
一种可降低汽车白车身装配偏差的改进DBSCAN算法
2023-02-08 02:05:24林静康竞然张天侃张晨曦高艳俊
汽车工艺与材料 2023年1期
林静 康竞然 张天侃 张晨曦 高艳俊
(吉利汽车研究院(宁波)有限公司,宁波 315336)
1 前言
汽车白车身(Body in White,BIW)装配尺寸偏差是影响整车制造质量的重要因素,而白车身需要在装配线6 个区域40 个工位上装配完成[1],每个区域的每个工位都由人、机、料、法、环因素组成,都可能存在导致白车身尺寸发生偏差的因素。由这些因素导致的偏差在拼焊过程中传播、耦合累积,会对汽车的密封性、动力性、平衡性等整车性能产生重要影响[2-3]。实际上,影响白车身装配尺寸偏差的因素有很多,有些因素是偶发的、人为不能控制的,而有些是如工件定位、夹具磨损、焊接变形等的事实因素,可以通过定位误差源而纠正偏差。基于对大量由事实因素引起装配偏差的白车身进行分析,提出了一种通过对连续生产的离线白车身装配偏差趋势的分析方法,发现连续装配的白车身存在的变形趋势,快速定位源头,纠正偏差,提高装配质量。
目前,汽车学术界针对白车身装配偏差识别提出了很多有效的方法,如主成分分析[4]、模式识别[5]、结合模式识别和主成分分析[6]、反向传播神经网络[7]等。上述分析方法或者计算效率不高,或者深度依赖工业领域知识,或者算法过于复杂难懂,汽车工业界基于产能、经济和效益的考虑,没有很好地在实际生产中应用这些方法。
针对上述问题,提出了一种基于改进的、参数自适应的DBSCAN 算法,对连续的离线白车身的区域装配偏差进行识别,能实现连续偏差区域诊断和自动报警,有效定位偏差源,及时发现和纠正问题,提高白车身的装配质量。其中,依据特征点的非空间属性,划分数据集,缩短聚类时间;构建有权无向图来改进DBSCAN 算法,不依赖工程经验,并对非均匀分布的白车身特征点的聚类效果也符合期望,对算法工程师友好;改进后的DBSCAN 算法复杂度低,过程和结果均能可视化,对工业制造工程师友好。
2 降低汽车白车身装配偏差的改进DBSCAN算法
白车身的重要检测点(也叫特征点)能反映白车身各分总成之间的焊接工艺质量和车身整体装配状态,需要通过分析白车身各个特征点的检测信息,筛选出白车身某个区域上的特征点存在超差,且超差方向都相同,即识别白车身上存在装配偏差的区域;将数据扩展到连续的多台白车身,即可判断连续的多台白车身识别的装配偏差区域是否存在重叠部分,从中挖掘出白车身的区域装配偏差趋势,从而快速定位偏差源,并及时纠正,提高装配质量。
本算法基于三坐标测量仪CMM 测量的白车身特征数据,结合试制工艺数据进行预处理;对预处理后的白车身数据依次利用改进的DBSCAN算法进行区域装配偏差识别,并记录识别结果;再根据存储的单台白车身识别结果,分析连续多台白车身是否存在重叠的装配偏差区域,若存在,则可视化结果并报警,若不存在,则重复上述过程,如图1所示。
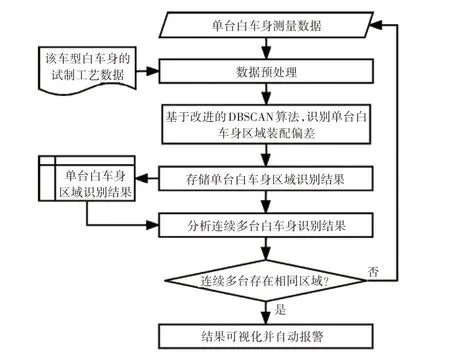
图1 连续白车身区域装配偏差识别算法流程
2.1 DBSCAN算法
DBSCAN 算法是一种典型的基于密度的聚类算法,以数据的稠密程度作为划分簇的依据,可在有噪声的空间数据库中发现任意形状的簇。DBSCAN 算法简单且易于理解,它将数据分为核心点、边界点和噪声点3 类;点与点之间的关系分为密度直达、密度可达、密度相连和非密度相连4种。但DBSCAN 算法聚类结果的准确性由输入的参数:邻域Eps 和最小节点数MinPts 决定。传统的方法一般依靠人工经验设定参数,但这需要专家知识;且固定参数对非均匀密度的数据集不适用,参数过大或过小,都会使聚类结果不理想。由于存在上述问题,DBSCAN 算法并不能适用所有应用场景,为了更好地解决实际情况,需要对其进行改进。
目前DBSCAN 有很多改进方法,比如基于K 近邻距离的改进DBSCAN[8],基于k-均值的改进DBSCAN[9],但这些改进方法都不能很好地解决本研究中的问题。针对传统DBSCAN 的缺点和白车身特征点不是均匀分布的特性,提出了一种结合非空间属性,基于构建的有权无向网络图,对DBSCAN 算法进行改进,不固定全局参数,不依赖人工经验,缩短聚类时间,提高聚类准确性。
2.2 数据说明及预处理
目前,汽车工业界约定的绘制三维坐标轴方式为:以白车身前轴轴心的中心点为坐标原点,指向车身后部为X轴正方向,指向车身右侧为Y轴正方向,指向车身上方为Z轴正方向,如图2 所示。用夹具固定好白车身,利用CMM 测量白车身的特征点信息,包含白车身N个特征点的特征名Feature,三维空间坐标值(x,y,z),法向量(i,j,k)、测量日期、测量人员等信息。

图2 白车身三维坐标系的标定
对测量数据进行预处理,得到需要的白车身数据,其中特征点属性包括,特征名Feature,测量空间坐标(x,y,z),试制工艺空间坐标(X,Y,Z),X轴公差范围[-Tx,Tx],Y轴公差范围[-Ty,Ty],Z轴公差范围[-Tz,Tz],法向量(i,j,k),测量日期Date,装配偏差值(Δx,Δy,Δz);一台白车身样本空间中有N个特征点组成的数据集D,每台白车身有2 000 多个特征点,不同车型,特征点个数可能不同。根据行业约定,特征点的数据在公差范围内的都是合格的测点,只有超过公差范围,即超差的特征点,才是不合格的,有问题的测点,算法针对的也是这些超差的点。
2.3 DBSCAN的改进
针对传统DBSCAN 的缺点和白车身特征点的特性,从2 方面对DBSCAN 进行改进。
a.基于非空间属性的数据划分即缩短聚类时间。基于特征点法向量的方向和大小,将白车身的特征点划分为多个模块;基于特征点是否超差,将每个模块中的特征点划分为超差特征集和未超差特征集,其中,超差特征集是本研究关注的重点,有权无向图是基于超差特征集构建的,算法识别的结果区域也是这个数据集的子集;基于特征点的超差方向,即超差值的正负符号,将每个模块中的超差特征集分为正超差特征集和负超差特征集。
b.基于有权无向图的局部聚类—自适应的Eps 和MinPts。有权无向图的构建如上所述,是基于每个模块中的超差特征集的,对点集中的每两个特征点建立一条无向的边,计算它们之间的欧式距离,作为边的权值。整个算法过程中需要多次用到两个特征点之间的距离,利用有权无向图记录计算结果,避免多次重复计算。且在过程中,会根据统计值对特征集中的噪声点进行筛选,即去掉有权无向图中相应的边,使噪声点成为孤立点。
对白车身划分后的每个特征集,基于有权无向图,先分别计算每个特征点的最小平均距离,从中选取最小的平均距离对应的特征点作为核心点,最小的平均距离为Eps,以核心点的最小平均距离范围内的特征点个数为MinPts,再用DBSCAN算法进行局部聚类;将聚类结果从有权无向图中清除,再对清除后的有权无向图重复上述计算、聚类和清除等步骤,直至有权无向图没有子图时结束对该特征集的识别。
改进的DBSCAN 算法整体流程,如图3 所示。
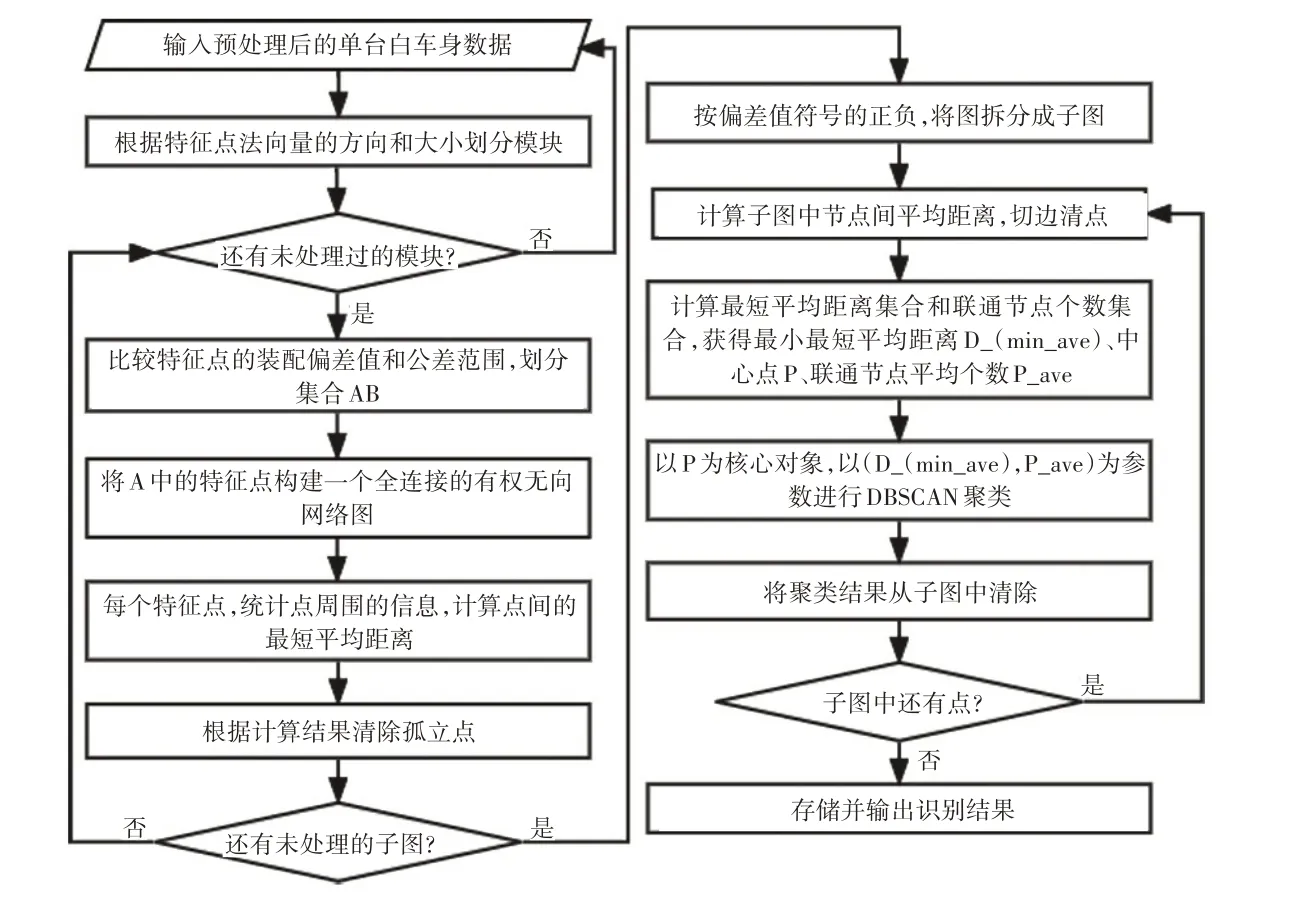
图3 改进的自适应DBSCAN算法流程
改进DBSCAN 算法的实现步骤如下。
a.输入:白车身特征点的数据集D;
b.输出:识别的装配偏差区域;
c.步骤1 根据特征点法向量的大小和方向划分模块Di;
d.步骤2 对每个Di,根据特征点装配偏差值与公差范围的比较,划分成2 个数据集,超过公差范围的数据集DiA,未超过公差范围的数据集DiB,将DiA中的点构建一个全连接的有权无向网络图,边的权重是两个节点之间的实际距离,节点的属性包括特征名、空间属性、装配偏差值、偏差值的正负符号等;
e.步骤3 对全连接有权无向网络图中的每个节点,分别计算它与其他偏差值正负符号相同和不同的节点之间的平均距离,统计它与相同正负符号的节点最短距离范围内属于数据集DiB的特征点个数、不同正负符号特征点的个数,统计它与不同正负符号的节点的最短距离范围内属于数据集DiB的特征点个数、相同正负符号特征点的个数;根据统计结果,清除孤立点;
f.步骤4 按偏差值的正负符号,将有权无向图拆分成两个子图;
g.步骤5 对每个子图,计算每个节点与其他节点之间的平均距离,切断两节点之间距离大于平均距离的边,清除孤立子图(总节点数<3);
h.步骤6 对每个子图,根据Dijkstra 算法,计算每个节点到其他节点的最短平均距离,组成最短平均距离集合,最小的最短平均距离Dmin_ave的节点为该子图的中心点;统计每个节点在Dmin_ave领域范围内,包含的联通的节点个数,组成联通节点个数集合,计算联通节点的平均个数Pave;
i.步骤7 对每个子图,以该中心点为核心对象,以最短平均距离Dmin_ave为Eps 邻域,以联通节点的平均个数Pave为MinPts 进行DBSCAN 聚类,将聚类结果从子图中清除;
j.步骤8 重复执行步骤5~8,直到没有子图时,停止运算。
3 案例分析
为了验证方法的有效性和正确性,将上述方法应用于实际工程中,以某车型的右侧围为例,将右侧围上的特征点展示在三维空间上,如图4所示。侧围上特征点的偏差会影响到车门的安装,进而影响到汽车的风噪声、密封性等。
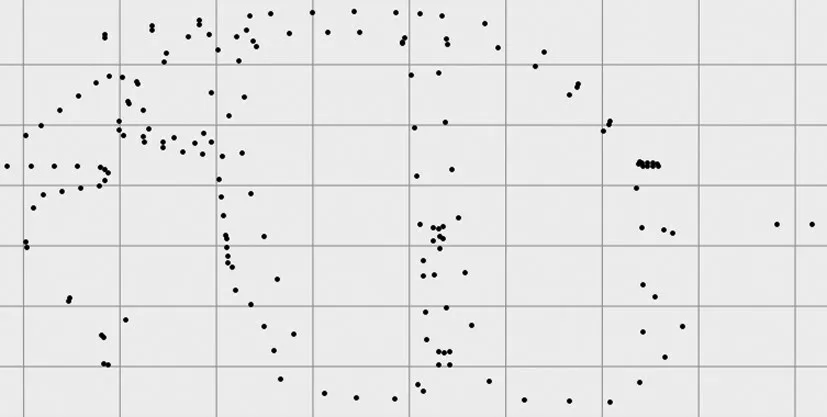
图4 右侧围的特征点位置
随机选取3 种车型,对每种车型抽取连续的200 台样车,获得CMM 测量的各个特征点的信息,按样车生产先后进行排序,利用改进的DBSCAN 算法进行分析诊断,可视化结果并自动报警。将步长设定为1,即每次分析一台白车身的区域装配偏差;连续多台的取值窗口设定为3,每输入一台白车身的区域装配偏差,就舍弃最早输入的那台白车身的数据,使窗口数据长度保持为3,即从每3 台白车身的识别结果中提取一次变形趋势。
识别的连续多台白车身区域装配偏差可视化结果如图5 所示,每个图上的点位置都是实际测量的结果展示。其中,图5a~图5c 中,点颜色的深浅表示偏差的大小,颜色越深,表示偏差越大;每个矩形表示算法识别的白车身右侧围存在的装配偏差的区域,图5d 展示的是对这连续的3 台白车身进行相同问题区域识别的结果,图5d 上的矩形,是3 台连续白车身右侧围都识别出的存在装配偏差的区域。
观察图5d 可以直观提取出连续白车身存在变形趋势的区域,根据区域位置可以快速地在100 多个装配焊接夹具中定位到哪些夹具可能存在磨损、位置偏差等问题。将可能存在问题的夹具信息,通过平台预警机制,向装配工程师发送提醒短信和预警邮件,邮件内容包括夹具ID、夹具照片、夹具所在位置、夹具定位精度、夹具对应的零件或分总成、夹具在仓库中存放的位置ID 等信息,便于工程师快速定位误差源,及时更换或纠正夹具,提高装配质量,减少生产过程中因装配偏差造成的减产,同时减轻工程师的工作量。

图5 装配偏差识别结果
4 结束语
本研究提出了一种简单实用的离线连续白车身的区域装配偏差识别方法,通过对数据集的划分和有权无向网络图的构建来改进DBSCAN 方法,并用3 种车型的实际测量数据进行验证。结果表明该方法可以对离线的连续白车身的装配偏差区域进行识别,可以加快聚类速度,不依赖工程经验,且聚类效果符合预期,有效地减轻了工程制造工程师的工作量,提高了白车身的装配质量。
猜你喜欢
世界汽车(2022年11期)2023-01-17 09:30:50
装备制造技术(2021年1期)2021-05-21 07:54:52
哈尔滨轴承(2021年4期)2021-03-08 01:00:48
装备制造技术(2020年9期)2021-01-26 00:15:30
同济大学学报(自然科学版)(2019年2期)2019-04-02 05:43:48
同济大学学报(自然科学版)(2019年2期)2019-04-02 05:43:48
制造技术与机床(2017年10期)2017-11-28 05:20:46
电子科技大学学报(2016年2期)2016-08-31 02:50:00
汽车维修与保养(2015年7期)2015-04-17 02:12:44
汽车维护与修理(2015年6期)2015-02-28 12:17:31
