
基于多信息感知的多方对话问答方法
2023-02-10 06:31:40高晓倩周夏冰张民
北京大学学报(自然科学版) 2023年1期
高晓倩 周夏冰 张民
北京大学学报(自然科学版) 第59卷 第1期 2023年1月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 59, No. 1 (Jan. 2023)
10.13209/j.0479-8023.2022.069
国家自然科学基金(62176174)和江苏高校优势学科建设工程项目资助
2022-05-13;
2022-08-05
基于多信息感知的多方对话问答方法
高晓倩 周夏冰†张民
苏州大学计算机科学与技术学院, 苏州 215000; † 通信作者, E-mail: zhouxiabing@suda.edu.cn
目前基于多方对话文本的自动问答任务侧重于探索对话结构信息或说话者角色信息, 忽视问题文本和对话文本的交互。针对这一问题, 提出一个融合多信息的全新模型。该模型使用图卷积神经网络, 对多方对话文本中的话语结构、说话者角色以及问题–上下文信息进行分层次建模, 并设计合理的基于注意力机制的交互层, 通过选择更有帮助的信息, 加强对多方对话文本的理解。此外, 该模型首次对问题和上下文间的显式交互给予关注。实验结果表明, 所提模型的性能优于多个基线模型, 实现对多方对话文本的深层次理解。
多方对话; 自动问答; 图卷积网络; 注意力机制
自动问答(question answering, QA)任务通过理解相关上下文进行问题解答。根据上下文类型的不同, QA 任务大致可分为基于文本的问答(document based question answering, DQA)[1–2]、基于结构化数据的知识库问答[3]以及基于图片或视频信息的视觉问答[4]等。早期的 DQA 任务主要基于段落式文本, 通过理解语义连贯的段落或篇章来回答给定问题。随着大量可用数据集的发布[5–8], 基于对话文本的自动问答任务逐渐受到关注, 该任务旨在让模型理解对话并回答与对话上下文有关的问题。早期的工作侧重从双方对话中通过提取与问题相关的证据进行答案预测。Niu 等[9]使用自训练的方法, 在非抽取式且不带证据标签的数据集上进行证据提取器的训练, 获得预测答案。Perez 等[10]通过在两方对话文本上训练一个强有力的证据提取器来提高模型的答案预测能力。
作为自然语言处理中的一个重要课题, 基于多方对话文本的自动问答任务(question answering in multi-party conversation, QAMC)也受到越来越多的关注。相较于两方对话[7–8], 多方对话文本具有至少 3 个对话者, 他们具备各自的语言风格和对话目的, 并且对话者的发言顺序不具有轮换规律, 这会带来更分散的信息分布和更频繁的指代。为了进一步说明 QAMC 任务的挑战性, 本文从 Molweni数据集[6]中抽取一个对话示例, 如图 1 所示。为了解答示例中的问题 Q, 模型需首先找出 Q 与 U3 的关系, 然后利用 U3 与 U2 之间的话语依赖, 解决“you”带来的共指问题。其次, 模型需锁定说话者“djjason” 的系列话语, 并从中探索与 U3 存在话语依赖的语句, 最后将关注点放在 U4 上完成预测。可以看出, 相比于传统基于段落式文本的问答任务, QAMC 任务包含更多的信息感知和推理。
近年来在 QAMC 任务中出现很多新技术的探索。Shi 等[11]提出面向多方对话文本的话语结构解析工具, He 等[12]提出多任务学习对话语结构解析任务和 QA 任务联合建模, Gu 等[13]提出的 SA-BERT 模型主要关注特定对话者的信息。Liu 等[14]提出基于说话者的掩码自注意力机制, 通过两个互补的掩码矩阵以及恰当的信息聚合方式, 在字符级别上对文本进行理解。这些工作极大地促进了 QAMC 任务的发展, 但是它们只关注特定对话者角色感知的信息或话语结构信息, 在处理问题文本时, 将其与对话文本进行拼接, 然后使用预训练语言模型统一编码, 进行特征提取, 未关注问题文本和对话文本的交互。从图 1 的示例中可以发现, 模型需要对话语结构、说话者角色感知以及问题–上下文感知等多方信息进行建模, 才能够更加全面地理解多方对话文本。
本文针对 QAMC 任务, 提出一个融合多方信息的模型 Dis-QueGCN (both discourse- and question-aware graph convolutional network, Dis-QueGCN),利用图卷积神经网络, 对对话文本和问题文本之间的细粒度交互信息进行分层次建模。最后, 在Molweni 数据集上进行实验, 结果表明本文提出的模型性能优于强大的基线模型。
1 结构化建模方法
本文提出的 Dis-QueGCN 模型如图 2 所示。模型分为 4 个分层模块: 输入编码层、对话理解层、信息交互层和答案预测层。其中, 输入编码层使用BERT 作为编码器进行字符级特征提取[15], 对话理解层应用图卷积神经网络, 对多方对话文本进行分层次建模[16], 信息交互层使用注意力机制, 为字符级特征分别融入多层次的话语级特征, 答案预测层对交互后的分层次信息进行拼接融合, 并预测答案 区间。
1.1 问题定义
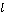

图1 多方对话示例
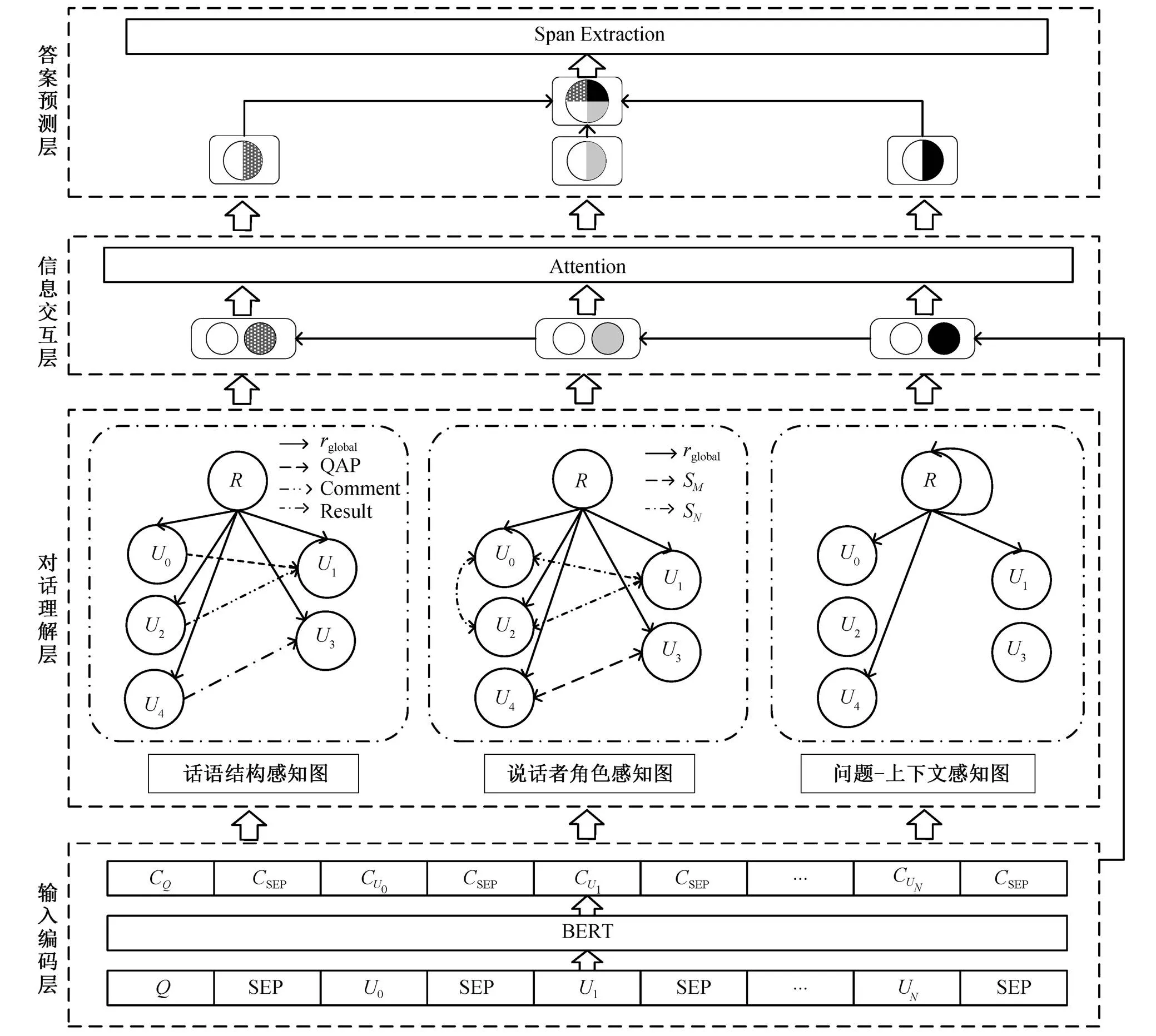
图2 Dis-QueGCN模型框架
1.2 输入编码层
由于预训练语言模型在各类任务中的出色表现[17–18], 本文使用一种基于 Transformer 结构的双向编码器 BERT 来获得字符级上下文特征表示[19]。为了更好地学习上下文表示, BERT 的预训练采用两个子任务: 掩码语言建模和下一句预测任务。
首先将对话中个独立的话语单元U进行拼接, 并在句首对问题进行拼接。接着在句首和单个话语单元U的句尾分别插入[CLS]标识符和[SEP]分隔符, 将输入处理成[CLS][SEP]0[SEP0]1[SEP1]...U[SEP]形式后输入 BERT, 经过编码可以得到初始化的上下文表示=R×Dim。其中,表示输入序列的长度, Dim 表示隐藏状态的维度。
1.3 对话理解层
对话理解层包含话语结构感知图、说话者角色感知图和问题–上下文感知图。话语结构感知图对对话文本之间的结构关系进行建模, 说话者角色感知图主要关注特定说话者的信息, 问题–上下文感知图对问题文本和对话文本进行显式建模。三幅图从不同层面对多方对话文本进行分层次建模。
1.3.1 话语结构感知图
说话者角色的复杂转换打破了原有段落式文本的一致性, 从而导致话语之间的相互关系错综复杂。本文构建一幅有向图d= {d,d,d}来建模对话文本中的话语结构。其中d,d和d分别代表话语结构感知图中的顶点集合、边集合和关系集合。
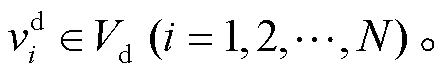
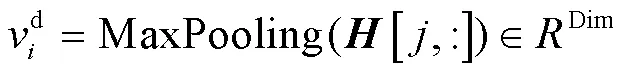
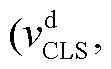
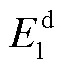
本文使用两步图卷积操作, 将话语结构信息融合进字符级特征向量中, 信息融合的计算方式[16]如下:
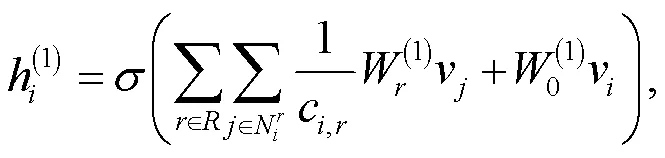
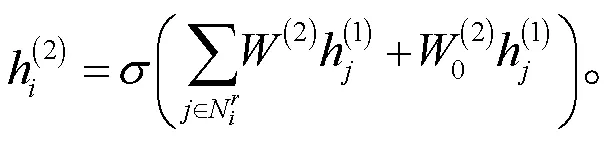
1.3.2 说话者角色感知图
为了捕捉特定于说话者的信息, 本文构建一幅有向图s={s,s,s}来建模对话文本中基于说话者的信息流动。
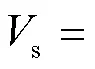
与话语结构感知图d的计算方式相同, 最终得到融合了说话者角色感知信息的特征向量s=(N+1)×Dim。
1.3.3 问题–上下文感知图
为了设计问题与对话文本之间的交互, 本文对Molweni 数据集中明确提到说话者的问题比例进行统计, 结果如表 1 所示。可以看出, 在训练集、验证集和测试集上均有超过 50%的问题明确提及说话者。本文构建一幅有向图q= {q,q,q}, 对问题信息和上下文信息进行结构化建模。
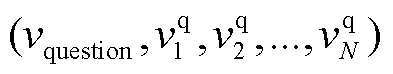
2)边: 本文以question作为根节点, 首先建立一条根节点上的自回路question→question来加强问题文本自身间的交互。然后, 对于问题中提及的说话者S, 从节点question向所属该说话者的话语节点建立有向边, 符号化表示为question→v,question→v,S= S=S, 从而形成边集合q。
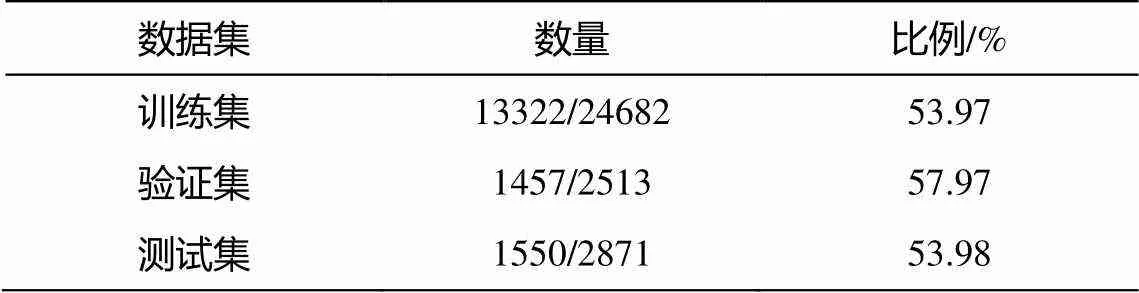
表1 Molweni数据集中提及说话者的问题统计
3)边权重: 受 Skianis 等[20]启发, 本文采用角度相似度为边赋予权重:
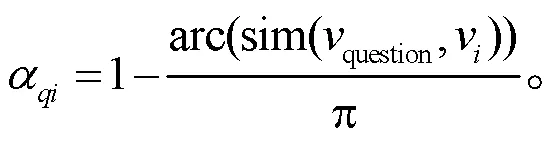
本文使用两个图卷积层, 得到融合了问题–上下文交互信息的特征向量q=(N+1)×Dim, 计算方式 如下:
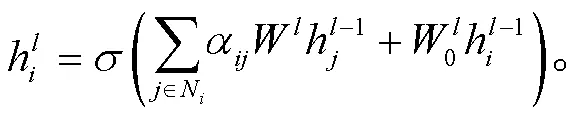
1.4 信息交互层
为了在字符级信息中融入话语级信息, 同时对卷积后的话语级信息中的重要线索进行筛选, 本文模型引入注意力机制。首先通过式(6), 计算得到每个字符位置上对各话语的关注度, 然后通过式(7),根据关注度的不同, 在话语级特征表示中进行重要信息筛选:

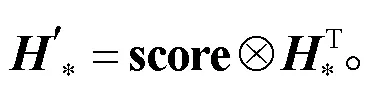
1.5 答案预测层
对 2.4 节得到的 3 个分层次的字符级特征向量进行拼接, 通过融合多方信息, 得到对多方对话文本具有深层次理解的特征表示。使用一个线性全连接层, 对特征向量进行映射, 使其映射后的维度代表模型预测的答案区间。此外, 使用交叉熵作为目标函数进行训练, 计算方式如下:
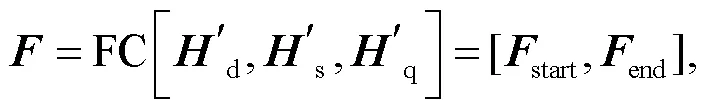


其中, FC 表示线性全连接层, […]表示向量拼接。
2 实验设置
2.1 数据集
Molweni 是在 Ubuntu Chat Corpus 语料[21]上众包产生的多方对话数据集, 可同时用于对话解析和机器阅读理解研究。Molweni 中, 对包含 86042 条话语的 9754 组对话进行标注, 产生总计 30066 个问题和 78245 个话语关系的数据集, 具体划分细节如表 2 所示。平均每组对话包含来自 3.51 个说话者的8.82 条话语。Molweni 数据集具有恰当的平均话语长度, 包含说话者和所说内容的独立话语单元, 并且话语之间具有显式结构关系。因此, 本文将 Mol-weni 作为理想基准数据集。
2.2 参数设置
本文针对基线模型, 设置多组超参数进行实验。选择在开发集上表现最优的超参数组合作为基线模型的超参数, 如表 3 所示。评估指标为精确匹配率 EM 和模糊匹配率 Macro-F1。本文使用的BERT 基线模型为 BERT-base-uncased, 隐藏层大小Dim 为 768, 包含 12 个编码层和 12 头注意力机制。
2.3 基准模型
为了验证本文模型的有效性, 实验中选取以下对比方法。
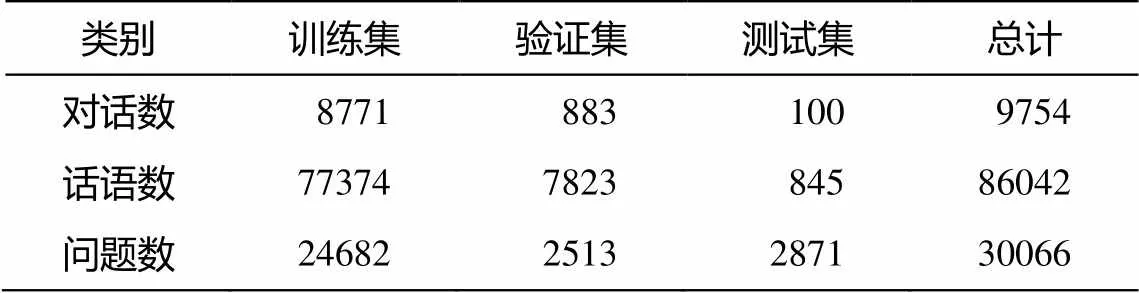
表2 Molweni数据集概览
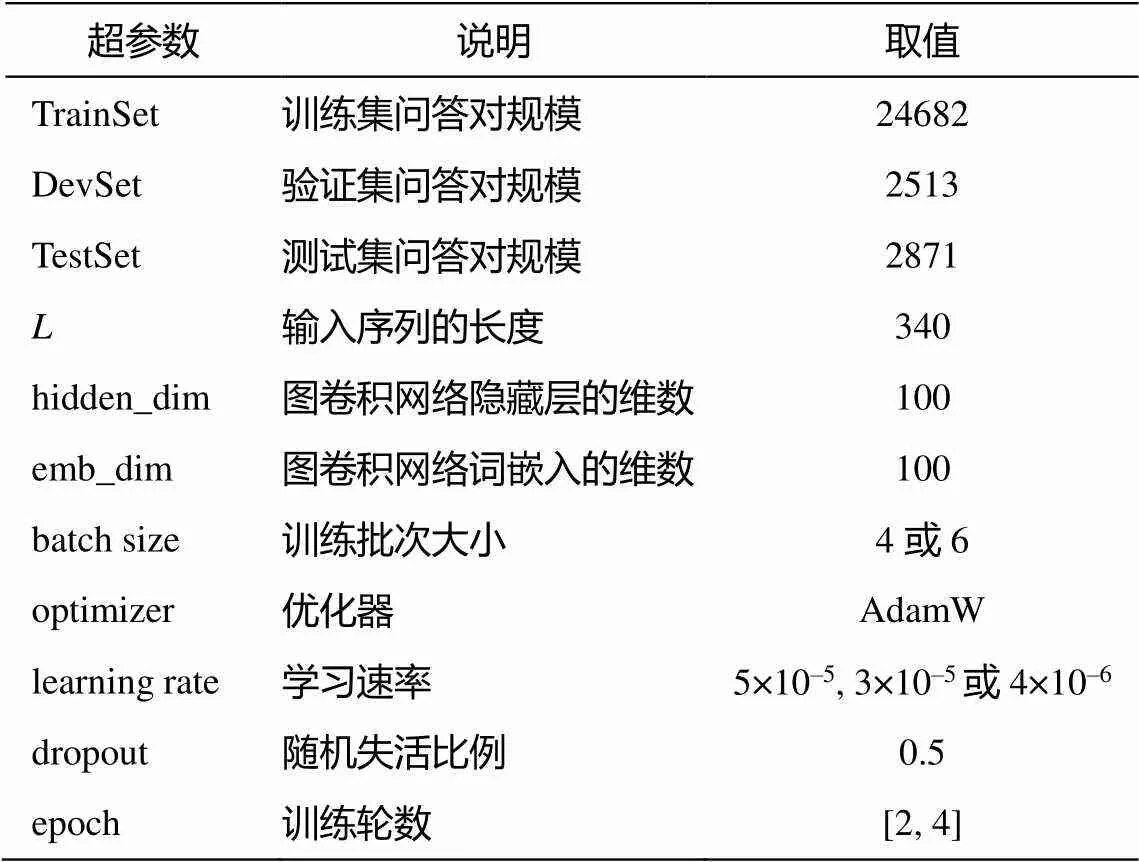
表3 参数说明
BERT[11]: 一种基于 Transformer 结构的双向编码器。为了更好地学习上下文表示, BERT 的预训练采用两个子任务: 掩码语言建模和下一句预测任务。遵循 Li 等[6]的设置, 本文将 BERT 作为基线模型。
SA-BERT[10]: 一种具有说话者角色感知信息的BERT 模型。本文对 SA-BERT 方法进行调整, 只在BERT 的词向量嵌入部分添加用来标志说话者角色的额外信息, 用以捕捉话语对应的说话者信息。
DialogueRNN[22]: 使用 3 个 GRU 对话语中说话者状态、全局上下文和情绪状态进行跟踪。
DialogueGCN[23]: 是一种基于图的神经网络模型, 通过捕捉基于说话者的自我感知和说话者间的依赖关系来理解对话上下文。
MDFN[15]: 利用 Transformer 中的掩码机制, 获得对话文本中的话语感知和说话者感知信息。本文对该方法进行调整, 使其适用于多方对话文本。
DADgraph[24]: 是 DialogueGCN 结构的变体。不同的是, DADgraph 利用图卷积神经网络来捕捉对话文本中的特定话语结构信息。
MTL model[9]: 一个在多方对话文本上联合执行 QA 任务和话语解析任务的多任务学习框架。
3 实验结果
3.1 对比实验结果
本文实验在 Molweni 数据集上与 7 个基线模型进行对比, 结果如表 4 所示, 可以看出, 本文提出的 Dis-QueGCN 模型在 F1 和 EM 上分别达到 63.6%和 47.7%的性能, 优于 7 个基线模型。
DialogueGCN, DialogueRNN, SA-BERT 和MDFN未考虑对话文本的话语结构信息。其中 Dialogue-GCN 和 SA-BERT 只关注对话文本的相关说话者特性, DialogueRNN 只关注到文本的时间序列信 息, 而 MDFN 在字符级信息上同时考虑了说话者感知和话语感知, 因而比前三者表现稍好。尽管DADgraph 和 Multi-task 分别通过关系图卷积和多任务框架捕捉到话语结构信息, 但未关注话语的说话者特性。另外, 7 个基线模型的关注点集中在如何理解对话文本上, 忽视了对问题文本的理解, 且未过多关注问题文本和对话文本的交互。因此, 本文提出的模型表现优于基线模型。
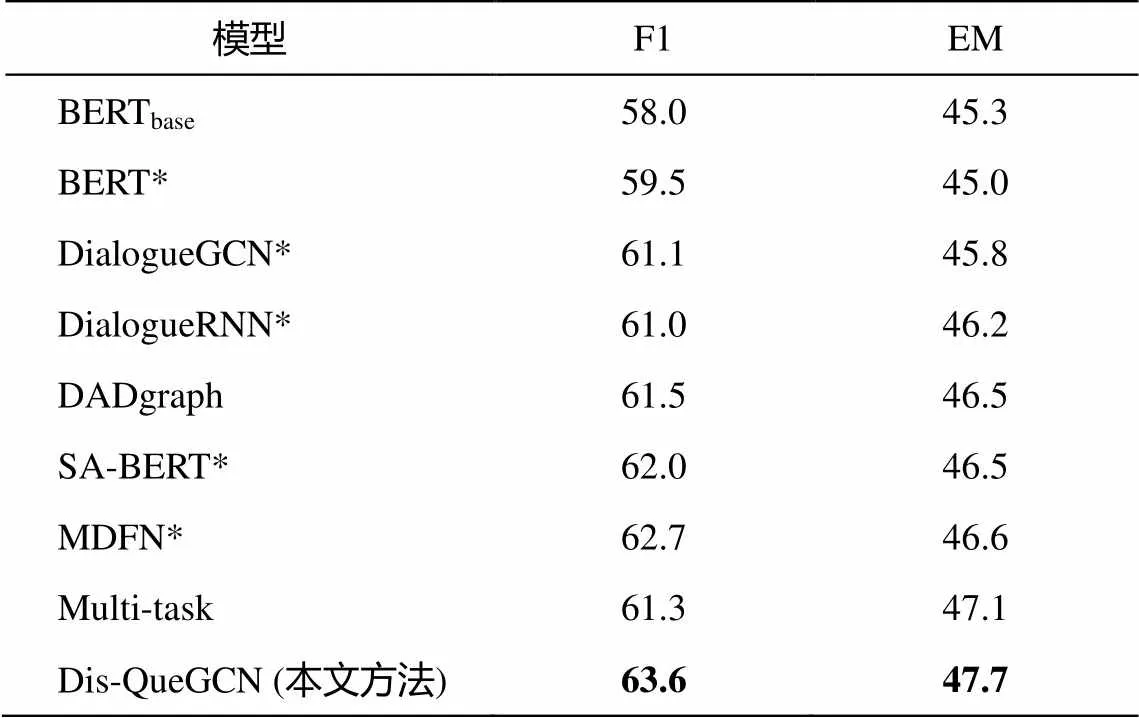
表4 在Molweni测试集上的实验结果(%)
注: *表示是基于本文的数据集和参数设置重新做的实验。除SA-BERT外, 本文对DialogueRNN, DialogueGCN和MDFN的处理均是用其替换“对话理解层”模块, 其他模块不做改动。
3.2 消融实验结果分析
为了进一步说明本文模型的有效性, 我们分别通过一次去掉或添加对话理解层中的一个组件进行消融实验 1 和 2, 其他 3 个模块的设置不变, 结果如表 5 所示。说话者角色感知图主要加强了来自同一说话者的话语之间的信息交互, 推测由于多方对话文本之间的信息流动大多存在于不同说话者之间, 因而该组件对多方对话文本理解的贡献最小, 去掉该组件后, 模型在 F1 和 EM 上的表现均下降 0.5%。消融实验 2 同样表明, 说话者角色感知信息仍对部分问题有一定的效果。如图 1 提到的对话示例, 模型需要关注到特定说话者“djjason”的话语才可解决问题。话语结构感知图使用图卷积网络对话语之间的结构关系进行建模, 作为多方对话文本中不可或缺的一部分, 去掉该组件后, 模型在 F1 和 EM 上的表现分别下降 0.6%和 1.0%。结果表明, 问题–上下文感知图对多方对话文本理解的贡献最大, 去掉该组件后, 模型在 F1 和 EM 上的表现分别下降 0.9%和 1.4%。
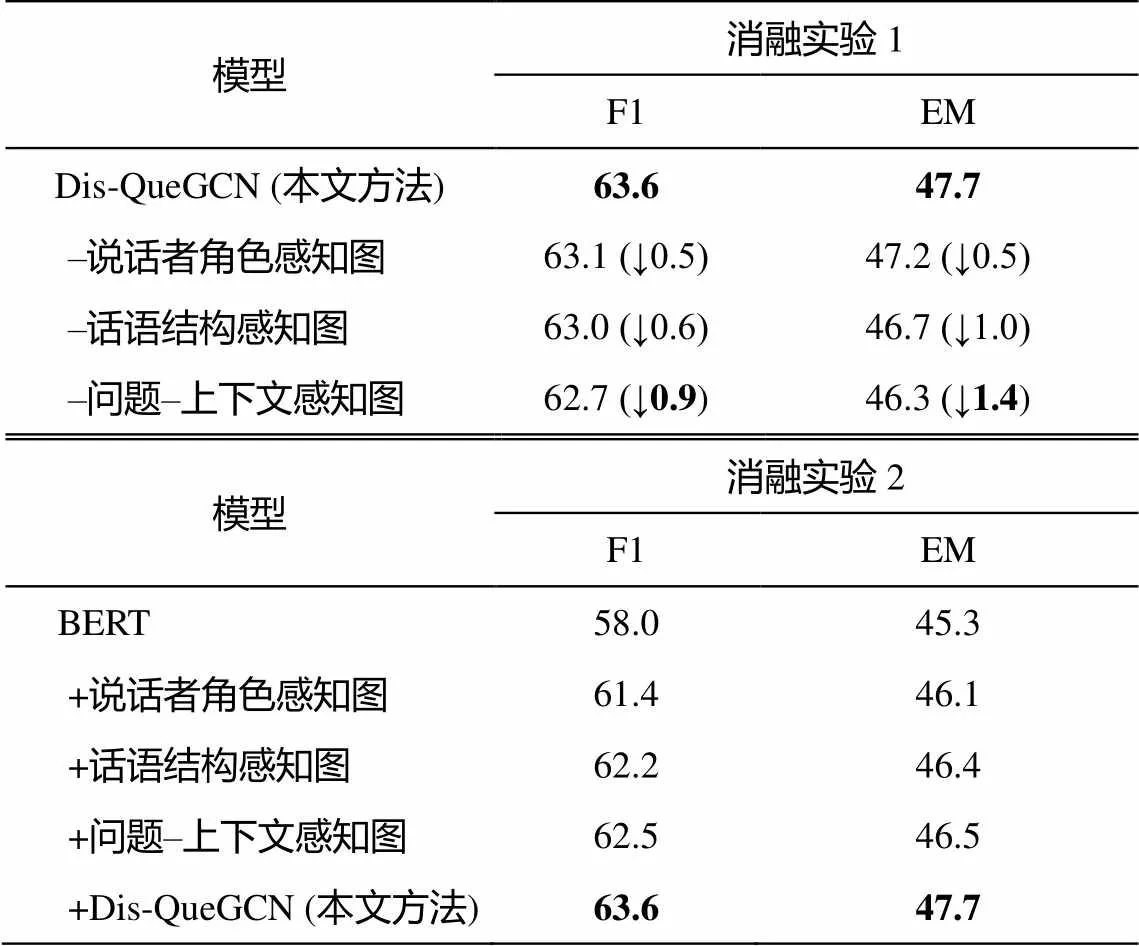
表5 消融实验1和2 (%)
消融实验 2 的结果直观地显示了对话理解层中单个组件的性能。为了更深层次地剖析单个组件带来性能提升的原因, 本文针对话语结构感知图和说话者角色感知图, 分别定义结构复杂度和基于说话者的话语密度两个指标。通过分析 BERT+说话者角色感知图和 BERT+话语结构感知图带来的 F1 值提升来说明两组件的有效性。为方便表示, 分别用组件 1 和组件 2 来表示 BERT+说话者角色感知图和BERT+话语结构感知图。两个指标定义如下:
基于说话者的话语密度
= 话语总量/说话者数量, (11)
结构复杂度 = 关系数量/话语总量。 (12)
由式(11)可知, 在说话者数量一定的情况下, 话语总量越多, 基于说话者的话语密度越高。对本文的说话者角色感知图来说, 基于说话者的话语密度越高, 表明图中各子节点通过卷积操作聚合到的信息越密集, 因此推测该指标越大, 与 BERT 基线模型相比, 组件 1 所带来的性能提升越大。
由式(12)可知, 在话语总量一定的情况下, 关系数量越多, 结构复杂度越高。本文的话语结构感知图组件对话语之间的结构关系进行显式建模, 因此推测话语结构复杂度越高, 相较于 BERT基线模型, 组件 2 带来的性能提升越大。
为了验证以上两个猜想, 本文对测试集数据的话语密度和结构复杂度进行统计, 根据区间取值和数据分布, 对两指标范围进行划分, 并分别评价组件 1 和组件 2 在各自不同的划分段带来的性能提升。如表 6 和 7 所示, 随着基于说话者的话语密度增大, 组件 1 所能聚合的信息较多, 所以性能提升较大。随着对话结构复杂度增大, 由于组件 2 对语句之间的结构信息进行显式建模, 所以带来的性能提升较大。由此验证了两个猜想, 也进一步说明了两个组件的有效性。
3.3 示例分析
为了直观地展示模型效果, 本文通过示例对BERT 基线模型和 Dis-QueGCN 的预测结果进行分析。对于图 3 中的问题, Dis-QueGCN 首先利用捕获到的问题–上下文感知信息, 将注意力放在 U4 上, 再利用 U4-U2 间的话语结构依赖关系, 解决“your”的指代问题。然后, 利用说话者角色感知图聚合的信息, 关注说话者“Bacon5o”的系列话语。最后, 依据 U5-U4 以及 U6-U5 之间的话语依赖关系给出答案预测。然而, BERT 未对以上信息进行显式建模, 错将问题判断为不可回答。因此, 本文提出的模型具有对多方对话文本更深入的理解能力。

表6 话语密度指标下组件1的性能提升

表7 结构复杂度指标下组件2的性能提升

波浪线和下划线分别表示Gold answer和Dis-QueGCN的回答
4 总结与展望
本文针对 QAMC 任务, 提出一个融合多方信息的问答模型 Dis-QueGCN, 从话语结构、说话者角色以及问题–上下文信息三方面对对话文本和问题文本进行分层次的理解, 并设计了合理的信息交互方式来进行信息筛选和传递。该方法首次在 QAMC任务中考虑了问题文本和对话文本的显式交互, 并利用图卷积神经网络, 对该交互信息进行建模。在 Molweni 数据集上与其他基线模型的对比实验表明, Dis-QueGCN 模型的 F1 和 EM 分别达到 63.6%和 47.7%, 优于基线模型。
目前, 本文方法侧重于使用显式的话语结构信息, 如何采用隐式的信息捕捉方式, 从而关注到对话中的隐含线索, 是未来工作的重点。
[1]Rajpurkar P, Zhang J, Lopyrev K, et al. SQuAD: 100,000+ questions for machine comprehension of text // Proceedings of the 2016 Conference on Empiri-cal Methods in Natural Language Processing. Austin, 2016: 2383–2392
[2]Rajpurkar P, Jia R, Liang P. Know what you don’t know: unanswerable questions for SQuAD // Procee-dings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Pa-pers). Melbourne, 2018: 784–789
[3]Zhang Y, Dai H, Kozareva Z, et al. Variational rea-soning for question answering with knowledge graph // Thirty-second AAAI conference on artificial intelli-gence. New Orleans, 2018: 6069–6076
[4]Lei J, Yu L, Bansal M, et al. TVQA: localized, com-positional video question answering // Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, 2018: 1369–1379
[5]Yang Z, Choi J D. FriendsQA: open-domain question answering on TV show transcripts // Proceedings of the 20th Annual SIGdial Meeting on Discourse and Dialogue. Stockholm, 2019: 188–197
[6]Li Jiaqi, Liu Ming, Kan Min-Yen, et al. Molweni: a challenge multiparty dialogues-based machine reading comprehension dataset with discourse structure // Pro-ceedings of the 28th International Conference on Computational Linguistics. Barcelona, 2020: 2642–2652
[7]Sun Kai, Yu Dian, Chen Jianshu, et al. Dream: a challenge dataset and models for dialogue-based rea-ding comprehension. Transactions of the Association for Computational Linguistics, 2019, 7: 217–231
[8]Cui Leyang, Wu Yu, Liu Shujie, et al. MuTual: a dataset for multi-turn dialogue reasoning // Procee-dings of the 58th Annual Meeting of the Association for Computational Linguistics. Online Meeting, 2020: 1406–1416
[9]Niu Yilin, Jiao Fangkai, Zhou Mantong, et al. A self-training method for machine reading comprehension with soft evidence extraction // Proceedings of the 58th Annual Meeting of the Association for Compu-tational Linguistics. Online Meeting, 2020: 3916–3927
[10]Perez E, Karamcheti S, Fergus R, et al. Finding generalizable evidence by learning to convince Q&A models // Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Hong Kong, 2019: 2402–2411
[11]Shi Zhouxing, Huang Minlie. A deep sequential model for discourse parsing on multi-party dialogues // Pro-ceedings of the AAAI Conference on Artificial Intelli-gence. Hawaii, 2019: 7007–7014
[12]He Yuchen, Zhang Zhuosheng, Zhao Hai. Multi-tas-king dialogue comprehension with discourse parsing // Proceedings of the 35th Pacific Asia Conference on Language, Information and Computation. Shanghai, 2021: 551–561
[13]Gu Jia chen, Li Tianda, Liu Quan, et al. Speaker-aware BERT for multi-turn response selection in retrieval-based chatbots // Proceedings of the 29th ACM International Conference on Information & Knowledge Management. Ireland, 2020: 2041–2044
[14]Liu Longxiang, Zhang Zhuosheng, Zhao Hai, et al. Filling the gap of utterance-aware and speaker-aware representation for multi-turn dialogue // The Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI-21). Online Meeting, 2021: 13406–13414
[15]Devlin J, Chang M, Lee K, et al. BERT: pre-training of deep bidirectional transformers for language un-derstanding // Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Techno-logies, Volume 1 (Long and Short Papers). Minnea-polis, 2019: 4171–4186
[16]Schlichtkrull M, Kipf T N, Bloem P, et al. Modeling relational data with graph convolutional networks // The Semantic Web ― 15th International Conference. Heraklion, 2018: 593–607
[17]Yang Zhilin, Dai Zihang, Yang Yiming, et al. XLNET: generalized autoregressive pretraining for language understanding // Advances in Neural Information Pro-cessing Systems. Vancouver, 2019: 5754–5764
[18]Liu Y, Ott M, Goyal N, et al. RoBERTa: a robus- tly optimized BERT pretraining approach [EB/OL]. (2019–07–26) [2022–04–27]. https://arxiv.org/abs/190 7.11692
[19]Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need // Advances in Neural Information Pro-cessing Systems. Long Beach, 2017: 5998–6008
[20]Skianis K, Malliaros F, Vazirgiannis M. Fusing docu-ment, collection and label graph-based representa-tions with word embeddings for text classification // Proceedings of the Twelfth Workshop on Graph-Based Methods for Natural Language Processing (TextGra-phs–12). New Orleans, 2018: 49–58
[21]Lowe R, Pow N, Serban I, et al. The ubuntu dialogue corpus: a large dataset for research in unstructured multi-turn dialogue systems // The 16th Annual Mee-ting of the Special Interest Group on Discourse and Dialogue. Prague, 2015: 285–294
[22]Majumder N, Poria S, Hazarika D, et al. Dialogue-RNN: an attentive RNN for emotion detection in conversations // Proceedings of the AAAI Conference on Artificial Intelligence. Hawaii, 2019: 6818–6825
[23]Ghosal D, Majumder N, Poria S, et al. DialogueGCN: a graph convolutional neural network for emotion recognition in conversation // Proceedings of the 2019 Conference on Empirical Methods in Natural Lan-guage Processing and the 9th International Joint Con-ference on Natural Language Processing. Hong Kong, 2019: 154–164
[24]Li Jiaqi, Liu Ming, Zheng Zihao, et al. DADgraph: a discourse-aware dialogue graph neural network for multiparty dialogue machine reading comprehension // International Joint Conference on Neural Networks. Shenzhen, 2021: 1–8
A Multi-information Perception Based Method for Question Answering in Multi-party Conversation
GAO Xiaoqian, ZHOU Xiabing†, ZHANG Min
School of Computer Science and Technology, Soochow University, Suzhou 215000; †Corresponding author, E-mail: zhouxiabing@suda.edu.cn
Question answering in multi-party conversation typically focuses on exploring discourse structures or speaker-aware information but ignores the interaction between questions and conversations. To solve this problem, a new model which integrates various information is proposed. In detail, to hierarchically model the discourse structures, speaker-aware dependency of interlocutors and question-context information, the proposed model leverages above information to propagate contextual information, by exploiting graph convolutional neural network. Besides, the model employs a reasonable interaction layer based on attention mechanism to enhance the understanding of multi-party conversations by selecting more helpful information. Furthermore, the model is the first to pay attention to the explicit interaction between question and context. The experimental results show that the model outperforms multiple baselines, illustrating that the model can understand the conversations more comprehensively.
multi-party in conversation; question answering; graph convolutional network; attention mechanism
猜你喜欢
能源工程(2022年2期)2022-05-23 13:51:50
高技术通讯(2021年3期)2021-06-09 06:57:46
河北画报(2021年2期)2021-05-25 02:07:18
科学(2020年5期)2020-11-26 08:19:14
重型机械(2020年2期)2020-07-24 08:16:16
装备制造技术(2019年12期)2019-12-25 03:07:36
舰船电子对抗(2016年5期)2016-12-13 08:41:14
太阳能(2015年11期)2015-04-10 12:53:04
浙江人大(2014年6期)2014-03-20 16:20:34
浙江人大(2014年5期)2014-03-20 16:20:20
