
大坝安全监测数据的治理与统计
2023-01-03 10:36冯涛
大坝与安全 2022年5期
冯涛
(中国电建集团华东勘测设计研究院有限公司,浙江 杭州,311122)
0 引言
近年来,随着信息自动化技术的快速发展,大中型水电站大坝安全监测自动化采集系统不再局限于内观仪器,外观测量机器人、GNSS、图像监测等新的自动化监测手段逐步得到广泛应用。自动化采集系统按照固定的采集频次自动完成数据的采集、计算、入库等一系列工作。
自动化采集系统代替了人工采集作业,降低了监测工作的强度和难度,尤其某些特殊部位,观测人员很难到达,自动化监测系统能很好地完成日常数据采集工作。同时实现了采集远程控制、即时采集,减少了人工采集误差,较大提高了采集频次,从而产生了大量的安全监测数据,为在线监控预警及后期的监测资料整编与分析提供了技术支撑。
自动化采集系统存在数据量大、数据错误、数据不规范、数据异常等情况,在分析监测数据时,需要对数据进行清洗、治理、统计、分析和提炼,从而获取其中有价值的数据,构建数据产品,再结合水工建筑物的特点,辅以各种监控模型进行有针对性的评判分析,更好地掌握大坝安全运行性态。
1 软件实现思路
利用大数据治理的思想,软件采用前后端分离的架构来完成数据统计工作,将数据清洗、数据统计和数据服务工作置于后台,提高效率,并减少前端用户的消耗。图1为数据治理与统计的软件实现思路。

图1 数据治理与统计的软件实现思路Fig.1 Realization of data management and statistics by software
首先由后台采集服务从各自动化采集系统、人工数据录入系统获取大坝安全监测数据,经过数据清洗和治理形成大坝安全数据仓库。
后台统计服务再按照统计方案,对数据仓库中的数据进行统计,将结果分类保存,形成不同的数据产品,最终服务于前端各类应用。
为了提高数据质量,需要对采集到的数据进行处理,从数据完整性、统一性、有效性上保证数据质量。图2为数据产生到形成数据产品的流程。

图2 大坝安全监测数据产品流程Fig.2 Generation of dam safety monitoring data products
2 数据集成
数据集成是对自动化系统采集数据和人工采集数据的汇聚过程,包括对历史观测数据的批量导入,人工观测数据的录入、导入,自动化采集数据的批量导入,以及远程自动化采集等。集成数据源包括各种类型的数据库、文本文件、Excel 文件等。
集成的数据包括外观数据、渗流数据、应力应变及温度数据、水雨情数据、微震数据、强震数据和巡查数据等。数据集成技术目前已相对较成熟。
3 数据治理
首先,需要构建一套大坝安全监测数据标准,提供全面完整的数据标准管理流程及办法,用于决定和建立单一、准确、权威的事实来源,实现数据的完整性、有效性、一致性、规范性、开放性和共享性管理,并为数据质量检查、数据安全管理提供标准依据。数据治理的过程就是将集成汇聚的数据按照统一标准进行格式化处理和存储。
其次,需要对采集汇聚的大坝安全监测数据进行清洗。数据清洗指发现并纠正数据文件中可识别的错误,包括检查数据一致性、处理无效值和缺失值等。数据清洗也是整个信息化实施过程中不可缺少的一个环节,其结果质量直接关系到整个信息化的最终实施效果。
“脏数据”通常包括不完整的数据、错误的数据和重复的数据。大坝安全监测数据从内观、水雨情、地震、外观等不同自动化采集系统中汇聚而来,而且包含多年历史数据,不可避免有数据错误、数据相互之间有冲突的情况。按照一定的规则先清洗“脏数据”,过滤不符合要求的数据。
系统采用后台服务的方式部署数据治理软件,监控数据变化。一旦数据发生了变化,则针对相关数据启动治理服务,确保数据的完整性、统一性和有效性。
3.1 格式处理
格式问题是一个细节问题,格式不统一将直接影响分析判断的执行,如跨表关联失败、数字格式不匹配导致无法识别、不同分量测值颠倒等情况。为了保证数据源在格式和内容上与元数据的描述保持一致,需要从以下几个方面考虑对大坝安全监测数据进行格式化处理:
(1)时间、日期、测量单位等转换。这类问题通常与输入端有关,在整合多来源数据时也有可能遇到,需要将其处理成一致的某种格式。大坝安全监测管理中,针对同类仪器的监测量,不同的采集系统可能存在不同的测量单位,时间、日期格式可能也有差异,需按照统一的数据标准对这类存在差异的数据进行格式化处理。
(2)分量错位纠正。人工采集的数据最容易出现分量错位问题,如数据在Excel 中没有对齐,或复制粘贴时导致数据列错位。自动化系统通道配置也存在错列情况,最终导致左、右读数,相对量与累计量存储错位等问题。通过经验对比,发现类似问题后,经现场人工确认,对分量列进行置换处理。
(3)“非法”字符。在测值、测点名、监测量名中存在空格、逗号等特殊非法字符的现象。该情况下,数据治理时需对每份数据做合法性校验,并自动剔除常见的特殊字符,经过多次校验仍不能成功的,再辅助人工方式找出可能存在的问题,并去除不需要的字符。
3.2 缺失值处理
监测数据在一段时间内的缺失也是一个常见的问题,主要分以下几种情况:
(1)单个测点部分测次单个分量值缺失:考虑仪器某个通道采集不稳定等情况;
(2)单个测点所有测次单个分量缺失:考虑仪器某个通道异常、计算公式无法正常计算等情况;
(3)单个测点部分测次整条记录缺失:考虑仪器采集不稳定、通信不稳定等情况;
(4)单个测点所有测次整条记录缺失:考虑仪器损坏、通信故障等情况;
(5)某个采集模块内容所有测点整条记录缺失:考虑模块损坏、模块通信故障等情况。
针对上述各种数据缺失的情况,采取以下步骤对缺失数据进行处理:
(1)缺失原因分析:分析每个监测量的缺失情况和属性,判断是原始量缺失、中间成果缺失还是成果量缺失,并根据缺失的五种情况进行初步的原因分析。原始量缺失可以从采集上查找原因,成果量缺失则可以从计算公式和参数上查找原因。
(2)缺失值填充:部分缺失值可以通过对比、计算进行填充。如某些环境量值,因其在短时间内变化较小,可以采用插值算法自动填充;针对某些中间成果值或成果量值,则可以通过计算进行填充。
(3)重新采集:重新采集数据也是一种填充方式,提供二次仪表录入新测值,或自动发起采集指令,由自动化采集系统重新采集数据回填。
3.3 逻辑错误处理
(1)去重。部分数据在系统中会存在重复现象,可能是由于数据不规范导致,如单位名称有全称和简称等多个表述,但实际上属于同一个单位。需针对此类数据进行合并去重。监测数据也存在相同测点、相同观测时间的重复问题,由于大部分采集系统将采集时间定在8∶00 或某个时间,导致出现同一日期采集的多条数据重复的现象,这类数据变化不大,通常保留最后一次入库的数据即可。
(2)异常检测。根据每个变量的合理取值范围和相互关系,检查数据是否满足要求,发现超出正常范围、逻辑不合理或相互矛盾的数据,如气温高于50℃、水位高于坝顶高程等,都应视为超出正常值域范围。
(3)矛盾值纠错。这类错误主要由计算导致,根据测值之间的相关性、测值来源判断数据的可靠性,通过对应的规则(或公式)删除或重构数据,以解决数据之间的矛盾,使数据有效。
4 数据统计
所有统计必须设置统计范围,包括统计对象(测点、监测项目、监测量)、统计时间区间、测值属性(人工观测、自动化观测)、统计方法(按实际值、按绝对值)等。其中,统计对象最小单位为单个测点的单个监测量;统计时间区间为统计数据观测时间的起止范围;测值属性可选择仅针对人工测值、仅针对自动化测值或针对全部测值;统计方法可以按照正常测值大小不做任何换算,也可以将测值全部转换成绝对值后再进行统计。
系统采用后台服务的方式部署数据统计软件,在数据治理完成后启动统计服务,实现对大量数据的瘦身和提炼,为后期数据应用和展示提供支撑。
4.1 特征值统计
4.1.1 时段特征值统计
时段特征值统计(见图3)针对单个测点、单个监测量的有效测值,统计的监测数据观测时间必须在指定的时间区间内,统计内容包括:

图3 时段特征值统计模块展示Fig.3 Display of the statistics module of period characteristic values
(1)时段最大(小)值及其发生时间:指定时间区间内所有测值的最大(小)值及其对应的观测时间。如果该时间区间内最大(小)值出现了多次,则可取最晚一次观测时间。
(2)平均值:指定时间区间内所有测值的平均值。
4.1.2 年度特征值统计
年度特征值统计(见图4)针对单个测点、单个监测量的有效测值。首先将指定的统计时间区间按照自然年分成不同的年度子区间,计算每个子区间的开始时间和截止时间,按照不同年度子区间分别统计。统计内容包括:
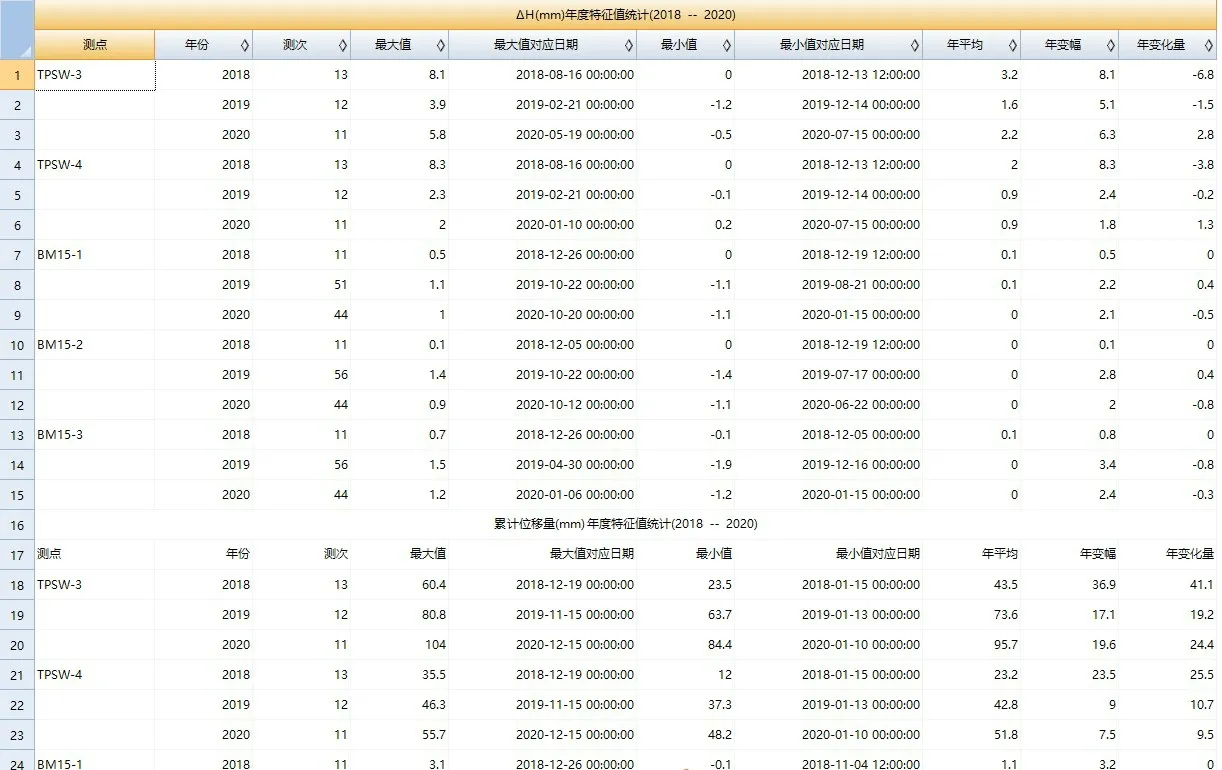
图4 年度特征值统计模块展示Fig.4 Display of the statistics module of annual characteristic values
(1)年份:将指定的时间区间按自然年划分出的年度子区间。
(2)测次:每个年度子区间的有效测次。
(3)最大(小)值及其发生时间:每个年度子区间所有测值的最大(小)值及其对应的观测时间。如果该年度子区间内最大(小)值出现了多次,则取最晚一次观测时间。
(4)年平均值:每个年度子区间所有测值的平均值。
(5)年变幅:每个年度子区间所有测值最大值与最小值的差。
4.1.3 月份特征值统计
月份特征值统计(见图5)针对单个测点、单个监测量的有效测值。统计内容包括:
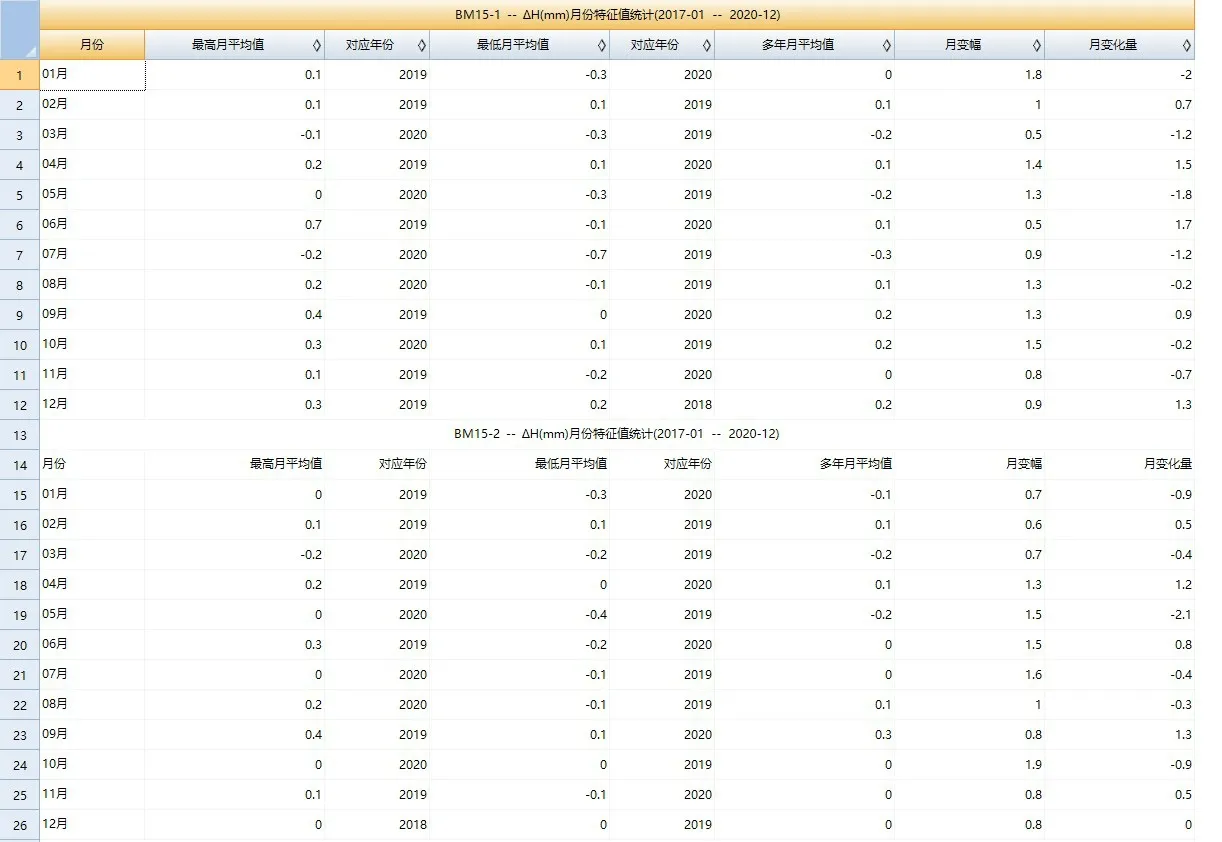
图5 月份特征值统计模块展示Fig.5 Display of the statistics module of monthly characteristic values
(1)月份:指定的时间区间所包含的月份数字,时间跨度超过11个自然月时,包括1~12个自然月。
(2)最高月平均值及对应年份:将统计时间区间内的数据按照各个不同的自然年月计算平均值,然后再取这组平均值的最大值及其对应年份。
(3)最低月平均值及对应年份:将统计时间区间内的数据按照各个不同的自然年月计算平均值,然后再取这组平均值的最小值及其对应年份。
(4)多年月平均值:将统计时间区间内不同的自然月数据作为统计基数,计算平均值。如将所有年份中1月份的数据作为统计基数计算平均值,计算结果为1月份的多年月平均值。
(5)多年月变幅:将统计时间区间内不同的自然月数据作为统计基数,求最大值与最小值的差。如将所有年份中1月份的数据作为统计基数求最大值与最小值的差,计算结果为1月份的多年月变幅。
4.2 日常统计
按照不同的时间区间(日、周、月、季度、年份等)进行监测数据的日常统计和汇总。统计内容包括:
(1)最大值及其发生日期:每个统计时间区间内测值最大值及其对应的观测时间。
(2)最小值及其发生日期:每个统计时间区间内测值最小值及其对应的观测时间。
(3)平均值:每个统计时间区间内测值的平均值。
(4)变幅:每个统计时间区间内测值最大值与最小值的差。
4.3 相同条件下的统计
相同条件下的统计通常是指除设置的统计条件外,另外增加一些可变的条件,如历史同期、相同环境等条件下的统计。
(1)历史同期:统计每个测点每个分量在历年相同日期的测值,比较其差值变化。
(2)相同环境:统计每个测点每个分量在历史同水位、同温度等情况下的测值,比较其差值变化。
4.4 其他统计
根据水工建筑物结构的特点,某些数据分析还需对测值做一些特殊的统计,如极值出现情况统计、首尾测值统计等。
(1)极值出现情况统计:设置极值的大小范围或时间范围,即以某个测值作为极值标准,当统计范围内的值超过该值时,表明出现了极值,此时要统计极值的大小、极值出现的时间等。
(2)首尾测值统计:统计某段时间范围内第一期测值、最后一期测值及其观测时间、该时间区间内的变幅和变化速率等。
5 应用与实践
测值统计作为大坝安全管理信息系统的主要模块,从多维度对数据最大值、最小值和变幅等进行了统计,实现了历史同期值的对比分析,不仅为大坝安全性态的分析提供了手段,也为日常监测报表、分析报表的编制提供了数据来源。该模块在多个运行单位得到了很好的应用,使用频率很高,已逐渐成为水工观测人员日常工作必不可少的工具。
6 结语
通过集成监测数据形成大坝安全监测专题数据库后,对数据进行治理,确保用户获得有效、完整的数据,然后再通过数据统计,获取各类数据的特征及成果,对数据进行压缩提炼,最终形成可服务于监控分析的可视化数据。■
猜你喜欢
食品科学与人类健康(英文)(2022年4期)2022-06-20
网络安全与数据管理(2022年3期)2022-05-23
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
烟台大学学报(自然科学与工程版)(2020年1期)2020-02-08
百科知识(2018年6期)2018-04-03
课程教育研究·新教师教学(2016年18期)2017-04-12
少儿科学周刊·少年版(2016年4期)2017-02-15
全球定位系统(2015年4期)2015-02-28
数据(2009年1期)2009-04-08
