
基于多任务学习的多罪名案件信息联合抽取
2023-01-29 13:19王卓越陈彦光邢铁军孙媛媛林鸿飞
计算机工程与应用 2023年2期
王卓越,陈彦光,邢铁军,孙媛媛,杨 亮,林鸿飞
1.大连理工大学 计算机科学与技术学院,辽宁 大连116024
2.东软集团股份有限公司,沈阳110179
随着中国司法信息的透明化,大量裁判文书在中国裁判文书网[1]上公开,这些开源的刑事判决书中蕴含着大量的法律信息。从法律文书中自动抽取信息对于法律文书分析和相关业务处理至关重要。下游司法应用如识别案件事实、协助审查案件文件,以及辅助生成法律文件等,都依赖于信息抽取技术。实体关系抽取是信息抽取技术中至关重要的模块,旨在捕获案件事实描述中的实体对及其相互关系,将非结构化的法律文书转换成结构化的三元组知识。实体关系抽取技术有效缓解了人工提取信息费力费时的问题,对于司法业务智能化有着十分重要的意义。
近些年来,随着神经网络的广泛应用,实体关系联合抽取技术迅速发展。Miwa等[2]提出了一种端到端的神经网络模型,通过参数共享机制对实体识别和关系抽取两个任务进行联合学习。Zheng等[3]提出了一种新颖的标注方案,包含实体信息和实体间的关系,基于这种标注方案,将联合抽取问题转化为序列标注问题。此外,Zeng等[4]和Zeng等[5]使用基于编码器-解码器的联合抽取模型,将三元组抽取任务看作序列生成任务。Nayak等[6]在编码器-解码器模型的基础上,提出了一种新的三元组表示方法,通过指针网络进行解码生成三元组序列。Chen等[7]将司法领域词典特征融入模型编码器部分,进一步提高了联合抽取模型在法律文本上的性能。
目前,面向法律文书的实体关系联合抽取模型一般只针对某一特定罪名的情境进行设计,很少有工作研究面向多罪名案件情形下的实体关系抽取。而在实际的司法业务应用中,常常需要分析多类罪名的案件,单独为各类罪名下的文本训练独立的模型既耗费时间,又要存储不同罪名对应的模型参数,耗费存储空间,因此,多罪名情境下的实体关系抽取是很值得研究的。由于不同罪名案件的法律文书中的案件事实的描述不同,不同罪名的案件所涉及的实体类型、实体长度等特点也不尽相同,所以模型所关注的文本特征也是不同的。在这种情况下,如果直接将不同罪名的案件数据整合到一个数据集中一起训练,由于不同罪名的文本存在的内在的差异性,会导致一类罪名数据向另一类罪名数据引入噪声,降低模型的性能。为了解决此问题,本文引入多任务学习进行多罪名情形下的实体关系联合抽取的研究。
多任务学习的核心思想是通过共享跨任务的有用信息以提升多个模型的性能和泛化能力。目前,多任务学习已经被广泛地应用到图像领域[8-10]和自然语言处理领域[11-15]中。Hashimoto等[14]根据词性分析、语块分析、依存句法分析、文本语义相关和文本蕴涵等五个任务间的语言学层次关系,提出了一种层次增长的神经网络模型联合学习五个任务。Sun等[15]将实体识别和关系抽取作为多任务学习的两个子任务,提出了一种渐进的多任务学习模型,利用早期预测的交互来改进特定于任务的表示。
多任务模型能够在单一的模型中同时学习多个任务,并被证明通过任务之间的信息共享能够提高学习效率[16]。模型学到的共享表示通常会有较好的抽象能力,使得单个模型能够适应多个相关但不同的目标任务。多任务学习中的任务通常可以分为主任务与辅助任务,通常设置一个或几个与主任务相关的任务作为辅助任务,辅助任务与主任务共同训练以提升主任务性能和泛化能力。考虑到不同种类的罪名的案件数据之间存在的固有差异,在对犯罪事实文本进行实体关系抽取之前,知道文本属于哪种罪名对联合抽取是有所帮助的。由此,本文构建了一个罪名分类任务来预测文本所属的罪名,把主任务设置成实体关系联合抽取任务,把辅助任务设置成罪名分类任务,通过多任务模型同时对联合抽取和罪名分类两个任务进行学习,相比单任务联合抽取模型,取得了性能的提升。
1 单任务模型
在本章中,将会依次介绍用于实体关系联合抽取和罪名分类的两个单任务模型。对于联合抽取任务,借鉴Nayak等[6]的工作,使用基于编码器-解码器架构的实体关系联合抽取模型,其中,编码器和解码器均采用双向长短期记忆网络(bi-directional long-short term memory,BiLSTM)。对于罪名分类任务,同样采用BiLSTM进行编码,然后通过分类器进行罪名分类。
1.1 实体关系联合抽取模型
实体关系联合抽取模型由编码器和解码器构成。编码器用来把源句子表示为语义向量,解码器用来解码出三元组序列。具体地,给定输入句子S,使用预训练的词向量和字符级向量拼接后的特征向量作为S中的每个词的表示,向量化表示后的句子为{x1,x2,…,xN},xi∈ℝ(dw+dc),其中,dw是词向量的维度,dc是字符嵌入向量的维度。词向量采用Word2vec[17]方法在30万份法律文书上进行预训练得到,每个单词的字符级向量是通过最大池化的卷积神经网络来提取的。特征向量xi被输入到由BiLSTM构成的编码器中获得隐层表示hi,最终编码器的输出为HEncoder={h1,h2,…,hN}。给定编码器的表示HEncoder,解码器解码出三元组序列T,T={t1,t2,…,tM},其中tk表示序列中的第k个三元组,M表示三元组序列T的长度。tk由第k个三元组的头尾实体的起始索引和终止索引以及实体之间的关系类型构成。根据实体的起止索引即可从原始文本中提取出实体,通过关系分类器可以获得实体对的关系种类。解码器在每一个时间步解码出一个三元组,当解码出的三元组的关系类型变为“NA”或目标序列长度达到默认的最大值时,解码器停止解码。具体地,对于时间步k,将解码器的隐藏状态向量定义为将时间步k之前解码器输出的三元组序列表示为tpr,tpr由该时刻已经解码出的三元组的向量求和得出,如公式(1)所示。为了计算,首先用Attention机制对编码器和解码器进行交互,得到特征向量ak,如公式(2)所示。

然后将ak和tpr拼接,作为当前时间步的输入输入到LSTM单元中,得到
最后,基于HEncoder和预测实体对的起止索引和关系类型。首先,将扩展到输入序列长度N得到矩阵然后将来自编码器和解码器的这两个表示进行拼接并通过一个BiLSTM层,计算输入文本中各个单词是实体开始的概率pb和是实体末尾的概率pe,由此,可以通过实体的起止索引确定实体。计算过程如式(3)~(5)所示。其中,[;]表示拼接操作,Wb和We为可训练的参数矩阵。

为了预测实体间的关系,首先要得到实体的向量表示,如式(6)所示,其中,ek是k时刻解码出的三元组中一个实体的向量化表示,hi是Hk中的一个隐层向量。按公式分别计算头尾实体的向量化表示,然后通过softmax分类器得到关系的概率分布,如式(7)所示,再经过一个关系嵌入层得到关系的表示rk,将实体的向量表示和关系的向量表示进行拼接得到三元组表示再计算下一时刻的tpr。
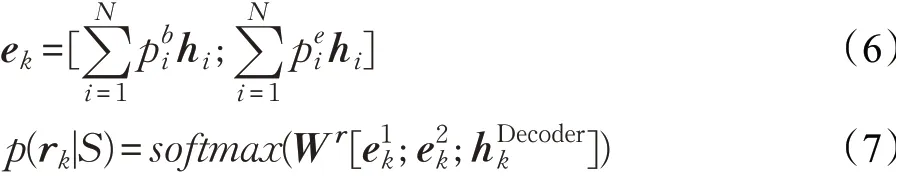
1.2 罪名分类模型
罪名分类任务使用的文本数据和联合抽取模型相同,文本数据的罪名标签是通过数据的来源类型获得的。
罪名分类模型的编码层与联合抽取模型相同,也采用BiLSTM编码。给定编码器的输出为HClassifier,首先通过一个池化层,获得输入句子的向量表示vc,这里采用最大池化(Max Pooling)操作。然后将vc输入到一个线性层中,最后通过softmax函数预测源句子S所属的罪名类别标签c,得到概率分布p,如式(8)、(9)所示,其中Wc为线性层中可训练的参数。
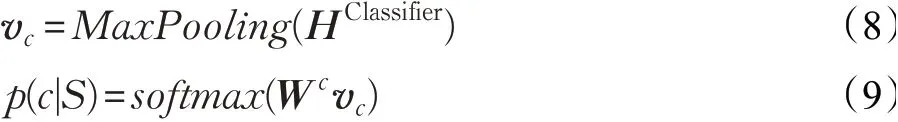
2 多任务模型
在本章中,以司法领域涉毒类案件和盗窃类案件的案情文本作为实验数据,将联合抽取模型应用到多罪名案件中。给定一条来自判决文书的案件事实描述语句S={w1,w2,…,wN},其中,wi是语句S的第i个词,N是语句S的长度。模型的目标是预测语句S所属的罪名以及从案情描述中识别出文本中所包含的全部形如<e1,r,e2>的三元组,其中e1、e2分别是S中的头尾实体,r是它们之间的关系。本章将介绍本文构建的三个多任务模型:硬共享多任务模型、共享-私有多任务模型以及基于特征筛选的动态加权多任务模型。
2.1 硬共享多任务模型
硬共享(hard shared model,HSM)多任务模型的结构如图1所示。硬共享模型中,模型的编码层的参数在两个任务之间是全部共享的,此外,每个任务都有一个任务特定的上层网络,对于联合抽取任务,上层网络是1.1节所述的解码器,对于罪名分类任务,上层网络是一个池化层和分类层。硬共享模型假设全部任务共享同样的文本特征,但不同任务可能存在特定的任务相关的特征,因此硬共享模型无法很好地处理任务间的差异性。

图1 硬共享多任务模型Fig.1 Hard shared multi-task model
2.2 共享-私有多任务模型
共享-私有模型(shared-private model,SPM)的模型如图2所示。该模型和硬共享模型一样,有一个共享的编码层网络,除此之外,两个任务还各有一个任务特定的编码层网络。

图2 共享-私有多任务模型Fig.2 Shared-private multi-task model
具体地,共享的编码层网络为两个任务学习一个共享的编码表示HShare,联合抽取任务和罪名分类任务的私有编码层网络分别为两个任务学习各自任务特定的编码表示HEncoder和HClassifier。对于联合抽取任务,将该任务的私有表示和共享表示拼接后的表示[HShare;HEncoder]作为联合抽取任务最终的输入特征表示,将其传递到联合抽取任务的任务特定上层网络中,进行解码和三元组的生成。对于罪名分类任务,将该任务的私有表示和共享表示拼接后的表示[HShare;HClassifier]作为罪名分类任务最终的输入特征表示,对其进行最大池化特征提取操作,然后传递到softmax分类器中,进行罪名分类。
与硬参数共享模型相比,共享-私有模型能够通过共享的编码层网络和私有的编码层网络分别学习任务之间的共有的信息和每个任务特定的信息,从而在一定程度上减轻了某个任务特定的信息给另一个任务的学习引入噪声的现象。同时共享-私有模型又能学习到任务之间共同的部分,有利于模型泛化性的提升。
2.3 基于特征筛选的动态加权多任务模型
在共享-私有模型的基础上,本文提出了基于特征筛选的动态加权多任务模型(dynamic weight model with feature filtering,FF-DWM)。首先,模型在学习多个任务时,对于每个任务来说,共享特征起到的作用也有所不同,基于此,本文设计了一种新的特征融合方式,通过Attention机制分别为不同子任务筛选共享特征中对其有益的部分。首先,将两个子任务的任务特定编码表示HEncoder和HClassifier分别输入到线性层,进行线性变换,得到矩阵公式如式(10)、(11)所示,其中,WE和WC是线性层中可训练的参数。同理,将共享的编码表示HShare通过线性层得到两个不同的矩阵然后分别计算自注意力,计算公式如式(12)、(13)所示,其中,h表示多头注意力中的第h个头,dk表示多头注意力中每个头的维度,为联合抽取任务特征与共享特征计算自注意力后的结果为罪名分类任务特征与共享特征计算自注意力后的结果。

在计算自注意力后,把每个注意力头的结果进行拼接,并通过一个前馈神经网络,获得共享-私有特征融合后的表示HShare_E和HShare_C。
其次,在多任务训练的不同阶段,任务对共享特征和私有特征的依赖程度也是不同的。为了让模型可以在多任务训练的不同阶段自动地学习共享特征与私有特征之间的比例,本文为各个子任务设置了一个加权权重值,并且在训练过程中不断更新该权重,以动态调节共享特征与私有特征之间的比例,计算过程如式(14)、(15)所示,其中,α1和α2是在训练过程中习得的参数。
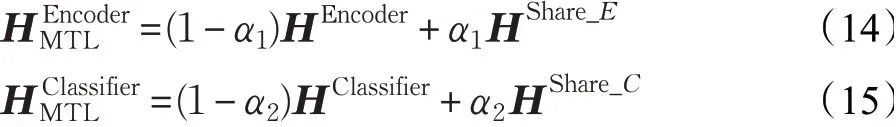
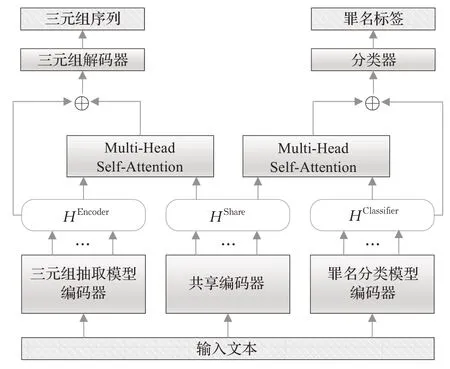
图3 基于特征筛选的动态加权多任务模型Fig.3 Dynamic weight model with feature filtering model
3 实验结果与分析
3.1 数据集及超参数设置
实验所使用的数据集来自中国裁判文书网所公开的刑事判决书。本文针对涉毒类刑事案件和盗窃类刑事案件进行实验,其中,涉毒类数据集涉及三类罪名,即贩卖毒品罪、非法持有毒品罪和容留他人吸毒罪,包括了4种关系类型,分别为贩卖(给人)(sell_drug_to)、贩卖(毒品)(traffic_in)、持有(possess)、非法容留(provide_shelter_for),这4种关系涵盖了3类涉毒类案件中的各犯罪行为。涉毒类刑事案件数据集共有1 750条案情描述文本,经过标注后以4∶1的比例切分成训练集和测试集。相应的关系统计情况如表1所示。

表1 涉毒类案件数据集中关系类型的统计情况Table 1 Statistics of relation types in drug-related dataset
盗窃类案件的数据集定义了4种关系类型,为偷盗(steal)、(涉案物品)属于(belong_to)、(涉案物品)价格(worth)、盗窃所得(earn_profits)。以750份盗窃类案件刑事判决书的案情描述文本为原始语料,以案件为单位对数据集进行随机划分,以比例4∶1切分训练集和测试集。经过标注后的数据集中,训练集共4 487条实例,包含600份案件的案情文本,测试集共1 084条实例,包含150份案件的案情文本。数据集的关系类型统计情况如表2所示。最后,根据每条数据样本的来源案件类型确定其所属罪名标签,形成罪名分类任务所使用的数据集。
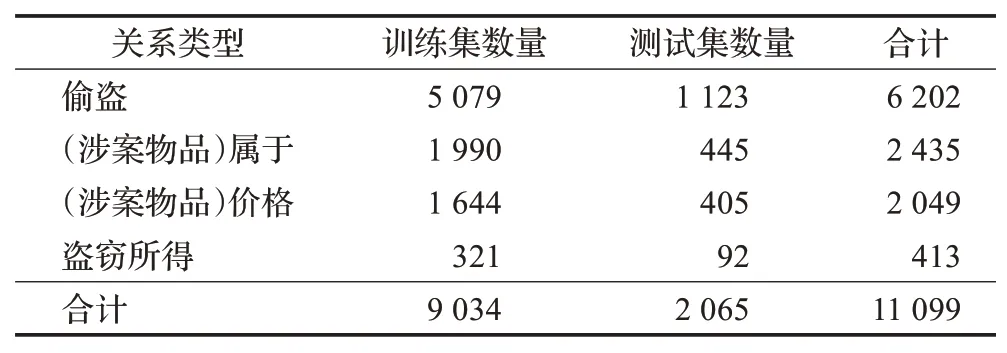
表2 盗窃类案件数据集中关系类型的统计情况Table 2 Statistics of relation types in drug-related dataset
在对模型性能进行评估方面,使用对完整三元组提取的精确率(P)、召回率(R)以及F1值(F1)作为评价指标,精确率评估模型预测为正例的样本中预测正确的样本占比,召回率评估模型预测正确的正例样本在所有正例样本中的占比,F1值为二者的调和平均值,评估模型的综合能力。实验采用的超参数设置如表3所示。

表3 超参数设置Table 3 Hyperparameter settings
3.2 多罪名实体关系联合抽取实验
为验证本文提出的基于特征筛选的动态加权多任务模型在处理多罪名实体关系联合抽取问题上的优越性,本文与单任务模型以及三个多任务模型进行了实验对比,结果如表4所示。其中,Single是未使用任何多任务方法,直接将两类罪名文本数据放到一起训练得到的实体关系联合抽取的结果,HSM、SPM分别为硬共享模型和共享私有模型的结果,此外,PLE为文献[16]所提出的基于门控机制的多任务模型复现到多罪名实体关系联合抽取任务上的结果,Our Method是本文提出FFDWM模型。Drug_和Larceny_表示分别在涉毒类案件测试集和盗窃类案件测试集上进行评价得到的结果,P、R、F是对两类罪名数据测试集中的文本进行三元组抽取实验得到的结果。
由表4结果可以看出,不使用多任务方法直接对两类案件数据集进行实体关系联合抽取,无论是在特定罪名的数据集上还是整体上的F1值都是最低的。几种多任务方法都在单任务模型的基础上取得了性能的提升,证明了将多任务方法应用到多罪名案件的实体关系联合抽取任务中的有效性,同时也证明了本文所设计的辅助任务的合理性,在处理多罪名案件的任务时,罪名分类任务可以很好地辅助主任务学习,提升主任务性能。

表4 不同多任务学习模型下三元组抽取实验结果Table 4 Performance of different multi-task learning models 单位:%
本文模型与单任务模型相比,整体F1值提升了2.4个百分点,与HSM、SPM、PLE相比,分别提升了1.5、1.8和1.7个百分点,且在单独的数据集上也取得了最好的性能,证明了本文所提出的多任务模型的有效性。HSM在整体F1值上较SPM高0.3个百分点,但在涉毒类数据集上的F1值较SPM低0.5个百分点,本文分析是因为两个数据集的规模不同,涉毒数据集数据量较小,其罪名标签数量也相较盗窃类数据更少,致使模型更倾向对盗窃类样本的学习,而HSM中完全共享两个任务的编码器参数,从而导致了涉毒类数据集实体关系抽取性能相比SPM下降。
3.3 消融实验
为进一步证明共享特征筛选和动态加权策略的有效性,本文进一步进行了实验,实验结果如表5所示,其中w/o att为模型不使用Attention机制对共享特征进行筛选的结果,w/o weight为模型不对共享特征和私有特征进行动态加权的结果。在不使用Attention机制进行特征筛选时,模型的整体F1值下降了0.6个百分点,其中,在涉毒类数据集上F1值下降较为明显,为1.9个百分点,说明是否对共享特征进行筛选对涉毒类数据集上的联合抽取性能影响较大,进一步证明了在对规模不同的数据集进行联合学习时,对共享特征筛选能够保证规模较小的数据集不被规模较大的数据集所影响。在不使用动态加权方法时,模型整体F1值下降了1.3个百分点,说明在多任务训练的不同阶段给共享特征和私有特征设置动态权值对多任务训练是有积极作用的。

表5 消融实验结果Table 5 Ablation experiment results 单位:%
此外,本文对表4、表5中对比实验的整体F1值进行了T检验,在显著性水平0.05下,实验结果差异显著。对于表4,本文模型与基线模型中性能最好的HSM模型进行T检验的结果p值为0.031 9;对于表5,本文模型与w/o att、w/o weight进行T检验的结果p值分别为0.032 5和0.003 9。
3.4 错误分析
本文对四个基线方法中性能最好的HSM方法的典型错误案例进行了分析,并与本文提出的FF-DWM模型的识别结果进行了对比,出现较多的错误类型的实例如表6所示。对于实例1,HSM方法错误地识别出实体“八千元”,注意,货币这一实体类型是不会出现在预定义的涉毒类数据集的4种关系中的,但会出现在盗窃类案件中的worth和earn_profits这两种关系所对应的实体中,说明两类罪名的案件对彼此产生了干扰。相比之下,本文提出的FF-DWM模型能够较好地减轻不同数据集给彼此带来的噪声,正确地识别出文本中所包含的三元组。对于实例2,HSM方法错误地识别出三元组“洪某某;王某甲;belong_to”,而在盗窃类案件数据集预定义的4种关系中不存在头尾实体类型均是“人”的关系,这种实体对的类型存在于涉毒类案件的sell_drugs_to这一关系类型中,分析也是由于不同类罪名数据集的特点不同而模型没有很好地区分两类案件数据的关系的特点所造成的,同样,对于该案例,FF-DWM模型也能够识别出正确三元组,同时,错误案例对“**牌两轮摩托车”这一实体的实体边界识别不准确,而FF-DWM模型也能精确地识别出准确的实体边界。可以看出FFDWM模型在能够对两类案件数据进行较充分地学习的基础上,也能较好地区分两类罪名数据的不同特征。

表6 错误案例Table 6 Error cases
4 结束语
针对处理多罪名案件文书的实际业务需求,本文研究了多任务学习在多罪名实体关系联合抽取任务上的应用,通过引入对司法案情文本进行罪名分类的辅助任务,更好地促进了作为主任务的联合抽取任务的性能提升。此外,本文研究了三种多任务学习框架的参数共享模式,提出了一种基于特征筛选的动态加权多任务模型,既能保留特定任务的特有特征表示,又能通过Attention机制自动为不同任务筛选对其有益的共享特征,同时,在多任务训练的不同阶段,允许模型动态地调整共享特征和私有特征在主辅任务中的比重。实验结果显示,本文构建的三个多任务模型在性能上均优于单任务模型,而且本文提出的基于特征筛选的动态加权多任务方法的性能取得了最优的结果。
在下一步工作中,将在更多类罪名数据集上进行司法实体关系联合抽取实验。此外,也将研究其他多任务学习框架和多任务优化方法,进一步提升任务性能。
猜你喜欢
北京大学学报(自然科学版)(2022年1期)2022-02-21
山东警察学院学报(2022年3期)2022-02-05
山西大学学报(自然科学版)(2021年1期)2021-04-21
五邑大学学报(自然科学版)(2019年3期)2019-09-06
中国生物医学工程学报(2019年6期)2019-07-16
计算机技术与发展(2018年12期)2018-12-20
环球时报(2018-05-19)2018-05-19
自动化学报(2016年3期)2016-08-23
浙江警察学院学报(2016年5期)2016-08-15
中国检察官(2015年19期)2015-01-30
