的多轮事件论元抽取模型, 用于增强文本的语义信息和论元之间的交互能力, 提升事件论元抽取的性能。首先, 为了更好地利用角色知识来引导论元的抽取, 该模型根据角色定义构造角色知识, 对角色信息和文本独立编码, 并采用基于注意力机制的方法获取标签知识增强的文本表示, 进而采用增强嵌入来预测各角色论元的起始和结束位置。同时, 为了在抽取过程中充分利用事件论元之间的交互, 受多轮对话模型的启发, 设计一种多轮事件论元抽取算法。该算法参照“先易后难”的自然逻辑, 每次选择预测概率最大, 也是最容易确定的角色进行抽取。在论元抽取过程中, 为了对论元之间的交互进行建模, 模型引入历史嵌入, 并在每一次预测结束后更新历史嵌入, 帮助下一轮事件论元的抽取。实验结果表明, 角色信息的引导和多轮抽取算法均有效地提升了论元抽取的性能, 使得该模型的表现优于其他基线模型。
事件论元抽取; 角色知识; BERT; 信息融合; 多轮抽取
随着网络新闻行业和社交平台的迅猛发展, 网络新闻用户快速增长。因网络的实时性和设备的便利性, 在网络平台上浏览新闻资讯成为日常。然而面对海量的数据, 用户不可能一一阅读, 因此有效的数据筛选尤为重要。新闻文档中包含的事件往往是关键信息, 它能在短时间内让用户了解事件发生的地点、时间及涉及的相关人员等。因此, 新闻文档中的事件抽取技术备受关注。事件抽取任务可细分为事件检测(或称触发词识别)子任务和事件论元抽取子任务, 本文仅针对事件论元抽取子任务进行研究。
在论元抽取任务相关研究中, 很多学者开始应用角色标签知识。例如, 在句子“Valls took a jet plane to Berlin.”中, “jet plane”意为喷气式飞机, 若已知“Vehicle”的标签含义为转移事件中搭乘的交通工具, 那么预测“jet plane”在 Transport 事件中为Vehicle 类型的论元便十分简单。同理, 作为城市, “Berlin”有极大可能扮演目的地(Destination)这一角色。这就需要解决如何让模型明确抽取目标的问题, 一种方法是在文本编码过程中融合角色知识, 让模型主动学习抽取目标, 从而帮助模型有目的地抽取论元。然而, 当前融合角色信息的方法较为单一, 拼接文本的方法增加了文本编码的长度, 并且不够灵活。
一个事件中通常存在多个论元, 但此前大部分研究中将论元抽取作为一次分类任务。事实上, 论元角色间的潜在关系能够帮助论元的抽取, 但同时抽取所有论元的方式忽视了论元之间的交互影响。在图 1 所示例句中, 存在以“killed”为触发词的Attack 类事件。在确定位于右侧的“them”为事件中Target 角色的情况下, 左侧的主语“The mob”将很有可能扮演 Attacker 角色。因此, 将论元抽取拆分成多次任务, 每次仅抽取一个角色的论元, 将每一轮的结果传递下去, 以便影响后续预测, 最终实现论元间的交互。为了在抽取过程中向当前角色的识别传递其他论元角色的预测信息, 需要针对论元或角色间的关系进行建模。
面对上述问题, 本文选择单独编码的方式, 对文本信息和角色信息分别建模, 然后进行信息聚合, 以便在文本表示中加入角色知识的引导。本文还提出多轮论元抽取算法, 旨在利用抽取过程中论元间的交互影响来提升事件论元抽取的性能。
1 相关工作
对于特定领域的事件抽取, 许多研究者积极引入领域信息, 加入外部资源库, 用来丰富文本中词的表示。尤其在生物医学领域, 文本中不少实体名属于未登录词, 而专业知识库中存在相应的实体信息, 因此引入外部知识库有助于事件抽取。Li 等[1]提出基于外部知识库(knowledge base, KB)驱动的事件抽取模型, 从基因本体论中提取实体的属性和类型描述, 并分别编码, 作为 KB 概念嵌入。Wang 等[2]在 PubMed 语料上使用文本分类工具 FastText 训练词嵌入, 即构建单词的语义空间, 以此提高触发词检测的性能。
不同于特定领域的事件, 由于通用领域中事件类型较多, 且多为新闻报道的热点, 引入知识库的方法并不适用。因此, 作为为数不多的外部信息, 官方文档中的论元角色定义受到关注。已有实验证明角色信息的引导能有效地提高模型性能, 常见的做法是拼接角色知识作为原始文本的上下文。如Du 等[3]和 Li 等[4]将触发词识别和论元抽取任务转换成 QA (question answering)问题, 用角色标签的信息拼接原始文本, 作为模型的输入, 通过 BERT 模型, 以共同编码的方式在词表示中加入角色的引导, 从而抽取相应角色的论元。
在编码前, 必须将每个文本转换为||对(|C|是标签类别集的大小), 这种转换同时增加了样本集合的大小和文本序列的长度, 若使用 BERT 模型编码, 还需注意最大长度限制。同时, 仅用[sep]符号对二者进行分割, 不能明显地区分主要信息和次要信息。在实际任务中, 原始语句的信息更为重要, 但类似拼接的方法不易调整“关注度”。于是, Yang等[5]提出在命名实体识别和触发词识别任务中分别对标签知识和预测语句单独进行编码的方法, 并将标签知识显式地集成到文本表示中, 解决标签知识利用不足的问题。

图1 论元之间的交互影响
在论元抽取任务中, 有研究者尝试用显式方法建模触发词类型之间、触发词类型与论元角色乃至论元角色之间的关系。如 JRNN[6]和 dbRNN[7]模型中使用的记忆向量和 SMA (self-matching attention)矩阵, 其中仅有一种构建方式经实验证明有效, 且均难以学习到论元之间的关系。由于论元角色之间的显式关系难以捕捉, 因此出现将论元抽取过程建模为多轮问答的方法[4], 通过增加历史嵌入, 为后续角色的抽取传递信息, 隐式地建模了触发词、事件类型和论元之间丰富的交互。
然而, 固定角色顺序抽取论元的方法未考虑每一文本的特性, 若当前事件中某些角色的预测概率极低(即可能不存在相应论元), 依照此方法仍需做无用的预测。本文受多轮对话任务启发, 提出多轮抽取算法, 遵循“先易后难”的思想, 根据文本表示的预测概率, 无固定顺序地对各角色论元进行抽取, 并更新历史嵌入, 为后续抽取提供信息。
早先, 事件论元抽取多被视为序列标注任务, 缺点是无法正确地预测同一个 token 扮演多个角色的现象。后来, 更多的研究者将事件论元的抽取作为跨度抽取任务来处理。Sheng 等[8]为了解决角色重叠问题, 设计一组特定于角色的标注器, 预测每一个 token 是否为论元的起始位置和结束位置, 然后使用解码策略来确定论元。此外, Yang 等[9]和Ahmad 等[10]先后提出不同的文本跨度解码策略来提升论元抽取的性能。本文效仿上述做法, 通过预测起始和结束位置来确定论元。
2 研究方法
受前人工作启发, 本文提出角色信息引导的多轮事件论元抽取模型。该模型分为语义编码层、角色信息融合层、历史嵌入层和多轮论元抽取层几个模块, 结构如图 2 所示。模型输入包括文本和角色知识集。首先, 两个输入分别由预训练的 BE-RT 模型进行编码, 其编码器共享权重。在角色信息融合层, 将得到的文本嵌入和角色标签知识嵌入进行融合, 得到标签知识增强的文本嵌入。然后, 采用增强嵌入来预测每个 token 是否为某类别的起始位置或结束位置。最后, 按照多轮抽取算法, 根据预测的概率分布, 每次仅抽取一个类型的论元, 直至完成当前事件中所有可能的论元角色预测。
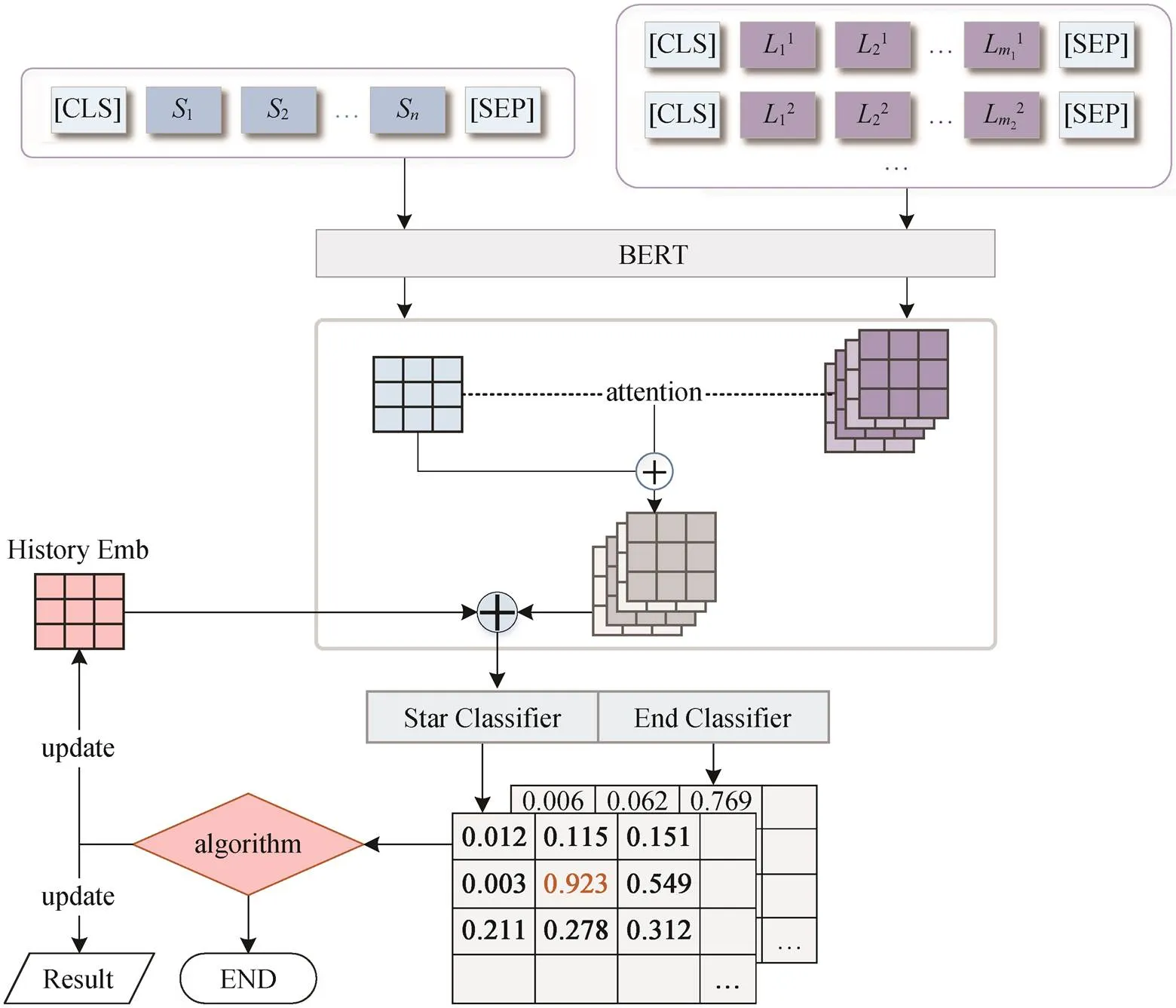
图2 角色信息引导的多轮事件论元抽取模型
2.1 预处理
本文实验均在 ACE05 数据集上进行。与引入外部知识库的方法不同, 本文使用的类别标签知识仅来源于事件抽取任务的官方文档中给出的定义, 仅对部分角色的注释做了调整, 大部分角色与文档给出的释义保持一致, 如表 1 中 Transport 事件包括交通工具(Vehicle)和目的地(Destination)在内的 7 种角色。
与其他角色不同, 时间(Time)类别又分为 8 个子类型, 已发生、正在发生和将要发生的事件具有不同的子类型, 并且一个事件可同时存在多个子类型, 但官方文档中仅给出 Time 角色大类的释义。于是, 本文通过在尾部添加关键词来区分子类型(表2)。
2.2 语义编码层
对于输入文本和角色知识, 均采用预训练的BERT 模型[11]进行编码。对于长度为的输入语句(1,2, …,), 经过 BERTarg编码所得结果如式(1)所示:
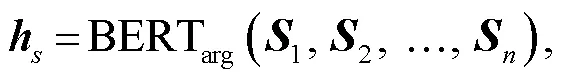
取最后一层隐藏状态作为嵌入。

2.3 角色信息融合层
信息融合模块旨在用角色知识显式地增强文本表示。将经过共享编码器产生的文本嵌入和类别嵌入进行融合, 得到类别知识增强的文本表示。首先, 在编码层分别增加全连接层1和2, 将两种嵌入表示映射到同一个语义空间中, 如式(3)和(4)所示:

表1 Transport类事件中的论元角色及对应标签释义
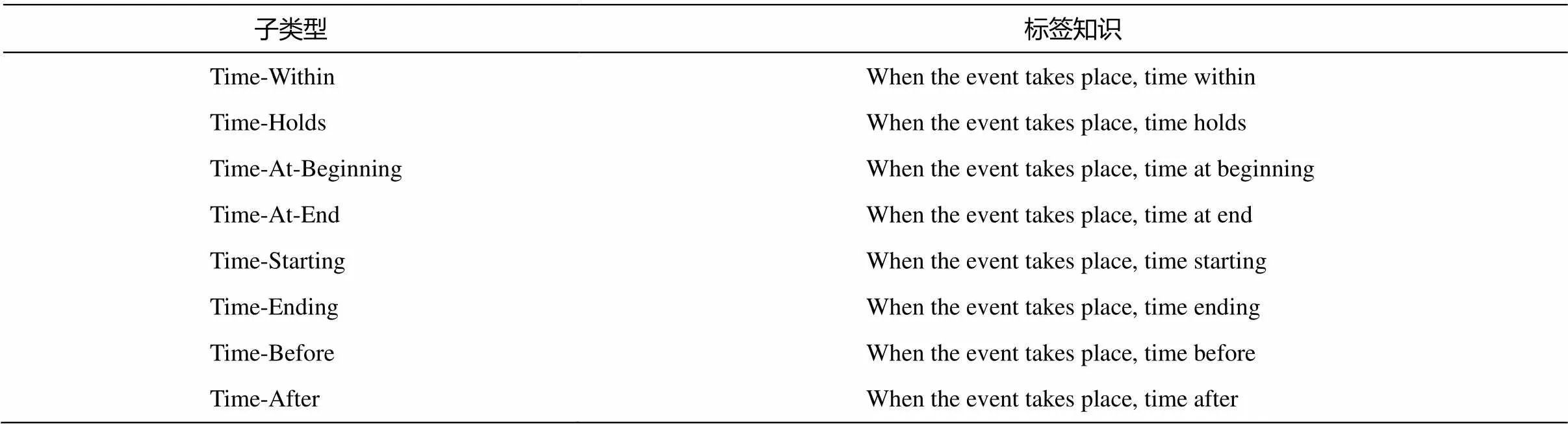
表2 Time角色的 8 个子类型及对应标签释义
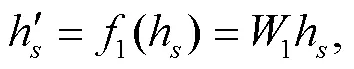
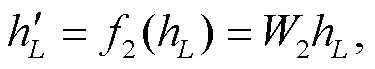
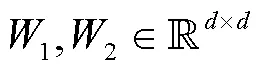
余弦相似度是一种传统的相似度计算方法, 常用于推荐系统中计算文章内容和物品相似度。另外, 考虑到经过转换后类别信息和原始文本在同一个语义环境中, 故采用 Luong 等[12]提出的 attention机制进行关注度计算, 从而融合角色信息。两种融合方式的操作步骤如下。

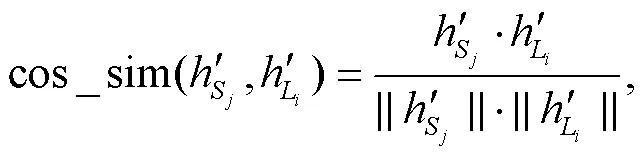
其中, 1≤≤, 1≤≤。
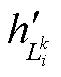

根据注意力分数计算角色知识中每个 token 的加权和后, 为了在融合的过程中保留原始文本表示, 加上原始编码层的语义表示, 通过式(7)中向量加法得到融合信息表示:
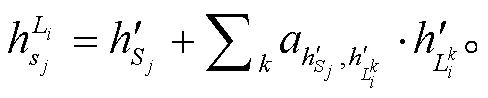
为了缓解反向传播过程中梯度消失问题, 在全连接层添加 tanh 激活函数, 如式(8)所示:
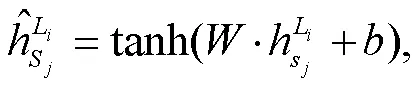
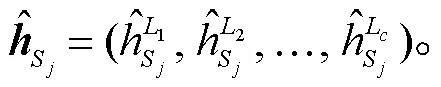
2.4 历史嵌入层
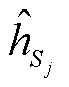
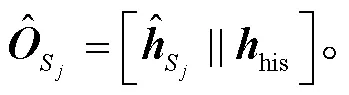
对于历史嵌入向量, 直觉上可以根据角色类型编码不同的历史嵌入, 类似依存标签的应用。但是, 当前绝大多数的依存句法应用中, 都未使用依存标签, 而是用简单的二值化方法来区分是否存在支配与从属关系。Cui 等[13]指出, 区分依存类型会导致过度参数化。同理, 本文模型选择使用两个嵌入向量和来区分 token 是否在前几轮的抽取中被预测为某个角色的论元, 其中和的初始化是随机的。为了探究多标签历史嵌入是否有效, 我们在对比实验中设计了各种历史嵌入向量, 包括生成可训练的多类别嵌入和间接使用角色知识嵌入等。
2.5 多轮事件论元抽取层
经过编码层得到 token 的表示之后, 需要对其进行分类。为了确定论元 span, 本文模型使用起始分类器(start-classifier)和结束分类器(end-classifier)分别预测论元在句子中的起始位置和结束位置。对于每一个 tokens, 预测为一个角色的论元起始或结束位置概率的计算方法如式(11)和(12)所示:
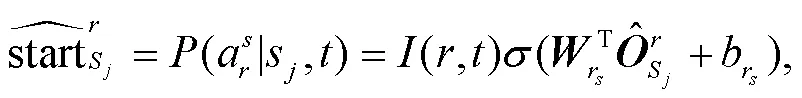
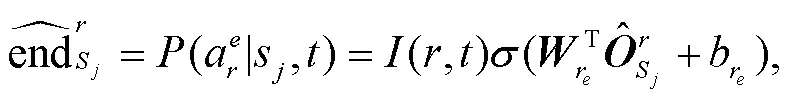
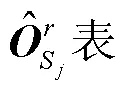
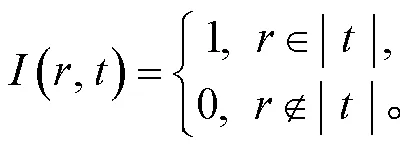
(,)的结果来源于角色 mask 矩阵, 当角色属于类型的事件时其值为 1, 否则为 0。
由于同样的角色标签在不同的事件类型中的标签知识不尽相同, 所以归为不同角色类别。但是, 这也导致角色数量成倍增加。为了保证在事件中抽取论元时仅考虑属于此类型的角色, 使用角色mask 矩阵来存储它们的对应关系, 矩阵的“行”表示一类事件中包含的角色类别, “列”表示该角色存在的事件类型。
在得到预测概率之后, 根据本文设计的算法 1来确定当前一轮提取的角色。

秉持先易后难的原则, 本文算法设计的初衷是优先抽取较易确定的角色。当一个 token 被预测为某个角色时, 相应地, 该 token 作为其他类型角色的概率降低。循环抽取, 以此提高抽取的准确度。算法 1 的主要步骤如下。
1)假设每个 token 对所有角色的预测起始位置概率构成一个×的矩阵, 找出矩阵中的最大值(,), 其中为最大值对应的角色编号。
2)判断是否达到抽取阈值, 低于阈值则结束论元抽取, 高于阈值则使用 get_span 函数解码, 将结果记为 result spans。关于解码规则, 目前应用最广泛的是“最近匹配原则”, 该方法将类别的起始位置与距离最近的下一个结束位置相匹配。但是, 为了更合理地抽取出 span, 本文使用 Yang 等[9]提出的“启发式匹配原则”。
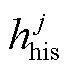
循环执行上述 3 个步骤, 直至某轮的抽取结果为空, 结束论元抽取。
2.6 损失函数
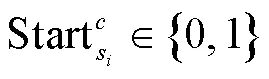

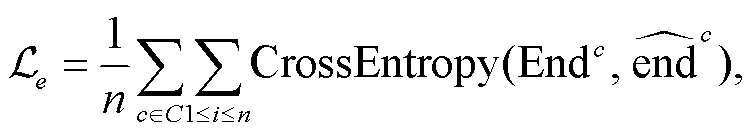
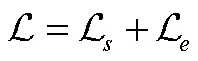
3 实验
本文实验均在 ACE2005 英文数据集上进行训练和测试。ACE05 数据集[14]: 由 ACE2005 给出, 用于 ACE2005 定义的实体识别、关系抽取和事件抽取任务。数据来源主要有微博(weblogs)、广播新闻(broadcast news)、新闻专线(newsgroup)和广播对话(broadcast conversation), 其中数据的语言含中文、英语和阿拉伯语三类。为了便于实验结果的直接比较, 本文保持与既有工作相同的数据分割, 40篇新闻专线文档用于验证集, 30 篇文档用于测试集, 剩余 529 篇文档分配给训练集。三类数据子集的统计结果见表 3。
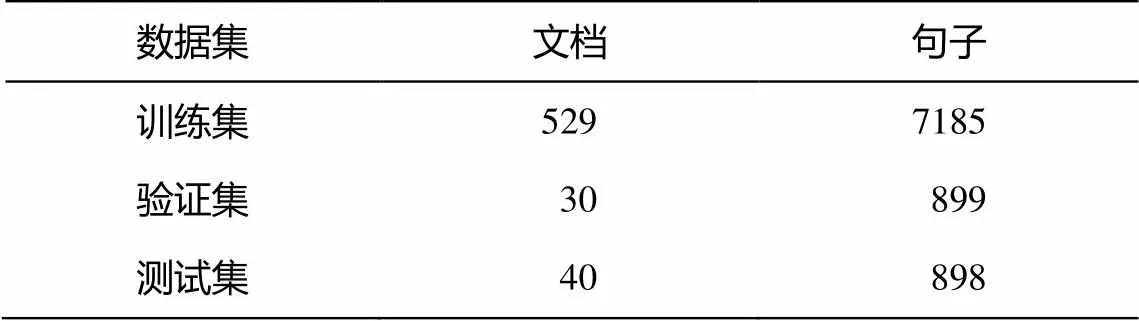
表3 ACE05数据集中文档和句子数量
3.1 实验设置
本文模型框架的构建以及训练和测试均通过Pytorch 实现。在语义编码层, 使用预训练的 bert-base-uncased, 获得的词嵌入维度为 768。在历史嵌入层, 为已抽取过和未抽取过的论元分别设置和两个向量。在抽取之前, 向量随机初始化, 并将其维度设置为 250。此外, 在论元抽取过程中, 起始和结束位置的预测阈值为 0.5。
3.2 基线方法
在论元抽取任务被开发后, 研究者提出众多模型, 本研究只选取以下 6 种具有代表性的模型进行 对比。
1) Li’s BASELINE[15]: 提出基于特征的系统, 使用根据专家知识设计的词汇和语法特征。
2) DMCNN[16]: 采用 CNN 和分段动态池化方式来获取句子级语义特征, 然后拼接词级特征, 对触发词和候选论元关系进行分类。
3)JRNN[6]: 是一种基于 RNN 的事件抽取联合模型, 并且为了利用潜在触发词与论元角色间的关系, 设计了事件类型间与角色间的记忆向量。
4) DYGIE++[17]: 是一个基于 BERT 的信息抽取框架, 通过对捕获了句内信息和跨句信息的 spans进行枚举和打分来完成各类信息抽取任务。
5)BERT_QA_Arg[3]: 将论元抽取任务建模成 QA问题, 根据角色知识来构造问题, 使用 BERT 获取原始语句中的上下文表示, 最后针对问题中的角色进行 span 抽取。
6)MQAEE[4]: 用多轮对话的形式完成论元抽取任务, 每轮抽取使用前轮的历史回答信息, 且固定角色抽取顺序。
3.3 实验
3.3.1 模型对比
表 4 中, 只有 Li’s BASELINE 模型采用传统的手动特征工程, 由于人工构建的语法规则较为强硬, 约束性较强, 所以准确率较高, 召回率较低。DM-CNN 和 JRNN 模型均未使用 BERT 生成上下文相关的词嵌入, 但事件抽取联合模型 JRNN 仍然表现出很强的竞争力。JRNN 的实验结果表明, 虽然设计的记忆向量对触发词检测阶段没有帮助, 但在提高论元预测性能方面非常有效。
与本文所提模型相同, DYGIE++也使用 BERT获取词的上下文嵌入, 但没有用到丰富的角色知识, 也忽略了抽取过程中论元之间产生的交互影响, 导致模型效果一般。模型 BERT_QA_Arg 和 MQAEE对事件论元抽取任务的处理方式相似, 均建模为阅读理解问题, 并且使用官方文档中的类别注释来引导答题, 不同点在于 MQAEE 使用多轮问答, 在抽取过程中加入历史回答信息。
本文模型的特点在于将角色的知识和文本独立编码后进行信息融合, 既能避免文本编码长度的增加, 又使得文本 token 能够充分关注论元角色信息而不被文本自身的 token 分散注意力。并且, 在抽取阶段, 本文设计了遵循“先易后难”循环抽取思想的算法, 隐式地捕捉事件论元之间的交互。因此, 对比其他模型, 本文模型获得较有竞争力的表现。
3.3.2 消融实验
1)探究历史嵌入的设计和维度大小带来的影响。实验中设计 3 种历史嵌入向量: ①使用随机初始化的方法, 生成字典大小为 label_num+1 的嵌入表(label_num 为角色数量, 加上一种非论元类型); ②间接使用角色知识嵌入, 即将角色知识嵌入输入全连接层进行降维, 得到历史嵌入向量; ③使用二值历史嵌入向量, 仅用两个不同的可训练向量表示当前 token 是否已经被抽取。实验结果表明, 使用前两种方法时, 模型在数据集上训练多个 epoch 后仍然无法收敛。
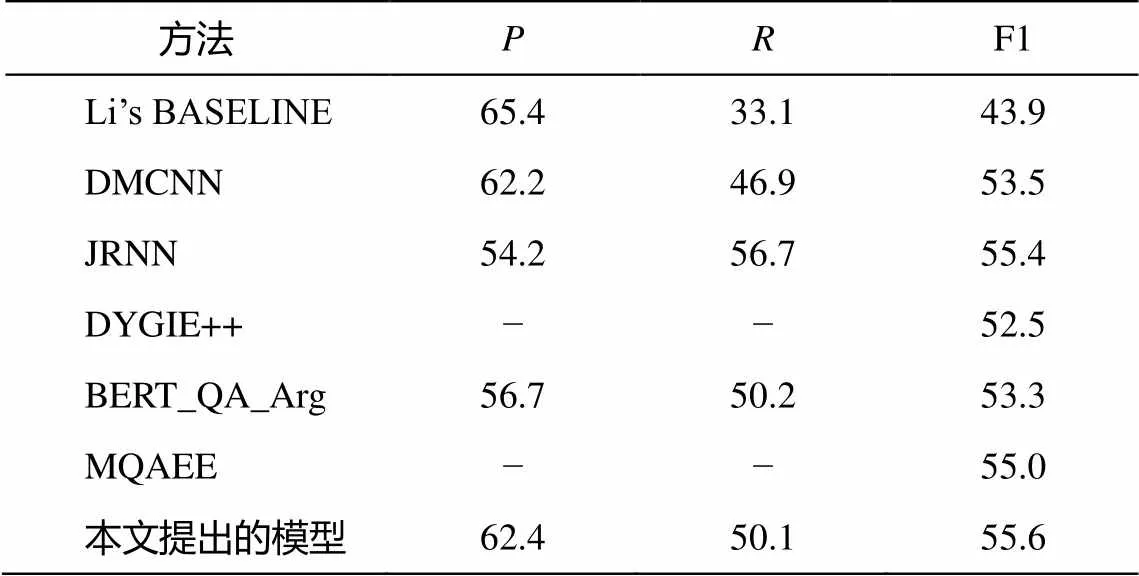
表4 各模型在 ACE05 论元抽取任务上的表现(%)
另外, 实验中对历史嵌入加入的位置也进行了多种尝试, 在初始文本与类别信息融合之前和之后分别拼接历史嵌入向量。但是, 在信息融合模块之前进行拼接, 模型效果很差, 原因可能是历史嵌入与文本和角色知识的编码不在同一个语义空间。
为了探究历史嵌入维度对性能的影响, 本文模型分别在 3 种不同维度的二值化历史嵌入向量上进行实验, 性能的变化如表 5 所示。当维度为 250 时, F1 值最高。前两种设置的模型训练结果不太稳定, 平均来看, 几乎与同时抽取的效果持平, 最优结果略好。表 5 中给出的是较稳定的结果。
2)两种信息融合方式的性能比较。在本文的实验中使用余弦相似度和 attention 机制的效果差距不明显, 原因可能是使用句子级语义已经足够引导分类器抽取。另外, 事件论元抽取任务的和 F1 值难以提升的原因也许并不在于角色标签理解方面的 困难。
3)角色 mask 矩阵和多轮抽取算法的有效性。考虑到论元角色众多, 角色 mask 矩阵的使用显然是必要的。由于论元抽取任务的整体准确率不算太高, 多轮抽取算法企图利用潜在的论元之间交互是否有效, 还需实验加以证明。因此, 本文设计 3 组实验来证明两种方法的正向作用, 结果列于表 6。首先测试不加角色 mask 矩阵的情况, 结果显示 F1值不到 0.35。使用 mask 矩阵之后,值和值均大幅度上升。在此基础上使用多轮抽取模块, 在设置历史嵌入维度为 250 的条件下, 又将 F1 值提高近一个百分点。实验结果表明, 多轮抽取算法有不错的 效果。
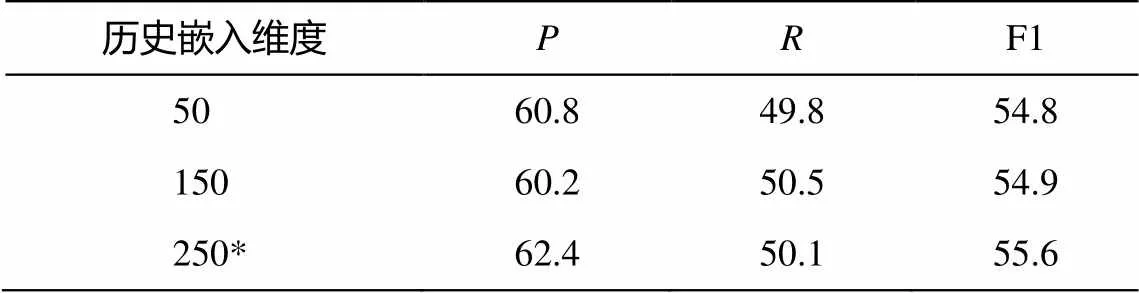
表5 不同维度的历史嵌入下模型性能(%)
注: *效果最佳设置, 下同。
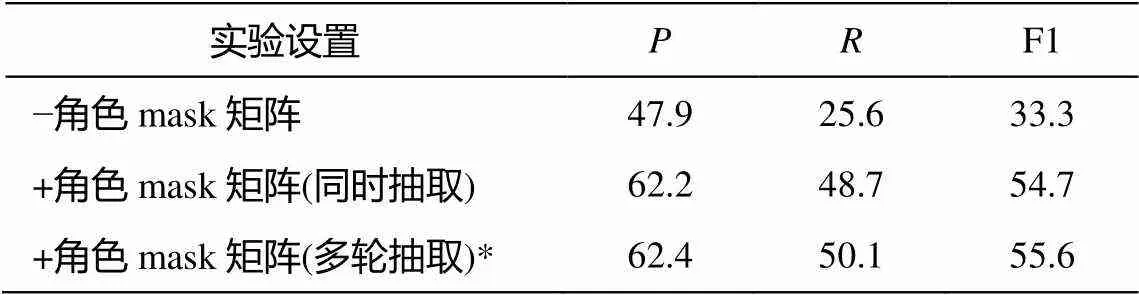
表6 角色mask矩阵和多轮抽取算法的影响(%)
4 总结
本文提出角色信息引导的多轮论元抽取模型, 将独立编码的文本表示和角色知识表示用信息聚合技术生成知识增强的嵌入, 以便加入角色知识的引导。本文还设计多轮抽取算法, 通过使用论元抽取的中间结果, 间接地捕捉论元间的交互。通过与其他模型结果的对比和消融实验, 验证了角色知识这一外部信息在抽取过程中对文本表示的有效引导以及多轮抽取算法的有效性。
[1]Li Diya, Huang Lifu, Ji Heng, et al. Biomedical event extraction based on Knowledge-driven Tree-LSTM // Proceedings of the 2019 Conference of the North American Chapter of the Association for Computa-tional Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Minneapolis, 2019: 1421–1430
[2]Wang Yan, Wang Jian, Lin Hongfei, et al. Bidirec-tional long short-term memory with CRF for detecting biomedical event trigger in FastText semantic space. BMC Bioinformatics, 2018, 19(20): 59–66
[3]Du Xinya, Cardie C. Event extraction by answering (almost) natural questions // Proceedings of the 2020 Conference on Empirical Methods in Natural Lan-guage Processing. Demos, 2020: 671–683
[4]Li Fayuan, Peng Weihua, Chen Yuguang, et al. Event extraction as multi-turn question answering // Find-ings of the Association for Computational Linguistics: EMNLP. Online Meeting, 2020: 829–838
[5]Yang Pan, Cong Xin, Sun Zhengyun, et al. Enhanced language representation with label knowledge for span extraction // Proceedings of the 2021 Conference on Empirical Methods in Natural Language Proces-sing. Punta Cana, 2021: 4623–4635
[6]Nguyen T H, Cho K, Grishman R. Joint event extrac-tion via recurrent neural networks // Conference of the North American Chapter of the Association for Com-putational Linguistics: Human Language Technolo-gies. San Diego, 2016: 300–309
[7]Sha Lei, Qian Feng, Chang Baobao, et al. Jointly extracting event triggers and arguments by depen-dency-bridge RNN and tensor-based argument interac-tion // Proceedings of the AAAI Conference on Arti-ficial Intelligence. New Orleans, 2018: 5916–5923
[8]Sheng Jiawei, Guo Shu, Yu Bowen, et al. CasEE: a joint learning framework with cascade decoding for overlapping event extraction // Findings of the Asso-ciation for Computational Linguistics: ACL-IJCNLP. Online Meeting, 2021: 164–174
[9]Yang Sen, Feng Dawei, Qiao Linbo, et al. Exploring pre-trained language models for event extraction and generation // Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Flo-rence, 2019: 5284–5294
[10]Ahmad W U, Peng N Y, Chang K W, et al. GATE: graph attention transformer encoder for cross-lingual relation and event extraction // Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelli-gence. Online Meeting, 2021, 4: 74–75
[11]Devlin J, Chang M W, Lee K, et al. BERT: pre-training of deep bidirectional transformers for langu-age understanding // Proceedings of the 2019 Confe-rence of the North American Chapter of the Asso-ciation for Computational Linguistics: Human Lan-guage Technologies. Minneapolis, 2019: 4171–4186
[12]Luong M T, Hieu P, Manning C D.Effective app-roaches to attention-based neural machine translation [EB/OL]. (2015–09–20) [2022–01–15]. https://arxiv. org/abs/1508.04025
[13]Cui Shiyao, Yu Bowen, Liu Tingwen, et al. Edgeen-hanced graph convolution networks for event detec-tion with syntactic relation // Findings of the Asso-ciation for Computational Linguistics: EMNLP. On-line Meeting, 2020: 2329–2339
[14]Walker C, Strassel S, Medero J, et al. ACE 2005 multilingual training corpus. Linguistic Data Consor-tium, Philadelphia, 2006, 57: 45. (2006–02–15) [2021– 09–22]. https://catalog.ldc.upenn.edu/LDC-2006T06
[15]Li Qi, Ji Heng, Huang Liang. Joint event extraction via structured prediction with global features // Pro-ceedings of the 51st Annual Meeting of the Associa-tion for Computational Linguistics (Volume 1: Long Papers). Sofia, 2013: 73–82
[16]Chen Yubo, Xu Liheng, Liu Kang. Event extraction via dynamic multi-pooling convolutional neural net-works // Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Lan-guage Processing (Volume 1: Long Papers). Beijing, 2015: 167–176
[17]Wadden D, Wennberg U, Luan Y, et al. Entity, rela-tion, and event extraction with contextualized span representations // Proceedings of the 2019 Conferen-ce on Empirical Methods in Natural Language Pro-cessing and the 9th International Joint Conference on Natural Language Processing. Hong Kong, 2019: 5784–5789
Multi-turn Event Argument Extraction Based on Role Information Guidance
YU Yuanfang, ZHANG Yong†, ZUO Haoyang, ZHANG Lianfa, WANG Tingting
School of Computer, Central China Normal University, Wuhan 430079; † Corresponding author, E-mail: ychang@ccnu.edu.cn
Aiming at the two problems of insufficient utilization of role information and lack of interaction between arguments in general domain event argument extraction research, a role information-oriented multi-turn event argument extraction model is proposed to enhance the semantic information of texts and interactions between arguments. The interactive capability can improve the performance of event argument extraction. First, to better utilize role knowledge to guide argument extraction, the model builds role knowledge based on role definitions, independently encodes role information and text, and uses a method based on attention mechanism to obtain label-knowledge-enhanced representations. Then the augmented embeddings are used to predict whether or not each token is a start or end position for some category. At the same time, in order to make full use of the interaction between event arguments in the extraction process, inspired by the multi-turn dialogue model, this paper designs a multi-turn event argument extraction algorithm. The algorithm refers to the natural logic of “easiness to hardness”, and selects the character with the highest prediction probability, that is, the most predictable character, for extraction each time. In the process of argument extraction, in order to model the interaction between arguments, the model introduces historical embedding, and updates the historical embedding after each prediction to help the extraction of the next round of event arguments. The experimental results show that the guidance of role information and multi round extraction algorithm effectively improve the performance of argument extraction, and the method achieves state-of-the-art performance.
event argument extraction; role knowledge; BERT; information fusion; multi-turn extraction
猜你喜欢
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09 06:12:12
汉字汉语研究(2020年2期)2020-08-13 07:52:48
电子制作(2019年22期)2020-01-14 03:16:24
疯狂英语·新读写(2018年3期)2018-11-29 22:37:11
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
韶关学院学报(2017年4期)2017-04-13 20:25:22
海外华文教育(2016年3期)2017-01-20 08:22:14
公民与法治(2016年10期)2016-05-17 04:12:58
计算机工程(2015年8期)2015-07-03 12:20:27
