
糖尿病电子病历实体及关系标注语料库构建
2023-02-04 09:26叶娅娟张坤丽昝红英
中文信息学报 2023年12期
叶娅娟,胡 斌,张坤丽,昝红英
(郑州大学 计算机与人工智能学院,河南 郑州 450001)
0 引言
随着电子信息技术的发展,医疗服务模式由被动接受转为主动获取,如何从海量医疗信息中获取有用的信息成为当下研究的热点。命名实体识别和实体关系抽取是信息抽取中的重要任务,对信息抽取技术的研究与应用都有重要意义。中文电子病历命名实体识别任务的识别目标主要包括检查、手术、疾病、症状、药物、部位等。实体关系抽取是从非结构化的文本中抽取结构化信息,其主要任务目标不仅仅是抽取文本中的实体关系,更重要的是判断实体间关系的类型,如“患者糖尿病3年,给予二甲双胍治疗,血糖控制可”,实体关系抽取需要抽取出“糖尿病”与“二甲双胍”之间的关系为“治疗改善了疾病”。电子病历作为医疗信息的重要来源,研究电子病历实体识别及实体关系抽取对促进医疗行业的发展具有重大意义。
此外,随着我国居民生活方式的变化,糖尿病已成为流行病,且逐渐呈年轻化趋势,我国成年人患病率高达11.2%,其中2型糖尿病患者约占我国糖尿病患者总数的90%。近年来,国内外陆续发布更新多项预防、治疗糖尿病及并发症、合并症指南及专家共识,促进了糖尿病防治工作的规范化[1]。刘勇等[2]以《中国2型糖尿病防治指南(2017年版)》内容为核心,结合电子病历、医学指南、医学词典等基础数据,构建了基于糖尿病防治的医学知识图谱,促进了糖尿病医学知识的共享、传播和利用。尽管糖尿病防治工作已经得到了自然语言领域众多学者的关注,但是由于非结构化的医学文本具有实体类型复杂、实体关系密度高、对具体关系描述连续等特性,以及目前公开的语料库仍然比较缺乏,这些在一定程度上阻碍了其研究工作的进展。
临床电子病历是进行医学研究的重要数据来源,其真实性和严谨性被大众普遍认可。因此本文采集了糖尿病电子病历数据,制定了糖尿病电子病历实体及关系标注规范,采用多轮迭代的标注模式,构建了糖尿病电子病历实体及关系标注语料库,为电子病历命名实体识别和关系抽取以及糖尿病知识图谱的构建提供数据支撑。本文组织结构如下: 第1节介绍相关研究;第2节概述糖尿病电子病历实体及关系标注体系;第3节阐述语料库的构建过程及构建结果;第4节是进行初步实验,对语料库进行评估;最后一节是结语。
1 相关研究
近年来,国内外众多学者聚焦于语料库构建的研究。在医学领域,国外著名医学本体库有SNOMED、IBM Watson Health和CT[3]等。2006年Meystre等人[4]构建了包含80种常见医疗术语命名实体标注语料,该语料共含有 160 份文档,文档类型包括病程记录、出院小结等。2008年美国梅奥诊所构建了160份医疗文档规模的命名实体语料,对其中的疾病实体进行了标注,并首次对实体和实体关系的修饰信息进行了细致的分类,该语料包括住院记录、门诊记录以及出院小结3种类型[5]。2009年Roberts等人[6]构建了两万份癌症患者病历的标注语料,并详细介绍了语料库的标注和构建方法,其研究主要用于对从患者病历中自动提取临床重要信息的系统开发和评估。2010年I2B2组织了关于抽取概念、概念的修饰及关系的评测任务,发布了394份训练语料和477份测试语料[7]。另外,Mizuki等[8]组织了在日文电子病历上进行命名实体识别的TCIR-10MedNLP任务,发布50份病历标注语料。2014年Névéol等[9]采用机器标注和人工校对的方式构建了涉及15类实体的命名实体标注语料,共包含2 500篇医学文章。2017年Campillos等[10]构建了500份文档规模的法语命名实体及实体关系语料库,文档类型包含出院小结、程序报告、医生来信和处方,对11类实体和37类关系进行了标注。
相比较于英文及日文医疗语料,中文医疗语料库的构建起步较晚。Lei等[11]收集了北京协和医院800 份电子病历并由两位医生参考I2B2 2010标注规范进行标记,该语料包含4类实体,把治疗细分为药物和过程,初始语料包括入院小结和出院记录各400份。Wang等[12]采用复旦大学附属中山医院的115份肿瘤患者的手术记录作为语料,由3位医生参与制定标注体系,定义12种实体类型,共标注961个实体。有关医疗命名实体标注体系较多,但规模较小,覆盖的医疗概念实体少。Wang等[13]于2014年构建了医学症状名的语料,包含11 613条,标注工作由在职医生完成。2016年杨锦锋等[14]结合中文电子病历中命名实体的特点,制定了中文电子病历命名实体和实体关系详细标注规范,涉及5种实体类型、6种关系类型,通过手工标注构建了标注体系完整、规模较大的中文电子病历标注语料库,语料库包含了992份病历文本。昝红英等[15]将儿科经典教材作为初始语料,以儿科疾病为中心,涵盖11类医学实体,45种子关系的命名实体和实体关系标注体系。2018年,阿里云举办的天池大赛,提供的糖尿病数据集共包含84个特征、1个0-1标签的1 000条妊娠糖尿病样本,通过数据挖掘和机器学习的方法预测出有高风险患妊娠糖尿病(Gestational Diabetes Mellitus, GDM)的患者。2020年Chang等[16]以中文糖尿病领域专家共识为数据来源构建了中文糖尿病科研文献实体关系数据集(Diabetes Dataset for Medical Knowledge Graph Construction,DiaKG),主要包括对医学实体及实体关系的标注。
经过调研,目前已经存在的电子病历实体和实体关系语料库存在以下问题: ①电子病历标注语料的来源不完整,仅包含入院记录、首次病程、查房记录、出院小结和出院医嘱等多类文档中的其中几类; ②标注语料来源于某个科室或者多类科室,缺乏针对糖尿病电子病历所构建的数据集。因此,本文筛选了完整的糖尿病电子病历数据进行标注,并完成了语料库的构建、分析与评估。
2 糖尿病电子病历实体及关系标注体系
2.1 标注体系
对糖尿病电子病历进行分析的过程中发现,有一些身体部位与其对应的症状之间存在一些修饰词,且修饰词与症状之间存在一对多的关系,如“全腹无压痛、反跳痛及肌紧张”,否定修饰把身体部位与症状隔开了,如果只标注后面的“压痛”“反跳痛”和“肌紧张”则与原文表达意思有出入,因此本文添加了身体部位的标注,当身体部位与症状之间存在其他词时,需要对身体部位进行标注,身体部位与后面的多个症状建立位置关系,为了使得标注的信息更全面,修饰词“无”需要与“压痛”“反跳痛”和“肌紧张”分别建立否定修饰关系。此外,电子病历数据中的时间也是很重要的一类实体,糖尿病是一种慢性病,病历文本中的时间对糖尿病的分析起着较为重要的作用,本文把时间划分为时间段和时间点两个子类,并将时间与疾病和症状分别建立修饰关系。
通过对糖尿病电子病历的分析,并参考I2B2 2010评测数据[7]以及国内外已有的医学领域标注语料实体及关系分类,在医生的指导下,制定了糖尿病电子病历实体及关系标注体系。所制定的标注体系包含的实体主要有疾病、症状、检查、治疗、部位五大类,考虑到治疗方式对疾病的影响不同,将治疗分为药物治疗、手术治疗以及其他治疗。
在实体分类的基础上,本文将关系划分为治疗-疾病、治疗-症状、检查-疾病、检查-症状、疾病-症状和部位-症状6类关系,具体的子分类如表1所示。
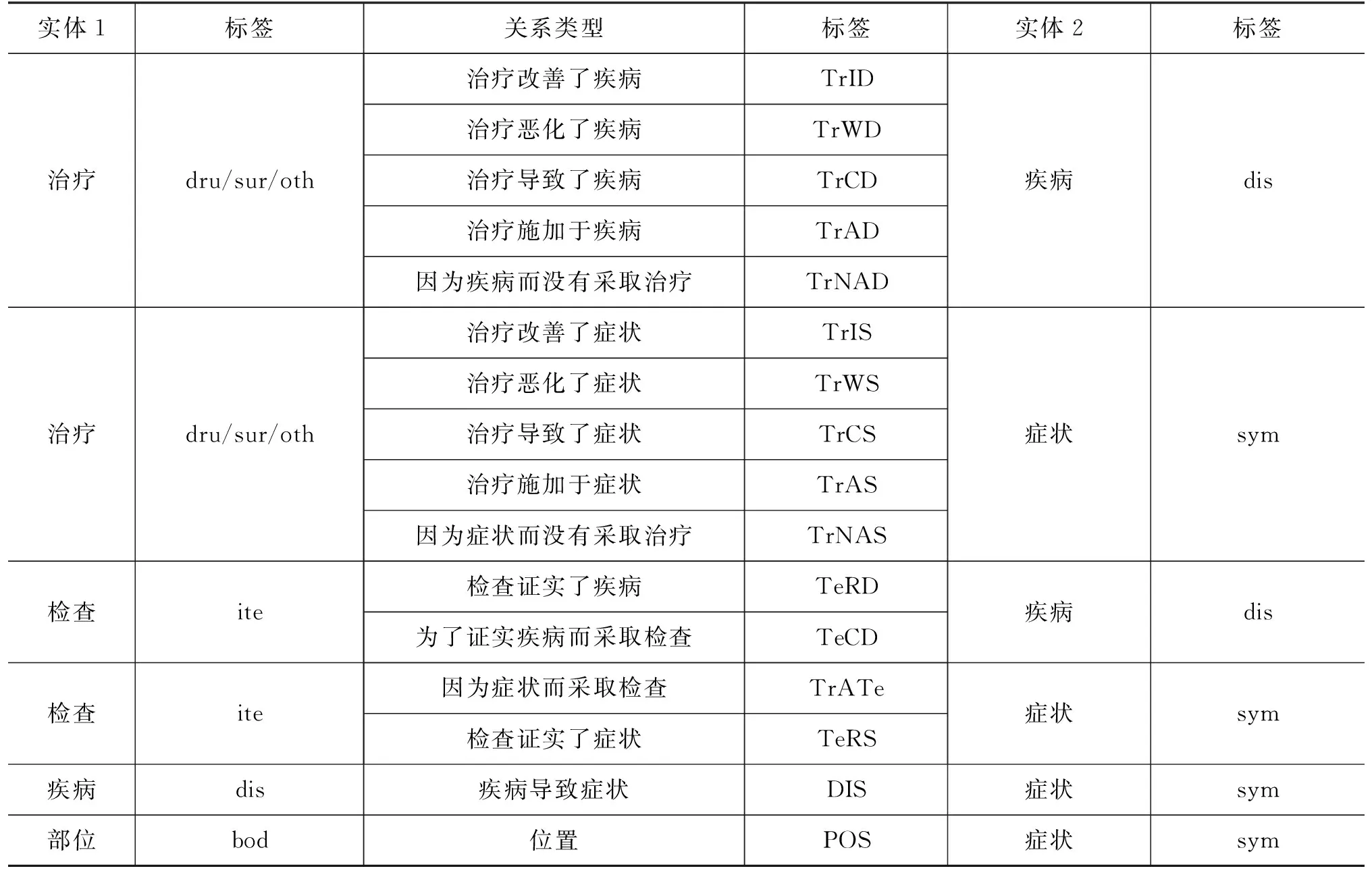
表1 实体关系分类
修饰识别(Modifier Recognition)是电子病历信息抽取过程特有的任务,指在给定病历文本中的疾病、症状等特定类别实体的情况下,从文本中识别出这些实体的修饰成分的过程。本文的处理方式是标注实体时,将修饰词标注为修饰,将修饰类型作为一种关系建立在修饰词与被修饰实体之间,此时,修饰识别转化为了修饰关系抽取,方便进行语料库的评估以及后续研究。本语料库共包含疾病修饰、症状修饰和治疗修饰3类,其中症状的修饰划分为11类,疾病的修饰划分为9类,治疗划分为3类。表2是具体的修饰类型说明。

表2 修饰分类
2.2 标注准则
命名实体所遵循的标注规则: ①不重叠标注,即同一字符串不能标注为两种不同的实体类型。②不嵌套标注,即一个实体不能在另一个实体的内部。③实体尽可能不包含标点符号(、,。: ;)以及连接词(或、和、以及)。
实体修饰会存在一些符号,比如“?”是指“可能的”,因此为了保证标注信息的完整性。本文中实体修饰标注所遵循的标注原则: ①遵循命名实体标注规则。②允许标注“?”“+”及“-”等符号。
实体关系所遵循的标注原则: 优先标注句内关系,若同句内不存在实体关系,允许跨句标注。
2.3 特殊情况处理
2.3.1 修饰词与实体之间关系数目的界定
在糖尿病病历文本中,修饰词与实体之间存在一对多或者多对一的情况,为了保证标注的信息更全面,本文的处理是一个实体允许标注多个修饰关系,一个修饰词也可与多个实体建立修饰关系。但如果一个实体存在两个类似的修饰词,则只标注其中一个。
例11天前无明显诱因出现双手麻木,为间断性。
该样例中,“双手麻木”为症状,“1天前”和“间断性”均为修饰词,“1天前”用来界定症状发生的时间,“间断性”用来表示症状的性质,二者均为“双手麻木”的修饰词,均需要标注。
例2口渴、多饮、多尿7年,测空腹血糖12.0 mmol/L,口服降糖药物二甲双胍片0.5g 3次/日,未控制饮食及运动,空腹血糖波动在12~13 mmol/L。
该样例中的“7年”修饰“口渴”“多饮”“多尿”三个实体,表示症状持续的时间,标注时需要将“7年”分别与“口渴”“多饮”“多尿”建立修饰关系。
例3体型肥胖,2型糖尿病可能性大,青年患者不排除1型糖尿病可能性大。
2.3.2 患者拒绝医生的建议的标注界定
如果出现患者拒绝某种治疗,后续的结果与该治疗无关,因此本文的处理是,病历文本中所提到的治疗实体无须标注。
例4患者双肺多发磨玻璃密度结节,请呼吸科会诊,建议在CT引导下型肺穿刺活检术,患者拒绝,要求暂查血真菌感染等相关指标。
该样例中的“肺穿刺活检术”和“CT”则不需要标注。
2.3.3 身体部位的作用范围及标注说明
部位是症状的重要信息,无法把二者严格分开,所以需要根据上下文,确定症状和部位是否合并。如果症状和部位直接相邻没有被标点符号隔开的话,就把症状和部位合并到一起标注为一个完整的症状,否则需要标注部位和症状。
例5头颅无畸形、压痛、包块。
6月冷气团依然较为活跃,但暖气团逐渐占据主导地位。高空槽东移,中低层有切变或急流配合,地面有倒槽或低压存在是6月份最常见的天气系统配置(表3),23次暴雨过程中有8次是这样的天气系统配置造成。另外东北冷涡与地面倒槽或低压的配合也是常见和典型的系统配置,此时低空急流的强度在一定程度上影响着降水量的大小,分析时段内东北冷涡和地面倒槽或低压引起的暴雨过程共4次,降水量和对应的低空急流大小分别为100.1 mm(低空急流轴强度为16~22 m/s),99.8 mm(低空急流轴强度为16~20 m/s),76.6 mm(低空急流轴强度为14~16 m/s),55.9 mm(低层风速未达到急流标准)。
该样例中,首先是否定修饰词“无”分别与 “畸形”“压痛”“包块”建立修饰关系,“头颅”表示身体部位,其作用范围除了“畸形”之外,还包括“压痛”“包块”,该情况下,本文的处理是将部位“头颅”与后面的三个症状分别建立位置关系。
3 语料库构建过程及构建结果
3.1 数据预处理
本文构建语料库的初始语料来自于临床电子病历,最初获得的电子病历数据主要包括病程记录、入院记录、患者病情评估、手术记录、其他记录和知情文件六种类型。对该批数据进行分析,保留后缀为“入院记录”“病程记录”“其他记录”的文件,其中一位病人的病历文件中包含“入院记录”和“病程记录”各一份,“其他记录”四份。
对“入院记录”“病程记录”“其他记录”这三类数据进行内容和格式分析,其中“入院记录”无须进行处理,对“病程记录”“其他记录”这两类数据的处理方式如下:
(1) “病程记录”包含首次病程记录和查房记录,其中一些数据存在噪声、不完整或者不一致的问题。首先将“病程记录”拆分为“首次病程记录”和“查房记录”,并过滤掉一些标记信息,对不完整的数据进行补充,对不一致的数据进行纠正。此外,还会存在一些属性值超出了限定范围、格式及标点符号的问题,需要对此类数据进行一定的修改或删除。为了方便后续标注,还需要对病历文本进行了统一的格式处理。
(2) “出院记录”包含“出院小结”及“出院医嘱”,都包含在“其他记录”中,每份电子病历中有四份“其他记录”,“出院医嘱”较为典型的是包含用药指导关键词。“出院小结”较为典型的是包含患者基本信息及入院日期、出院日期、诊疗经过等信息。仅将“其他记录”中的“出院小结”和“出院医嘱”保留进行标注,另外两份“其他记录”则删除。
对原始电子病历数据分析发现,存在缺失的情况,因此需要进行数据的筛选,筛选出完整的电子病历数据。共筛选出糖尿病电子病历文本800份,其中包括“入院记录”“病程记录”各200份,“其他记录”共400份。在标注之前需要将筛选好的电子病历数据进行去隐私化,病历文本包含患者和医生的隐私信息,隐私信息主要包括患者的姓名、证件号码、家庭住址、工作单位,医生的隐私主要是姓名,文本中出现的医疗机构名称也是隐私信息。本文主要参考文献[17]的方法进行数据去隐私化。
3.2 标注平台及标注过程
为了提升标注人员的标注效率,对张坤丽等[18]开发的实体关系标注平台进行二次开发部署,使之适用电子病历实体及关系的标注,如图1所示。在标注平台上标注人员可以选中不同的电子病历实体及关系进行标注,其中不同类别的实体使用不同的色块表示,方便区分,两个实体之间的关系显示在二者之间。平台提供了文件管理功能,可以查看一标、二标等完成进度情况,方便进行多轮标注工作。此外,平台提供标注数据的即时分析功能和标注对比报告的生成功能,方便用户在标注的同时把握标注质量。

图1 标注平台
本文进行的实体关系的标注建立在实体标注的基础之上,考虑到实体标注的质量会影响到关系标注的质量,因此,本文的标注分为两个过程,先进行实体的标注,实体标注完成之后,再进行实体关系的标注,并将每个过程分为预标注和正式标注两个阶段。
在预标注阶段,组织标注人员学习标注规范,同时组织标注人员进行预标注,目的在于熟悉电子病历实体及关系标注规范,以及收集在实际标注电子病历文本中发生的问题。两轮预标注后,经过与医学专家讨论,进一步对标注规范进行完善,使标注规范更贴近本次研究任务,为正式标注打下基础。
在正式标注阶段,标注过程采取多轮迭代模式,即每一份电子病历文本由两名标注人员负责。一标人员完成标注任务后,记录存在疑问的地方,接着由二标人员在此基础上进行标注并且记录不一致和不确定的地方,与医学专家商量讨论后获得统一的解决方案。讨论之后再由一标人员负责修改语料,形成最后的三标文件。在这个阶段,会根据标注人员标注时的反馈意见修正标注规范,使标注规范更加适用于电子病历文本。具体流程如图2所示,为了对标注结果有更直观的展示,在标注流程之后加入了原始语料与标注之后的语料对比图,其中“text”为原始文本,“spo_list”为标注的内容。

图2 实体及实体关系标注流程及标注结果
3.3 语料库统计与分析
经过多轮迭代标注,将标注好的数据进行处理并统计,所构建的DEMRC中实体及实体关系数目如图3、图4所示,从实体数目来看,症状将近占据总实体数的37.90%,其次是检查与疾病分别占实体总数的21.90%和11.10%,从关系数目来看,“检查-症状”和“药物治疗-疾病”这两类关系最多,这是因为临床电子病历数据中存在大量否定修饰的症状,大多出现在检查部分,此外,糖尿病存在一些并发症等。

图3 DEMRC实体数目统计

图4 DEMRC实体关系数目统计
语料库构建一般选用Kappa值[19]和F1值[20]作为标注一致性的评价指标。在人工构建实体或关系标注语料库构建的研究中,通常使用F值计算标注一致性[21],具体做法是,将一标人员(A)的标注结果作为标准答案,计算二标人员(B)标注结果的准确率(P)、召回率(R)以及F1值。在将独立标注语料与最终语料比较时,将A视作最终语料,即为标准答案,独立B视为标注语料。
对本文构建的糖尿病实体及关系标注语料库进行一致性计算,通过统计我们构建的语料库的命名实体识别一致率达到了0.856 2,实体关系一致率达到了0.941 6,表明本文构建的语料库是可信赖的[22]。
4 实体及关系抽取初步实验
为了分析语料库对模型性能的影响,对本文构建的DEMRC分别进行了实体识别及关系抽取初步实验,并根据实验结果对所构建的语料库进行详细评估。
4.1 实体识别实验结果与分析
针对实体识别任务,使用序列标注模型T-Bi-LSTM-CRF[23]进行实验,将标注好的数据进行分句和去重处理,将10 484条实体标注数据按照8∶1∶1随机进行划分,8 389作为训练集,1 048条作为验证集,1 047条作为测试集,并将数据转换为序列格式。整个网络初始的学习率为3e-3,字向量维度为100,批量的大小为32,Dropout比率为0.5,采用Adam优化算法进行40轮训练。表3为语料库中各类实体的实体识别结果。
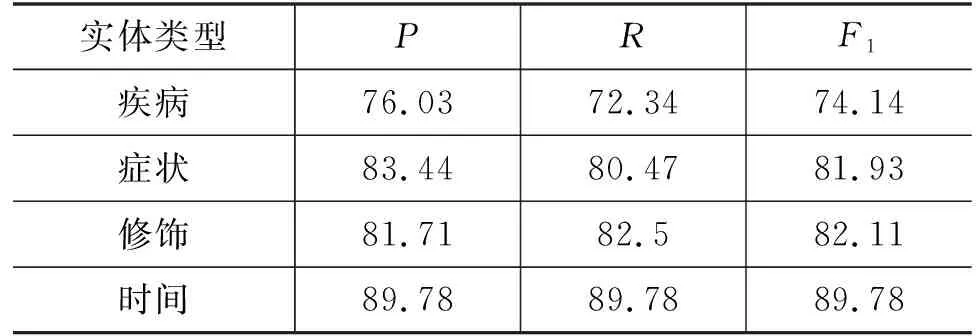
表3 T-BiLSTM-CRF实体识别结果 (单位: %)
通过表3可以看出,时间的识别属于通用领域的命名实体识别任务,识别效果最好,其次是药物治疗、检查和身体部位的识别,因为这三类实体的实体边界相对确定,而疾病、手术治疗和其他治疗的识别效果较差,这与我们在标注语料时的情况相似,手术治疗和其他治疗的数量较少,标注时容易漏标,而有一些疾病与症状不太容易区分而被误标。
4.2 实体关系抽取实验结果与分析
针对实体关系抽取任务,本文使用RoBERTa[24]模型进行实验,主要是采用RoBERTa作为预训练模型,进行头实体预测、融合头实体向量以及尾实体及关系预测。整个网络初始的学习率为3e-5,字向量维度为310,批量的大小为16,Dropout比率为0.5,进行30轮训练。对标注好的数据进行预处理,将最终得到的6 380条实体关系标注语料数据按照 8∶1∶1的比例划分,5 104条作为训练集,638条作为验证集,638条作为测试集,表4为实体关系实验结果。

表4 实体关系实验结果 (单位: %)
从表4可以看出,修饰-疾病、时间-疾病、药物治疗-症状、时间-症状以及修饰与症状之间的关系抽取效果较好,针对修饰-疾病和修饰-症状,是因为疾病和症状中存在大量的否定修饰,时间-疾病和时间-症状之间的修饰关系中,仅包含既往和持续两类修饰关系,因此这类关系较好识别,对于药物治疗-疾病之间的关系,从图4的数据统计可以看出,语料中此类关系数据量较大,模型可以得到很好的训练,故识别效果较好,这些和人工标注时的情况一致。
针对关系抽取效果较低的关系类型,对语料进行分析发现,主要存在以下原因,一方面是标注数据的问题,在原始语料中该类实体关系较少,模型不能得到很好的训练,从而导致关系抽取效果较差。另一方面,关系抽取不仅仅是预测出实体对之间存在关系,还需要预测出关系是什么,对于数据量少,但关系子类较多的实体对,由于子类关系之间会存在一定的相似性,从而会增加模型从多个候选关系中抽取出正确关系的难度。
根据实体识别及关系抽取初步实验,可以根据实验结果对人工标注过程进行调整,比如对于识别效果不好的几类关系,分析其特点,对标注人员着重进行培训,以此来提高标注的质量。通过以上的实验结果可以看出,数据量的大小会影响模型的性能,未来将会考虑如何提升少样本数据的关系抽取效果。
5 结论
本文在对糖尿病电子病历特点进行分析的基础上,并参考I2B2 2010的类型定义,制定了标注规范,遵循这一规范,建立了糖尿病电子病历标注规程以及标注一致性控制方案。本文重点介绍了糖尿病电子病历实体及关系标注体系和语料库的构建过程,经过对糖尿病电子病历标注方案的不断完善及多轮标注,该语料库已完成8 899个实体、456个实体修饰及16 564个关系的标注。在此基础上,对该语料库进行一系列的数据统计和标注一致性分析。并利用T-BiLSTM-CRF模型和RoBERTa模型分别对糖尿病实体及实体关系语料库进行评估,为今后的电子病历信息抽取研究以及糖尿病知识图谱构建打下基础。
猜你喜欢
趣味(语文)(2021年9期)2022-01-18
作文周刊·小学一年级版(2021年48期)2021-01-04
数学小灵通·3-4年级(2020年9期)2020-10-27
少年文艺·开心阅读作文(2018年1期)2018-01-19
海外华文教育(2016年1期)2017-01-20
中国卫生(2016年10期)2016-11-13
当代教育理论与实践(2015年9期)2015-12-16
中国卫生(2015年10期)2015-11-10
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
