
基于多模态特征的无监督领域自适应多级对抗语义分割网络
2023-01-27 09:08王泽宇布树辉黄伟郑远攀吴庆岗常化文张旭
通信学报 2022年12期
王泽宇,布树辉,黄伟,郑远攀,吴庆岗,常化文,张旭
(1.郑州轻工业大学计算机与通信工程学院,河南 郑州 450000;2.西北工业大学航空学院,陕西 西安 710072)
0 引言
语义分割[1]作为计算机视觉的基础工作,它的核心问题是如何准确地对图像中每个像素进行分类。高精度的语义分割对有效实现机器人任务规划[2]、车辆自动驾驶[3]以及语义SLAM(simultaneous localization and mapping)[4]等智能视觉任务起到至关重要的作用。因此,基于深度学习的语义分割被广泛研究。卷积神经网络(CNN,convolutional neural network)在语义分割的局部对象视觉特征提取中取得成功[1,5],但是,由于卷积核感知域较小,因此提取的视觉特征一般缺少全局上下文信息,从而影响分割准确率。为弥补CNN 空间结构化学习能力的不足,长短期记忆网络(LSTM,long short-term memory network)联合CNN 的混合网络应运而生,文献[6]通过LSTM 逐像素地遍历图像视觉特征来学习对象间的依赖关系,从而显式地推理全局场景的空间特征。为进一步提升分割精度,基于注意力机制的局部和全局特征融合被应用于语义分割,文献[7]根据对象视觉特征和所处全局场景空间特征的相关性自适应地聚合有用上下文信息并屏蔽噪声上下文信息,从而生成高质量的综合语义特征。
虽然上述有监督训练语义分割网络取得成功,但是,在有标签源域到无标签目标域的无监督领域自适应中,尽管领域间具有较高的语义相似性,由于目标域没有标签,不能直接优化网络参数,仅基于源域训练的网络无法理想地分割目标域场景,而人工制作目标域标签又必然提升成本。为能够利用无标签目标域间接调优网络参数,对抗学习[8]被广泛应用于领域自适应中。文献[9]首次通过对抗学习和附加类别约束减小领域间特征分布差异。基于此,文献[10]提出多级对抗学习,通过设置的多个判别器与语义分割网络的不同层次进行对抗,从而对齐不同抽象级别特征的分布。但是,由于领域间存在对象纹理不同和外界环境变化(季节、天气以及光照等)引起的视觉风格差异,从而出现误识别相兼容语义类别的问题。
为此,循环一致性[11]和域内风格不变表示(ISR,intra-domain style-invariant representation)[12]等图像风格转换方法被应用于减小领域间视觉风格差异。在此基础上,双向学习(BDL,bidirectional learning)[13]、标签驱动重建(LDR,label driven reconstruction)[14]和双路径学习(DPL,dual path learning)[15]等方法均提出一种双向学习框架,通过图像风格转换网络和语义分割网络相互促进,从而在确保语义内容不变的情况下实现源域到目标域图像的视觉风格转换,进而降低特征分布的错误对齐。进一步地,文献[16]提出零风格损失来分离图像的语义内容和视觉风格,从而使用去除风格差异的源域和目标域图像进行有监督训练。但是,引入图像风格转换方法会增大网络结构的复杂度,同时降低网络的训练效率。
为了利用无标签目标域有监督训练语义分割网络,自监督学习被用来为目标域图像生成标签,并基于多分类交叉熵损失调优网络,从而直接拉近领域间的特征分布差异[17-19]。两阶段目标域标签密集化(TPLD,two-phase pseudo label densification)生成策略[17]解决了目标域标签过于稀疏而导致的特征分布距离无法有效拉近问题。无监督域内自适应(UIA,unsupervised intra-domain adaptation)学习方法[18]首先按照同源域的分布接近程度对目标域进行划分,然后按照分布差异由小到大的顺序逐次对齐分布。文献[19]通过不确定学习策略迭代自动纠正目标域生成的错误标签,从而不断提升所生成标签的正确率。但是,上述自监督学习方法无法同时确保选定目标域子集的稠密性和目标域子集所生成标签的正确性,从而导致目标域中出现较多未充分对齐或错误对齐的像素。
值得注意的是,由于上述领域自适应方法所训练ResNet-101(101-layer residual network)[5]的空间结构化学习能力有限,因此,虽然对抗学习、图像风格转换学习和自监督学习在对齐领域间局部对象视觉特征分布上取得成功,但是上述方法无法有效减小全局场景空间特征的分布差异,从而由于缺少目标域场景的全局上下文信息而影响综合语义特征的生成质量。为此,CDA(context-aware domain adaptation)[20]提出跨域的空间和通道注意力模块,用来学习领域间共享的上下文信息,并基于对抗学习减小上下文信息的分布差异。另外,文献[21]通过采样和聚类的方法显式学习领域间的上下文依赖关系,并同样基于对抗学习对齐结构化特征的分布。但是,上述方法未能全面地减小领域间视觉和空间特征的分布差异,同时没有考虑融合视觉和空间信息的综合语义特征的分布对齐。
综上,由于领域间不仅存在局部对象的颜色、形状以及纹理等视觉外观差异,而且存在全局场景的环境、布局以及对象间边界等空间结构不同,因此,领域自适应不仅需要减小局部对象的视觉特征分布差异,而且需要减小全局场景的空间特征分布差异,同时需要对齐融合视觉和空间信息的综合语义特征分布。但是,现有方法[9-21]均未考虑全面减小上述三类特征的分布差异,从而导致无法在目标域场景有效生成融合对象视觉和空间信息的综合语义特征,这不仅会影响易混淆类别的区分,而且会出现尺寸较小对象的误分割,因此,如何全面最小化领域间视觉、空间以及语义等三类特征的分布距离成为领域自适应需要解决的核心问题。为此,本文提出基于多模态特征的无监督领域自适应多级对抗网络(UDAMAN-MF,unsupervised domain adaptation multi-level adversarial network based on multi-modal features),首先,设计3 层结构语义分割网络分别从源域和目标域学习视觉、空间以及语义特征,从而为领域间上述三类特征的分布对齐奠定网络结构基础;然后,在单级对抗学习中引入改进的自监督学习,从而在特征分布距离最小化过程中实现更大目标域子集的分布对齐;最后,基于多级对抗学习全面对齐3 层网络所学三类特征的分布,从而有效学习各类特征的域间不变表示。主要贡献如下。
1) 提出基于3 层结构的注意力融合语义分割网络。所提网络由特征提取层、结构化学习层和特征融合层组成,3 层子网能够从源域和目标域分别学习局部对象的多维视觉特征(HVF,hierarchical visual feature)、全局场景的空间结构化特征(SSF,spatial structural features)以及包含综合语义的多模态混合特征(MHF,multi-modal hybrid features),为领域间视觉、空间以及语义特征的分布对齐奠定基础。
2) 联合分布置信度和语义置信度的自监督学习。为特征分布接近源域并且语义分类概率较高的目标域子集生成标签,以同时确保选定子集的稠密性和生成标签的正确性,从而能够通过有监督训练直接对齐接近源域的有标签目标域子集的分布,进而有助于无监督对抗学习对齐远离源域的无标签目标域子集,以实现更大目标域子集的分布对齐。
3) 基于多模态特征的多级对抗学习方法。通过3 路对抗分支与3 个自适应子网的联合对抗训练,以充分调优各子网的参数,从而全面减小低层子网所学视觉特征、中层子网所学空间特征以及整个网络所学语义特征的分布差异,进而有效学习上述三类特征的域间不变表示。
1 UDAMAN-MF 结构与学习方法
在领域自适应中,由于领域间不仅存在局部对象视觉外观特征的分布差异,而且存在全局场景空间结构化特征的分布差异,同时存在包含对象视觉和空间信息的综合语义特征的分布差异,因此,如何全面地减小上述三类特征的分布差异成为领域自适应研究的关键。为此,本文提出 UDAMAN-MF。UDAMAN-MF 由2 个相互对抗的模块组成,即基于3 层结构的注意力融合语义分割网络G和基于3 路并行对抗分支的判别器D,结构如图1 所示。G由特征提取层GHVF、结构化学习层GSSF和特征融合层GMHF组成,分别用来提取局部对象的多维视觉特征、推理全局场景的空间结构化特征以及融合生成包含对象综合语义的多模态混合特征,从而为领域间视觉、空间以及语义等三类特征的分布对齐奠定网络结构基础;D由3 路并行的对抗分支DHVF、DSSF和DMHF构成,用来与低层子网GHVF、中层子网GHVF+GSSF以及整个网络GHVF+GSSF+GMHF进行多级对抗训练,从而逐步减小领域间各子网所学特征的分布差异。

1.1 基于3 层结构的注意力融合语义分割网络
为了分别从源域和目标域场景学习视觉、空间以及语义特征,本文提出基于3 层结构的注意力融合语义分割网络,具体结构如图2 所示,其中,前端的特征提取层GHVF通过ResNet-101 提取局部对象的多维视觉特征,中端的结构化学习层GSSF采用LSTM 推理全局场景的空间结构化特征,后端的特征融合层GMHF基于注意力机制生成包含对象综合语义的多模态混合特征,从而为领域间上述三类特征的分布对齐奠定网络结构基础。
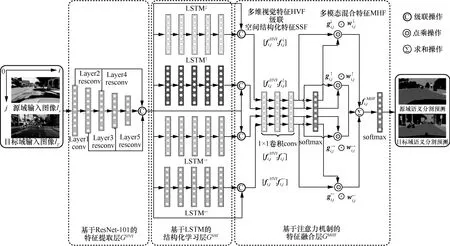
图2 基于3 层结构的注意力融合语义分割网络结构
1.1.1基于ResNet-101 的特征提取层
在特征提取层,ResNet-101 提取局部对象的多维视觉特征。ResNet-101 共5 层,设输入图像为I,则第l层的特征提取过程可以表示为

然后,级联ResNet-101 各层上采样的特征,则图像中像素(i,j)的多维视觉特征可以表示为如式(2)所示。
其中,n、h和w分别表示多维视觉特征的维数、高度和宽度,函数up 表示上采样操作。
1.1.2基于长短期记忆网络的结构化学习层
结构化学习层由4 路长短期记忆网络分支组成,各分支均由5 层LSTM 单元堆叠而成。4 路分支分别从4 个方向(用↓↑→←表示)逐像素地遍历多维视觉特征,上述结构化学习过程可以表示为

多维视觉特征经过4 路LSTM 分支在4 个不同方向上的逐像素遍历,推理的空间结构化特征可以定义为

1.1.3基于注意力机制的特征融合层
为自适应融合多维视觉特征HVF 和空间结构化特征SSF,对于图像中每个像素(i,j),首先,将其HVF 分别与4 个方向上的SSF 级联,并通过卷积操作对4 个方向上的级联特征依次降维,上述过程可以表示为


其中,⊙表示点乘操作,e、h和w分别表示多模态混合特征的维数、高度和宽度。
最后,利用softmax 分类器并根据多模态混合特征逐像素地标注图像的语义类别。
1.2 面向3 层结构语义分割网络的多级对抗学习方法
为了全面对齐领域间网络G所学多维视觉特征HVF、空间结构化特征SSF 以及多模态混合特征MHF 的分布,本文提出基于多模态特征的多级对抗学习方法。通过判别器D中设置的3 路并行分支DHVF、DSSF和DMHF与网络G中各自适应子网GHVF、GHVF+GSSF和GHVF+GSSF+GMHF分别进行单级对抗训练,从而逐步减小领域间各层子网所学模态特征的分布差异,进而有效学习上述三类特征的域间不变表示。
对于网络G所学每类特征,为了充分对齐目标域中各像素的该类特征表示,在单级对抗学习中引入联合分布置信度和语义置信度的自监督学习方法。一方面,改进自监督学习为分布接近源域并且语义分类概率较高的目标域子集生成标签,以同时确保选定目标域子集的稠密性和所生成标签的正确性,从而能够基于多分类交叉熵损失直接对齐有标签目标域子集的分布;另一方面,对抗学习通过对抗分支与对应子网的竞争,从而间接拉近远离源域的无标签目标域子集与源域间的分布差异。两者相互结合,从而在领域间所学特征分布距离最小化中实现更多目标域像素的分布对齐。
1.2.1基于改进自监督学习的单级对抗学习方法
设标签源域S={(IS,YS)},YS表示源域图像IS的标签,无标签目标域T={IT},IT表示目标域图像。在从源域S到目标域T的领域自适应中,一般对语义分割网络G和判别器D进行单级对抗训练[13],其中,D训练的目标是能够准确地区分源域和目标域语义分类概率间的分布差异;G训练的目标是使目标域语义分类概率能够不断接近源域语义分类概率的分布,从而达到成功欺骗D的目的。两者相互对抗,从而逐步减小领域间网络G所学特征的分布差异。
1) 判别器D的训练
为训练判别器D区分源域和目标域语义分类概率的能力,目标函数定义为二分类交叉熵损失lD,即

其中,当z=1 时,判别器D的输入为源域语义分类概率G(IS);当z=0 时,判别器D的输入为目标域语义分类概率G(IT)。
2) 语义分割网络G的训练
为对齐目标域中更多像素的分布,网络G的训练分为3 个过程:①基于多分类交叉熵损失,使用有标签源域S对网络G进行有监督训练;②基于改进自监督学习损失为分布接近源域并且语义分类概率较高的目标域子集生成标签,并利用包含标签的目标域子集优化网络G;③基于对抗学习损失,通过判别器D的竞争对抗再次调优网络G。较不包含自监督学习的对抗训练,包含改进自监督学习的对抗训练能够对齐更大目标域子集的分布,如图3(a)和图3(b)所示。

图3 基于不同自监督学习方法的领域间特征分布对齐
首先,使用有标签源域S训练网络G,该目标函数定义为多分类交叉熵损失lseg,计算式为

其中,YS表示源域图像IS的标签,G(IS)表示源域语义分类概率,C表示语义类别数。
然后,为了利用无标签目标域T有监督训练网络G,先通过基于源域S预训练的网络G为目标域图像IT生成伪标签YT,计算式为

其中,函数argmax 用来选择目标域语义分类概率G(IT)中最大值对应的通道作为图像IT的伪标签。
为选择伪标签中高可信的部分作为自监督学习的真值标签,一般基于语义置信度选择语义分类概率大于阈值的目标域子集生成标签并进行有监督训练[13]。但是,若语义置信度阈值设置过大,则无法保证包含标签的目标域子集的稠密性,从而导致对抗训练无法充分对齐剩余较大无标签目标域子集的分布,如图3(c)所示;若阈值设置过小,则无法保证选定目标域子集所生成标签的正确性,从而导致部分有标签目标域子集出现错误的分布对齐,如图3(d)所示。但是,若先求得分布接近源域的目标域子集,再从接近源域的子集中选择语义分类概率大于阈值的像素生成标签,则不需要设置较大的阈值便可保证其生成标签的正确性,同时,迭代的自监督学习和对抗学习能够不断增大分布接近源域的目标域子集尺寸,进而可确保包含标签的目标域子集的稠密性。因此,为特征分布接近源域并且语义分类概率较高的目标域子集生成标签,并基于改进多分类交叉熵损失函数优化网络G,该目标函数定义为自监督学习损失lssl,计算式为

其中,MD表示伪标签YT的分布置信度掩码,用来选择分布接近源域的目标域子集;TD表示分布置信度阈值,当分布分类概率D(G(IT)) >TD时,掩码置1,否则置0;MG表示伪标签YT的语义置信度掩码,用来选择语义分类概率较高的目标域子集;TG表示语义置信度阈值,当语义分类概率G(IT) >TG时,掩码置1,否则置0。
最后,利用判别器D与网络G进行对抗,从而达到目标域语义分类概率G(IT)成功欺骗判别器D的目的,该目标函数定义为对抗学习损失ladv,计算式为

综上,为使网络G生成的目标域语义分类概率G(IT)不断接近源域语义分类概率G(IS)的分布,定义网络G的单级领域自适应损失lG为
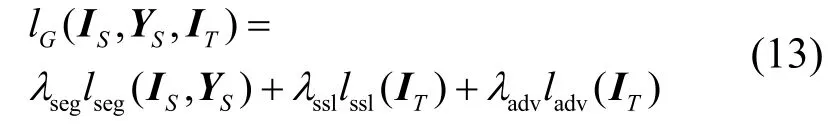
其中,lseg表示多分类交叉熵损失函数,lssl表示自监督学习损失函数,ladv表示对抗学习损失函数,λseg、λssl和λadv分别表示上述三类损失的权重系数。
1.2.2基于多模态特征的多级对抗学习方法
由于自适应子网GHVF和GHVF+GSSF距离网络G输出端较远,低层和中层子网的参数无法通过单级对抗训练被充分调优,从而影响对应层次所学特征的分布对齐。因此,本文基于单级对抗学习,面向3 层结构网络G提出基于多模态特征的多级对抗学习方法,通过判别器D中3 路分支DHVF、DSSF和DMHF与网络G中各子网GHVF、GHVF+GSSF和GHVF+GSSF+GMHF分别进行单级对抗训练,从而全面减小领域间所学视觉、空间以及语义等三类特征的分布差异。
为使单级领域自适应损失适用于基于多模态特征的多级对抗学习,扩展网络G的目标函数lG为多级领域自适应损失,即

其中,F={HVF,SSF,MHF}表示网络G所学三类特征的集合;i表示子网层次,当i=HVF 时表示低层子网GHVF,当i=SSF 时表示中层子网GHVF+GSSF,当i=MHF 时表示整个网络GHVF+GSSF+GMHF;分别表示第i层子网的多分类交叉熵损失、自监督学习损失和对抗学习损失;分别表示第i层次子网的三类损失对应的权重系数。
同时,为与网络G中各子网进行对抗,在判别器D中设置3 路对抗分支,并扩展判别器D的目标函数lD为

其中,i表示判别器分支的层次,当i=HVF 时表示低层子网的对抗分支DHVF,当i=SSF 时表示中层子网的对抗分支DSSF,当i=MHF 时表示整个网络的对抗分支DMHF。
为了清晰地说明语义分割网络G的参数调优,UDAMAN-MF 的多级对抗学习过程介绍如下。首先,基于多分类交叉熵损失lseg,使用有标签源域S对网络G迭代训练100 次epoch,从而初始化网络G的参数。然后,为保证网络G的参数在后续的多级对抗训练中较快收敛,对网络G和判别器分支DMHF迭代单级对抗训练200 次epoch,在每次迭代中,一方面,基于二分类交叉熵损失lDMHF训练对抗分支DMHF区分源域语义分类概率G(IS)和目标域语义分类概率G(IT)的能力;另一方面,基于单级领域自适应损失lGMHF训练网络G,使网络G输出的目标域语义分类概率G(IT)不断接近源域语义分类概率G(IS)的分布。最后,对网络G中3 个子网和判别器D中3 路分支迭代多级对抗训练200 次epoch,在每次迭代中,自适应子网GHVF、GHVF+GSSF和GHVF+GSSF+GMHF分别与对应的判别器分支DHVF、DSSF和DMHF依次进行单级对抗训练,从而逐步调优网络G中各子网的参数,进而全面对齐领域间所学三类特征的分布。
2 实验
2.1 训练数据集和性能评价标准
为了验证UDAMAN-MF 的普适性,分别在室外和室内场景数据集上对所提网络进行训练和测试。
在室外场景的领域自适应中,选择合成的GTA5[22]或SYNTHIA 数据集[23]作为源域,同时选择真实的Cityscapes 数据集[24]作为目标域。在训练阶段,使用有标签的GTA5(SYNTHIA)数据集和无标签的Cityscapes 训练数据集进行多级对抗训练;在测试阶段,使用Cityscapes 验证数据集进行测试。
在从源域 SUN-RGBD 数据集[25]到目标域NYUD-v2 数据集[26]的室内场景领域自适应中,由于 SUN-RGBD 数据集由 NYUD-v2、Berkeley B3BO、SUN3D 以及新制作的数据四部分组成,为满足领域间的差异性,选择去除 NYUD-v2 的SUN-RGBD 数据集作为源域。在训练阶段,使用有标签的 SUN-RGBD 训练数据集和无标签的NYUD-v2 训练数据集进行多级对抗训练,在测试阶段,使用NYUD-v2 测试数据集进行验证。
另外,使用像素准确率(PA,pixel accuracy)、平均准确率(MA,mean accuracy)和平均交并比(mIoU,mean intersection over union)作为面向语义分割领域自适应网络的性能评价标准[1,13]。
2.2 实验环境和参数设置
基于开源的深度学习框架PyTorch[27]编码实现UDAMAN-MF,并在一台2 个2.4 GHz Intel Xeon Silver 4214R CPU(2×12 Cores)、24 GB NVIDIA GeForce GTX 3090 GPU 以及128 GB 内存的计算机上进行训练和测试。
2.2.1判别器的结构
判别器D由3 路对抗分支DHVF、DSSF和DMHF组成,每路分支均由5 层核尺寸为4×4、步长为2 的卷积操作构成,各卷积层后均设置一个leaky ReLU激活函数,各卷积层输出特征的维数分别为64、128、256、512 和1。另外,为使判别器输出的分布分类概率图与输入图像尺寸相同,在最后一层卷积操作后添加一个上采样操作。
2.2.2UDAMAN-MF 的训练
UDAMAN-MF 的训练共包括3 个阶段:首先,基于多分类交叉熵损失训练网络G;然后,对网络G和判别器D中的分支DMHF进行单级对抗训练;最后,对判别器D中3 路分支与网络G中3 个子网进行多级对抗训练。
训练阶段1,通过反向传播算法对网络G中各层联合优化。在特征提取层,首先,通过公用模型resnet_v1_101_2016_08_28[5]初始化该层的参数;然后,上采样并级联ResNet-101 各层输出特征,各层输出特征的维数分别为64、256、512、1 024和2 048;最后,将级联特征送入3 层1×1 卷积做降维,各层输出特征的维数分别为2 048、1 024 和512。在结构化学习层,首先,为4 路遍历分支均设置5 个LSTM 单元,并设置各LSTM 单元隐藏层状态的维数分别为512、256、128、256 和512;然后,在[-0.05,0.05]的均匀分布下随机地初始化4 路分支的参数。在特征融合层,首先通过3 层1×1 卷积将多维视觉特征依次与4 个方向上的空间结构化特征做降维,各层输出特征的维数分别为512、256 和256;然后,利用softmax 函数分别计算4 个方向上降维特征的注意力权重,并将4 个方向上的降维特征加权求和;最后,根据自适应聚合的多模态混合特征逐像素地标注语义类别;另外,在均值为0、标准差为0.05的正态分布下初始化该层的参数。在完成G的网络参数设置后,设置G的训练参数如下:learning_rate=5×10-4、batch_size=8、momentum=0.9、weight_decay=10-4以及epoch=100,并采用随机梯度下降算法优化G的参数。
训练阶段2,对网络G和对抗分支DMHF进行单级对抗训练。在每次迭代中,首先,基于多分类交叉熵损失微调网络G;然后,基于二分类交叉熵损失训练对抗分支DMHF;接着,为目标域生成标签,并基于自监督学习损失优化网络G;最后,固定对抗分支DMHF的参数,并基于对抗学习损失调优网络G。
训练阶段3,对网络G和判别器D进行多级对抗训练,即判别器D中的3 路分支DHVF、DSSF和DMHF依次与网络G中的3 个子网GHVF、GHVF+GSSF和GHVF+GSSF+GMHF进行重复的单级对抗训练。
训练阶段2 和训练阶段3,设置网络G的训练参数如下:optimizer(G)=SGD,learning_rate=2.5×10-4,batch_size=4,decay_policy=Poly,decay_power=0.9,momentum=0.9,weight_decay=5×10-4以及epoch=200。同时,在均值为0、标准差为0.05 的正态分布下初始化判别器D中各分支的网络参数,并设置其训练参数如下:optimizer(D)=SGD,learning_rate=10-4,batch_size=4,momentum=0.9,weight_decay=5×10-4以及epoch=200。
在自监督学习损失的阈值设置中,为3 个自适应子网对应的损失设置相同的阈值,其中,分布置信度阈值TD=0.6,语义置信度阈值TG=0.7。在多级领域自适应损失的权重系数设置中,为距离网络G输出端较远的子网对应的损失设置较小的权重系数,权重系数分别设置如下:λsegHVF=0.3,λsslHVF=0.3,λadvHVF=0.000 2,λsegSSF=0.5,λsslSSF=0.5,λadvSSF=0.000 6,λsegMHF=1,λsslMHF=1 和λadvMHF=0.001。
2.3 实验结果与分析
2.3.1GTA5 到Cityscapes 的领域自适应
1) UDAMAN-MF 与先进方法的分割精度对比
源域GTA5 到目标域Cityscapes 上UDAMAN-MF(基于3 层结构语义分割网络)与先进方法(基于ResNet-101)的训练方法与分割精度如表1 所示,训练方法中,A 表示对抗学习方法,S 表示自监督学习方法,T 表示图像风格转换方法;mIoU 表示分割精度的评价标准。从总体上讲,所提网络取得最优的平均交并比62.2%;从相兼容19 种类别上看,相比其他方法,UDAMAN-MF 在11 种类别上的交并比均有一定程度的提升。特别地,所提网络不仅在尺寸较小的类别上(如围栏、杆、信号灯和交通标识等)取得最优的交并比,而且在易混淆类别上(如行人和骑手、摩托车和自行车等)也取得更高的分割精度。UDAMAN-MF 获取成功的原因可归纳如下:第一,3 层结构语义分割网络不仅能够有效提取局部对象的多维视觉特征,而且可以准确推理全局场景的空间结构化特征,融合生成的多模态混合特征能够全面表达对象的综合语义;第二,改进的自监督学习方法能够确保选定目标域子集的稠密性和所生成标签的正确性,从而能够基于多分类交叉熵损失直接对齐接近源域的有标签目标域子集的分布,同时有助于对抗学习拉近远离源域的无标签目标域子集与源域间的分布差异,进而实现目标域中更多像素的分布对齐;第三,多级对抗学习方法能够充分调优3 层网络中各子网的参数,从而全面减小领域间所学视觉、空间以及语义特征的分布差异,进而在目标域场景中生成融合对象视觉和空间信息的综合语义特征。
UDAMAN-MF 虽然在大多数类别上均取得较优的交并比,但是在少数类别上(如地面、卡车和火车等)的分割精度却较低,如表1 所示。为分析分割精度不够理想的原因,图4 列出语义分割混淆矩阵,其中,对角线表示各类别的像素准确率,非对角线表示行类别误预测为列类别的概率。从混淆矩阵中可发现:第一,“地面”易误分类为“马路”和“人行道”,这主要由于上述类别在外观或属性上存在较高的相似度;第二,“卡车”易误分类为“汽车”,“火车”和“公交车”易相互混淆,除了视觉相似度较高外,主要与“卡车”和“火车”类别的出现频率较低有关,从而影响上述类别的充分学习。
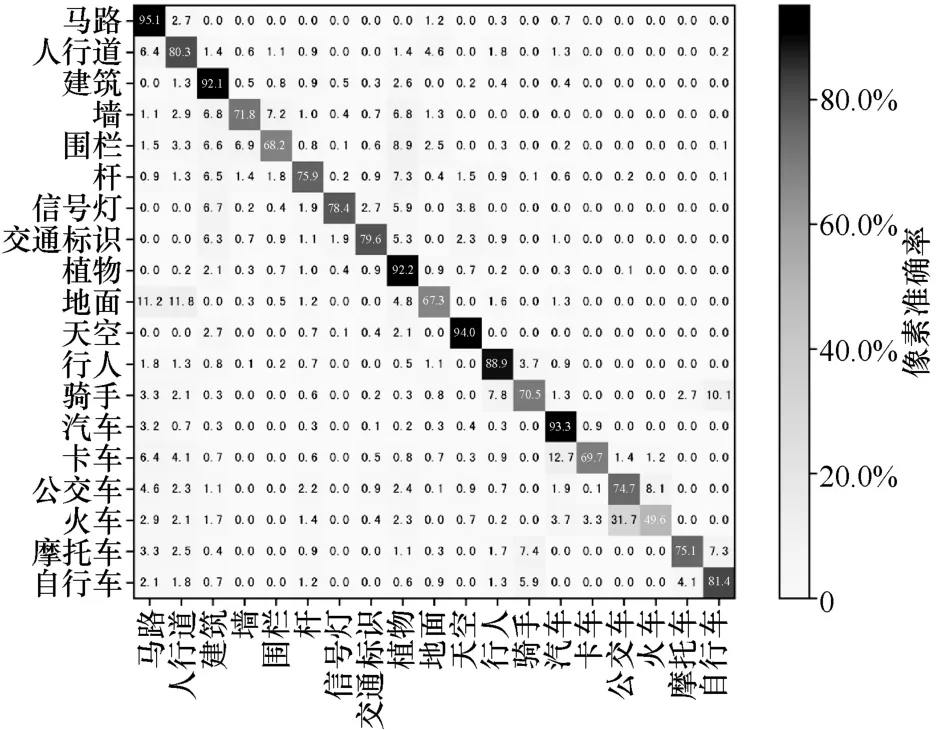
图4 语义分割混淆矩阵
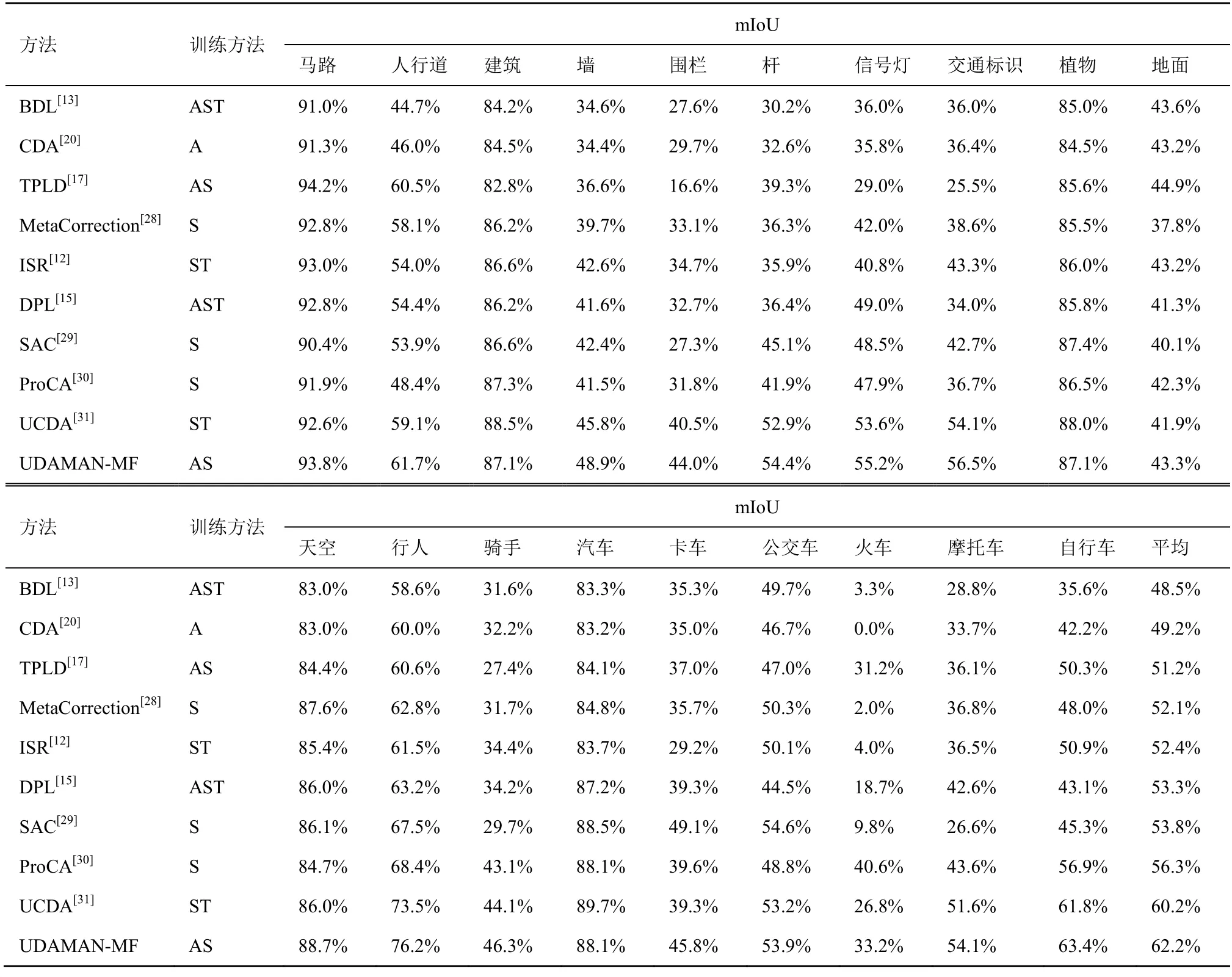
表1 源域GTA5 到目标域Cityscapes 上UDAMAN-MF 与先进方法的训练方法与分割精度
2) UDAMAN-MF 的消融学习
为研究3 层结构语义分割网络、改进自监督学习方法以及多级对抗学习方法对于UDAMAN-MF的性能影响,在源域GTA5 到目标域Cityscapes 的领域自适应上进行消融学习,结果如表2 所示。

表2 源域GTA5 到目标域Cityscapes 上的消融学习结果
首先,分别对低层子网GHVF、中层子网GHVF+GSSF和整个网络GHVF+GSSF+GMHF进行不包含自监督学习的单级对抗训练。当结构化学习层GSSF添加到特征提取层GHVF末端时,mIoU 从45.9%提升到49.2%;当特征融合层GMHF添加到结构化学习层GSSF末端时,mIoU 从49.2%提升到50.4%。分割精度提升的原因如下。第一,结构化学习层能够准确推理对象邻近4 个区域的全局上下文信息,同时,单级对抗学习可以减小领域间所学空间特征的分布差异,从而使网络G更加准确地推理目标域场景的全局上下文信息,进而能够基于空间结构化特征调优分类结果和避免分类错误。例如,虽然“行人”和“骑手”具有相似的视觉外观,但是能够根据邻近场景的空间结构化特性区分上述易混淆类别。第二,单级对抗训练的特征融合层能够基于注意力机制实现目标域场景中视觉和空间特征的有机融合,即根据对象邻近4 个区域的全局上下文信息与其自身视觉信息的相关性进行加权求和,从而自适应聚合有用上下文信息和避免噪声上下文信息,进而显著提升目标域场景所学多模态混合特征的质量。例如,对于“杆”“信号灯”和“交通标识”等尺寸较小的类别,基于注意力机制的自适应聚合可屏蔽背景噪声的引入,以避免尺寸较小对象的视觉信息遭到破坏。
然后,对整个网络GHVF+GSSF+GMHF分别进行不包含和包含改进自监督学习的单级对抗训练,实验结果表明包含自监督学习的对抗训练使分割精度提升了7.1%。这说明联合分布置信度和语义置信度的自监督学习在减小领域间分布差异上起到重要作用,该方法为分布接近源域并且语义分类概率较高的目标域子集生成标签,从而可以直接对齐选中目标域子集的分布,并大幅减小尚未对齐的目标域子集尺寸,进而有助于对抗学习对齐远离源域的无标签目标域子集的分布,以实现更大目标域子集的分布对齐。
最后,对整个网络分别进行单级和多级对抗训练,实验结果表明,与单级对抗训练相比,多级对抗训练使分割精度提升了4.7%。这说明多级对抗训练能够充分调优距离网络G输出端较远的低层子网GHVF和中层子网GHVF+GSSF的参数,从而全面减小领域间所学视觉、空间以及语义特征的分布差异,进而有效学习上述三类特征的域间不变表示,融合生成的多模态混合特征能够更准确地表达对象的综合语义特征。
3) UDAMAN-MF 的语义分割视觉效果
源域GTA5到目标域Cityscapes领域自适应的分割视觉效果如图5 所示。从图5 可发现,首先,与图5(b)相比,图5(c)的误分类像素大量减少,从而证明3 层结构网络有效提取多维视觉特征、显式推理空间结构化特征以及自适应融合多模态混合特征的能力;然后,与图5(c)相比,图5(d)对象轮廓更平滑,从而证明对抗学习联合改进自监督学习具有充分对齐目标域中各像素特征分布的能力;最后,与图5(d)相比,图5(e)中形状复杂对象的分割轮廓更精细,从而证明多级对抗学习具有全面拉近领域间视觉、空间以及语义等三类特征分布差异的能力。

图5 源域GTA5 到目标域Cityscapes 领域自适应的分割视觉效果
4) UDAMAN-MF 与先进方法的稳健性对比
为测试UDAMAN-MF 的稳健性,使用基于快速梯度标签算法生成的3 组扰动测试数据集评估所提网络抗噪声攻击的能力,3 组数据集分别由干净的Cityscapes 验证数据集和不同扰动幅度ε(分别为0.1、0.25 和0.5)的噪声输入PSPNet(pyramid scene parsing network)生成[32]。源域GTA5 到目标域Cityscapes 的抗攻击能力如表3 所示,其中,mIoU 表示扰动测试数据集上的平均交并比,mIoU*表示干净测试数据集上的平均交并比,mIoU drop表示mIoU 较mIoU*的下降值,若mIoU 越高且mIoU drop 越低,则表明网络的稳健性越强。
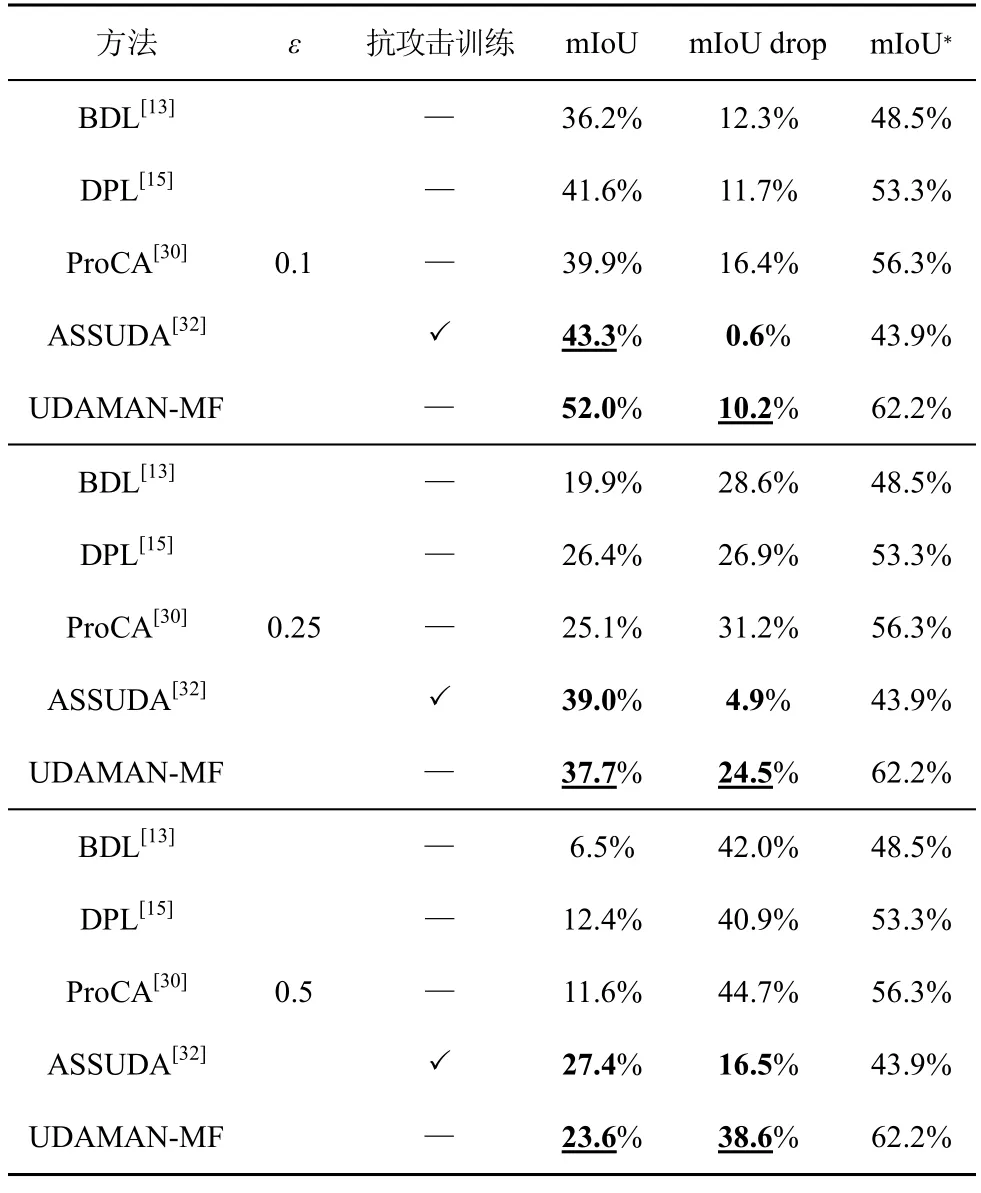
表3 源域GTA5 到目标域Cityscapes 的抗攻击能力
从表3 中可发现,第一,与没有抗攻击训练的方法相比,UDAMAN-MF 不仅在3 组扰动数据集上的mIoU 均最优,而且mIoU drop 也均最低,这说明所提网络具有较强的稳健性,从而证明全面减小领域间所学视觉、空间以及语义等三类特征的分布差异能够有效对抗噪声扰动的攻击,进而降低噪声扰动对所生成多模态混合特征质量的影响;第二,较抗攻击训练的ASSUDA(adversarial self-supervision unsupervised domain adaptation)网络[32],虽然所提网络在3 组数据集上的mIoU 优于或接近 ASSUDA,但是 mIoU drop 却均高于ASSUDA,这说明所提网络的稳健性逊于ASSUDA,导致稳健性不强的原因在于噪声扰动会再次拉大领域间的特征分布差异,从而破坏所学特征的域间不变表示。
2.3.2SYNTHIA 到Cityscapes 的领域自适应
源域SYNTHIA 到目标域Cityscapes 的分割精度如表4 所示,mIoU 为分割精度的评价标准。在相兼容13 种领域自适应中,UDAMAN-MF 在总体上将分割精度从63.1%提升到66.9%;同时,在相兼容16 种领域自适应中,UDAMAN-MF 在总体上也取得最优的平均交并比58.8%。
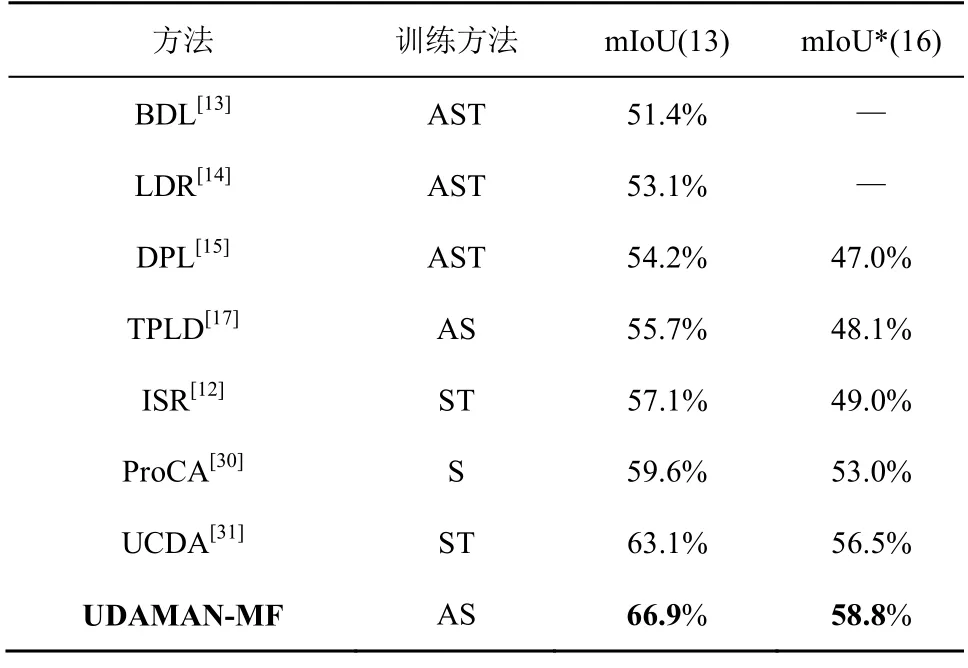
表4 源域SYNTHIA 到目标域Cityscapes 的分割精度
但是,对于墙、围栏以及杆等类别,UDAMANMF 分割效果不够理想,如图6 所示。这主要由于上述类别出现的频率不高,从而影响其有效学习。此外,由于源域SYNTHIA 和目标域Cityscapes 间存在较大的视觉风格差异(如光照和物体纹理),从而在一定程度上影响上述类别的分布差异拉近。因此,后续工作将在多级对抗学习中引入多级图像风格转换方法,从而尽量降低视觉风格差异对特征分布对齐的影响。

图6 源域SYNTHIA 到目标域Cityscapes 领域自适应的分割视觉效果
2.3.3 SUN-RGBD 到NYUD-v2 的领域自适应
为验证所提网络的普适性,本节在源域SUN-RGBD到目标域NYUD-v2的室内场景进行领域自适应学习,分割精度如表5 所示,像素准确率、平均准确率以及平均交并比为分割精度的评价标准。虽然相兼容类别多达37 种,但是所提网络在上述评价标准上仍取得最优的成绩,其PA、MA 和mIoU 分别为84.9%、74.6%和59.7%,较当前先进方法中的最优结果,上述3 项评价标准分别提升了3.6%、4.9%和4.5%。源域SUN-RGBD 到目标域NYUD-v2 领域的自适应分割视觉效果如图7 所示。从图7 可以看出,所提网络不仅能够准确地分割易识别类别(如墙面、地面、床、沙发和天花板等),而且可以较理想地解析形状复杂类别(如椅子和人等)。所提网络在室内场景领域自适应中取得的成绩主要归功于精心设计的3层结构语义分割网络和基于改进自监督学习的多级对抗学习方法,从而能够在目标域场景有效地生成融合对象视觉和空间信息的综合语义特征。

表5 源域SUN-RGBD 到目标域NYUD-v2 的分割精度
3 结束语
本文面向语义分割提出基于多模态特征的无监督领域自适应多级对抗语义分割网络。首先,所提3 层结构的语义分割网络能够分别从两域学习视觉、空间以及语义特征,从而为特征分布对齐奠定基础。然后,改进自监督学习能够确保选定目标域子集的稠密性和所生成标签的正确性,从而可以直接对齐有标签目标域子集的分布,与对抗学习相互结合,能够实现更大目标域子集的对齐。最后,多级对抗学习对3 路对抗分支与3 个子网分别进行单级对抗训练,从而有效学习各子网输出特征的域间不变表示。实验结果表明,在室外和室内场景的3 个数据集上,UDAMAN-MF 均取得最优的分割精度,证明其不仅具有全面对齐领域间视觉、空间以及语义特征分布的能力,而且具有良好的普适性。但是,当目标域数据遭受噪声扰动攻击时,所提网络无法理想地对齐特征分布,因此,后续工作将在多级对抗学习中引入抗攻击训练,从而提升网络的稳健性,以满足机器人任务规划和车辆自动驾驶等智能视觉任务对安全性的要求。
猜你喜欢
电力建设(2022年10期)2022-09-28
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
计算机技术与发展(2020年11期)2020-12-04
合肥工业大学学报(自然科学版)(2020年2期)2020-03-23
南京大学学报(数学半年刊)(2020年1期)2020-03-19
中国新通信(2019年21期)2019-03-30
航天器工程(2018年2期)2018-04-24
青年文学家(2015年29期)2016-05-09
都市丽人(2015年4期)2015-03-20
科技传播(2010年19期)2010-04-12
