
多模态与文本预训练模型的文本嵌入差异研究
2023-02-10 06:31:40孙宇冲程曦苇宋睿华车万翔卢志武3文继荣
北京大学学报(自然科学版) 2023年1期
孙宇冲 程曦苇 宋睿华,3,† 车万翔 卢志武,3文继荣,3
北京大学学报(自然科学版) 第59卷 第1期 2023年1月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 59, No. 1 (Jan. 2023)
10.13209/j.0479-8023.2022.074
北京高校卓越青年科学家计划(BJJWZYJH012019100020098)资助
2022-05-13;
2022-08-18
多模态与文本预训练模型的文本嵌入差异研究
孙宇冲1程曦苇2宋睿华1,3,†车万翔4卢志武1,3文继荣1,3
1.中国人民大学高瓴人工智能学院, 北京 100872; 2.中国人民大学统计学院, 北京 100872; 3.北京智源人工智能研究院, 北京 100084; 4.哈尔滨工业大学计算学部, 哈尔滨 150001; †通信作者, E-mail: rsong@ruc.edu.cn
为了详细地分析文本单模态预训练模型 RoBERTa 和图文多模态预训练模型 WenLan 文本嵌入的差异, 提出两种定量比较方法, 即在任一空间中, 使用距离一个词最近的近邻词集合表示其语义, 进而通过集合间的 Jaccard 相似度来分析两个空间中词的语义变化; 将每个词与其近邻词组成词对, 分析词对之间的关系。实验结果表明, 图文多模态预训练为更抽象的词(如成功和爱情等)带来更多的语义变化, 可以更好地区分反义词, 发现更多的上下义词, 而文本单模态预训练模型更擅长发现同义词。另外, 图文多模态预训练模型能够建立更广泛的词之间的相关关系。
多模态预训练; 文本表示; 文本嵌入分析
随着预训练模型(如 BERT[1], GPT[2–3]和 RoBE-RTa[4]等)在诸多自然语言处理(NLP)任务中取得巨大成功, 研究人员将预训练的技术拓展到多模态领域, 并在图文检索、图像描述和文本到图像生成等多项跨模态任务中取得领先的效果[5–8]。CLIP[6]和WenLan[8]这两种使用对比学习方法, 在大规模的图像–文本数据对上进行训练, 将文本和图像分别编码, 并在同一语义空间将其对齐。以往的研究主要关注提升多模态预训练模型在下游任务中的表现, 很少分析多模态数据给文本嵌入带来的变化。如果把单模态文本预训练视为通过“读书”来达到对文字的理解, 那么多模态预训练则更像人类通过看和听或写来达到对文字的认识。研究这两种预训练方式对文本嵌入的影响, 对探索人类大脑的编码方式具有启发意义, 也会为更好地利用多模态信息提供有价值的依据。
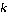
1 相关工作
1.1 单模态文本嵌入
分布式假说认为, 出现在相似上下文中的词具有相似的语义[9–10]。基于这一假说, 早期的词表示模型通过降维算法, 将词共现矩阵变换为语义向 量[11], 使词的语义关系可以通过其在语义空间中用向量表示的距离来体现。Word2Vec 通过基于上下文窗口的词预测任务来学习词的密集向量表示[12]。GloVe 词向量通过语料中词共现的全局统计信息来学习词表示[13]。上述方法将一个词表示为固定的向量, 无法解决一词多义问题。基于上下文的语言模型使用上下文信息动态地表示词。例如, ELMO使用在大量语料上训练得到的基于双向 LSTM (长短期记忆递归神经网络)的语言模型来提取基于上下文的词表示[14]。基于 Transformer[15]的大规模预训练语言模型, 能够学到更丰富的语义信息, 在多项NLP任务中取得最佳效果[1–3]。
尽管单模态的词表示获得很大的成功, 但该方法仅通过词在语料中的共现关系来学习语义。这与人类学习语言的方式有很大的不同, 人在学习语言的过程中往往融入多模态的感知信息。
1.2 多模态文本嵌入
有研究尝试将感知信息融入词表示中。一种方式是使用人工构建的词属性数据(例如苹果–可食用, 轮胎–圆形的)来修正词表示[16–17]。这些数据集规模有限, 只包含显著的属性。另一种方式是直接用多模态数据学习词表示。这类研究大部分聚焦于视觉模态, 因为视觉模态是人类学习语言时最主要的感知信息来源[18]。Bruni 等[19]将图像中的“视觉单词”[20]与文本中的词相联系, 证明在词关联性和词聚类任务中, 多模态语义表示具有更好的效果。Kottur 等[21]将“词袋模型”扩展到预测视觉特征任务中。Xu 等[22]通过最大化图像特征和对应词向量的相似度来学习多模态词表示。Gupta 等[23]使用图像数据集标注的视觉共现关系来提升 GloVe 词向量。
近期, 预训练也被用于视觉和语言的联合学习[5–8,24–25]。早期的研究使用跨模态的 Transformer编码器来表示图像和文本[5,24], 这类模型(又称为单塔模型或单流模型)为需要强模态交互的下游任务设计。一些研究使用对比学习, 在一个多模态空间中将文本特征和图像特征对齐[6,8,25], 这些模型(又称双塔模型或双流模型)一般具有独立的图像编码器和文本编码器, 其中的文本编码器可用于提取文本表示。
预训练的视觉+语言模型在很多跨模态的下游任务(如图文检索、图像描述和文本生成图像等)中取得很好的效果[4–8]。
1.3 词表示评价
评价词表示质量的方法有两种: 内部评价法和外部评价法[26–27]。内部评价法关注词表示的语义关系, 外部评价法关注将词表示应用于下游任务的效果。
内部评价法一种内部评价方法是通过计算模型预测的词对相似度与人工标注的词对相似度之间的 Spearman 相关系数来评价[28], 常用的评测数据包括 MEN[19], SIMLEX-999[29]和 SimVerb-3500[26]。但是, 由于人工评测的主观性以及相关程度定义不清晰, 这种方法受到质疑[30]。另一种方法是使用词聚类, 将词分成几个集合[28], BM[31]和 AP[32]是常用的用于聚类评价的数据集。除使用人工标注的数据外, 还有一些方法使用神经激活模式来评价词表示, 但这些激活模式并不总与词义相关[33]。
外部评价法一些 NLP 任务可以用来评价词表示的能力, 在下游任务中表现好的词表示被认为有更好的质量[27]。常用来评价词表示的 NLP 任务有词性标注、命名实体识别、情感分析和文本分类 等[34]。在不同的下游任务中, 词表示的表现并不总是正相关, 因此外部评测法并不适合作为一种通用的词表示质量度量[35]。
2 研究方法
2.1 训练模型选取
预训练模型 BERT 使用堆叠的 Transformer 编码器结构, 模型输入是两句拼在一起的文本, 它使用两个预训练任务: 1)掩码语言模型, 基于上下文预测被遮蔽掉的单词; 2)句子关系预测, 预测两个句子是否相连。RoBERTa 是 BERT 模型的改进版本, 使用更多的训练语料, 并训练了更长的时间。本文使用中文版 RoBERTa[36], 它使用 RoBERTa 的训练策略, 并结合全词遮蔽策略的优点。全词遮蔽指属于同一个汉语词中的汉字都会被遮蔽掉。因为 RoBERTa-base 被用作 WenLan 的文本骨干网络, 因此本文使用中文版 RoBERTa-base。为了减少因训练数据不同造成的差异, 我们使用 WenLan 训练数据的文本部分(约 2200 万条数据), 以 1×10–5的学习率, 使用掩码语言模型对它进行一轮微调, 得到的模型记为 RoBERTa-ft。
我们选取 WenLan 作为图文预训练的模型进行分析, 图 1 展示 WenLan 的基本结构。
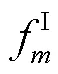
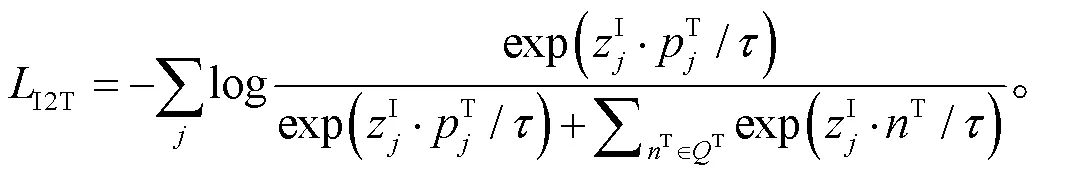
其中,T为存储在T中的负样本,为温度系数。
类似地, 文到图的对比学习损失为
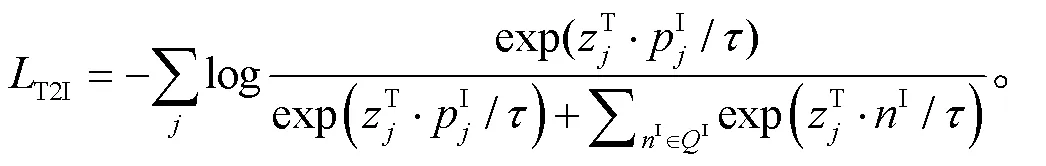
其中,I为存储在I中的负样本。总的损失为=T2I+I2T。
本文使用 WenLan 的文本编码器提取多模态的词表示, 使用 RoBERTa-ft 提取单模态的词表示, 将词表示为两组高维向量, 构成两个文本嵌入空间, 然后在每个空间中分别计算所有词对的余弦相似度。图 2 展示两个空间中词对相似度的分布。可以看到, RoBERTa-ft 和 WenLan 对应的文本嵌入空间中, 词对的平均相似度分别为 0.87 和 0.66, 不能直接比较相似度的数值; 两个空间中词对的相似度分布也明显不同, WenLan 对应的相似度分布近似正态分布, 而 RoBERTa-ft 对应的相似度分布略左偏, 因此, 即使将相似度都标准化, 也不能相互比较。
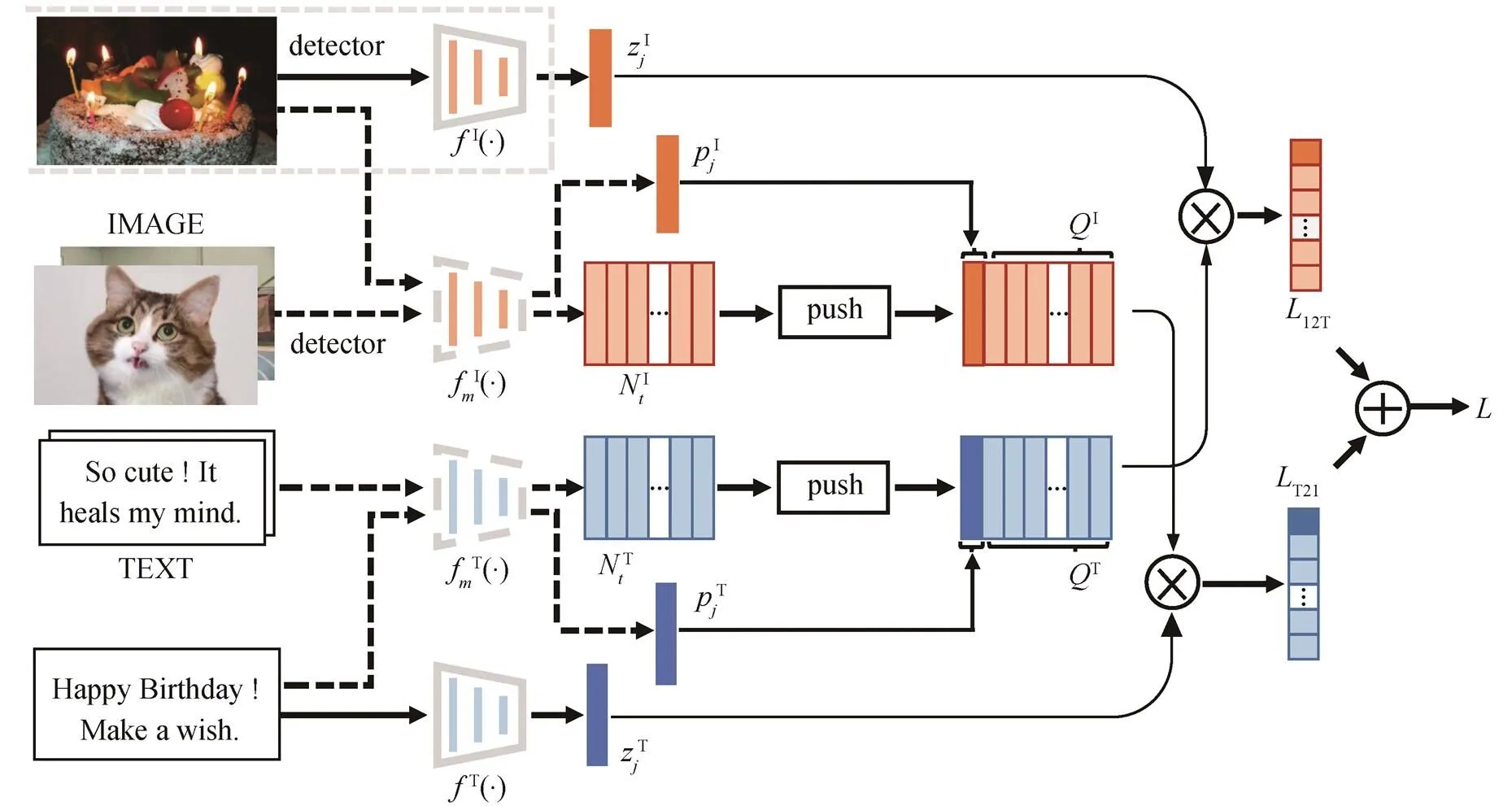
图1 WenLan模型结构[8]

图2 两个空间中词对相似性分布
2.2 基于k-近邻的模型比较方法
预训练的目的是使模型学到的特征在高维空间有更好的分布, 使空间中一些词的距离更近, 另外一些词的距离更远。从语义的角度来看, 高维空间中与某一词邻近的词应当具有揭示该词含义的能力。据此, 本文提出一种基于-近邻的方法来比较两个模型的文本嵌入, 包含如下两个步骤。
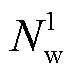
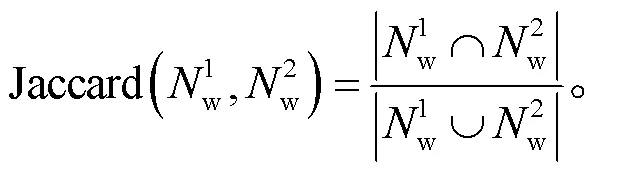
杰卡德相似度的取值范围为[0, 1], 在两个文本嵌入空间中, 词 w 的语义变化越小, 杰卡德相似度越趋近1。
2)为了衡量词对间关系的变化, 需要从文本嵌入空间提取词对。在文本嵌入空间中, 距离词w最近其个词{1,2, …,v}构成词对。例如, “体育–赢球”、“体育–篮球运动”和“体育–国际裁判”等是WenLan文本嵌入空间里构成的词对。
3 实验设计与结果分析
3.1 单个词表示变化规律实验
我们使用Jieba分词工具包①https://github.com/fxsjy/jieba对WenLan的文本训练数据进行分词, 最终保留在全部数据中出现次数超过50次的词, 形成长度为288000的词表。使用预训练的模型抽取词表示, 构成文本嵌入空间。
3.1.1 单个词表示变化实验设计与结果
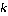
从图3可以看出, 对于分析组, 即WenLan v.s. RoBERTa-ft, 直方图中频数峰值位于(0.05, 0.07), 呈右偏分布, 大部分词对应的杰卡德相似度低于0.2。对于对照组, 即RoBERTa-ft v.s. RoBERTa, 相似度分布近似一个峰值为0.4的钟形。需要注意的是, 我们仅使用WenLan图文数据集中文字部分对RoBERTa微调, RoBERTa与RoBERTa-ft 结果的不同主要来自新增数据。WenLan与RoBERTa-ft使用相同的文本数据, 此外还使用相应的图像数据做预训练。最终分布呈现出较大差异, 说明图像信息在表示学习的过程中发挥出显著的作用。
3.1.2 变化规律实验与结果
本文基于词性(part of speech, POS), 分类统计两个空间中词表示的变化。对于普通名词、动词、人名、地名、数词、形容词、组织名称、时间词、代词、方位词和数量词这11类词性类别, 分别计算各类词的平均杰卡德相似度, 在分析组和对照组之间没有观察到明显的区别。通过观察词表示在两个空间发生较大变化的多个实例, 发现其中大部分是语义抽象的词; 相反, 很多语义具象的词则在两个空间中变化较小。因此, 我们猜想多模态预训练对于词语语义的影响与词语的具象/抽象程度相关。
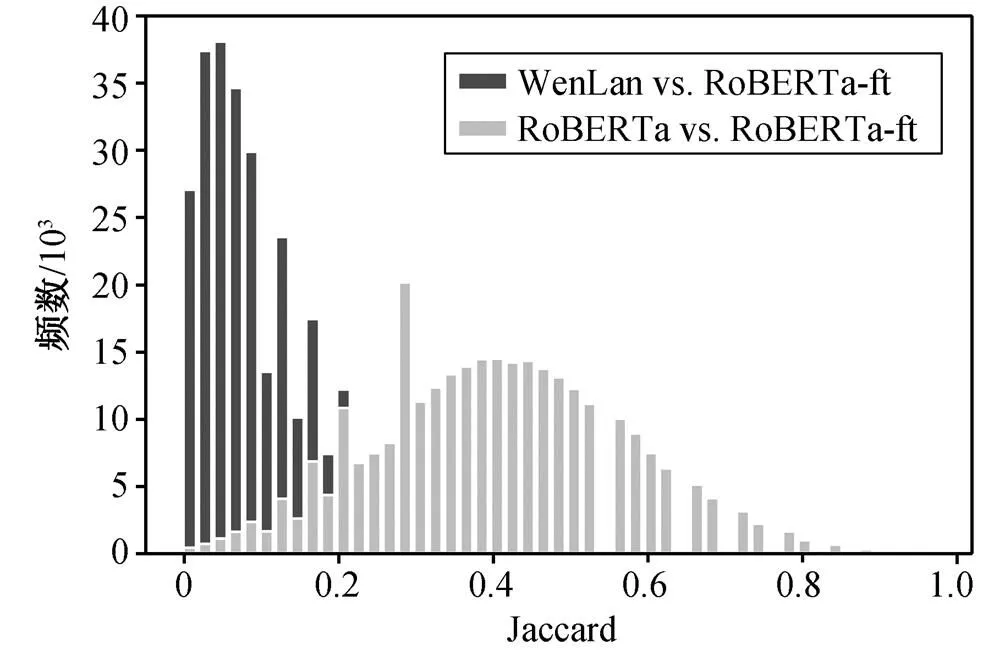
图3 词语义变化图
Brysbaert等[39]对单词的具象度进行细致的定义, 并使用人工标注的方法, 完成一个高质量的数据集。该数据集主要包含英文名词、动词和形容词, 每个单词由多名标注者根据具象程度打分(1~ 5), 1分表示最为抽象, 5分则表示最为具象。通过 对多个标注得分取平均, 得到最终具象度(Concre-teness), 它是一个[1, 5]区间的实数。由于本文比较的模型均采用中文训练, 因此将该标注数据集中的英文词翻译为中文词, 取最常用词义, 与中文词表相交, 最终获得26000个词。
表1列举一些在WenLan和RoBERTa-ft文本嵌入空间中距离最近的词。可以看出, 更具象的词在两个模型得到的重合词更多, 而抽象词所得的重合词更少。我们将具体度得分以0.5分的间隔划分区间, 对得分区间内的所有词对应杰卡德相似度求平均, 统计结果如图4所示。横轴表示词的具体度, 纵轴表示相对杰卡德相似度(以1.0~1.5区间的相似度为基准)。可以看出, 对于分析组, 随着词具体度得分上升, 相似度也明显上升。对于对照组, 相似度则未发现明显上升趋势。相关性检验结果表明, 分析组的相关系数约为0.32, 而对照组的相关系数为0.07。因此, 多模态预训练为抽象词带来更多的语义变化, 越抽象的词, 语义变化越大。
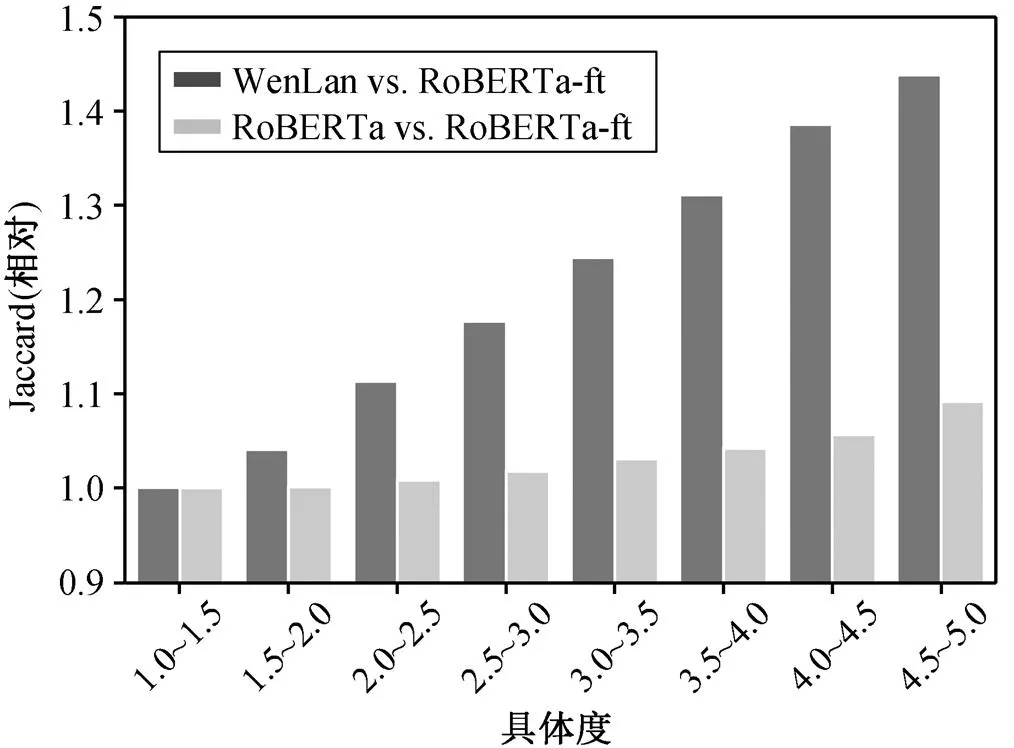
图4 词语义变化与词具体度的关系
3.2 词与词之间关系变化规律实验
3.2.1 利用已有标注研究词与词之间的关系
我们选择广泛应用的蕴含丰富的关系种类的大规模知识图谱ConceptNet[40]。为了确认WenLan能否发现更多视觉相关词对, 我们还选择拥有丰富物体及属性标签的 Visual Genome数据集[41]和拥有图片级标签的 ImageNet 数据集[42]作为有标注数据集, 用来匹配词对之间的视觉关系。
ConceptNet 中含 386000 种中文概念关系。剔除不被词表包含、拥有数据记录过少及记录涵盖过多噪声的概念关系后, 共有 10 种概念关系被保留, 如表 2 所示。这 10 种关系中包含如同义词、反义词和“是”(上位词)这些基本类型的关系, 以及如“被用于”、“导致某种结果”和混合多种类型的“其他相关”(除上述类型外的相关)这些高级类型的关系。对于 Visual Genome 和 ImageNet, 受 Vaswani 等[15]的启发, 我们主要考虑两种视觉关系。1)视觉语境(或视觉共现)关系: 与文本中的语境类似, 我们将出现于同一图像中的物体定义为该图的语境, 曾多次共同出现在同一语境的物体对被认为有视觉语境关系, 比如, 耳朵和头饰。2)物体–上位词关系: 对图像中物体, 取 WordNet[43]中该物体的上位词, 形成物体–上位词关系的标注数据。与 ConceptNet 的处理方法一致, 我们剔除词表中不包含的词所涉及的词对。
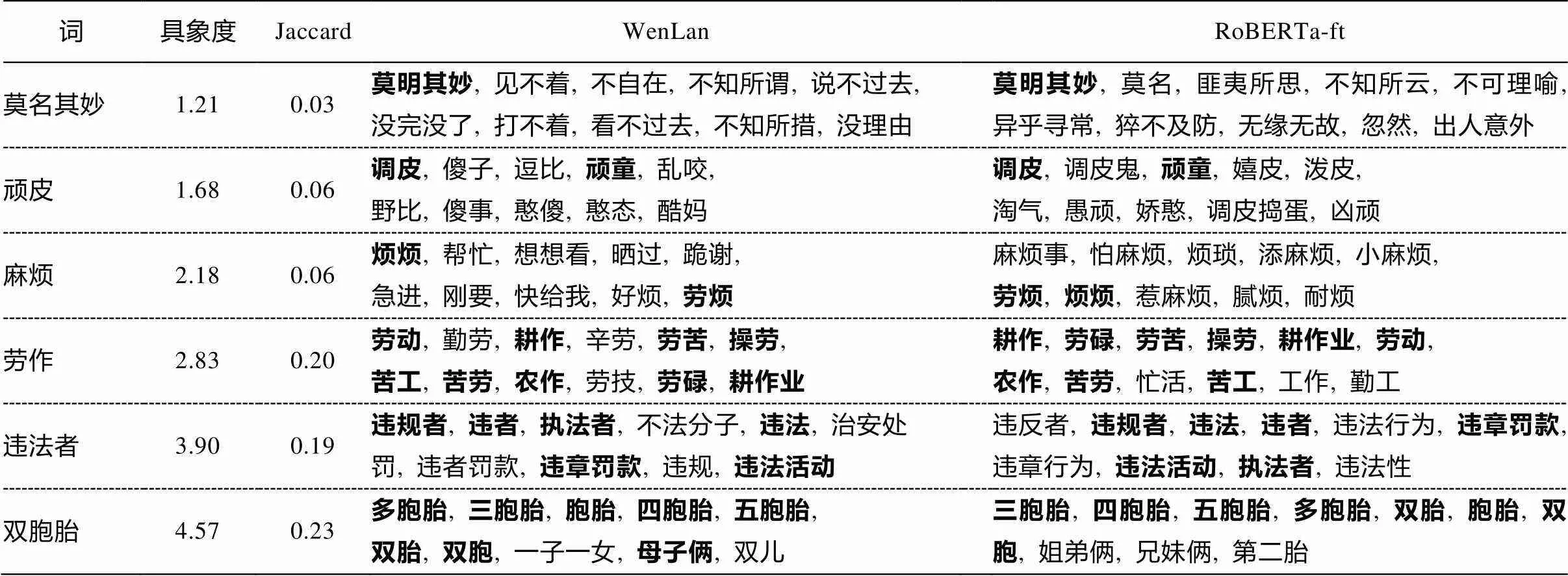
表1 单个词在两个文本嵌入空间的语义变化举例
说明: 粗体字为重合词。
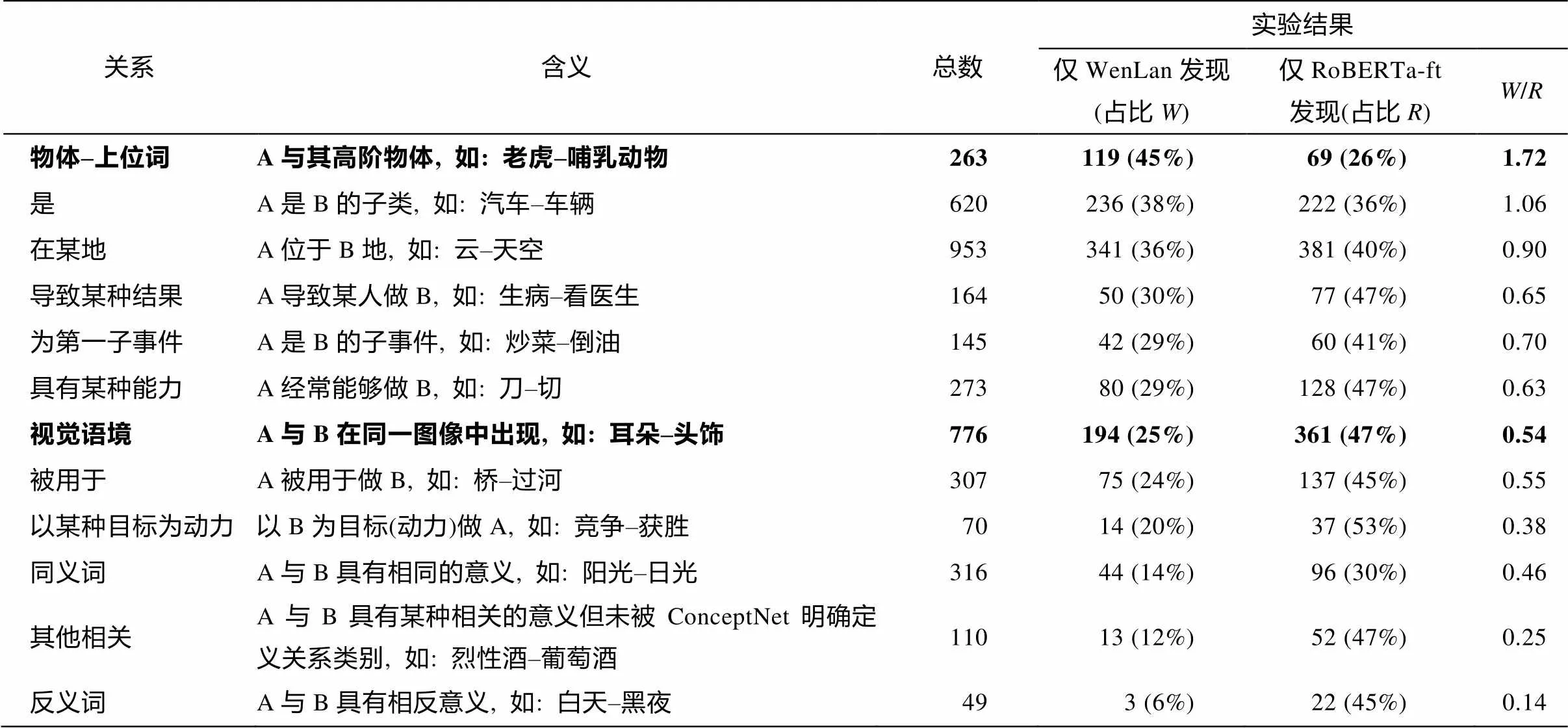
表2 两个空间挖掘出的词对与现有数据集中关系类型匹配的统计结果
说明: 总数是两种空间挖掘到的具有该种关系类型的词对并集大小; 表2数据以占比降序排列; 粗体字表示来自视觉数据集, 其余来自ConceptNet数据集。
对每一个词, 分别通过 WenLan 和 RoBERTa-ft获得邻近词对集(=50), 对出现在标注数据集中的词对, 记录其关系类型, 统计结果见表2。我们用与的比值来表示哪种模型在挖掘一种关系类型时更具优势。
根据表2, 与单模态RoBERTa-ft模型相比, 多模态WenLan模型更擅长发现上下位词关系(不论是来自视觉数据集的“物体–上位词”关系, 还是来自ConceptNet 的“是”关系)。除少量知识介绍类文本外, 人们在文字中提到一个名词时, 通常不会赘述它们属于哪个上位类别或包括哪些下位词。例如, 在讲武松打虎的故事时, 通常不会插入“老虎是一种哺乳动物”这样的常识性文字。但是散落在互联网的图像–文本数据对中, 一张老虎的图片可能常被用作展示老虎相关的文字内容, 也可能在描述抽象的哺乳动物时作为一个实例出现。“老虎”和“哺乳动物”不必同时出现在一段文字里, 而通过老虎图像和对比学习的优化目标, 这两个词表示逐渐与老虎的视觉表示靠近, 因此它们因在WenLen空间中的距离相近而被挖掘出。
表2最后一行表明, 仅RoBERTa-ft发现的反义词对数量是仅WenLan发现的7倍。但是, 由于文本上下文相似, 从Word2Vec到BERT(包括RoBE-RTa-ft在内), 这些单模态模型普遍会使“成功–失败”这类反义词具有距离相近的表示向量。令人惊讶的是, 在融合视觉信息后, 这种情况获得明显的改善。
如图5所示, 以反义词“成功–失败”为例, 在RoBERTa-ft对应的单模态文本嵌入空间中有一簇与“失败”相近的词(如“挫败”、“颓败”和“溃败”), 距离“成功”不远。在WenLan对应的多模态文本嵌入空间中, 其距离被大大拉远, 未进入前50的近邻。研究训练数据集发现, “成功”和“失败”在文本中出现时, 上下文是相似的。与文本不同, 周围文字带有“成功”的图像中, 大多色彩明亮, 并且具有积极的情感表达(如微笑); 周围文字中带有“失败”的图像中, 大多色调阴暗, 且具有消极的情感表达。视觉信息上的差异使WenLan通过对比学习, 增大了“成功–失败”这对词在多模态特征空间中的距离。这表明, 多模态WenLan模型具有能够拉远反义词之间距离的优势。
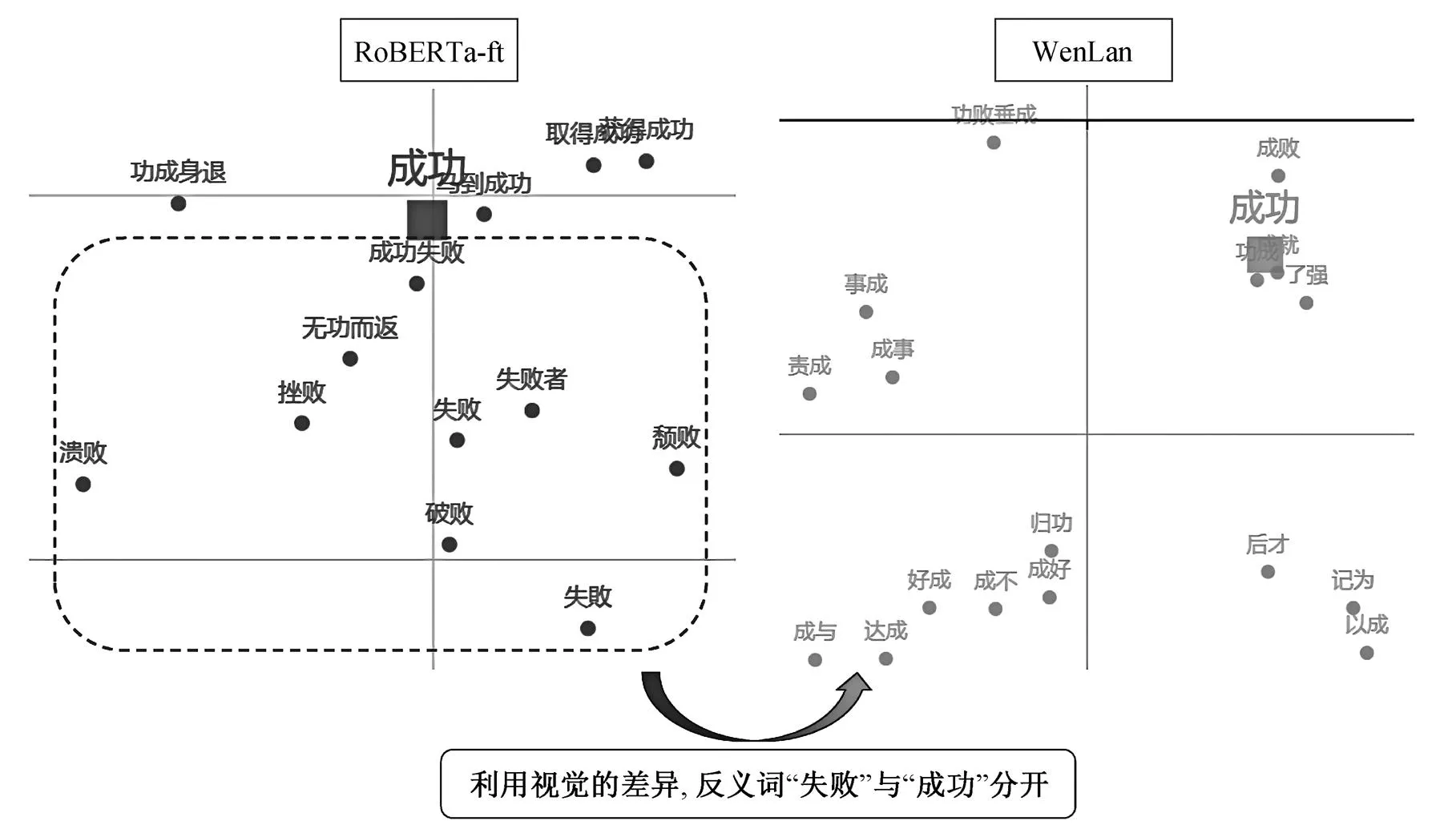
图5 “成功”在两个空间中周围的词
综上所述, 可以得出以下结论。
1)文本单模态模型RoBERTa-ft更擅长发现同义词对。“出现在相似上下文中的词具有相似的语义”这一假设对同义词非常有效, 与仅WenLan发现相比, 仅RoBERTa-ft发现能贡献两倍多的同义词。
2)RoBERTa-ft更擅长发现有逻辑关联的词对, 包括“导致某种结果”、“为第一子事件”、“具有某种能力”、“被用于”、“以某种目标为动力”和“其他相关”。这些关系更常见于文本, 较难用图像表达。越难以用图像表达的类别(如“以某种目标为动力”), RoBERTa-ft的贡献比例越高。
3)RoBERTa-ft可以发现大量视觉语境关系词对。虽然如“耳朵”和“头饰”这样的“视觉语境”类词对是由Visual Genome和ImageNet视觉数据集中出现在同一张图像中的物体构成, 我们原本猜想多模态模型会在这一类型上有优势, 但事实上, 单模态模型的贡献更多, 即47%比25%。这说明, 文字中也包含视觉场景的描写, 让人能够身临其境地理解作者想要描述的内容。当然, WenLan模型也贡献了相当多的视觉语境词对。
3.2.2 基于人工标注词对关系的实验
用已有标签的数据集与两个空间发现的近邻词对进行匹配, 仅少部分词对能够匹配成功, 大量新发现的词对之间的关系没有被标注。于是, 我们做了一个用户研究, 对抽样的词对进行人工标注。
标注4种类型后的统计结果如表3所示。我们分别计算4种关系的词对在从不同特征空间抽样而得词对中所占的比例, 并比较比例间的差异, 还对差异的显著性进行检验。统计结果表明, WenLan比RoBERTa-ft少发现35%的同义词对, 多发现7%的相关词对, 少发现47%的反义词对。这与表2中的两个事实一致: 文本单模态模型更擅长发现同义词对, 多模态模型可以改善反义词对在特征空间中距离过近的情况。此外, 与表2中“其他相关”的结果不同, 实验表明WenLan比RoBERTa-ft发现了更多的相关词对, 其中部分相关词对甚至未被Con-ceptNet, Visual Genome和ImageNet涵盖。

表3 两个空间挖掘出的词对与人工标注关系类型的统计结果
4 展望和总结
为了在文本模型 RoBERTa 与多模态模型 Wen-Lan 的词表示之间做出公平的有意义的比较, 本文采取-近邻的方法, 将距离一个词最近的个词构成集合, 使用集合来表示该词的语义; 将文本嵌入空间中每个词与其距离最近的个词构建成个词对, 进而研究词对间的关系。实验表明, WenLan改变了词义, 对越抽象的词, 改变越明显。视觉信息可以帮助 WenLan 建立更多的上下义联系, 发现更少的反义词; RoBERTa 则更倾向于发现同义词。
多模态信息的引入让文本表示发生改变, 因此下一步工作中拟探索将此变化更好地与文本预训练模型在监督学习上的优势相结合。另外, 图像和文本的强弱关系在很大程度上决定了多模态模型的特征空间特点, 但目前没有一个量化的方式可以刻画图文相关性的强度。我们计划构造一些强度渐变的图文数据集来探索数据集对多模态模型, 特别是文本表示方面的影响和规律。
致谢 研究工作得到北京智源人工智能研究院的算力支持, 在此表示衷心感谢。
[1]Devlin J, Chang M W, Lee K, et al. BERT: pre-training of deep bidirectional transformers for langua-ge understanding // Proceedings of NAACL-HLT. Min-neapolis, 2019: 4171–4186
[2]Radford A, Wu J, Child R, et al. Language models are unsupervised multitask learners [EB/OL]. (2019–02–14)[2022–04–15]. https://openai.com/blog/better-lang uage-models
[3]Radford A, Narasimhan K, Salimans T, et al. Im-proving language understanding by generative pre-training [EOB/OL]. (2018–06–11)[2022–04–15]. https:// openai.com/blog/language-unsupervised
[4]Liu Y, Ott M, Goyal N, et al. Roberta: a robust- ly optimized BERT pretraining approach [EB/OL]. (2019–07–26)[2022–04–15]. https://arxiv.org/abs/1907. 11692
[5]Li X, Yin X, Li C, et al. Oscar: object-semantics aligned pre-training for vision-language tasks // Pro-ceedings of ECCV. Cham, 2020: 121–137
[6]Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision // Proceedings of ICML. New York, 2021: 8748–8763
[7]Ramesh A, Pavlov M, Goh G, et al. Zero-shot text-to-image generation // Proceedings of ICML. New York, 2021: 8821–8831
[8]Huo Y, Zhang M, Liu G, et al. WenLan: bridging vision and language by large-scale multi-modal pre-training [EB/OL]. (2021–03–11)[2022–04–15]. https:// arxiv.org/abs/2103.06561
[9]Harris Z S. Distributional structure. Word, 1954, 10 (2/3): 146–162
[10]Firth J R. A synopsis of linguistic theory, 1930–1955 // Studies in Linguistic Analysis. Oxford: The Philolo-gical Society, 1957: 1–32
[11]Lund K, Burgess C. Producing high-dimensional semantic spaces from lexical co-occurrence. Behavior Research Methods, Instruments, & Computers, 1996, 28(2): 203–208
[12]Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space [EB/OL]. (2013–01–16)[2022–04–15]. https://arxiv.org/ abs/1301.3781
[13]Pennington J, Socher R, Manning C D. Glove: global vectors for word representation // Proceedings of EMNLP. Stroudsburg, 2014: 1532–1543
[14]Peters M E, Neumann M, Iyyer M, et al. Deep contextualized word representations // Proceedings of NAACL-HLT. Stroudsburg, 2018: 2227–2237
[15]Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need. Proceedings of Advances in Neural Information Processing Systems, 2017: 6000–6010
[16]McRae K, Cree G S, Seidenberg M S, et al. Semantic feature production norms for a large set of living and nonliving things. Behavior Research Methods, 2005, 37(4): 547–559
[17]Silberer C, Ferrari V, Lapata M. Models of semantic representation with visual attributes // Proceedings of ACL. Stroudsburg, 2013: 572–582
[18]Regier T. The human semantic potential: spatial language and constrained connectionism. Cambridge: MIT Press, 1996
[19]Bruni E, Tran N K, Baroni M. Multimodal distribu-tional semantics. Journal of artificial intelligence research, 2014, 49: 1–47
[20]Bosch A, Zisserman A, Munoz X. Image classification using random forests and ferns // Proceedings of ICCV. Piscataway, 2007: 1–8
[21]Kottur S, Vedantam R, Moura J M F, et al. Visual word2vec (vis-w2v): learning visually grounded word embeddings using abstract scenes // Proceedings of CVPR. Piscataway, 2016: 4985–4994
[22]Xu R, Lu J, Xiong C, et al. Improving word rep-resentations via global visual context // NIPS Workshop on Learning Semantics. Cambridge, 2014: 9
[23]Gupta T, Schwing A, Hoiem D. ViCo: word embed-dings from visual co-occurrences // Proceedings of ICCV. Piscataway, 2019: 7425–7434
[24]Chen Y C, Li L, Yu L, et al. Uniter: universal image-text representation learning // Proceedings of ECCV. Cham, 2020: 104–120
[25]Jia C, Yang Y, Xia Y, et al. Scaling up visual and vision-language representation learning with noisy text supervision // Proceedings of ICML. New York, 2021: 4904–4916
[26]Gerz D, Vulić I, Hill F, et al. SimVerb-3500: a large-scale evaluation set of verb similarity // Proceedings of EMNLP. Stroudsburg, 2016: 2173–2182
[27]Bakarov A. A survey of word embeddings evaluation methods [EB/OL]. (2018–01–21)[2022–04–15]. https:// arxiv.org/abs/1801.09536
[28]Baroni M, Dinu G, Kruszewski G. Don’t count, predict! A systematic comparison of context-counting vs. context-predicting semantic vectors // Proceedings of ACL. Stroudsburg, 2014: 238–247
[29]Hill F, Reichart R, Korhonen A. SimLex-999: eva-luating semantic models with (genuine) similarity es-timation. Computational Linguistics, 2015, 41(4): 665–695
[30]Batchkarov M, Kober T, Reffin J, et al. A critique of word similarity as a method for evaluating distribu-tional semantic models // Proceedings of the 1st Workshop on Evaluating Vector-Space Representations for NLP. Stroudsburg, 2016: 7–12
[31]Baroni M, Murphy B, Barbu E, et al. Strudel: a corpus-based semantic model based on properties and types. Cognitive science, 2010, 34(2): 222–254
[32]Almuhareb A. Attributes in lexical acquisition [D]. Colchester: University of Essex, 2006
[33]Huth A G, De Heer W A, Griffiths T L, et al. Natural speech reveals the semantic maps that tile human cerebral cortex. Nature, 2016, 532: 453–458
[34]Collobert R, Weston J, Bottou L, et al. Natural language processing (almost) from scratch. Journal of Machine Learning Research, 2011, 12: 2493− 2537
[35]Schnabel T, Labutov I, Mimno D, et al. Evaluation methods for unsupervised word embeddings // Pro-ceedings of EMNLP. Stroudsburg, 2015: 298–307
[36]Cui Y, Che W, Liu T, et al. Revisiting pre-trained models for Chinese natural language processing // Findings of the Association for Computational Lin-guistics: EMNLP 2020. Stroudsburg, 2020: 657–668
[37]Chen T, Kornblith S, Norouzi M, et al. A simple framework for contrastive learning of visual represen-tations // International Conference on Machine Lear-ning. Shangri-La, 2020: 1597–1607
[38]He K, Fan H, Wu Y, et al. Momentum contrast for unsupervised visual representation learning // Procee-dings of CVPR. Piscataway, 2020: 9729–9738
[39]Brysbaert M, Warriner A B, Kuperman V. Concre-teness ratings for 40 thousand generally known Eng-lish word lemmas. Behavior Research Methods, 2014, 46(3): 904–911
[40]Speer R, Chin J, Havasi C. ConceptNet 5.5: an open multilingual graph of general knowledge // Procee-dings of AAAI. Menlo Park, 2017: 4444–4451
[41]Krishna R, Zhu Y, Groth O, et al. Visual genome: connecting language and vision using crowdsourced dense image annotations. International Journal of Computer Vision, 2017, 123(1): 32–73
[42]Deng J, Dong W, Socher R, et al. Imagenet: a large-scale hierarchical image database // Proceedings of CVPR. Piscataway, 2009: 248–255
[43]Miller G A. WordNet: a lexical database for English. Communications of the ACM, 1995, 38(11): 39–41
Difference between Multi-modal vs. Text Pre-trained Models in Embedding Text
SUN Yuchong1, CHENG Xiwei2, SONG Ruihua1,3,†, CHE Wanxiang4, LU Zhiwu1,3, WEN Jirong1,3
1. Gaoling School of Artificial Intelligence, Renmin University of China, Beijing 100872; 2. School of Statistics, Renmin University of China, Beijing 100872; 3. Beijing Academy of Artificial Intelligence, Beijing 100084; 4. Faculty of Computing, Harbin Institute of Technology, Harbin 150001; † Corresponding author, E-mail: rsong@ruc.edu.cn

multi-modal pre-training; text representation; text embedding analysis
猜你喜欢
开放教育研究(2020年2期)2020-03-31 01:54:14
制造技术与机床(2019年10期)2019-10-26 02:48:08
电子制作(2018年18期)2018-11-14 01:48:06
现代语文(2016年21期)2016-05-25 13:13:44
小学教学参考(2015年20期)2016-01-15 08:44:38
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
上海电机学院学报(2015年4期)2015-02-28 14:30:00
大连民族大学学报(2015年2期)2015-02-27 08:28:11
计算物理(2014年2期)2014-03-11 17:01:39
语文知识(2014年1期)2014-02-28 21:59:13
