
小样本困境下的图像语义分割综述
2023-01-29 13:10李馨蕾
计算机工程与应用 2023年2期
韦 婷,李馨蕾,刘 慧
上海对外经贸大学 统计与信息学院,上海201620
自全卷积网络(fully convolutional network,FCN)[1]提出以来,图像语义分割技术飞速发展,涌现出Deep-Labv3+[2]、Auto-DeepLab[3]、DANet[4]等新型网络模型,并在多个领域广泛应用[5]。通常情况下,图像语义分割任务的标签是像素级的[6],因此图像的标注需要耗费大量的人力和时间成本。为了克服这一难题,领域内大量学者开始研究如何利用少量的样本达到同样的预测效果。另外,早期方法无法预测未在训练集中出现的语义类别,这同样限制了图像语义模型的跨领域泛化应用。为了应对以上两个挑战,元学习(meta-learning)[7]方法被提出,其主要思想在于让机器能够像人一样“学会如何学习(learn to learn)”,即仅使用少量有标注的训练样本就可以实现新的(未标注的)图像语义类别预测。运用该项技术可以在减轻图像数据标注工作量的同时提高模型的泛化能力。
小样本学习(few-shot learning,FSL)[8]正是利用了元学习的思想,试图通过少量标注样本对新类进行预测,摆脱深度学习对大规模、有标注数据集的依赖。小样本学习在计算机视觉的目标检测[9]、图像分类[10]等领域得到了广泛应用。2017年Shaban等人[11]从小样本图像分类中受到启发,提出一个小样本语义分割(few-shot semantic segmentation,FSS)模型OSLSM(one-shot learning for semantic segmentation method),设计了经典的双分支结构。同年,原型网络(prototype network)[12]被提出,取得良好的性能表现,此后大部分工作都基于原型网络进行改进创新。近年来,学者们尝试在模型中引入注意力(attention)机制[13]、图神经网络(graph neural networks,GNN)[14]等结构来优化模型性能,为小样本语义分割的发展开拓了新思路。
本文旨在介绍近年来小样本学习在语义分割任务中的发展,总结当前领域内的重要方法及各自的优缺点,针对后续研究方向提出自己的思考。
1 小样本语义分割问题设定
小样本语义分割延续小样本学习的问题设定。小样本语义分割旨在应对两个难题:标注数据集较少和模型的泛化能力不佳。小样本语义分割在每次训练和测试时都只使用少量样本,为了提高模型对样本中未出现的类别(称为“不可见类”)的预测能力,模型训练和测试时所用样本图像中不包含相同的语义类别。例如训练集中使用猫、狗等类别的样本时,测试集中不包含这两种类别[15]。
图1展示了小样本语义分割中的数据集划分。小样本语义分割训练前需将数据集分为可见类Dseen和不可见类Dunseen两个类别不交叉的部分,分别作为训练集和测试集。

图1 数据集划分Fig.1 Dataset partitioning
小样本语义分割基于可见类的样本进行训练,训练中包含多次任务,每次任务中采用一个由支撑集(support set)和查询集(query set)构成的样本对(S,Q)。支撑集和查询集中都包含一张或几张带标注的样本图像,模型从支撑图像及其标注信息中获取信息进而指导查询图像中目标区域的分割。
小样本语义分割基于不可见类进行测试,测试数据集同样被划分为支撑集和查询集,其中,支撑集包含标注信息,查询集不含标注信息。训练后的模型通过提取支撑图像得到的信息来指导分割,检验模型的预测效果。
小样本语义分割中每个支撑集包含N×K个样本,其中N表示N个类别(猫、狗等),K表示每个类别有K个样本,都随机抽取自训练集;除抽取的N×K个样本外,查询集由N个类别剩余的样本中随机抽取一部分样本组成。因此,支撑集和查询集的数据都是来源这N个类别。模型通过学习N×K个支撑样本的特征,预测查询图像中每个像素点所属的类别,被称为N-wayK-shot问题[16]。小样本语义分割的研究中通用1-shot和5-shot数据集设定。早期研究[11]都基于1-way,即学习一个类别,直到Dong等人[17]提出2-way 1-shot的分割任务,用不同模块测量不同对象之间的相似度,从而将1-way问题拓展到N-way。
2 小样本语义分割方法
小样本语义分割主要采用基于度量学习[18]的元学习方法[19],利用支撑图像和查询图像的特征向量在高维空间中的距离来预测图像中每一个像素点的类别概率。本文按照不同的模型结构将小样本语义分割方法分为基于孪生神经网络(siamese neural network)[20]、基于原型网络(prototype learning,PL)和基于注意力机制三种类型,如图2。表1总结了各类小样本语义分割方法的优缺点。

表1 小样本语义分割方法总结Table 1 Summary of few-shot semantic segmentation methods

图2 小样本语义分割方法及代表性模型Fig.2 Few-shot semantic segmentation methods and representative models
2.1 基于孪生神经网络的方法
Bromley等人[26]于20世纪90年代初提出孪生神经网络,近年来,不少学者将其引入到小样本学习中,用于小样本图像识别[27]等任务。孪生神经网络的结构中,两个样本作为“头部”分别输入到权值共享的两个神经网络中,神经网络提取各自的特征向量,并计算两个特征向量之间的距离或者相似度,根据距离或相似度判断其是否属于同一个类别,进而指导图像的预测分割。权值共享使模型的参数量减少,复杂度降低,图像以成对的方式输入网络,也可增加模型的训练数据。
以前的监督方法在学习新类时需要在数据集上更新网络,而孪生神经网络不需要在大量的数据集上训练就可以直接对新类进行分类。孪生神经网络的这一优势符合小样本学习中的设定,在小样本语义分割任务中表现也较好,使其成为小样本语义分割中的重要方法。基于孪生神经网络的小样本语义分割方法可以分为双分支结构和单分支结构两类。双分支结构简单,但预测新类时容易造成过拟合,因此不少工作都在单分支模型的基础上增加特定的功能模块以改进模型结构。
2.1.1 双分支孪生神经网络模型
双分支孪生神经网络的结构如图3,一般由两个分支分别对支撑图像和查询图像提取特征,支撑分支生成的权重指导查询分支对预测图像进行分割。

图3 双分支孪生神经网络模型Fig.3 Bi-branch siamese neural network model
Shaban等人[11]和Rakelly等人[28]先后采用了双分支结构的小样本语义分割模型,为后续的研究奠定了基础。但他们的方法较为简单、模型较为粗糙。Zhang等人[29]巧妙地运用双分支结构搭建了一个密集比较(dense comparison)模块,用于比较支撑图像和查询图像的特征。图像具有多级特征,例如,当分割查询图像中的狐狸时,高级特征能提供眼睛等特性的信息,中级特征则可以提供比表面纹理更多的信息。该实验表明仅依赖高级特征会导致模型的预测能力下降,因此模型中主要比较了图像的中级特征。然而高级特征和中级特征都有各自的特点,能为小样本语义分割提供不同级别的信息。因此Tian等人[21]首先通过预训练模型提取支撑图像和查询图像的高级特征,生成查询图像的先验掩码(prior mask),再将中级特征与先验掩码交互,用于生成精确的预测结果。该方法也表明将高级特征与中级特征结合可以提高模型的分割性能,保留模型的泛化能力,因此这一工作也被后续许多学者借鉴[30]。
双分支结构以数据对为输入,在提取图像特征时所捕获的信息有限,而且相同类别的对象在视觉相似的区域也易产生误差。因为相同对象类别的图像在其背景特征中的特征相似度高于实际前景特征,例如不同的鱼也许有不同的纹理,但其所处海域等背景具有较高的相似度,所以双分支结构的孪生神经网络可通过提取丰富的背景信息得到更多的分割线索[31]。
最近的工作中,BAM(base and the meta)[32]算法在基础的元学习器分支上增加了一个额外的分支(基础学习分支)用于识别图像中的背景,为网络的分割提供更多信息。BAM可以自适应地集成这两个分支并行输出的粗略结果,更精确地分割图像。对于分割出的背景,可以通过场景解析[33]、场景对比[34]的方法,比较支撑图像和查询图像之间的差异,以此来提高模型分割预测的稳定性。
2.1.2 单分支孪生神经网络模型
双分支并行的操作虽然可以获得支撑图像和查询图像在高级特征空间中的信息,但参数较多[35],在预测新类别图像时更易过拟合。因此,一些学者[36]提出了单分支孪生神经网络的方法,其模型结构如图4,通常在基础模型上增加特定的功能模块来优化模型的性能。

图4 单分支孪生神经网络模型Fig.4 Single-branch siamese neural network model
双分支孪生神经网络在比较支撑图像和查询图像之间的特征时往往采用简单的乘法计算,Zhang等人[22]认为计算支撑图像和查询图像的特征之间的像素相似性可以更有效地指导查询图像的分割,并提出相似性引导网络SG-One(similarity guidance)。该网络主要运用全局平均池化(global average pooling,GAP)方法,其思想是:背景像素的嵌入和目标区域像素的嵌入在高维空间中的距离通常较远,通过对支撑图像中目标区域的特征进行平均并提取代表向量,可以排除背景噪声的影响。这一方法可以有效缓解模型过拟合的问题,已成为小样本语义分割中的通用技术。但由于不同支撑图像的质量不尽相同,全局平均池化对所有支撑图像提取同等信息时会遗漏部分重要的信息。通过对支撑集的初始原型做出初始预测,将所覆盖和未覆盖的前景区域分别编码到主要和辅助支撑向量并聚合[37],可以改善多张支撑图像平均融合的问题,使高质量的支撑图像在分割预测时能提供更多信息,从而使分割的结果更加精确。
综上所述,由于孪生神经网络的设定适用于小样本的情况,使其成为小样本语义分割任务中的重要方法。双分支孪生神经网络模型通常具有两个分支,分别处理支撑图像与查询图像,将其以数据对的形式输入模型中,结构较为简单,同时参数量较多,计算成本较高,容易造成过拟合的问题;单分支结构的孪生神经网络模型更加灵活,参数量较少,可以通过增加特定的功能模块来优化模型的性能。两者在多样本情况下效率较低,更加适用于类别数较多,样本数量较少时的情况。
2.2 基于原型网络的方法
Snell等人[12]于2017年提出原型网络,这是一种具有代表性的小样本学习方法。如图5所示,该方法首先计算支撑集中每种类别所有样本的嵌入中心,将其作为该类样本的原型,然后将各个类别的原型映射到一个度量空间,计算测试样本的嵌入向量与各个类别的原型在度量空间的距离并进行比较,选择与测试样本更接近的类别用于指导分割测试样本。
图6展示了基于原型网络的小样本图像语义分割网络框架。基于原型网络的模型一般先通过骨干网络提取支撑集中各类别样本的原型(单原型或多原型),然后运用度量函数(如余弦函数、欧氏距离等)计算查询图像与原型在高维空间中的距离或相似度,根据该距离或相似度指导分割查询图像。

图6 基于原型网络的小样本语义分割模型Fig.6 Few-shot semantic segmentation model based on prototype network
基于原型网络的模型通常采用全局平均池化计算支撑图像特征的原型,有的方法[38]也会通过计算查询图像的原型反向指导分割支撑图像,以此优化模型。本节将基于原型网络的小样本语义分割方法分为单原型方法和多原型方法两类分别介绍。
2.2.1 单原型网络模型
Dong等人[17]首次在语义分割任务中引入单原型网络方法。该方法提取的特征具有鲁棒性,但在合并来自查询分支的原型和特征图时会忽略掉一些低级特征,无法捕获完整的、不同级别的语义信息[24]。当支撑图像和查询图像的对象存在较大差异时,这一问题更加明显。低级特征可提供表面纹理等信息,在分割任务中不可或缺。可以在得到整体原型的基础上,通过分解整体原型得到部分前景和背景原型,由此获得更加多样化和细粒度的样本特征[39]。
2.2.2 多原型网络模型
采用多原型的网络模型通常会将图像的特征浓缩为几个原型特征向量。由于测试数据是没有出现在训练集中的新类别,支撑图像和查询图像之间的外观和形状通常存在较大差异,即类间差异。多原型方法可以通过结合更多区域原型以更好地应对这一差异[40]。
除此以外,当图像中的目标所占范围较小,背景所占比例较大时,只需单个或少量原型就可以提取足够的信息;但当一个目标占据图像的大部分时,图像携带的信息较多,需要更多的原型来提供这些必要信息。PMMs[23](prototype mixture models)方法中运用EM算法[41]分别计算前景和背景的原型,关联多个原型的图像区域,为模型的分割提供了通道信息和空间语义信息。但PMMs方法仍然存在语义混叠问题,导致一部分目标区域被错误分割。语义混叠问题是由度量学习中的特征共享机制所引起的,SST[42]和SimProp[31]算法分别采用自监督微调和相似性传播的方法,利用特定类别的语义约束来应对语义混叠问题。但当背景类别的特征之间的正交性没有被考虑到时,这两类方法都会遇到阻碍[43]。
原型网络是小样本语义分割任务中的重要方法。基于原型网络的小样本语义分割方法具有计算简单、稳定性较好的优点。但其提取原型向量时容易丢失部分的空间信息,造成信息的不完整。同时,基于原型网络的小样本语义分割方法也难以适应不同图像的外观、形状等,在对目标区域的边界进行分割时也不够精确。通过分解整体原型或对图像的多个区域提取多个原型可以在一定程度上缓解上述问题。
2.3 基于注意力机制的方法
人在观察一张图像时,会首先注意到重要的部分,然后才会给予其余部分少量关注。注意力机制[25]正是来自这一灵感。根据不同的任务,注意力机制会给予输入的每个部分不同的权重,重点提取关键信息,忽略无关信息[44]。注意力机制在图像分类[45]、行人检测[46]等多个任务中都有广泛应用。小样本语义分割任务中的注意力机制常用于解决支撑集样本间的信息融合[29]等问题。图7展示了一般基于注意力机制的小样本语义分割方法的模型结构,主要由编码器和解码器组成。编码器通过卷积等操作提取图像的特征,解码器则用于将图像恢复至原始分辨率[47]。

图7 基于注意力机制的小样本语义分割模型Fig.7 Few-shot semantic segmentation model based on attention mechanism
现有的大部分工作只考虑到了图像的全局信息,仅有少部分[48]考虑到局部信息。局部信息的丢失会导致模型无法实现更精细的分割[49]。基于注意力机制的方法通常会提取到图像中重要的局部信息,并结合不同区域信息,减少重要信息的遗漏。不同于只关注重要的信息,Wang等人[24]采用民主的方法建立支撑图像和查询图像之间的对应关系。通过抑制高权重像素间的连接,增强低权重像素间的连接,使目标区域中的像素都能参与训练中。因此,网络可以将更多目标区域的信息从支撑图像引导到查询图像中,增强其对新类图像进行分割时的鲁棒性和泛化能力。但是这一方法计算量较大,也无法应对注意力机制无法捕获图像的位置信息[50]的问题。
也有一些工作通过注意力机制提取支撑集和查询集的特征,在此基础上交换查询图像和支撑图像的信息[51]或将支撑集训练的分类器的权重动态地调整到各个查询图像[52],以此来应对类内差距和类间差距,帮助训练好的模型更好地适应新类。
综上所述,基于注意力机制的小样本语义分割方法可以捕捉到更多的上下文信息,提取有效的局部信息,因此注意力机制成为激活支撑图像和查询图像的重要方法。尽管相较于基于原型网络的方法,基于注意力机制的小样本语义分割方法探索了多级特征之间的相关性,为图像的分割提供了更多信息,但它们仅在一小部分中间卷积层建立了特征的相关性,因此仍然具有局限性[53]。
3 小样本语义分割模型性能分析
3.1 数据集
当前小样本语义分割的研究中有两类常用数据集,自然数据集和医学图像数据集,自然数据集用于学术研究,医学图像数据集用于医学研究。表2简要汇总了各个数据集的相关信息,其中自然数据集的年份采用首次应用于小样本语义分割研究中的年份。自然数据集主要有三个,PASCAL-5i[11]、COCO-20i[36]和FSS-1000[54];医学图像数据集主要来自医学样本和一些医学相关挑战赛,分别为ISIC[55]、PH2[56]、Abd-CT[57]和Abd-MRI[58]四个数据集,下文将对这些数据集作详细说明。
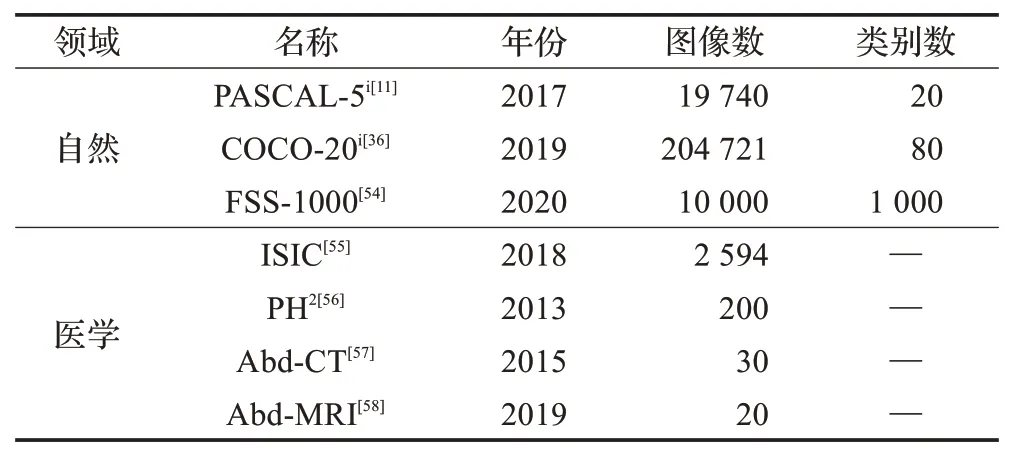
表2 小样本语义分割数据集Table 2 Few-shot semantic segmentation datasets
3.1.1 自然数据集
自然数据集包含PASCAL-5i[11]、COCO-20i[36]和FSS-1000[54],其示例如图8所示。

图8 自然数据集示例Fig.8 Nature dataset examples
PASCAL-5i[11]包含PASCAL VOC 2012[59]的图像、标注,以及SBD[60]的扩展标注,其标注的语义信息包含飞机、自行车、狗、猫等20个类别,将其平均分为4个集合,每个集合包含5个类别。每次实验时选取其中3个集合共15个类别作为训练集,剩余5个类别作为测试集。实验时一般会从测试集中随机抽样1 000个支撑查询数据对。
COCO-20i[36]使用MSCOCO[61]数据集,图片更加生活化,背景中包含更多物体,部分图像的尺寸比PASCAL-5i更小。COCO-20i一共包含80个类别,平均分为4个集合,每个集合包含20个类别。
FSS-1000[54]数据集包含1 000个类别,每个类别10张样本,其中584个类别来自ILSVRC[62]数据集,剩余类别来自网络。图像的类别非常丰富,包含常见的大部分物品,如建筑、乐器、工具、水果、电子设备等。
3.1.2 医学图像数据集
根据小样本语义分割在医学图像中的相关研究,常用的有ISIC[55]、PH2[56]、Abd-CT[57]和Abd-MRI[58]四类数据集,其示例如图9所示。
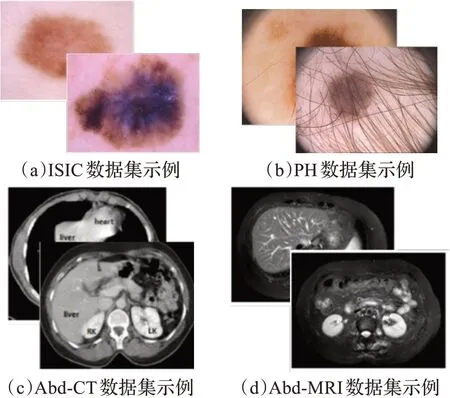
图9 医学图像数据集示例Fig.9 Medical image dataset examples
ISIC[55]来自2018国际皮肤影像协作大挑战赛。数据集分为3个任务,第1、2类任务的训练集包含2 594张RGB皮肤镜图像,每张图像有5张标注,测试集包含1 000张图像;第3类任务的训练集包含10 015张图像和对应的图像标注,测试集包含1 512张图像。目前ISIC有2016至2020年5个版本。
PH2[56]来自Pedro Hispano医院皮肤科服务处。数据集包含200张黑色素细胞病变的RGB皮肤镜图像。
Abd-CT[57]来自MICCAI 2015多图集腹部标签挑战赛,是一个临床数据集,包含30个3D腹部CT扫描图像。
Abd-MRI[58]来自ISBI 2019联合健康腹部器官分割挑战赛,包含20个3D T2-SPIR MRI扫描图像。
3.2 性能评价指标
小样本语义分割中常用平均交并比[10](mean intersection over union,MIoU)和前景背景交并比[28](foregroundbackgroud intersection over union,FBIoU)两个指标比较模型的分割精度。
交并比[63]指预测区域和真实区域中交集与并集的比值,数值越大说明模型预测结果越接近真实值。小样本语义分割中定义语义类别i的交并比IoUi为:

其中,FP(false positive)、FN(false negetive)、TP(true positive)分别表示预测结果中假阳性(预测为语义类别i的部分,实际为背景)、假阴性(预测为背景,但实际属于语义类别i的部分)和真阳性(预测和实际都属于语义类别i)的个数。
3.3 性能比较
本节从参数量及精度两个角度比较各算法的性能。表3总结了部分算法的参数量,从表中可以看出,基于孪生神经网络的方法的训练过程通常分为两个阶段,即预训练和元训练。在第一个阶段会采用标准的监督学习方式训练基础学习器,第二个阶段采用元学习的方式结合元学习器与其他模块进行训练,参数在这个阶段数量是固定的。两个学习器共享相同的编码器来提取输入图像的特征,也可减少参数量。因此该类方法可有效控制参数数量。
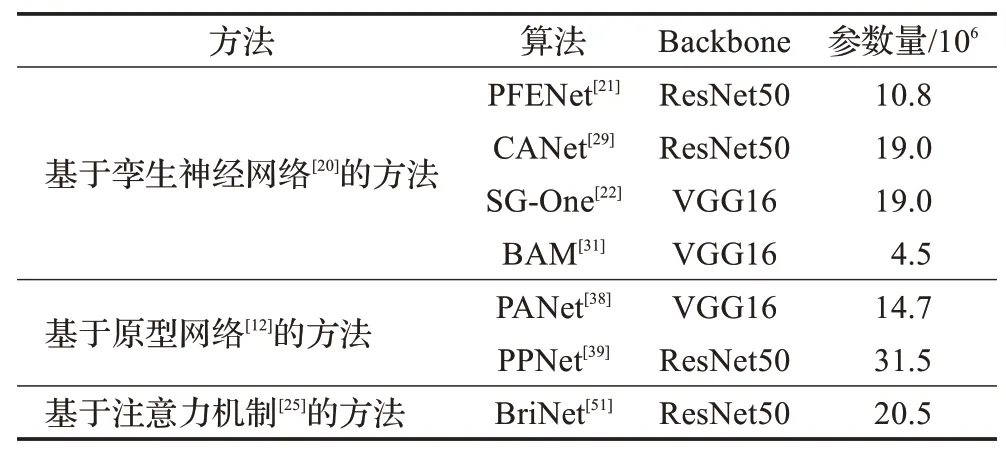
表3 各算法的参数量Table 3 Parameters of each algorithm
由于FSS-1000数据集于2020年被提出,相关实验数据较少,因此本节分组总结了各方法具有代表性的几个算法在PASCAL-5i、COCO-20i两个自然数据集上的性能。本节采用平均交并比和前景背景交并比两类评估指标评估各算法的精确性。由于不同类别的测试样本数量并不平衡,前景背景交并比忽略了类别的差异,会使预测结果更多地偏向于某一类别,平均交并比则可以有效地表现出不同类别的分割结果,因此平均交并比值得重点关注。
表4总结了各算法在COCO-20i数据集上的表现,各实验通常采用ResNet50和ResNet101两个常见的骨干网络进行测试,加粗部分表示相应设置下的最优结果。可以看出BAM[31]在1shot、5shot实验中的平均交并比最高,分别为46.2、51.1。PFENet[21]和ASGNet[40]分别在1shot、5shot实验中的前景背景交并比最优。由于COCO-20i数据集的背景更加复杂,类别更加丰富,因此分割的难度也较大,算法的分割精度不高。表5归纳了各算法在PASCAL-5i数据集上的表现,并补充了部分算法基于VGG16测试的结果,加粗部分表示相应设置下的最优结果。可以看出BAM[31]在1shot、5shot实验中的平均交并比和前景背景交并比都是最高的,主要原因可能是由于,BAM算法运用PSPNet[33]有效地结合背景信息,为分割提供了更多线索,并采用ASPP[64]取代PFENet[21]中的FEM模块以降低复杂性。同时可以看出基于孪生神经网络的方法都有较为稳定的表现。

表4 各算法在COCO-20i数据集上的表现Table 4 Performance of each algorithm on COCO-20i dataset

表5 各算法在PASCAL-5i数据集上的表现Table 5 Performance of each algorithm on PASCAL-5i dataset
结合各算法在两类数据集上的表现,基于孪生神经网络的方法在小样本语义分割任务中的相关研究更早也更多,也是目前较稳定的方法。基于孪生神经网络的方法将样本对作为输入计算样本间的相似度,更能对特征进行比较,同时结合特征融合等模块,可以获得更多尺度的信息。基于原型网络的小样本语义分割方法则侧重于获取更具代表性的特征向量,模型效果趋于稳定,但对于边界、小物体的分割则不够精细。基于注意力机制的方法在获取上下文信息时更有优势,分割时可提供更多的信息。
4 小样本语义分割的应用与发展
4.1 潜在应用领域
小样本语义分割可应用于医学图像、点云图像和遥感图像等领域。
(1)医学图像领域。小样本语义分割在医学图像的应用中有巨大潜力,一般通过训练高性能的模型来完成分割任务,但训练高性能模型需要大量像素级的标注样本,在某些罕见疾病的研究中可能难以获得,因此小样本语义分割的方法有极大的研究价值[65]。当前小样本语义分割在医学图像的应用还不算太多,而且在少量数据条件下训练小样本语义分割模型会大大增加过拟合的风险。因此,相关问题还有待研究与解决。目前,也有越来越多自监督[66]、半监督[67]框架被提出,以改进小样本语义分割模型中的过拟合问题。但总体而言,小样本语义分割在医学图像的应用上仍存在缺乏标注、模型过拟合等难题亟待解决。
(2)3D点云图像领域。3D点云分割的任务是指将特定的点云按照不同的语义类别划分为不同的子集,这需要了解图像全局的几何结构和每个点的细粒度细节。尽管目前处理点云图的语义分割方法有很多[68],但是完全监督的点云分割网络通常需要大量带有标注的数据,获取成本很高,所以相关研究仍缺乏完善的、大规模的3D点云数据集。Chen等人[69]提出了组合原型网络,为小样本语义分割在点云图上的研究做出了突破。未来如何运用小样本学习方法对3D点云图像精细分割的课题十分具有研究价值。
(3)遥感图像领域。遥感图像中的语义分割任务主要是将图像中的地理空间目标,如船舶、车辆等从背景中分割出来。遥感图像的分割对城市的规划和管理有重要意义。但是遥感图像的获取并不容易,标注工作也需消耗极大成本。目前已有一些学者[70]研究小样本语义分割在遥感图像上的应用,试图通过少量标注样本指导新类遥感图像的分割,并取得了一定的成果。但目前遥感图像领域的小样本语义分割网络模型都较为复杂,未来可以向着精简网络结构的方向展开研究。
当前小样本语义分割的主要应用领域还是在医学图像等领域,未来有望向更多的生活、工业应用场景,如违禁品检测[71]、设备缺陷检测[72]等展开研究。
4.2 发展方向
(1)理论方向。不同于小样本图像分类[73]和小样本目标检测[74]任务,小样本语义分割任务不仅需要分类信息,还需要精确到像素级别的位置信息。尽管小样本学习已经在上述视觉任务中有了一些较为成熟的发展和相关的理论依据,但仅依赖现有的小样本学习理论并不足以支撑小样本语义分割任务的研究。因此,只有将小样本学习的相关理论与语义分割理论结合起来,才能为后续小样本语义分割的研究提供科学的理论基础。例如,如何结合全局信息和局部信息,为分割提供更加精确的位置信息;如何有效抑制背景类别,提高网络的分割精度;以及如何在小样本的情形下增强模型的泛化能力等。
(2)基于图神经网络的小样本语义分割。图神经网络[75]是目前备受关注的深度学习方法之一。相较于卷积神经网络常用于处理欧几里德空间的结构数据,图神经网络更擅长处理非欧几里德空间的结构数据(如社交网络、交通网络等)[76]。语义分割任务在于预测图像中的每一个像素点的类别,但图像中的目标区域往往不是规律的网格形状,而且分割预测时需要考虑到全局信息,所以卷积神经网络在完成语义分割任务时具有局限性。图神经网络具有融合更多结构信息的优点,可以捕捉到图像中目标的变化,如比例、外观和空间位置等,指导更精确的分割预测[77],因此可以将其引入到语义分割任务中。基于图神经网络的小样本语义分割方法[78]研究工作较新,也存一些问题需要进一步研究与探索[79]。
(3)轻量级模型。当前很多小样本语义分割算法都达到了较好的分割效果,但在实际应用中一些模型需要占用较多资源,限制了其应用。这其中的原因就包括当前的算法模型大多较为复杂,参数量也较大。所以不少学者开始研究更为轻量级的模型,在尽可能保证网络同等表现的情况下减少参数的数目,从而使网络更加高效[80]。因此,未来的小样本语义分割研究可向着更轻量级、可适用于现实场景的方向展开。
5 结束语
本文对当前小样本语义分割的相关研究做了归纳和总结,当前小样本语义分割的方法主要采用基于度量学习的元学习方法,可将研究方法按照不同的模型结构划分为基于孪生神经网络、基于原型网络和基于注意力机制三大类。本文总结了上述方法的主要思想,并介绍了其各自的优缺点。本文还总结了小样本语义分割研究中各领域常用的数据集,包括自然数据集和医学图像数据集,并归纳了这些数据集的特点及类别等。此外,本文还总结了当前小样本语义分割的潜在应用领域及未来的发展方向。
猜你喜欢
小资CHIC!ELEGANCE(2021年45期)2021-01-11
开放教育研究(2020年2期)2020-03-31
英美文学研究论丛(2018年2期)2018-08-27
民族古籍研究(2018年1期)2018-05-21
中国修辞(2017年0期)2017-01-31
西夏学(2016年2期)2016-10-26
剑南文学(2016年14期)2016-08-22
中国社会历史评论(2016年2期)2016-06-27
长江学术(2016年4期)2016-03-11
人间(2015年20期)2016-01-04
