
基于知识增强的多视野表征学习辅助诊断方法
2023-02-04 08:23王好天姜京池
中文信息学报 2023年12期
王好天,李 鑫, 关 毅, 杨 洋, 李 雪, 姜京池
(1. 哈尔滨工业大学 语言技术研究中心,黑龙江 哈尔滨 150001;2. 哈尔滨工业大学 物联网与泛在智能中心,黑龙江 哈尔滨 150001)
0 引言
随着人们生活水平的不断提高,医疗健康问题也逐渐成为大众日益关注的重要民生问题。国家卫健委在国卫基层函〔2018〕195号(1)http://www.nhc.gov.cn/jws/new_index.shtml中启动了“优质服务基层行”活动,该文件指出乡镇卫生院及社区卫生服务中心需要至少具备识别和初步诊治50种常见病、多发病的能力。基层医院直接对接群众,是医疗卫生服务过程中重要的一环,但由于就诊压力大、医疗设施不完善、医生能力有限等问题,基层医院的误诊情况时有发生。
近年来,人工智能技术取得了重大突破,相关技术已经在医疗、金融、法律等领域实现落地应用[1-2],这也使利用人工智能技术为医生提供辅助诊断成为可能。医生在问诊时会主动收集患者的性别、年龄、主诉、现病史和既往史等信息,并综合各项信息完成初步诊断。因此,利用人工智能技术构建一个基于电子病历(Electronic Medical Record, EMR)文本信息的辅助诊断系统,可以为医生提供诊断建议,有效减少误诊的发生。
早在20世纪60年代,Lealey等人[3]提出了机器疾病诊断的概念,吸引了大批学者投身于该领域的研究。传统疾病诊断方法需要医学专家人工制定特征,面临海量数据时无法展现出很好的处理能力。随着深度学习技术的快速发展与计算机硬件水平的提高,深度学习模型在海量数据面前表现出了优异的性能,也为辅助诊断提供了良好的思路。目前研究者主要使用序列模型和注意力机制(Attention Mechanism)抽取电子病历中的序列特征以实现疾病的辅助诊断。然而,电子病历文本中含有丰富的专业术语与医学关系,其中蕴含丰富的医学知识,但目前的深度学习模型难以建模这种结构化知识。因此,研究者们开始尝试利用图神经网络抽取电子病历文本中结构化知识表示,帮助辅助诊断模型提升性能。
虽然现有模型在辅助诊断任务上已经取得了较大进展,但是仍然存在以下不足: ①电子病历文本较长,传统的序列模型无法准确地从长文本中抽取诊断需要的特征; ②病人所患疾病不单一,且疾病之间一般会存在关联,如“糖尿病”与“视网膜病变”之间存在着“并发症”关系,现有模型并未考虑疾病之间的内在关联。
针对现有方法的不足,本文提出了一个基于知识增强的多视野表征学习辅助诊断模型(Multi-View Representation Learning Network, MVRLN)。该模型使用双向长短时记忆网络(Bidirectional Long-Short Term Memory Network,Bi-LSTM)提取语义信息,并利用注意力机制提取疾病的字符视野表征,基于医疗知识图抽取疾病的实体视野表征,基于预训练语言模型(Pretrain Language Model, PLM)抽取疾病的文档视野表征。将不同视野疾病表征融合后,基于疾病关系图利用知识增强方式融合疾病标签之间的内在关系,进而实现疾病辅助诊断。
本文的主要贡献有:
(1) 提出一种多视野疾病表征学习方法,分别从字符、实体、文档三个视野抽取疾病表征,有效缓解难以从长文本的准确抽取疾病表征的问题。
(2) 提出一种基于疾病关系图的知识增强方法,利用图神经网络通过知识融合增强疾病表征,更好地建模疾病之间的内在关系。
(3) 在“华为云杯”测评数据集上的实验表明,该模型相比于基线方法有显著性能提升,验证了该模型的有效性,项目代码已开源(2)https://github.com/FutureForMe/MVRLN。
1 相关工作
随着人们对自身健康关注度的不断提高,基于电子病历的辅助诊断研究也成为了人工智能应用技术的热点之一。现有方法主要是基于序列特征、结构化知识和与预训练语言模型的疾病诊断方法。
1.1 基于序列特征的辅助诊断方法
随着数据量的不断增加,深度学习技术凭借自动提取特征的能力及强大的学习能力受到研究者们的青睐,开始被应用于疾病辅助诊断任务中,如卷积神经网络(Convolutional Neural Network,CNN)和循环神经网络(Recurrent Neural Network,RNN)。Yang等人[4]提出使用CNN从电子病历文本中抽取高阶语义信息进行疾病诊断。Mullenbach等人[5]提出了CAML模型,通过CNN聚合电子病历文本中的特征信息,并利用Attention机制得到与每个疾病最相关的特征信息用于疾病诊断。Li等人[6]提出了MultiResCNN模型,该模型使用多尺度CNN提取文本中的多元特征,通过残差网络扩大感受野,并利用注意力网络得到每种疾病对应的表示用于疾病诊断。Vu等人[7]使用Bi-LSTM提取文本中的序列特征,并通过注意力网络得到每种疾病表示进行疾病诊断。
1.2 基于结构化知识的辅助诊断方法
自从图卷积神经网络[8](Graph Convolutional Neural Networks,GCN)提出以来,就受到人们的广泛关注。由于医疗文本中包含丰富的专业术语和医学关系,研究者们开始尝试利用电子病历中的结构化知识帮助模型提升性能。刘勘等人[9]使用知识表示模型学习医疗知识图谱结构化知识表示,并与文本特征融合进行并发症的疾病诊断。Zhao等人[10]基于电子病历数据构造了医疗知识图谱,并利用知识图谱嵌入方法进行概率推理,进行疾病的辅助诊断。Wang等人[11]使用多尺度标签注意力抽取疾病标签的对应特征,提出溯因因果图融合结构化特征进行辅助诊断。Xie等人[12]提出了MSATT-KG模型,该模型融入了疾病之间树状的层次信息,并结合CNN抽取的多元特征信息进行疾病诊断。Yuan等人[13]从电子病历中抽取结构化因果知识并与文本特征通过注意力网络融合后用于疾病诊断。
1.3 基于预训练语言模型的辅助诊断方法
预训练语言模型已经在自然语言处理任务上取得了优异的表现,如BERT[14]、ERNIE[15]等。研究者们开始尝试训练医学领域的预训练模型完成疾病诊断任务。Gu等人[16]使用医疗文献语料库训练PubMedBERT模型,并在医疗命名实体识别、文本分类等任务上取得较好效果。Huang等人[17]提出PLM-ICD模型,使用医学领域知识对PLM进行预训练,并将长病历文本划分为不同片段微调PLM,进而完成疾病分类编码任务。
以上方法利用医疗文本中的序列信息建模病人表征,忽视了文本中的多粒度信息,难以从长医疗文本中准确抽取疾病相关特征。此外,疾病诊断任务中的标签并不是相互独立的,因为疾病间存在内在关联。为了解决以上问题,本文提出一种基于知识增强的多视野表征学习方法,同时考虑了文本中的多粒度特征以及疾病标签之间的内在关联,有效提升了模型性能。
2 本文方法介绍
本文提出了一种基于知识增强的多视野表征学习辅助诊断方法,框架如图1所示。模型主要分为两个模块: 疾病的多视野表征学习模块和基于知识增强的标签关系融合模块。
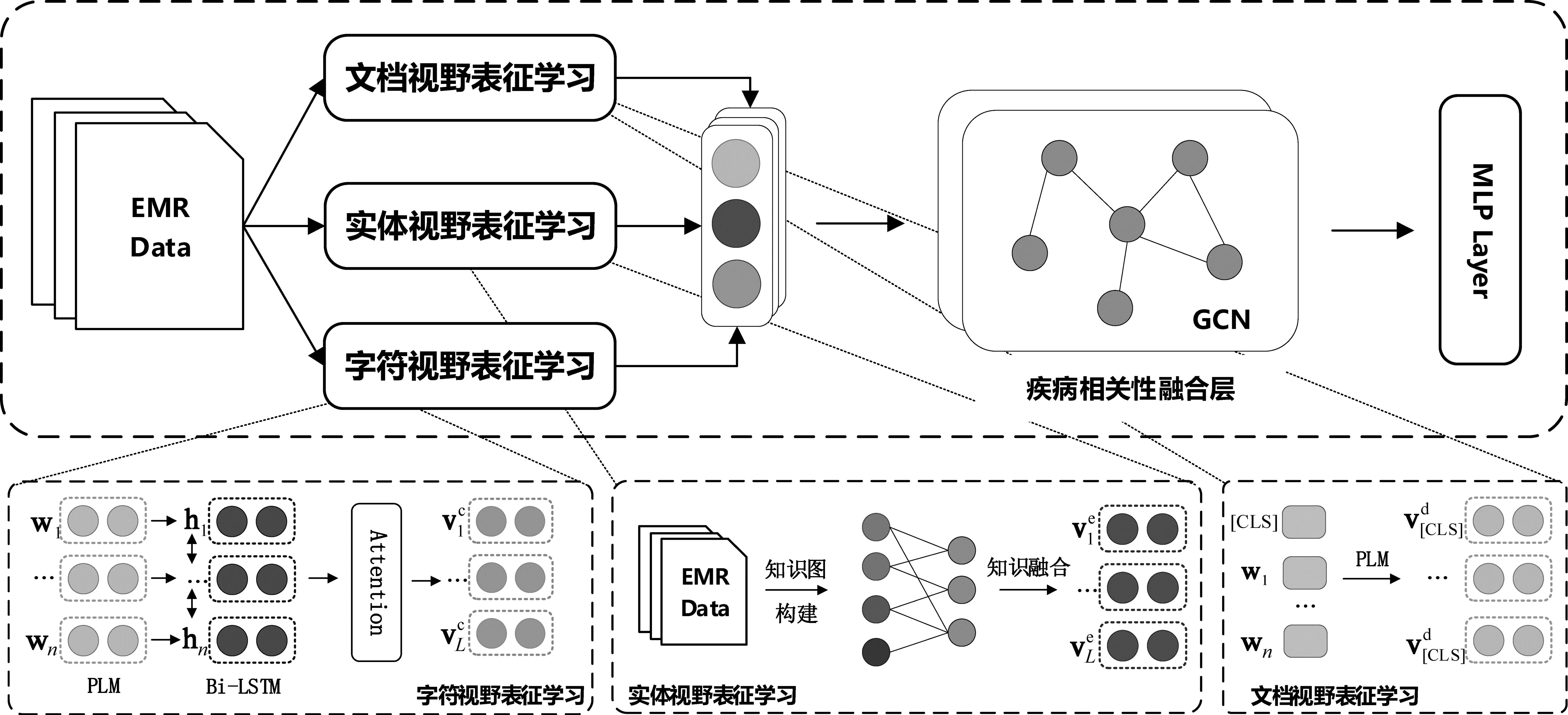
图1 模型的整体框架
疾病的多视野表征学习模块主要考虑三个视野的特征信息,即字符视野表征学习、实体视野表征学习和文档视野表征学习。三个视野分别对长医疗文本进行不同粒度的表征学习,相比于单一视野,三视野可以为每种疾病抽取更丰富的特征。为了融合疾病标签之间的内在关联信息,利用训练集数据构造标签关系知识图,并使用GCN进行知识融合以增强疾病表示,用于最终的疾病辅助诊断。
2.1 字符视野表征学习
2.1.1 Embedding层
给定医疗电子病历文本X,对X切分可得到对应的token序列[token1,token2,…,tokenn],n表示文本中token的个数。鉴于PLM已经在众多自然语言处理任务中有优异表现,本文使用PLM例如BERT[14],得到每个token的表示向量E=[e1,e2,…,en]∈Rn×d,d表示词向量的维度。
2.1.2 Bi-LSTM层
为了提取文本中的语义特征,得到更加契合当前语境的向量表示,我们将文本中token的表示向量作为输入,使用Bi-LSTM提取字符级语义信息,获得字符表征,如式(1)~式(3)所示。
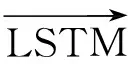
2.1.3 Attention层
通过Bi-LSTM层可以得到每个字符的表示H∈Rn×2u,由于每个标签对于token的关注程度不同,因此模型使用注注意力机制为每个标签提取对应的表征,如式(4)、式(5)所示。
其中,W∈R2u×|L|为可学习的参数矩阵,用来计算疾病标签与不同字符之间的注意力权重Ac∈Rn×|L|。Vchar∈R|L|×2u为使用注意力权重Ac和字符表示H计算得到的字符视野疾病表征。其中,|L|表示疾病标签的数量。
2.2 实体视野表征学习
2.2.1 医疗知识图构建
在进行实体视野表征学习之前,需要根据现有训练集中的电子病历数据构造医疗知识图。首先利用命名实体识别(Named Entity Recognition,NER)技术得到病历文本中的医疗实体;而后根据限定词去掉否认实体(如“否认高血压”),保留肯定实体。
在得到医疗实体之后,本文借鉴条件概率公式计算医疗实体与疾病标签之间的相关程度,如式(6)所示。

2.2.2 实体视野表征学习
医疗电子病历文本中往往会含有较多的专业术语和医学关系,且文本较长,传统的基于序列模型的辅助诊断模型无法很好地捕捉长距离依赖信息以及文本中蕴含的结构化信息。我们首先使用预训练模型得到实体的初始化向量E=[e1,e2,…,em]∈Rm×d,m为实体数量,d表示实体向量维度。而后根据实体是否在病人病历中出现构造患者个性化one-hot表示p=[p1,p2,…,pm],pi∈{0,1}。为了融合患者个性化实体特征,我们根据病人的个性化表示对实体向量进行掩码,并基于医疗知识图进行知识融合,如式(8)所示。

2.3 文档视野表征学习
由于预训练模型中[CLS]位置的表示可以融合整段文本的特征信息,因此本文将{[CLS],token1,token2,…,tokenn,[SEP]}作为预训练模型的输入,在预训练模型学习过程中[CLS]关注整段上下文特征,因此本文直接将[CLS]的表示作为文档视野疾病的表征Vdoc∈R|L|×d。
模型在得到字符视野、实体视野、文档视野的疾病表征之后,将其拼接得到多视野表征学习的疾病表征,如式(9)所示。
2.4 基于知识增强的标签关系融合
在实际诊断过程中,病人患有的疾病往往不单一,且疾病之间不相互独立,会存在一些内在联系,例如,“糖尿病”与“视网膜病变”之间存在着“并发症”关系,即患有糖尿病的病人患有视网膜病变的概率要比未患有糖尿病的病人患有视网膜病变的概率高。因此在辅助诊断的过程中考虑疾病标签之间的内在关系会对疾病诊断结果产生积极影响。
为捕捉疾病标签之间的内在联系,本文使用训练集电子病历,利用统计概率方法计算疾病标签之间协同关系的概率,并构建标签相关图(Disease Correlation Graph,DCG),计算过程同2.2.1节。将多视野表征学习得到的疾病表示向量作为疾病标签知识图中疾病节点的初始化向量H0=Vm,使用GCN进行知识融合,融合不同疾病标签之间关系,如式(10)所示。
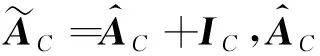
其中,Φ表示所有可训练参数,E表示输入的文本序列,G表示实体视野的知识图和标签相关图。
3 实验设置
3.1 数据集
本文实验用到的所有数据均来自于“华为云杯”2022人工智能创新应用大赛(3)https://competition.huaweicloud.com中的真实电子病历数据,对数据筛选后选取诊断标签较多的电子病历构成本文数据集。该数据已经过严格去隐私化处理,病历包含病人的性别、年龄、主诉、现病史、既往史和诊断疾病字段,具体统计信息如表1所示。

表1 数据集信息统计表
本文将性别、年龄、主诉拼接作为一个字段,并与现病史、既往史共同作为模型输入,字段间使用[SEP]分隔。在构造医疗知识图过程中使用医生人工标注的实体数据集训练BERT+Bi-LSTM+CRF模型[18],该数据由6 511份电子病历构成,包括5种实体类型: 疾病、症状、治疗、检查和检查结果,具体统计结果见表2。训练集和验证集划分比例为8∶2,最优模型在验证集上的MacroF1为95.07%,并利用最优模型对本文数据集的电子病历文本进行实体识别。
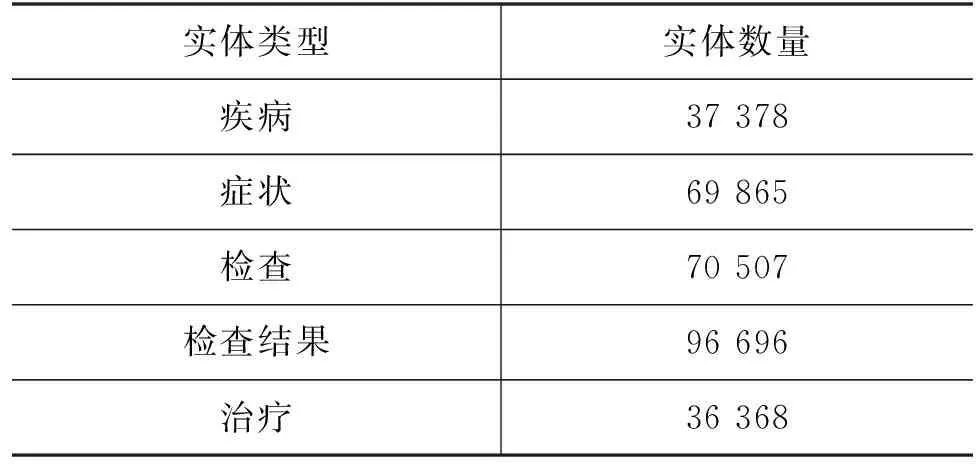
表2 实体数据信息统计表
3.2 基线方法
为了全面分析本文提出的MVRLN方法的效果,我们选取了以下基线方法进行实验对比。
(1)TextCNN[19]: 使用卷积神经网络抽取文本特征进行疾病辅助诊断。
(2)TextRNN[20]: 使用循环神经网络(Bi-LSTM)抽取文本特征进行疾病辅助诊断。
(3)TextRCNN[21]: 首先使用循环神经网络提取文本语义特征,而后利用最大池化进行疾病辅助诊断。
(4)CAML[5]: 使用多尺度卷积神经网络进行疾病辅助诊断。
(5)MultiResCNN[6]: 利用多尺度卷积神经网络与残差神经网络提取文本N-gram特征,并使用Attention得到每个标签的表示用于辅助疾病诊断。
(6)LAAT[7]: 利用Bi-LSTM提取文本时序特征,且通过Label Attention得到标签表示并进行疾病辅助诊断。
(7)KenMeSH[22]: 利用Bi-LSTM分别提取不同字段表示,并结合动态知识增强技术进行疾病辅助诊断。
(8)BERT[12]: 使用BERT预训练模型(4)https://huggingface.co/bert-base-chinese在病历文本数据上微调实现辅助疾病诊断。
(9)ERNIE[13]: 使用ERNIE Health模型(5)https://huggingface.co/nghuyong/ernie-health-zh在病历数据上微调实现疾病辅助诊断。
(10)Longformer[23]: 长文本预训练模型(6)https://github.com/IDEA-CCNL/Fengshenbang-LM,在病历数据上微调进行辅助疾病诊断。
3.3 实验设置
模型代码基于PyTorch框架实现,使用RTX 3090 24 GB显卡训练测试。预训练模型获取的词向量维度统一为768;Dropout参数设置为0.5,预训练模型学习率设置为0.000 01,非预训练模型学习率设置为0.000 5,优化器为AdamW,GCN层数为2;batch size设置为12,epochs设置为30;阈值设置θ为0.5,da设置为128,LSTM隐变量u设置为384。所有实验结果均取随机种子训练5次的平均值。
3.4 评价指标
本方法将辅助诊断任务作为一个多标签分类任务,评价指标为MacroP,MacroR,MacroF1和MicroP,MicroR,MicroF1,计算如式(13)~式(18)所示。
(13)
(14)
(15)
(16)
(17)
(18)
其中,|L|表示疾病标签的数量,在计算MacroF1时,首先计算所有疾病类别的F1,然后取所有类别的平均值作为结果。在计算MicroF1时,将每一个样本数据作为独立个体进行预测,并计算F1。
4 实验结果及分析
4.1 实验结果分析
为验证方法的有效性,我们分别结合不同的预训练模型进行向量初始化,并在数据集上与不同的基线方法进行实验对比,实验结果如表3所示。其中,MVRLNB、MVRLNE和MVRLNL分别表示使用Bert、 ERNIE和Longformer预训练模型初始化向量的模型。通过实验结果可以看出:

表3 对比实验结果 (单位: %)
(1) 本文提出的方法效果超过了所有基线方法,获得了最佳效果。其中,MVRLNL在F1指标上取得所有基线方法中的最佳结果,其MacroF1和MicroF1分别为53.49个百分点和77.89个百分点。实验结果表明,多视野表征学习模块能抽取出疾病更准确的表示,通过知识增强技术融合疾病标签内在关联后可以有效提升模型性能,验证了本文方法的有效性。
(2) 在所有深度学习基线方法中TextRNN模型效果最差,主要原因是电子病历文本较长,而RNN模型无法很好地提取长距离依赖特征。LAAT模型在Bi-LSTM基础上增加了Label Attention机制,可以为每个疾病提取最相关的特征,有效缓解长距离依赖问题,使得性能有所提升。
TextCNN比TextRNN效果更好,这是因为电子病历中含有较多的医学名词,使用CNN可以抽取文本中的多元特征,取得更好的模型效果。MultiResCNN在CNN基础上进一步改进,通过残差网络增加感受野范围,设置不同卷积核提取特征,取得了深度学习基线方法中的最优效果。
相比于MultiResCNN模型,本文提出的方法在MacroF1上提升5.73个百分点,在MacroF1上提升2.53个百分点,这表明疾病内在关联在疾病诊断过程中具有优越性,通过知识增强技术可以有效建模疾病间的结构化特征。相比于知识引导的学习方法KenMeSH,本文提出的方法在MacroF1上提升16.32个百分点,在MacroF1上提升3.42个百分点,这表明相比于仅使用Bi-LSTM提取字符级疾病特征,增加实体视野的结构特征以及文档级的整体特征可以更准确地捕捉疾病相关的语义信息,获得更全面的疾病特征表示。
(3) 在所有预训练模型基线方法中,MVRLNB相比于BERT在MacroF1和MacroF1上分别提升2.99和2.21个百分点,MVRLNE相比于ERNIE在MacroF1和MacroF1上分别提升了3.69和1.12个百分点,MVRLNL相比于Longformer在MacroF1和MacroF1上分别提升了3.17和1.08个百分点。这说明本文提出的方法在不同的预训练模型基础上均可以提升模型性能,取得更好的实验结果。
由于医疗文本长度较长,受预训练模型输入文本长度限制,MVRLNB和MVRLNE无法有效建模长文本中的特征,因此MVRLNL相比MVRLNB和MVRLNE凭借着Longformer可以建模长文本特征的优势取得更优异的结果。
4.2 消融实验
我们对本文方法的不同模块进行了消融实验,实验结果如表4所示。其中,w/o char表示去除字符视野表征,w/o ent表示去除实体视野表征,w/o doc表示去除文档视野表征,w/o DCG表示去除标签关系融合模块。

表4 MVRLNL消融实验结果 (单位: %)
通过表4可以看出:
(1) 通过对多视野表征学习模块的消融实验可以发现,相比于w/o char、w/o ent、w/o doc方法,本文提出的MVRLNL在MacroF1上分别提升了1.12个百分点,0.37个百分点,3.70个百分点;在MacroF1上分别提升了0.77个百分点,0.17个百分点,0.51个百分点。其中,在MacroF1指标文档视野特征贡献度最大,在MacroF1指标字符视野特征贡献度最大,由此可以看出: 文档视野从粗粒度学习疾病特征,可以更全面地提取每类疾病特征,因此对少样本数据的关注度更高;而字符视野使用Bi-LSTM和Label Attention学习医疗文本的细粒度信息,使得学习到的疾病特征更关注于样本数量较多的疾病。
此外,实体视野在MacroF1和MacroF1贡献度最小,其主要原因是本文构建实体视野的知识图时仅使用电子病历中的主诉、现病史、既往史字段,文本较少,包含的实体信息并不丰富,后续会融入更多的病历文本,构建蕴含更丰富知识的图。通过以上实验可以验证多视野表征学习模块中每个视野均能在疾病诊断过程中起到作用,这也表明该模块可以帮助模型取得更好的结果。
(2) 通过对比基于知识增强的标签关系融合模块的消融实验可以发现,相比w/o DCG方法,本文提出的MVRLNL在MacroF1和MacroF1上分别提升1.64和0.28个百分点,证明该模块在疾病诊断过程中起到了积极作用。该模块在MacroF1指标上的贡献度高于MacroF1指标上的贡献度,这表明通过知识增强技术融合标签之间的内在联系,可以增强少样本疾病的表示,保证在辅助诊断任务中更多地关注样本较少的疾病。
4.3 注意力可视化
为了探究模型是否关注了医疗电子病历中与疾病最相关的文本片段,我们对字符视野表征学习中Label Attention的score进行了可视化。随机从测试集中选取一个病人,该病人的入院诊断为“高血压”、关节炎”和“骨折”,可视化结果如图2~图4所示。图2表示“高血压”疾病注意力可视化图,图3表示“关节炎”疾病注意力可视化图,图4表示“骨折”疾病注意力可视化图,颜色越深说明该片段对该疾病越重要。

图2 高血压注意力可视化图

图3 关节炎注意力可视化图

图4 骨折注意力可视化图
从图2可以看出,该病人有“高血压病史十几年”,曾因“头晕”住院,通过以上片段可以判断出该病人患有高血压。
从图3可以看出,该病人有“左侧足踝部红肿热痛”“足部红肿热痛病史”等症状,并且曾被诊断为“痛风性关节炎”,因此通过以上信息可推理出该病人患有“关节炎”疾病。
从图4可以看出,该病人曾因“外伤致左腓骨下段骨折”进行手术治疗,近两天又因“左腓骨骨折术后”入院,因此可以推理出该病人患有“骨折”疾病。
通过对该病人所患三种疾病的可视化结果进行分析可以说明,注意力机制能很好地为每种疾病提取最相关的片段特征,可以帮助模型进行准确的疾病诊断。
5 总结
本文提出了一种基于知识增强的多视野表征学习辅助诊断方法。为解决医疗长文本数据中难以准确抽取疾病相关特征的问题,本文提出了多个视野特征表示模块,分别从字符视野、实体视野和文档视野抽取每种疾病不同粒度的表征。为了解决病人患病不单一、疾病间存在内在关联的问题,本文利用知识增强的方式融合疾病标签之间的内在关系,进一步提升了模型的性能。在华为云杯评测数据上的实验结果表明,本文提出的基于知识增强的多视野表征学习辅助诊断方法可以有效提升疾病诊断的准确率。未来的研究可以尝试引入医疗知识图谱和医疗本体等结构化知识解决罕见疾病的辅助诊断问题,并考虑如何利用逻辑知识增强模型的可解释性问题。
猜你喜欢
趣味(语文)(2021年9期)2022-01-18
中华养生保健(2020年5期)2020-12-02
数学小灵通·3-4年级(2020年9期)2020-10-27
中华民居(2020年3期)2020-07-24
国际呼吸杂志(2019年22期)2019-12-09
中国卫生(2016年10期)2016-11-13
广东技术师范大学学报(2016年5期)2016-08-22
中国继续医学教育(2015年6期)2016-01-07
中国卫生(2015年10期)2015-11-10
科学家(2015年2期)2015-04-09
