
电力业务流转数据库中分布式数据一致性算法
2023-01-08 16:49明哲,余芸,甘杉
电子设计工程 2023年1期
明 哲,余 芸,甘 杉
(南方电网数字电网研究院有限公司,广东广州 510000)
电力业务流转数据库中分布式数据的处理对电力业务的管理效率有较大的影响,传统方法采用在数据库中复制数据的方式完成电力业务流转数据的处理,以此保证电力数据的一致性,但是该方式会增加电力系统的内存开销,不仅降低业务流转的速度,而且还加大了电力系统的存储负荷[1-2]。
为了解决上述问题,该文设计了新型的电力业务流转数据中分布式数据一致性算法,采用数据分层异步复制方式优化现有算法中的数据复制方式,提高电力业务流转数据处理效率。
1 封锁协议和解锁协议
传统的数据库分布式数据一致性算法在应用时,数据复制和转发过程中没有设置相应的验证行为,导致电力业务数据转发时出现目标误识或者不识的故障[3-4],为了解决以上问题,在算法中融入了两个阶段的协议,分别是对电力业务流转数据的封锁和解锁协议。
在数据库中设置协议可以避免一些不安全的行为,如部分隐藏的危险电力业务数据跟随通过验证的数据成功传输到数据库中,对电力业务流转数据的安全造成威胁。两个协议具有唯一性,一个周期内的电力业务流转数据转发,只能申请一个封锁协议,只有对此封锁协议解锁后,才可以重新申请数据封锁协议,避免出现解锁密钥不匹配,电力业务自动销毁的情况。具体的封锁和解锁协议与数据库和电力业务流转数据之间的关系如图1所示。
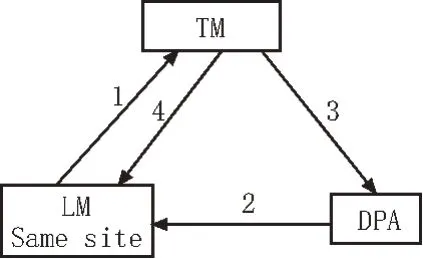
图1 协议与数据库和电力业务之间关系图
其中,TM 表示电力业务流转数据管理器;LM 表示接收数据库;DPA 表示数据处理管理器[5]。
封锁协议利用集中式封锁技术完成部署,数据流转过程中,由数据库向电力系统内的锁管理器申请一个封锁空间,并获取锁空间权限。此操作完成后,利用锁管理器发送的数据封锁的辨识码,并向封锁字典获取解锁密钥,但是此密钥此时只秘密地存储并转发到解锁协议中,封锁协议不具有查看的权限[6-7]。然后获取需要向数据库中通信的电力业务流转数据条,获取后直接将数据条封锁,封锁数据条数量与业务数据流转数量保持一致,禁止私自增加或者减少电力业务流转数据的数量。最后释放封锁的数据流,目的是向解锁协议和数据库发送待通信通知[8-9]。
解锁协议利用并发控制技术完成部署,解锁流程为首先获取电力业务流转数据封锁协议的封锁空间序列号,然后对应序列号验证此封锁协议是否是正规的封锁信息,如果不是,立即销毁;如果是,则进行下一步操作。其次,获取封锁协议自带的解锁密钥。获取密钥时,解锁协议需携带封锁释放数据和解锁密钥。最后解密封锁协议封装的电力业务流转数据,完成后释放电力业务流转发数据的锁空间[10-12]。
2 分布式数据一致性分析
2.1 分布式数据一致性控制分析
电力业务流转数据库分布式数据一致性算法的目的是在不更改数据库中主体数据的前提下,对电力业务流数据与数据库中已存在的数据进行匹配,如果存在相同电力业务流转数据,则对数据库内的主体和副本数据进行更改,如果不存在,则直接存入即可[13]。算法必须记录所有传入数据库内的电力业务流转数据的转发时间戳和RD 地址,为后期数据库内电力信息的调用奠定基础。算法的具体计算原理如图2 所示。

图2 一致性算法原理
电力业务流转数据库中数据一致性校验的关键是使数据库中不存在重复或冗余的电力业务流转数据信息,分布式数据一致性算法判断数据库中是否存在相同电力业务流转数据信息的过程,如下所示:

其中,ts(MD)表示数据库中主体数据的时间戳信息;ts(RD) 表示数据库中副本数据的时间戳信息;Update(RD) 表示封信副本信息的数据;B表示数据复制算法;Read(RD)表示读取数据库中副本数据信息[14]。
电力业务流转数据库中数据一致性算法在一致性校验时,不仅校验的是电力业务数据内容,而且还依次校验了电力业务信息流中包含的分布式数据,如节点数量、属性、目录地址、RD 地址等数据,以此防止发生更新不相同的数据时造成数据丢失的情况。算法确定数据库中数据一致性后,在执行算法时,必须先删除数据库中冗余数据的全部注册信息的主参数和基本参数后,再存储新数据。为了防止因为算法校验错误,导致数据库中数据丢失,数据库中待删除数据信息副本的所有参数会临时存储一段时间[15-16]。
数据库中数据一致性算法的能耗计量公式如式(1)所示:

式(1)中,co表示电力业务流转数据量;c1表示数据库和电力传输业务流转数据初始化的时间;X表示传输速率。
2.2 分布式数据分层复制分析
分布式数据分层复制操作的核心是分别处理数据库中主本和副本的数据,一方面可以将电力业务分布式数据流存储到数据库中,另一方面又可以备份数据库中已经更新的分布式数据,保障数据库内信息的安全。
该文采用的分布式数据分层复制操作的指导算法为Directory 协议,此协议操作简单,可以快捷完成电力业务流转数据复制的工作。数据信息复制的工作主要包括读取和写入两个操作行为,当数据库中不存在重复的分布式数据时,此协议只需要读取通信的数据,读取后判断此业务流转数据信息是否与数据库中分布式数据相同,如果不存在相应的数据,直接写入到数据库中即可。如果数据库存在分布式数据,则协议首先需要对数据库中原始的分布式数据进行读取和删除操作,再写入转发的电力业务流转数据,完成分布式电力业务的复制。
3 实验分析
通过以上的论述和分析,完成了电力业务流转数据库中分布式数据一致性算法的设计。为了检验算法的可行性,设计了对比实验。
3.1 实验准备
测试前需要提前准备一个存在大量数据业务的电力系统、独立的30 条电力业务数据条以及一个内存空间足够大并且存有数据的数据库,作为测试样本。将文献[3]基于信息分散算法的分布式数据实时存储方法、文献[4]基于一致性算法的电力系统分布式经济调度方法以及该文方法三个算法分别隶属于三台计算机。计算机内录入数据库,连接电力系统,开始实验测试,记录开始时间。
实验测试的流程是同时启动三台计算机,并且同时向三台算法隶属的电力系统部署和发送需要传输的电力业务流转数据信息。当三个系统全部完成电力业务流转数据库操作后,保存所有算法工作产生的数据记录,关闭系统、断开数据库连接、关闭计算机,结束实验,进行实验结果分析。
3.2 能耗和经济开销分析
实验结束后,根据计算反馈的基本信息对比三个算法通信过程中的能耗和经济开销,如图3 所示。
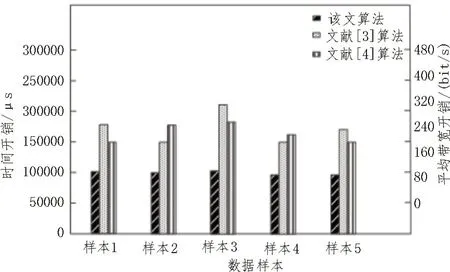
图3 能耗和经济开销实验图
图3 中,样本1-5 中均包含了300 个传输数据。由图3 可知,文献[3]算法在整个完成任务周期内能耗开销和经济开销都是最高的,该文设计算法的开销是最低的。因为在电力业务流转数据库操作中一定会存在能耗开销和经济开销,设计算法降低了隶属系统的能耗和经济开销,保证电力业务传输的利益。
3.3 收敛速度分析
分析数据库接收500 个电力业务流转数据后,得到三个算法传输电力业务流转数据的收敛速度,结果如图4 所示。
根据图4 可知,三个算法传输电力业务流转数据的收敛时间均为7 s,但是图中三个算法最终汇聚的点不同,此汇聚点表示算法一致性收敛的速率。其中,该文设计算法的收敛速度最快,文献[3]算法的收敛速度最慢。因此,根据三个算法完成任务的时间和电力业务流转数据收敛速度,可以证明该文设计的电力业务流转数据库中数据一致性算法具有最佳收敛特点,并且工作效率优于现有的一致性算法。

图4 不同算法一致性收敛速度实验图
3.4 响应延迟时间分析
关于算法的响应速率实验结果,如图5 所示。
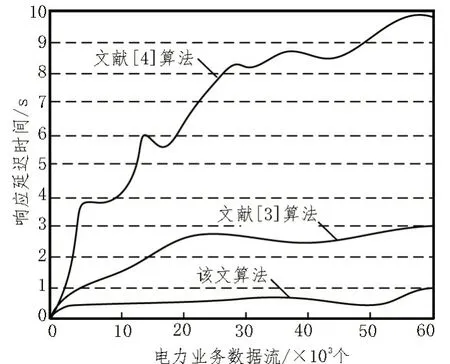
图5 不同算法响应延迟时间示意图
图5 展示的是三个算法在向数据库中传输电力业务流转数据的响应延迟情况,由图可知,三种算法在响应过程中,随着传输电力业务流转数据量的增加,算法的响应延迟效果越明显。根据电力业务管理规定,业务流转数据库的响应延迟时间不大于2 s,即为系统处于正常运行状态。传输10×103个电力业务流转数据时,文献[3]算法和该文设计算法的响应延迟时间均在2 s 以内,该文设计算法延迟时间更低,在0.5 s 左右,文献[4]算法达到3.9 s,无法正常运行。但是在经历了20×103个电力业务流转数据转发时,文献[3]算法的响应延迟已经达到了2.7 s,该文设计的算法响应延迟持续为0.5 s 左右。在完成所有的电力业务流转发到数据库中的任务后,该文设计算法的响应延迟时间最高为1 s,但是两个对比算法的响应延迟时间持续上升。由此可以证明设计的电力业务流转数据库中数据一致性算法的响应延迟达到了认证标准,具有一定的可用性。
3.5 误传率分析
最后对数据库中接收到的数据进行检验,查看所有算法转发的30 条电力业务数据成功转发的条数,为保证实验的严谨性,将误传率实验次数设置为8 次,由此得到数据转发的误传率,得到的误传率实验结果如图6 所示。
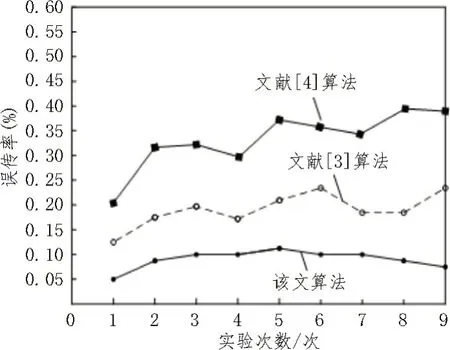
图6 误传率实验结果
由图6 可知,文献[4]算法在通信电力业务数据时,误传率最高;文献[3]算法对应数据库次之,且误传率均高于该文算法,该文设计算法误传率最高为0.10%。
综合上述实验结果可知,该文设计的电力业务流转数据库中数据一致性算法具有较高的通信收敛速度,传输的响应延迟和误传率均符合应用标准。
4 结束语
电力业务流转数据库中分布式数据一致性算法不仅可以加强电力领域相关业务的管控,而且提高了电力业务的处理效率。集中式控制和并发式控制封锁协议涵盖了目前电力业务流转数据一致性算法验证的多种状态,避免电力业务流转数据库中出现格式单一匹配错误、数据多次转发情况的发生。在该文电力业务流转数据库中分布式数据一致性算法分析的基础上,可以进一步对一致性算法进行优化或者更改,应用在电力业务流的其他工作程序中,达到电力业务处理流程节能、高效的效果。
猜你喜欢
公民与法治(2022年5期)2022-07-29
教学考试(高考物理)(2021年5期)2021-11-08
中医眼耳鼻喉杂志(2021年1期)2021-07-22
新世纪智能(高一语文)(2020年5期)2020-07-24
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
燕山大学学报(2015年4期)2015-12-25
雷达与对抗(2015年3期)2015-12-09
自动化博览(2014年12期)2014-02-28
军事历史(2004年3期)2004-11-22
