
基于多特征融合与多语言预训练的藏文文本分类
2023-02-04 08:22胥桂仙马慧麟
中文信息学报 2023年12期
胥桂仙,陈 哲,马慧麟
(1. 中央民族大学 民族语言智能分析与安全治理教育部重点实验室,北京 100081;2. 中央民族大学 信息工程学院,北京 100081)
0 引言
文本分类可以使计算机自动对海量文本信息进行处理,节约大量信息处理费用和人力成本,被广泛应用于信息社会生活的各个领域。目前,基于深度学习的文本分类方法在富文本语言的文本处理上已经取得了良好的应用成果,但对于藏语而言,由于资源的匮乏和公共数据集稀少,导致文本分类的研究进展较为缓慢。目前藏文文本分类已有少量基于规则和传统机器学习方法的分类研究,但将神经网络模型应用于藏文文本分类的研究仍处于最浅显层面,又因为平台上缺乏开源的藏文语料,而每个研究人员所使用的语料也大不相同,因此使得实验研究数据缺乏可比性,其分类准确率难以评估与对比。
本文主要研究多特征融合和多语言预训练的藏文文本分类,基于藏文新闻分类数据集(Tibetan News Classification Corpus, TNCC)进行数据增强,利用少数民族语言预训练模型(Chinese Minority Pre-trained Language Model, CINO)和TextCNN、双向长短时记忆神经网络(Bidirectional Long Short-Term Memory, BiLSTM)提取特征并进行特征融合,实现藏文文本分类。本文提出的模型同时结合了TextCNN和BiLSTM模型,能够在获取局部特征的同时,又有效获取了上下文语义信息,在模型上实现了优势互补。
1 相关工作
目前基于深度学习的文本分类算法大致可以分为三类: 基于卷积神经网络(Convolutional Neural Network, CNN)的文本分类算法、基于循环神经网络(Recurrent Neural Network, RNN)的文本分类算法、基于注意力机制的文本分类算法。
Kalchbrenner等人提出了第一个基于CNN的文本分类模型。该模型采用动态k-max-pooling,因此称为动态CNN(DCNN)[1]。DCNN使用宽卷积层与动态k-max-pooling给出动态池层交替的卷积结构来生成句子上的特征映射,该特征映射能够显式地捕获单词和短语的短期和长期关系。随后,Kim提出一个比DCNN更简单的基于CNN的文本分类模型(TextCNN)[2]。TextCNN仅在从无监督神经语言模型(即Word2Vec)获得的单词向量上使用了一层卷积,利用多个不同尺寸的kernel来提取句子中的关键信息,从而能够更好地捕捉局部相关性。
基于RNN的模型将文本视为一个单词序列,旨在获取文本分类的单词相关性和文本结构。然而,普通RNN模型的性能并不好,往往不如前馈神经网络。在RNN的许多变体中,长短时记忆网络(Long Short-term Memory, LSTM)[3]是最流行的模型,该模型旨在更好地捕捉长期依赖性。LSTM通过引入存储单元以及输入门、输出门和遗忘门来调整信息输入和输出单元,缓解了普通RNN面临的梯度消失或爆炸问题。
注意力机制最早被应用于图像领域中,在2017年才被应用于文本表示任务。Transformer[4]通过应用自注意力机制来并行计算句子中的每个单词,或通过记录“注意力分数”来模拟每个单词对另一个单词的影响。自2018年以来,我们看到了一系列基于Transformer的大规模预训练语言模型的兴起。基于Transformer的预训练模型使用了更深层的网络架构,并在大量文本语料库上进行预训练,通过预测基于上下文的词来学习上下文的文本表示。这些预训练模型使用特定任务的标签进行了微调,并在包括文本分类在内的许多下游NLP任务中创造了新的技术水平[5]。
藏文的文本分类研究还处于较浅显的阶段,周登、贾会强、王勇、群诺等人研究了基于机器学习的文本分类,包括基于N-gram、朴素贝叶斯、逻辑回归模型、支持向量机等方法[6-12]。王莉莉[13]提出了基于多分类器藏文文本分类模型,其中包含深度学习的卷积神经网络、循环神经网络、长短时记忆网络和双向长短时记忆网络;苏慧婧等人实现了基于高斯朴素贝叶斯模型[14]、多层感知机和深度可分离卷积模型[15]的藏文文本分类;李亮[16]提出了基于ALBERT预训练模型。以上模型虽然都取得了较好的分类效果,但大多不是采用公共数据集,由于数据集不同因此无法横向比较各自方法的优劣。尽管在藏文文本分类上已经有了一些较为深入的研究,但相比于中文和英文等富文本语言,针对藏文文本分类的研究还是比较缺乏。
2 藏文文本分类模型
本文模型首先对少数民族语言预训练模型CINO进行微调,通过训练得到基于本文藏文语料TNCC的文本表示,同时结合TextCNN、BiLSTM模型进行进一步特征提取和特征融合,再进行模型学习训练,得到基于多特征融合与多语言预训练的藏文文本分类模型。该模型简称为MFMLP模型(Multi-feature Fusion and Multi-Language Pre-training Model),其结构示意图如图1所示。
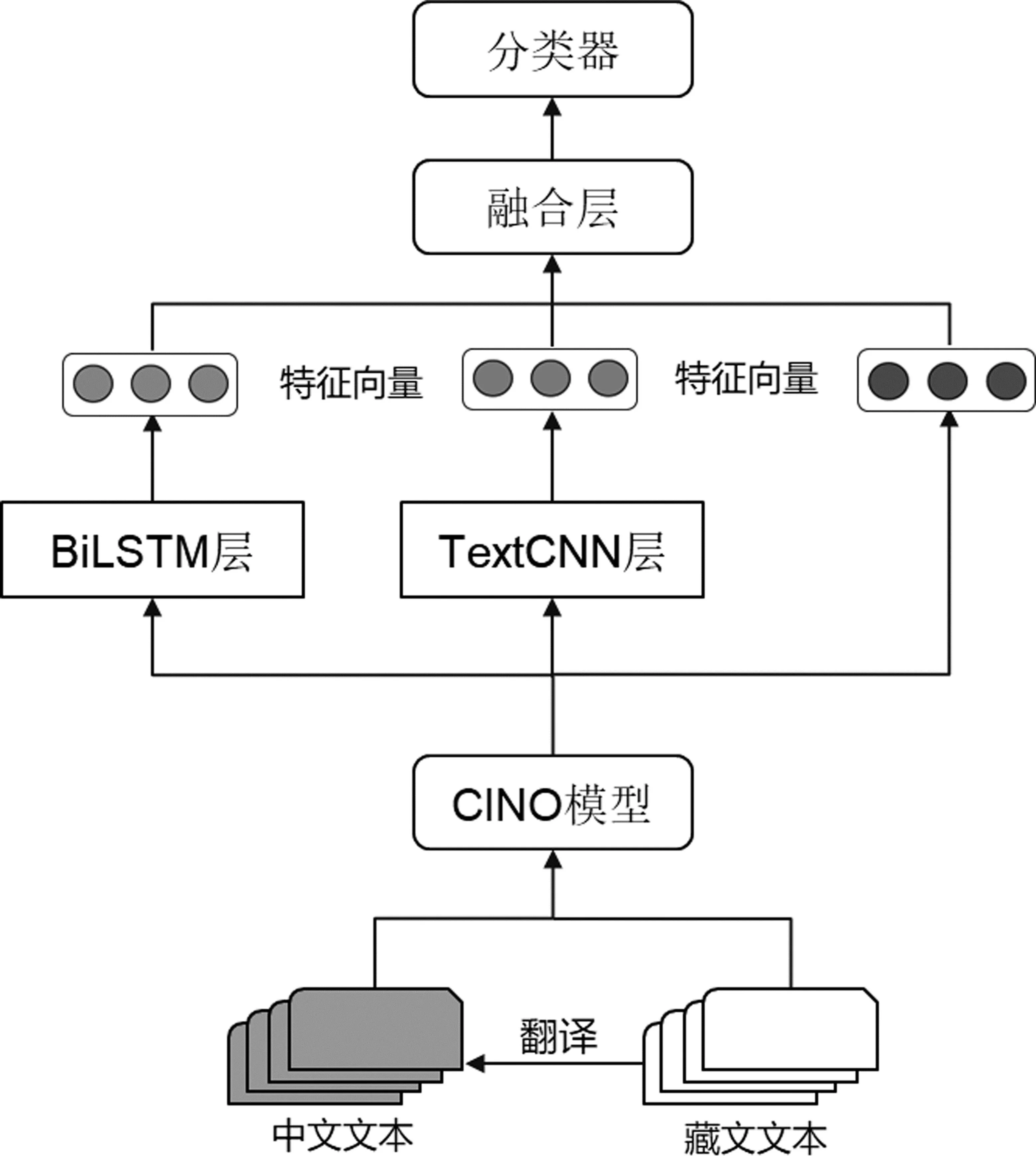
图1 MFMLP模型结构示意图
基于模型各自核心神经网络结构的功能和特点,不同的模型对于文本特征的提取能力和侧重方向也不同。实验证明CINO预训练模型已经具备处理藏文的能力。TextCNN模型适合用来提取藏文文本的深层特征,通过不同尺寸的卷积核获取文本特征,可以使特征更加多样。然而卷积层提取的特征向量经过池化、全连接后进入分类器,无法充分体现特征之间的深层语义联系。相较于TextCNN模型,BiLSTM模型由于具有记忆能力并且适合处理序列数据,能够体现相隔较远的文本之间的相互联系。因此,本文模型通过结合这些模型的优点,在藏文文本分类任务上具有一定优势。
2.1 CINO模型
CINO[17]是哈工大讯飞联合实验室发布的一个多语种预训练语言模型,也是第一个针对中国少数民族语言的多语言预训练模型。CINO涵盖了标准汉语、粤语和藏语、蒙语、维吾尔语、哈萨克语、朝鲜语、壮语六种少数民族语言,并且在藏语上表现较好。实验表明,CINO已经具备了对少数民族语言的理解能力,并优于基准模型。CINO是一个基于Transformer的多语言模型,其模型架构与XLM-R[18]相同。相比于XLM-R模型,CINO模型进行了词汇扩展和词汇修剪。
本文将TNCC藏文数据集翻译为中文后,与原数据集合并为新的数据集,输入到CINO模型中,生成的字嵌入向量作为BiLSTM层和TextCNN层的输入。
2.2 BiLSTM层特征提取
本文采用的数据集为新闻长文本,当文本序列过长时,传统的RNN容易出现梯度消失和爆炸问题,因此LSTM通过引入存储单元和输入门、输出门、遗忘门来控制进出单元的信息流,这样不仅可以解决梯度消失和爆炸问题,还能捕捉单词的长期依赖性。
为了更好地获得文本的语义信息,本文采用双向LSTM模型,分别从前向和后向对文本进行特征提取。文本经过CINO模型中的编码器,得到Encoder的所有输出,将字嵌入矩阵输入到BiLSTM层中进行上下文特征提取,再将前后向的文本信息和词向量进行拼接。BiLSTM层结构如图2所示。

图2 BiLSTM层结构示意图
2.3 TextCNN层特征提取
卷积神经网络在局部特征提取上表现良好,通过不同大小的卷积窗口来捕捉不同的N-gram特征。一段文本包含全局语义特征和不同粒度大小的局部语义特征,因此需要考虑不同粒度下的特征提取。通过设计多种大小的卷积核对文本信息进行特征提取,并将不同粒度大小的特征融合在一起作为最终的局部特征表示。
通过TextCNN的卷积结构可以提取出文本的局部特征,从而有利于文本分类。将CINO模型Encoder结构中的所有输出作为TextCNN层的输入。通过调整不同大小的卷积核尺寸,获得不同宽度视野下的文本局部特征。设置词向量维度为2,3,4的卷积核,对文本序列进行卷积操作。输出的向量通过Relu函数激活,再输入到最大池化层,获得句子的重要信息。将经过池化操作后的特征向量进行拼接,得到TextCNN层的输出。TextCNN的结构如图3所示。

图3 TextCNN层结构示意图
2.4 融合层原理
通过多特征融合的方式可以更加全面地提取文本各方面的语义特征。CINO中内置了藏文和中文分词器,将经过CINO模型后提取的Encoder最后一层的编码向量分别进一步输入到TextCNN模型和BiLSTM模型中提取特征向量,随后与CINO中产生的[CLS]特征信息在融合层进行拼接,再输入到分类器中。
在融合层,CINO输出的[CLS]一维特征向量y1,TextCNN输出的一维向量y2,BiLSTM输出的一维向量y3进行拼接融合生成向量M。
融合层的输出M的公式为:
M=[y1y2y3]
(1)
各通路输出的特征均为一维向量,采用这种拼接融合的方式可以不需要对通路输出的数据进行统一维度,从而避免数据信息损失。
2.5 藏文文本分类模型框架
本文提出的MFMLP模型结合CINO模型提取的[CLS]特征信息以及TextCNN和BiLSTM提取的特征向量,进行融合后的特征将能更好地表示文本特征,从而取得更好的分类结果。
将得到的新的藏文序列输入到分词器中进行文本预处理,再输入到CINO模型中。通过CINO模型处理,得到了Encoder的所有输出和最后一层的[CLS]特征。将Encoder的所有输出并行输入到TextCNN模型和BiLSTM模型中,获取文本信息的深层特征和上下文特征。TextCNN和BiLSTM提取的特征向量和[CLS]特征在融合层进行特征融合,最后将融合的特征输入到分类器中进行文本分类。
3 实验设计与分析
3.1 实验环境配置
论文实验环境描述如表1所示。

表1 实验环境配置参数
3.2 实验语料来源和处理
本文中的实验选用由复旦大学自然语言处理实验室发布的藏语新闻数据集[19]。该数据集收集自中国西藏网,包含12个类别,分别为: 政治、经济、教育、旅游、环境、语言、文学、宗教、艺术、医学、风俗、工具类。该数据集包含两个文本分类数据集: 新闻标题分类和新闻正文分类,本篇论文的实验主要采用新闻正文分类数据集。语料库分为训练集、开发集和测试集。训练集占数据集的80%,开发集和测试集各占10%,其中训练集有7 363条数据,开发集和测试集各920条数据。由于TNCC数据集的文本类别分布不均衡,容易造成模型过拟合,因此本实验采取翻译的数据增强方法,通过将TNCC数据集的每条藏文数据进行藏译中,达到数据扩充和融合多语言信息的效果。扩增后的多语言数据集简称为TCNCC(Tibetan and Chinese News Classification Corpus),TCNCC数据集总共18 406条文本数据,其中藏文数据共9 203条,中文数据共9 203条。
藏文的音节之间用藏文分隔符分开,但分隔符通常只表示占位而不是起着分隔的作用。在基于神经网络的文本分类中,通常采用单词的分布式表示作为输入,但藏文文本处理很难实现单词级分词。主要有两个原因: 一是没有分隔符来标记两个单词之间的边界;二是藏文词汇非常庞大,通常包含数百万个单词,因此对稀有和复杂词的表征很差。因此TNCC数据集在音节和字母级别对藏文文本进行建模,而不进行明确的分词,从而提高对稀有词和复杂词的表征[20]。该数据集已经对藏文文本进行了以音节为单位的分词。文本数据与标签之间用TAB分割,标签数字对应的是不同类别的编号。TNCC数据集藏文新闻正文样例如图4所示。

图4 TNCC数据集藏文新闻正文样例
3.3 评价指标
考虑每个类别的样本数量在总数量中的占比,采用加权平均(Weighted Average)的计算方法。本文使用精确率(P)、召回率(R)、F1值(F1-score)等性能指标作为评价指标。计算如式(2)~式(4)所示。
其中,TP为将正类预测为正类的个数,FN为将正类预测为负类的个数,FP为将负类预测为正类的个数,TN为将负类预测为负类的个数。
3.4 实验对比和分析3.4.1 实验参数说明
为了使模型达到最好的效果,实验对PyTorch版本的CINO-large-v2模型进行了微调。在TextCNN模块,设置卷积核的大小filter_sizes=(2,3,4);卷积核数量num_filters=256,池化操作选取Max-pooling。在BiLSTM模块,设置双向LSTM,正向与反向LSTM均有768个隐藏单元,隐藏层数为2。对TextCNN、BiLSTM和CINO提取的[CLS]特征在融合层进行特征融合,不设置分层学习率,然后输入到分类器中。整体模型参数如表2所示。

表2 模型参数
3.4.2 基于藏文数据的不同融合方式对比和分析
在对比实验中,为了验证多特征融合模型在藏文文本分类上的实验效果,基于TNCC藏文数据集,本文设计了三种融合方式: (1)CINO+BiLSTM: CINO提取的[CLS]特征+BiLSTM,设置分层学习率(LSTM层参数学习率是基学习率的100倍);(2)CINO+TextCNN: CINO提取的[CLS]特征+TextCNN,不设置分层学习率;(3)MFMLP: CINO提取的[CLS]特征+TextCNN+BiLSTM,不设置分层学习率。同时将这三种融合方式与CINO进行微调后的效果进行对比。为了避免偶然性和误差,本文所有实验均进行了五折交叉验证,五次实验结果取平均值。不同融合方式结果对比如表3所示,不同融合方式分类性能对比图如图5所示。
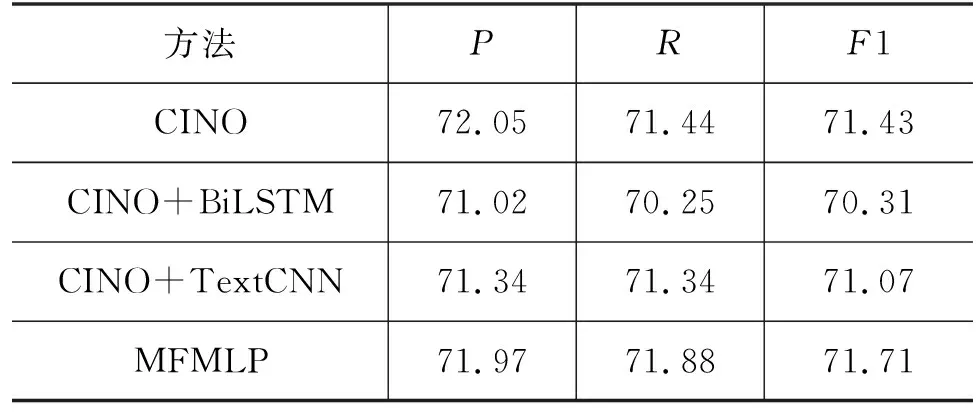
表3 不同融合方式结果对比表 (单位: %)
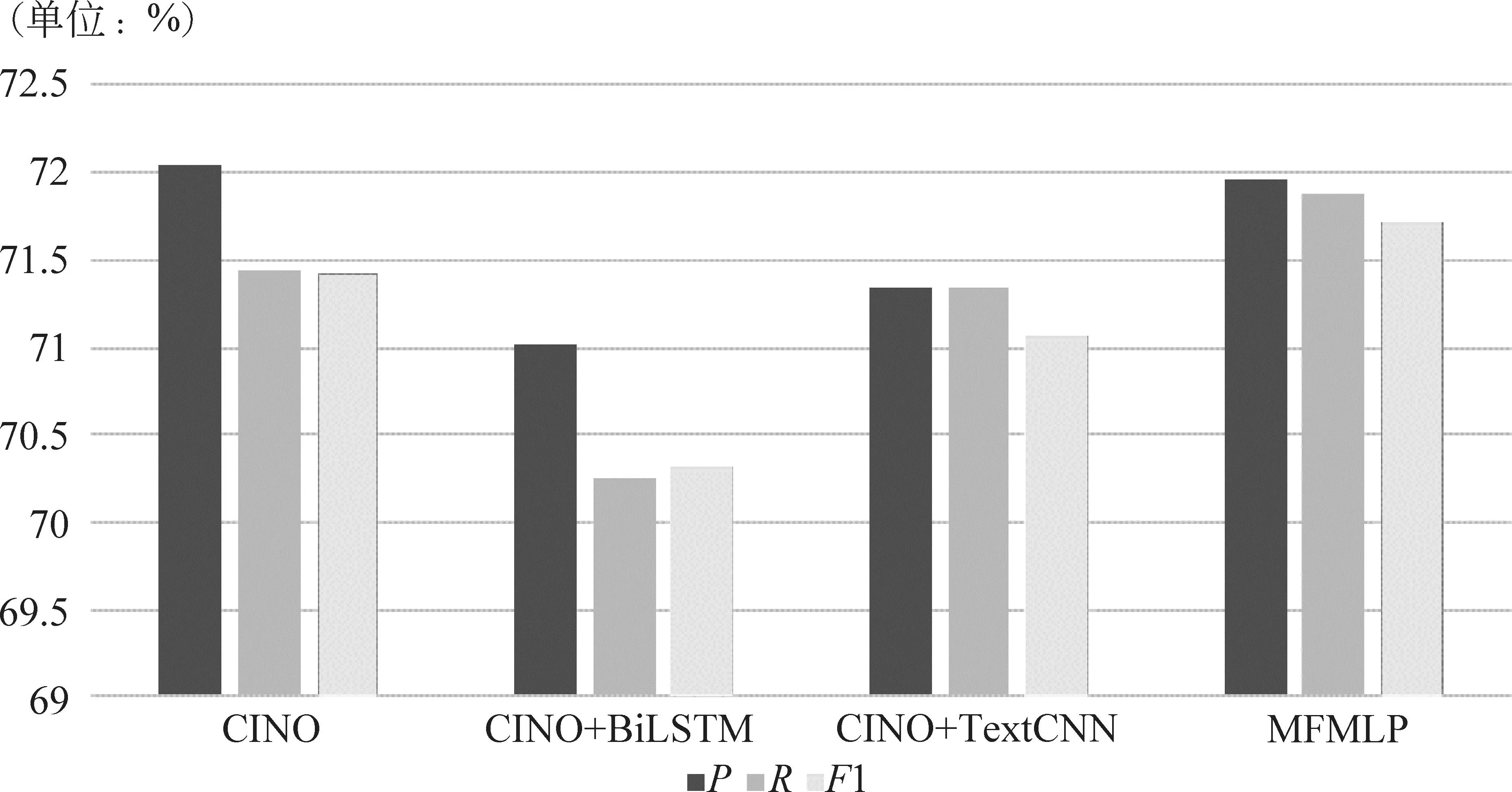
图5 不同融合方式分类性能对比图
根据表3和图5,从不同融合方式对比中可以看出,MFMLP模型在藏文文本分类上的效果最佳。首先将MFMLP模型与CINO基准模型对比,可以看出MFMLP模型的F1值比CINO模型高0.28%,说明CINO融合BiLSTM和TextCNN模型能够有效提取藏文文本的上下文信息和局部特征,对模型效果有提升作用。CINO+BiLSTM模型的精确率、召回率和F1值比MFMLP模型分别低0.95%、1.63%、1.40%,CINO+TextCNN模型的精确率、召回率和F1值比MFMLP模型分别低0.63%、0.54%、0.64%,这两个对比实验证明了CINO+BiLSTM+TextCNN模型在提取藏文文本的全局语义特征的有效性。
3.4.3 基于藏文数据的基准模型对比和分析
为了验证模型的分类效果,使用TNCC藏文数据集将本文提出的模型多特征融合和多语言预训练模型MFMLP与常用的六种模型对比。
TextCNN[2]: Kim在CNN网络中使用一维卷积核来提取文本的N-gram特征,然后通过最大池化保留最重要的特征,通过softmax分类器进行分类。
TextRNN[20]: Liu等提出的一种通用于文本分类的循环神经网络结构,它将单向LSTM最后一个时间步的隐藏层状态向量作为文本的全局语义特征表示,然后将该向量输入到Softmax分类器。
TextRNN_att: 与TextRNN不同的是,引入了注意力层对文本信息附加权重。
TextRCNN[21]: Lai等引入循环卷积神经网络用于文本分类,与TextRNN相比,TextRCNN通过循环神经网络后,又引入了一个最大池化层来捕捉文本中的重要信息。
DPCNN[22]: Johnson等提出的一种类似于金字塔结构的分类模型,通过增加网络深度来提升模型的性能。
Transformer[4]: Vaswani等在机器翻译任务中提出该模型,在文本分类任务中使用Transformer的Encoder结构,提取文本的长距离依赖特征。
基准模型结果对比如表4所示,基准模型分类性能对比图如图6所示。
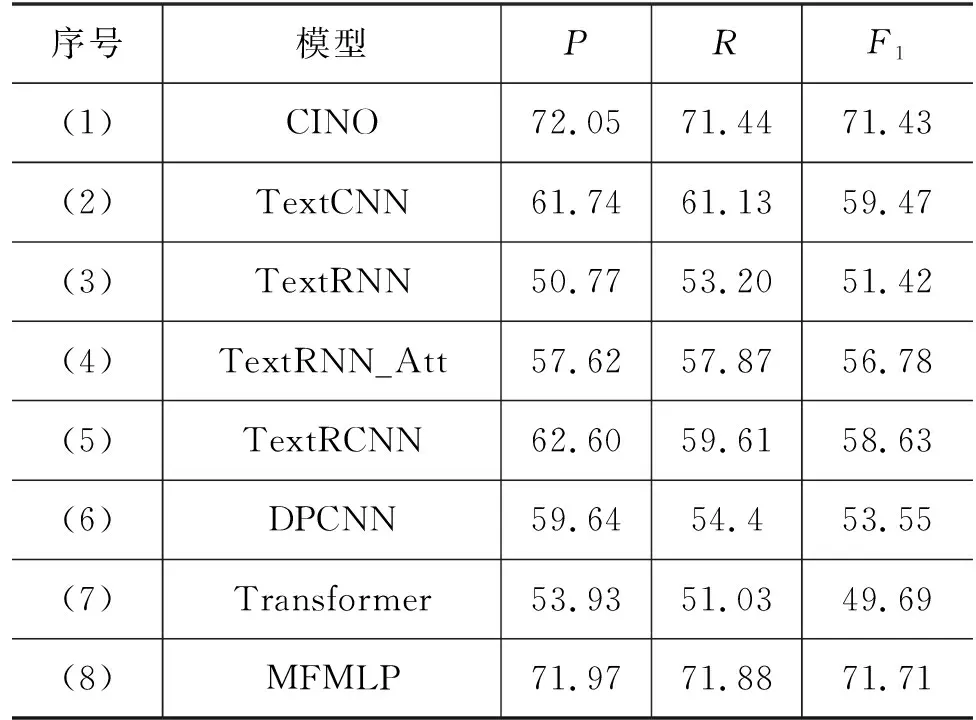
表4 基准模型结果对比表 (单位: %)

图6 基准模型分类性能对比图
依据表4和图6,从各种基准模型对比结果可以看出,本文提出的MFMLP模型在藏文文本分类任务上的F1值最高,达到了71.71%。在表5的(2)至(7)对比实验中均只采用单一模型对藏文文本进行特征提取处理,相较于采用多特征融合方法的MFMLP模型,分类效果不佳,因此采用多特征融合方法提取特征具有明显优势。在前6个基准模型中,实验效果最好的是TextCNN,精确率、召回率和F1值分别达到了61.74%、61.13%、59.47%。比本文提出的MFMLP模型分别低10.23、10.73、12.24个百分点,从而证明本模型融合CINO、TextCNN和BiLSTM模型提取的文本上下文语义特征和多粒度的文本局部特征能够有效提升藏文分类效果。
3.4.4 基于多语言数据的不同模型效果对比
经过实验发现,TNCC藏文数据集存在类别分布不均衡的问题,可能会造成模型过拟合,因此将TNCC数据集进行数据增强。采用数据增强中的翻译法,将藏文文本输入到翻译器进行藏译中处理,再将得到的中文文本合并到原藏文数据中得到新的数据集TCNCC,解决了藏文数据集稀缺和一些类别样本过少的问题。同时将数据进行翻译可以使数据既保留了藏文语义特征,又拓展了中文语义特征,实现多语言训练。
为了验证不同模型在数据增强后数据集上的效果,本节基于TCNCC数据集,对上文提到的不同融合方式和不同基准模型进行对比,各个模型取F1-score作为评测指标。基于多语言数据的模型效果对比图如图7所示。
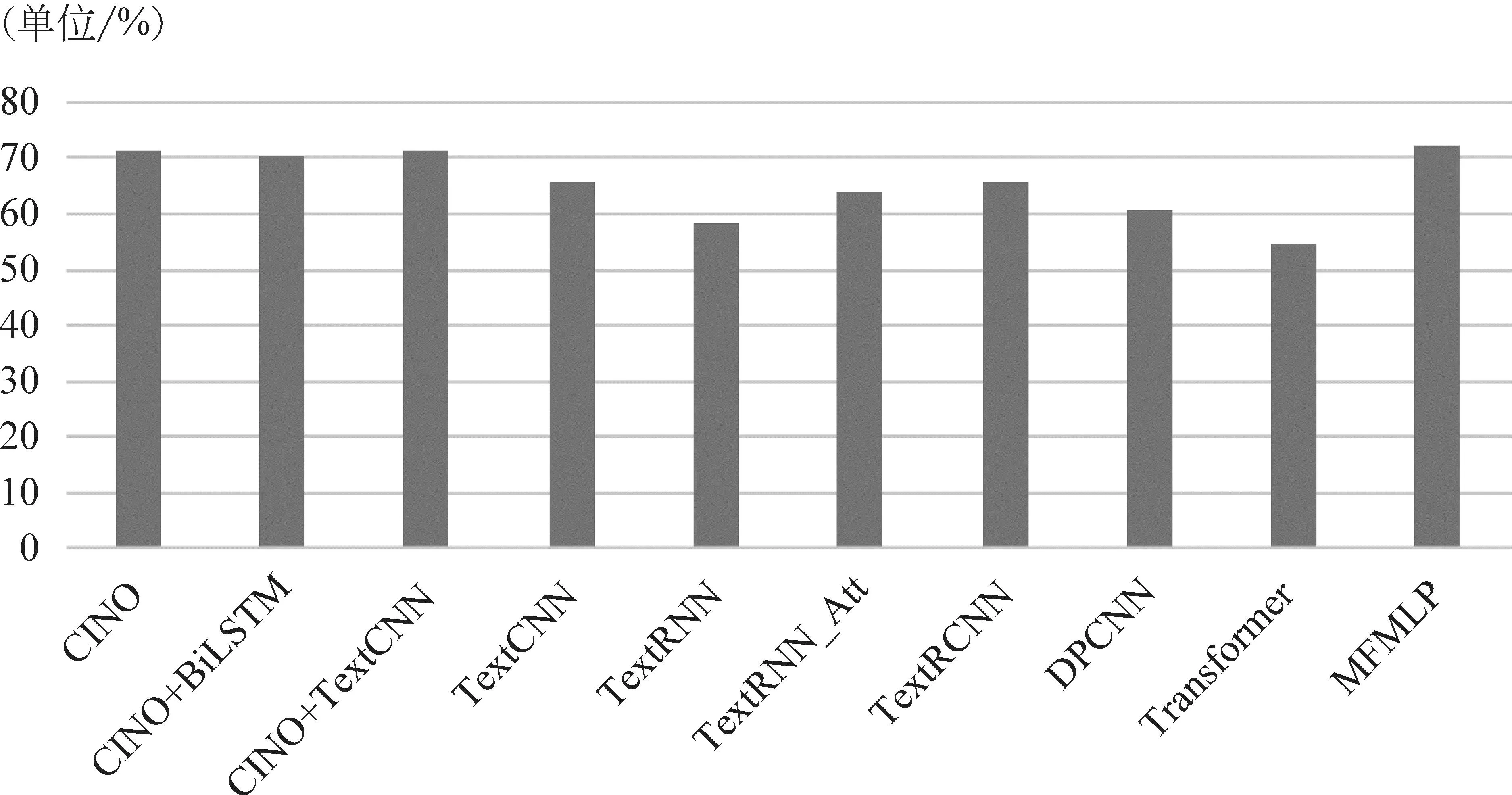
图7 基于多语言数据的模型效果对比图
由图7可以看出,在数据增强后的多语言数据集TCNCC上,本文提出的MFMLP模型效果最佳,达到了72.11%,体现了MFMLP模型在多语言数据集上的优势。
3.4.5 多语言数据增强效果对比和分析
基于数据增强后的数据集训练模型使模型包含多语言信息,为了验证数据增强的效果,基于数据增强前的TNCC数据集和增强后的TCNCC数据集,本节对上文提到的不同融合方式和基准模型的效果进行对比,各模型取F1-score作为评测指标。对比结果如图8所示。

图8 各模型数据增强前后对比图
从图8中可以看出除CINO模型外,经过数据增强后,各模型的F1值都有一定的提高。其中各基准模型效果提升较大,相较于未增强的藏文原始数据集TNCC,基于数据增强后的多语言数据集TCNCC训练的模型F1值都提升了5个百分点以上。由于数据增强实现了数据的扩充,融合了多语言信息,而基准模型未经过预训练,因此分类效果提升比较显著。基于数据增强后的数据集,不同融合方式的模型效果也实现了小幅度提升,体现了数据增强方法的有效性。相较于数据增强前,MFMLP模型的F1值达到了72.11%,比增强前提升了0.40个百分点。由于翻译法的数据增强依赖于翻译器的性能,本实验采取的小牛翻译器在翻译过程中产生了许多噪声,对CINO模型的分类效果产生了一定影响,使得CINO模型数据增强前F1值略高于数据增强后。
实验结果表明经过数据增强后融合了多语言特征,对预测结果有一定的提高效果。但由于翻译法依赖翻译器性能,小牛翻译在翻译过程中产生的噪声会对实验效果产生影响,因此数据增强的效果不太明显,为以后实验提供了改进方向。
本文使用了少数民族多语言预训练模型CINO,使模型对藏文具有良好的理解能力。在经过对CINO原模型的微调后,提高了该模型对藏文的理解能力,为后续的多特征融合打下了良好的基础。其次,本文提出的模型同时结合了TextCNN和BiLSTM模型,能够在获取局部特征的同时,又有效获取了上下文语义信息,在模型上实现了优势互补。因此,在与基准模型对比时,本文模型的分类效果达到了最佳,说明本文提出的MFMLP模型在藏文文本分类任务中具有一定优势。
4 结论与展望
针对藏文数据集稀缺的问题,为了有效获取文本的关键信息,本文提出了基于多特征融合与多语言预训练的藏文文本分类模型。在对TNCC数据集进行数据增强后,数据实现了扩充并融合了多语言知识。在模型构建过程中,首先使用CINO模型对数据集进行预训练,提取出所有特征向量和最后一层的[CLS]特征,然后将所有的特征向量分别输入到TextCNN和BiLSTM模型中,将获取到的特征与[CLS]进行拼接融合,最终输入到分类器中进行分类,从而实现藏文文本分类。
本文的多特征融合和多语言预训练模型相比于CINO模型和其他基准模型的分类效果取得了一定程度的提升,但仍存在一些不足。数据增强效果并不明显,这是由于翻译的质量不高,但这也为后续研究提供了思路和改进空间。根据模型分类效果可以看出,分类还存在着一定的错误,并且由于藏文数据集的稀缺性,只在TNCC数据集上进行了验证。未来工作将在此基础上进行进一步的深入研究。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通(1-2年级)(2021年4期)2021-06-09
布达拉(2020年3期)2020-04-13
电子制作(2019年11期)2019-07-04
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
西夏学(2019年1期)2019-02-10
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
北京航空航天大学学报(2018年1期)2018-04-20
初中生世界·七年级(2017年9期)2017-10-13
西藏大学学报(自然科学版)(2016年1期)2016-11-15
