
基于改进YOLOv5s的行人车辆目标检测算法
2022-12-29 06:37章恩泽乐云亮
扬州大学学报(自然科学版) 2022年6期
蒋 超, 张 豪, 章恩泽, 惠 展, 乐云亮
(扬州大学信息工程学院, 江苏 扬州 225127)
随着中国城市化水平的发展, 城市道路拥挤已成为亟须解决的普遍问题, 其中交通目标的识别系统研究尤为重要.传统的检测方法如梯度直方图或支持向量机, 主要采用滑动窗口检测目标, 时间冗余长且手工设计的特征无鲁棒性[1].卷积神经网络中深度学习的实时性和准确性高, 且由于通过对大量样本的特征学习完成目标检测, 故在面对复杂图像识别问题时有着较好的鲁棒性[2]; 因此, 基于深度学习的目标检测算法成为当前机器视觉领域的主流方法.目前, 基于深度学习网络的目标检测方法主要分为如下2类: 1) 基于区域的方法.如R-CNN[3]、Fast R-CNN[4]、Faster R-CNN[5].首先利用选择性搜索、边缘检测和图像区域提取网络等技术生成可能包含目标的候选区域集合,然后通过神经网络对图像区域进行特征提取,最后进行边界框回归和预测.该类方法虽然精度高, 但由于提取大量的候选区域,导致处理效率低且推理速度慢; 2) 基于回归的方法.如YOLO[6]、YOLOv2系列[7]和SSD系列[8].该类方法无须提取候选区域,而是直接将图像输入网络进行卷积特征提取,再在特征图像上进行边界框回归, 检测时间大幅降低, 但精度受到一定影响.在实时性要求较高的场景中, 基于回归的方法应用更为广泛[9].
YOLO算法的结构简单且可以在保证高检测精度的前提下提高检测速度,被广泛用于行人车辆目标检测领域.张陈晨等[10]通过改变输入图像尺寸和使用部分池化层替换卷积层的方式对YOLO算法进行改进, 提升了车辆识别的检测精度; 袁小平等[11]针对YOLO算法对中小目标检测效果不理想的问题, 在算法中引入密集连接实现特征重用, 提高了特征提取效率, 提升了对远处较小目标检测的准确率.然而, 由于参数量和计算复杂度较高,上述方法的检测速度偏低.作为当前YOLO系列最轻量化的模型,YOLOv5s的参数量和计算复杂度仍然较高, 故对部署平台的硬件要求较高[12].
Ghost模块[13]是华为公司于2020年提出的轻量化模块, 一定程度上可降低参数量和计算复杂度.本文拟采用YOLOv5s与ghost模块相结合的方式, 进一步降低网络参数量和提高检测速度, 使得网络的性能更加均衡, 并在网络中引入注意力机制(efficient channel attention, ECA)[14], 以期让特征层的通道通过共享权重参数实现通道之间的信息交互, 使得网络更关注重要特征的学习.此外, 通过改进边界框回归损失函数中宽高比的计算, 促使损失函数更快收敛.
1 改进的YOLOv5s目标检测算法
1.1 YOLOv5s算法
YOLOv5s网络结构主要分为输入端、Backbone、Neck和输出端4个部分, 如图1所示.在输入端对图像进行预处理, 完成Mosaic数据增强、自动计算锚框和自适应图像缩放.将图像输入Backbone部分进行Focus操作, 即对图像进行切片操作, 每隔一个像素取一个值,将原始图像划分为4份数据, 该方式可以减少下采样导致的信息损失.跨阶段局部(cross-stage partial, CSP)模块在主干网络中主要是用作局部跨通道融合, 利用每层的特征信息获取更加丰富的特征图像.在Neck部分通过上采样层和CSP模块将高层的语义信息与底层的位置信息相融合,进而得到预测的特征图像并将其输入输出端.输出端拥有3种不同尺寸的特征图像,根据各特征生成预测框进行非极大值抑制,保留局部类别置信度较高的预测框.

图1 YOLOv5s的网络结构Fig.1 Network structure of YOLOv5s
1.2 YOLOv5s改进算法
1.2.1 主干网络的改进
基于YOLOv5s模型, 采用ghost模块替换主干网络中2个CSP模块进行模型剪枝, 改进后的YOLOv5s模型结构如图2所示.将ghost模块中通道分为2个相等部分, 一部分通过1×1卷积和3×3 深度可分离卷积后与另一部分并联.首先利用1×1卷积和3×3深度可分离卷积组合模块替换传统的卷积, 通过1×1卷积生成更少通道数的特征层,然后利用深度可分离卷积对生成的特征层进行简单运算,最后将其拼接成与原始尺寸相同的特征层.随着特征层数的叠加,主干网络中特征层的尺寸越来越大,网络的参数量也更为庞大.据分析, 使用ghost模块替换网络中参数量最大的2个模块能有效降低网络的参数量和计算量.

图2 改进后YOLOv5s的网络结构Fig.2 Network structure of the improved YOLOv5s
1.2.2 注意力机制的引入
输入特征图像经全局平均池化得到一维特征图像,然后通过权重共享的一维卷积学习各通道的权重, 其中一维卷积代表模块跨通道信息的交互率,其卷积核大小随通道数的变化而改变.对一维特征图像进行Sigmoid函数操作,将原特征图像与一维特征图像相乘得到新的特征图像,可有效解决通道数变化导致的信息丢失等问题[14].为了提升网络的性能, 本文将如图3所示的ECA模块与网络中的CSP 模块相结合, 对重要特征层进行通道上的注意力学习.

图3 ECA模块Fig.3 ECA module
1.2.3 边界框回归损失函数的优化
目标检测算法在训练时须降低边界框回归损失,使得预测框在预测过程中更加接近真实框的位置和尺寸.YOLOv5s的边界框回归损失函数由真实框与预测框的交并比(intersection over union, IOU)损失、中心点距离损失、宽高比距离损失等三部分组成.损失函数

(1)
其中IOU用来衡量预测框与真实框的重叠程度, IOU值越高, 预测框与真实框重合程度越高, IOU损失则越小;ρ2(·)为欧氏距离;b,bgt分别为预测边界框和真实边界框的中心点;C为两个候选框中最小包围框的对角线长度,当两个锚框中心点距离越小时其中心点距离损失越小;α为平衡参数;wgt,hgt分别为真实边界框的宽和高;w,h分别为预测框的宽和高.
边界框回归损失函数(1)的最后一项为宽高比距离损失,通过分别计算真实框与预测框的宽高比值,可以优化二者宽高比之间的距离.然而,宽高比距离损失定义的宽高比为相对值,而不是分别考虑宽和高的差异,当预测框与真实框之间的宽高比呈线性关系时预测框的宽和高不能同时增加或减小,此时网络将无法继续收敛.为了避免上述问题,本文直接计算预测框与真实框宽和高的差值,替代原有宽高比的距离损失,其更新后的损失函数
(2)
其中wc,hc分别为覆盖真实框与预测框的最小外接框的宽度和高度.
2 实验结果与分析
2.1 数据集
实验采用的数据集由HUAWEI P40 Pro拍摄, 包含公交车、轿车、电动车和行人等4类检测目标,共908幅图像.将该数据集按照3∶1∶1划分为训练集(545幅)、验证集(182幅)、测试集(181幅), 数据集中4类检测目标的数量分布如表1所示.
2.2 训练环境与检测性能评价
实验平台为AMD Ryzen 7 4800H@2.90 GHz,16 GB内存,Nvidia GTX3060显卡, CUDA版本

表1 数据集中各目标的数量分布
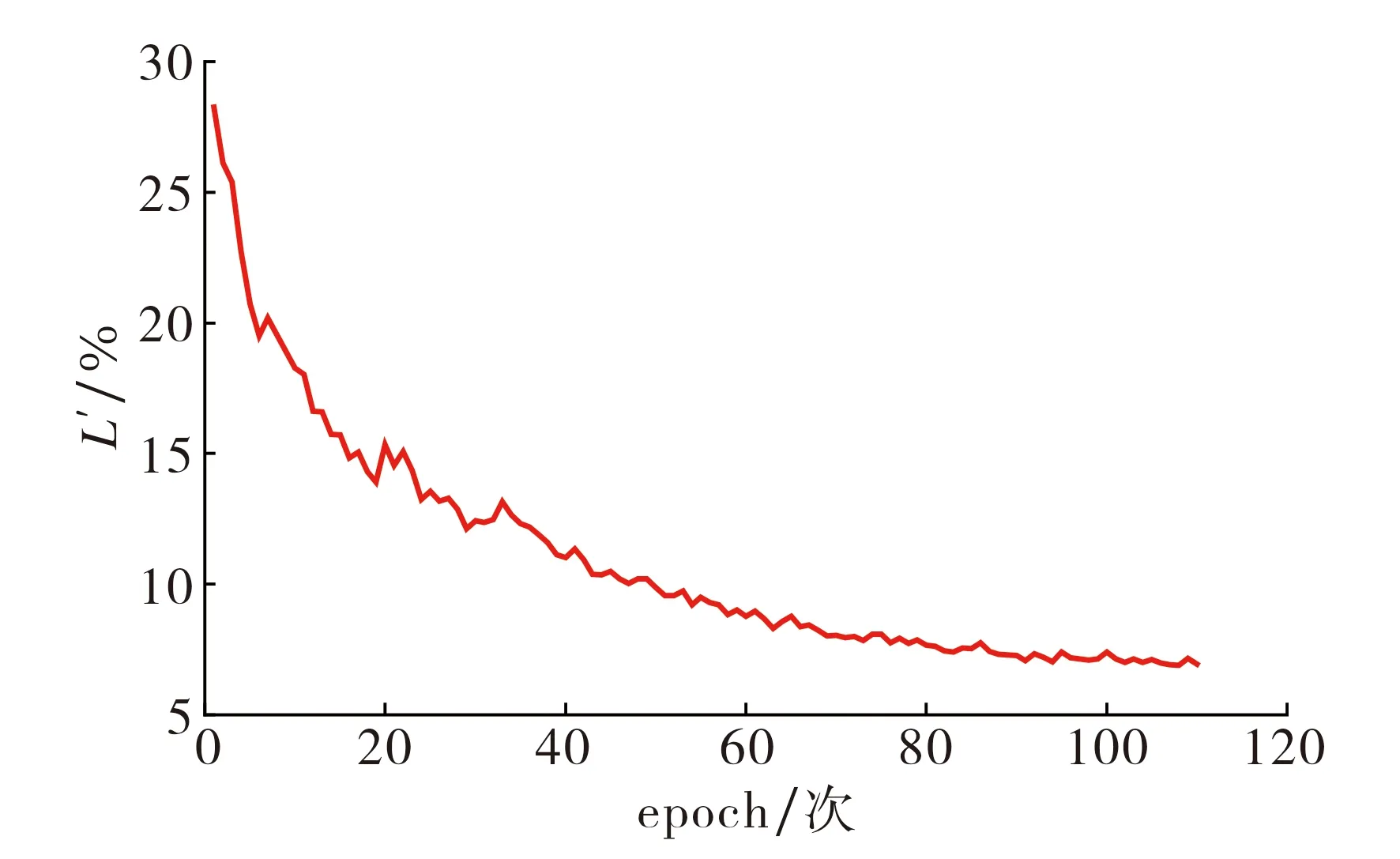
图4 损失函数的训练曲线Fig.4 Training curve of the loss function
是11.2, 深度学习框架为Pytorch.网络每训练一遍数据集, 称为1个epoch,该模型共训练110个epoch.训练过程中的损失函数曲线如图4所示.由图4可见: 随训练次数增加,训练过程中的损失逐渐收敛,在完成100个epoch后损失逐渐平稳.
图像目标检测的重要评价指标主要有平均精度(average precision, AP)和平均精度均值(mean average precision, MAP),其计算式如下:
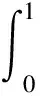
(3)
(4)
其中P为精确率, 表示真正的正样本占预测正样本的比例;R为召回率, 表示真正的正样本占实际正样本的比例;c为预测的类别;n为类别的数量.
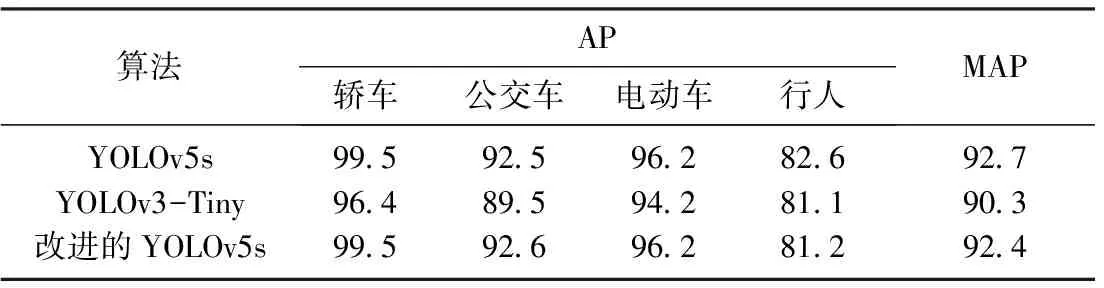
表2 不同算法的检测精度

表3 不同算法的性能
对比YOLOv5s[12]、YOLOv3-Tiny[10]和本文改进的YOLOv5s等3种轻量化目标检测算法的性能, 结果如表2~3所示.由表2~3可知: 1) 3种算法都对轿车类别检测的效果最好,主要是由于轿车类别在数据集中的目标数量比例较高, 致使网络对轿车的学习较充分,同时在数据集中轿车属于中型尺寸, 受物体遮挡或距离的影响较小; 2) 3种算法对行人类别的检测效果最差,这是因为相较于轿车和电动车,行人类别数量较少,且行人类别在数据集中尺寸最小,较易受到物体大面积的遮挡或重叠,导致网络对行人类别漏检严重, 检测效果最差; 3) 本文算法对单个类别的检测精度明显高于YOLOv3-Tiny算法, 只是在行人单个类别上略低于YOLOv5s; 4) 改进后YOLOv5s算法的网络参数量、计算量、模型大小以及图像处理时间均优于其他2种算法, 其中参数量和模型大小较YOLOv5s算法分别下降28%和27%.其原因是使用ghost模块替换了主干网络中的部分卷积模块,而ghost模块可以通过一系列简单的线性操作生成更多的特征映射,有效减少了参数量,进而降低了计算量和模型大小.此外,注意力机制的引入使得网络在减少模型参数量的同时,保持了算法原有的检测精度.
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
小天使·二年级语数英综合(2019年10期)2019-11-08
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
共产党员(辽宁)(2015年2期)2015-12-06
