
智能配网调度命令票语义合规性校验模型
2023-01-08 16:48孟子杰吴龙腾蔡新雷黎嘉明梁升洪
电子设计工程 2023年1期
孟子杰,吴龙腾,蔡新雷,黎嘉明,梁升洪
(1.广东电网调度控制中心,广东广州 510600;2.肇庆供电局电力调度控制中心,广东 肇庆 526201)
智能配网安全和最优经济运行是持续性研究的关键课题[1-2]。目前我国用电负荷日益攀升,供电短缺问题非常严重。电力调度是电力生产与分配的关键,在发电与供电企业中均占据重要地位[3]。调度员为电网操作者,肩负着电网稳定安全运行的职责。各级别调度均规划出严格的电力调度操作规范与记录的填写需求,下发每项调度命令前要谨慎填写和打印调度命令票,调度命令票即为电网设备操作中最为核心的步骤[4]。
为确保调度命令票内容严谨性与可靠性,该文在获取调度文本内容的同时,使用基于规则的设计标准,完成语义合规性校验模型的构建。
1 智能配网调度命令票文本数据采集
为准确校验智能配网调度命令票语义合规性是否符合要求,首先采集调度命令票中的文本数据。将调度命令票数据作为研究目标,创建蚁群优化下的文本数据采集方法。蚁群优化算法包含如下步骤:更改信息素更新模式、增添信息素负载调节元素。
设定待处理文本集合为Task,可用服务器集合为M,分别描述为:
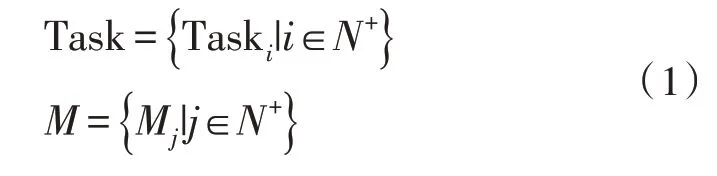
式中,Taski代表第i个任务仅在一个服务器内接收,Mj是第j个服务器。
智能电网调度取决于待处理任务与服务器,对Task 和M采取笛卡尔积运算,获得调度数据集合K。依照K值推算出调度命令票打印执行时间,打印时间为T。
初始化蚁群优化算法内的启发函数与信息素函数,依次将两个函数解析式记作:
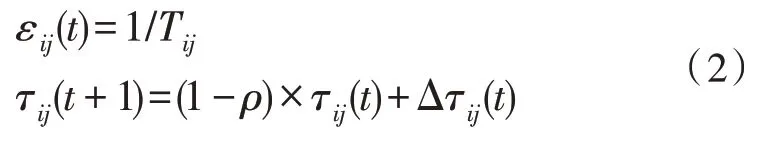
信息素函数代表Taski分配至Mj的信息素浓度,Δτij为信息素增量,1-ρ是信息素浓度残余量。在蚂蚁k实现一次遍历后,获得遍历选择节点局部信息素更新后的增量值:

更新全局信息素最佳路径增量,得到:

蚂蚁b从目前节点i访问下一个邻近节点j的几率是:
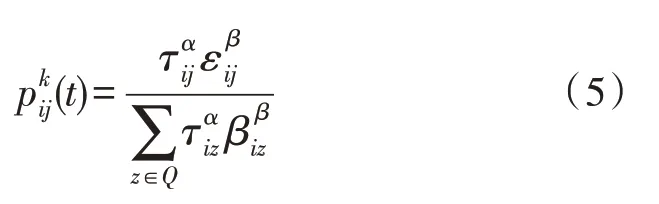
式中,α、β分别为蚂蚁在打印调度命令票时路径内的残余信息素与启发式数据对智能电网调度的影响。
引入信息素负载调节元素[5],记载各台服务器目前打印调度命令票的时间,将信息素函数改写为:
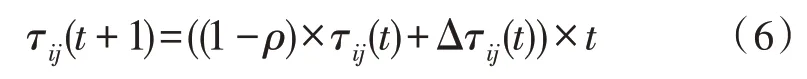
对比全部蚂蚁此次迭代内的路径,挑选最佳路径,调节信息素[6],记载此次挑选的目前最优解。凭借调整后的信息素与启发式数据实施下一次搜寻,直至迭代终止。从迭代结果内挑选最优解,完成数据采集任务。
2 调度命令票文本数据预处理
获得调度命令票内的文本数据后,使用k 均值聚类算法将具有相同特性的调度命令票语义内容聚类在一起,减少后续校验操作复杂度。k 均值聚类算法类属聚类技术内的基础分类手段,拥有简便快捷的计算优势。k 均值聚类算法将欧式距离当作相似度权衡标准,欧式距离计算公式记作:
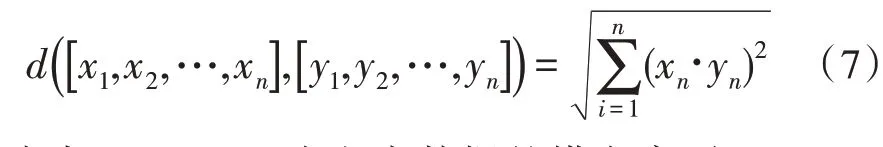
式中,x1,x2,…,xn为文本数据的横向序列,y1,y2,…,yn为文本数据的纵向序列。k 均值聚类算法使用偏差平方与准则函数[7]当作聚类标准,描述成:
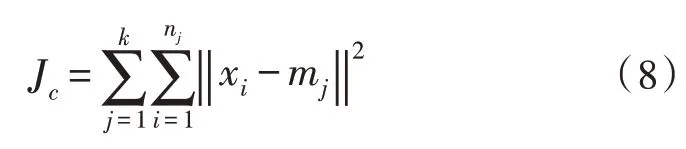
其中,k表示要构成聚类的数量,nj是第j类内样本数量,mj是第j类样本平均值,也是此种类型集合的核心点:

从N个样本数据目标任意择取D个点当作原始聚类中心,针对其他剩余点,按照其自身和聚类中心的间距,依次将其配发至和自身最相近的聚类集合,再推算新聚类集合的聚类中心,按照相似度完成重新分配[8-9],重复执行以上操作,直至各个簇中的对象不会发生改变为止。
研究传统k 均值聚类算法可知,D值是预先设定的,在真实应用中,D值的挑选过程难度很高,多数情况下无法获得准确数值。k 均值聚类算法任意择取原始聚类中心,致使很多的迭代结果精度不高[10]。下面对传统k 均值聚类算法做出以下完善:
想获取准确的聚类结果,最大限度维持每个聚类中心的间距为最大,因此,设计一个最远距离下的原始聚类中心挑选方法。
最远距离方法首先要获取参加聚类的N个数据目前两两之间的间距,继而构造距离矩阵[11]。扫描矩阵择取全部目前距离最远的两个点当作前两个原始聚类中心。挑选不同的中心点,直至中心点数量与D值相等。利用余弦夹角推算矢量之间的相似度,将余弦夹角距离运算过程描述成:
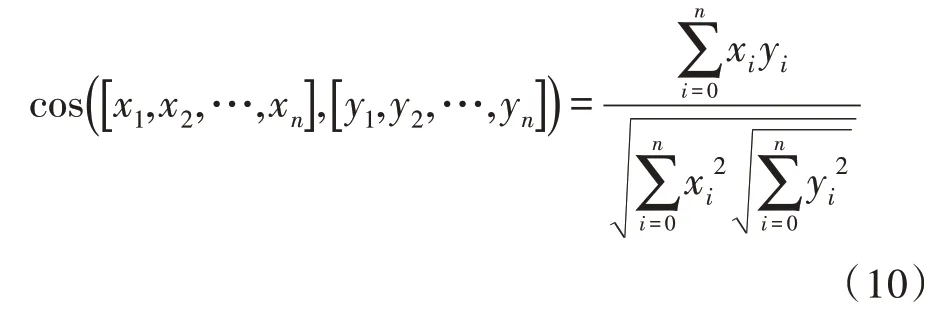
矢量之间的相似度和余弦值为反比例关联,余弦值越高,表明两个点的间距越小,反之两点之间的距离越大。k 均值聚类算法的关键点是明确D值,也就是聚类数量。由于传统方法缺少得到D值的先验知识,因此对D值的计算难度较高。一般状态下,聚类数量要远低于样本集合内的目标总量,不然会削减后续校验模型计算结果精度。该文使用和错误率相似的目标函数来完善调度命令票文本数据测量性能。
设定xi为第i个目标的矢量,ci∈{1,k}表示与之相呼应的聚类索引,创建一个明确聚类D值的方法[12],即求解聚类平均值的总方差:
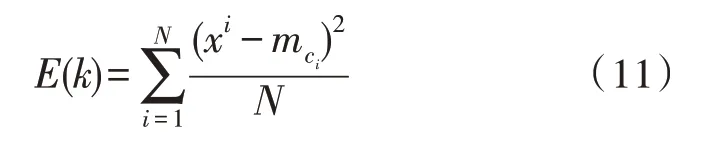
关于各个目标的矢量xi及其聚类平均值mci,算出N个文本的平方误差均值E(k),更改k值,计算出三个聚类集合,并返回k 均值聚类算法。利用k值的改变对比目标函数值大小,挑选k值的基础原则是增加k值,对应的方差不会减小。
假如用户不知晓智能配网调度命令票文本数据目标集合分布情况,就不能选定一个恰当的D值。改进后的k 均值聚类算法可完成簇个数D的自适应评判,利用聚类结果及聚类均值方差总和获得最优聚类结果相应的D值。对于N个文本目标聚类,其簇的个数一定低于D值。
3 命令票语义合规性校验模型
通过上述计算过程,把调度命令票按特征分为不同的数据集合,此时要进一步对其进行合规性校验。该文创建一个基于规则的语义合规性校验模型,系统性分析模型构建过程及其性能。
针对普通用户,模型供应的图像界面配备规则文件,具备可扩展标记语言基础知识的用户,采用规则描述文档[13],模仿可扩展标记语言文件模式直接完成校验工作;具备相关编程知识的用户,则能创建专属的规则类,拓宽规则类型,使语义合规性校验的应用范围更加广泛,降低校验失误的可能性。
3.1 模型运行过程
所建模型包含数据格式变换、重复记录辨别、规则设定和分析、数据校验、结果显示和交互等模块,模型运行过程如图1 所示。
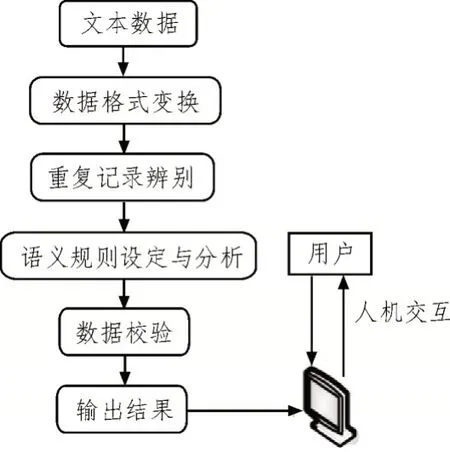
图1 语义合规性校验模型运行过程
3.2 功能模块分析
3.2.1 数据格式变换
用户挑选需要校验的调度命令票数据项,加载相对的数据表、Excel 数据表,通过数据格式变换模块将数据表封装成Java 数据目标列表[14]。数据变换操作中,还能挖掘调度命令的调度类型错误,变换流程如图2 所示。
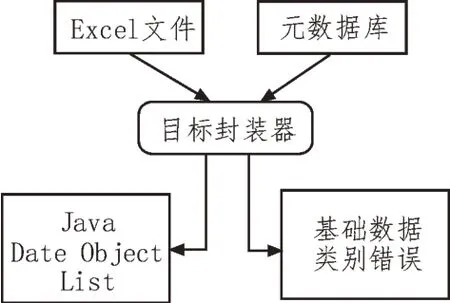
图2 数据格式变换流程示意图
3.2.2 重复记录辨别与规则设定
按照编辑距离和距离算法,寻找相似度较多的记录,让用户估算是否具备多次录入状况。
在用户设定的校验规范内,某些值源自往年观测数据的平均值、最高值、最低值、空间变异等统计变量,用户按照自己对网络的熟练程度,使用不同的层次设定,拓展原始规则库。
3.2.3 数据校验与输出
凭借用户自定义的规则,对数据表实施校验,同时把校验结果记录至各个错误列表内。数据输出过程中,用户根据校验结果,挑选是否进行校验值输出,输出包含两种模式[15]:一是以Excel 表的模式导出并引入语义合规性校验结果的Excel 文件;二是把数据输出值储存在数据库。数据输出前,用户首先编辑规则,然后进行校验,直到输出准确的合规性校验结果。
3.3 模型实现
规则引擎架构如图3 所示。
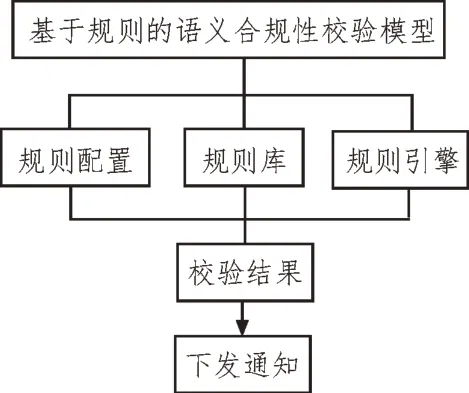
图3 规则引擎架构
模型设计使用规则定义语言,规则定义语言是在模板语言前提下,实施二次改造开发得到的。规则定义语言可以在校准过程中,准许人为控制变量,动态地把语义本文引入模板内替换任意变量,确保在不同环境下的高效率应用。其次是规则分析技术与背景知识库技术。通过解析模式串后返回的字符串判断是否满足模式串描述的规则。背景知识库技术中,通过专家描述文本语义数据格式、临界值及作用于填充缺失值的某类数值,反复记录度量规则,数据规则设定时要代入的关键值也源自背景知识库。规则分发技术使用可扩展标记语言来描述,因此在每个校验流程中均能完成自由分发[16]。
4 仿真实验
为检测该文语义合规性校验模型性能的优劣[17],对其进行仿真实验分析,实验计算机硬件环境是Intel(R)Core(TM)CUP T6600,2.2 GHz,仿真软件是SimuWorks。
图4 为该文方法与文献[14]、文献[15]的语义合规性校验输出频谱的比较情况。

图4 语义合规性数据校验输出频谱对比图
根据图4 可知,文献[14-15]方法语义合规性校验受到冗余数据干扰较多,振幅频度较高,这样会大幅降低语义合规性校验精度。而该文方法具备极强的抗干扰能力,旁瓣波束抑制性能也得到显著增强,可以充分保证智能配电调度命令票语义规范性。出现此种现象的原因在于,该文方法采用k 均值聚类算法,可以快速精准分类文本信息,一旦校验结果显示某个数据为冗余数据,则判断该数据集合为冗余数据集合,从根本上剔除冗余数据对校验的干扰。
5 结论
为提升智能配网调度命令票文本语义规范性与准确性,设计基于规则的调度命令票语义合规性校验模型。与传统方法相比,所建模型抗干扰能力强,校验精度高,时延低,可充分保障调度命令票内容的严谨性,提升调度员工作效率,为实现智能配网高质量电力调度提供扎实基础。
猜你喜欢
娃娃乐园·综合智能(2022年3期)2022-04-19
中学生学习报(2022年15期)2022-04-17
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
军营文化天地(2018年2期)2018-04-20
中国铸造装备与技术(2017年6期)2018-01-22
电子制作(2017年1期)2017-05-17
中国老区建设(2016年9期)2016-02-28
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01
创新科技(2014年14期)2014-07-27
