
基于目标语言预训练和联合解码的低资源语言端到端语音翻译
2023-02-04 08:22朱丽平赵小兵仁曾卓玛王燕敏
中文信息学报 2023年12期
李 宁,朱丽平,赵小兵,仁曾卓玛,王燕敏
(1. 中央民族大学 信息工程学院,北京 100081;2. 中央民族大学 国家语言资源监测与研究少数民族语言中心,北京 100081;3. 中央民族大学 民族语言智能分析与安全治理教育部重点实验室,北京 100081)
0 引言
自动语音翻译(Automatic Speech Translation,AST)可以将源语言语音转换为目标语言文字[1],促进世界各地不同语言的人的交流。目前,AST有两种实现方式: 级联方式和端到端方式。级联方式使用自动语音识别(Automatic Speech Recognition,ASR)模块级联机器翻译(Machine Translation,MT)模块构建AST系统,其中ASR模块将源语言语音转换为源语言文字,后续MT模块将源语言文字转换为目标语言文字[2],进而实现语音翻译。级联方式不需要专用的AST数据集,即源语言语音到目标语言文字数据集,就可实现语音翻译。ASR和MT的技术现在都很成熟,具有很高的准确率。但是级联语音翻译容易发生误差传播现象[3],同时级联方式不适用于没有书面形式的口语,因为它需要源语言文字作为中间数据[4]。端到端方式直接将源语言语音转换为目标语言文本,解决了误差传播的问题,并且具有较低的延迟[3]。此外,它绕过了级联法所需的平行源语言文本的要求,是语音翻译的新趋势。与级联方式相比,端到端方式在数据量足够的情况下具有更好的语音翻译结果[5]。
目前端到端AST的研究主要集中在多任务[2,6-7]、多语言[8-10]、预训练[6,11-15]、数据增强[16]、元学习[17-18],使用其他声音表示[19-20],添加额外的副语言信息,如押韵[21]、强调[22]、情感等方法上。虽然使用端到端方式原则上不需要源语言文本,但目前语音翻译数据集太小,数据稀缺严重,因此使用上述大多数方法往往需要源语言ASR数据集来提供必要的信息,有些还需要包含副语言信息的特定数据集。源语言ASR数据或副语言信息数据集的缺乏,限制了这些方法在低资源语言中的应用。
对于AST中使用的预训练方法,大多数端到端研究都预训练ASR模块和MT模块以获得ASR信息和MT信息,这些信息用于为AST提供良好的初始参数,从而提高AST的性能。MSperber指出,预训练方法优于多任务[23]。
上述方法不适用于稀缺语言的语音翻译。端到端语音翻译需要大量数据来训练模型,但是对于稀缺语言来说可用的语音数据量有限。
本论文的贡献主要有以下几点:
第一,使用目标语言ASR数据集预训练模型,与使用端到端数据直接训练翻译模型相比,提高了AST的性能,促进了模型收敛。目标语言领域的语音识别数据集用于预训练模型,模型可以学习到目标语言的语言信息,与源语言预训练相比,无须添加额外的语言模型。同时,目标语言预训练模型可以使用相同的预训练模型快速开展多种源语言到目标语言的研究任务,缩短开发时间。这使得模型能够适应多种稀缺语言到目标语言的翻译需求,提高了实用性。
第二,使用目标语言预训练的端到端模型作为基线模型,用映射模块替代端到端模型中的编码器结构,使源语言特征与目标语言特征建立联系,模型学习到从源语言语音到目标语言文字的关联,改进了语音翻译效果。本文方法在20h的维吾尔语-汉语数据集上实现了61.45的BLEU值。
第三,受端到端语音识别的启发,本文使用CTC和注意力机制解码器联合解码,强制对齐语音和标签,进一步提高BLEU值。
1 数据集构建
数据集是端到端AST的基础。目前,AST领域存在严重的数据集稀缺问题。国际AST数据集主要集中在英语上,例如,英语语音到中文文本数据集。尽管中国对中国少数民族语言的语音翻译需求很大,但相关的AST数据集几乎是空白。
本文使用机器翻译和人工校对相结合的半自动化方法,基于现有的公开数据集THUYG-20[24]构建了一个包含20h维吾尔语语音的维吾尔语-汉语AST数据集。半自动数据集构建流程如图1所示。与通过现有ASR数据集的机器转录或现有MT数据集的语音合成的全自动方法相比,专家校验步骤确保了数据质量,提高了可靠性。

图1 维汉数据集构建流程
2 预训练模型
2.1 预训练方法
预训练AST模型的常规方法如图2所示。首先,如图2(a)所示使用源语言的ASR数据集对ASR编码器和解码器进行预训练。然后如图2(b)所示,使用从源语言文本到目标语言文本的MT数据集对MT编码器和解码器进行预训练。最后,如图2(c)所示,将预训练的ASR编码器、ASR解码器、MT编码器和MT解码器全部或部分作为初始AST模型框架,使用AST数据集对其进行微调,将源语言语音作为AST模型的输入,将目标语言文本作为输出。例如,MSperber使用ASR编码器、ASR解码器、MT编码器和MT解码器的结构构建了端到端的AST模型[5],而Kano使用ASR编码器和MT解码器的组合结构训练了AST模型[4]。

图2 预训练语音翻译模型
上述预训练方法在ASR模型和MT模型的训练过程中都需要使用大规模的源语言数据集。采用这种方法构建AST端到端模型,需要提前构建ASR和MT模型,需要大规模的源语言数据集和大量的计算资源进行训练,不适合低资源语言。使用源语言语音识别数据集训练ASR模型来构建AST模型,AST模型提前学习到的是源语言语言模型。在源语言预训练的端到端语音翻译模型中,翻译模型是基于源语言的,因此在翻译时,模型可能无法处理目标语言中的一些复杂语法或特定语言结构,导致翻译不准确,需要添加额外的语言模型。
使用目标语言预训练模型可以提高翻译的准确率,因为模型会对目标语言中的语法和结构有更好的理解,更容易捕捉到语言之间的差异。此外,由于目标语言是翻译的最终目的地,因此该方法更注重目标语言的质量。目标语言数据集通常规模大、质量高,对语音翻译模型更有帮助。
以维吾尔语和汉语为例,源语言与目标语言之间在语言学上存在差距。维吾尔语和汉语属于不同的语系,对语境的依赖程度不同。从语境来看,维吾尔语属于阿尔泰-突厥语系,构词和构词的附加成分非常丰富。名词有数、人称、格等语法范畴,动词有语气、肯定否定、时态、人称、数、动词、动名词、副词等语法范畴,表达各种情态的助动词也很发达。词汇本身可以传达足够的信息,较少依赖上下文。汉语属于汉藏语系,汉语单词的语音、语义和语法的确定在很大程度上取决于语境,需要结合语境才能准确理解。没有特定的语境,不仅无法确定词的读音,也无法确定词的语义[25]。
使用目标语言预训练已经包含了目标语言的语言信息,无须添加额外的语言模型,减少了计算资源的消耗。与源语言预训练模型相比,目标语言预训练模型更容易调整以满足特定场景或用户需求。同时可以针对特定领域或术语进行优化,提高翻译质量和可用性,使用相同的预训练模型,只需要在不同的AST数据集上进行微调即可实现高质量的语音翻译。目标语言预训练模型只需要预训练一种语言,与源语言预训练模型相比,训练所需的计算资源和时间会减少。
2.2 映射结构
如图3所见,在迁移学习之前,使用目标语言ASR数据集预训练的端到端模型,编码器-解码器结构充分学习目标语言语音知识。其中编码器结构学习目标语言语音知识,解码器结构学习目标语言语言学知识。在新构建的AST端到端语音模型中,期望学习到源语言语音知识以及目标语言语言学知识。由此可见,在使用目标语言ASR数据集预训练的端到端模型中,编码器结构对于构建AST端到端语音翻译模型作用较小,因其无法提供源语言语音知识,而解码器结构则很有用,因其包含了目标语言文本信息。为此,需要添加一个映射模块来学习源语言语音知识,从而使源语言语音和目标语言文本相关联。保留ASR预训练模型中的解码器,并添加学习了源语言语音的映射模块,就可以实现端到端的源语言语音到目标语言文本的语音翻译模型。
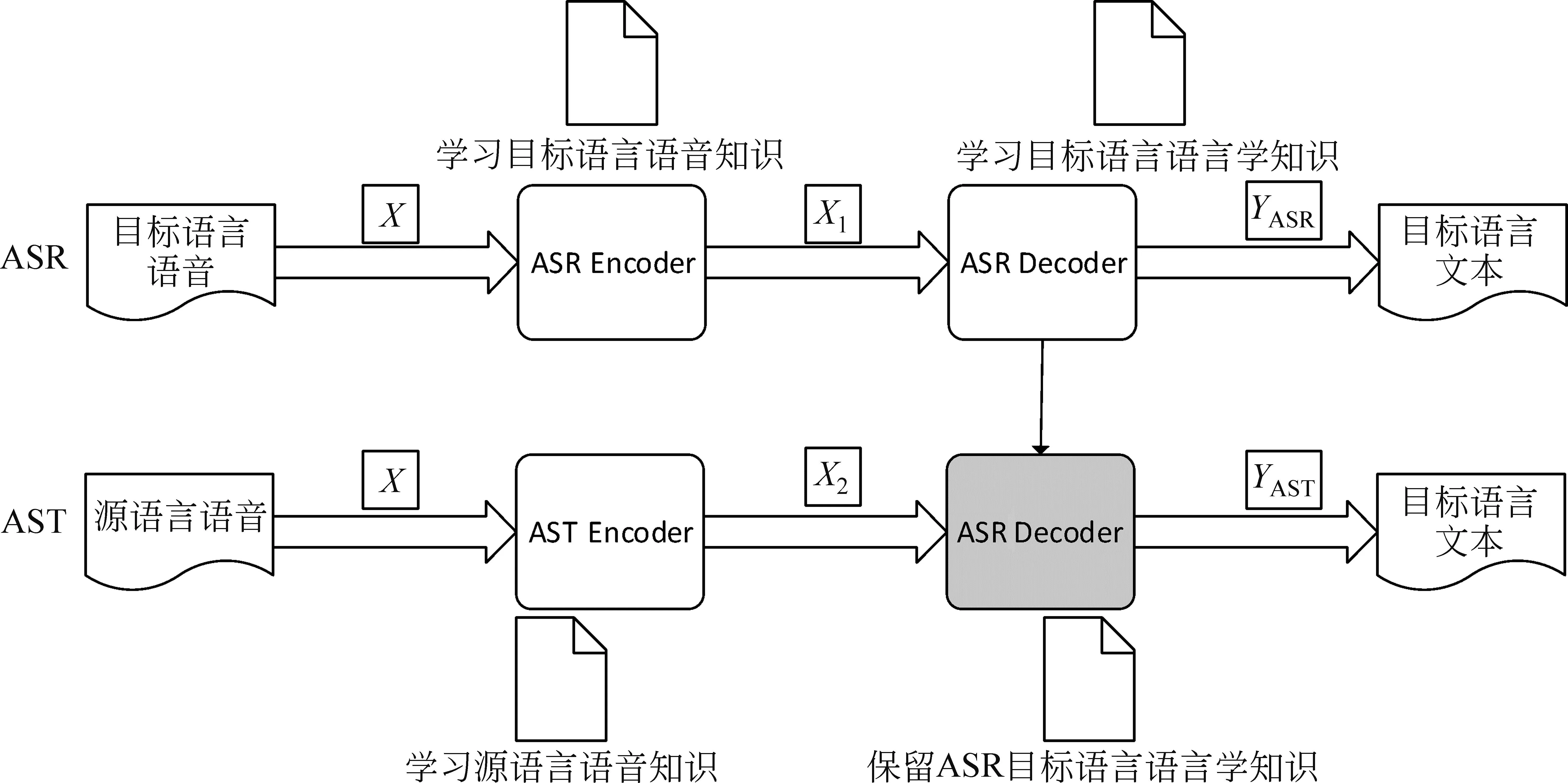
图3 语音翻译模型
令X为输入语音数据。在语音识别模型中,X通过ASR Encoder成为语音高级表示X1,X1通过ASR Decoder得到语音识别输出YASR。在语音翻译模型中,X通过AST Encoder转化为语音高级表示X2,X2通过ASR Decoder得到语音翻译输出YAST。AST编码器使用Conformer模块,AST解码器使用Transformer[26]模块。
2.3 联合解码
受端到端语音识别混合模型[27-28]的启发,基于链接时序性(Connectionist Temporal Classification,CTC)和基于注意力的编码器-解码器(Attention-based Encoder-Decoder, AED)模型的联合训练,相对于单一的注意力模型,CTC的前向-后向算法被用来进行语音和标签之间的强制对齐,加速了对齐过程,可以改善注意力机制在长文本上的效果。注意力机制关注的目标是字符集,CTC的目标在序列层面,注意力机制与CTC联合有助于提高CTC目标的准确率。如图4所示,模型结构由三部分组成: 共享编码器、CTC解码器和Attention解码器。共享编码器由多个Transformer层组成,只需要有限地考虑上下文即可保持平衡的延迟。CTC解码器由一个线性层组成,通过CTC激活对共享编码器的输出进行变换,而注意力解码器由多个Transformer解码器层组成。使用交叉损失标准对分数进行联合评分,从而提高了鲁棒性。

图4 联合解码
L(X,Y)=λLCTC(X,Y)+(1-λ)LAED(X,Y)
(5)
其中,X是语音特征,Y是相应的标签,LCTC(X,Y)和LAED(X,Y)分别是CTC和AED损失,λ是平衡CTC和AED损失重要性的超参数。
3 实验
本文分别使用第2节中构建的维吾尔语-汉语数据集以及图3和图4中所示的端到端AST模型进行语音翻译实验。本文使用了AMD EPYC 7402 @2.8 GHz CPU和NVIDIA RTX3090的24 GB GPU训练。微调模型迭代次数仅仅只需16次左右就可完全收敛,在4 h内即可完成训练。
3.1 模型参数
实验中采用的端到端AST模型的参数如下: 使用12个编码器层,编码器嵌入维度为2 048,4个注意力头,6个解码器层,解码器嵌入维度为2 048,dropout为0.1。该模型使用Fbank特征,初始学习率为0.002。
3.2 Conformer
与Transformer相比,Conformer结合了Transformer和CNN的优点。前者擅长利用注意力机制捕捉基于内容的全局交互,而后者则有效地利用了局部特征的建模能力。它在ASR领域的LibriSpeech数据集上取得了非常好的结果,在小模型上也取得了很好的结果,例如,参数为10M数量级的模型,显示了Conformer结构的优势[29]。因此,将其应用于AST领域。
3.3 实验结果
本文发现,用小规模的AST数据集(包含20 h源语音)直接训练如图3所示的端到端AST模型,则模型效果极差,因其无法学习到有价值的知识,无法执行端到端AST任务。因此,对不使用目标语言直接训练、基于目标语言预训练的端到端模型、添加了映射模块的端到端模型和联合解码端到端模型进行了对比实验,分别记录为传统Conformer、迁移学习Conformer、Conformer-add和Conformer-combined。同时引入了M2M模型[8]作为对比实验,并在M2M基础上对其基于目标语言进行了迁移学习,分别记录为M2M和迁移学习M2M。在实验中,使用了两个评估指标CER和BLEU,来比较AST在数据集上的性能。
表1展示了使用目标语言预训练模型取得的优异成绩,在20 h的维汉数据集上,使用迁移学习Conformer,获得了28.63的CER值和61.45的BLEU 4分数,相较于不使用迁移,学习有了提升。同时在M2M模型中使用目标语言迁移学习,也可以改善语音翻译效果。
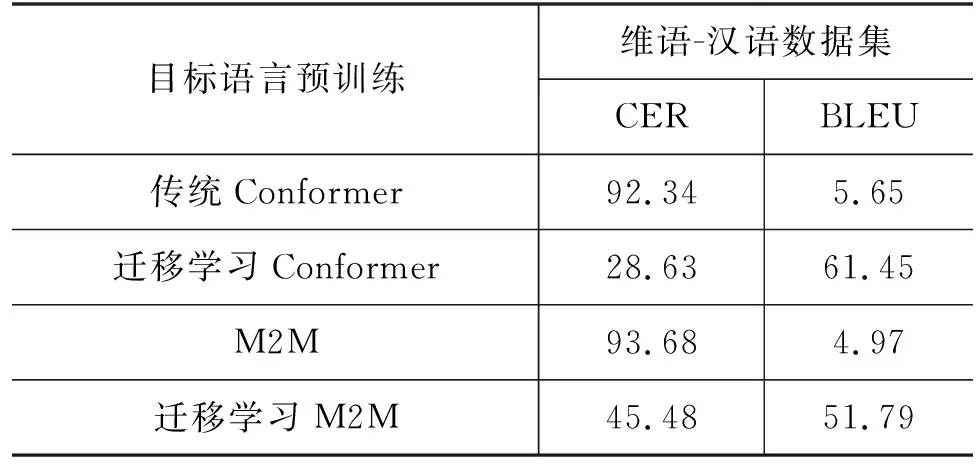
表1 预训练实验结果
图5是预训练和微调后解码器结构中Attention模块公共部分权重差异的热力图。将预训练和微调后的模型取出相同的注意力模型权重,相减得到热力图。本文发现图中热力图的颜色大多偏浅,说明两个模型的解码器结构中Attention层的权重相差不大。相似的权重表明端到端模型在预训练和微调后具有相似的语言模型,解码器主要学习的是目标语言的语言模型。通过预训练目标语言数据集,解码器已经可以学习到目标语言的语言模型。与级联语音翻译和源语言预训练语音翻译相比,无须添加额外的语言模型,所需数据量更小,节省计算资源。

图5 部分模型参数的热图
表2显示了所提出的预训练方法(传统Conformer)、映射模块(Conformer-add)和联合解码(Conformer-combined)方法在数据集上的性能比较。

表2 实验结果
后两种方法在维吾尔语-汉语数据集上取得了更好的结果。使用Conformer-add,在CER上降低了7.24个百分点,在BLEU上提高了3.7个百分点。使用Conformer-combined,CER值和BLEU 4分数分别为19.78和67.36,从CER和BLEU 4的联合角度来看,Conformer-add效果最好。
表3显示,Conformer-combined比Conformer-add在长文本数据上取得了更好的翻译效果。当实际结果为“尽 管 外 面 寒 风 凛 冽 大 门 前 的 两 棵 云 杉 被 冰 雪 覆 盖 大 厅 里 呼 啸 燃 烧 的 奥 兰 德 式 火 炉 和 六 个 人 参 加 党 组 织 召 开 的 追 悼 会 的 人 都 感 到 热 乎 乎 的”时,使用Conformer-combined与实际结果一致,而使用Conformer-add则漏掉了“寒风凛冽”中的“凛冽”,“热乎乎的”中漏掉了一个“乎”。说明使用Attention机制软对齐时,音频边界分割不清,与其他输出标签混在一起,导致遗漏字现象。

表3 长文本实际效果对比
3.4 交叉检验
为了评估预训练方法的准确性和稳定性,采用了K折交叉验证(K-fold Cross-Validation,KCV),这是一种常用于机器学习的统计分析方法。KCV将原始数据分成K组,抽取1个不重复的子集作为初级验证集,将剩余的K-1个数据子集组合在一起作为训练集[30]。在实验中的维吾尔语-汉语数据集上选择了K=5。如表4所示,将数据集分为F1、F2、F3、F4和F5五个部分,其中一个依次作为验证集,其余四个作为训练集来训练AST模型。总共生成了五个交叉验证数据集D1、D2、D3、D4和D5。

表4 交叉验证数据集
表5显示了预训练方法在五个交叉验证数据集上的语音翻译结果。CER和BLEU的平均值分别为38.44和60.44,CER和BLEU的标准差分别为3.61和2.59,这表明预训练方法在多个实验中表现稳定。
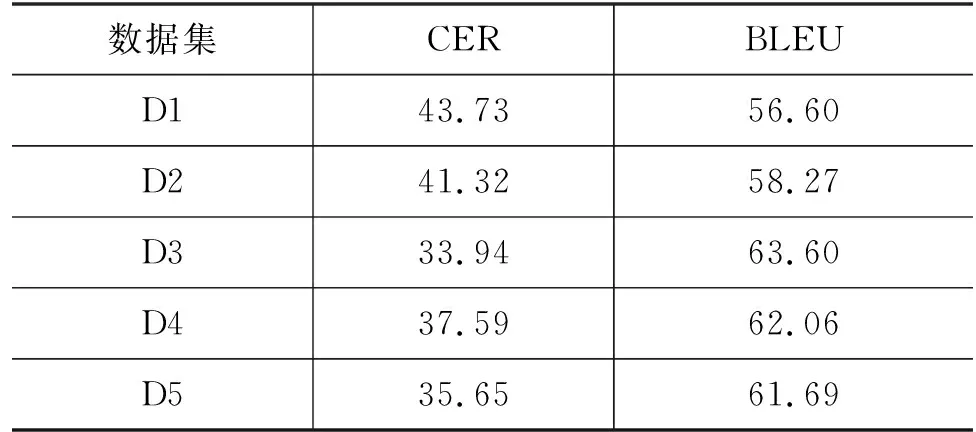
表5 语音翻译结果
4 结论
本文提出了一种构建语音翻译数据集的方法来解决数据稀缺问题。使用目标语言ASR数据集预训练端到端AST模型,获取目标语言信息,然后使用AST数据集微调模型参数。基于所提出的预训练方法,端到端AST模型取得了较好的性能。此外,只需在预训练后替换映射模块以及联合解码,就可以进一步提高模型性能。实验证明与同规模语音翻译相比,本文所提出的预训练方法、替换映射模块以及联合解码可以显著提高语音翻译效果。后续将进一步探索该方法的应用,构建多语言语音翻译系统。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
家庭影院技术(2019年8期)2019-12-04
河南教育·高教(2019年3期)2019-04-11
北方文学(2018年18期)2018-09-14
文理导航(2017年25期)2017-09-07
速读·下旬(2016年7期)2016-07-20
考试周刊(2015年36期)2015-09-10
华南师范大学学报(社会科学版)(2013年1期)2013-12-02
