
Adapter与Prompt Tuning微调方法研究综述
2023-01-29 13:10林令德王正安
计算机工程与应用 2023年2期
林令德,刘 纳,王正安
1.北方民族大学 计算机科学与工程学院,银川750021
2.北方民族大学 图像图形智能处理国家民委重点实验室,银川750021
在过去几十年中,互联网的兴起改变了人们的生活方式,每天有大量的文本数据在互联网中产生,如何从这些文本数据中获取有用的信息是文本挖掘主要的研究内容。自然语言处理(natural language processing,NLP)作为文本挖掘的核心技术,是一门语言与计算机科学的交叉学科,属于人工智能中一个重要研究领域,主要研究如何让机器更好地理解人类语言,研究方向有机器翻译、命名实体识别等。随着深度学习发展,各种各样的神经网络模型在自然语言处理领域得到应用,例如卷积神经网络(convolutional neural network,CNN)[1-3]、循环神经网络(recurrent neural network,RNN)[4-5]、图神经网络(graph neural networks,GNN)[6-8]。神经网络通过低维和密集向量表示文本中的句法与语义特征,缓解之前特征工程中存在的问题[9]。神经网络的应用提高了NLP各个任务的准确率,然而神经网络模型需要针对具体的任务进行设计,无法构建一个适用于多任务的通用模型。
从2018年起,迁移学习的思想被广泛应用在自然语言处理领域,提出了许多预训练语言模型,如ELMO[10]、GPT[11]、BERT[12]、XLNET[13]、ELECTRA[14]、Albert[15]等。预训练语言模型采用两阶段学习方法,首先在大型语料库中训练模型,使模型学习通用语言表示,再根据不同的下游任务对预训练模型进行微调。预训练模型通常采用Transformer[16]结构,例如BERT模型基于多层双向Transformer编码器实现,这种双向结构能更好地捕捉语句中单词之间关系,提高模型在下游任务中的表现能力。而且使用预训练模型可以降低后期训练成本、加快在下游任务中模型的收敛速度、显著提升下游任务的准确率。
随着计算机性能的提升,预训练模型参数量也呈现快速增长的趋势。预训练模型参数量从2018年的1.1亿(Bert-base)增长到2021年的53 000亿(Megatron-Turing),增长了48 000倍。随着参数量的增长,模型的学习能力也随之提升,在各个领域中的应用效果也更好,如Megatron-Turing NLG[17]、ERNIE 3.0[18]、Yuan 1.0[19]等。但是模型参数量的增长在带来益处的同时,也表现出许多隐患。因为巨大的参数量会导致模型的迁移能力下降,传统预训练模型中的两阶段学习方法很难适用于参数量达到数万亿的巨大模型,即使在微调时使用了较大的数据集,也无法保障模型能够快速记住微调样本[20]。并且,传统微调方法需要对每一种下游任务进行全模型微调,并存储一份该任务的模型样本,对存储资源造成巨大压力,对计算机算力也有更高的要求。而且,目前大多数研究组织还没有足够的算力对这些参数量巨大的模型进行微调,并在实际场景中部署应用。
近两年,学者们提出了许多传统微调方法的替代方案,主要可以分为Adapter和Prompt两类。Adapter微调方法的主要思想是在预训练模型中添加Adapter模块,每个Adapter模块中包含少量参数,在下游任务中微调时固定预训练模型参数,通过Adapter模块学习特定任务中的知识,其中每个下游任务通常对应多个Adapter模块。由于每个Adapter模块中包含的参数较少,训练时只需更新Adapter模块中的权重,降低了对计算机算力的要求。Prompt微调方法通过模板将不同的下游任务转换为模型预训练时常见的形式,缩小预训练与微调时训练数据的差异性,提升模型在下游任务中的表现。
目前预训练模型微调方法综述较多[21-22],大多从预训练模型出现开始,介绍了预训练模型的整个发展历程,导致篇幅较长。与之相比,本文仅对Adapter与Prompt两类微调方法进行介绍,具有较强的针对性,且篇幅较短,适合研究人员快速了解该方向的发展现状。
本文对Adapter与Prompt中的经典方法进行介绍,对各种方法的优缺点进行讨论并总结归纳,并对本文工作进行总结与展望。本文的研究意义有:(1)与其他综述文章相比较,本文针对Adapter与Prompt Tuning两种方法进行介绍、分析与总结,针对性强。(2)以预训练模型为切入点,引出当前微调方法现状,帮助科研工作者了解当前预训练模型微调方法发展动态与存在的问题。
1 基于Adapter的微调方法
随着计算机硬件性能的提高,预训练模型参数量越来越多,在训练下游任务时进行全模型微调变得昂贵且耗时,Adapter的出现缓解了这个问题。Adapter在预训练模型每层中插入用于下游任务的参数,在微调时将模型主体冻结,仅训练特定于任务的参数,减少训练时算力开销。本章主要介绍Adapter模块设计方法、后续改进算法以及在部分领域中的应用。
2019年,Houlsby等人[23]将Adapter引入NLP领域,作为全模型微调的一种替代方案。Adapter主体架构如图1所示,在预训练模型每一层(或某些层)中添加Adapter模块(如图1左),微调时冻结预训练模型主体,由Adapter模块学习特定下游任务的知识。每个Adapter模块由两个前馈子层组成,第一个前馈子层将Transformer块的输出作为输入,将原始输入维度d投影到m,通过控制m的大小来限制Adapter模块的参数量,通常情况下m<<d。在输出阶段,通过第二个前馈子层还原输入维度,将m重新投影到d,作为Adapter模块的输出(如图1右)。通过添加Adapter模块来产生一个易于扩展的下游模型,每当出现新的下游任务,通过添加Adapter模块来避免全模型微调与灾难性遗忘[24-25]的问题。Adapter方法不需要微调预训练模型的全部参数,通过引入少量针对特定任务的参数,来存储有关该任务的知识,降低对模型微调的算力要求。

图1 Adapter主体架构图Fig.1 Adapter main architecture diagram
2020年,Pfeiffer等人[26]对Adapter进行改进,提出Adapter Fusion算法,用以实现多个Adapter模块间的最大化任务迁移(结构如图2所示)。Adapter Fusion将学习过程分为两个阶段:(1)知识提取阶段。训练Adapter模块学习下游任务的特定知识,将知识封装在Adapter模块参数中。(2)知识组合阶段。将预训练模型参数与特定于任务的Adapter参数固定,引入新参数学习组合多个Adapter中的知识,提高模型在目标任务中的表现。首先,对于N个不同的下游任务训练N个Adapter模块。然后使用Adapter Fusion组合N个适配器中的知识,将预训练参数Θ和全部的Adapter参数Φ固定,引入新的参数Ψ,使用N个下游任务的数据集训练,让Adapter Fusion学习如何组合N个适配器解决特定任务。参数Ψ在每一层中包含Key、Value和Query(如图2右)。在Transformer每一层中将前馈网络子层的输出作为Query、Value和Key的输入是各自适配器的输出,将Query和Key做点积传入SoftMax函数中,根据上下文学习对适配器进行加权。在给定的上下文中,Adapter Fusion学习经过训练的适配器的参数混合,根据给定的输入识别和激活最有用的适配器。作者通过将适配器的训练分为知识提取和知识组合两部分,解决了灾难性遗忘、任务间干扰和训练不稳定的问题。Adapter模块的添加也导致模型整体参数量的增加,降低了模型推理时的性能。
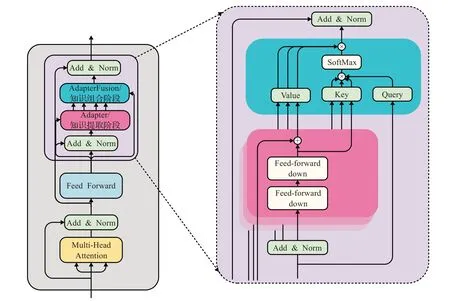
图2 Adapter Fusion架构图Fig.2 Adapter Fusion architecture diagram
Adapter Fusion在Adapter的基础上进行优化,通过将学习过程分为两阶段来提升下游任务表现。如表1所示,作者对全模型微调(Full)、Adapter、Adapter Fusion三种方法在各个数据集上进行对比实验。从表中数据可以看出,Adapter Fusion在大多数情况下性能优于全模型微调和Adapter,特别在MRPC[27](相似性和释义任务数据集)与RTE[27](识别文本蕴含数据集)中性能显著优于另外两种方法。在MRPC数据集中,Adapter Fusion与全模型微调方法相比,提升了5.15个百分点,与Adapter相比提升3.63个百分点。
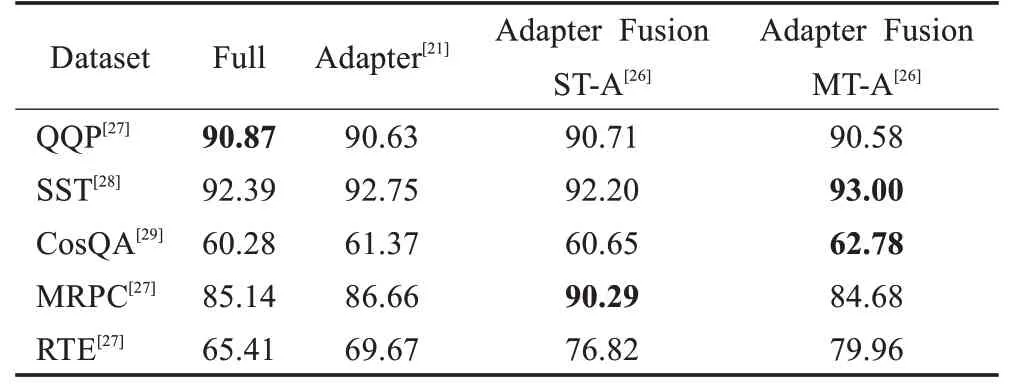
表1 Full(全模型微调)、Adapter、Adapter Fusion比较Table 1 Comparison of Full(full model fine-tuning),Adapter,and Adapter Fusion 单位:%
Rücklé等人[30]对Adapter的计算效率进行分析,发现与全模型微调相比适配器在训练时快60%,但是在推理时慢4%~6%,并提出了Adapter Drop方法缓解该问题。Adapter Drop在不影响任务性能的情况下,对Adapter动态高效地移除,尽可能地减少模型的参数量,提高模型在反向传播(训练)和正向传播(推理)时的效率。在删除了前五层的Adapter后,在对八个任务进行推理时,效率提高了39%。
Bapna等人[31]基于Adapter的思想在机器翻译领域提出了一种简单的自适应机器翻译方法。首先在大型语料库中训练一个基础通用NMT(neural machine translation,神经机器翻译)模型,作为预训练模型。在模型收敛后将模型主体部分进行冻结,保留在预训练阶段学习的通用知识。在每个Transformer层中为每种语言分别添加Adapter模块,在对应语料库中进行训练,调整Adapter参数,让其学习对应语言知识。与全模型微调相比,基于Adapter的机器翻译获得了更好的效果,并且无需对不同自适应数据集和模型容量进行调整。
2020年,Wang等人[32]将Adapter应用在迁移学习领域,提出K-Adapter方法。解决新知识注入时,历史知识被冲走(灾难性遗忘)的问题。主要思想与Adapter类似,固定预训练模型参数,针对每一种新知识添加一个Adapter模块进行训练。将Adapter模块作为预训练模型的插件,每个插件之间没有信息流传输,这样可以有效地训练多个Adapter模块,做到即插即用。避免了新的任务出现,需要对所有任务重新训练的问题。
Adapter作为全模型微调的替代方法,已经广泛应用在域迁移[33]、机器翻译[31,34]、迁移学习[32,35-36]和跨语言迁移[37-39]等方面。表2从方法的贡献、不足等方面进行总结归纳,轻量和易扩展的Adapter已经成为了全模型微调的合适替代方法。与之前昂贵的全模型微调方法相比,Adapter只需要一个较小的训练和存储代价就可以获得与全模型微调方法相近的结果。然而,基于Adapter的微调方法需要在预训练模型中添加针对下游任务的相关参数。虽然提高了模型的训练效率,但也会降低模型推理时的性能。将模型在实际应用中部署时,速度下降会非常明显。

表2 Adapter方法比较Table 2 Comparison of Adapter methods
2 基于Prompt Tuning的微调方法
全模型微调方法通过微调预训练模型来提高模型在下游任务中的表现,但是目前预训练模型都过于庞大,对预训练模型进行全微调资源消耗巨大。Prompt方法为不同下游任务设计模板,通过将下游任务重构为与模型预训练相近的形式,减少预训练与在下游任务微调时输入之间的差距。提出Prompt方法初衷是探测模型中的知识含量,让模型回忆在预训练时学习的知识。基于Prompt的微调方法降低了预训练模型在下游任务微调时存储和运算的资源使用。如图3所示,Prompt的设计分为三个步骤:(1)模板设计。通过手动或自动设计模板,将输入x转变成x′。通常情况下x′中包含空槽,让预训练语言模型对空槽填充,从而推断出y。模板的设计灵活多变,需要根据下游任务与预训练语言模型来选择合适的模板。(2)答案搜索。在通过模板得到x′后,预训练语言模型在答案空间中进行搜索,找出得分最高的值填充到对应空槽中。(3)答案映射。通过答案搜索得到空槽对应填充值后,部分任务的槽值为最终结果,部分任务的槽值需要进行转换,将槽值对应到最终的输出标签y。

图3 Prompt流程图Fig.3 Prompt flow chart
如何构建一个模板使模型在下游任务中获得最好的表现是Prompt Tuning研究的主要问题,目前在模板设计阶段主要有人工构建模板、离散模板和连续模版三种方法,本文会分别介绍这三种方法。
2.1 人工构建模板方法
依靠专业人员的经验手动构建模板是最直接高效的方式,可以支持下游任务,也可以使用辅助半监督学习的方式构建数据集,进行数据增强。在大型预训练模型的场景下可以实现小样本甚至零样本学习,实现全模型微调的效果。
2019年,Petroni等人[40]对预训练模型中包含的知识进行探测。使用BERT作为基础模型,通过将下游任务训练数据集转换为完形填空的形式(如表3所示)模仿MLM预训练机制,缩小模型预训练与微调时看到的数据差异,来检验模型中包含的知识量。作者提出了LAMA probe数据集,用来评估预训练语言模型中包含的事实和常识知识。LAMA probe是Google-RE、T-Rex等数据集的整合,通过构造模板将知识三元组转换为模型常见的完形填空的形式,来探测预训练模型中所包含的知识。其思想为研究者们带来了很大的启发。

表3 模板构建示例Table 3 Template construction example
2020年,Open AI发布了GPT-3[41],同样采用了人工构建模板的方式。将预训练好的模型参数冻结,在输入文本中加入提示构成模板引导模型完成相应问题,在避免全模型微调的情况下获得了很好的结果。提示通常由任务描述和几个相关示例组成,将任务相关提示与输入x拼接生成新的输入,无需针对不同的下游任务进行设计。该方法使得同一个模型可以服务于不同的任务,无需针对每个任务分别生成模型副本。但是该方法也具有一定的缺点:(1)每一次做新预测时,都需要针对当前任务给定训练样本,无法将上次预测时的有用信息抓取并存储。(2)该方法基于上下文来进行学习,通过注意力机制来处理序列信息。但通常模型输入序列长度固定,导致该模型无法充分利用大数据集的优点。(3)该语言模型巨大,有1 750亿参数,在实际场景中应用非常困难。
2021年,Schick等人[42]将有监督的微调和无监督的微调相结合提出了PET(pattern exploiting training),采用了半监督训练的方式,将输入示例转换为完形填空形式的短语,帮助模型理解相应任务。该方法使用手工构建模板的方式,使用相应短语为未标记数据添加软标签,最后对生成的训练集执行标准的监督训练。通过定义一个模式函数P(x),将x输入后生成模板。在生成的模板中包含[mask]标记,让模型对标记位置进行预测,预测结果通过词表V映射为最终结果y。在每个任务中设计多个模板,采用模型集成与模型蒸馏的思想来寻找表现最好的模板。首先为每组模板分配权重,通过SoftMax和温度系数生成伪标签集合并在新的PLM中进行训练。作者将多个PVP的结果融合得到置信度较高的软标签,而不是选择最好的PVP。
由于模板之间无法相互学习,如果其中某个模板性能差,会导致最终生成的训练集包含许多错误示例。作者针对这种情况提出iPET[42]。首先在数据集上进行训练得到多个单独微调模型,对于每个模型,随机选取剩下的多个模型对未标注数据进行预测,将预测结果作为该模型新的训练集。其次为每个模型分配新的数据集,继续训练得到一组新的PET模型。最后,将前面步骤重复k次,每次将生成的训练集大小增加d倍,最后一组模型将用于创建软标记数据集,用于标准分类。
虽然PET有助于将预训练语言模型中包含的知识用于下游任务,但是只有在语言模型预测的答案对应于词汇表中单个标记时才起作用,导致许多任务不容易通过这种方式完成。此外在PET中,是将每个V映射为一个token,但目前很多语言模型都是以BPE[43]为基本单元,预测中的token可能是单词中的某一部分,所以无法解决答案由多个token组成的问题。对于这个问题,作者在PET的基础上又进行了改进,提出Multiple Tasks PET[44]使其能够应用在需要预测多个标记的任务。首先针对特定任务,计算词表V中所有答案的最长长度k,在进行转换时,将[mask]长度设置为k,一次预测这k个位置的数据。
2.2 离散模板方法
虽然人工构建模板较为直观高效,但是由于构建过程繁琐,模板微小的变化可能会导致结果出现较大的变化,自动构建模板方式的提出用于解决这一问题。离散模板是自动构建模板的一种方法,模板由具体的字符构成。
2020年,Shin等人[45]针对手动设计模板既耗时性能又不稳定的问题,提出了AUTOPROMPT。通过梯度引导搜索为各种任务创建提示。如图4所示,首先定义模板λ,λ中包含触发标记Xtrig、原始输入Xinp和填充预测结果的插槽[mask]。触发标记Xtrig在所有任务中共享,并通过梯度搜索寻找确定。将Xinp与Xtrig输入到λ中,生成Xprompt作为预训练模型输入。对于抽象任务中标签选择不清晰的问题,作者使用通用的两阶段操作来自动选择标签集合的方法。首先训练一个逻辑分类器,使用[mask]作为输入来预测类标签。然后将预训练模型的输出来当作训练好的逻辑分类器的输入,来获得相应标签。AUTOPROMPT与手工构建模板相比,减少了人力的消耗并获得了不错的性能。
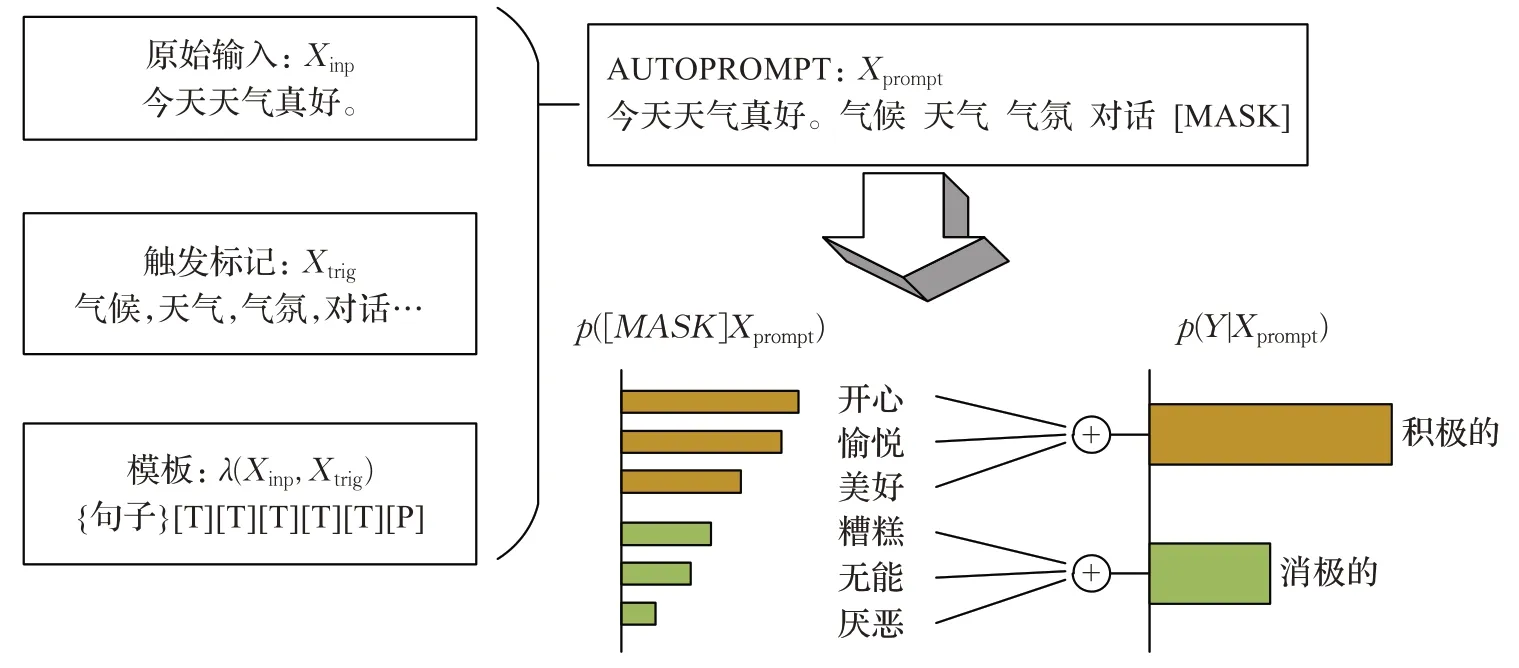
图4 AUTOPROMPT模板构建Fig.4 AUTOPROMPT template construction
GPT-3虽然在小样本微调中有不错的效果,但是其参数太多,在真实场景中难以应用部署。对此,Gao等人[46]在2020年提出LM-BFF模型。通过T5[47]模型来自动创建Prompt模板,避免人工标注导致的局部最优问题。首先自动选择标签值,针对每一个类c∈Y,使用初始L基于它们的条件似然来构建前k个词汇单词的剪枝集Vc⊂V,将Vc作为:
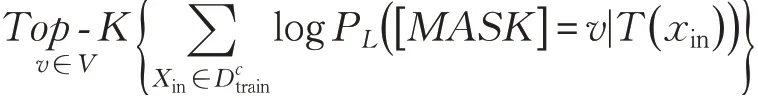
其中,PL表示L的输出概率分布。为了进一步缩小搜索空间,在修剪后的空间中找到前n个分配来最大限度地提高在训练集中的零样本学习的精度。然后构建模板,选择候选标签词,在标签词前后添加填充位后作为T5模型的输入。并在T5输出中,将标签词转换为[mask]标签形成多个模板,最后采用集束搜索对候选模板解码,类似于词表搜索方法[42,48]。对每一个模板在开发集中微调,选择效果最好的模板。虽然LM-BFF微调效果高于标准微调,但是面对较困难的任务,性能仍然落后于全模型微调方法,并且结果中也存在高方差的现象。
目前提示的微调方法大都基于令牌级别的,基于GPT[11]的L2RLM(left to right language model)或者BERT[12]的MLM(mask language model)。2021年,Sun等人[49]使用了被RoBERTa[50]等模型抛弃的Bert原始训练任务NSP(next sentence predict)来构建句子级提示方法,称为NSP-BERT。NSP-BERT为不同的下游任务分别构建模板并通过添加soft-position将候选词与[Blank]映射到同一位置,解决完形填空中候选词无法感知[Blank]上下文的缺点。
BARTScore Prompt是Yuan等人[51]在2021年提出的一种模版生成方法,将Prompt加在源文本前面或采用自动搜索模板的方式。首先构建一个提示,对提示中文本进行同义词替换生成新的提示,以这种方式来扩充提示数量。最终将生成的提示加在文本的前面或者后面,构成模板作为预训练模型的输入。虽然该构建方法简单,但是没有证明在事实和语言质量视角下的有效性。
2021年,Haviv等人[52]将构建模板将模板使用两个步骤合并,提出了一种新的模板生成方法,使用BERT1和BERT2两个模型完成任务。首先,构建初始模板作为BERT1模型的输入,计算每一个隐时刻状态与BERT1中哪一个词嵌入的token最接近,将token与原始模板中对应词进行替换优化生成新模板。将新模板作为BERT2的输入,预测结果。虽然这个方法简单并易于理解,但整个训练过程需要使用两个BERT模型,对计算机算力有较高的要求。
2.3 连续模板方法
由于手动设计模板十分困难,需要大量验证集,并且当模板发生细微变化时,容易产生不可预估的变化。离散模板与连续模板相比,在许多情况下存在性能不理想的问题。连续模板构建是对整个连续空间进行微调,放松了模板由实际存在词语组成的约束,与离散模板相比,连续模板具有更强的表现力。并且连续模板可以强调词语,并对具有误导性和歧义性的词语进行调整。
2021年,Li等人[53]提出prefix-tuning解决全模型微调中每个任务存储一份预训练模型参数的问题。每个下游任务只需要存储对应的前缀,使用前缀来优化任务。Prefix-tuning通过在预训练模型的每一层插入与任务相关的向量,在下游任务中调整相关参数,同时保持预训练模型参数不变。自回归语言模型添加prefix后表示为z=[prefix;x;y],编码器-解码器模型则表示为z=[prefix;x;prefix;y],模型添加前缀可训练的参数为Pθ∈R|pidx|×dim(hi),其中|Pidx|表示前缀的长度,dim(hi)表示模型第i时刻的隐藏状态维度。prefix的长度可以自己定义,但是宽度必须与预训练模型的隐状态维度保持一致。
2021年,Liu等人[54]提出P-tuning并证明GPT使用P-Tuning可以获得与BERT相媲美的效果。给定一个模板T={[P0:i,x,[Pi+1;m],y]},P-tuning将[Pi]映射到{h0,…,hi,e(x),hi+1,…,hm,e(y)},其中hi的值是一个可以训练的变量,这使得模型能够找到超出模型M原始词汇表V所能表达的更好的连续提示,并且使用BiLSTM将hi建模为序列,使提示嵌入hi的值相互依赖,缓解由于对hi进行随机分布初始化,在梯度下降时只改变小邻域参数[55],容易落入局部最小值的问题。DART(differentiable prompt)[56]在为hi值建立依赖时,没有使用BiLSTM,而是利用辅助流利度约束目标为hi之间建立联系。
2021年,Lester等人[57]在prefix-tuning的基础上进行简化,提出Soft-Prompt。Soft-Prompt仅在输入前加入提示,采用与目标任务相关的token对提示进行初始化。Soft-Prompt比prefix-tuning添加更少的参数,允许transformer根据输入的上下文更新中间层的任务表示,不需要重新参数化。
Hambardzumyan等人[58]受到了对抗性重新编程[59]的启发,提出了一种基于对抗性重构的方法WARP(word-level adversarial reprogramming)。与之前手工寻找或者学习离散token作为Prompt的方法不同,WARP直接优化embedding作为Prompt,给予模型更高的自由度,并且在最终的下游任务中获得了更好的表现。在模型中有两组需要优化的embeddingθ={θP,θV},其中P表示Prompt,V表示每一类的分类参数。首先将Prompt tokenP1…p插入到输入序列中(可以是前面、中间、后面任意位置),经过encoder、MLM head后,通过θV。使用梯度优化来寻找使loss最小的参数。
目前提示调优已经展现出强大的能力,但是想要达到全模型微调的效果,需要一个巨大的模型(参数量在100亿以上)。然而超大的预训练模型在实际应用部署中存在较多的问题,目前实际应用中通常使用中型模型(参数量在1亿到10亿之间)。在这部分模型中,提示调优效果远低于全模型微调。2021年10月,Liu等人[60]受prefix-tuning启发,在P-tuning基础上进行改进提出P-tuning v2。采用了深层实体调优,通过在不同层中添加标记,增加可以调节的参数量,解决P-tuning在复杂NLU任务中表现差的问题。
2.4 小结
本章从人工模板构建、离散模板构建、连续模板构建三种模板构建方式对Prompt Tuning进行介绍。如表4所示,对三种模板构建方式的优缺点进行总结归纳。并对三种构建方式下不同的方法贡献与不足进行分析梳理,如表5所示。

表4 模板构建方式比较Table 4 Comparison of template construction methods
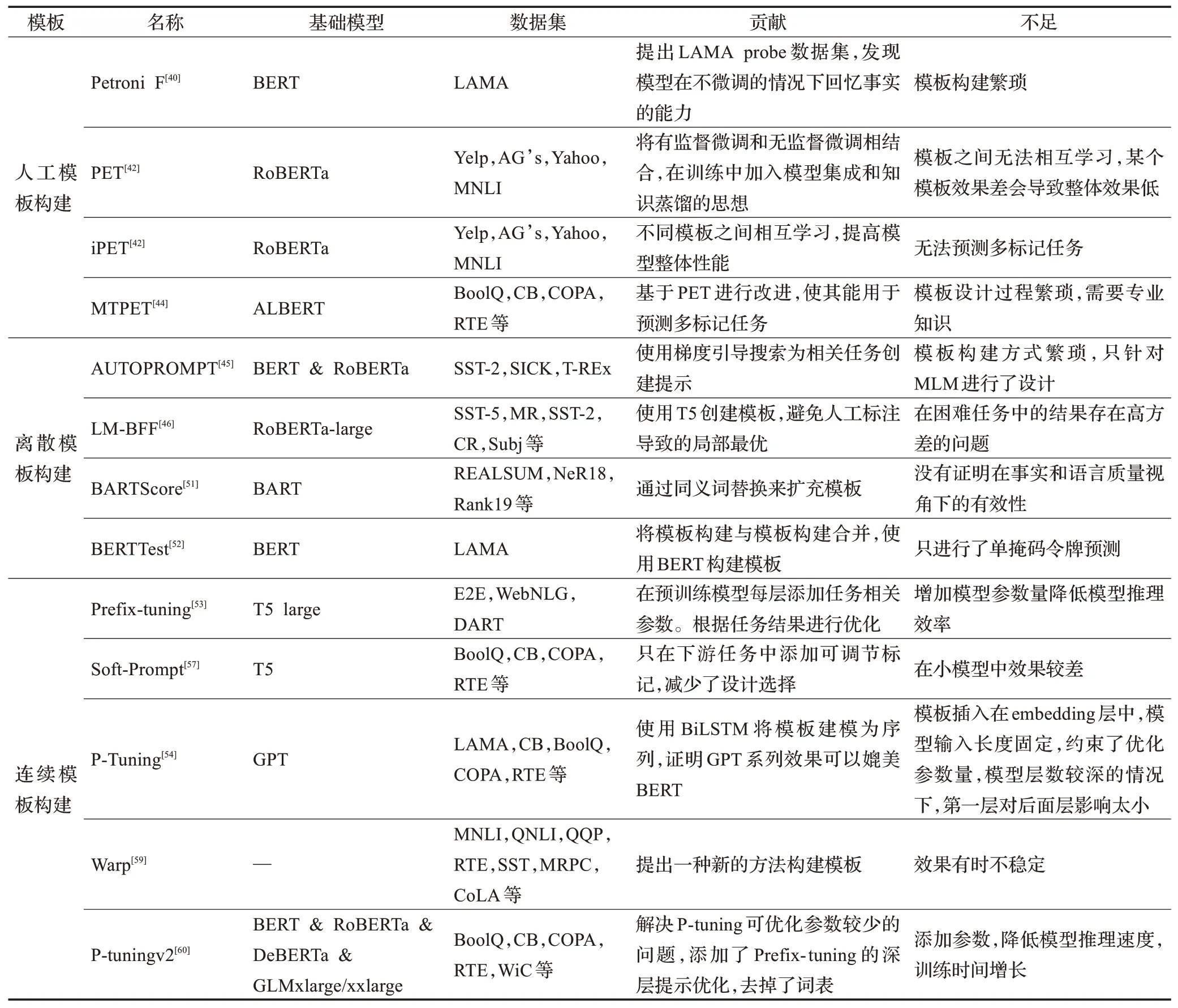
表5 各种模板构建方法比较Table 5 Comparison of various template construction methods
3 总结与展望
Adapter方法在模型中添加少量参数,在训练时将模型主体冻结,使Adapter块学习下游任务的知识,减少了训练时的参数量并达到了全模型微调的效果。与Adapter微调方法相比,基于Prompt的微调是非侵入性的,无需附加大量参数。在下游任务繁多的背景下,使用Prompt可以解决为每个任务生成一个模型样本的问题,是全模型微调的一种轻量化替代方案。但目前Prompt的研究主要针对分类和生成两方面,对于其他领域研究相对较少,对于模板与答案之间的关联也了解甚少。Prompt在自然语言处理领域大放异彩,取得的优异成绩足以证明其有效性。可以预见,在未来Prompt工作会推动自然语言处理领域的快速发展。
本文对预训练模型微调方法进行了综述,目前预训练模型微调方式种类繁多,本文仅选取了Adapter与Prompt两种方式进行介绍,对两种微调方式中经典方法进行分析、总结、归纳。虽然目前的微调方法多样且设计较为复杂,但总体趋势是结构越来越简单,未来预训练模型的微调方法会更加丰富且简单高效。
通过对最近几年预训练模型微调方法的梳理,本文对微调方法未来的发展趋势进行展望。(1)训练速度。Adapter和Prompt中连续模板的构造需要在预训练模型的基础上添加参数,并在训练过程中对参数进行优化。与全模型微调方法相比,虽然降低了训练成本,但是在模型中新添加了参数,会导致模型在推理过程中效率的降低,在实际中应用中这个缺点会被放大。如何在少量添加模型参数甚至不添加的情况下将模型微调至较好的效果是未来的一个研究方向。(2)Prompt的可解释性。Prompt已经表现出强大的能力,甚至被称为NLP的第四范式[22],但是目前针对Prompt可解释性的相关研究较少。基于Prompt的微调方法发展迅速,在短短几年的时间里已有数百篇相关工作。Prompt Tuning应更加集中地针对目前的超大模型,探索其在小样本甚至零样本中的能力上界。未来在多模态、多任务等领域的提示学习也会成为一个重要的研究方向。
猜你喜欢
建材发展导向(2022年23期)2022-12-22
建材发展导向(2022年12期)2022-08-19
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
乐器(2021年1期)2021-09-10
中国房地产业(2016年24期)2016-02-16
中国卫生(2015年9期)2015-11-10
汽车与新动力(2012年1期)2012-03-25
中国工程咨询(2011年12期)2011-02-13
