
基于CBAM-Res2Net的人群计数算法
2023-01-09 07:16陈江川吴云韬
武汉工程大学学报 2022年6期
陈江川,吴云韬*,孔 权
1.武汉工程大学计算机科学与工程学院,湖北 武汉 430205;
2.智能机器人湖北省重点实验室(武汉工程大学),湖北 武汉 430205;
3.武汉工程大学艺术设计学院,湖北 武汉 430205
人群计数是近年来计算机视觉领域中的一个热门研究领域,其目的是通过计算机对输入图像的处理来估计图像中的人数。随着城市化的进程以及世界人口的不断增长,在火车站、体育场、音乐会和游行等许多场景中,可能会出现大量人群快速聚集的情况。而人群计数能够针对这些特定场景下的人群目标数量进行估计,做到对重大事件的事先警告以及在事后复盘中发挥积极作用[1]。此外,人群计数方法也能够辅助实现实时估计场景人数,进而对各个场景中人数进行有效的管控,减少人群的聚集,这对当下新冠肺炎疫情的控制起着不可或缺的作用。
在早期的人群计数中,大多使用基于检测的方法,这些方法通常通过一个滑动窗口在图像上对人或头部进行检测。然而其准确性和模型性能却极容易受到目标尺度大小不一、目标间重叠、背景干扰、图像分辨率低等因素的影响。为了改善这些问题,Chen等[2]提出了基于回归的方法。该方法直接学习从图像到计数的映射,虽然从整体上来说提升了计数的性能,然而回归的计数方法依旧忽视了图像中的空间信息,仅仅只得到一个最终的计数结果,因此缺乏可靠性和解释性。
近年来,卷积神经网络(convolutional neural networks,CNN)发展迅速,相较于传统技术来说,使用深度学习技术的算法往往能够获得更好的性能,并且具有更强的泛化能力。因此,越来越多的基于CNN的方法被应用于人群计数领域[3-5]。不同于传统方法需要手工制作特征,基于CNN的方法[6]对于输入的人群图像自动的提取特征,并在末端通过一个卷积核大小为1×1的输出层生成包含人群数量信息和位置信息的密度图。
针对人群计数中的尺度变化问题,Zhang等[7]提出了一种多列卷积神经网络(multi-column CNN,MCNN),每一列使用不同大小的卷积核,这种结构在一定程度上缓解了计数目标尺寸大小不一致的问题。Shi等[8]提出了一种尺度聚合网络(scale aggregation network,SANet),不 同 于MCNN,该网络采用分层的方式提取多尺度特征,以进行后续处理。虽然多列卷积神经网络相较于传统算法拥有了更好的性能和泛化能力,但由于其多列的特性导致网络结构冗余,模型参数繁多、训练困难,因此为了克服这些问题,越来越多新型的CNN结构被引入到人群计数领域。Li等[9]提出了一种空洞卷积神经网络模型(network for congested scene recognition,CSRNet),采用空洞卷积神经网络,在保持分辨率的同时扩大感受野,保留了更多的图像细节信息。Liu等[10]提出了一种融合注意力机制的可形变卷积网络(attentioninjective deformable convolutional network for crowd understanding,ADCrowdNet),该网络的注意力生成器(attention map generator,AMG)可以过滤掉复杂背景等无关信息,使得后续模型只关注人群区域。
本文提出的方法从增强特征的尺度适应性和降低背景噪声干扰两方面进行了优化,从而达到提高人群计数性能的目的,并进行了模型消融性实验,验证了本文方法的有效性。
1 人群计数网络
为了实现在静态图像中进行人群计数,本文结合卷积注意力模块(convolutional block attention module,CBAM)[11]与Res2Net模块[12],提出了一种基于CBAM-Res2Net的人群计数算法,网络模型的结构如图1所示。该网络可以分为前端网络、CBAM-Res2Net模块以及后端网络3个部分,整个网络的输入为一幅人群图像,输出为对应的人群密度图。

图1 整体网络架构Fig.1 Overall network architecture
该网络前端部分为视觉几何组网络(visual geometry group networks,VGG)16[13]网络的前10层,对输入图像进行初步的特征提取。为了解决背景噪声干扰等问题引入了CBAM模块,该模块能够对输入的特征分别在空间域和通道域上编码注意力特征,让模型更多的去关注人群区域。由于人群图像广泛存在拍摄角度差异大,目标尺度变化不均匀等问题,仅靠VGG在整个图像上编码相同的感受野难以得到完整的多尺度信息,因此引入了多尺度特征提取模块Res2Net,它通过在一个残差块中构造分层残差连接来实现。并在此基础上串联Res2Net模块和CBAM模块组合成CBAM-Res2Net模块来提升模型的计数性能和泛化能力。后端网络设计了一个扩张模块以提取更深层的特征并进行特征融合回归。
1.1 卷积注意力模块
在计算机视觉领域,注意力机制可以让网络像人一样有选择地关注图像信息的突出部分。因此,为了防止背景噪声对特征图的干扰,在网络中引入了卷积注意力模块CBAM,如图2所示。CBAM模块不仅关注通道域信息,同时也关注空间域信息,因此相较于单通道域注意力网络(squeeze-and-excitation networks,SENet)[14],
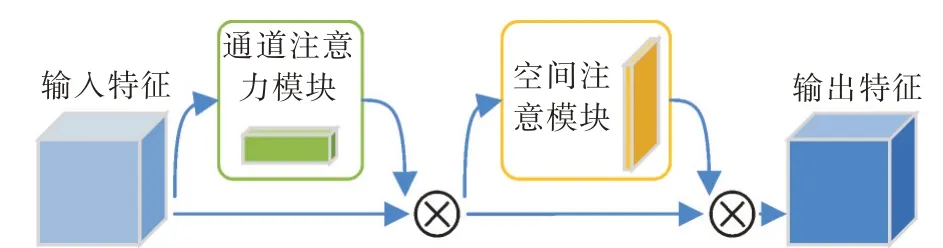
图2 卷积注意力模块Fig.2 Convolutional block attention module
CBAM模块更适合需要关注人群空间分布信息的人群计数任务。通道注意力模块通过学习特征间的通道关系生成通道注意图,空间注意力模块通过学习特征间的空间关系生成空间注意力图,根据通道和空间注意力图对特征进行调整,以达到提高特征图中人群区域权重的目的。
1.2 多尺度特征提取模块
多尺度特征现已广泛应用于计算机视觉任务中。然而,大多数现有方法以分层的方式表示多尺度特征。Gao等[12]提出了一种新的构建模块,即Res2Net模块,它通过卷积分组的方式以更细的粒度提取多尺度特征。输入特征图在通过1×1卷积后被均分为s组,原先通道数为n的卷积层也被均分为s组通道数为n/s的小卷积层,每一组特征图都会输入到与其对应的小卷积层,并将其输出结果和下一组特征图相加后输入到下一个小卷积层。当所有的小卷积层都输出结果后,将这些特征图进行拼接并通过1×1卷积对多尺度信息进行融合。在这个过程中,分组后的输入特征图经过所有路径,并融合为输出特征图,由于组合效应,每经过一个3×3的卷积层,其感受野都会增加。
图3展示了残差块和Res2Net模块之间的差异[12]。在通过1×1卷积之后,将输入特征均匀地分割为s个特征子集,并用xi表示,其中i∈{1,2,…,s}。每个特征子集xi都具有相同的空间大小。除了x1以外每个xi都有与之相对应的3×3卷积,用Ki来表示,并将其输出表示为yi。yi的定义公式如下:
在Res2Net模块中,使用了一个新的控制参数“规模”,用s来表示,更大的s能使模型拥有更大的感受野。图3(b)中s设定为4,在模型中s设定为8。为了减少模型的参数量,省略了第1次分割后的卷积,这也是特征重用的一种形式,假设输入输出特征的通道数分别为Ic和Oc,对于残差块,其参数 量 为3×3×Ic×Oc,即9×Ic×Oc,对 于Res2Net模块,其参数量为(s-1)×9×(Ic/s)(Oc/s)。显然Res2Net模块具有更少的参数量。
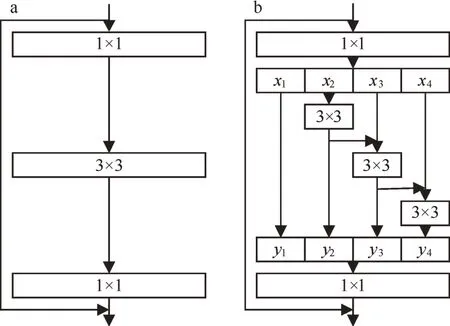
图3 (a)残差块,(b)Res2Net模块Fig.3(a)Bottleneck block,(b)Res2Net module
1.3 CBAM-Res2Net模块
本文设计的CBAM-Res2Net模块如图4所示。在Res2Net模块中集成CBAM模块,能够使CBAM模块的优势更加突出,即在残差单元内部实现在空间域和通道域上对原始特征的重标定,完成特征调整。将CBAM模块添加在Res2Net模块的残差连接之前,1×1卷积之后,这也是目前主流的网络结构对于残差块和注意力模块的组合构造 方 式,如SE-Res2Net、SE-ResNet以 及SEInception等。
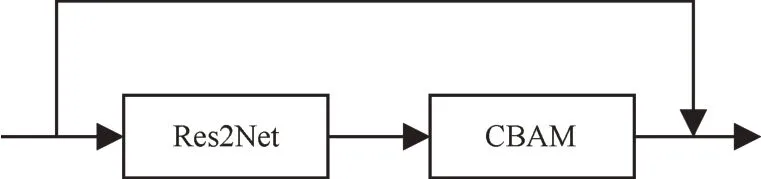
图4 CBAM-Res2Net模块Fig.4 CBAM-Res2Net module
1.4 损失函数
本文模型在训练中使用欧氏距离来评估真实密度图与预测密度图之间的差异,因此将欧氏距离作为损失函数来调整预测密度图的生成,具体公式如下:
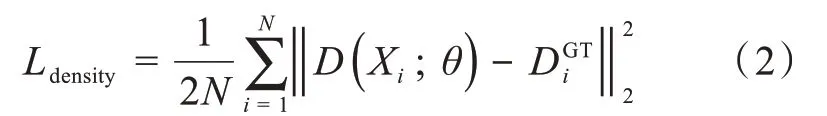
式中,N是一次训练图片的总数量,Xi为第i张训练图片,D(Xi;θ)为第i张图片的预测密度图,其中i∈[1,N],θ为网络模型参数,为第i张训练图片的真实密度图。
2 实验部分
2.1 真实密度图的生成
为了获得真实密度图,采用了与之前工作[9]相同的策略,即使用几何自适应高斯核生成密度图,作为预测学习的标签,具体公式如下:

式中,x为图像中的像素点,xi表示第i个人头在图片中的位置,G(x)为高斯核滤波器为每个人的头部与其相邻的k个人之间的平均距离,β参照文献[9]设置为0.3。
2.2 实验环境和参数设置
实验所使用的是NVIDIA-3060 12 GB显卡,深度学习框架为PyTorch 1.11.0。在模型的训练过程中,对于图像尺寸大小不一致的数据集使用批量大小为1的随机梯度下降(stochastic gradient descent,SGD)优化器进行训练,对于图像尺寸固定的数据集使用批量大小为8的Adam优化器进行模型优化。由于人群数据集图片有限,为了获得更多的图片用于训练,进行了数据增强工作,即在不同的位置将图像随机裁剪为原始大小的1/4,并对裁剪后的图片进行镜像翻转。
2.3 评价指标
选取平均绝对误差(mean absolute error,MAE)和均方根误差(root mean square error,RMSE)作为评价指标,MAE通常用来评估人数估计的准确性,其值越小也就表明该算法的准确性越好,而RMSE通常用来量度算法的鲁棒性,其值越小也就表明该算法的鲁棒性越好。MAE和RMSE的定义公式如下:Ci和CGTi分别为第i张图像中的预测人数和真实人数。
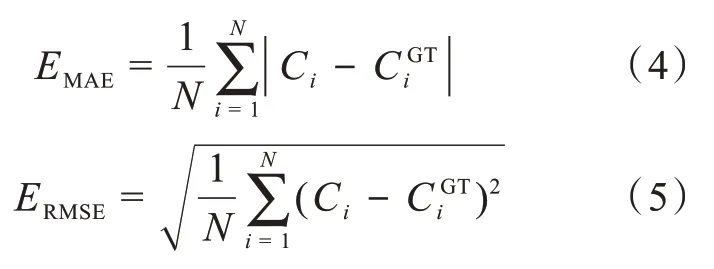
2.4 数据集与实验结果分析
2.4.1 ShanghaiTech数据集ShanghaiTech数据集中共有1 198张图片并根据人群密度等级分为A、B两个部分。其中A部分包含482张人数从33到3 193人不等的图像,平均人数为501人,训练集和测试集分别包含了300和182张图像。B部分中包含了716张人数范围为9到578人的图片,平均人数为124人,训练集和测试集分别包含了400和316张图像。数据集的总共标记人数达到了330 165人。该数据集的实验结果如表1所示。
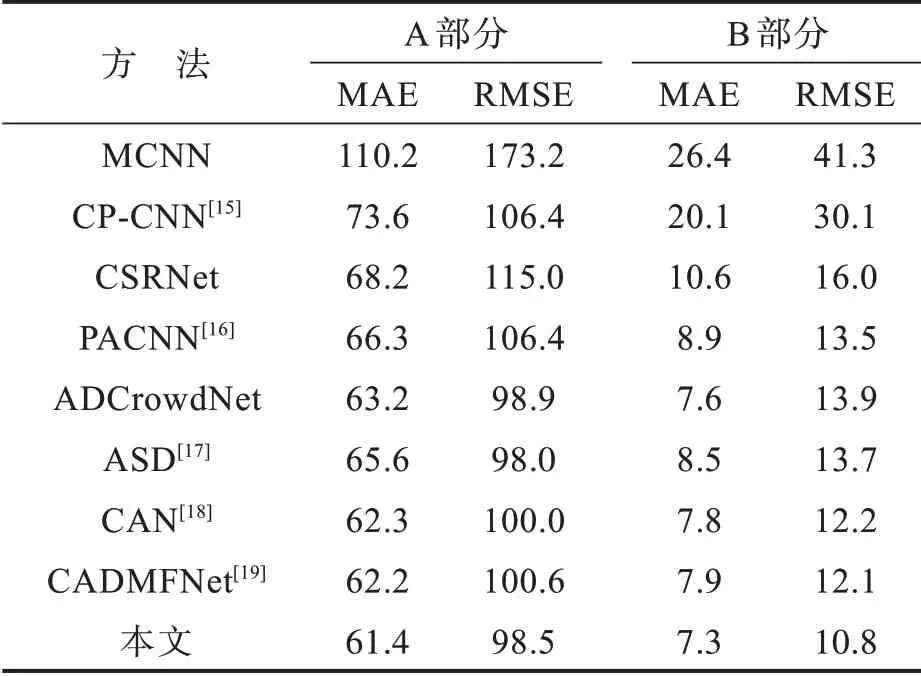
表1 基于ShanghaiTech数据集的实验结果对比Tab.1 Comparison of experimental results on ShanghaiTech dataset
与现有算法相比,本文方法在B部分上的性能指标MAE与RMSE均取得了最优的结果。而在A部分,本文方法在RMSE的表现上仅次于ASD,在MAE的表现上取得了最优。
2.4.2 UCF_CC_50数据集UCF_CC_50数据集中共有50张图片,其中场景包括火车站、大型游行、演唱会等大量人群聚集的场合。每张图片包含的人数从94到4 543人不等,数据集的总共标记人数达到了63 974人,平均每张图片标记的人数为1 280人。该数据集的实验结果如表2所示。由表2可见,即使在这种人群密度变化大、人头模糊、背景复杂的数据集上,本文方法的性能依然优于其它算法。
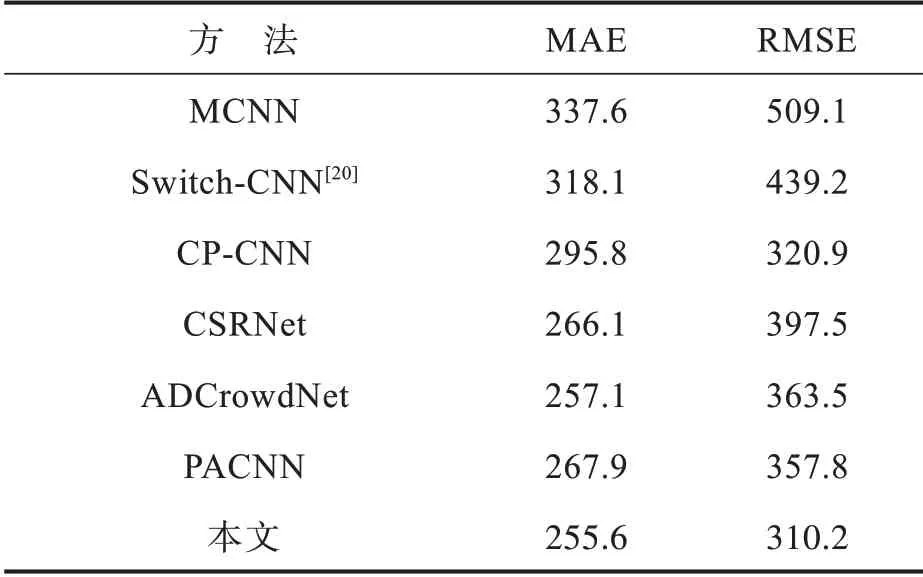
表2 基于UCF_CC_50数据集的实验结果对比Tab.2 Comparison of experimental results on UCF_CC_50 dataset
2.4.3 实验结果可视化为了能够直观的展示本文方法的预测效果,列出了部分在不同数据集上生成的预测密度图的可视化结果,真实密度图和预测密度图的计数结果均标注在图片右下角,如图5所示,其中第1行和第2行为ShanghaiTech数据集Part B中的测试图像,第3行和第4行为ShanghaiTech数据集Part A中的测试图像,第5行和第6行为UCF_CC_50数据集的测试图像。由图5结果可知,本文模型能够有效的学习人群图像和人群密度图之间的映射关系。
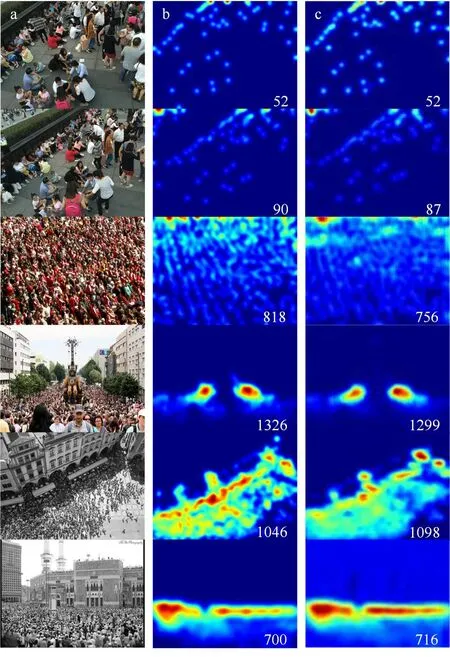
图5 可视化结果:(a)人群图像,(b)真实密度图,(c)预测密度图Fig.5 Visual results:(a)crowd images,(b)ground-truth density maps,(c)estimation density maps
2.4.4 消融实验为了验证Res2Net模块和CBAM模块的有效性。在ShanghaiTech B数据集中进行了相关的消融实验。其中Baseline为本文模型去掉CBAM-Res2Net模块之后的网络,结果如表3所示。

表3 基于ShanghaiTech Part B数据集的消融实验结果Tab.3 Ablation experimental results on ShanghaiTech Part B dataset
从表3中可以看出在加入Res2Net模块和CBAM注意力模块后均可以使人群计数的MAE和RMSE下降,具有提升计数准确性的效果。在加入CBAM-Res2Net模块之后,本文模型的计数效果得到了显著的提升。
3 结论
本文对CSRNet进行改进,在其后端网络前加入一种融合注意机制的多尺度特征提取模块CBAM-Res2Net,该模块采用Res2Net提取多尺度特征进行融合,融合后的多尺度特征对尺度变化具有良好的鲁棒性;采用CBAM提升特征图中人群区域的权重,并抑制弱相关的背景特征。在ShanghaiTech和UCF_CC_50公共数据集上,本文模型均具有良好的准确性和鲁棒性。但本文中的方法仍有不足之处,在经过3次最大池化后,生成的密度图的高度和宽度只有输入图片的1/8大小,这对最终的计数结果带来了负面影响。在未来的工作中,将针对如何生成高分辨率高质量的密度图进行研究,进一步提高人群计数的精度。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
数学小灵通(1-2年级)(2021年11期)2021-12-02
中等数学(2020年8期)2020-11-26
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
小学生学习指导(低年级)(2020年4期)2020-06-02
甘肃教育(2020年22期)2020-04-13
数学大王·低年级(2019年8期)2019-08-27
第二课堂(课外活动版)(2016年2期)2016-10-21
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
